
Text-Guided Customizable Image Synthesis and Manipulation



Abstract
:1. Introduction
- We propose an effective and novel method that can perform customized image synthesis based on text and contour information and then utilize new text to modify the customized image content.
- Compared with recent T2I methods, our proposed method can basically ensure the synthesized image’s authenticity because the contour information determines the basic shape. On the other hand, since the new text is allowed to modify the content of the previously synthesized image continuously (see Figure 1b), the whole work is more practical.
- The text description and contour information are interactive and intuitive to users. Therefore, our proposed method has excellent flexibility.
2. Related Work
3. Our Proposed Method
3.1. Preliminary
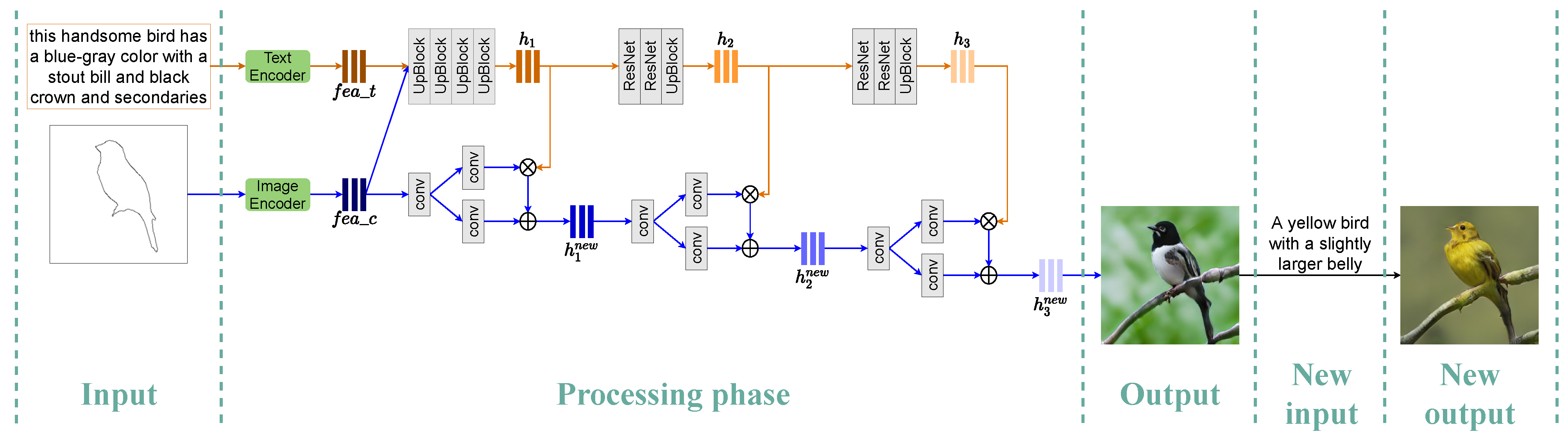
3.2. Customizable and Manipulation Architecture
3.3. Generator Implementation Details
3.4. Loss Function
3.5. Training and Testing Details
4. Experimental Results
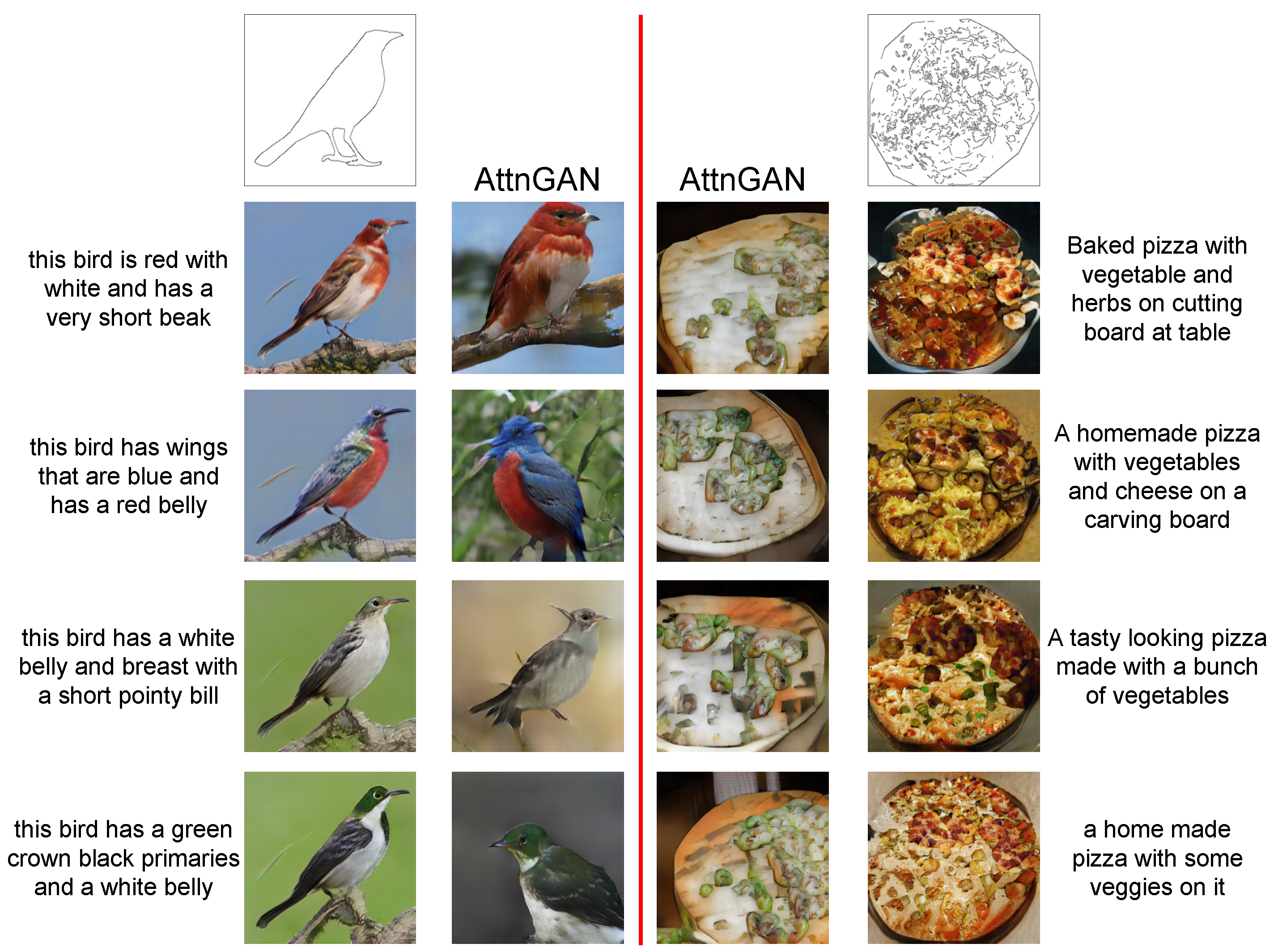
4.1. Qualitative Results
4.2. Quantitative Results
4.3. More Discussion
- (1)
- Enter new contours to modify the shape information of the generated image. For synthesized results using text and contours, our method currently can only continue to input new text to modify the content of the generated image but cannot input new contours to modify the shape information of the generated result. Therefore, to further improve the practicality of the method, we will explore the method that can use the new contour to change the shape of the image in the future.
- (2)
- Allow determining the background information of the image. Currently, our method can only control the foreground information of the synthesized image through the text and contour but cannot effectively control the background information. Controlling the background content can further improve the method’s practicality, so this is worth researching in the future.
- (3)
- Allow changing the position and orientation of the composite object. Adjustment of the position and orientation is a common operation in image editing. Therefore, based on our method, achieving the operation of adjustment of the positions and orientations of synthetic objects can greatly improve the overall practicality.
