

Enhanced Firefly-K-Means Clustering with Adaptive Mutation and Central Limit Theorem for Automatic Clustering of High-Dimensional Datasets



Abstract
:1. Introduction
2. Related Research
3. Methodology
3.1. Firefly Algorithm
- —a scaling factor that controls the random walk step sizes.
- β0—the attractiveness constant when the distance between two fireflies equals zero, that is, .
- γ—the scale-dependent parameter that controls the visibility of the fireflies.
- —gives the nonlinear attractiveness of a firefly, which varies with distance.
- —the randomization term (where refers to the use of Gaussian distribution for generating random values at each iteration).
- I0—the intensity of light when = 0.
- —the coefficient of light absorption.
- —the distance.
- is the dimension of the problem.
| Algorithm 1: Pseudocode for the improved FA | |
| Input Output 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | Begin Do i = 1:n using Equations (2) and (3); end Execute mutation () End Compute new fitness value for all fireflies Accept new solutions with the best fitness End update α reduction by a factor; End |
3.2. K-Means Algorithm
- i.
- Perform an initial partition into number of clusters based on user-specified .
- ii.
- Repeat steps 3 and 4 until cluster membership is stable.
- iii.
- Assign each data object to the closest cluster to it to generate a new partition.
- iv.
- Perform cluster center update.
| Algorithm 2: Standard K-means Pseudocode | |
| Input | :Array D //Input Dataset |
| //Specified k number of clusters | |
| Output | ://Final cluster centroids |
| 1 | Begin |
| 2 | //Parameter Initialization |
| 3 | //dataset |
| 4 | //Select initial cluster centroids randomly |
| 5 | Do |
| 6 | //Calculations of Distance |
| 7 | for do |
| 8 | for do |
| 9 | Compute data objects’ Euclidean distance to all clusters |
| 10 | end |
| 11 | //Data object Assignment to clusters |
| 12 | Assign data objects to the closest cluster |
| 13 | end |
| 14 | //Updating Cluster centroid |
| 15 | Evaluate the new cluster centroid |
| 16 | While cluster centroids’ difference of two consecutive iterations are not the same |
| End | |
3.3. The Central Limit Theorem
- i.
- Select number of samples such that .
- ii.
- Use the K-means algorithm on the selected data samples and store the cluster centroids of each sample.
- iii.
- Combine the numbered cluster centroids obtained from step 2 to produce a new population of cluster centroids of size nk.
- iv.
- Perform the data assignment step using the centroids obtained from step 3.
| Algorithm 3: Pseudocode for CLT-based K-means | |
| Input: Output: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | Array D //input Dataset //specified number of clusters ns //number of samples ss //sample size //final cluster centroids For I = 1 to //Generate random samples from dataset //select Sample Dataset randomly //Generate optimal cluster centroids for the data sample //Run K-means algorithm on the data sample Begin //Parameter Initialization //dataset //Select initial cluster centroids randomly Do //Calculations of Distance for i = 1 to ss do for do Compute data objects’ Euclidean distance to all cluster centroids end //Data object assignment to clusters Assign data objects to the closest cluster end i //Updating cluster centroids 2Evaluate the new cluster centroid While cluster centroids’ difference of two consecutive iterations are not the same //Keep the generated sample cluster centroids as a representative dataset Add the generated sample cluster centroid to the existing collation of cluster centroids End // //Generate final cluster centroids from the combined cluster centroids obtained from each data sample //Run K-means on collated cluster centroids as the new datasets Begin //Parameter Initialization //collated cluster centroids form the new dataset //Select initial cluster centroids randomly Do //Calculations of distance for do for j = 1 to k do Compute data objects’ Euclidean distance to all clusters end //Data object Assignment to clusters Assign data objects to the closest cluster end //Updating Cluster centroid Evaluate the new cluster centroid While cluster centroids’ difference of two consecutive iterations are not the same End |
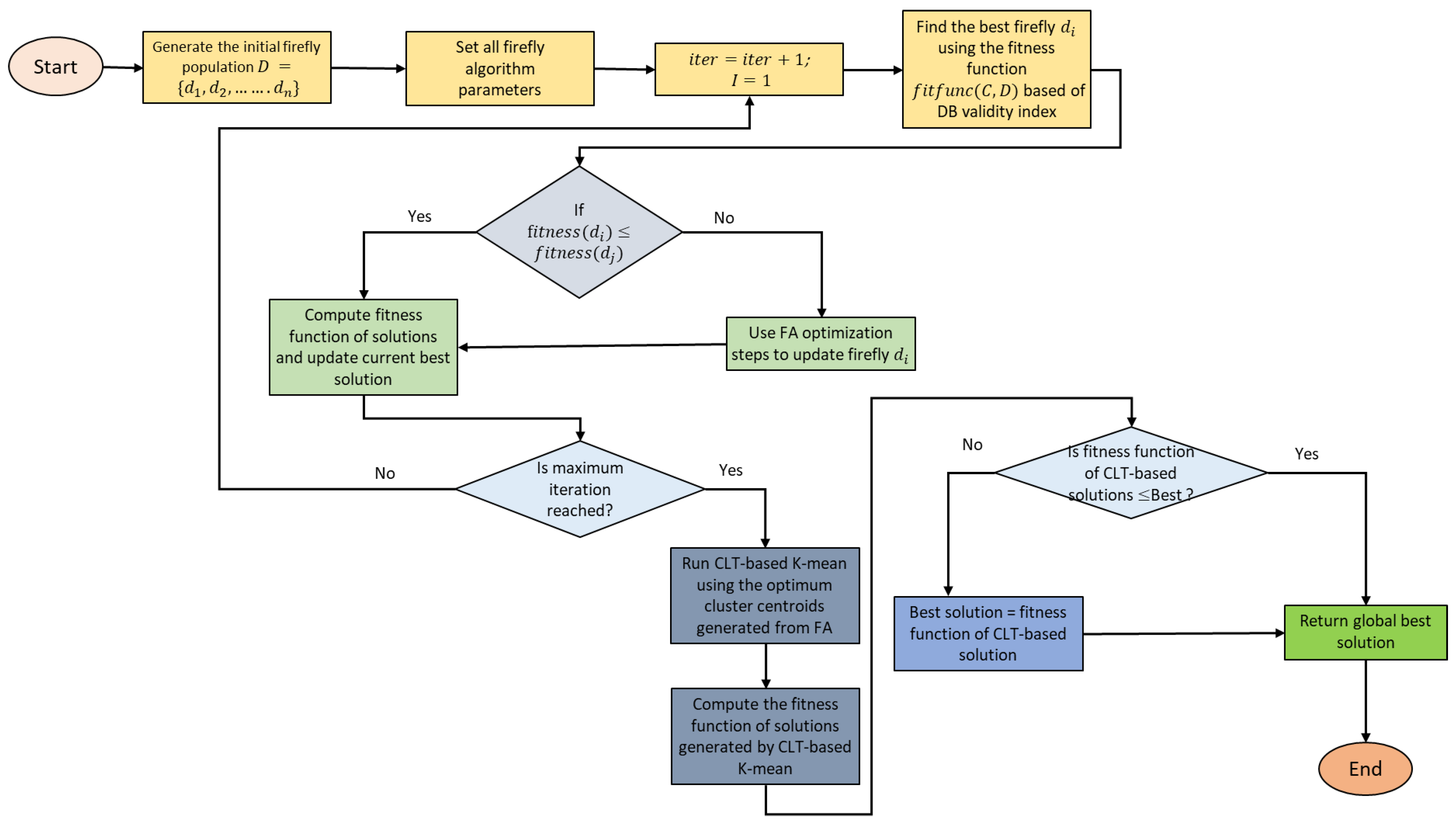
3.4. The Proposed CLT-Based FA-K-Means Model
| Algorithm 4: Pseudocode for the HFA-K-means Algorithm | |
| Input: Output: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | Begin number of cluster centres as the initial population for if as the best solution; end for iteration is not more than the maximum do for j = 1 to n NewPop(i) if NewPop(i).Cost <= BestSol.Cost NewPop(i) as the new solution end while Apply CLT-based K-means using output from FA Compute cost function using optimal clusters from CLT-based K-means end if |
3.5. Davies Bouldin Index
