
2D Winograd CNN Chip for COVID-19 and Pneumonia Detection


Abstract
:1. Introduction
1.1. Background
1.2. Research Goal
2. Materials and Methods
2.1. Materials
Test Data
2.2. Methods
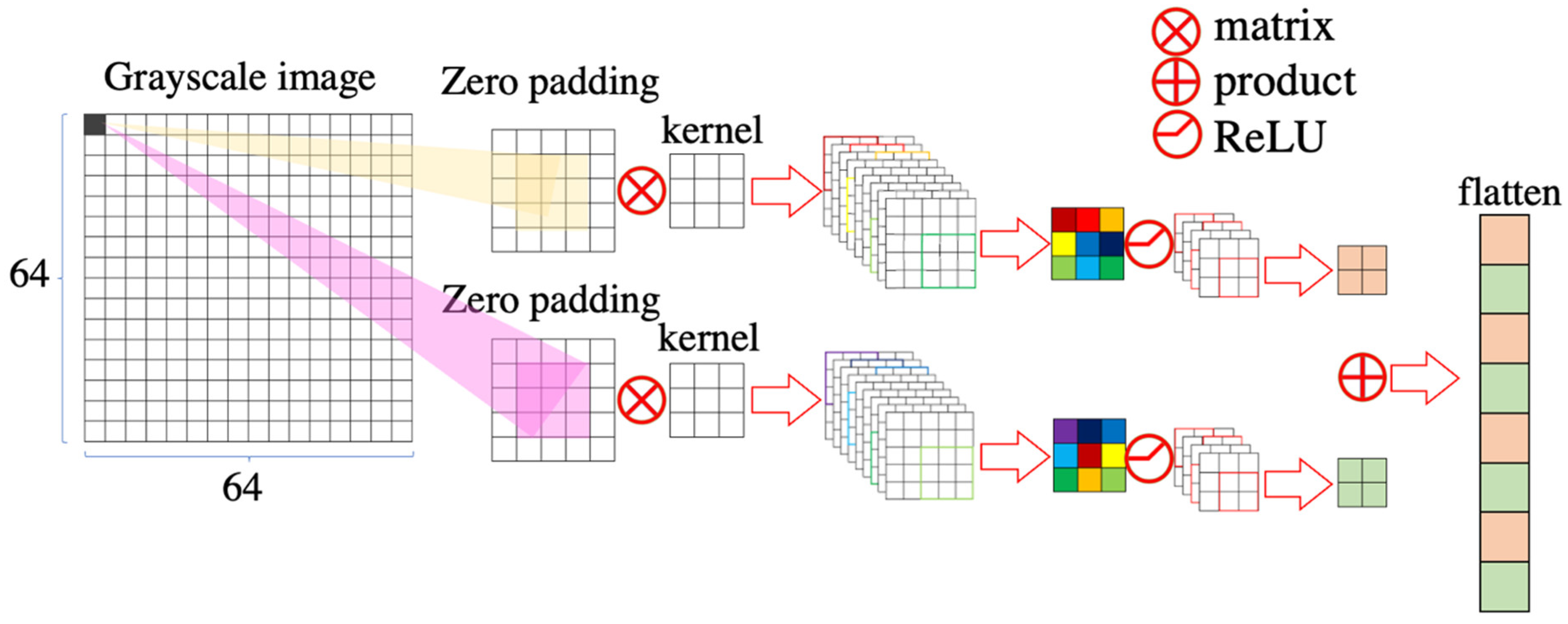
2.2.1. Design Chip of CNN
2.2.2. Enhance Convolutional Calculated Speed
2.2.3. Authentication Method
2.2.4. Automatic Layout and Routing
2.2.5. Model Selection
3. Results
3.1. Specification
3.2. Waveform
3.3. Curve of Model
4. Discussion
4.1. Calculating Time
4.2. Model Analysis
4.3. Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Male, V. SARS-CoV-2 infection and COVID-19 vaccination in pregnancy. Nat. Rev. Immunol. 2022, 22, 277–282. [Google Scholar] [CrossRef]
- Boni, M.F.; Lemey, P.; Jiang, X.; Lam, T.T.; Perry, B.W.; Castoe, T.A.; Rambaut, A.; Robertson, D.L. Evolutionary origins of the SARS-CoV-2 sarbecovirus lineage responsible for the COVID-19 pandemic. Nat. Microbiol. 2020, 5, 1408–1417. [Google Scholar] [CrossRef] [PubMed]
- Zhan, C.; Tse, C.K.; Gao, Y.; Hao, T. Comparative Study of COVID-19 Pandemic Progressions in 175 Regions in Australia, Canada, Italy, Japan, Spain, U.K. and USA Using a Novel Model That Considers Testing Capacity and Deficiency in Confirming Infected Cases. IEEE J. Biomed. Health Inform. 2021, 25, 2836–2847. [Google Scholar] [CrossRef]
- Regmi, S.; Malla, K.P.; Adhikari, R. Current scenario of COVID-19 pandemics in the top ten worst-affected countries based on total cases, recovery, and death cases. Appl. Sci. Technol. Ann. 2020, 1, 92–97. [Google Scholar] [CrossRef]
- Sitaula, C.; Basnet, A.; Mainali, A.; Shahi, T.B. Deep Learning-Based Methods for Sentiment Analysis on Nepali COVID-19-Related Tweets. Comput. Intell. Neurosci. 2021, 2021, 2158184. [Google Scholar] [CrossRef]
- Nishio, M.; Noguchi, S.; Matsuo, H.; Murakami, T. Automatic classification between COVID-19 pneumonia, non-COVID-19 pneumonia, and the healthy on chest X-ray image: Combination of data augmentation methods. Sci Rep. 2020, 10, 17532. [Google Scholar] [CrossRef]
- Williams, G.D.; Townsend, D.; Wylie, K.M.; Kim, P.J.; Amarasinghe, G.K.; Kutluay, S.B.; Boon, A.C.M. Nucleotide resolution mapping of influenza A virus nucleoprotein-RNA interactions reveals RNA features required for replication. Nat. Commun. 2018, 9, 465. [Google Scholar] [CrossRef] [Green Version]
- Qayyum, A.; Qadir, J.; Bilal, M.; Al-Fuqaha, A. Secure and robust machine learning for healthcare: A survey. IEEE Rev. Biomed. Eng. 2021, 14, 156–180. [Google Scholar] [CrossRef]
- Gabriella, I.; Kamarga, S.A.; Setiawan, A.W. Early Detection of Tuberculosis Using Chest X-Ray (CXR) with Computer-Aided Diagnosis. In Proceedings of the 2018 2nd International Conference on Biomedical Engineering, Shanghai, China, 6–8 July 2018; pp. 76–79. [Google Scholar]
- Sitaula, C.; Hossain, M.B. Attention-based VGG-16 model for COVID-19 chest X-ray image classification. Appl. Intell. 2020, 51, 2850–2863. [Google Scholar] [CrossRef]
