2. Related Work
A detailed review of related studies on the subject of the concept described in this study is presented in this section. The literature shows that several binary metaheuristic algorithms have been developed to solve the feature selection problem. The feature selection technique based on the wrapper approach uses the binary search capability of metaheuristic algorithms. Swarm- and evolutionary-based algorithms are becoming commonplace methods in the feature selection domain [
15].
Particle Swarm Optimization (PSO) [
16] is a bio-inspired metaheuristic method which has attracted much attention due to its tested and trusted mathematical modelling. This algorithm has been binarized and enhanced to solve problems in discrete search spaces. A study by Unler and Murat [
17], presented a modified discrete PSO that used the logistic regression model and applied it to the feature selection domain. A year later, Chuang et al. [
18], proposed an improved BPSO that introduced the effect of catfish, called “catfishBPSO”, for feature selection. The BPSO was also improved to tackle the optimization problem of feature selection [
19]. Ji et al. [
13], proposed an improved PSO based on the Levy flight local factor, a weighting inertia coefficient based on the global factor and a factor of improvement based on the mechanism of mutation diversity, called (IPSO), to tackle the feature selection problem. This improvement came with shortcomings, however, such as the inclusion of more parameters compared with other improved versions of the PSO, which makes tuning difficult for various application problems and increases computational time. Since every particle in BPSO moves closer to and farther from the hypercube corner, its major shortcoming is stagnation.
The genetic algorithm (GA) is another popular bio-inspired feature selection method which has been widely utilized as a wrapper-based technique. Huang and Wang [
20], proposed a GA-based method using the support vector machine (SVM) as a learning algorithm to solve the feature selection problem. The major goal of their work was concurrent parameter and feature subset optimization without reducing the classification accuracy of the SVM. The method reduced the number of feature subsets and improved the accuracy of classification but was outperformed by the Grid algorithm. Later, Nemati et al. [
21], presented a hybrid GA and ant colony optimizer (ACO) as a feature selection method to predict protein functions. These two algorithms were combined to enable better and faster capabilities with very low computational complexity. Furthermore, Jiang et al. [
22], proposed a modified GA (MGA), i.e., a feature selection method using a pre-trained deep neural network (DNN) for the prediction of the demand for different patients’ key resources in an outpatient department.
Apart from these two notable algorithms, several other nature-inspired methods have been utilized to solve feature selection problems. The binary wrapper-based bat algorithm was developed by Nakamura et al. in 2012 [
23]. It uses the classifier optimum-path forest to locate the feature sets that produce maximum classification accuracy. Hancer et al. [
24], proposed a binary artificial bee colony (ABC) that employed a similarity search mechanism inspired by evolution to resolve the feature selection problem. Emary et al. [
11], proposed the binary ant lion optimizer (BALO) which utilizes the transfer function as a means of moving ant lions within a discrete search space. The binary grey wolf optimizer with two techniques was proposed the following year to locate a subset of features that cater for the two conflicting objectives of the feature selection problem, i.e., to maximize the accuracy of the classification and minimize the number of selected features. However, this method was plagued with premature convergence, despite its outperformance of other methods used for comparison in the study. Zhang et al. [
25], designed a variation of the binary firefly algorithm called return-cost-based FFA (Rc-FFA), which was able to prevent premature convergence. A binary dragonfly optimizer was developed by Mafarja et al. [
26], which employed a time-varying transfer function that improved its exploitation and exploration phases. However, its performance was not close to optimal.
Faris et al. [
27], proposed two variants of the salp swarm algorithm (SSA) to solve the feature selection problem. The first utilized eight transfer functions to convert a continuous search space to a binary one, and the other introduced a crossover operator to improve the exploration behavior of the SSA; however, the study did not provide an analysis of the transfer functions. A binary grasshopper optimization algorithm (BGOA) was proposed by Mafarja et al. [
28], using the V-shaped transfer function and sigmoid. This study incorporated the mutation operator to enhance the exploration phase of the BGOA. In Mafarja and Mirjalili [
29], two binary versions of the whale optimization algorithm were proposed. The first utilized the effect of a roulette wheel and tournament mechanisms of selection with a random operator in the process of searching, while the second version employed the mutation and crossover mechanisms to enhance diversification. Kumar et al. [
30], proposed a binary seagull optimizer which employed four S- and V-shaped transfer functions to binarize the baseline algorithm, applying it to solve the feature selection problem. The reported results showed competitive performance with other methods; their technique was also evaluated using high-dimensional datasets.
Elgin Christo et al. [
31], and Murugesan et al. [
32], designed bio-inspired metaheuristics comprising three algorithms. The former combined glowworld swarm optimization, lion optimization algorithm and differential evolution, while the latter hybridized krill herd, cat swarm and bacteria foraging optimizers, with both using the AddaBoostSVM classifier as the fitness function and a backpropagation neural network to perform classification, which was applied to clinical diagnoses of diseases. The methods showed superior performance over other methods. However, these proposed methods were computationally expensive due to the use of combinations of different metaheuristic methods. Balasubramanian and Ananthamoorthy [
33], proposed a bio-inspired method (salp swarm) with kernel-ELM as a classifier to diagnose glaucoma disease from medical images. The results produced by this method showed superior performance over other methods. However, the technique was not tested on collections of large, real-time datasets because this proved to be more challenging. The different algorithms mentioned above provided better solutions to many of the feature selection problems [
34]. Many of these methods, however, could not yield an optimal subset of features for datasets of high-dimensional magnitude. Additionally, the inference from the NFL theorem that no single algorithm can solve all optimization problems holds in the feature selection domain as well. Hence, a new binary method needs to be developed to solve the optimization problem of feature selection.
Some bio-inspired metaheuristic algorithms are based on susceptible infectious recovery (SIR), the class of models to which the EOSA algorithm belongs. Therefore, reviewing some efforts made using this model in the literature is appropriate here. Some such methods have been proposed to tackle the problem of detection and classification, among which we may cite the SIR model [
35]. This approach is based on sample paths and was employed to detect the sources of information in a network. The assumption of that study was that all nodes on the network were in their initial state and were susceptible, apart from a source that was in a state of infection. The susceptible nodes could then become infected by the infected node, which itself may have no longer been infected. The result of this simulation revealed that the estimator that the reverse-infection algorithm produced for the tree network was nearer to the real source. A further performance evaluation was conducted on many real-world networks with good outcomes. However, the assumption of a single source node only was the drawback of this model, since, in most real-world scenarios, this is close to impossible. To overcome this problem, Zang et al. [
36], utilized a divide-and-conquer approach to find many sources in social networks using the SIR model. The technique showed promising results with high accuracy of its estimations. However, these methods have not been directly employed in the feature selection optimization problem.
