
High-Accuracy Insulator Defect Detection for Overhead Transmission Lines Based on Improved YOLOv5


Abstract
:1. Introduction
2. Materials and Methods
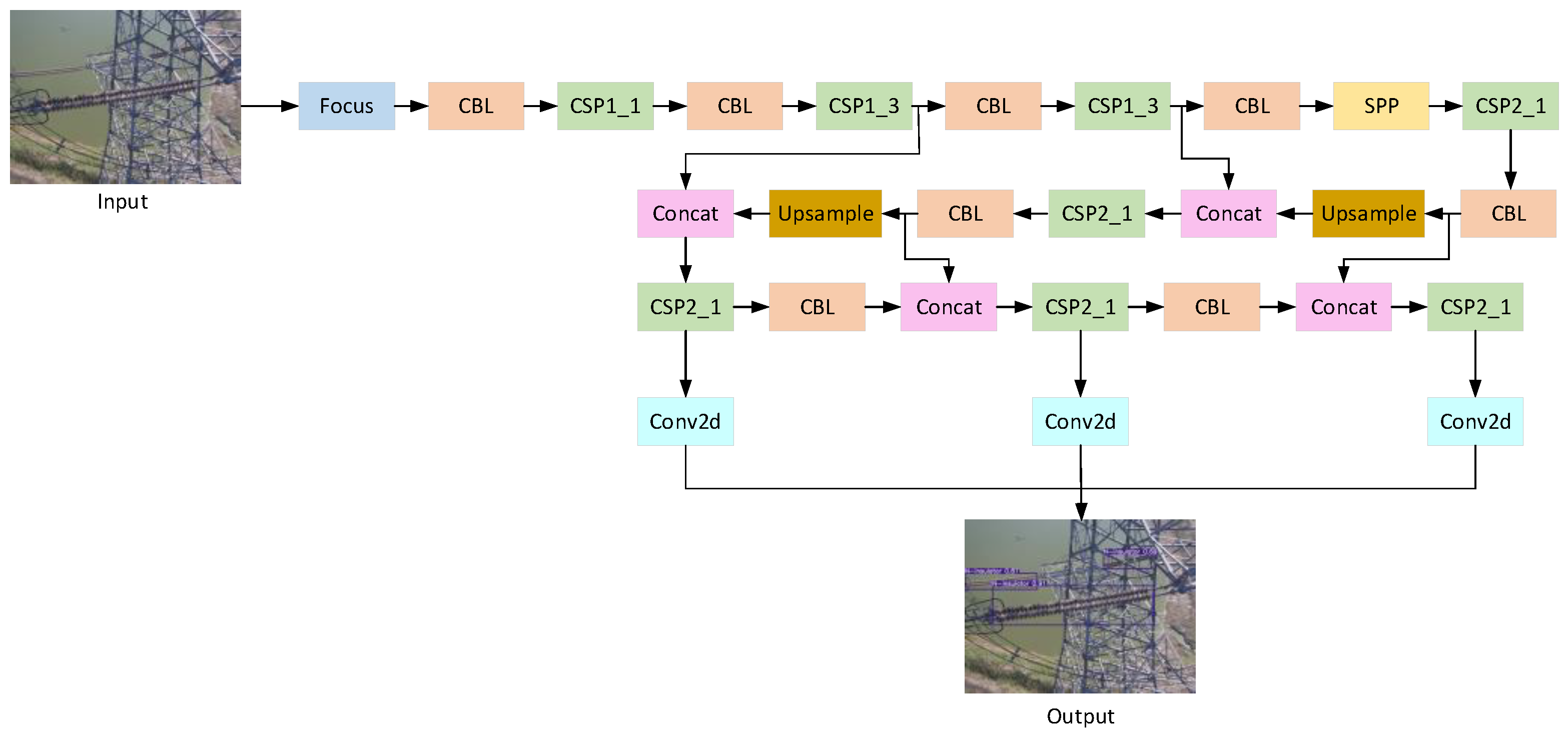
2.1. Original YOLOv5 Algorithm
2.2. Improved YOLOv5 Algorithm
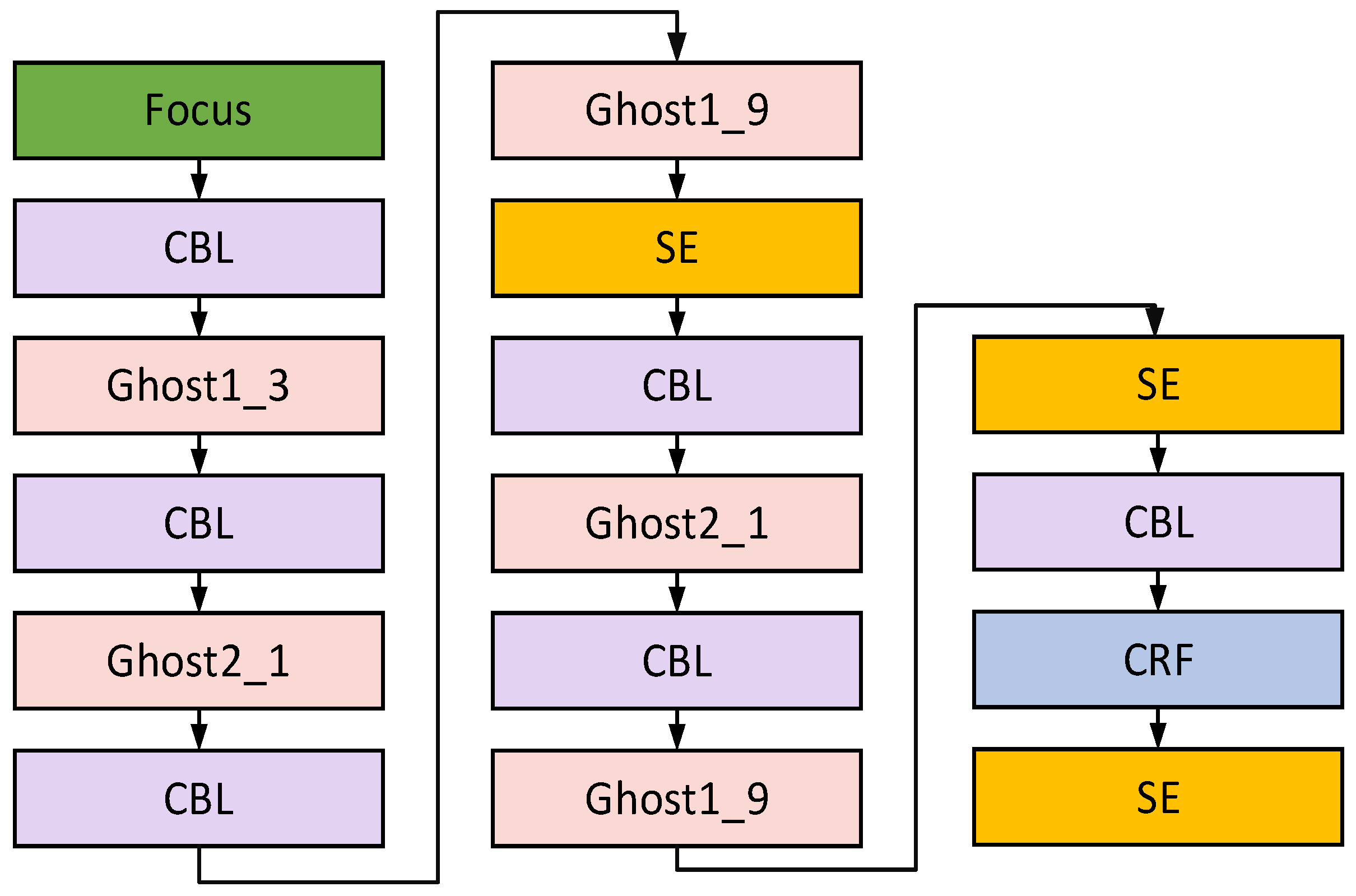
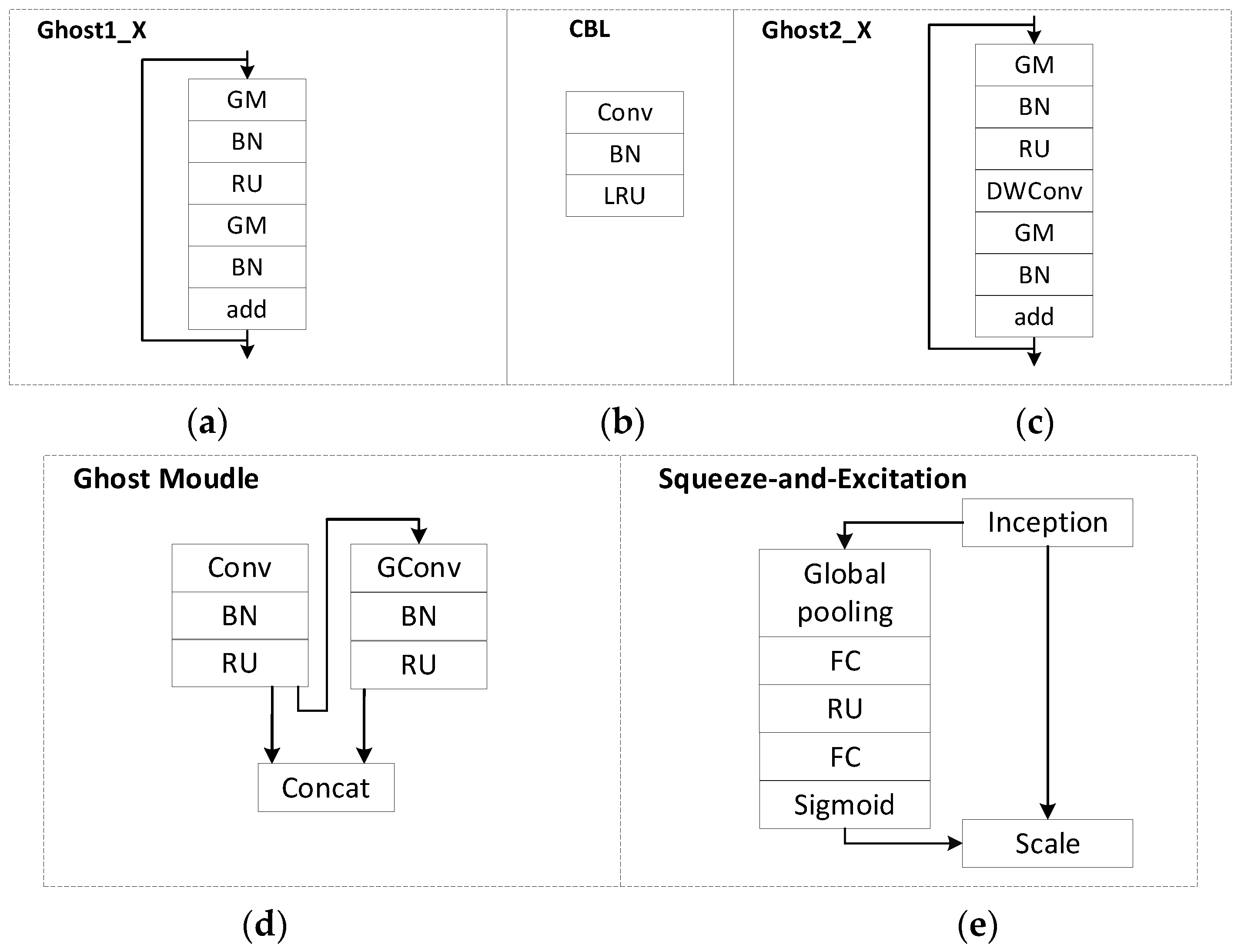
2.2.1. Backbone Network
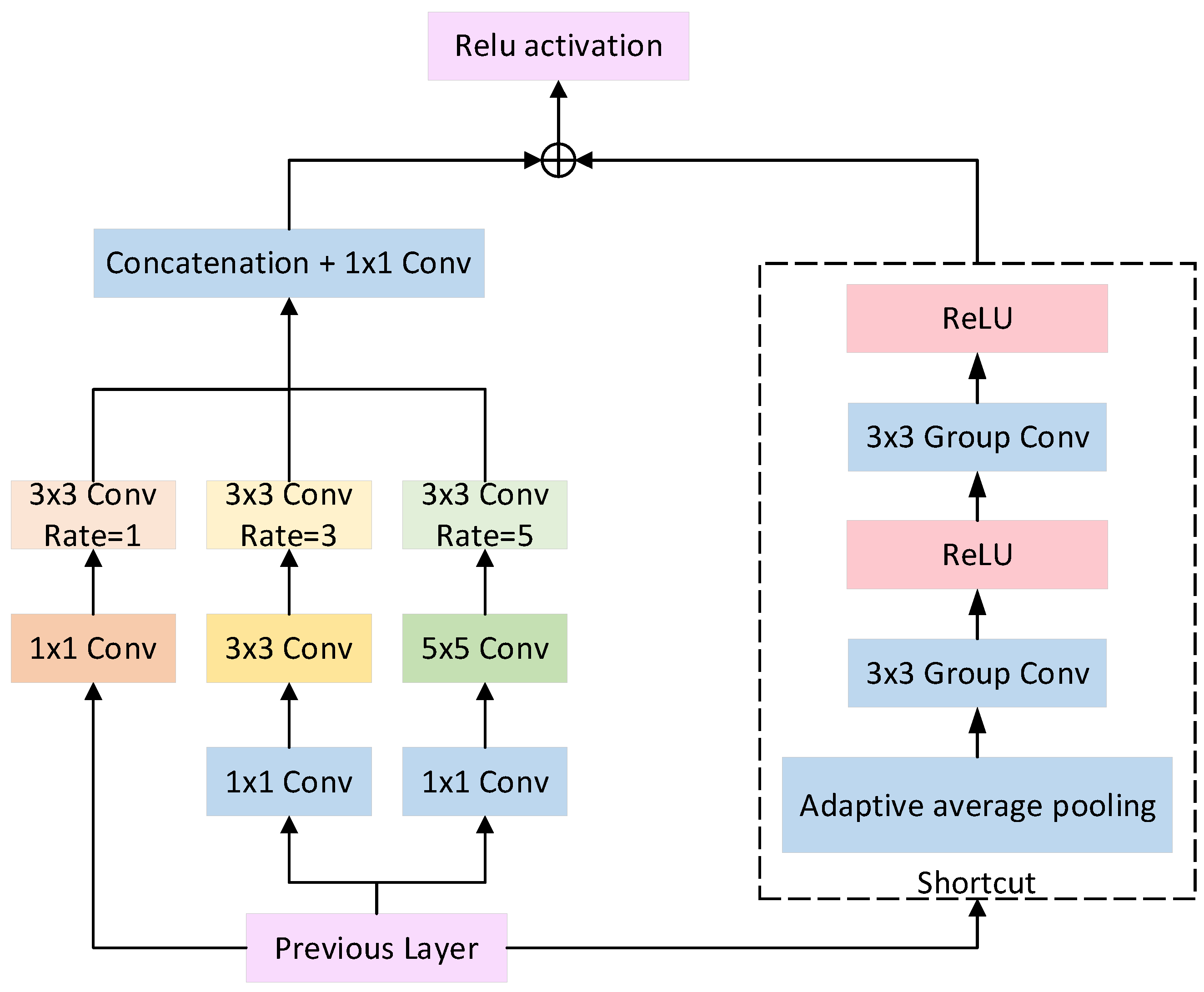
2.2.2. CRF Receptive Field Module
2.2.3. Multiscale Detection Layer
3. Experiment and Dataset
3.1. Experiment Setting
3.2. Experimental Datasets
3.3. Evaluating Indicator
4. Discussion
4.1. Comparison of Different Receptive Field Modules
4.2. Ablation Experiment
4.3. Contrast Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, H.; Liu, Y.; Sun, Y.; Li, J.; Shi, Z.; Zhang, C.; Lai, C.S.; Lai, L.L. Arbitrary-Oriented Detection of Insulators in Thermal Imagery via Rotation Region Network. IEEE Trans. Ind. Inform. 2022, 18, 5242–5252. [Google Scholar] [CrossRef]
- Zhao, Y.; Yan, J.; Wang, Y.; Jing, Q.; Liu, T. Porcelain Insulator Crack Location and Surface States Pattern Recognition Based on Hyperspectral Technology. Entropy 2021, 23, 486. [Google Scholar] [CrossRef] [PubMed]