- Kalaiselvi, S.M.P.; Tang, E.X.; Moser, H.O.; Breese, M.B.H.; Turaga, S.P.; Kasi, H.; Heussler, S.P. Wafer scale manufacturing of high precision micro-optical components through X-ray lithography yielding 1800 Gray Levels in a fingertip sized chip. Sci. Rep. 2022, 12, 2730. [Google Scholar] [CrossRef]
- Su, L.; Fu, X.; Zhang, X.; Cheng, X.; Ma, Y.; Gan, Y.; Hu, Q. Delineation of carpal bones from hand X-ray images through prior model, and integration of region-based and boundary-based segmentations. IEEE Access 2018, 6, 19993–20008. [Google Scholar] [CrossRef]
- Cho, H.; Kim, Y.; Lee, E.; Choi, D.; Lee, Y.; Rhee, W. Basic Enhancement Strategies When Using Bayesian Optimization for Hyperparameter Tuning of Deep Neural Networks. IEEE Access 2020, 8, 52588–52608. [Google Scholar] [CrossRef]
- Van Grinsven, M.J.; van Ginneken, B.; Hoyng, C.B.; Theelen, T.; Sánchez, C.I. Fast convolutional neural network training using selective data sampling: Application to hemorrhage detection in color fundus images. IEEE Trans. Med. Imaging 2016, 35, 1273–1284. [Google Scholar] [CrossRef] [PubMed]
- Mehrabian, A.; Miscuglio, M.; Alkabani, Y.; Sorger, V.J.; El-Ghazawi, T. A Winograd-Based Integrated Photonics Accelerator for Convolutional Neural Networks. IEEE J. Sel. Top. Quantum Electron. 2019, 26, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Wang, C.; Cao, J.; Gong, L.; Zhou, X. WinoNN: Optimizing FPGA-Based Convolutional Neural Network Accelerators Using Sparse Winograd Algorithm. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2020, 39, 4290–4302. [Google Scholar] [CrossRef]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.-A. SINet: A Scale-Insensitive Convolutional Neural Network for Fast Vehicle Detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Lavin, A.; Gray, S. Fast Algorithms for Convolutional Neural Networks. arXiv 2015, arXiv:1509.09308. [Google Scholar]
- Yepez, J.; Ko, S.B. Stride 2 1-D, 2-D, and 3-D winograd for convolutional neural networks. IEEE Trans. Very Large Scale Integr. Syst. 2020, 2, 853–863. [Google Scholar] [CrossRef]
- Fan, Y.-C.; Yelamandala, C.M.; Chen, T.-W.; Huang, C.-J. Real-Time Object Detection for LiDAR Based on LS-R-YOLOv4 Neural Network. J. Sensors 2021, 2021, 5576262. [Google Scholar] [CrossRef]
- Lin, K.Y.; Tsai, Y.H.; Fan, Y.C. A Model-Based Convolutional Neural Network for Covid-19 and Related Lung Diseases Prediction with Graphical Interface Operation and Chip Design. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Toseong-myeon, Republic of Korea, 1–3 November 2021; pp. 1–4. [Google Scholar]
- Bashir, I.; Staszewski, R.B.; Eliezer, O.; de-Obaldia, E. Built-in Self Testing (BIST) of RF Performance in a System-on-Chip (SoC). In Proceedings of the 2005 IEEE Dallas/CAS Workshop on Architecture, Circuits and Implementtation of SOCs, Richardson, TX, USA, 10 October 2005; pp. 215–218. [Google Scholar]
- Fan, Y.-C. Testing-Based Watermarking Techniques for Intellectual-Property Identification in SOC Design. IEEE Trans. Instrum. Meas. 2008, 57, 467–479. [Google Scholar]