3.6. Computational Complexity of the HFA-K-Means Algorithm
4. Experimentation, Performance Evaluation, and Discussion
4.1. System Configuration
4.2. Parameter Settings
4.3. Data Sets
4.4. Metrics for Performance Evaluation
4.5. Results and Discussion
4.6. Statistical Analysis Tests
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Esmin, A.A.A.; Coelho, R.A.; Matwin, S. A review on particle swarm optimization algorithm and its variants to clustering high-dimensional data. Artif. Intell. Rev. 2015, 44, 23–45. [Google Scholar] [CrossRef]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Kriegel, H.-P.; Kröger, P.; Zimek, A. Clustering high-dimensional data: A survey on subspace clustering, pattern-based clustering, and correlation clustering. ACM Trans. Knowl. Discov. Data 2009, 3, 1–58. [Google Scholar] [CrossRef]
- McCallum, A.; Nigam, K.; Ungar, L.H. Efficient clustering of high-dimensional data sets with application to reference matching. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 169–178. [Google Scholar] [CrossRef]
- Agarwal, P.; Mehta, S.; Abraham, A. A meta-heuristic density-based subspace clustering algorithm for high-dimensional data. Soft Comput. 2021, 25, 10237–10256. [Google Scholar] [CrossRef]
- Punhani, A.; Faujdar, N.; Mishra, K.K.; Subramanian, M. Binning-Based Silhouette Approach to Find the Optimal Cluster Using K-Means. IEEE Access 2022, 10, 115025–115032. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E. A comprehensive survey of K-means clustering algorithm and analysis of variants. Inf. Sci. 2022; in press. [Google Scholar]
- Xie, T.; Liu, R.; Wei, Z. Improvement of the Fast Clustering Algorithm Improved by K-Means in the Big Data. Appl. Math. Nonlinear Sci. 2020, 5, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Alguliyev, R.M.; Aliguliyev, R.M.; Sukhostat, L.V. Parallel batch k-means for Big data clustering. Comput. Ind. Eng. 2021, 152, 107023. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, C.; Zhang, H. Improved K-means algorithm based on density Canopy. Knowl.-Based Syst. 2018, 145, 289–297. [Google Scholar] [CrossRef]
- Alguliyev, R.; Aliguliyev, R.; Bagirov, A.; Karimov, R. Batch clustering algorithm for big data sets. In Proceedings of the 2016 IEEE 10th International Conference on Application of Information and Communication Technologies (AICT), Baku, Azerbaijan, 12–14 October 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Olukanmi, P.O.; Nelwamondo, F.; Marwala, T. k-Means-Lite: Real Time Clustering for Large Datasets. In Proceedings of the 2018 5th International Conference on Soft Computing & Machine Intelligence (ISCMI), Nairobi, Kenya, 21–22 November 2018; pp. 54–59. [Google Scholar] [CrossRef]
- Islam, Z.; Estivill-Castro, V.; Rahman, A.; Bossomaier, T. Combining K-Means and a genetic algorithm through a novel arrangement of genetic operators for high quality clustering. Expert Syst. Appl. 2018, 91, 402–417. [Google Scholar] [CrossRef]
- Sinha, A.; Jana, P.K. A hybrid MapReduce-based k-means clustering using genetic algorithm for distributed datasets. J. Supercomput. 2018, 74, 1562–1579. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, X. A novel clustering algorithm combining niche genetic algorithm with canopy and K-means. In Proceedings of the 2018 International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 26–28 May 2018; pp. 26–32. [Google Scholar] [CrossRef]
- Behera, H.S.; Nayak, J.; Nanda, M.; Nayak, K. A novel hybrid approach for real world data clustering algorithm based on fuzzy C-means and firefly algorithm. Int. J. Fuzzy Comput. Model. 2015, 1, 431. [Google Scholar] [CrossRef]
- Paul, S.; De, S.; Dey, S. A Novel Approach of Data Clustering Using An Improved Particle Swarm Optimization Based K–Means Clustering Algorithm. In Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Kaur, A.; Pal, S.K.; Singh, A.P. Hybridization of K-Means and Firefly Algorithm for intrusion detection system. Int. J. Syst. Assur. Eng. Manag. 2017, 9, 901–910. [Google Scholar] [CrossRef]
- Pavez, L.; Altimiras, F.; Villavicencio, G. A K-means Bat Algorithm Applied to the Knapsack Problem. In Proceedings of the Computational Methods in Systems and Software; Springer: Cham, Switzerland, 2020; pp. 612–621. [Google Scholar] [CrossRef]
- Kumari, G.V.; Rao, G.S.; Rao, B.P. Flower pollination-based K-means algorithm for medical image compression. Int. J. Adv. Intell. Paradig. 2021, 18, 171. [Google Scholar] [CrossRef]
- Wang, X.; Yu, H.; Lin, Y.; Zhang, Z.; Gong, X. Dynamic Equivalent Modeling for Wind Farms With DFIGs Using the Artificial Bee Colony With K-Means Algorithm. IEEE Access 2020, 8, 173723–173731. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Almutari, M.S.; Ezugwu, A.E. K-Means-Based Nature-Inspired Metaheuristic Algorithms for Automatic Data Clustering Problems: Recent Advances and Future Directions. Appl. Sci. 2021, 11, 11246. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E. Boosting k-means clustering with symbiotic organisms search for automatic clustering problems. PLoS ONE 2022, 17, e0272861. [Google Scholar] [CrossRef]
