


Consecutive and Effective Facial Masking Using Image-Based Bone Sensing for Remote Medicine Education


Abstract
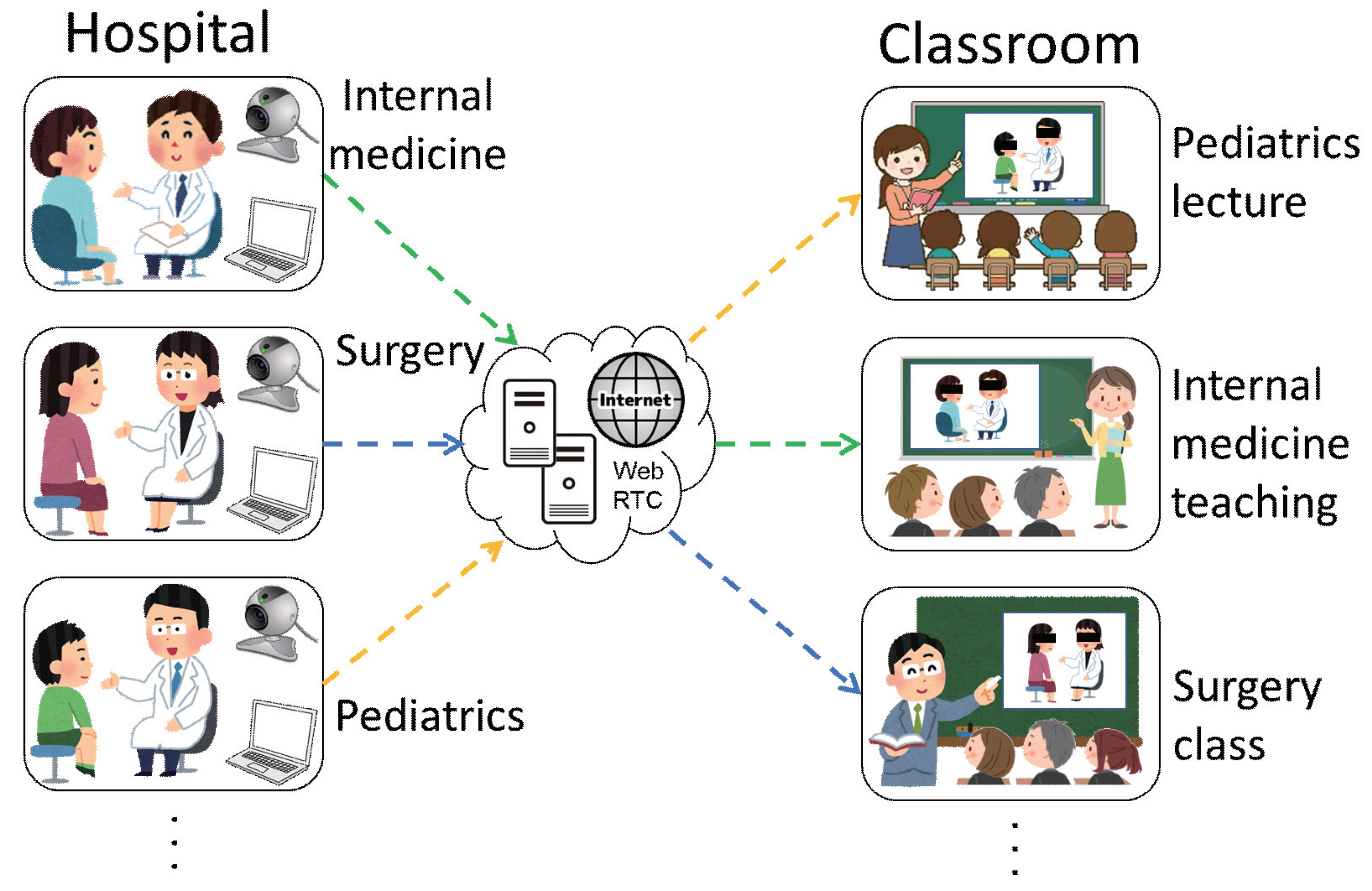
:1. Introduction
2. Related Work
3. Methodology
3.1. Purpose and Approach
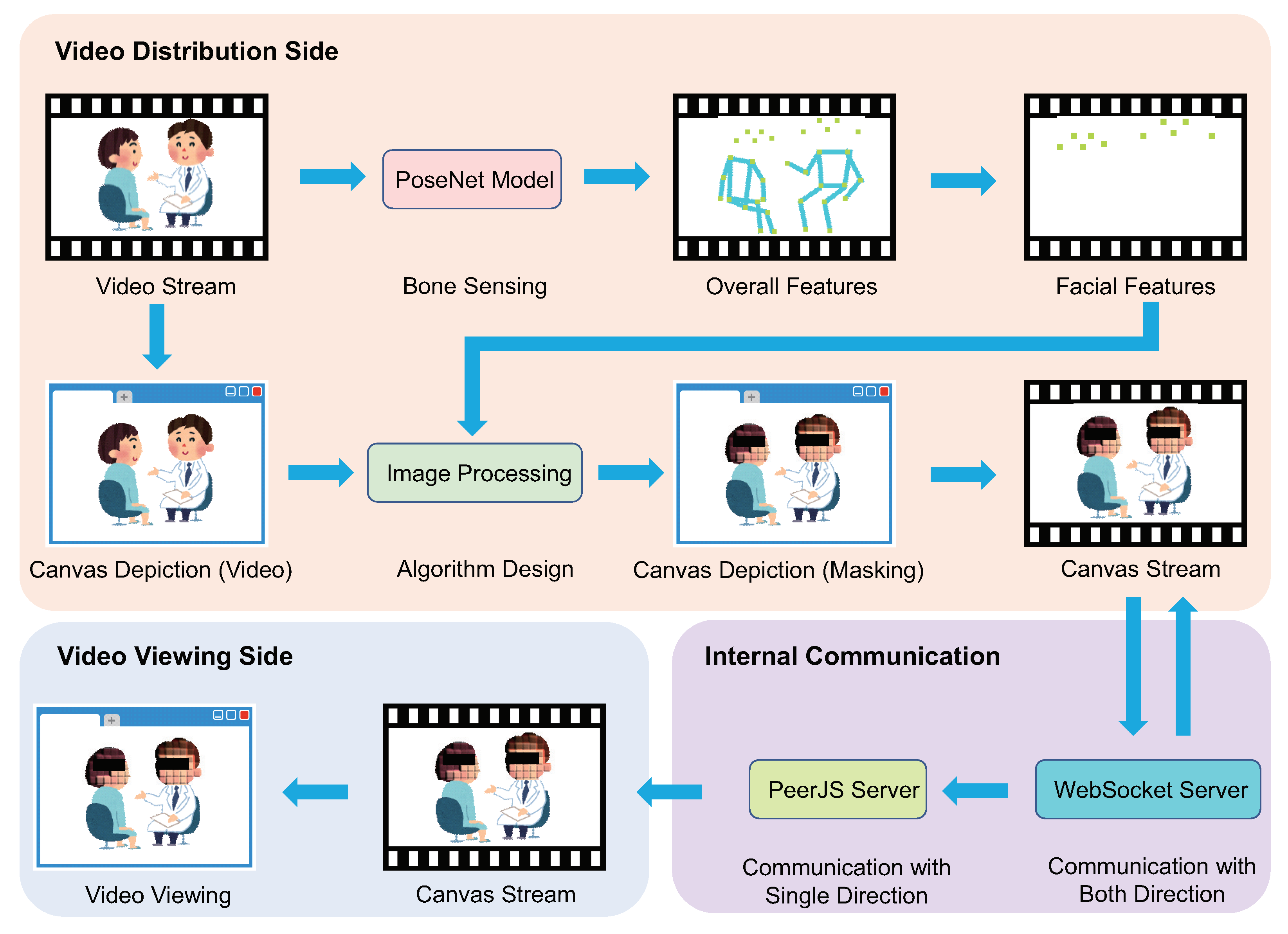
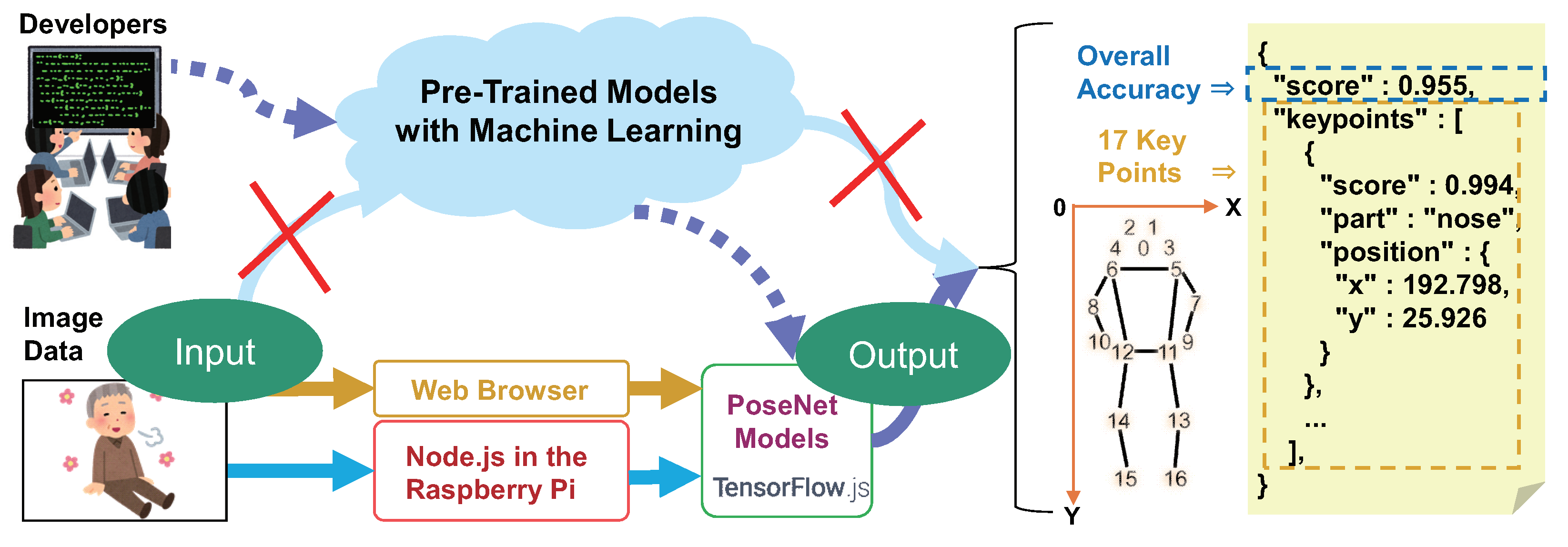
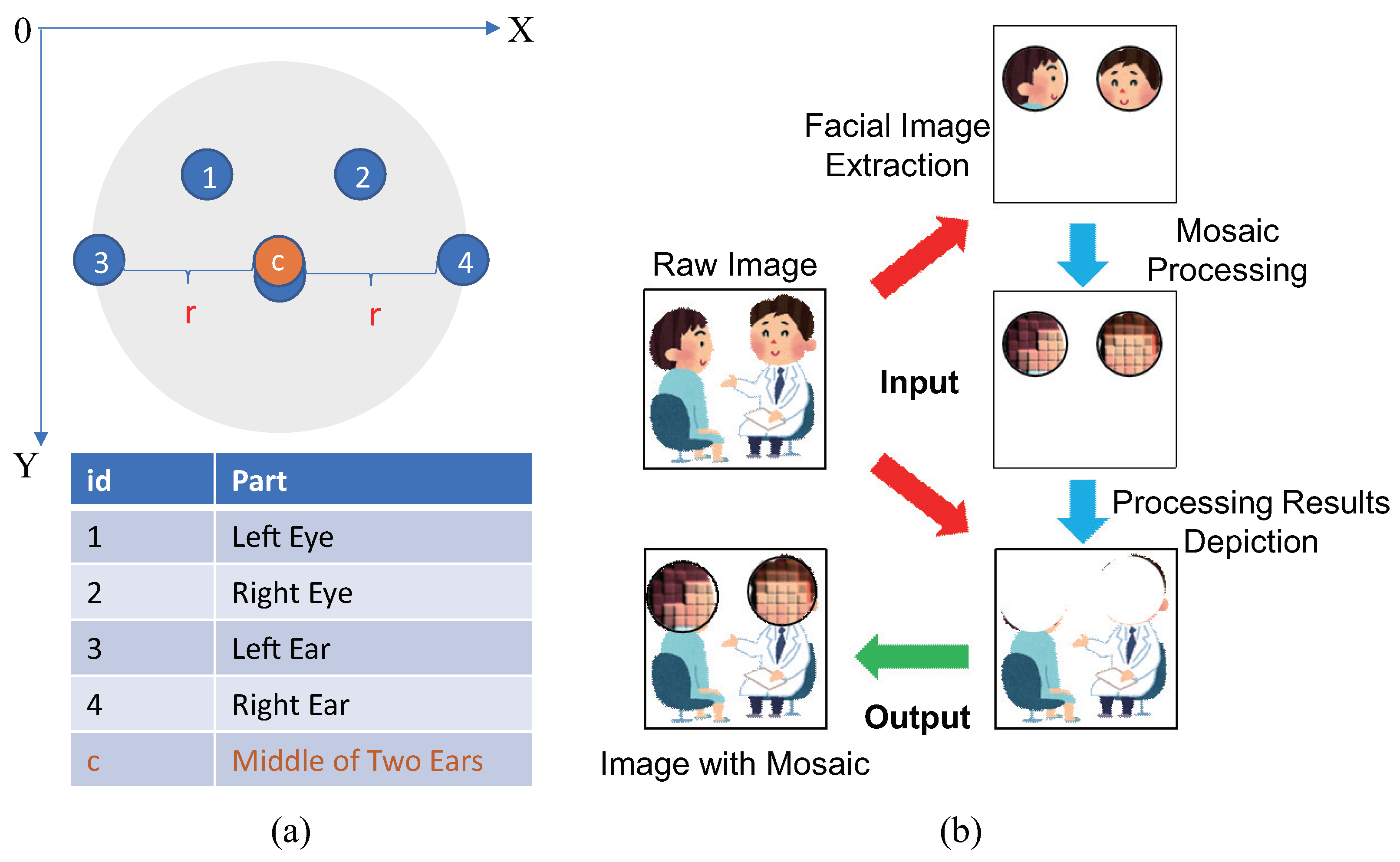
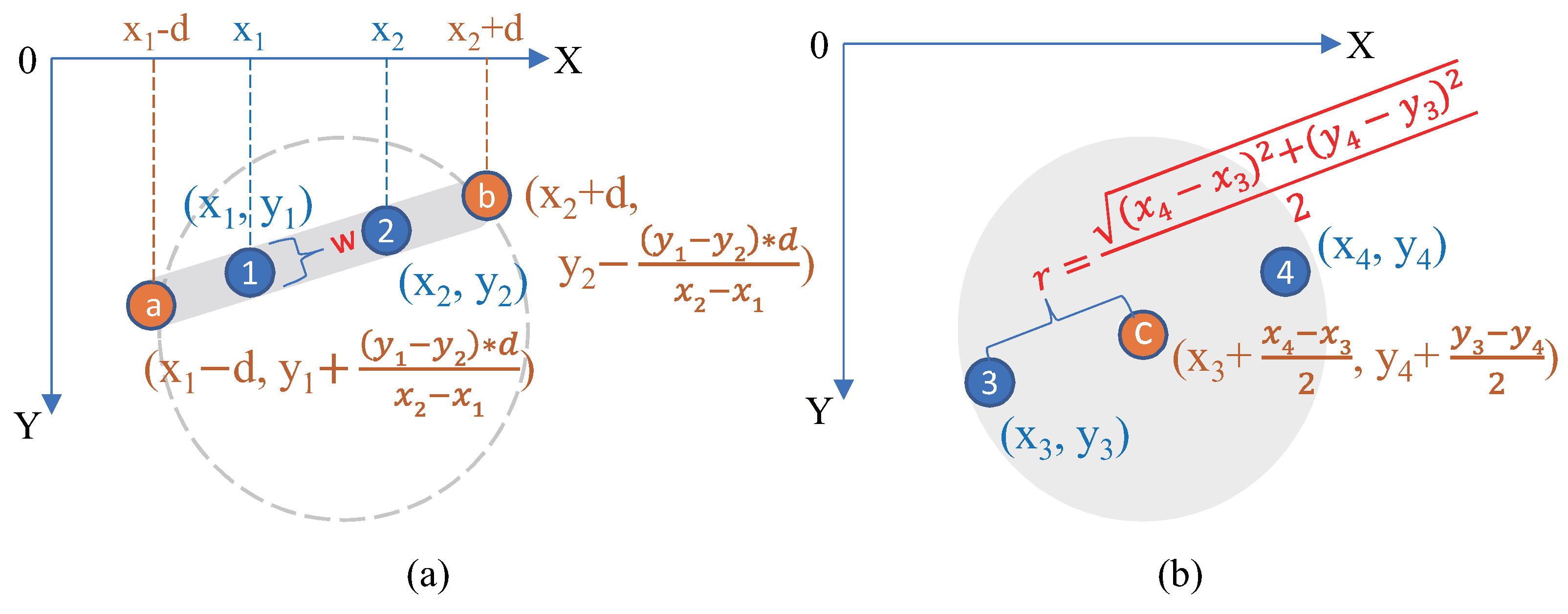
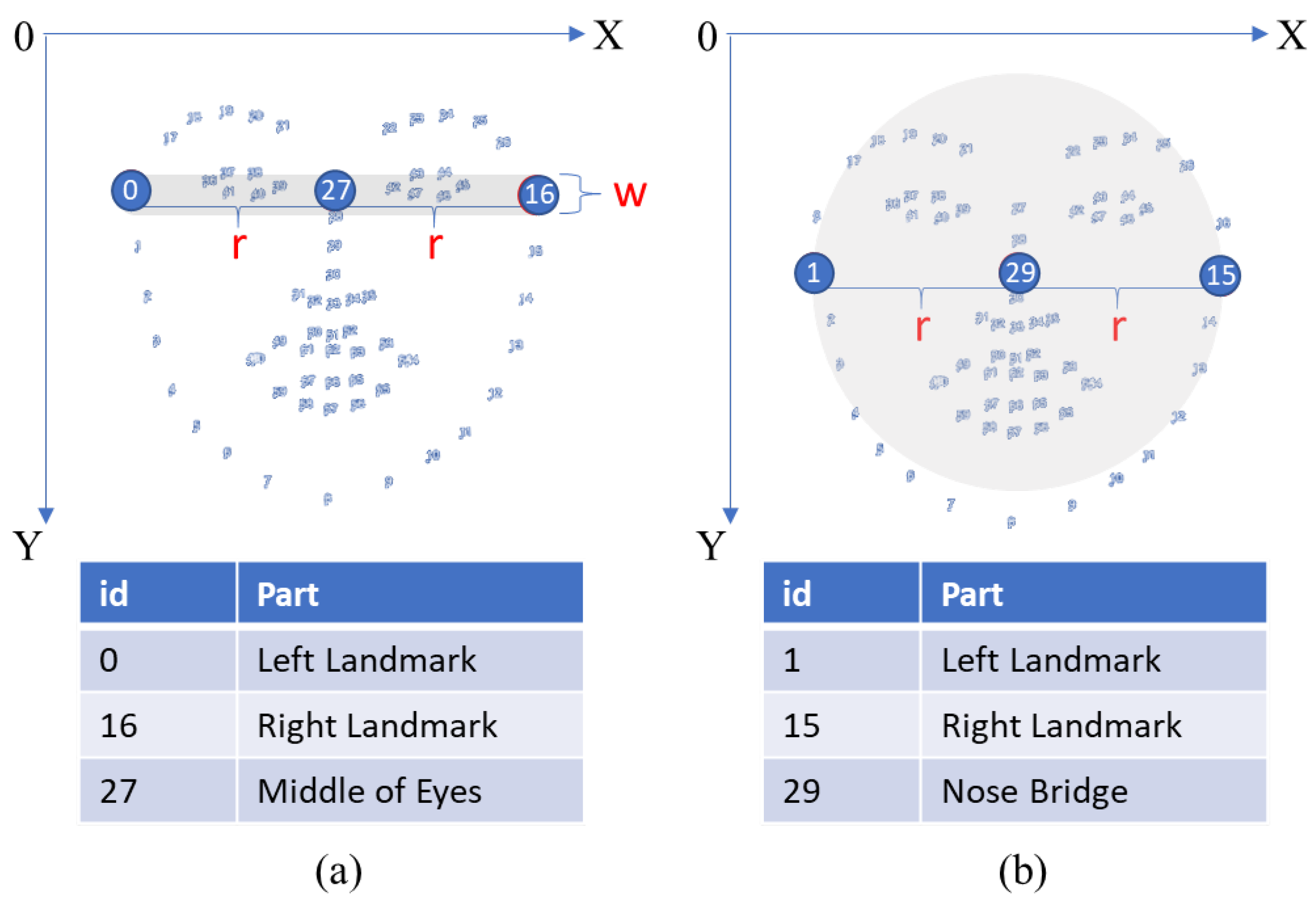
3.2. A1: Feature Extraction in Video Stream
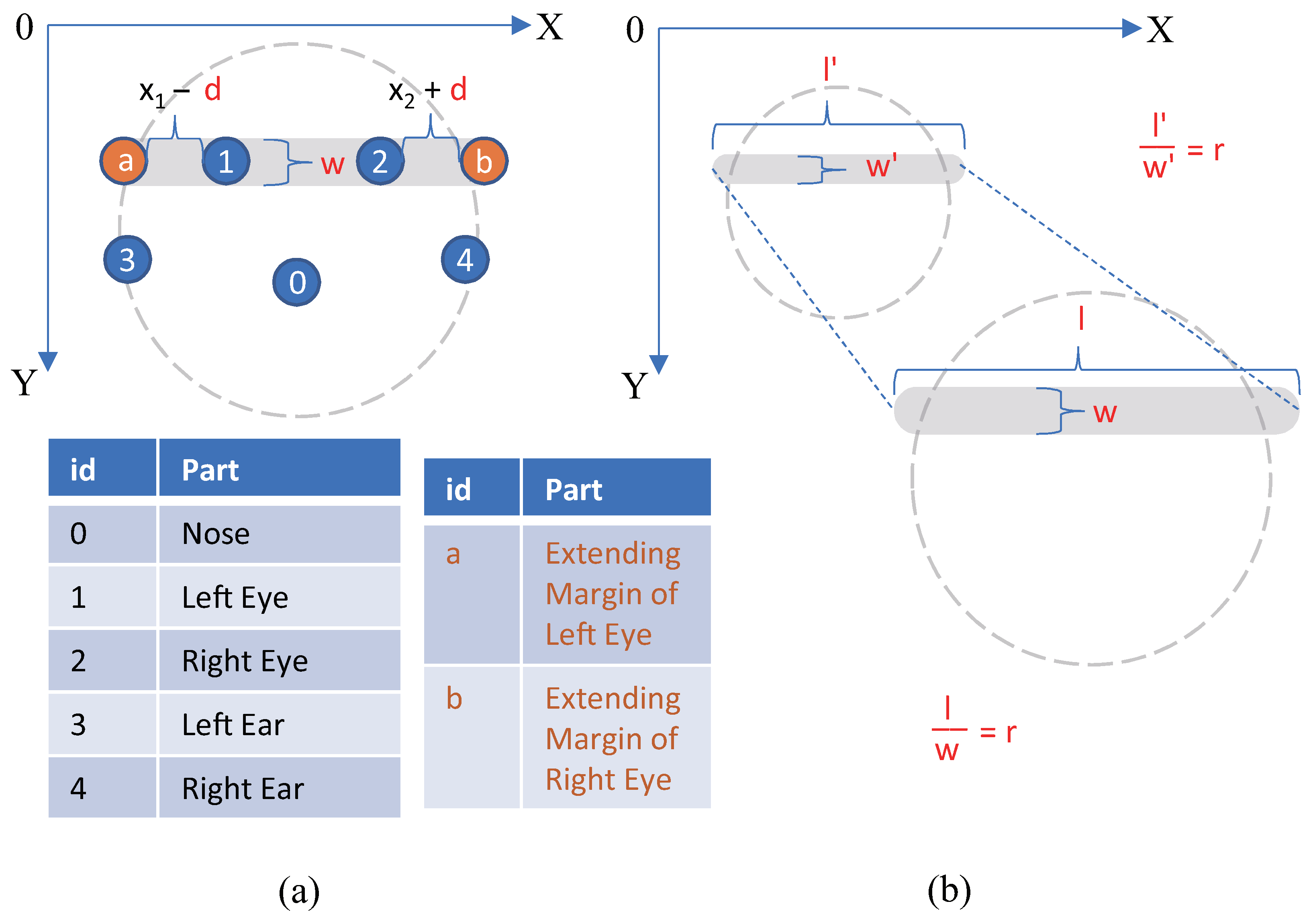
3.3. A2: Facial Masking Algorithm Design
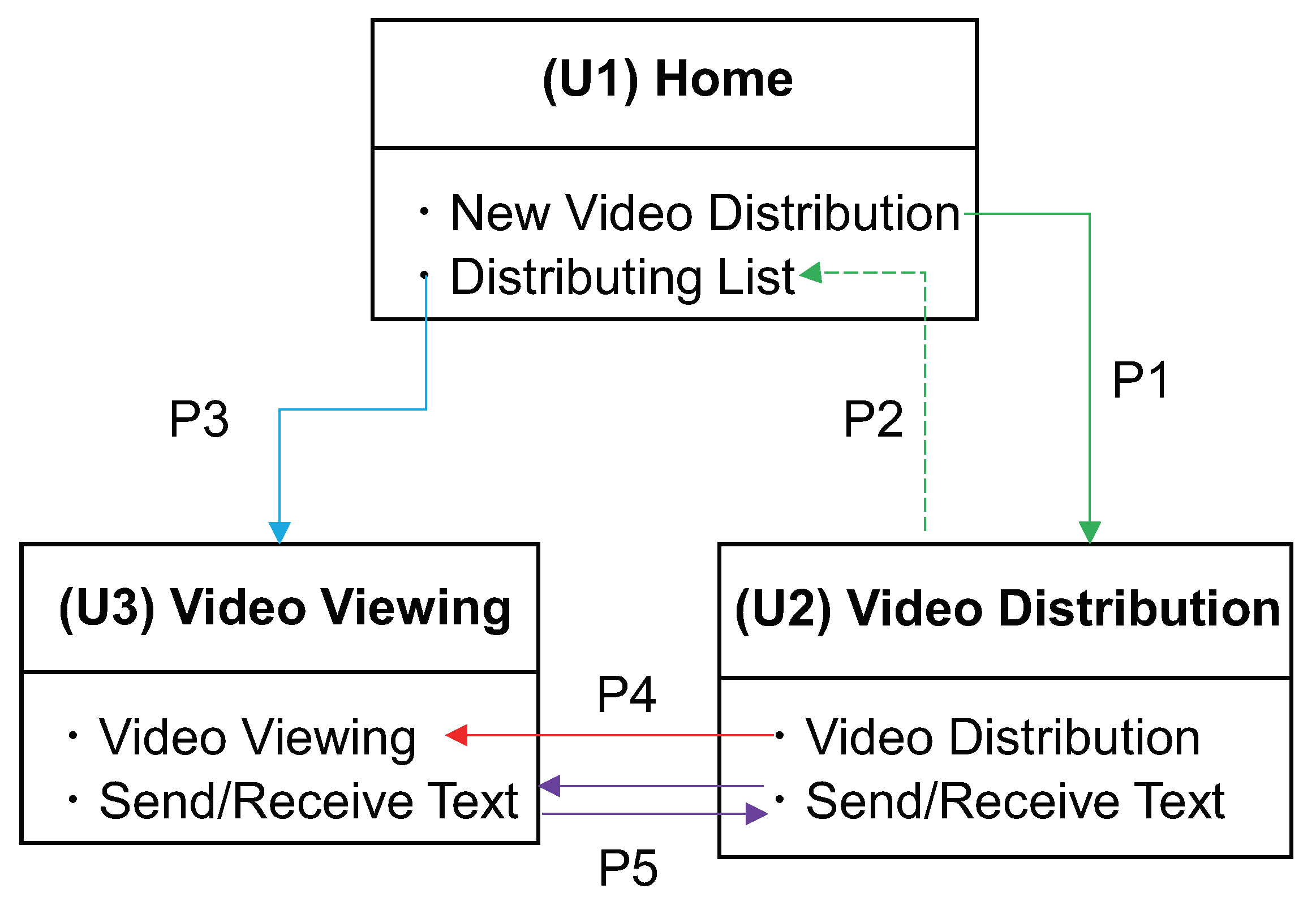
3.4. A3: Video Distribution Using WebRTC
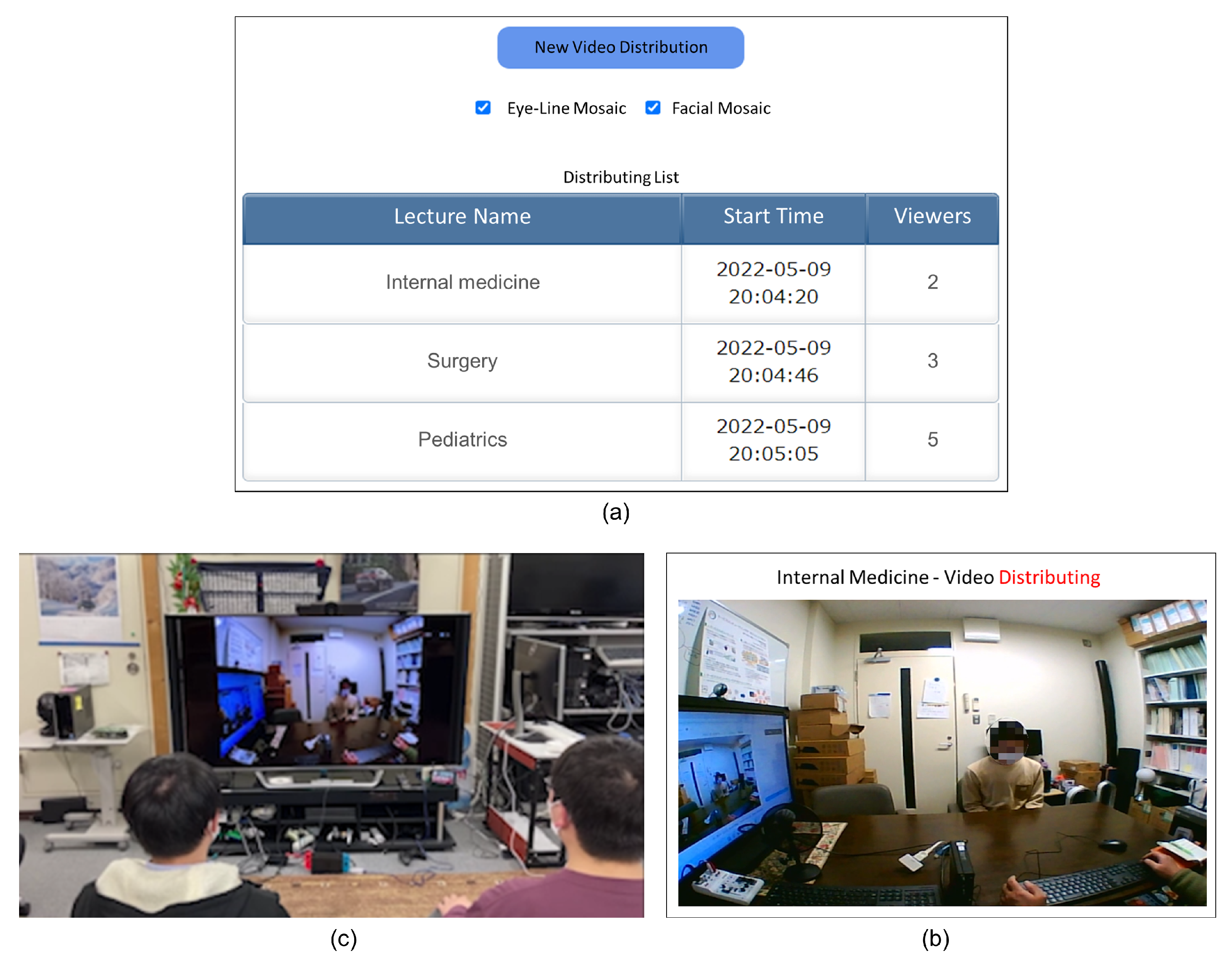
3.5. System Implementation
4. Preliminary Experiment
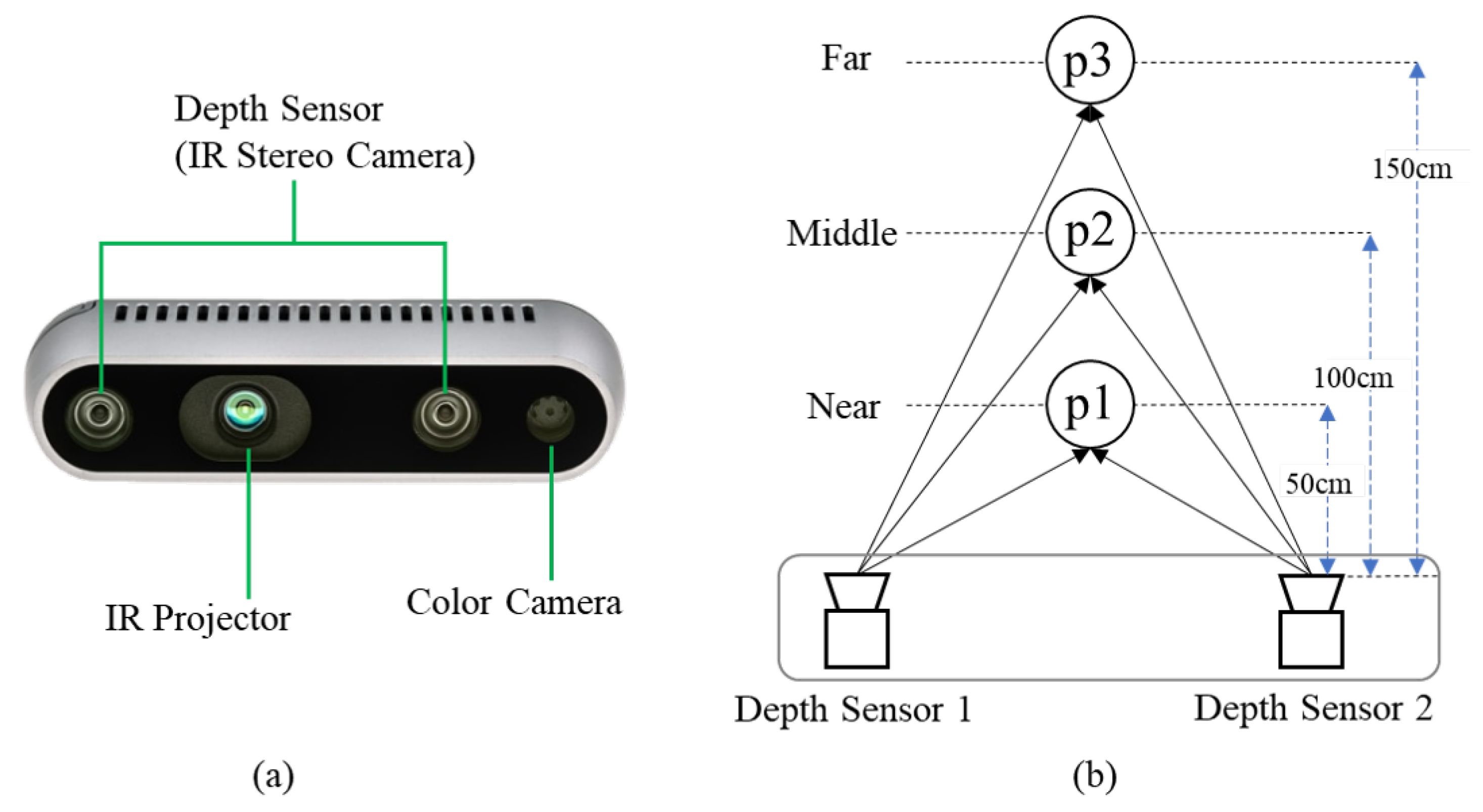
4.1. Purpose and Experimental Setup
4.2. Evaluation Method and Scale
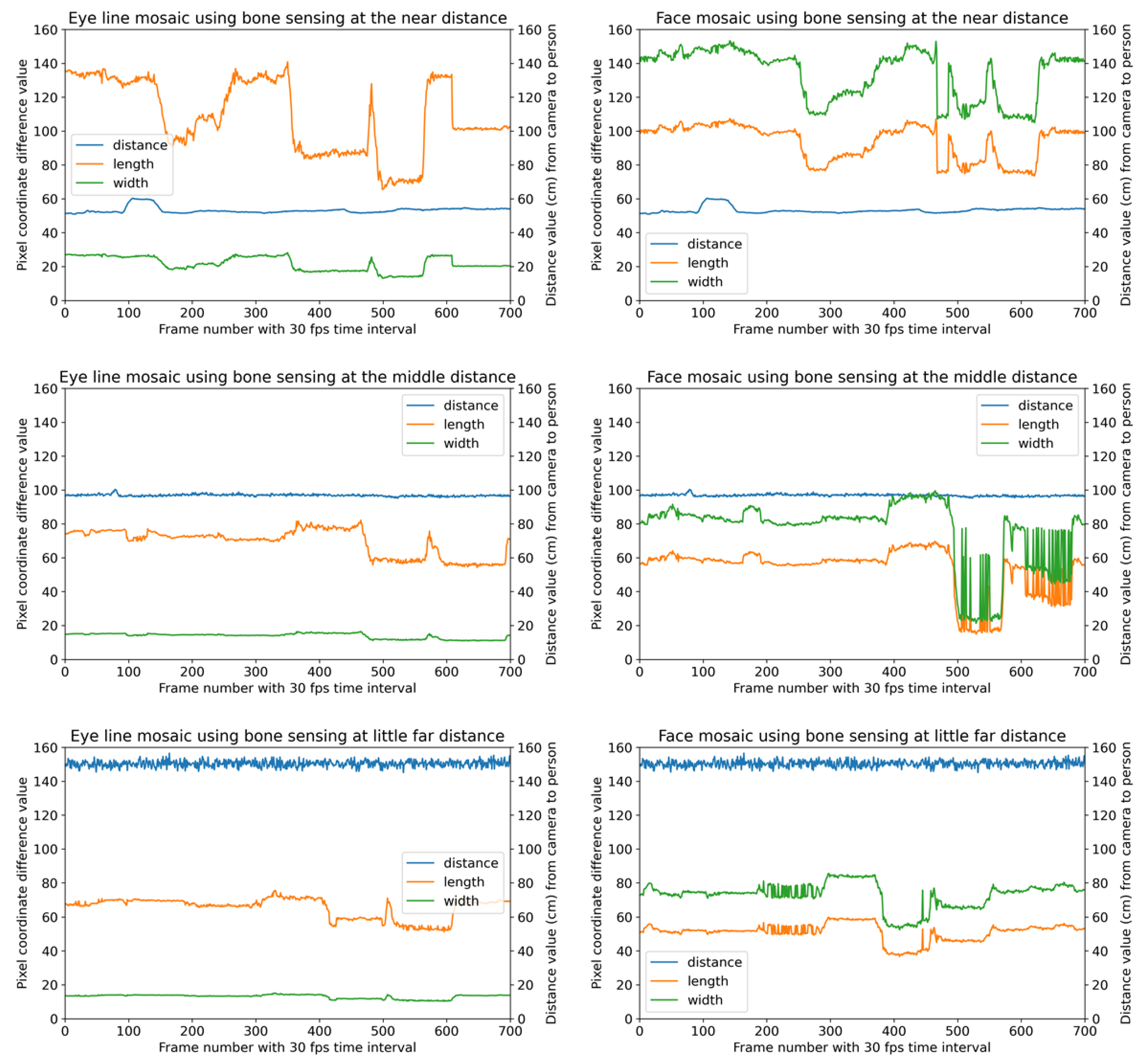
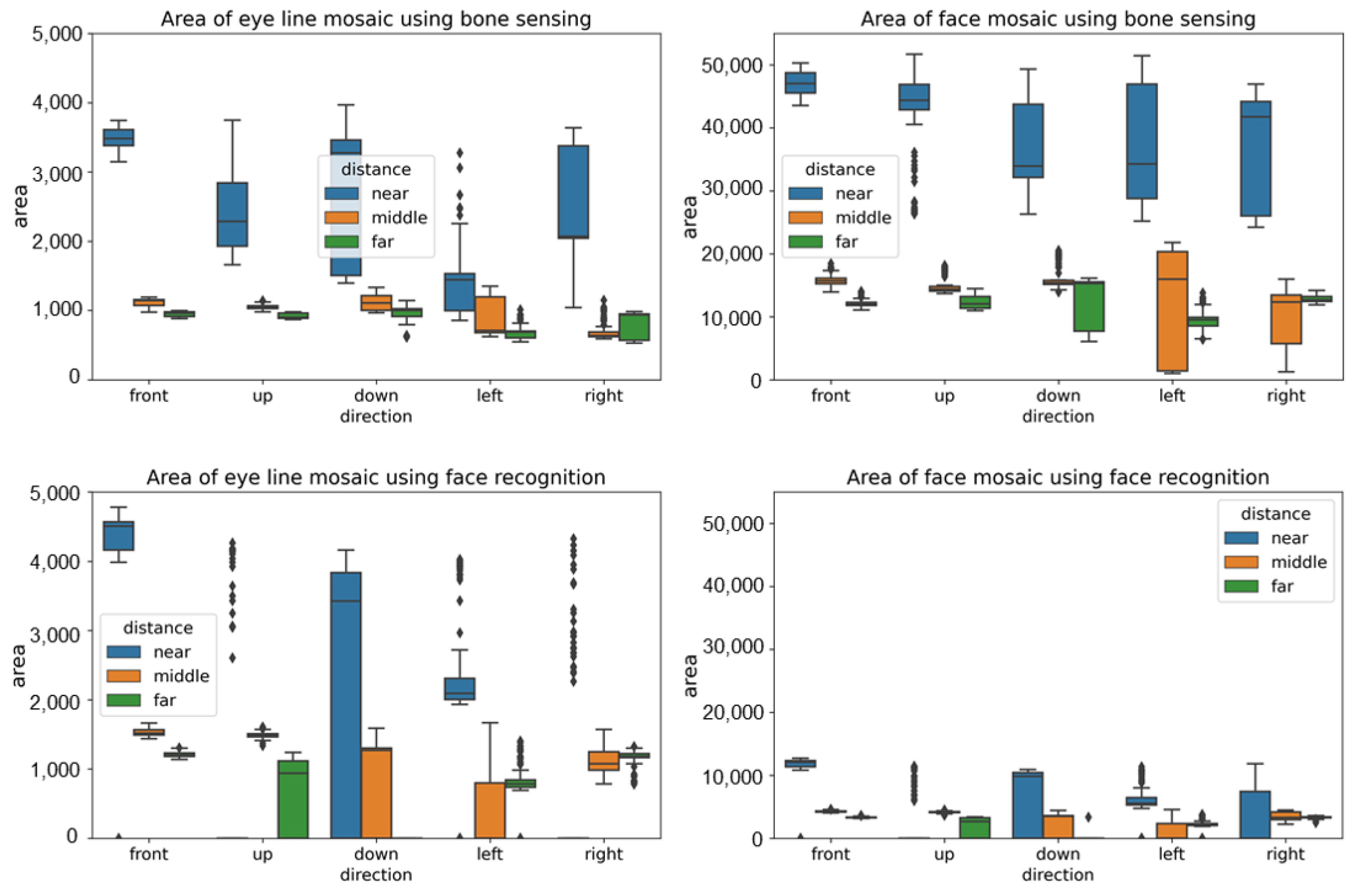
4.3. Results Using Image-Based Bone Sensing
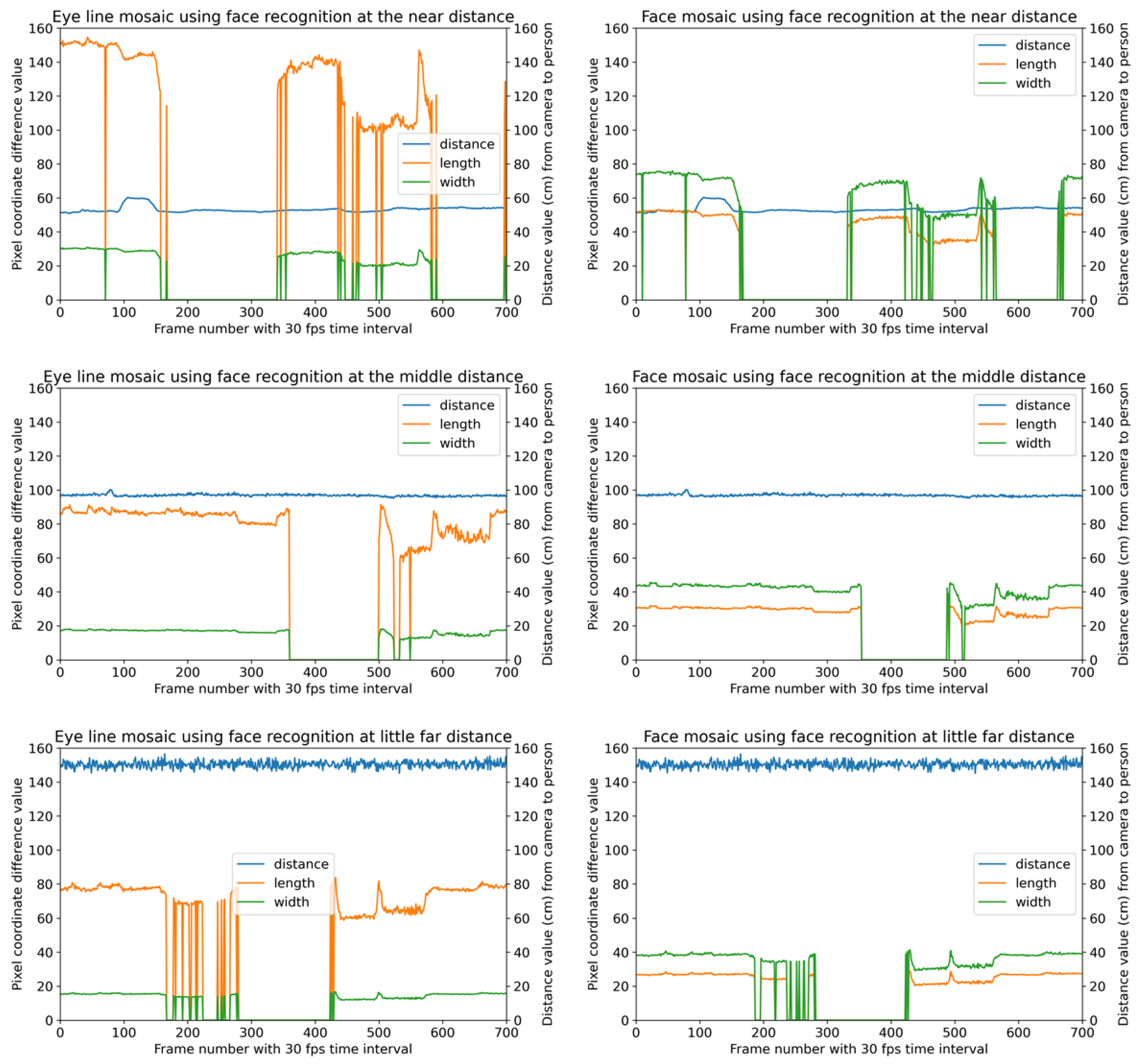
4.4. Results Using Image-Based Face Recognition
4.5. Experimental Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Ashokka, B.; Ong, S.Y.; Tay, K.H.; Loh, N.H.W.; Gee, C.F.; Samarasekera, D.D. Coordinated responses of academic medical centres to pandemics: Sustaining medical education during COVID-19. Med. Teach. 2020, 42, 762–771. [Google Scholar] [CrossRef] [PubMed]
