
A Hybrid Method of Enhancing Accuracy of Facial Recognition System Using Gabor Filter and Stacked Sparse Autoencoders Deep Neural Network


 ,
,  and
and 
Abstract
:1. Introduction
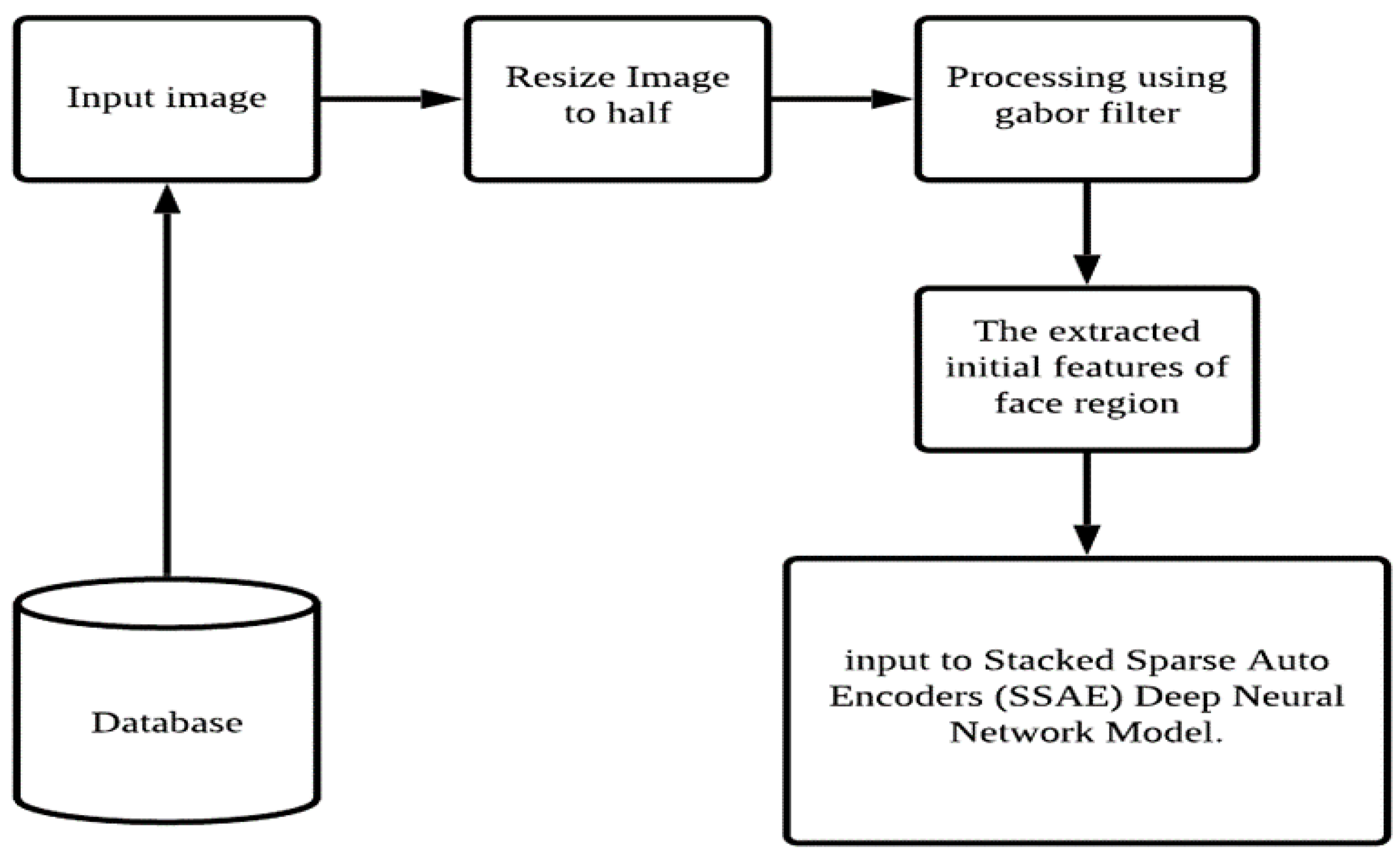
2. Materials and Methods
2.1. Materials
- The first database is the OLR, which contains a collection of face images photographed between April 1992 and April 1994 at the Olivetti Research Laboratory in Cambridge, UK. This database can be accessed via https://cam-orl.co.uk/facedatabase.html (accessed on 10 June 2021). Accordingly, each of the 40 distinct human subjects has ten different facial photographs. The photos were taken at different times and with various facial details (no glasses/glasses) and facial appearance (non-smiling/smiling, closed eyes/open eyes). All photographs were taken against a dark homogeneous backdrop, with subjects standing frontally, upright, tolerating any rotation, and tilting up to about 20 degrees. There are some variations in the scale range, of up to 10%. Figure 1 depicts some face image samples from the OLR database. These images are grayscale image-type and have a resolution of 92 × 112 pixels. In order to reduce computation time, we resized the selected face images in the OLR database by half of their original sizes in this work.