- Yang, X. Firefly Algorithms for Multimodal Optimization. Stoch. Algorithms Found. Appl. 2009, 5792, 169–178. [Google Scholar]
- Fister, I.; Fister, I., Jr.; Yang, X.S.; Brest, J. A comprehensive review of firefly algorithms. Swarm Evol. Comput. 2013, 13, 34–46. [Google Scholar] [CrossRef] [Green Version]
- Agbaje, M.B.; Ezugwu, A.E.; Els, R. Automatic Data Clustering Using Hybrid Firefly Particle Swarm Optimization Algorithm. IEEE Access 2019, 7, 184963–184984. [Google Scholar] [CrossRef]
- Ariyaratne, M.K.A.; Fernando, T.G.I. A Comprehensive Review of the Firefly Algorithms for Data Clustering. Adv. Swarm Intell. 2022, 1054, 217–239. [Google Scholar]
- Kumar, V.; Kumar, D. A Systematic Review on Firefly Algorithm: Past, Present, and Future. Arch. Comput. Methods Eng. 2020, 28, 3269–3291. [Google Scholar] [CrossRef]
- Hassanzadeh, T.; Meybodi, M.R. A new hybrid approach for data clustering using firefly algorithm and K-means. In Proceedings of the 16th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP 2012), Shiraz, Iran, 2–3 May 2012; pp. 007–011. [Google Scholar] [CrossRef]
- Mathew, J.; Vijayakumar, R. Scalable parallel clustering approach for large data using parallel K means and firefly algorithms. In Proceedings of the 2014 International Conference on High Performance Computing and Applications (ICHPCA), Bhubaneswar, India, 22–24 December 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Nayak, S.; Panda, C.; Xalxo, Z.; Behera, H.S. An Integrated Clustering Framework Using Optimized K-means with Firefly and Canopies. In Computational Intelligence in Data Mining-Volume 2; Springer: New Delhi, India, 2015; pp. 333–343. [Google Scholar] [CrossRef]
- Nayak, J.; Naik, B.; Behera, H.S. Cluster Analysis Using Firefly-Based K-means Algorithm: A Combined Approach. In Computational Intelligence in Data Mining; Springer: Singapore, 2017; pp. 55–64. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, L.; Lim, C.P.; Yu, Y.; Liu, C.; Liu, H.; Walters, J. Improving K-means clustering with enhanced Firefly Algorithms. Appl. Soft Comput. 2019, 84, 105763. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Fister, I.; Yang, X.-S.; Fister, D. Firefly Algorithm: A Brief Review of the Expanding Literature. Cuckoo Search Firefly Algorithm 2014, 516, 347–360. [Google Scholar] [CrossRef]
- Senthilnath, J.; Omkar, S.; Mani, V. Clustering using firefly algorithm: Performance study. Swarm Evol. Comput. 2011, 1, 164–171. [Google Scholar] [CrossRef]
- Rajah, V.; Ezugwu, A.E. Hybrid Symbiotic Organism Search algorithms for Automatic Data Clustering. In Proceedings of the 2020 Conference on Information Communications Technology and Society (ICTAS), Durban, South Africa, 11–12 March 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Ezugwu, A.E.-S.; Agbaje, M.B.; Aljojo, N.; Els, R.; Chiroma, H.; Elaziz, M.A. A Comparative Performance Study of Hybrid Firefly Algorithms for Automatic Data Clustering. IEEE Access 2020, 8, 121089–121118. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Kumar, A.; Ingle, Y.S.; Pande, A.; Dhule, P. Canopy Clustering: A Review on Pre-Clustering Approach to K-Means Clustering. Int. J. Innov. Adv. Comput. Sci. (IJIACS) 2014, 3, 22–29. [Google Scholar]
- Jitpakdee, P.; Aimmanee, P.; Uyyanonvara, B. A Hybrid Approach for Color Image Quantization Using K-means and Firefly Algorithms. World Acad. Sci. Eng. Technol. 2013, 7, 142–149. [Google Scholar]
- Kuo, R.; Li, P. Taiwanese export trade forecasting using firefly algorithm-based K-means algorithm and SVR with wavelet transform. Comput. Ind. Eng. 2016, 99, 153–161. [Google Scholar] [CrossRef]
- Langari, R.K.; Sardar, S.; Mousavi, S.A.A.; Radfar, R. Combined fuzzy clustering and firefly algorithm for privacy preserving in social networks. Expert Syst. Appl. 2020, 141, 112968. [Google Scholar] [CrossRef]
- Yang, X.-S.; Deb, S.; Zhao, Y.-X.; Fong, S.; He, X. Swarm intelligence: Past, present and future. Soft Comput. 2018, 22, 5923–5933. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Hoboken, NJ, USA, 1988. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Pelleg, D.; Moore, A. Accelerating exact k-means algorithms with geometric reasoning. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 277–281. [Google Scholar]
- Alsabti, K.; Ranka, S.; Singh, V. An Efficient K-Means Clustering Algorithm. 1997. Available online: https://surface.syr.edu/eecshttps://surface.syr.edu/eecs/43 (accessed on 7 October 2020).
