1. Introduction
In recent years, with the development of wireless communication and intelligent vehicle technology, the on-board network has attracted extensive attention from the industry and academia [
1,
2,
3,
4]. Vehicle to everything (V2X) includes vehicle to vehicle (V2V), vehicle to infrastructure (V2I), vehicle to pedestrian (V2P) and vehicle to network (V2N). The third generation partnership project (3GPP) already supports V2X services in long term evolution (LTE) and fifth generation mobile communication technology (5G) networks; through the wireless communication network formed by the vehicle and various nodes, real-time information such as driving assistance and accident avoidance can be transmitted, and data services such as on-board entertainment, real-time navigation and Internet access can be provided to provide people with a safer, more efficient, environmentally friendly and comfortable driving environment. Spectrum resources are limited natural resources. With the wide application of various radio technologies and services, the demand for spectrum resources in various industries and fields of the national economy keeps increasing. The development of new generation of information technologies such as mobile Internet and Internet of Things also puts forward new demands for spectrum resources. Therefore, spectrum resources are increasingly scarce and are wasted if not fully utilized or used improperly. The rational allocation of spectrum is the key to achieving high quality vehicle network communication. With the rapid and widespread development of advanced broadband wireless technologies and the increasing demand for high speed and quality services, traditional static spectrum allocation policies are becoming obsolete. Dynamic spectrum sharing, as one of the key technologies to solve the problem of insufficient spectrum utilization, has received a lot of attention and research in recent years [
5] to alleviate the current situation of insufficient spectrum resource utilization. The main goal of dynamic spectrum allocation is to design a flexible spectrum allocation strategy between existing users and new users without compromising the utilization of spectrum resources by existing users, so as to effectively allocate the idle spectrum to new users, so as to improve the efficiency of spectrum utilization [
6]. However, with the continuous expansion of the application scope of the Internet of vehicles and the improved communication performance requirements in the network, it is necessary to design an effective spectrum resource allocation scheme to ensure the Internet of vehicles communication services with high reliability and low delay.
Vehicle nodes in vehicle-mounted networks have high mobility and complex time-varying characteristics. It is very challenging to provide high-quality services for vehicles, such as super-large capacity, ultra-high reliability and low delay. In order to solve these problems, it is necessary to provide an efficient spectrum resource allocation method for vehicles in V2X scenarios. The authors in [
7] propose a spectrum resource allocation scheme that can adapt to the slow-changing large-scale channel fading, and maximizes the capacity of V2I by using the slow-fading statistical characteristics of channel status information (CSI). In [
8], quality of service (QoS) requirements for different connections are different. Under the condition of ensuring V2V link reliability and waiting time constraints, the total traversal capacity of the V2I link is maximized to reduce network signaling overhead. In particular, this scheme allows spectrum resources to be shared not only between V2I and V2V links, but also between different V2V links. In [
9], the authors proposes a method to convert the actual delay and reliability requirements of V2V communication into optimization constraints, but the optimization constraints can only be calculated by slowly changing CSI. In [
10], in areas where spectrum resources are in short supply, vehicle horizontal sharing is combined with available spectrum resources to improve the success rate of alarm information transmission, reduce transmission delay of alarm information and reduce noise to reduce the incidence of traffic accidents, making a great contribution to improving traffic safety. In [
11], a spectrum allocation scheme oriented to service priority in the Internet of vehicles based on long-term evolution was proposed. The spectrum allocation problem was modeled as a mixed integer programming problem and solved by the immune cloning-based algorithm to maximize the system utility. The authors in [
12] propose a spectrum allocation model based on pricing and auction. While the fairness of secondary users is effectively guaranteed, idle spectrum information needs to be obtained in advance, which requires high spectrum perception ability. The authors in [
13] adopt the spectrum sharing model driven by the spectrum database to dynamically adjust the protection boundary of major users according to the geographical location database to improve spectrum utilization efficiency, but this has high requirements for real-time updating of spectrum information. In [
14], the dynamic spectrum allocation problem is mapped to a graph coloring model by using topological graph relations, and the interference graph is used to reduce the interference caused by spectrum sharing. However, as long as the topological structure changes, re-mapping calculation is required, which is mostly suitable for a static network environment. However, in the future vehicular network with a high dynamic unknown environment, the traditional spectrum resource allocation scheme is often difficult to achieve.