- Serhan, D. Transitioning from Face-to-Face to Remote Learning: Students’ Attitudes and Perceptions of Using Zoom during COVID-19 Pandemic. Int. J. Technol. Educ. Sci. 2020, 4, 335–342. [Google Scholar] [CrossRef]
- Chu, M.; Dalwadi, S.; Profit, R.; Searle, B.; Williams, H. How Should Medical Education Support Increasing Telemedicine Use Following COVID-19? An Asian Perspective Focused on Teleconsultation. Int. J. Digit. Health 2022, 2, 1–6. [Google Scholar] [CrossRef]
- Jacob, I.J.; Darney, P.E. Design of deep learning algorithm for IoT application by image based recognition. J. ISMAC 2021, 3, 276–290. [Google Scholar] [CrossRef]
- Hirayama, K.; Chen, S.; Saiki, S.; Nakamura, M. Toward Capturing Scientific Evidence in Elderly Care: Efficient Extraction of Changing Facial Feature Points. Sensors 2021, 21, 6726. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Yan, W.Q. Face Detection and Recognition From Distance Based on Deep Learning. In Aiding Forensic Investigation through Deep Learning and Machine Learning Frameworks; IGI Global: PA, USA, 2022; pp. 144–160. [Google Scholar] [CrossRef]