- Nittel, S.; Leung, K.; Braverman, A. Scaling clustering algorithms for massive data sets using data streams. In Proceedings of the International Conference on Data Engineering, Boston, MA, USA, 30 March–2 April 2004; Volume 20, p. 830. [Google Scholar] [CrossRef]
- Bradley, P.S.; Fayyad, U.; Reina, C. Scaling EM Clustering to Large Databases Scaling EM (Expectation-Maximization) Clustering to Large Databases. Electr. Eng. Comput. Sci.—All Scholarsh. 1998, 43, 0–25. Available online: https://surface.syr.edu/eecs/43 (accessed on 8 October 2022).
- Jin, R.; Goswami, A.; Agrawal, G. Fast and exact out-of-core and distributed k-means clustering. Knowl. Inf. Syst. 2006, 10, 17–40. [Google Scholar] [CrossRef] [Green Version]
- Domingos, P.; Hulten, G. A General Method for Scaling up machine learning algorithm and its application to clustering. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Olukanmi, P.O.; Nelwamondo, F.; Marwala, T. Rethining k-means clustering in the age of massive datasets: A constant-time approach. Neural Comput. Applic. 2020, 32, 15445–15467. [Google Scholar] [CrossRef]
- José-García, A.; Gómez-Flores, W. Automatic clustering using nature-inspired metaheuristics: A survey. Appl. Soft Comput. 2016, 41, 192–213. [Google Scholar] [CrossRef]
- Ezugwu, A.E. Nature-inspired metaheuristic techniques for automatic clustering: A survey and performance study. SN Appl. Sci. 2020, 2, 273. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.-Y.; Prayogo, D. Symbiotic Organisms Search: A new metaheuristic optimization algorithm. Comput. Struct. 2014, 139, 98–112. [Google Scholar] [CrossRef]
- Das, S.; Konar, A. Automatic image pixel clustering with an improved differential evolution. Appl. Soft Comput. 2009, 9, 226–236. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Maulik, U. Nonparametric genetic clustering: Comparison of validity indices. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2001, 31, 120–125. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Gu, J.; Shen, S.; Ma, H.; Miao, F.; Zhang, H.; Gong, H. An Automatic K-Means Clustering Algorithm of GPS Data Combining a Novel Niche Genetic Algorithm with Noise and Density. ISPRS Int. J. Geo-Inf. 2017, 6, 392. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Maulik, U. Genetic clustering for automatic evolution of clusters and application to image classification. Pattern Recognit. 2002, 35, 1197–1208. [Google Scholar] [CrossRef]
- Kumar, V.; Chhabra, J.K.; Kumar, D. Automatic Data Clustering Using Parameter Adaptive Harmony Search Algorithm and Its Application to Image Segmentation. J. Intell. Syst. 2016, 25, 595–610. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, X.; Shen, Y. Automatic clustering using genetic algorithms. Appl. Math. Comput. 2011, 218, 1267–1279. [Google Scholar] [CrossRef]
- Lai, C.-C. A Novel Clustering Approach using Hierarchical Genetic Algorithms. Intell. Autom. Soft Comput. 2005, 11, 143–153. [Google Scholar] [CrossRef]
- Lin, H.-J.; Yang, F.-W.; Kao, Y.-T. An Efficient GA-based Clustering Technique. J. Appl. Sci. Eng. 2005, 8, 113–122. [Google Scholar]
- Anari, B.; Torkestani, J.A.; Rahmani, A. Automatic data clustering using continuous action-set learning automata and its application in segmentation of images. Appl. Soft Comput. 2017, 51, 253–265. [Google Scholar] [CrossRef]
- Kumar, V.; Chhabra, J.K.; Kumar, D. Automatic cluster evolution using gravitational search algorithm and its application on image segmentation. Eng. Appl. Artif. Intell. 2014, 29, 93–103. [Google Scholar] [CrossRef]
- Liu, R.; Zhu, B.; Bian, R.; Ma, Y.; Jiao, L. Dynamic local search based immune automatic clustering algorithm and its applications. Appl. Soft Comput. 2015, 27, 250–268. [Google Scholar] [CrossRef]
- Chowdhury, A.; Bose, S.; Das, S. Automatic Clustering Based on Invasive Weed Optimization Algorithm. In International Conference on Swarm, Evolutionary, and Memetic Computing; Springer: Berlin/Heidelberg, Germany, 2011; pp. 105–112. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| GA [55,56] | ABC [25] | DE [25] | PSO [25] | FA [24] | IWO [25] | TLBO [55] | SOS [57] | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| n | 25 | n | 25 | n | 25 | n | 25 | n | 25 | n | 25 | n | 25 | n | 25 |
| Pc, Pm | 0.8, 0.3 | a | 0.009 | CRmin, CRmax | 0.2, 1.0 | W1, W2 | 1.0, 0.99 | 2 | s | 5 | m | 2 | Pc | 0.2 | |
| MP | 0.02 | #nOn-looker bees | 25 | F | 0.8 | , | 1.5, 2.0 | 1 | , | 0.5, 0.001 | Fl, Fu | 0.2, 0.8 | |||
| Kmin | 2 | m | 2 | Kmin | 2 | Kmin | 2 | Kmin | 2 | 2 | mr | 0.02 | |||
| Kmax | 16 | MaxFE | 50,000 | Kmax | 256 | Kmax | 256 | Kmax | 256 | Kmax | 256 | ||||
| MaxFE | 50,000 | MaxFE | 50,000 | MaxFE | 50,000 | MaxFE | 50,000 | MaxFE | 50,000 | MaxFE | 50,000 | MaxFE | 40 + 2k | ||
| Datasets | Dataset Types | Dimension of Data | Number of Data Objects | Number of Clusters | References |
|---|---|---|---|---|---|
| A1 | Synthetically generated | 2 | 3000 | 20 | [58,59,60] |