- Pathak, D.; Satwani, M.; Patel, M.; Patel, C. The development of silicone rubber composite insulators in power system. In Proceedings of the 2009 International Conference on Control, Automation, Communication and Energy Conservation, Perundurai, India, 4–6 June 2009; pp. 1–4. [Google Scholar]
- Gao, S.; Jia, J.; Huang, X.; Liu, Y.; Zhang, B.; Zhang, Y.; Geng, J. Research on Electric Field Detection of Degraded Insulators Based on a Sensitive Detection Method under Complex Operating Conditions. Appl. Sci. 2022, 12, 5680. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, Z.; Shi, S.; Rui, E. Design of Porcelain Insulator Defect Recognition System Based on UAV Line Inspection Image. In 6GN for Future Wireless Networks; Springer: Cham, Switzerland, 2022; Volume 5, pp. 397–408. [Google Scholar] [CrossRef]
- Liu, X.; Miao, X.; Jiang, H.; Chen, J. Data analysis in visual power line inspection: An in-depth review of deep learning for component detection and fault diagnosis. Annu. Rev. Control. 2020, 50, 253–277. [Google Scholar] [CrossRef]
- Zheng, Y.; Hao, Y.; Liu, L.; Zhang, Z.; Yang, L.; Wang, G.; Gao, C.; Zhou, F. An Ultrasonic Nondestructive Testing Method for Density Uniformity of Basin-Type Insulators in GIS. IEEE Trans. Instrum. Meas. 2021, 70, 6010308. [Google Scholar] [CrossRef]
- Li, Z.; Song, Y.; Li, R.; Gu, S.; Fan, X. A Novel Data Augmentation Method for Improving the Accuracy of Insulator Health Diagnosis. Sensors 2022, 22, 8187. [Google Scholar] [CrossRef]
- Chen, Z.; Xiao, Y.; Zhou, Y.; Li, Z.; Liu, Y. Insulator Recognition Method for Distribution Network Overhead Transmission Lines Based on Modified YOLOv3. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 2815–2820. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Liu, Y.; Li, E.; Peng, J.; Liang, Z. A Review on State-of-the-Art Power Line Inspection Techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Zhai, Y.; Chen, R.; Yang, Q.; Li, X.; Zhao, Z. Insulator Fault Detection Based on Spatial Morphological Features of Aerial Images. IEEE Access 2018, 6, 35316–35326. [Google Scholar] [CrossRef]