- However, the second database used in this study is the Extended Yale-B database. This database contains 2432 frontal face images, each with a dimension of 192 × 168 pixels for all the 38 human subjects. This database can be accessed at http://vision.ucsd.edu/leekc/ExtYaleDatabase/ExtYaleB.html (accessed on 10 June 2021). Furthermore, each subject has 64 photographs with varying levels of illumination. The photographs were taken under various lighting intensities and facial expressions. The intensity of lighting on these faces varies greatly across subjects, to the point where only a small portion of the face is visible in some cases. We close-cropped these face datasets with each photograph cropped to include only a look without hair or background. In addition, we resized the face images to half of their original sizes in order to reduce the computation time of the proposed model. Figure 2 shows face image samples from the Extended Yale-B database.
2.2. Methods
2.3. Gabor Filters-Based Feature Extraction Method
| Algorithm 1: An algorithm for the Gabor filter for feature extraction |
| Input: images after resizing Output: feature regions and features in the image (length, width, orientations, frequency, bandwidth) Initialization: f-sinusoid frequency, spatial aspect ratio γ, gaussian envelope σ and offset phase ϕ, Gabor function normal orientations θ 1: Read half-resized images with input values (f, π, γ, σ, and ϕ) 2: Estimate Gaussian function using: 3: Compute the Gaussian function values by using Equations (1) and (2): 4: Compute the image features according to the orientation and width values by using Equations (6) and (7). |
2.4. Deep Neural Network and Autoencoders Model
2.4.1. The Basic Sparse Autoencoder (SAE) Network
2.4.2. Stacked Sparse Autoencoder (SSAE) Network
2.5. Training of the Proposed SSAE Deep Neural Network
| Algorithm 2: An algorithm for training stacked sparse autoencoder (SSAE) model with soft-max classifier |
| Input: Extracted features by Algorithm 1 Output: Authenticated image or not Initialization: bias , weight W, input x. 1: Training of facial image features // Training initial face image features using number of the pixels in each initial face feature 2: Compute hidden layer output: // where is a vector of a bias, and W is a matrix of weight 3: Calculate the next hidden layer output that will be used to predict the output value using Equation (8) as follows: // where h is the input hidden layer // enter feature of the initial face and its exemplification at hidden layer l 4: Estimate the new feature-related output value f using: // which convert pixels of input raw of initial face image feature to // new feature exemplification specified 5: Estimate the soft-max optimization to predict the final output value using Equations (9)–(11). // all three layers are merged jointly to shape SSAE with two hidden layers // and an ultimate layer of soft-max classifier capable of classifying the face //attributes of both the OLR and the Expanded Yale-B Face databases 6: Input unrecognized: // returning to Algorithm 1 if more face photos are required for training. |