| A2 | Synthetically generated | 2 | 5250 | 35 | [58,59,60] |
| A3 | Synthetically generated | 2 | 7500 | 50 | [58,59,60] |
| Birch1 | Synthetically generated | 2 | 100,000 | 100 | [38,40,61] |
| Birch2 | Synthetically generated | 2 | 100,000 | 100 | [38,40,61] |
| Birch3 | Synthetically generated | 2 | 100,000 | 100 | [58,60,61] |
| Bridge | Grey-scale image blocks | 16 | 4096 | 256 | [60,62] |
| D31 | Shape sets | 2 | 3100 | 31 | [60,63] |
| Dim002 | Synthetically generated | 2–15 | 1351–10,126 | 9 | [58,60,64] |
| Dim1024 | High-dimensional | 1024 | 1024 | 16 | [58,60,65] |
| Housec5 | RGB image | 3 | 34,112 | 256 | [60,62] |
| Housec8 | RGB image | 3 | 34,112 | 256 | [60,66] |
| Letter | UCI dataset | 16 | 20,000 | 26 | [60,62] |
| Finland | Mopsi locations | 2 | 13,467 | 4 | [60,67] |
| S1 | Synthetically generated | 2 | 5000 | 15 | [58,60,68] |
| S2 | Synthetically generated | 2 | 5000 | 15 | [58,60,68] |
| S3 | Synthetically generated | 2 | 5000 | 15 | [58,60,68] |
| S4 | Synthetically generated | 2 | 5000 | 15 | [7,58,60,68] |
| T4.8k | Miscellaneous | 2 | 8000 | 3 | [60,69] |
| Yeast | UCI dataset | 8 | 1484 | 10 | [60,62] |
| Dataset | HFAK-Means | HABCK-Means | HIWOK-Means | HSOSK-Means | HTLBOK-Means | HDEK-Means | HPSOK-Means | HGAK-Means | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Mean | Std. Dev | Min | Max | Mean | Std. Dev | Min | Max | Mean | Std. Dev | Min | Max | Mean | Std. Dev | Min | Max | Mean | Std. Dev | Min | Max | Mean | Std. Dev | Min | Max | Mean | Std. Dev | Min | Max | Mean | Std. Dev | |
| A1 | 0.2441 | 0.3503 | 0.2942 | 0.0304 | 0.2892 | 0.6123 | 0.5794 | 0.0691 | 0.2387 | 0.6550 | 0.2964 | 0.0866 | 0.2519 | 0.3126 | 0.2768 | 0.0194 | 0.2424 | 0.5902 | 0.2983 | 0.0717 | 0.2638 | 0.3323 | 0.2853 | 0.0148 | 0.2512 | 0.5901 | 0.3017 | 0.0720 | 0.5902 | 0.6116 | 0.5944 | 0.0087 |
| A2 | 0.2186 | 0.4406 | 0.3155 | 0.0746 | 0.2865 | 0.6840 | 0.6594 | 0.0879 | 0.2445 | 0.4275 | 0.3027 | 0.0465 | 0.2530 | 0.4622 | 0.3344 | 0.0573 | 0.2198 | 0.5199 | 0.3407 | 0.0916 | 0.2349 | 0.6776 | 0.3595 | 0.1025 | 0.2226 | 0.4016 | 0.2954 | 0.0493 | 0.6776 | 0.6780 | 0.6778 | 0.0002 |
| A3 | 0.7908 | 0.7922 | 0.7915 | 0.0007 | 0.7796 | 0.7929 | 0.7881 | 0.0036 | 0.7730 | 0.9172 | 0.8402 | 0.0322 | 0.8124 | 0.8743 | 0.8406 | 0.0181 | 0.7908 | 0.7970 | 0.7932 | 0.0026 | 0.7908 | 0.7922 | 0.7912 | 0.0005 | 0.7922 | 0.8019 | 0.7994 | 0.0037 | 0.7909 | 0.8043 | 0.7967 | 0.0054 |
| Birch 1 | 0.7774 | 0.8018 | 0.8001 | 0.0053 | 0.7753 | 0.7965 | 0.7881 | 0.0059 | 0.8081 | 0.8996 | 0.8335 | 0.0204 | 0.8165 | 0.8577 | 0.8345 | 0.0143 | 0.8010 | 0.8018 | 0.8014 | 0.0003 | 0.8010 | 0.8018 | 0.8010 | 0.0002 | 0.8010 | 0.8025 | 0.8020 | 0.0005 | 0.8010 | 0.8034 | 0.8018 | 0.0006 |
| Birch 2 | 0.1585 | 0.2154 | 0.1880 | 0.0198 | 0.5070 | 0.5082 | 0.5074 | 0.0004 | 0.1617 | 0.2071 | 0.1852 | 0.0117 | 0.1511 | 0.2170 | 0.1886 | 0.0192 | 0.1630 | 0.2490 | 0.1972 | 0.0231 | 0.1740 | 0.2318 | 0.1977 | 0.0155 | 0.1471 | 0.2226 | 0.1909 | 0.0167 | 0.5070 | 0.5071 | 0.5070 | 0.0000 |
| Birch 3 | 0.6130 | 0.7160 | 0.6539 | 0.0421 | 0.7161 | 0.7438 | 0.7244 | 0.0082 | 0.5188 | 0.7973 | 0.6264 | 0.0747 | 0.4679 | 0.7413 | 0.6631 | 0.0690 | 0.5187 | 0.7139 | 0.6155 | 0.0578 | 0.4217 | 0.7160 | 0.6160 | 0.0882 | 0.4928 | 0.7179 | 0.6150 | 0.0722 | 0.7160 | 0.7660 | 0.7356 | 0.0223 |
| Bridge | 0.3289 | 0.3714 | 0.3489 | 0.0132 | 0.5202 | 0.9266 | 0.6549 | 0.1471 | 0.3110 | 1.0576 | 0.5210 | 0.1509 | 0.3168 | 0.6670 | 0.5014 | 0.1096 | 0.3064 | 0.5795 | 0.3667 | 0.0751 | 0.3044 | 0.5810 | 0.3589 | 0.0567 | 0.3216 | 0.6117 | 0.4277 | 0.0930 | 0.4650 | 0.6305 | 0.5930 | 0.0551 |
| D31 | 0.5773 | 0.7929 | 0.6923 | 0.0658 | 0.8017 | 0.8556 | 0.8271 | 0.0114 | 0.5385 | 0.8354 | 0.7251 | 0.0858 | 0.5906 | 0.8701 | 0.7374 | 0.0821 | 0.4945 | 0.8363 | 0.7056 | 0.0845 | 0.5503 | 0.7930 | 0.7134 | 0.0669 | 0.6315 | 0.8412 | 0.7290 | 0.0679 | 0.7930 | 0.8591 | 0.8236 | 0.0237 |
| Dim002 | 0.7309 | 0.7309 | 0.7309 | 0.0000 | 0.7160 | 0.7841 | 0.7563 | 0.0160 | 0.7309 | 0.8429 | 0.7862 | 0.0304 | 0.7046 | 0.9054 | 0.8395 | 0.0599 | 0.7309 | 0.7614 | 0.7552 | 0.0110 | 0.6872 | 0.7377 | 0.7293 | 0.0101 | 0.7309 | 0.7913 | 0.7547 | 0.0217 | 0.7311 | 0.7928 | 0.7586 | 0.0183 |
| Dim1024 | 0.3717 | 1.1511 | 1.0698 | 0.1783 | 1.8425 | 1.9023 | 1.8814 | 0.0166 | 0.8700 | 1.9619 | 1.8897 | 0.2403 | 0.3701 | 2.0337 | 1.8350 | 0.3987 | 1.4323 | 1.5769 | 1.5023 | 0.0306 | 1.4495 | 1.6282 | 1.5808 | 0.0541 | 0.7368 | 2.0528 | 1.9086 | 0.3991 | 1.7855 | 1.8308 | 1.8122 | 0.0137 |
| Housec5 | 0.2465 | 0.4808 | 0.3255 | 0.0572 | 0.5159 | 0.7018 | 0.6150 | 0.0622 | 0.2730 | 0.6019 | 0.3405 | 0.0671 | 0.2349 | 0.4649 | 0.3321 | 0.0669 | 0.2576 | 0.5400 | 0.3558 | 0.0927 | 0.2815 | 0.5557 | 0.4950 | 0.0528 | 0.2819 | 0.4987 | 0.3333 | 0.0464 | 0.4987 | 0.6445 | 0.6073 | 0.0643 |