Machine learning, as one of the powerful artificial intelligence tools, has been widely used in wireless communication networks in recent years, such as multiple input–multiple output (MIMO), D2D, heterogeneous network composed of femtocells and small cells, etc. [
15]. In particular, reinforcement learning (RL), as a kind of machine learning, has the ability of adaptive adjustment and does not require real-time spectrum perception. Agents only need to observe the changes of environmental state and improve performance according to the reward feedback received after learning to take action [
16], which greatly reduces the complexity of spectrum sharing. Moreover, they do not need the real-time spectrum perception—knowledge concerning only the status of environmental change—in learning to take action after, accordingly as they receive feedback to improve performance, greatly reducing the complexity of spectrum sharing. This has achieved great success in many applications such as AlphaGo [
17]. Inspired by its excellent performance, researchers began to use reinforcement learning methods to solve the spectrum resource allocation problem in the unknown high dynamic vehicle-mounted network environment. A spectrum allocation scheme based on distributed learning is proposed in [
18], in which D2D users explore the environment and autonomously select spectrum resources to maximize throughput and spectrum efficiency and at the same time to meet the minimum interference caused to cellular users. In [
19], a distributed spectrum resource allocation scheme based on multi-agent RL is proposed. Each V2V link is regarded as an agent, and each agent autonomously learns how to rationally select spectrum and power to improve the total capacity of the V2I link and the payload transmission rate of the V2V link. In [
20], each vehicle is regarded as an agent, and multiple agents make decisions autonomously based on local observations in V2V broadcast communication to find the available spectrum. In [
21], a deep RL method is developed to enable BS to centrally manage network, cache and computing resources. In [
22], BS is used to summarize and compress vehicle observation data, and then the compressed information is fed back and the reinforcement learning process is carried out at the base station to improve the spectrum sharing decision performance in the network. In [
23], the graph neural network (GNN) is used to build the V2X network; GNN extracts the features of each V2V pair. Based on the extracted features and local observations, the V2V pair can use the Q-network to make distributed decision-making. The authors in [
24] propose a V2V communication wireless resource allocation system based on proximal policy optimization. In this radio resource allocation framework, continuous actions and multi-dimensional actions can be output to reduce the implementation complexity of large-scale communication scenarios. In [
25], the DQN network is improved. Aiming at the non-stationarity problem caused by multi-agent parallel learning, lag Q-learning and parallel experience replay trajectory are introduced to stabilize the training process, and approximate regret reward (ARR) is added to stabilize the reward estimation. In order to improve the adaptability of the traditional deep reinforcement learning (DRL) algorithm in a dynamic environment, [
26] further combines meta-learning with DRL and proposes a meta-based DRL algorithm. Compared with the DQN-based algorithm, our DRL-based algorithm can provide better performance on both V2I and V2V links. In addition, the DRL algorithm training strategy proposed in this paper has good generalization ability and can quickly adapt to the new environment with limited experience. The authors in [
27] propose a centralized dynamic channel allocation method based on deep reinforcement learning for satellite Internet of Things. This method makes use of the strong representation ability of the deep neural network to make intelligent allocation decisions through continuous learning of allocation strategies so as to minimize the average transmission delay of all sensors. However, in the above methods, differentiated service design is carried out according to vehicle type or link service characteristics. However, in real life, special vehicles can be seen everywhere on the road, such as police cars, ambulances, fire trucks and so on; they need a better information transmission environment in the Internet of vehicles. Faced with these special vehicles with urgent business needs, compared with all V2V links in existing literature that compete fairly for spectrum resources, this paper proposes a V2V link and V2I link sharing strategy for the scenario that urgent services need to be handled first in the Internet of vehicles. Mode 4 in cellular V2X architecture is used for resource allocation, and vehicles share resource pools for communication between V2V and V2I. In this strategy, the link priority mechanism is introduced, and the higher priority link can get a better information interaction environment by reinforcing the reward design of learning.
The innovation points of this paper are summarized as follows:
- (1)
Formulate the dynamic spectrum allocation problem in a CU and D2D co-existed vehicle network.
- (2)
Develop a centralized low complexity algorithm based on the deep reinforcement learning method to achieve priority-based spectrum allocation.
- (3)
Build a weighted sum reward function to realize the dynamically adaptive rates—interference between V2I and V2V links.
The simulation results show that the proposed control method can effectively improve the service quality of high-priority links while ensuring the overall performance of the system, and has good robustness to communication noise.
The rest of this paper is organized as follows. We depict the system model and formulate the optimization problem in
Section 2. The proposed RL-based algorithm is presented in
Section 3.
Section 4 demonstrates simulation results and
Section 5 concludes this paper.