- Gouiffès, M.; Caye, V. The Vera Icona Installation and Performance: A Reflection on Face Surveillance in Contemporary Society. Leonardo 2022, 55, 439–444. [Google Scholar] [CrossRef]
- Petrangeli, S.; Pauwels, D.; Van Der Hooft, J.; Žiak, M.; Slowack, J.; Wauters, T.; De Turck, F. A scalable WebRTC-based framework for remote video collaboration applications. Multimed. Tools Appl. 2019, 78, 7419–7452. [Google Scholar] [CrossRef]
- Divya, R.; Peter, J.D. Smart healthcare system-a brain-like computing approach for analyzing the performance of detectron2 and PoseNet models for anomalous action detection in aged people with movement impairments. Complex Intell. Syst. 2022, 8, 3021–3040. [Google Scholar] [CrossRef]
- Zhang, F.; Yang, T.; Liu, L.; Liang, B.; Bai, Y.; Li, J. Image-only real-time incremental UAV image mosaic for multi-strip flight. IEEE Trans. Multimed. 2020, 23, 1410–1425. [Google Scholar] [CrossRef]
- Hasby, M.A.; Putrada, A.G.; Dawani, F. The Quality Comparison of WebRTC and SIP Audio and Video Communications with PSNR. Indones. J. Comput.-(Indo-JC) 2021, 6, 73–84. [Google Scholar]
- Murley, P.; Ma, Z.; Mason, J.; Bailey, M.; Kharraz, A. WebSocket adoption and the landscape of the real-time web. In Proceedings of the Web Conference 2021, Virtually, 19–23 April 2021; pp. 1192–1203. [Google Scholar]