| Housec8 | 0.3131 | 0.4720 | 0.4164 | 0.0460 | 0.3941 | 0.5715 | 0.5264 | 0.0376 | 0.3487 | 0.5184 | 0.4113 | 0.0435 | 0.3246 | 0.7094 | 0.4276 | 0.0874 | 0.2689 | 0.5209 | 0.3926 | 0.0587 | 0.3519 | 0.4874 | 0.4401 | 0.0438 | 0.3009 | 0.4781 | 0.4110 | 0.0422 | 0.4644 | 0.5212 | 0.5097 | 0.0232 |
| Letter | 0.7548 | 0.8157 | 0.7921 | 0.0231 | 0.8457 | 0.9814 | 0.9368 | 0.0359 | 0.6294 | 1.3885 | 1.1558 | 0.2253 | 0.2180 | 1.3460 | 0.9572 | 0.3256 | 0.3461 | 0.9189 | 0.8158 | 0.1167 | 0.7773 | 0.8305 | 0.8064 | 0.0146 | 0.7701 | 0.8880 | 0.8233 | 0.0346 | 0.8033 | 0.9284 | 0.8616 | 0.0261 |
| Finland | 0.2042 | 0.4789 | 0.3061 | 0.0910 | 0.2193 | 0.4994 | 0.4424 | 0.0553 | 0.1833 | 0.7142 | 0.3327 | 0.1364 | 0.2000 | 0.6692 | 0.3628 | 0.1282 | 0.2212 | 0.4397 | 0.3105 | 0.0724 | 0.1797 | 0.4393 | 0.2799 | 0.0784 | 0.2153 | 0.5731 | 0.3632 | 0.1305 | 0.4393 | 0.5766 | 0.4473 | 0.0305 |
| S1 | 0.6801 | 0.7767 | 0.7714 | 0.0215 | 0.7660 | 0.7903 | 0.7730 | 0.0057 | 0.6693 | 0.8565 | 0.8074 | 0.0403 | 0.6395 | 0.8380 | 0.8068 | 0.0428 | 0.7500 | 0.7767 | 0.7751 | 0.0060 | 0.7741 | 0.7767 | 0.7755 | 0.0011 | 0.5897 | 0.7969 | 0.7693 | 0.0425 | 0.7746 | 0.7973 | 0.7800 | 0.0053 |
| S2 | 0.5412 | 0.9898 | 0.7332 | 0.1215 | 0.7382 | 0.7700 | 0.7453 | 0.0067 | 0.5991 | 0.7928 | 0.7082 | 0.0699 | 0.6173 | 0.8288 | 0.7291 | 0.0629 | 0.4908 | 0.7470 | 0.7029 | 0.0729 | 0.6072 | 0.7391 | 0.7103 | 0.0510 | 0.5469 | 0.7470 | 0.7053 | 0.0574 | 0.7392 | 0.7470 | 0.7447 | 0.0030 |
| S3 | 0.3782 | 0.6038 | 0.5073 | 0.0641 | 0.7126 | 0.7305 | 0.7174 | 0.0047 | 0.3878 | 0.6352 | 0.4823 | 0.0599 | 0.3824 | 0.7527 | 0.4891 | 0.0773 | 0.3853 | 0.5973 | 0.4883 | 0.0529 | 0.3868 | 0.6838 | 0.4993 | 0.0727 | 0.3863 | 0.5955 | 0.4846 | 0.0600 | 0.7112 | 0.7305 | 0.7162 | 0.0063 |
| S4 | 0.6802 | 0.7690 | 0.7645 | 0.0198 | 0.7684 | 0.7810 | 0.7761 | 0.0032 | 0.6714 | 0.8334 | 0.7962 | 0.0329 | 0.6784 | 0.8170 | 0.7928 | 0.0330 | 0.6951 | 0.7699 | 0.7641 | 0.0167 | 0.7690 | 0.7696 | 0.7691 | 0.0002 | 0.7229 | 0.7898 | 0.7726 | 0.0152 | 0.7693 | 0.7829 | 0.7773 | 0.0033 |
| T4.8k | 0.0178 | 0.0227 | 0.0218 | 0.0020 | 0.0213 | 0.0427 | 0.0300 | 0.0067 | 0.0178 | 0.3229 | 0.1248 | 0.0990 | 0.0179 | 0.3341 | 0.1582 | 0.0783 | 0.0176 | 0.0227 | 0.0220 | 0.0017 | 0.0182 | 0.0227 | 0.0220 | 0.0016 | 0.0179 | 0.0227 | 0.0215 | 0.0020 | 0.0218 | 0.0227 | 0.0226 | 0.0002 |
| Yeast | 0.4379 | 0.5559 | 0.5205 | 0.0570 | 0.5882 | 0.9583 | 0.8232 | 0.1141 | 0.2335 | 0.5569 | 0.5286 | 0.0784 | 0.7694 | 0.9057 | 0.8665 | 0.0300 | 0.2248 | 0.7931 | 0.6228 | 0.1514 | 0.2323 | 0.5660 | 0.4892 | 0.0745 | 0.2021 | 0.7869 | 0.5539 | 0.1992 | 0.2986 | 0.8131 | 0.6637 | 0.1409 |
| Overall average | 0.4533 | 0.6164 | 0.5522 | 0.0467 | 0.6402 | 0.7717 | 0.7276 | 0.0349 | 0.4604 | 0.7911 | 0.6347 | 0.0816 | 0.4409 | 0.7803 | 0.6487 | 0.0890 | 0.4678 | 0.6776 | 0.5813 | 0.0545 | 0.5028 | 0.6581 | 0.5860 | 0.0400 | 0.4581 | 0.7005 | 0.6031 | 0.0713 | 0.6689 | 0.7424 | 0.7116 | 0.0225 |
| Metaheuristic-Based K-Means Hybrid Algorithm | Mean Rank |
|---|---|
| HFAK-means | 2.48 |
| HTLBOK-means | 3.21 |
| HDEK-means | 3.36 |
| HPSOK-means | 3.67 |
| HIWOK-means | 4.90 |
| HSOSK-means | 5.62 |
| HABCK-means | 6.29 |
| HGAK-means | 6.48 |
| High-Dimensional Datasets | DB Index | |||
|---|---|---|---|---|
| Best | Worst | Mean | Std. Dev | |
| A1 | 0.2441 | 0.3503 | 0.2942 | 0.0304 |
| A2 | 0.2186 | 0.4406 | 0.3155 | 0.0746 |
| A3 | 0.7908 | 0.7922 | 0.7915 | 0.0007 |
| Birch1 | 0.7774 | 0.8018 | 0.8001 | 0.0053 |
| Birch2 | 0.1585 | 0.2154 | 0.1880 | 0.0198 |
| Birch3 | 0.6130 | 0.7160 | 0.6539 | 0.0421 |
| Bridge | 0.3289 | 0.3714 | 0.3489 | 0.0132 |
| D31 | 0.5773 | 0.7929 | 0.6923 | 0.0658 |
| Dim002 | 0.7309 | 0.7309 | 0.7309 | 0.0000 |
| Dim1024 | 0.3717 | 1.1511 | 1.0698 | 0.1783 |
| Housec5 | 0.2465 | 0.4808 | 0.3255 | 0.0572 |
| Housec8 | 0.3131 | 0.4720 | 0.4164 | 0.0460 |
| Letter | 0.7548 | 0.8157 | 0.7921 | 0.0231 |
| Finland | 0.2042 | 0.4789 | 0.3061 | 0.0910 |
| S1 | 0.6801 | 0.7767 | 0.7714 | 0.0215 |
| S2 | 0.5412 | 0.9898 | 0.7332 | 0.1215 |
| S3 | 0.3782 | 0.6038 | 0.5073 | 0.0641 |
| S4 | 0.6802 | 0.7690 | 0.7645 | 0.0198 |
| T4.8k | 0.0178 | 0.0227 | 0.0218 | 0.0020 |
| Yeast | 0.4379 | 0.5559 | 0.5205 | 0.0570 |
| Average | 0.4544 | 0.6164 | 0.5522 | 0.0464 |
| High-Dimensional Datasets | HFA-K-Means | FA | K-Means | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | Worst | Mean | Std. Dev | Best | Worst | Mean | Std. Dev | Best | Worst | Mean | Std. Dev | |
| A1 | 0.2441 | 0.3503 | 0.2942 | 0.0304 | 0.5901 | 0.5901 | 0.5901 | 0.0000 | 0.7788 | 0.7788 | 0.7788 | 0.0000 |
| A2 | 0.2186 | 0.4406 | 0.3155 | 0.0746 | 0.6776 | 0.6776 | 0.6776 | 0.0000 | 0.9229 | 0.9229 | 0.9229 | 0.0000 |
| A3 | 0.7908 | 0.7922 | 0.7915 | 0.0007 | 0.7908 | 0.7922 | 0.7915 | 0.0007 | 1.2433 | 1.2793 | 1.2631 | 0.0184 |