- (4)
- Modify the texture content of the specific region. The modification effect of the existing method is to modify the overall object content, and it is hard to edit the regional texture content of the specific position of the object. Therefore, in order to achieve a more friendly interactive effect, it is necessary to research the corresponding method to achieve a more effective image content manipulation effect.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representation, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Van Den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1747–1756. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1316–1324. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset. In CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Salimans, T.; Goodfellow, I.J.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Proceedings of the Advances in Neural Information Processing Systems 29, Barcelona, Spain, 5–10 December 2016; pp. 2226–2234. [Google Scholar]
- Reed, S.E.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1060–1069. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H. StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5908–5916. [Google Scholar]
- Zhao, B.; Meng, L.; Yin, W.; Sigal, L. Image Generation From Layout. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8584–8593. [Google Scholar]
- Gao, C.; Liu, Q.; Xu, Q.; Wang, L.; Liu, J.; Zou, C. SketchyCOCO: Image Generation From Freehand Scene Sketches. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5173–5182. [Google Scholar]
- Wang, S.-Y.; Bau, D.; Zhu, J.-Y. Sketch Your Own GAN. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14030–14040. [Google Scholar]
- Reed, S.E.; Akata, Z.; Mohan, S.; Tenka, S.; Schiele, B.; Lee, H. Learning What and Where to Draw. In Proceedings of the Advances in Neural Information Processing Systems 29, Barcelona, Spain, 5–10 December 2016; pp. 217–225. [Google Scholar]
- Zhang, Z.; Yu, W.; Zhou, J.; Zhang, X.; Jiang, N.; He, G.; Yang, Z. Customizable GAN: A Method for Image Synthesis of Human Controllable. IEEE Access 2020, 8, 108004–108017. [Google Scholar] [CrossRef]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Neural Photo Editing with Introspective Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Liu, M.-Y.; Breuel, T.M.; Kautz, J. Unsupervised Image-to-Image Translation Networks. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Dong, H.; Yu, S.; Wu, C.; Guo, Y. Semantic Image Synthesis via Adversarial Learning. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22-29 October 2017; pp. 5707–5715. [Google Scholar]
- Nam, S.; Kim, Y.; Kim, S.J. Text-Adaptive Generative Adversarial Networks: Manipulating Images with Natural Language. In Proceedings of the Advances in Neural Information Processing Systems 31, Montréal, QC, Canada, 3–8 December 2018; pp. 42–51. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H.S. ManiGAN: Text-Guided Image Manipulation. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7877–7886. [Google Scholar]
- Che, T.; Li, Y.; Zhang, R.; Hjelm, R.D.; Li, W.; Song, Y.; Bengio, Y. Maximum-Likelihood Augmented Discrete Generative Adversarial Networks. arXiv 2017, arXiv:1702.07983. [Google Scholar]
- Vondrick, C.; Pirsiavash, H.; Torralba, A. Generating Videos with Scene Dynamics. In Proceedings of the Advances in Neural Information Processing Systems 29, Barcelona, Spain, 5–10 December 2016; pp. 613–621. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 2020, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V.S. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H.S. Controllable Text-to-Image Generation. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019; pp. 2063–2073. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-To-Image Synthesis. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5802–5810. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1947–1962. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CUB | MS COCO | ||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| Number of images | 8855 | 2933 | 82,783 | 40,504 |
| CUB | MS COCO | ||||
|---|---|---|---|---|---|
| Method | Model | IS ↑ | FID ↓ | IS ↑ | FID ↓ |
| (a) T2I | GAN-CLS [10] | 2.88 | 68.79 | 7.88 | 60.62 |
| StackGAN [11] | 3.7 | 35.11 | 8.45 | 74.05 | |
| StackGAN++ [35] | 4.04 | 18.02 | 8.3 | 81.59 | |
| AttnGAN [5] | 4.36 | 23.98 | 25.89 | 35.49 | |
| (b) Custom | GAWWN [15] | 3.62 | 53.51 | n/a | n/a |
| Customizable- GAN [16] | 3.12 | 65.36 | n/a | n/a | |
| (c) Manipulation | SISGAN [19] | 2.24 | n/a | n/a | n/a |
| TAGAN [20] | 3.32 | n/a | n/a | n/a | |
| ManiGAN [21] | 3.84 | 17.89 | 6.99 | n/a | |
| Custom and (d) Manipulation (Baseline) | Custom stage | 3.98 | 23.19 | 15.03 | 46.02 |
| Manipulation stage | 4.03 | 18.63 | 16.53 | 36.74 | |
| (e) Baseline + DM | Custom stage | 4.02 | 18.72 | 15.27 | 45.04 |
| Manipulation stage | 4.07 | 16.24 | 17.34 | 30.02 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Fu, C.; Weng, W.; Zhou, J. Text-Guided Customizable Image Synthesis and Manipulation. Appl. Sci. 2022, 12, 10645. https://doi.org/10.3390/app122010645
Zhang Z, Fu C, Weng W, Zhou J. Text-Guided Customizable Image Synthesis and Manipulation. Applied Sciences. 2022; 12(20):10645. https://doi.org/10.3390/app122010645
Chicago/Turabian StyleZhang, Zhiqiang, Chen Fu, Wei Weng, and Jinjia Zhou. 2022. "Text-Guided Customizable Image Synthesis and Manipulation" Applied Sciences 12, no. 20: 10645. https://doi.org/10.3390/app122010645
APA StyleZhang, Z., Fu, C., Weng, W., & Zhou, J. (2022). Text-Guided Customizable Image Synthesis and Manipulation. Applied Sciences, 12(20), 10645. https://doi.org/10.3390/app122010645