- Damayanti, F.U. Research of Web Real-Time Communication-the Unified Communication Platform using Node. js Signaling Server. J. Appl. Inf. Commun. Technol. 2018, 5, 53–61. [Google Scholar]
- Jannes, K.; Lagaisse, B.; Joosen, W. The web browser as distributed application server: Towards decentralized web applications in the edge. In Proceedings of the 2nd International Workshop on Edge Systems, Analytics and Networking, Dresden, Germany, 25 March 2019; pp. 7–11. [Google Scholar]
- Zhu, B.; Fang, H.; Sui, Y.; Li, L. Deepfakes for medical video de-identification: Privacy protection and diagnostic information preservation. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–8 February 2020; pp. 414–420. [Google Scholar]
- Qiu, Y.; Niu, Z.; Song, B.; Ma, T.; Al-Dhelaan, A.; Al-Dhelaan, M. A Novel Generative Model for Face Privacy Protection in Video Surveillance with Utility Maintenance. Appl. Sci. 2022, 12, 6962. [Google Scholar] [CrossRef]
- Kim, J.; Park, N. A Face Image Virtualization Mechanism for Privacy Intrusion Prevention in Healthcare Video Surveillance Systems. Symmetry 2020, 12, 891. [Google Scholar] [CrossRef]
- Kim, D.; Park, S. A study on face masking scheme in video surveillance system. In Proceedings of the 2018 IEEE Tenth International Conference on Ubiquitous and Future Networks (ICUFN), Prague, Czech Republic, 3–6 July 2018; pp. 871–873. [Google Scholar]