- Fan, Y.C.; Tsao, H.W. Boundary scan test scheme for IP core identification via watermarking. IEICE Trans. Inf. Syst. 2005, 88, 1397–1400. [Google Scholar] [CrossRef]
- Fan, Y.C.; Shen, J.H. DFT-based SoC/VLSI IP protection and digital rights management platform. IEEE Trans. Instrum. Meas. 2008, 58, 2026–2033. [Google Scholar]
- Chowdhury, M.E.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Al Emadi, N.; et al. Can AI help in screening viral and COVID-19 pneumonia? IEEE Access 2020, 8, 132665–132676. [Google Scholar] [CrossRef]
- Rahman, T.; Khandakar, A.; Qiblawey, Y.; Tahir, A.; Kiranyaz, S.; Kashem, S.B.A.; Islam, M.T.; Al Maadeed, S.; Zughaier, S.M.; Khan, M.S.; et al. Exploring the effect of image enhancement techniques on COVID-19 detection using chest X-ray images. Comput. Biol. Med. 2021, 132, 104319. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; He, Y.; Jiao, H. Efficient Zero-Activation-Skipping for On-Chip Low-Energy CNN Acceleration. In Proceedings of the 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021; pp. 1–4. [Google Scholar]
- Uchida, K.; Tanaka, M.; Okutomi, M. Coupled Convolution Layer for Convolutional Neural Network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3548–3553. [Google Scholar]
- Fan, Y.C.; Wu, B.T.; Huang, C.J.; Bai, Y.H. Environment Detection of 3D LiDAR by Using Neural Networks. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics, IEEE ICCE 2019, Las Vegas, NV, USA, 11–13 January 2019; pp. 1–2. [Google Scholar]
- Cai, K.; Chen, H.; Ai, W.; Miao, X.; Lin, Q.; Feng, Q. Improvement of learning for CNN with ReLU activation by sparse regularization. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2684–2691. [Google Scholar]
- Lin, J.; Ma, L.; Cui, J. A frequency-domain convolutional neural network architecture based on the frequency-domain randomized offset rectified linear unit and frequency-domain chunk max pooling method. IEEE Access 2020, 8, 98126–98155. [Google Scholar] [CrossRef]
- Jin, J.; Dundar, A.; Culurciello, E. Flattened Convolutional Neural Networks for Feedforward Acceleration. arXiv 2015, arXiv:1412.5474. [Google Scholar]
- Sultana, S.; Iqbal, M.Z.; Selim, M.R.; Rashid, M.; Rahman, M.S. Bangla Speech Emotion Recognition and Cross-Lingual Study Using Deep CNN and BLSTM Networks. IEEE Access 2021, 10, 564–578. [Google Scholar] [CrossRef]
- Multicore and Distributed Processing with TetraMAX ATPG. Available online: https://www.synopsys.com/content/dam/synopsys/implementation&signoff/white-papers/TMAX_Multicore_WP.pdf (accessed on 13 December 2022).
- Innovus Implementation System | Cadence. Available online: https://www.cadence.com/en_US/home/tools/digital-design-and-signoff/soc-implementation-and-floorplanning/innovus-implementation-system.html (accessed on 13 December 2022).
- NanoSim® User Guide. Available online: https://picture.iczhiku.com/resource/eetop/ShkGZkQIGqFWtCvn.pdf (accessed on 13 December 2022).