| Birch1 | 0.7774 | 0.8018 | 0.8001 | 0.0053 | 0.8010 | 0.8018 | 0.8013 | 0.0003 | 1.2875 | 1.2875 | 1.2875 | 0.0000 |
| Birch2 | 0.1585 | 0.2154 | 0.1880 | 0.0198 | 0.5070 | 0.5070 | 0.5070 | 0.0000 | 0.5882 | 0.5882 | 0.5882 | 0.0000 |
| Birch3 | 0.6130 | 0.7160 | 0.6539 | 0.0421 | 0.7160 | 0.7160 | 0.7160 | 0.0000 | 1.1592 | 1.1726 | 1.1650 | 0.0037 |
| Bridge | 0.3289 | 0.3714 | 0.3489 | 0.0132 | 0.6108 | 0.6116 | 0.6113 | 0.0003 | 0.9876 | 0.9876 | 0.9876 | 0.0000 |
| D31 | 0.5773 | 0.7929 | 0.6923 | 0.0658 | 0.7929 | 0.7929 | 0.7929 | 0.0000 | 1.3446 | 1.3446 | 1.3446 | 0.0000 |
| Dim002 | 0.7309 | 0.7309 | 0.7309 | 0.0000 | 0.7309 | 0.7309 | 0.7309 | 0.0000 | 1.1535 | 1.1535 | 1.1535 | 0.0000 |
| Dim1024 | 0.3717 | 1.1511 | 1.0698 | 0.1783 | 0.9489 | 1.1511 | 1.1106 | 0.0625 | 3.4291 | 3.4291 | 3.4291 | 0.0000 |
| Housec5 | 0.2465 | 0.4808 | 0.3255 | 0.0572 | 0.4987 | 0.6422 | 0.5561 | 0.0721 | 0.8678 | 0.8678 | 0.8678 | 0.0000 |
| Housec8 | 0.3131 | 0.4720 | 0.4164 | 0.0460 | 0.4644 | 0.5209 | 0.5068 | 0.0251 | 0.6395 | 0.6395 | 0.6395 | 0.0000 |
| Letter | 0.7548 | 0.8157 | 0.7921 | 0.0231 | 0.7548 | 0.8157 | 0.7921 | 0.0231 | 2.0355 | 2.0360 | 2.0359 | 0.0002 |
| Finland | 0.2042 | 0.4789 | 0.3061 | 0.0910 | 0.4393 | 0.4393 | 0.4393 | 0.0000 | 0.5461 | 0.5461 | 0.5461 | 0.0000 |
| S1 | 0.6801 | 0.7767 | 0.7714 | 0.0215 | 0.7743 | 0.7767 | 0.7762 | 0.0010 | 1.2048 | 1.3463 | 1.3044 | 0.0455 |
| S2 | 0.5412 | 0.9898 | 0.7332 | 0.1215 | 0.7391 | 0.7391 | 0.7391 | 0.0000 | 1.1230 | 1.1230 | 1.1230 | 0.0000 |
| S3 | 0.3782 | 0.6038 | 0.5073 | 0.0641 | 0.7111 | 0.7111 | 0.7111 | 0.0000 | 1.0750 | 1.0750 | 1.0750 | 0.0000 |
| S4 | 0.6802 | 0.7690 | 0.7645 | 0.0198 | 0.7690 | 0.7771 | 0.7694 | 0.0018 | 1.2354 | 1.2354 | 1.2354 | 0.0000 |
| T4.8k | 0.0178 | 0.0227 | 0.0218 | 0.0020 | 0.0227 | 0.0227 | 0.0227 | 0.0000 | 0.9649 | 0.9649 | 0.9649 | 0.0000 |
| Yeast | 0.4379 | 0.5559 | 0.5205 | 0.0570 | 0.4379 | 0.5559 | 0.5205 | 0.0570 | 0.7084 | 1.7844 | 1.7257 | 0.2395 |
| Average | 0.4544 | 0.6164 | 0.5522 | 0.0464 | 0.6389 | 0.6686 | 0.6581 | 0.0122 | 1.1647 | 1.2281 | 1.2219 | 0.0154 |
| High-Dimensional Datasets. | HFA-K-Means | GA | DE | PSO | IWO | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std. Dev | Mean | Std. Dev | Mean | Std. Dev | Mean | Std. Dev | Mean | Std. Dev | |
| A1 | 0.2942 | 0.0304 | 0.6907 | 0.0420 | 0.6016 | 0.0116 | 0.6662 | 0.0424 | 0.6308 | 0.0265 |
| A2 | 0.3155 | 0.0746 | 0.7549 | 0.0293 | 0.7081 | 0.0348 | 0.7134 | 0.0284 | 0.7483 | 0.0468 |
| A3 | 0.7915 | 0.0007 | 0.7758 | 0.0418 | 0.7349 | 0.0184 | 0.7279 | 0.0287 | 0.7545 | 0.0339 |
| Birch1 | 0.8001 | 0.0053 | 0.7976 | 0.0309 | 0.7480 | 0.0171 | 0.7528 | 0.0169 | 0.7644 | 0.0211 |
| Birch2 | 0.1904 | 0.0174 | 0.6197 | 0.0361 | 0.5086 | 0.0016 | 0.5876 | 0.0358 | 0.5168 | 0.0052 |
| Birch3 | 0.6577 | 0.0647 | 0.7718 | 0.0431 | 0.7488 | 0.0297 | 0.7213 | 0.0306 | 0.7568 | 0.0248 |
| Bridge | 0.3489 | 0.0132 | - | - | 0.8292 | 0.0516 | 0.9786 | 0.1331 | 1.1575 | 0.0967 |
| D31 | 0.6923 | 0.0658 | - | - | 0.8757 | 0.0302 | 0.7630 | 0.0514 | 0.7896 | 0.0312 |
| Dim002 | 0.7309 | 0.0000 | 0.6772 | 0.0664 | 0.6685 | 0.0263 | 0.5823 | 0.0772 | 0.6661 | 0.0403 |
| Dim1024 | 1.0698 | 0.1783 | - | - | 1.7678 | 0.0114 | 1.8224 | 0.0481 | 2.0105 | 0.0193 |
| Housec5 | 0.3255 | 0.0572 | - | - | 0.6190 | 0.0412 | 0.7456 | 0.0679 | 0.7034 | 0.0430 |
| Housec8 | 0.4164 | 0.0460 | - | - | 0.5245 | 0.0139 | 0.6418 | 0.0858 | 0.6206 | 0.0546 |
| Letter | 0.7921 | 0.0231 | - | - | 0.9852 | 0.0303 | 2.0354 | 0.1084 | 1.2245 | 0.0416 |
| Finland | 0.3061 | 0.0910 | 0.4407 | 0.0009 | 0.4575 | 0.0082 | 0.5761 | 0.0630 | 0.5036 | 0.0398 |
| S1 | 0.7714 | 0.0215 | 0.7006 | 0.0293 | 0.7363 | 0.0150 | 0.6472 | 0.0470 | 0.7572 | 0.0315 |
| S2 | 0.7332 | 0.1215 | 0.7417 | 0.0393 | 0.7256 | 0.0221 | 0.6878 | 0.0318 | 0.7625 | 0.0296 |
| S3 | 0.5073 | 0.0641 | 0.7682 | 0.0395 | 0.7265 | 0.0179 | 0.7261 | 0.0282 | 0.7567 | 0.0333 |
| S4 | 0.7645 | 0.0198 | 0.7663 | 0.0240 | 0.7635 | 0.0180 | 0.7455 | 0.0316 | 0.7809 | 0.0191 |
| T4.8k | 0.0218 | 0.0020 | 0.0023 | 0.0000 | 0.0228 | 0.0001 | 17.5004 | 22.6863 | 0.1119 | 0.0665 |
| Yeast | 0.5205 | 0.0570 | - | - | 0.8053 | 0.0401 | 0.7710 | 0.1219 | 0.5700 | 0.1055 |
| Average | 0.5526 | 0.0474 | 0.6544 | 0.0325 | 0.7279 | 0.0220 | 1.6696 | 1.1882 | 0.7793 | 0.0405 |
| High-Dimensional Datasets | HFA-K-Means | ISOSK-Means | PSODE | FADE | IWODE | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std. Dev | Mean | Std. Dev | Mean | Std. Dev | Mean | Std. Dev | Mean | Std. Dev | |
| A1 | 0.2942 | 0.0304 | 0.5911 | 0.0003 | 0.5949 | 0.0086 | 0.6171 | 0.0347 | 0.6525 | 0.0621 |
| A2 | 0.3155 | 0.0746 | 0.6781 | 0.0002 | 0.6912 | 0.0161 | 0.6976 | 0.0215 | 0.7296 | 0.0391 |
| A3 | 0.7915 | 0.0007 | 0.7945 | 0.0011 | 0.7106 | 0.0176 | 0.7085 | 0.0332 | 0.7527 | 0.0319 |
