

3D Model Retrieval Algorithm Based on DSP-SIFT Descriptor and Codebook Combination
Abstract
:1. Introduction
- Applying the Bag-of-Words model to the 3D model retrieval. The existing image processing technology can be used, and good retrieval results have been obtained.
- Extracting DSP-SIFT features and improving the Bag-of-Words model in the feature extraction stage.
- Improving the Bag-of-Words model through codebook combination, which corrects quantization artifacts of local features. Additionally, the Bayes merging algorithm is used to address the codebook correlation and improve the accuracy of the algorithm.
2. Bag-of-Words
3. Proposed Method
3.1. Feature Extraction
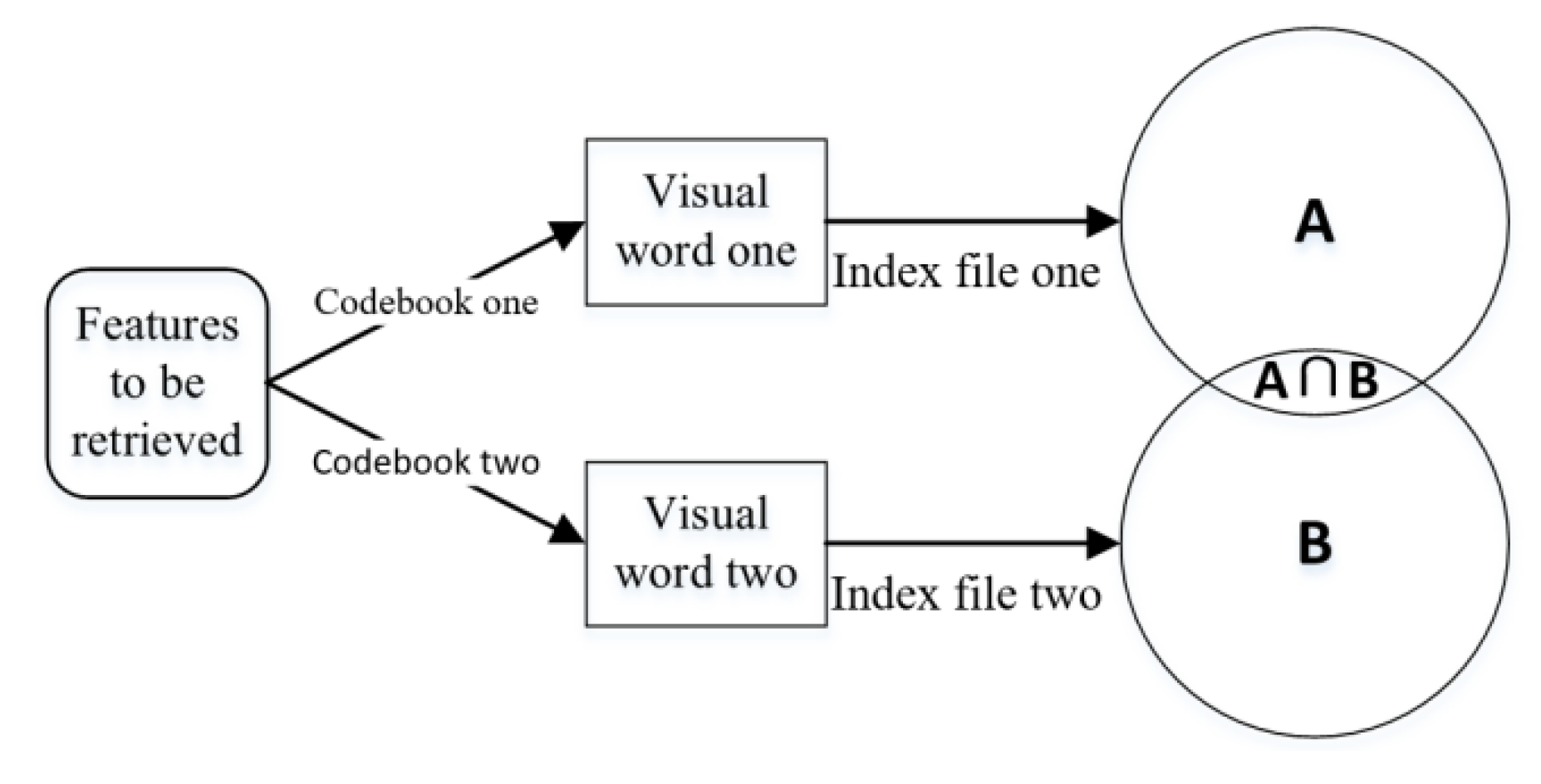
3.2. Codebook Combination
4. Experiments
4.1. ETH-80 Datasets
4.2. Evaluation Metrics
- 1.