- Rajput, A.S.; Raman, B.; Imran, J. Privacy-preserving human action recognition as a remote cloud service using RGB-D sensors and deep CNN. Expert Syst. Appl. 2020, 152, 113349. [Google Scholar] [CrossRef]
- Chen, S.; Saiki, S.; Nakamura, M. Nonintrusive fine-grained home care monitoring: Characterizing quality of in-home postural changes using bone-based human sensing. Sensors 2020, 20, 5894. [Google Scholar] [CrossRef]
- Chen, S.; Nakamura, M. Designing an Elderly Virtual Caregiver Using Dialogue Agents and WebRTC. In Proceedings of the 2021 4th IEEE International Conference on Signal Processing and Information Security (ICSPIS), Virtually, 24–25 November 2021; pp. 53–56. [Google Scholar]
- Mendez, K.M.; Pritchard, L.; Reinke, S.N.; Broadhurst, D.I. Toward collaborative open data science in metabolomics using Jupyter Notebooks and cloud computing. Metabolomics 2019, 15, 125. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.; Chakraborty, S.; Astya, R.; Khepra, S. Face detection and recognition using OpenCV. In Proceedings of the 2019 IEEE International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 18–19 October 2019; pp. 116–119. [Google Scholar]
- Andriyanov, N.; Khasanshin, I.; Utkin, D.; Gataullin, T.; Ignar, S.; Shumaev, V.; Soloviev, V. Intelligent system for estimation of the spatial position of apples based on YOLOv3 and real sense depth camera D415. Symmetry 2022, 14, 148. [Google Scholar] [CrossRef]
- Tadic, V.; Odry, A.; Kecskes, I.; Burkus, E.; Kiraly, Z.; Odry, P. Application of Intel realsense cameras for depth image generation in robotics. WSEAS Transac. Comput. 2019, 18, 2224–2872. [Google Scholar]
- Klym, H.; Vasylchyshyn, I. Face Detection Using an Implementation Running in a Web Browser. In Proceedings of the 2020 IEEE 21st International Conference on Computational Problems of Electrical Engineering (CPEE), Online Conference, Poland, 16–19 September 2020; pp. 1–4. [Google Scholar]
- Hao, W.; Zhili, S. Improved mosaic: Algorithms for more complex images. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 1684, p. 012094. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Authors (Year) | Masking Target | Materials and Methods | Intrusiveness | Contributions |
|---|---|---|---|---|
| Kim et al. [18] (2018) | Face | CCTV cameras, video surveillance, face identification | Exist | Found optimal masking values in case study |