3. Experimental Results and Discussion
4. Discussion
Performance Comparison of the Proposed Hybrid Method with the Existing Face Recognition Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sanchez-Moreno, A.S.; Olivares-Mercado, J.; Hernandez-Suarez, A.; Toscano-Medina, K.; Sanchez-Perez, G.; Benitez-Garcia, G. Efficient Face Recognition System for Operating in Unconstrained Environments. J. Imaging 2021, 7, 161. [Google Scholar] [CrossRef] [PubMed]
- Meshgini, S.; Aghagolzadeh, A.; Seyedarabi, H. Face recognition using Gabor-based direct linear discriminant analysis and support vector machine. Comput. Electr. Eng. 2013, 39, 727–745. [Google Scholar] [CrossRef]
- Lu, D.; Yan, L. Face Detection and Recognition Algorithm in Digital Image Based on Computer Vision Sensor. J. Sens. 2021, 2021, 4796768. [Google Scholar] [CrossRef]
- Reddy, A.H.; Kolli, K.; Kiran, Y.L. Deep cross feature adaptive network for facial emotion classification. Signal Image Video Process. 2021, 16, 369–376. [Google Scholar] [CrossRef]
- Aldhahab, A.; Ibrahim, S.; Mikhael, W.B. Stacked Sparse Autoencoder and Softmax Classifier Framework to Classify MRI of Brain Tumor Images. Int. J. Intell. Eng. Syst. 2020, 13, 268–279. [Google Scholar] [CrossRef]
- Görgel, P.; Simsek, A. Face recognition via Deep Stacked Denoising Sparse Autoencoders (DSDSA). Appl. Math. Comput. 2019, 355, 325–342. [Google Scholar] [CrossRef]
- Zafaruddin, G.; Fadewar, H.S. Face Recognition Using Eigenfaces. In Computing, Communication and Signal Processing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 855–864. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. Available online: http://code.google.com/p/cuda-convnet/ (accessed on 21 April 2020).
- Usman, O.L.; Muniyandi, R.C. CryptoDL: Predicting Dyslexia Biomarkers from Encrypted Neuroimaging Dataset Using Energy-Efficient Residue Number System and Deep Convolutional Neural Network. Symmetry 2020, 12, 836. [Google Scholar] [CrossRef]
- Usman, O.L.; Muniyandi, R.C.; Omar, K.; Mohamad, M. Advance Machine Learning Methods for Dyslexia Biomarker Detection: A Review of Implementation Details and Challenges. IEEE Access 2021, 9, 36879–36897. [Google Scholar] [CrossRef]
- Usman, O.L.; Muniyandi, R.C.; Omar, K.; Mohamad, M. Gaussian smoothing and modified histogram normalization methods to improve neural-biomarker interpretations for dyslexia classification mechanism. PLoS ONE 2021, 16, e0245579. [Google Scholar] [CrossRef]
- Shen, L.L.; Bai, L.; Fairhurst, M. Gabor wavelets and General Discriminant Analysis for face identification and verification. Image Vis. Comput. 2007, 25, 553–563. [Google Scholar] [CrossRef]
- Shen, L.; Bai, L. A review on Gabor wavelets for face recognition. Pattern Anal. Appl. 2006, 9, 273–292. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Zhang, H.-J. Orthogonal Laplacian faces for 3D face recognition. IEEE Trans. Image Process. 2006, 15, 3608–3614. [Google Scholar] [CrossRef] [Green Version]