- P-R curve: P-R curve evaluation metrics are widely used in information retrieval systems. The precision rate refers to the proportion of relevant results in the search results. Recall refers to the proportion of relevant search results in the entire datasets among the search results. Let represent all relevant results in the datasets and represent all search results, then:
- 2.
- F-measure (): is the weighted harmonic average of precision and recall, and is a commonly used retrieval metrics in information retrieval systems. can be defined as (taking the first 20 search results in the experiment):
- 3.
- : The evaluation methods of these three evaluation standards are similar. Searching the first test results, the proportion of the same category as the retrieved object is tested. Suppose there are objects in the category where the search object is located, and if , it is . represents . represents . The final result of the three evaluation metrics is the average of the retrieval results of all objects in the datasets.
- 4.
- : describes the location information of the relevant result in the search result. The higher the relevant result in the search ranking, the greater its weight. The value is between 0 and 1. The larger the value, the better the search result. The definition of is as follows:
- 5.
- The final result is defined as:
4.3. Qualitative Results
4.3.1. Codebook Size
4.3.2. The Effectiveness of Our Method
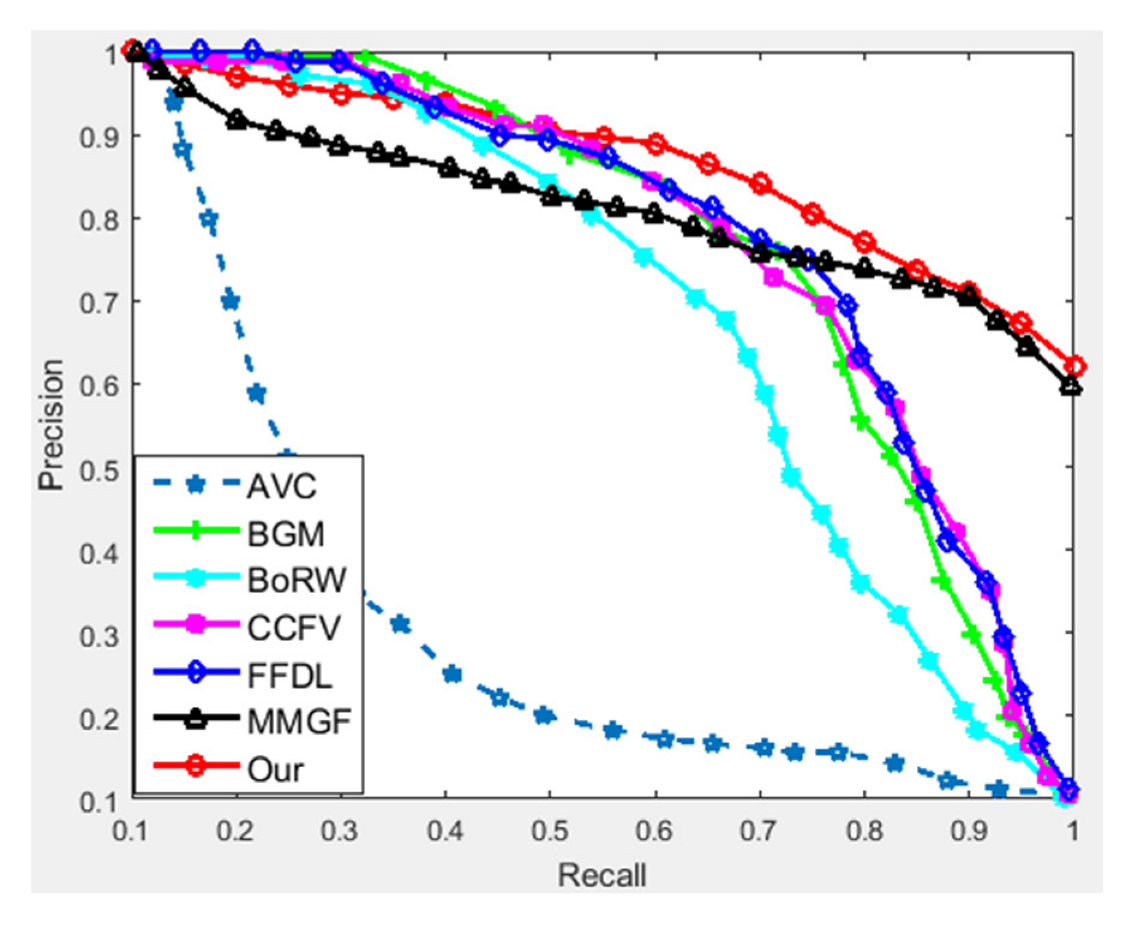
4.3.3. Comparison with Existing Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Zheng, Y.; Cao, J.; Cai, Q. Multi-view-based siamese convolutional neural network for 3D object retrieval. Comput. Electr. Eng. 2019, 78, 11–21. [Google Scholar] [CrossRef]
- Yang, H.; Tian, Y.; Yang, C.; Wang, Z.; Wang, L.; Li, H. Sequential learning for sketch-based 3D model retrieval. Multimed. Syst. 2022, 28, 761–778. [Google Scholar] [CrossRef]
- Zheng, Y.; Zeng, G.; Li, H.; Cai, Q.; Du, J. Colorful 3D reconstruction at high resolution using multi-view representation. J. Vis. Commun. Image Represent. 2022, 85, 103486. [Google Scholar] [CrossRef]
- Li, R.; Li, X.; Hui, K.H.; Fu, C.W. SP-GAN: Sphere-guided 3D shape generation and manipulation. ACM Trans. Graph. (TOG) 2021, 40, 151. [Google Scholar] [CrossRef]
- Li, H.; Wei, Y.; Huang, Y.; Cai, Q.; Du, J. Visual analytics of cellular signaling data. Multimed. Tools Appl. 2019, 78, 29447–29461. [Google Scholar] [CrossRef]
- Zeng, G.; Li, H.; Wang, X.; Li, N. Point cloud up-sampling network with multi-level spatial local feature aggregation. Comput. Electr. Eng. 2021, 94, 107337. [Google Scholar] [CrossRef]