- Vijayalakshmi, N.; Sindhu, S.; Suriya, S. Automatic Vehicle Number Recognition System using Character Segmentation and Morphological algorithm. In Proceedings of the 2020 IEEE International Conference on Advances and Developments in Electrical and Electronics Engineering (ICADEE), Coimbatore, India, 10–11 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Wu, Q.; An, J.; Lin, B. A Texture Segmentation Algorithm Based on PCA and Global Minimization Active Contour Model for Aerial Insulator Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1509–1518. [Google Scholar] [CrossRef]
- Wu, Q.; An, J. An Active Contour Model Based on Texture Distribution for Extracting Inhomogeneous Insulators from Aerial Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3613–3626. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, Z.; Han, Y. Automatic recognition for catenary insulators of high-Speed railway based on contourlet transform and Chan–Vese model. Optik 2016, 127, 215–221. [Google Scholar] [CrossRef]
- Yu, Y.; Cao, H.; Wang, Z.; Li, Y.; Li, K.; Xie, S. Texture-and-Shape Based Active Contour Model for Insulator Segmentation. IEEE Access 2019, 7, 78706–78714. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, J.; Li, B. ARG-Mask RCNN: An Infrared Insulator Fault-Detection Network Based on Improved Mask RCNN. Sensor 2022, 22, 4720. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Hu, H.; Liu, Y.; Rong, H. Detection of Insulators on Power Transmission Line Based on an Improved Faster Region-Convolutional Neural Network. Algorithms 2022, 15, 83. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Bao, W.; Du, X.; Wang, N.; Yuan, M.; Yang, X. A Defect Detection Method Based on BC-YOLO for Transmission Line Components in UAV Remote Sensing Images. Remote Sens. 2022, 14, 5176. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Zhao, Z. Missing-Sheds Granularity Estimation of Glass Insulators Using Deep Neural Networks Based on Optical Imaging. Sensors 2022, 22, 1737. [Google Scholar] [CrossRef]
- Cao, M.; Fu, H.; Zhu, J.; Cai, C. Lightweight tea bud recognition network integrating GhostNet and YOLOv5. Math. Biosci. Eng. 2022, 19, 12897–12914. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Ultralytics/yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 25 June 2020).