Since the outbreak of the COVID-19 virus in 2020, more SIR model-based methods have been designed to detect or diagnose corona virus infection in humans. In Al-Betar et al. [
37], a new coronavirus herd immunity optimizer (CHIO) was proposed which drew its inspiration from the concept of herd immunity and social distance strategy so as to protect society from contracting the virus. The herd immunity employed three main kinds of individuals: susceptible, infected and immunized; it was applied to solve engineering optimization problem. This algorithm has since been utilized to solve feature selection and classification problems, including the introduction of a novel COVID-19 diagnostic strategy, known as patient detection strategy (CPDS) [
38], that combined the wrapper and filter methods for feature selection. The improved k-near neighbor (EKNN) was used for the wrapper method using the chest CT images of COVID-19 infected and non-infected patients. The results revealed the superiority of the proposed method over other, recently developed ones in terms of accuracy, sensitivity, precision, and time of execution. Similarly, the greedy search operator was incorporated with and without the CHIO to make two wrapper-based methods, which were evaluated on 23 benchmark datasets and a real-world COVID-19 dataset.
Some high-dimensional datasets have been employed to assess the efficacy of the proposed methods. Alweshah [
39], boosted the efficiency of the probabilistic neural network (PNN) using CHIO to solve the classification problem. Eleven benchmark datasets were used to assess the accuracy of classification of the proposed CHIO-PNN which, on all the datasets used, produced a summative classification rate of 90.3% with a quicker rate of convergence than other methods. However, the drawback of this method was its use on low and medium rank datasets. As such, there is a concern that higher dimensional datasets may negatively impact its performance.
5. Results and Discussion of Findings
The results presented in this section are focused on the performance of BEOSA and BIEOSA in comparison with those of similar methods, i.e., the binary dwarf mongoose optimizer (BDMO) [
3], the binary simulated normal distribution optimizer (BSNDO) [
9], the binary particle swarm optimizer (BPSO) [
53], the binary whale optimization algorithm (BWOA) [
54], the binary grey wolf optimizer (BGWO) [
55] and the binary sailfish optimizer (BSFO) [
56] algorithms. The selection of these algorithms was based on their outstanding performance, as described in various reports, and their status as state-of-the-art methods for binary optimization. We note that our evaluations of most of these algorithms applied the same parameterizations, e.g., the number of iterations and parameter settings. The following subsections are organized as follows. Firstly, we provide a comparative analysis of the various methods based on their fitness performance and the number of selected features. We then examine the classification accuracy of each method as compared with others. Next, we compare the cost functions of all methods and show the impact of the choice of classifiers on the feature classification procedure. Finally, we report the computational time of each method and discuss our findings. The following subsections using tabular and graphical means for the sake of clarity.
5.1. Comparative Analysis of Fitness and Cost Functions
BEOSA and BIEOSA are now compared with related algorithms based on the results obtained for fitness and cost functions. The fitness function aims to minimize the objective function, while the cost function aims to maximize it.
Table 3 lists the results obtained for each of the binarized algorithms for all benchmark datasets.
The BWOA algorithms performed better on the BreastEW, Lung, Iris, Exactly2, Colon and Vote datasets, with fitness values of 0.0307, 0.0006, 0.0050, 0.2384, 0.0004 and 0.0013, respectively. BWOA showed superiority with six benchmark datasets, while BGWO showed superiority with WaveformEW, yielding a fitness value of 0.1817. BSNDO outperformed the other methods on eight datasets, i.e., Lymphography, M-of-n, PenglungEW, Sonar, SpectEW, Tic-tac-toe, Wine and KrVsKpEW, with fitness values of 0.0380, 0.0046, 0.0013, 0.0047, 0.0948, 0.1647, 0.0298 and 0.0250, respectively. Interestingly, BEOSA outperformed most of the other methods, showing superiority with nine datasets, i.e., CongressEW, Exactly, Exactly2, HeartEW, Ionosphere, Prostate, Wine and Zoo, with fitness values of 0.0575, 0.2620, 0.2384, 0.0772, 0.0722, 0.0002, 0.0298 and 0.0533, respectively. Meanwhile, the associated variant of the proposed algorithm, BIEOSA, was competitive with BEOSA, showing superiority on two datasets. The implication of these findings is that the new method is suitable for minimizing the fitness function, allowing it to solve the difficult problem of feature selection on a wide range of datasets with different dimensionalities.
The values obtained for the cost function are plotted in
Figure 6 to show the variation in the performance of the algorithms with the various datasets. A close examination of the plots for the Zoo, Vote, Wine, Sonar and Tic-tac-toe datasets shows that BEOSA yielded outstanding cost values during the iterative process. In the five considered datasets, the BGWO method showed unstable performance on the cost function, whereas the BEOSA, BIEOSA, BDMO, BSNDO, BPSO, and BWOA were stable and BEOSA, BIEOSA, and BPSO often yielded similar results. The BEOSA curve was above those of the other methods for the Zoo, Sonar and Tic-tac-toe datasets and was close behind those of other methods for the Vote and Wine datasets. In the second category, we compared the performance curves of all the methods using M-of-N, Ionosphere, Exactly, Exactly2, and HeartEW datasets. The BGWO maintained its unstable performance along the curve line, whereas all the remaining methods yielded good results. For example, BEOSA and BPSO closely shared the top section of the plots, meaning that their performance on the cost function was superior to those of the other methods. At the same time, both BDMO and BWOA were low in all the plots, showing that their performance in evaluating the cost function was poor. The BIEOSA and BSNDO were average performers in the five datasets. The third categories of datasets for comparison were Congress, Lymphography, BreastEW, Colon, and SpectEW. With the high dimensional Colon dataset, the BEOSA yielded similar results to BPSO and BGWO, even though the latter was unstable, while the variant BIEOSA and BSNDO methods demonstrated average performance. For the BreastEW dataset, both BEOSA and BIEOSA outperformed the other methods, yielding the best cost function curve. The BEOSA algorithm was just below that of BPSO on the Lymphography dataset, which superseded all other algorithms. The BIEOSA, BPSO, and BWOA were all plotted at the top section for the CongressEW datasets, while the BEOSA algorithm trailed behind. Similarly, the BEOSA outperformed all methods on the SpectEW datasets, although the BIEOSA algorithm yielded a curve in the lower section.
The performance of the algorithms on the Zoo dataset were as follows: the cost values range for BIEOSA was 0.50–0.52, BSNDO 0.64–0.65, BDMO 0.75–0.76, BWOA 0.80–0.81, BPSO 0.84–0.85, BGWO 0.74–0.95, and BEOSA 0.99–1.0. The Vote dataset yielded the following results: BWOA 0.80, BGWO 0.75–0.93, BSNDO, BDMO and BEOSA all 0.94, BIEOSA 0.94–0.97, and BPSO 0.98. The Wine dataset results were as follows: BDMO 0.58, BGWO 0.58–0.97, BSNDO 0.7750–0.7799, BWOA 0.81, BEOSA 0.94, BPSO 0.88–0.97, and BIEOSA 0.97. Performance with the sonar dataset was as follows: BDMO was the lowest among all curves at less than 0.55; meanwhile, BSNDO was at 0.76, BIEOSA was 0.78, BWOA was 0.81, BGWO 0.88–0.87, BPSO 0.88–0.91, and BEOSA 0.86–0.93. For the tic-tac-toe dataset performance BGWO outperformed the other methods by running from 0.62–0.82, BDMO was 0.59, BWOA was 0.62, BIEOSA was 0.63, BSNDO was 0.66, BPSO was 0.68, and BEOSA was 0.73.