| Kim et al. [17] (2020) | Face | Closed-circuit television, CCTV cameras, video surveillance | Exist | Inserted a virtual face used a blockchain as the storage area |
| Rajput et al. [19] (2020) | Face | RGB-D sensors, deep CNN, cloud service | None | Improved the security-recognition accuracy |
| Zhu et al. [15] (2020) | Face, body key points | De-identification, keypoint preservation, face-swapping | Exist | Though video processing to de-identify subjects |
| Our research in this paper (2022) | Face, eye line | General computer, bone sensing, edge computing | Exist | Validated advantages of bone sensing at multi-views |
| Item | Technologies and Libraries Used |
|---|---|
| HTTP server | express, http |
| WebSocket technology | socket.io |
| PeerJS technology | peer |
| Random ID generation | uuid |
| Basic authentication | basic-auth-connect |
| Bone sensing | PoseNet Model |
| Web browser | Chrome (101.0.1951.54) |
| Items | Contents |
|---|---|
| Target space | One seat in ES4 Nakamura lab |
| Subject information | One person (male, 20 s) |
| Video total length | 700 frame |
| Video resolution | 640 × 480 |
| Frame time interval | 30 fps |
| Shooting method | Intel RealSense Depth Camera D435 [25] |
| Number of head directions | 5 |
| Head directions | Front, up, down, left, right |
| Video length of each head direction | 140 frames |