- Zou, K.; Zhang, Q. Research progresses and trends of content based 3d model retrieval. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 3346–3351. [Google Scholar]
- Chen, Z.Y.; Tsai, C.F.; Lin, W.C. Cube of Space Sampling for 3D Model Retrieval. Appl. Sci. 2021, 11, 11142. [Google Scholar] [CrossRef]
- Dubey, D.; Tomar, G.S. BPSO based neural network approach for content-based face retrieval. Multimed. Tools Appl. 2022, 81, 41271–41293. [Google Scholar] [CrossRef]
- Peng, J.Z.; Aubry, N.; Zhu, S.; Chen, Z.; Wu, W.T. Geometry and boundary condition adaptive data-driven model of fluid flow based on deep convolutional neural networks. Phys. Fluids 2021, 33, 123602. [Google Scholar] [CrossRef]
- Li, H.; Liu, X.; Lai, L.; Cai, Q.; Du, J. An area weighted surface sampling method for 3D model retrieval. Chin. J. Electron. 2014, 23, 484–488. [Google Scholar]
- Teng, D.; Xie, X.; Sun, J. Video Traffic Volume Extraction Based on Onelevel Feature. In Proceedings of the 2022 IEEE 6th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 4–6 March 2022; Volume 6, pp. 1760–1764. [Google Scholar]
- Chen, H.; Zhang, W.; Yan, D. Learning Geometry Information of Target for Visual Object Tracking with Siamese Networks. Sensors 2021, 21, 7790. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Sun, L.; Dong, S.; Zhu, X.; Cai, Q.; Du, J. Efficient 3d object retrieval based on compact views and hamming embedding. IEEE Access 2018, 6, 31854–31861. [Google Scholar] [CrossRef]
- Qi, S.; Ning, X.; Yang, G.; Zhang, L.; Long, P.; Cai, W.; Li, W. Review of multi-view 3D object recognition methods based on deep learning. Displays 2021, 69, 102053. [Google Scholar] [CrossRef]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3D object detection from multi-view images via 3D-to-2D queries. In Proceedings of the Conference on Robot Learning, London, UK, 8 November 2021; pp. 180–191. [Google Scholar]
- Li, H.; Zhao, T.; Li, N.; Cai, Q.; Du, J. Feature matching of multi-view 3d models based on hash binary encoding. Neural Netw. World 2017, 27, 95. [Google Scholar] [CrossRef]
- Li, Y.; Wang, F.; Hu, X. Deep-Learning-Based 3D Reconstruction: A Review and Applications. Appl. Bionics Biomech. 2022, 2022, 3458717. [Google Scholar] [CrossRef]
- Joshi, K.; Patel, M.I. Recent advances in local feature detector and descriptor: A literature survey. Int. J. Multimed. Inf. Retr. 2020, 9, 231–247. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Generative and discriminative voxel modeling with convolutional neural networks. arXiv 2016, arXiv:1608.04236. [Google Scholar]