The performance of the algorithms on the M-of-n dataset was as follows: the cost function values for BDMO were just above the 0.50 value, while those of BSNDO were 0.62, BWOA was 0.72, BIEOSA was 0.78, BEOSA was 0.83, BGWO was 0.80–0.84 with its peak at 0.97, and BPSO was 0.92-1.0. The Ionosphere dataset yielded the following results: BGWO began its curve from 0.752 and ended at 0.777, BWOA ran through 0.812, BDMO ran through 0.8125, BIEOSA went from 0.826 to 0.840, BSNDO was above 0.850, the BEOSA curve was just above 0.875, and the BPSO curve started from 0.805 and extended to just above 0.900. The Exactly and Exactly2 datasets yielded the following patterns: the BDMO curves were at 0.577 and 0.45 for Exactly and Exactly2, respectively. The BIEOSA curve was 0.625 with Exactly and ranged from 0.64 to 0.68 on Exactly2, BWOA was 0.635 with Exactly and 0.47 with Exactly2, BSNDO was 0.635 with Exactly and 0.60 on Exactly2, BGWO ranged from 0.650 to 0.635 on Exactly and from 0.75 to 0.70 on Exactly2, BPSO was 0.675 with Exactly and 0.75 with Exactly2, and BEOSA was just below 0 to above 0.76 with Exactly and Exactly2, respectively. The result for HeartEW showed that BWOA and BDMO ranked lowest, with cost function value of around 0.50. BGWO followed, starting at 0.55, peaking at 0.83 and ending at 0.69; BIEOSA was 0.64, BPSO ran from 0.65 to 0.75, and lastly, BEOSA, was above all the other algorithms at 0.78.
The CongressEW and Lymphography datasets demonstrated some similarity, with the BSNDO curve at the bottom with 0.62 and 0.52, respectively. This was followed by BDMO, which was at 0.80 and 0.70 with the CongressEW and Lymphography. While the BIEOSA, BWOA and BPSO curves were around 0.95 for the CongressEW dataset, the same algorithms were sparsely plotted with the Lymphography dataset at 0.68, 0.80, and 0.90, respectively. Typically for BGWO, in this case, it started at 0.89 and ended at 0.86 for CongressEW and started at 0.84 and ended at 0.78 with the Lymphography dataset. The BEOSA curve was a 0.875 on the CongressEW dataset and 0.80 on the Lymphography dataset. The algorithm curves showed different performance with the Colon and BreastEW datasets. For instance, where the BWOA algorithm curve was below 0.70 with Colon, it shot up above 0.90 with BreastEW. Additionally, the curve of BSNDO was around 0.85 for the Colon graph but fell below 0.70 with the BreastEW graph. BIEOSA also showed some disparity on Colon, where it crossed the graph close to 0.85; meanwhile, with the BreastEW, it had a better cost value, running close to 0.95. The characteristic of BGWO is that it always zig-zagged its curves, as can be seen with Colon, where it started at 0.92 and ended on the same value, peaking at around 1.0 and dipping to around 0.85. The same algorithm started at 0.93 and ended at 0.92, with its peak at around 0.94 and trough at 0.86 for the BreastEW dataset. The BDMO curve was just below 0.70 on the Colon and around 0.93 on BreastEW. The BPSO and BEOSA curves were around 1.0 with the Colon dataset. Lastly, the SpectEW dataset had some interesting curves for BIEOSA, BPSO and BEOSA, with curves starting from 0.62, 0.83, and 0.90, respectively, and then stabilizing at 0.62, 0.83, and 0.89, respectively. BSNDO and BWOA consistently had curves at 0.75 and 0.80, respectively. BGWO spiked up and down, starting from 0.70 to 0.80 and having a peak at 0.81. BDMO was just below 0.80.
The takeaway from these cost function evaluations is that whereas the values obtained varied across datasets, both BPSO and BEOSA always performed well, mostly yielding curves above those of the other algorithms. This implies that both algorithms demonstrated superiority compared with the other methods, though in most cases, BEOSA outperformed BPSO.
The implication of these outcomes is that both the BEOSA and BIEOSA methods are relevant binary optimization algorithms with great potential for producing very good performance on heterogeneous datasets with different dimensionalities. The cost function, which evaluates how far an algorithm moves away from the fitness function value, also evaluates the robustness of the algorithm in terms of its ability to sustain a good cost function evaluation; the higher the cost function value, the better the fitness value obtained. Considering the consistently outstanding performance of both BEOSA and BIEOSA on the fitness and cost function evaluations with all datasets, we conclude that the algorithm is very suitable for solving the problem of feature selection with effective minimization and maximization of fitness and cost values, respectively. In the following subsection, we compare the number of selected features obtained for all methods and associate this with the fitness evaluation discussed in this section.
5.2. Comparative Analysis of Selected Features for All Methods
The basis of solving feature selection problems using the binary optimization method is to reduce the number of features used for classification purposes. This is necessary to eliminate the bottleneck which is often associated with high-dimensional datasets on classifiers. Another benefit of reducing the number of features is to ensure that only relevant ones are used for the classification operation. In this subsection, we evaluate BEOSA and BIEOSA and compare their performance with that of BWOA, BPSO, BFSO, BGWOA, BDMO and BSNDO.
Table 4 compares the number of features selected for each algorithm across four different population sizes, namely, 25, 50, 75 and 100.
An interesting performance result was observed when the algorithms were compared based on their average number of selected features. For example, the BPSO outputs a value of 1 for the number of selected features for all population sizes and for all datasets considered during our experiments. While this showed some measure of abnormality in the process of feature selection in the algorithm, we observed more standard performance for all the remaining methods. As an example, consider the outcome of some low-dimensional datasets such as the BreastEW, CongressEW, Exactly and Exactly2. The BEOSA and BIEOSA yielded similar results to all the other methods. For BWOA, BGWO, BDMO, BSNDO, BEOSA and BIEOSA, the average numbers of features (on population sizes yielding this average performance) were 17.0 (25), 16.9 (100), 5.5 (50), 3.0 (25), 7.3 (25) and 5.9 (75), respectively. The CongressEW showed 8.9 (100), 10.1 (25), 2.4 (50), 2.4 (50), 5.3 (100) and 4.6 (50) for the same BWOA, BGWO, BDMO, BSNDO, BEOSA and BIEOSA methods. Similarly, the Exactly dataset reported values of 6.2 (50), 8.5 (25), 3.0 (25), 2.2 (25), 4.2 (25) and 2.5 (75), while Exactly2 gave 7.0 (75), 8.3 (100), 3.5 (100), 2.0 (25), 1.7 (100) and 2.5 (25) on the same methods, respectively. These results show that in most cases, population sizes of 25–50 were sufficient to produce the desired results. Even population-intensive algorithms such as BEOSA and BIEOSA demonstrated that their best average feature selection counts could be obtained using a population size range of 25–75.