- Daugman, J.G. Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters. J. Opt. Soc. Am. A 1985, 2, 1160–1169. [Google Scholar] [CrossRef] [PubMed]
- Hamamoto, Y.; Uchimura, S.; Watanabe, M.; Yasuda, T.; Mitani, Y.; Tomita, S. A gabor filter-based method for recognizing handwritten numerals. Pattern Recognit. 1998, 31, 395–400. [Google Scholar] [CrossRef]
- Wang, X.; Ding, X.; Liu, C. Gabor filters-based feature extraction for character recognition. Pattern Recognit. 2005, 38, 369–379. [Google Scholar] [CrossRef]
- Kamarainen, J.-K.; Kyrki, V.; Kalviainen, H. Invariance properties of Gabor filter-based features-overview and applications. IEEE Trans. Image Process. 2006, 15, 1088–1099. [Google Scholar] [CrossRef]
- Liu, C.; Wechsler, H. Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition. IEEE Trans. Image Process. 2002, 11, 467–476. [Google Scholar] [CrossRef] [Green Version]
- Jean Effil, N.; Rajeswari, R. Wavelet scattering transform and long short-term memory network-based noninvasive blood pressure estimation from photoplethysmograph signals. Signal Image Video Process. 2021, 16, 1–9. [Google Scholar] [CrossRef]
- Rahman, M.A.; Muniyandi, R.C.; Albashish, D.; Rahman, M.M.; Usman, O.L. Artificial neural network with Taguchi method for robust classification model to improve classification accuracy of breast cancer. PeerJ Comput. Sci. 2021, 7, e344. [Google Scholar] [CrossRef]
- Rahman, M.M.; Usman, O.L.; Muniyandi, R.C.; Sahran, S.; Mohamed, S.; Razak, R.A. A Review of Machine Learning Meth-ods of Feature Selection and Classification for Autism Spectrum Disorder. Brain Sci. 2020, 10, 949. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Gideon, S. Estimating the Dimension of a Model Source. Ann. Stat. 2008, 6, 461–464. [Google Scholar]
- Fuad, T.H.; Fime, A.A.; Sikder, D.; Iftee, A.R.; Rabbi, J.; Al-Rakhami, M.S.; Gumaei, A.; Sen, O.; Fuad, M.; Islam, N. Recent Advances in Deep Learning Techniques for Face Recognition. IEEE Access 2021, 9, 99112–99142. [Google Scholar] [CrossRef]
- Ng, A. Sparse autoencoder. In CS294A Lecture Notes; Stanford University: Stanford, CA, USA, 2011; pp. 1–19. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [Green Version]
- Maroosi, A.; Muniyandi, R.C.; Sundararajan, E.; Zin, A.M. Parallel and distributed computing models on a graphics processing unit to accelerate simulation of membrane systems. Simul. Model. Pract. Theory 2014, 47, 60–78. [Google Scholar] [CrossRef]
- Rahman, M.A.; Muniyandi, R.C. Review of GPU implementation to process of RNA sequence on cancer. Inform. Med. Unlocked 2018, 10, 17–26. [Google Scholar] [CrossRef]
- Kamencay, P.; Benčo, M.; Miždoš, T.; Radil, R. A new method for face recognition using convolutional neural network. Digit. Image Process. Comput. Graph. 2017, 16, 663–672. [Google Scholar] [CrossRef]
- Tan, X.; Chen, S.; Zhou, Z.-H.; Li, J. Learning Non-Metric Partial Similarity Based on Maximal Margin Criterion. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 138–145. [Google Scholar] [CrossRef] [Green Version]
- Rejeesh, M. Interest point based face recognition using adaptive neuro fuzzy inference system. Multimed. Tools Appl. 2019, 78, 22691–22710. [Google Scholar] [CrossRef]