| Birch1 | 0.8001 | 0.0053 | 0.8030 | 0.0006 | 0.7256 | 0.0276 | 0.7232 | 0.0257 | 0.7692 | 0.0279 |
| Birch2 | 0.1904 | 0.0174 | 0.5071 | 0.0001 | 0.5070 | 0.0002 | 0.5155 | 0.0235 | 0.5176 | 0.0084 |
| Birch3 | 0.6577 | 0.0647 | 0.7168 | 0.0004 | 0.7074 | 0.0151 | 0.7012 | 0.0191 | 0.7570 | 0.0247 |
| Bridge | 0.3489 | 0.0132 | 0.6464 | 0.0009 | 0.7141 | 0.1007 | 0.6405 | 0.0709 | 1.1397 | 0.0666 |
| D31 | 0.6923 | 0.0658 | 0.8125 | 0.0070 | 0.8021 | 0.0407 | 0.7788 | 0.0376 | 0.7972 | 0.0514 |
| Dim002 | 0.7309 | 0.0000 | 0.6384 | 0.0222 | 0.5975 | 0.0445 | 0.6280 | 0.0607 | 0.6705 | 0.0432 |
| Dim1024 | 1.0698 | 0.1783 | 1.1332 | 0.3795 | 1.7644 | 0.0112 | 1.4759 | 0.1200 | 1.9654 | 0.0261 |
| Housec5 | 0.3255 | 0.0572 | 0.5377 | 0.0123 | 2.2408 | 4.0861 | 0.5467 | 0.0287 | 0.6865 | 0.0229 |
| Housec8 | 0.4164 | 0.0460 | 0.4919 | 0.5305 | 0.5022 | 0.0315 | 0.4707 | 0.0383 | 0.6344 | 0.0408 |
| Letter | 0.7921 | 0.0231 | 0.9683 | 1.0545 | 0.9121 | 0.0628 | 0.8665 | 0.0663 | 1.2057 | 0.0571 |
| Finland | 0.3061 | 0.0910 | 0.4427 | 0.0011 | 0.4465 | 0.0060 | 0.4686 | 0.0547 | 0.4864 | 0.0371 |
| S1 | 0.7714 | 0.0215 | 0.7770 | 0.0009 | 0.6739 | 0.0351 | 0.6756 | 0.0270 | 0.7501 | 0.0280 |
| S2 | 0.7332 | 0.1215 | 0.7412 | 0.0008 | 0.6844 | 0.0280 | 0.6939 | 0.0345 | 0.7556 | 0.0190 |
| S3 | 0.5073 | 0.0641 | 0.7126 | 0.0005 | 0.7106 | 0.0199 | 0.7072 | 0.0181 | 0.7559 | 0.0317 |
| S4 | 0.7645 | 0.0198 | 0.7723 | 0.0009 | 0.7299 | 0.0162 | 0.7356 | 0.0226 | 0.7896 | 0.0303 |
| T4.8k | 0.0218 | 0.0020 | 0.0227 | 0.0000 | 0.0227 | 0.0000 | 0.0423 | 0.0882 | 0.0928 | 0.0515 |
| Yeast | 0.5205 | 0.0570 | 0.7489 | 0.0682 | 0.7193 | 0.0677 | 0.6375 | 0.1344 | 0.5949 | 0.1144 |
| Average | 0.5526 | 0.0474 | 0.6768 | 0.1041 | 0.7729 | 0.2318 | 0.6665 | 0.0480 | 0.7752 | 0.0407 |
| High-Dimensional Datasets | HFA-K-Means | FAPSO | FADE | FATLBO |
|---|---|---|---|---|
| Mean Value | Mean Value | Mean Value | Mean Value | |
| Birch1 | 0.8001 | 0.6572 | 0.7232 | 0.6952 |
| Birch2 | 0.1904 | 0.5040 | 0.5155 | 0.5163 |
| Birch3 | 0.6577 | 0.6812 | 0.7012 | 0.7596 |
| Bridge | 0.3489 | 0.5901 | 0.6405 | 0.6108 |
| Housec5 | 0.3255 | 0.4187 | 2.2408 | 0.4158 |
| Housec8 | 0.4164 | 0.4245 | 0.5022 | 0.4559 |
| Letter | 0.7921 | 0.7146 | 0.9121 | 0.7775 |
| Average | 0.5046 | 0.5700 | 0.8908 | 0.6044 |
| Datasets | FA | K-Means | HFA-K-Means |
|---|---|---|---|
| A1 | 2.00 | 3.00 | 1.00 |
| A2 | 2.00 | 3.00 | 1.00 |
| A3 | 1.50 | 3.00 | 1.50 |
| Birch1 | 1.53 | 3.00 | 1.48 |
| Birch2 | 2.00 | 3.00 | 1.00 |
| Birch3 | 1.85 | 3.00 | 1.15 |
| Bridge | 2.00 | 3.00 | 1.00 |
| D31 | 1.95 | 3.00 | 1.05 |
| Dim002 | 1.50 | 3.00 | 1.50 |
| Dim1024 | 1.55 | 3.00 | 1.45 |
| Housec5 | 1.55 | 3.00 | 1.45 |
| Housec8 | 1.95 | 3.00 | 1.05 |
| Letter | 1.50 | 3.00 | 1.50 |
| Finland | 1.83 | 3.00 | 1.18 |
| S1 | 1.53 | 3.00 | 1.48 |
| S2 | 1.60 | 3.00 | 1.40 |
| S3 | 2.00 | 3.00 | 1.00 |
| S4 | 1.53 | 3.00 | 1.48 |
| T4.8k | 2.00 | 3.00 | 1.00 |
| Yeast | 1.50 | 3.00 | 1.50 |
| Datasets | HFA-K-Means vs. FA | HFA-K-Means vs. K-Means | FA vs. K-Means |
|---|---|---|---|
| A1 | 0.001 | 0.001 | 0.001 |
| A2 | 0.001 | 0.001 | 0.001 |
| A3 | 1.000 | 0.001 | 0.001 |
| Birch1 | 0.317 | 0.001 | 0.001 |
| Birch2 | 0.001 | 0.001 | 0.001 |
| Birch3 | 0.002 | 0.001 | 0.001 |
| Bridge | 0.001 | 0.001 | 0.001 |
| D31 | 0.001 | 0.001 | 0.001 |
| Dim002 | 1.000 | 0.001 | 0.001 |
| Dim1024 | 0.180 | 0.001 | 0.001 |
| Housec5 | 0.180 | 0.001 | 0.001 |
| Housec8 | 0.001 | 0.001 | 0.001 |
| Letter | 1.000 | 0.001 | 0.001 |
| Finland | 0.001 | 0.001 | 0.001 |
| S1 | 0.317 | 0.001 | 0.001 |
| S2 | 0.638 | 0.001 | 0.001 |
| S3 | 0.001 | 0.001 | 0.001 |
| S4 | 0.317 | 0.001 | 0.001 |
| T4.8k | 0.001 | 0.001 | 0.001 |
| Yeast | 1.000 | 0.001 | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ikotun, A.M.; Ezugwu, A.E. Enhanced Firefly-K-Means Clustering with Adaptive Mutation and Central Limit Theorem for Automatic Clustering of High-Dimensional Datasets. Appl. Sci. 2022, 12, 12275. https://doi.org/10.3390/app122312275
Ikotun AM, Ezugwu AE. Enhanced Firefly-K-Means Clustering with Adaptive Mutation and Central Limit Theorem for Automatic Clustering of High-Dimensional Datasets. Applied Sciences. 2022; 12(23):12275. https://doi.org/10.3390/app122312275
Chicago/Turabian StyleIkotun, Abiodun M., and Absalom E. Ezugwu. 2022. "Enhanced Firefly-K-Means Clustering with Adaptive Mutation and Central Limit Theorem for Automatic Clustering of High-Dimensional Datasets" Applied Sciences 12, no. 23: 12275. https://doi.org/10.3390/app122312275
APA StyleIkotun, A. M., & Ezugwu, A. E. (2022). Enhanced Firefly-K-Means Clustering with Adaptive Mutation and Central Limit Theorem for Automatic Clustering of High-Dimensional Datasets. Applied Sciences, 12(23), 12275. https://doi.org/10.3390/app122312275