High-dimensional datasets like Lung, Prostate, Leukemia and Colon, and moderate-dimensional datasets like the PenglungEW, showed how superior the BEOSA and BIEOSA methods were. For instance, the average feature selection numbers in the Lung dataset were 1692.5 (100), 2151.1 (75), 820.3 (50), 2098.4 (25), 403.9 (100) and 685.3 (75) for BWOA, BGWO, BDMO, BSNDO, BEOSA and BIEOSA respectively. Clearly, the BEOSA algorithm yielded the best performance, i.e., 403.9 using 100 as the population size. Additionally, the results obtained for the Prostate dataset showed that the BDMO, BSNDO, BEOSA and BIEOSA methods were able to yield average numbers of selected features of 1402.8 (100), 1478.4 (25), 682.2 (100) and 1141.5 (25), while the BEOSA provided the best performance with a population size of 100. A very impressive result was obtained for BEOSA and BIEOSA on the Leukemia dataset; the BWOA, BGWO, BDMO, BSNDO, BEOSA and BIEOSA algorithms yielded 1708.3 (25), 2320.4 (75), 999.7 (75), 928.5 (25), 50.3 (25) and 589.7 (75), respectively, for the average number of selected features. BEOSA produced an optimal number of 50.3 for selected features with a population size of 25. Moreover, the BIEOSA variant also yielded 589.7 as the average feature size with a population size of 75. Furthermore, the performance of the BWOA, BPSO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA algorithms on the PenglungEW dataset showed values of 170.0 (75), 4.0 (50), 193.0 (50), 23.9 (100), 124.0 (100), 35.0 (75) and 24.0 (25), respectively, as the average number of selected features. Accordingly, BEOSA and BIEOSA performed well using population sizes of 75 and 25, respectively. The performance on the Colon dataset for the BEOSA and BIEOSA methods was also very impressive compared with related methods; the BWOA, BGWO, BDMO, BSNDO, BEOSA and BIEOSA yielded 1016.1 (50), 1301.5 (100), 546.2 (25), 1374.3 (25), 157.1 (75) and 316.5 (100), respectively. We observed that both BEOSA and BIEOSA yielded a low average number of selected features, with values of 157.1 and 316.5, respectively, for methods with population sizes of 75 and 100. Note that the population was not so relevant to the obtained result, since BGWO, which obtained its best average number of selected features with a population size of 100, yielded a far worse result.
The performance of BEOSA and BIEOSA regarding the average number of selected features showed that the proposed method is suitable for selecting the optimal set of features required to achieve improved classification accuracy. An interesting finding revealed by this performance analysis was that BEOSA and BIEOSA are very suitable methods for high-dimensional datasets with a larger number of features to start with. The result also showed that both BEOSA and BIEOSA were very competitive approaches, even when dealing with low-dimensional datasets. In the following subsection, we evaluate and compare the classification accuracy of the selected features by each of the methods discussed in this section.
5.3. Comparative Analysis of the Classification Accuracy of All Methods
The average number of selected features influences the classification accuracy, with a lower number of features being desirable so that classification operation is not bottlenecked. In this subsection, we evaluate the performance of BIEOSA and BEOSA and compare these approaches to related methods. Moreover, a comparative analysis is done in a manner that considers the influence of the population size on performance. Similar to the previous subsection, population sizes of 25, 50, 75, and 100 were compared for each binary optimizer algorithm.
Table 5 shows the performance of the BreastEW, Exactly2, HeartEW and Ionosphere datasets in relation to BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA. For the BreastEW datasets, values of 0.9351, 0.9535, 0.9272, 0.8921, 0.6930, 0.9430 and 0.9149 were obtained for BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA, respectively. Interestingly, the BEOSA algorithm with a population size 100 yielded the best overall performance. The best overall performance obtained with the Exactly2, HeartEW and Ionosphere datasets was 0.7660, 0.8074 and 0.9286 using BPSO, BEOSA and BPSO, respectively. The breakdown results on the Exactly2 dataset showed classification accuracies of 0.7345, 0.7660, 0.7350, 0.7175, 0.6875, 0.5900, 0.7625 and 0.7495 when using BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA, respectively. Values of 0.6963, 0.8019, 0.7222, 0.6963, 0.5722, 0.4815, 0.8074 and 0.6870, and 0.8500, 0.9286, 0.9000, 0.8457, 0.8143, 0.7286, 0.9143 and 0.8729 were obtained for the BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA when using the HeartEW and Ionosphere datasets, respectively.
Similarly, the performance of the Tic-tac-toe, Vote, Wine and Zoo datasets with BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA was observed. The results showed with Tic-tac-toe, BEOSA was superior, with a classification accuracy of 0.7964. In contrast, the worst performance on this dataset was observed with the BDMO method, which yielded a value of 0.6219. The BEOSA method showed a classification accuracy of 0.9583 with the Vote dataset, a demonstration of superiority above all other methods; BPSO yielded 0.9450 and BDMO yielded 0.8333. The Wine and Zoo datasets yielded 0.9556 and 0.9400 classification accuracy with the BEOSA method for the two datasets. We note that in most cases where BEOSA outperformed the other methods, the population sizes were 75 and 100, which supports the attainment of optimal performance in the high dimensional datasets.
UPTOHERE The performance summary for all the methods showed that the BWOA algorithm operated with optimal classification accuracy on 10 datasets with 100 population size, while population sizes 25, 50 and 75 showed 0, 9 and 1 optimal classifications, respectively. The BPSO method demonstrated that using the population size of 100 resulted in 10 datasets performing very well. In contrast, the population sizes 25, 50 and 75 were only able to obtain the best performances, 2, 3 and 5, respectively. Similarly, we observed that the BSFO, BGWO, BDMO, and BSNDO obtained their best classification accuracy using the population sizes of 50, 75, 75, and 100 on 6, 9, 6, and 19 datasets, respectively. The BEOSA and BIEOSA methods obtained their best classification accuracy when the population sizes of 100 and 50 were used such that they both gave such best on 9 and 7 datasets, respectively. Meanwhile, BEOSA showed that using a population size of 25 and 50 will impair the performance, indicating that increased population size supports the improvement of the performance of the algorithm.