- Fernandes, S.; Bala, J. Performance Analysis of PCA-based and LDA-based Algorithms for Face Recognition. Int. J. Signal Process. Syst. 2013, 1, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Kumar, R.; Banerjee, A.; Vemuri, B.C.; Pfister, H. Trainable Convolution Filters and Their Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1423–1436. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | RGB Color/Grayscale | Images Size | No. of Persons | No. of Images per Person | Variation | Description |
|---|---|---|---|---|---|---|
| OLR | Grayscale | 92 × 112 pixel | 40 | 10 | i, t |
|
| Extended Yale-B database | Grayscale | 168 × 192 pixel | 38 | 64 | p, i |
|
| Hyperparameters | Proposed SSAE Model for OLR | Proposed SSAE Model for Extended Yale-B Database |
|---|---|---|
| Training samples | 320 | 2356 |
| HL1 Size | 1200 | 1200 |
| HL2 Size | 800 | 800 |
| 1st Autoencoder: | ||
| Function for activation | Log-Sigmoid | Log-Sigmoid |
| Parameters of sparsity | 0.15 | 0.15 |
| Weight sparsity | 4 | 4 |
| Decay value of weight | 0.004 | 0.004 |
| Iterations (max) | 400 | 400 |
| 2nd Autoencoder: | ||
| Function for activation | Log-Sigmoid | Log-Sigmoid |
| Parameters of sparsity | 4 | 4 |
| Weight sparsity | 0.1 | 0.1 |
| Decay value of weight | 0.002 | 0.002 |
| Iterations (max) | 200 | 200 |
| Final soft-max: | ||
| Function for activation | Soft-max | Soft-max |
| Iteration (max) | 200 | 200 |
| Pre-training learning rate | 0.000001 | 0.000001 |
| The finer tuning learning rate | 0.000001 | 0.000001 |
| Fine-tune iteration (max) | 100 | 100 |
| SN of Images | Name of Images in the Database | Execution Time of the Hybrid Method | Execution Time of Conventional SSAE |
|---|---|---|---|
| 1 | 01_OLR01 | 0.2973252 | 1.6227453 |
| 2 | 02_OLR02 | 0.2422379 | 0.4341096 |
| 3 | 03_OLR01 | 0.2412173 | 0.3973739 |
| 4 | 04_OLR02 | 0.2551962 | 0.2599288 |
| 5 | 05_OLR01 | 0.2518286 | 0.5701508 |
| 6 | 06_OLR02 | 0.2445681 | 0.2350624 |
| 7 | 08_OLR02 | 0.2546507 | 0.2208476 |
| 8 | 10_OLR01 | 0.2550419 | 0.2275963 |
| 9 | 12_OLR01 | 0.2448359 | 0.2136016 |
| 10 | 13_OLR02 | 0.2457450 | 0.2273580 |
| 11 | 15_OLR01 | 0.2505601 | 0.2269222 |
| 12 | 16_OLR02 | 0.2495898 | 0.2143724 |
| 13 | 17_OLR01 | 0.2435430 | 0.2196226 |
| 14 | 18_OLR02 | 0.2411174 | 0.2242768 |
| 15 | 19_OLR01 | 0.2409688 | 0.2173489 |
| 16 | 21_OLR02 | 0.2445355 | 0.2295809 |
| 17 | 23_OLR01 | 0.2492679 | 0.2278315 |
| 18 | 24_OLR02 | 0.2642704 | 0.2073777 |
| 19 | 25_OLR01 | 0.2477056 | 0.2160182 |
| 20 | 29_OLR01 | 0.2517592 | 0.2011851 |
| 21 | 31_OLR01 | 0.2459486 | 0.2240650 |
| 22 | 31_OLR02 | 0.2419242 | 0.2084263 |
| 23 | 32_OLR02 | 0.2494917 | 0.2226422 |
| 24 | 33_OLR01 | 0.2417259 | 0.2219115 |
| 25 | 34_OLR02 | 0.2469378 | 0.2150088 |
| 26 | 35_OLR01 | 0.2532889 | 0.2265672 |
| 27 | 36_OLR01 | 0.2419414 | 0.2074002 |
| 28 | 38_OLR01 | 0.2472856 | 0.2138572 |
| 29 | 39_OLR01 | 0.2515196 | 0.2170947 |
| 30 | 40_OLR01 | 0.2482124 | 0.2141638 |
| Average execution time | 0.2494747 | 0.2921483 |