- Hattikatti, P. Bangla Speech Emotion Recognition and Cross-Lingual Study Using Deep CNN and BLSTM Networks. In Proceedings of the 2017 International Conference on Big Data, IoT and Data Science (BID), Pune, India, 20–22 December 2017; pp. 20–22. [Google Scholar]
- Da Nóbrega, R.V.M.; Peixoto, S.A.; da Silva, S.P.P.; Rebouças Filho, P.P. Lung Nodule Classification via Deep Transfer Learning in CT Lung Images. In Proceedings of the 2018 IEEE 31st International Symposium on Computer-Based Medical Systems (CBMS), Karlstad, Sweden, 18–21 June 2018; pp. 244–249. [Google Scholar]
- Singh, K.K.; Singh, A. Diagnosis of COVID-19 from chest X-ray images using wavelets-based depthwise convolution network. Big Data Min. Anal. 2021, 4, 84–93. [Google Scholar] [CrossRef]
- Panthakkan, A.; Anzar, S.M.; Al Mansoori, S.; Al Ahmad, H. Accurate prediction of covid-19 (+) using ai deep vgg16 model. In Proceedings of the 2020 3rd International Conference on Signal Processing and Information Security (ICSPIS), Virtual, 25–26 November 2020; Volume 4, pp. 1–4. [Google Scholar]
- Li, C.; Zhan, G.; Li, Z. News Text Classification Based on Improved Bi-LSTM-CNN. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 890–893. [Google Scholar]
- Yang, S.; Yu, X.; Zhou, Y. LSTM and GRU Neural Network Performance Comparison Study: Taking Yelp Review Dataset as an Example. In Proceedings of the 2020 International Workshop on Electronic Communication and Artificial Intelligence (IWECAI), Shanghai, China, 1–4 June 2020; pp. 98–101. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. arXiv 2017, arXiv:1506.01186. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Shi, F.; Xia, L.; Shan, F.; Song, B.; Wu, D.; Wei, Y.; Yuan, H.; Jiang, H.; He, Y.; Gao, Y.; et al. Large-scale screening to distinguish between COVID-19 and community-acquired pneumonia using infection size-aware classification. Phys. Med. Biol. 2021, 66, 65031. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Lin, Z.Q.; Wong, A. Covid-net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci. Rep. 2020, 10, 19549. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Basic CNN | Winograd CNN | Winograd Pre-Sim | Winograd Post-Sim |
|---|---|---|---|---|
| Technology | TSMC 1P6M 0.18 μm | TSMC 1P6M 0.18 μm | TSMC 1P6M 0.18 μm | TSMC 1P6M 0.18 μm |
| Chip Size | ||||
| Core Size | ||||
| Package | CQFP144 | CQFP144 | CQFP144 | CQFP144 |
| Gate Count | 17,502 | 90,236 | 83,787 | 84,426 |
| Max Frequency | 100 MHz | 100 MHz | 100 MHz | 100 MHz |
| Fault Coverage | 99.54% | 99.90% | 99.90% | 99.90% |
| Power Supply | 1.62 V | 1.62 V | 1.62 V | 1.62 V |
| Power Consumption | 72.48 mW@100 MHz | 211.12 mW@100 MHz | 170.9 mW@100 MHz | 221.8 mW@100 MHz |
| Calculating Time | 2.937 ms | 1.734 ms | None | None |
| Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Proposed | 87.87% | 88.48% | 86.67% | 87.37% |
| Bi-LSTM | 81.83% | 80.52% | 79.08% | 79.57% |
| GRU | 82.84% | 80.99% | 82.39% | 81.55% |
| VGG16 | 85.49% | 84.56% | 84.21% | 84.17% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Y.-C.; Lin, K.-Y.; Tsai, Y.-H. 2D Winograd CNN Chip for COVID-19 and Pneumonia Detection. Appl. Sci. 2022, 12, 12891. https://doi.org/10.3390/app122412891
Fan Y-C, Lin K-Y, Tsai Y-H. 2D Winograd CNN Chip for COVID-19 and Pneumonia Detection. Applied Sciences. 2022; 12(24):12891. https://doi.org/10.3390/app122412891
Chicago/Turabian StyleFan, Yu-Cheng, Kun-Yao Lin, and Yen-Hsun Tsai. 2022. "2D Winograd CNN Chip for COVID-19 and Pneumonia Detection" Applied Sciences 12, no. 24: 12891. https://doi.org/10.3390/app122412891
APA StyleFan, Y. -C., Lin, K. -Y., & Tsai, Y. -H. (2022). 2D Winograd CNN Chip for COVID-19 and Pneumonia Detection. Applied Sciences, 12(24), 12891. https://doi.org/10.3390/app122412891