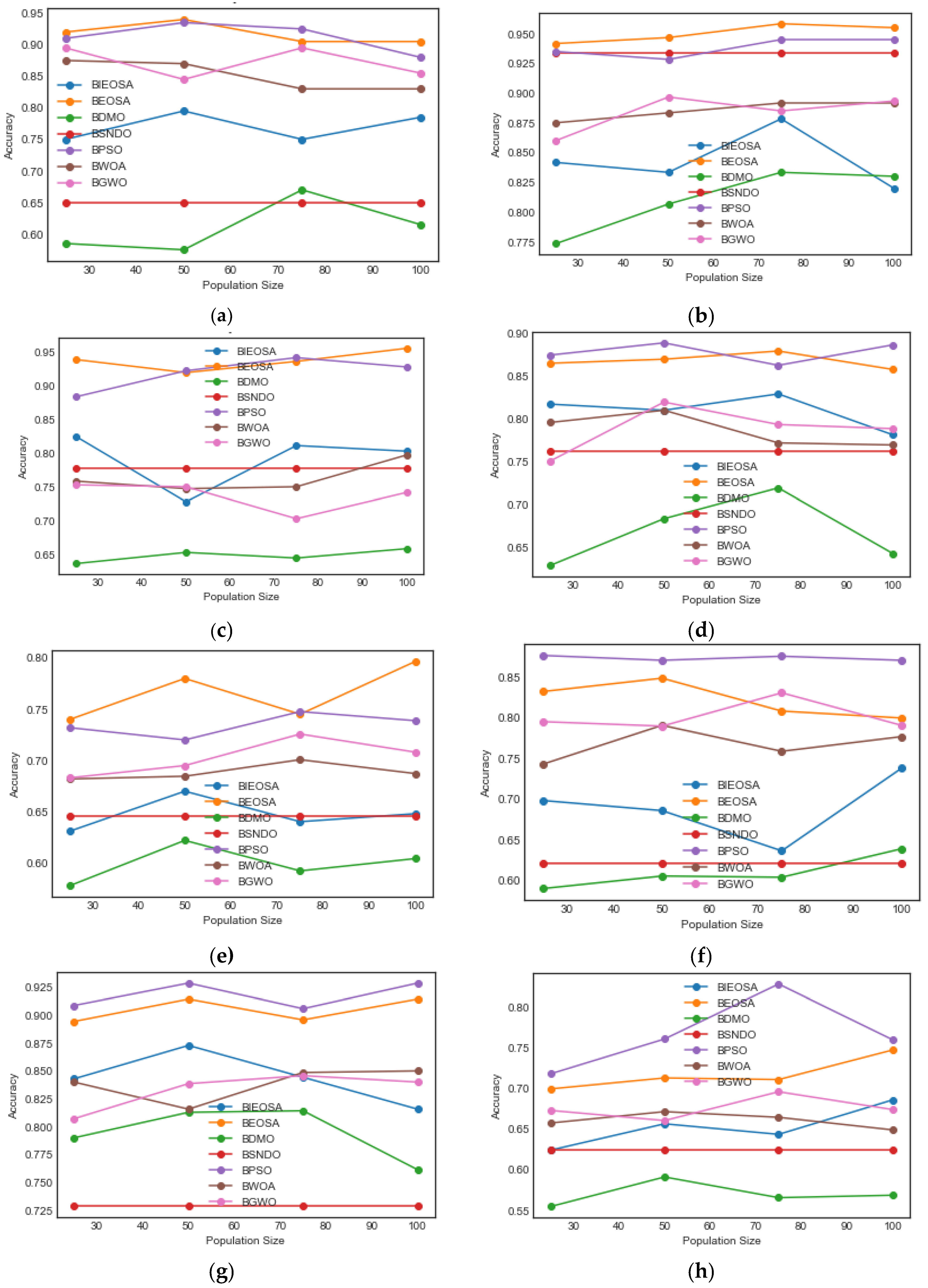
The classification accuracy curves for the Zoo, Vote, Wine, Sonar, Tic-tac-toe, M-of-n, Ionosphere, Exactly, Exactly2, HeatEW, CongressEW, Lymphography, Colon, BreastEW, and SpectEW datasets on the BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA, and BIEOSA are analyzed for further understanding of performance differences. The plots for classification curve analysis are presented in
Figure 7. The curves of all the methods on the Zoo dataset showed that BEOSA and BIEOSA performed better than any of the other methods. Similarly, we observed that the BEOSA method performed well on Vote, Wine, Sonar, Tic-tac-toe, HeartEW, CongressEW, BreastEW and SpectEW datasets. Using the M-of-n, Ionosphere, Exactly, and Exactly2 datasets, the BEOSA and BIEOSA methods demonstrated strong competition with the BPSO method while outperforming the remaining methods.
The classification accuracy for the Zoo dataset on each of the algorithms shows that the BDMO curve runs from 0.59 and ends at 0.61 with a peak at 0.66. BSNDO had a straight curve on 0.65. BIEOSA started from 0.75, peaked at 0.79 and ended at 0.78, BWOA started from 0.87, deep at 078 and ended at the same 0.78, BGWO started from 0.90 peaked and dipped at 0.85 and 0.89 respectively, and ended at 0.86. BPSO and BEOSA top the plots with their curves starting from 0.91 and 0.92 and ending at 0.88 and 0.91, respectively. For the Vote dataset, BDMO rose from 0.775 to 0.825, and BIEOSA started from 0.840, peaked at 0.875 and ended below 0.825. BGWO rose from above 0.850 and terminated above 0.875, while BWOA started from 0.875 and rose slightly to 0.880. BPSO and BSNDO both started just above 0.925 and ended at 0.935 and 0.925, respectively. BEOSA tops the graph by peaking just above 0.950. The performance of Wine and Sonar are similar, with the BDMO method running at the bottom of the graphs of the two datasets starting from an average accuracy value of 0.65 and ending at around 0.66, although the curve peaked above 0.70 for the Sonar dataset. BGWO started from around 0.75 for both Wine and Sonar, and ended just below 0.75 and 0.78 respectively. BSNDO curves in both datasets run between 0.75, and BIEOSA similarly started just above 0.80 and ended just below 0.80 in both cases. As a characteristic of BPSO and BEOSA, both algorithms peaked the graphs for Wine and Sonar by starting from 0.88 and 0.94 on Wine, 0.83 and 0.82 on Sonar, then ending at 0.93 and 0.95 on Wine, and 0.88 and 0.86 on Sonar. The Tic-tac-toe dataset has BDMO at the bottom and BEOSA at the top, starting from 0.61 and 0.74 and ending at 0.60 and 0.79, respectively. BSNDO and BIEOSA ended their curves at around 0.64 but started at 0.63 and 0.65, respectively, while BWOA and BGWO started at the same point of 0.68 but ended at 0.66 and 0.69, respectively. The performance for BPSO showed that it peaked when the population size of 75 was used to obtain an accuracy value of 0.75.