- Girdhar, R.; Fouhey, D.F.; Rodriguez, M.; Gupta, A. Learning a predictable and generative vector representation for objects. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 484–499. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. Adv. Neural Inf. Process. Syst. 2016, 29, 82–90. [Google Scholar]
- Li, Y.; Pirk, S.; Su, H.; Qi, C.R.; Guibas, L.J. Fpnn: Field probing neural networks for 3d data. Adv. Neural Inf. Process. Syst. 2016, 29, 307–315. [Google Scholar]
- Li, X.; Dong, Y.; Peers, P.; Tong, X. Modeling surface appearance from a single photograph using self-augmented convolutional neural networks. ACM Trans. Graph. (ToG) 2017, 36, 45. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Chen, B.M.; Lee, G.H. So-net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9397–9406. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 206–215. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Klokov, R.; Lempitsky, V. Escape from cells: Deep kd-networks for the recognition of 3d point cloud models. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 863–872. [Google Scholar]
- Zhou, H.Y.; Liu, A.A.; Nie, W.Z.; Nie, J. Multi-view saliency guided deep neural network for 3-D object retrieval and classification. IEEE Trans. Multimed. 2019, 22, 1496–1506. [Google Scholar] [CrossRef]
- Feng, Y.; Xiao, J.; Zhuang, Y.; Yang, X.; Zhang, J.J.; Song, R. Exploiting temporal stability and low-rank structure for motion capture data refinement. Inf. Sci. 2014, 277, 777–793. [Google Scholar] [CrossRef] [Green Version]
- Zheng, L.; Wang, S.; Zhou, W.; Tian, Q. Bayes merging of multiple vocabularies for scalable image retrieval. In Proceedings of the 2014 Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1963–1970. [Google Scholar]
- Furuya, T.; Ohbuchi, R. Dense sampling and fast encoding for 3D model retrieval using bag-of-visual features. In Proceedings of the ACM International Conference on Image and Video Retrieval, Thera, Greece, 8–10 July 2009; pp. 1–8. [Google Scholar]
- Ohbuchi, R.; Osada, K.; Furuya, T.; Banno, T. Salient local visual features for shape-based 3D model retrieval. In Proceedings of the Shape Modeling and Applications, 2008—SMI 2008, New York, NY, USA, 4–6 June 2008; pp. 93–102. [Google Scholar]
- Ohbuchi, R.; Furuya, T. Scale-weighted dense bag of visual features for 3D model retrieval from a partial view 3D model. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops (ICCV Workshops), Kyoto, Japan, 27 September–4 October 2009; pp. 63–70. [Google Scholar]