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Zhou, J.; Jiang, P.; Zou, A.; Chen, X.; Hu, W. Ship Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2021, 9, 908. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, X.; Su, Y.; Ti, Y.; Song, T. A_CenterNet: Object as a Point by Attention. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2255011. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Receptive Field Module | N-Insulator | D-Insulator | mAP@50 | ||
|---|---|---|---|---|---|
| P | R | P | R | ||
| SPP | 0.877 | 0.739 | 0.937 | 0.956 | 0.913 |
| RBF | 0.874 | 0.919 | 1 | 0.967 | 0.966 |
| CRF | 0.915 | 0.908 | 0.988 | 1 | 0.974 |
| Method | Ghost Module | Increase of Detection Layer | CRF Receptive Field Module | N-Insulator | D-Insulator | [email protected] | ||
|---|---|---|---|---|---|---|---|---|
| P | R | P | R | |||||
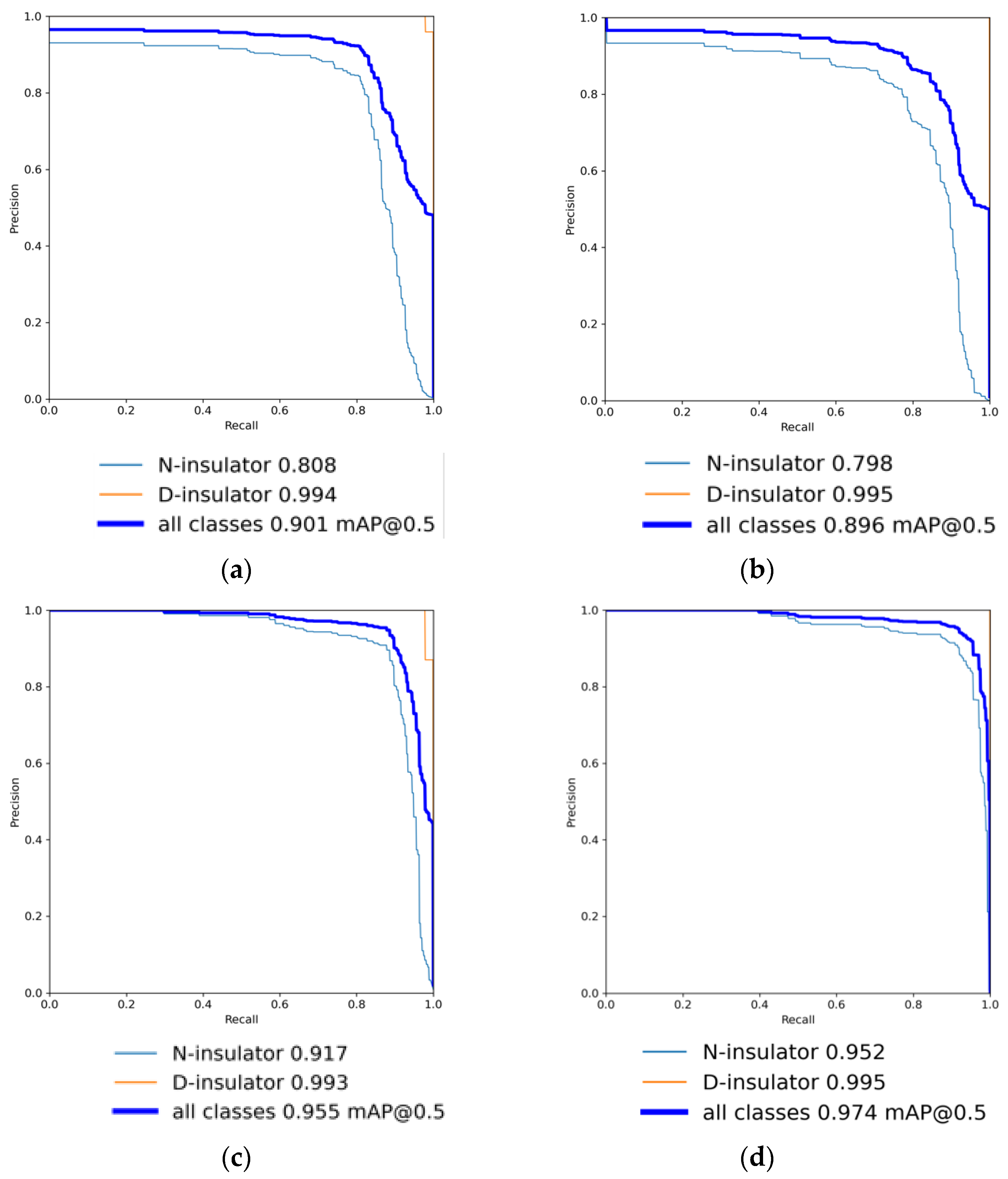
| 1 | × | × | × | 0.845 | 0.805 | 0.933 | 1 | 0.901 |
| 2 | √ | × | × | 0.814 | 0.771 | 0.976 | 1 | 0.896 |
| 3 | √ | √ | × | 0.909 | 0.879 | 0.99 | 0.979 | 0.955 |
| 4 | √ | √ | √ | 0.915 | 0.908 | 0.988 | 1 | 0.974 |
| Module | N-Insulator | D-Insulator | [email protected] | FPS | ||
|---|---|---|---|---|---|---|
| P | R | P | R | |||