Experimental results for M-of-n, Ionosphere and Exactly are consistent for BPSO which tops the graphs of the three datasets by showing the lowest performance with population size 25 in all cases, but reported the best accuracies at 75, 50 and 75 population sizes each at 0.87, 0.925, and 0.84 accordingly for three datasets. BDMO lies at the lowest in M-of-n and Exactly but ranked second lowest in Ionosphere by obtaining its peaks at 0.61 for 75 population size, 0.810 for 75 population size, and 0.64 at 50 population size for M-of-n, Ionosphere and Exactly, respectively. The BSNDO reported straight curves in the three datasets. BIEOSA curves showed its peak classification accuracies at 0.74 using 100 population size, around 0.875 using 50 population size, 0.67 using 100 population size for M-of-n, Ionosphere and Exactly. The BWOA and BGWO algorithms showed average performances in the three datasets by obtaining their peak classification accuracy values of 0.79 and 0.80 at 50 and 75 population size with M-of-n, 0.845 and 0.835 both at 75 population size with Ionosphere, and 0.67 and 0.69 at 50 and 75 population size with Exactly. BEOSA obtain its best accuracy at 0.85 using 50 population size, 0.910 using 50 population size, and 0.74 using 100 population size for M-of-n, Ionosphere and Exactly datasets, respectively. The Exactly2 and HeartEW datasets showed that BSNDO results in the same classification accuracy for all population sizes at around 0.580 and 0.480, respectively. This is followed by BDMO, which obtained the best classification accuracies at 0.685 and 0.57 using 75 and 50 population sizes. The BWOA, BPSO and BIEOSA algorithms are seen to overlap in performances on the two datasets, with each reporting peak accuracy at 0.725, 0.710, and 0.750 using 50, 25 and 25 population sizes on the Exactly2 dataset. Similarly, BWOA, BPSO and BIEOSA showed their peak accuracies at 0.69 using 100, 100 and 25 population sizes. BPSO and BEOSA demonstrate a strong competitive performance by having their peak accuracy values at around 0.750 in Exactly2 and 0.80 in HeartEW, in both cases at 100 population size.
Results obtained for CongressEW, Lymphography and BreastEW datasets showed that the BSNDO algorithm performances are almost similar for all population sizes at 0.63, 0.45, and 0.69, respectively. This is followed by the BDMO algorithm, which has its peak accuracies at 0.82, 0.63, and 0.89 using population sizes 50, 75, and 25 on the three datasets. The BIEOSA obtained its best classification accuracies at 0.90 using 100 population size, 0.69 using population size, and 0.91 using 75 population size for CongressEW Lymphography and BreastEW, respectively. BWOA and BGWO competed in performance as seen on their curves in CongressEW Lymphography and BreastEW where BWOA had its best accuracies at 0.93, 0.77, and 0.93 using 75, 50 and 50 population sizes. Similarly, BPSO and BEOSA both peaked in performance by obtaining 0.95, between [0.8–0.9], and around 0.95, all using 75 population size in the three datasets. We observed the curves on the Colon and SpectEW datasets for all algorithms. In both cases, BDMO curves rank lowest at the bottom of the graphs having its peak performances as 0.75 and 0.735, using 25 and 100 population sizes. BSNDO shows close flat curves in both datasets, and peak performances averaged at 0.85 and 0.74 for Colon and SpectEW, respectively. In the SpectEW dataset, BWOA, BIEOSA and BGWO all reported their peak performances at around 0.80 and using 100, 50, and 50 population sizes, while the same algorithms had different curve patterns on Colon. For instance, BIEOSA peak accuracy is at 0.88 and 0.81 using 100 and 50 population size, BWOA peak accuracy is at 0.98 and close to 0.82 using 50 and 100 population sizes, and BGWO peak accuracy is at 0.98 and 0.81 using 75 and 50 population size.
The summary of the results obtained for the classification accuracies on each algorithm with respect to all datasets is consistent with the performance reported for cost function evaluation. BPSO and BEOSA algorithms are seen to perform very well compared with other methods, but in most cases, the proposed BEOSA algorithm yields better performance than BPSO. These consistent performances of BEOSA with regard to fitness function evaluation, cost function evaluation, and classification accuracy for the selected feature sizes confirm the relevance of the algorithm in solving the feature selection problem.
The performance superiority demonstrated by the BEOSA and BIEOSA methods in this comparative analysis for this subsection reinforced the argument that the proposed method is suitable for solving the feature selection problem. This finding is supported by the fact the minimal and optimal number of features selected by the BEOSA and BIEOSA methods were sufficient and determinant enough to yield the best classification accuracy. In the following subsection, we investigate the impact of varying the choice of a classifier and whether this choice influences the performance of the binary optimizer method.
5.4. Performance Evaluation of State-of-the-Art Classifiers on Methods
The classification accuracy analysis applied for the comparative analysis discussed in the previous subsection uses the KNN method. This subsection presents our investigation regarding whether using a different classifier from the list of existing state-of-the-art classifiers would improve the classification accuracy of the optimizers.
Table 6 lists the comparative analysis of the influence of different classifiers is presented using the M-of-n dataset as a sample solution. The KNN, random forest (RF), MLP, decision tree (DTree), SVM, and Gaussian naïve Bayes (GNB) classifiers were compared using the accuracy, precision, recall, F1-score and area under curve (AUC) metrics.
The classification accuracy for KNN, RF, MLP, DTree, SVM, and GNB classifiers for BEOSA and BIEOSA were 0.815, 0.835, 0.84, 0.795, 0.845, and 0.83, 0.935, 0.665, 0.67, 0.67, 0.67, and 0.67 respectively. Results showed that the SVM and KNN worked well for the BEOSA and BIEOSA by obtaining classification accuracy of 0.845 and 0.935 for the SVM and KNN respectively. The most competing method, the BPSO algorithm, showed that the MLP and SVM classifiers are more suitable for obtaining better classification accuracy when compared with other classifiers. For precision-recall, F1-score and AUC, the values of 0.875, 1, 0.933333, and 0.993132 were obtained for the BEOSA, while the values of 1, 0.866667, 0.928571, and 1 were obtained for BIEOSA using the SVM and KNN classifiers respectively. This result confirms that when a classifier produces a good classification result on a binary optimizer, that classifier has a tendency to improve the results of the precision, recall, F1-score and area under curve (AUC) metrics as well.
To provide a broader view of the performance of the KNN, RF, MLP, DT, SVM and GNB classifiers with population sizes of 25, 50, 75 and 100, we plotted graphs to show how the BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA algorithms performed.