| Number of distances from person to camera | 3 |
| Distances from person to camera | About 50 cm (near), 100 cm (middle), 150 cm (far) |
| Used technologies | Bone sensing (posenet.js), face recognition (face-api.js) |
| Number of masking face methods | 2 |
| Masking face methods | Eye line mosaic, face mosaic |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Nakamura, M.; Sekiguchi, K. Consecutive and Effective Facial Masking Using Image-Based Bone Sensing for Remote Medicine Education. Appl. Sci. 2022, 12, 10507. https://doi.org/10.3390/app122010507
Chen S, Nakamura M, Sekiguchi K. Consecutive and Effective Facial Masking Using Image-Based Bone Sensing for Remote Medicine Education. Applied Sciences. 2022; 12(20):10507. https://doi.org/10.3390/app122010507
Chicago/Turabian StyleChen, Sinan, Masahide Nakamura, and Kenji Sekiguchi. 2022. "Consecutive and Effective Facial Masking Using Image-Based Bone Sensing for Remote Medicine Education" Applied Sciences 12, no. 20: 10507. https://doi.org/10.3390/app122010507
APA StyleChen, S., Nakamura, M., & Sekiguchi, K. (2022). Consecutive and Effective Facial Masking Using Image-Based Bone Sensing for Remote Medicine Education. Applied Sciences, 12(20), 10507. https://doi.org/10.3390/app122010507