| Faster-RCNN | 0.7541 | 0.9459 | 0.4375 | 0.913 | 0.832 | 12 |
| CenterNet | 0.825 | 0.5766 | 1 | 0.1304 | 0.776 | 56 |
| YOLOv5 | 0.845 | 0.805 | 0.933 | 1 | 0.901 | 53 |
| Ours | 0.915 | 0.908 | 0.988 | 1 | 0.974 | 62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Jiang, L.; Han, T.; Xu, S.; Liu, Y.; Fu, J. High-Accuracy Insulator Defect Detection for Overhead Transmission Lines Based on Improved YOLOv5. Appl. Sci. 2022, 12, 12682. https://doi.org/10.3390/app122412682
Huang Y, Jiang L, Han T, Xu S, Liu Y, Fu J. High-Accuracy Insulator Defect Detection for Overhead Transmission Lines Based on Improved YOLOv5. Applied Sciences. 2022; 12(24):12682. https://doi.org/10.3390/app122412682
Chicago/Turabian StyleHuang, Yourui, Lingya Jiang, Tao Han, Shanyong Xu, Yuwen Liu, and Jiahao Fu. 2022. "High-Accuracy Insulator Defect Detection for Overhead Transmission Lines Based on Improved YOLOv5" Applied Sciences 12, no. 24: 12682. https://doi.org/10.3390/app122412682
APA StyleHuang, Y., Jiang, L., Han, T., Xu, S., Liu, Y., & Fu, J. (2022). High-Accuracy Insulator Defect Detection for Overhead Transmission Lines Based on Improved YOLOv5. Applied Sciences, 12(24), 12682. https://doi.org/10.3390/app122412682