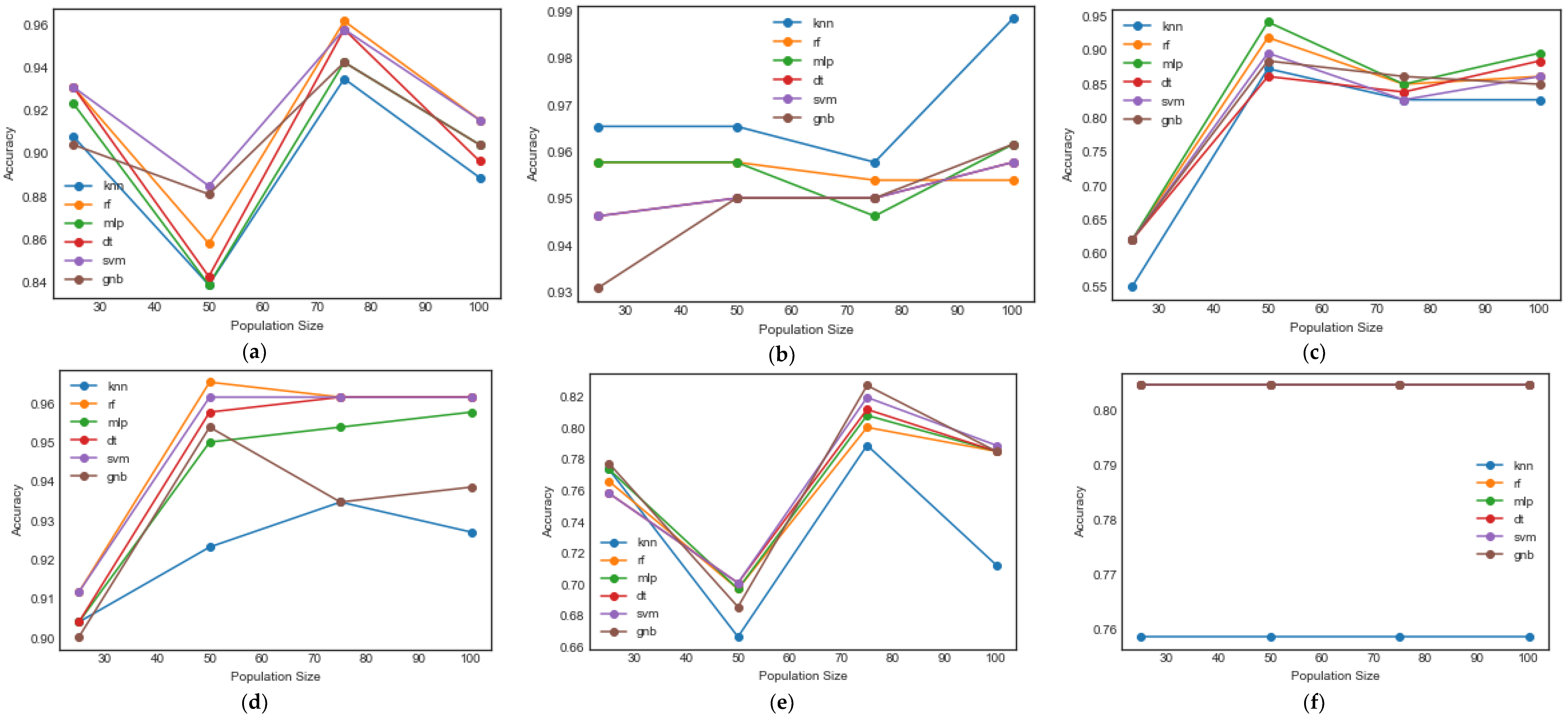
Figure 8 shows the results of the comparisons carried out using the CongressEW dataset as a sample. The BWOA algorithm performed well with SVM, BPSO performed well with KNN, BFSO performed well with MLP, BGWO performed well with RF, BDMO performed well with GNB, BSNDO performed well with GNB, SVM, MLP and RF, BEOSA performed well with KNN and BIEOSA performed well with SVM. These performance differences are a strong indication that research on the use of a binary optimizer to solve feature selection must not be limited to the performance of the optimizer alone, but rather, that efforts must be made to select a fitting classifier as well. Interestingly, we found that KNN and SVM, which are known to work well with most classification tasks, showed good performance with the proposed BEOSA and BIEOSA methods.
The experimental results for the five classifiers using the CongressEW dataset with the BWOA algorithm showed that the classification accuracies of GNB and KNN were around 0.90 for a population size of 25, rising to a peak at 0.94 and 0.93 with a population size of 75. RF and SVM yielded the same value, i.e., 0.93, with a population size of 25 but peaked at around 0.96 with a population size of 75. In the middle of the curves is MLP curve, which has its peak classification value at 0.94 with a population size of 75; its lowest reported value was 0.84, with a population size of 50. With BFSO and BGWO, KNN, RF, MLP, DT, SVM and GNB achieved classification accuracies of 0.86, 0.92, 0.94, 0.86, 0.89, and 0.88 with a population size 50, and 0.935, 0.968, 0.949, 0.956, 0.962 and 0.953 with a population size of 50. In contrast, KNN achieved the best performance with a population size of 75. The graph plots for BDMO and BIEOSA demonstrate another interesting aspect of their performance, i.e., all classifiers in each case peaked and deepened with a population size of 50. For instance, for BDMO, all the classifiers peaked with a population size of 75 with classification accuracies 0.781, 0.80, 0.801, 0.822 and 0.82 for KNN, RF, MLP, DT, SVM and GNB, resprectively. BIEOSA yielded the best classification accuracies for all classifiers with a population size of 25, showing values just above 0.925 for KNN, around 0.950 for MLP, DT and SVM, and around 0.975 for RF and GNB. BSNDO obtained curves running consistently at 0.805 for RF, MLP, DT, SVM and GNB, but obtained approximately 0.76 for all population sizes using the KNN classifier. With BPSO and BEOSA, KNN peaked with a population size of 100 and 75 at 0.989 and 0.0650 accuracies, while GNB peaked at 0.95 and around 0.9540 with a population size of 50 for BPSO and BEOSA. SVM obtained its peak performance at values of 0.959 and 0.9575 on BPSO and BEOSA with population sizes of 100 and 50. With BPSO and BEOSA, MLP peaked with population sizes of 100 and 75 at 0.96 and around 0.9525, while RF peaked at 0.959 and 0.9575 with population sizes of 50 and 75 for BPSO and BEOSA. DT peaked with a similar accuracy to that reported for GNB.
Figure 9 shows the performance of the BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA algorithms with the SpectEW dataset, providing the classification accuracies of the KNN, RF, MLP, DT, SVM, and GNB classifiers. From the plots shown in the figure, it can be seen that the best classification accuracies were obtained with population sizes of 25, 50, 75, and 100 for BWOA, BPSO, BSFO, BGWO, BDMO, BSNDO, BEOSA and BIEOSA using SVM, KNN, SVM (also DT and KNN), MLP, RF, KNN, KNN and RF. The result also showed that for BPSO, BSFO and BIEOSA, the best performance of their respective classifiers was obtained with a population size of 100. In contrast, BSFO, BDMO, BSNDO and BEOSA obtained their best classification accuracy with a population size of 25 using their respective classifiers. We note that BSFO and BGWO also performed well with a population size of 75, while BWOA did well with a population size of 50.