- Gao, Y.; Yang, Y.; Dai, Q.; Zhang, N. 3D object retrieval with bag-of-region-words. In Proceedings of the 18th International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 955–958. [Google Scholar]
- Alizadeh, F.; Sutherland, A. Charge density-based 3D model retrieval using bag-of-feature. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Girona, Spain, 11 May 2013; pp. 97–100. [Google Scholar]
- Leibe, B.; Schiele, B. Analyzing appearance and contour based methods for object categorization. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; pp. 409–415. [Google Scholar]
- Gao, Y.; Liu, A.; Nie, W.; Su, Y.; Dai, Q.; Chen, F.; Chen, Y.; Cheng, Y.; Dong, S.; Duan, X.; et al. SHREC’15 Track: 3D object retrieval with multimodal views. In Proceedings of the 2015 Eurographics Workshop on 3D Object Retrieval, Zurich, Switzerland, 2–3 May 2015; pp. 129–136. [Google Scholar]
- Ansary, T.F.; Daoudi, M.; Vandeborre, J.P. A bayesian 3-d search engine using adaptive views clustering. IEEE Trans. Multimed. 2007, 9, 78–88. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Tang, J.; Hong, R.; Yan, S.; Dai, Q.; Zhang, N.; Chua, T.S. Camera constraint-free view-based 3-D object retrieval. IEEE Trans. Image Process. 2012, 21, 2269–2281. [Google Scholar] [CrossRef] [PubMed]
- Nie, W.Z.; Liu, A.A.; Su, Y.T. 3D object retrieval based on sparse coding in weak supervision. J. Vis. Commun. Image Represent. 2015, 37, 40–45. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NN | FT | ST | F | DCG |
|---|---|---|---|---|---|
| C1 | 0.9500 | 0.7472 | 0.8917 | 0.5690 | 0.9170 |
| C2 | 0.9250 | 0.7514 | 0.8903 | 0.5638 | 0.9210 |
| SIFT+Bayes | 0.9250 | 0.6889 | 0.8694 | 0.5517 | 0.8860 |
| Ours | 0.9500 | 0.7528 | 0.8931 | 0.5698 | 0.9220 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Zhang, H.; Gao, J.; Li, N. 3D Model Retrieval Algorithm Based on DSP-SIFT Descriptor and Codebook Combination. Appl. Sci. 2022, 12, 11523. https://doi.org/10.3390/app122211523
Hu Y, Zhang H, Gao J, Li N. 3D Model Retrieval Algorithm Based on DSP-SIFT Descriptor and Codebook Combination. Applied Sciences. 2022; 12(22):11523. https://doi.org/10.3390/app122211523
Chicago/Turabian StyleHu, Yuefan, Haoxuan Zhang, Jing Gao, and Nan Li. 2022. "3D Model Retrieval Algorithm Based on DSP-SIFT Descriptor and Codebook Combination" Applied Sciences 12, no. 22: 11523. https://doi.org/10.3390/app122211523
APA StyleHu, Y., Zhang, H., Gao, J., & Li, N. (2022). 3D Model Retrieval Algorithm Based on DSP-SIFT Descriptor and Codebook Combination. Applied Sciences, 12(22), 11523. https://doi.org/10.3390/app122211523