| SN of Images | Image ID in Database | Execution Time of Hybrid Method | Execution Time of Conventional SSAE |
|---|---|---|---|
| 1 | 01_YB_01 | 1.0825900 | 0.5950821 |
| 2 | 02_YB_01 | 0.6231380 | 0.5850558 |
| 3 | 03_YB_02 | 0.6030670 | 0.5713341 |
| 4 | 04_YB_02 | 0.5553510 | 0.5623317 |
| 5 | 05_YB_02 | 0.7251700 | 0.5687663 |
| 6 | 06_YB_01 | 0.5211130 | 0.5678378 |
| 7 | 07_YB_01 | 0.5070610 | 0.5625726 |
| 8 | 08_YB_02 | 0.4905720 | 0.5635912 |
| 9 | 10_YB_01 | 0.5109780 | 0.5907825 |
| 10 | 10_YB_02 | 0.5028580 | 0.5717226 |
| 11 | 14_YB_01 | 0.4994620 | 0.5665855 |
| 12 | 15_YB_02 | 0.4910670 | 0.5693121 |
| 13 | 16_YB_01 | 0.5557580 | 0.5772575 |
| 14 | 18_YB_01 | 0.4915970 | 0.5866595 |
| 15 | 19_YB_01 | 0.4930950 | 0.5742290 |
| 16 | 20_YB_02 | 0.4936690 | 0.5866195 |
| 17 | 22_YB_02 | 0.5115960 | 0.5715895 |
| 18 | 23_YB_01 | 0.5485060 | 0.5794412 |
| 19 | 24_YB_02 | 0.5161060 | 0.5671572 |
| 20 | 25_YB_02 | 0.4984720 | 0.5666622 |
| 21 | 27_YB_02 | 0.5013040 | 0.5764131 |
| 22 | 28_YB_02 | 0.4901850 | 0.5709971 |
| 23 | 30_YB_02 | 0.4971250 | 0.5775362 |
| 24 | 31_YB_02 | 0.4892620 | 0.6135733 |
| 25 | 33_YB_02 | 0.5119080 | 0.5658698 |
| 26 | 35_YB_01 | 0.6732850 | 0.5691650 |
| 27 | 35_YB_02 | 0.6152030 | 0.5742719 |
| 28 | 36_YB_02 | 0.4926430 | 0.5595510 |
| 29 | 37_YB_01 | 0.5000210 | 0.5697548 |
| 30 | 38_YB_02 | 0.4935000 | 0.5753255 |
| Average execution time | 0.5495220 | 0.5745683 |
| Metrics | Proposed Hybrid Method | Conventional SSAE |
|---|---|---|
| Samples | 80 | 80 |
| Error Rate (MSE) | 0.0000 | 0.0009 |
| Perfectly recognized images | 80 | 79 |
| Recognition rate (%) | 100% | 98.75 |
| Metrics | Proposed Hybrid Method | Conventional SSAE |
|---|---|---|
| Samples | 76 | 76 |
| Error Rate (MSE) | 0.0000 | 0.0055 |
| Perfectly recognized images | 76 | 71 |
| Recognition rate (%) | 100% | 93.4211 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaber, A.G.; Muniyandi, R.C.; Usman, O.L.; Singh, H.K.R. A Hybrid Method of Enhancing Accuracy of Facial Recognition System Using Gabor Filter and Stacked Sparse Autoencoders Deep Neural Network. Appl. Sci. 2022, 12, 11052. https://doi.org/10.3390/app122111052
Jaber AG, Muniyandi RC, Usman OL, Singh HKR. A Hybrid Method of Enhancing Accuracy of Facial Recognition System Using Gabor Filter and Stacked Sparse Autoencoders Deep Neural Network. Applied Sciences. 2022; 12(21):11052. https://doi.org/10.3390/app122111052
Chicago/Turabian StyleJaber, Abdullah Ghanim, Ravie Chandren Muniyandi, Opeyemi Lateef Usman, and Harprith Kaur Rajinder Singh. 2022. "A Hybrid Method of Enhancing Accuracy of Facial Recognition System Using Gabor Filter and Stacked Sparse Autoencoders Deep Neural Network" Applied Sciences 12, no. 21: 11052. https://doi.org/10.3390/app122111052
APA StyleJaber, A. G., Muniyandi, R. C., Usman, O. L., & Singh, H. K. R. (2022). A Hybrid Method of Enhancing Accuracy of Facial Recognition System Using Gabor Filter and Stacked Sparse Autoencoders Deep Neural Network. Applied Sciences, 12(21), 11052. https://doi.org/10.3390/app122111052