The performance of BWOA with the SpectEW dataset showed that most classifiers achieved their peak accuracies with a population size of 50, except for GNB, which obtained its best output with a population size of 100, albeit at a much lower value of 0.64. Meanwhile, KNN, RF, MLP, DT and SVM obtained values of 0.87, 0.84, 0.84, 0.79 and 0.89, respectively. BPSO showed an interesting result when a population size of 50 was used, with all classifiers converging at a classification accuracy of 0.79 as their lowest values. Interestingly, their best accuracies also occurred with a population size of 100, with KNN yielding 0.89, RF 0.83, MLP 0.84, DT 0.80, SVM0.79 and GNB 0.73. The BSFO algorithm is unique, as it showed reccurring overlap with most of the classifiers, as can be seen with GNB and DT, whose maximum accuracy values were 0.75 with a population size of 75, while others also peaked at that point but with a classification accuracy of 0.8. Meanwhile, differentiated classification accuracies were observed for all classifiers when using the BGWO algorithm. The RF and GNB classifiers obtained their best performance with a population size of 50, i.e., 0.83 and 0.7. SVM, KNN, DT and MLP obtained their best accuracies, i.e., 0.82, 0.81, 0.79 and 0.88, with a population size of 75. For BDMO and BSNDO, KNN, RF, MLP, DT, SVM and GNB achieved their best performance as follows: 0.71 with a population size of 75; 0.82 with a population size of 25; 0.8 with a population size of 50; 0.86 with a population size of 25; and 0.53 with a population size of 75. The other algorithms yielded 0.83 with a population size of 75, 0.85 with a population size of 25 and 0.80 with a population size of 50 for KNN, RF, MLP, DT, SVM and GNB. We compared BEOSA and BIEOSA and found a large degree of variance. For instance, whereas KNN obtained its best value, i.e., 0.83, with a population size of 75 with BEOSA, for BIEOSA, the same classifier yielded a value of 0.98 with a population size of 25. Additionally, RF peaked at 0.85 with a population size of 100 and 0.89 with a population size of 25 in BEOSA and BIEOSA. MLP obtained its best values, i.e., 0.85 and 0.89, with a population size of 25 on BEOSA and BIEOSA, respectively. DT dipped in BIEOSA at an accuracy value of 0.78 with a population size of 100, but peaked in BEOSA with an accuracy of 0.85 with a population size of 25. SVM showed a good performance with BIEOSA, achieving an accuracy of 0.89 with a population size of 25, whereas with BEOSA, it achieved its best value, i.e., 0.80, with all population sizes. GNB performed better on BEOSA, with an accuracy of 0.85 with a population size of 25, but obtained 0.79 on BIEOSA with a population size of 100.
A comparative analysis of the plots of the CongressEW and SpectEW datasets showed that the performance of BEOSA on all of the classifiers was outstanding, standing shoulder-to-shoulder with BPSO and significantly outperforming BWOA, BSFO, BGWO, BSNDO, and BDMO. We note that the proposed method proved itself to be well-rounded and robust. Moreover, the good classification performance, derived from the number of features selected by the BEOSA, further confirms the applicability of the method to find the best number of required features, even in real-life problems. Additionally, the fitness function and cost function values were impressive for BEOSA and its variant BIEOSA.
The experiment using different classifiers in this study has shown that the choice of a classifier with a binary optimizer must be made carefully based on empirical investigation when such hybrid models are being deployed to address real-life problems. Having compared the performance of BEOSA with other related methods using the values obtained for fitness and cost functions, the average number of selected features and classification accuracy, in the following subsection, we compare the computational runtime required for each of the algorithms.
5.5. Computational Time Analysis
Computational resources, especially computational time, often play a pivotal role in the choice of an algorithm in time constrained applications. However, in cases where computational time is not a constraint, the selection of an algorithm is often based purely on performance. This subsection compares the computational time obtained for the binary optimizers considered in this study.
Table 7 outlines the performance of all the algorithms with respect to each of the applied benchmark datasets.
The computational time of BSNDO was abnormally distributed. However, we found that BWOA showed reduced computational time for the BreastEW, CongressEW, Exactly, Iris, Exactly2, Ionosphere, Sonar, SpectEW, Tic-tac-toe, Vote, Wine, Zoo and KrVsKpEW datasets. BSPO performed best on the Lymphography dataset, while BDMO reported a reasonable computational time with the HeartEW and M-of-n datasets. The proposed method, BEOSA, demonstrated minimal computational time with the Leukemia and Colon datasets.
Figure 10 shows a graphical illustration of the distribution of the computational time for each dataset with respect to all of the tested binary optimization methods. The figure shows that with most binary optimizer algorithms, BSFO often demanded the most computation time, followed by BDMO and then BIEOSA. BSNDO and BGWO were shown to require less computation runtime. The implication of this is that the proposed BEOSA algorithm achieved outstanding performance with an average computational time compared with those of the other binary optimizers.
5.6. Discussion of Findings
As corroborated by the obtained results and discussed in detail in previous sub-sections, this study may conclude that the proposed BEOSA method demonstrated very promising performance on all benchmark datasets. We have shown that this method produced the optimal average number of selected features on each of the tested datasets. Furthermore, we discovered that the popular classifiers KNN, MLP, SVM, GNB and RF were relevant in terms of supporting the performance of binary optimizers. This motivates designers of binary optimizers to investigate which state-of-the-art classifier is suitable for supporting particular wrapper-based feature selection and classification tasks. Moreover, when a classifier impedes the performance of a binary optimizer, it diminishes the importance of using the algorithm for optimization purposes. Hence, deploying such binary optimizers to real problems must be accompanied by the selection of an appropriate classifier. The average numbers of feature selected for all datasets using the proposed BEOSA demonstrated that the algorithm is suitable for maximizing the cost function and minimizing the fitness function. Our findings also confirm that the novel method used for applying the S-functions and V-functions enhanced the performance of the proposed method.
Research on the optimization of the number of selected features for classification operations is aimed at obtaining the best optimizer. It is expected that such an optimizer will advance research in the field by ensuring that while classification accuracy is maximized, the number of features must be as low as possible. This demonstrates the increasing need for new algorithms which are capable of solving this multi-objective function. The algorithm proposed in this study satisfies this condition, since the two objectives were achieved. Moreover, we noted that BEOSA also improved the fitness and cost function values; these functions are pivotal when justifying the relevance of a binary optimizer in terms of selecting the optimal number of features required to obtain the best classification result. Furthermore, this study provides a wealth of experimental results, i.e., comparisons of the performance of different classifiers with several binary optimizers. We found this to be very rare in the literature and, as such, we hope that our work will benefit the community of researchers in the field.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}