2. System Model and Problem Formulations
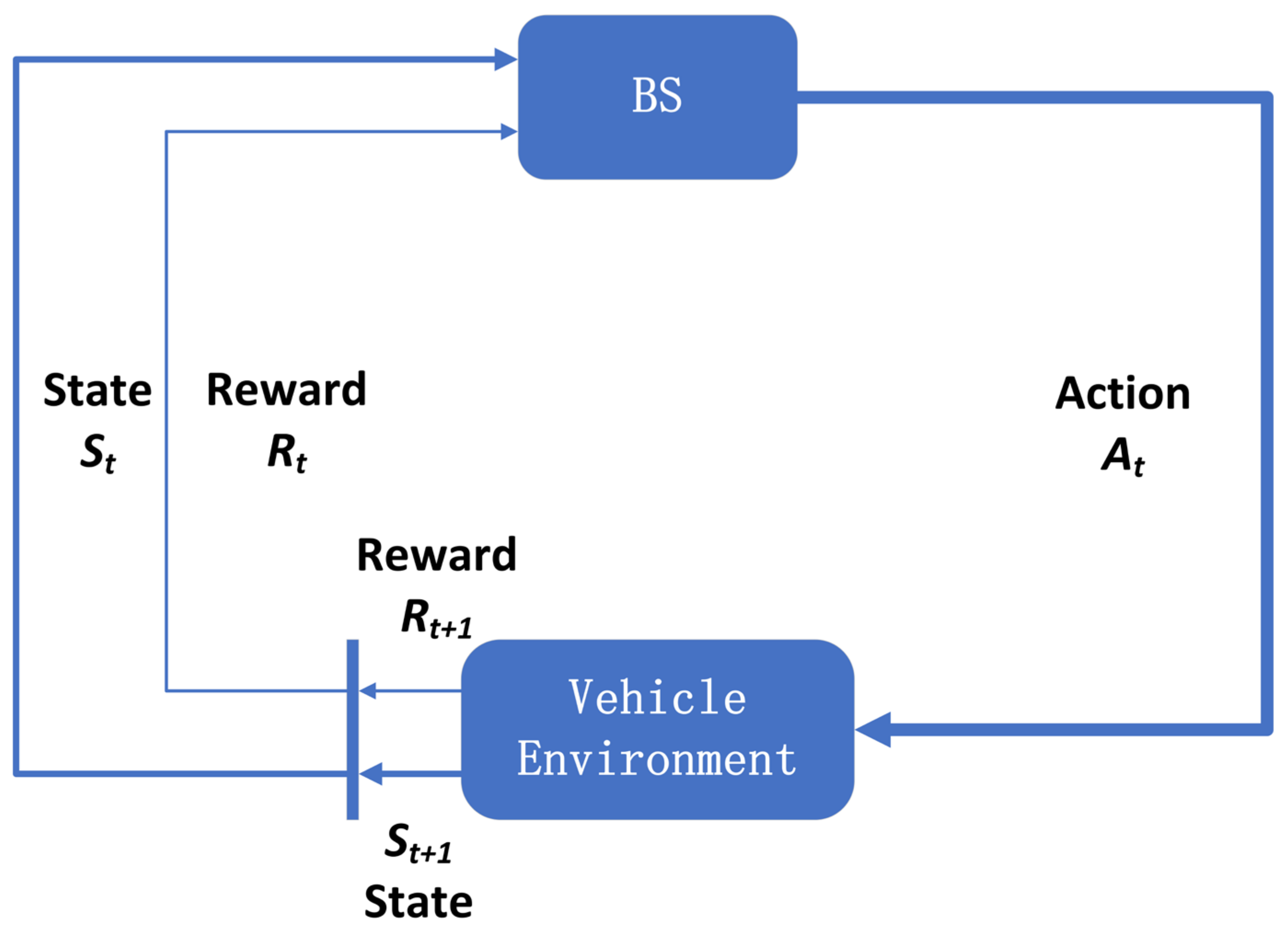
On a V2X network, each V2V link can independently select a different channel to maximize the transmission rate. However, the global performance is poor due to interference between different V2V links. On the other side, considering the V2X scenarios, BS has enough computing and storage resources and can achieve the efficient allocation of resources. With the help of reinforcement learning, this paper uses BS as an agent to interact with the unknown vehicle-mounted network environment.
Suppose there are CU and D2D users co-existing in a vehicle-mounted communication network, where each device is equipped with a single antenna. In this paper, the sets of CU and D2D users are, respectively, expressed as and . Each CU establishes V2I links with BS to support high-quality services, and each D2D user pair transmits information by establishing V2V links. In order to ensure high quality V2I link communication, it is assumed that each V2I link has been pre-assigned different orthogonal spectral subcarriers to eliminate the interference between V2I links in the network. Without sacrificing performance, V2V links and V2I links share the same spectrum resources. To improve the communication quality of V2V links, each V2V link needs to select its occupied spectrum subcarriers and transmitted power.
The channel power gain of the V2I link established between the CU user and BS on authorized channel is defined as . Represents the interference channel gain from the vehicle transmitter of the V2I link to the vehicle receiver of the V2V link occupying the subcarrier. and denote the transmitting power of the V2I link vehicle transmitter and the V2V link vehicle transmitter, respectively; represents the noise power. represents the spectrum allocation scheme, if the V2V link chooses the channel, ; otherwise .
In this case, the reception signal-to-noise ratio (SINR) of V2I link
using the
subcarrier can be expressed as follows:
Assume that each V2V link occupies only one channel. According to the Shannon formula, the transmission rate of the
V2I link using the
channel can be expressed as:
where
is the bandwidth of each channel.
Similarly,
represents the interference channel gain of the
V2V link occupying the
subcarrier.
denotes the interference channel gain from the
V2V link vehicle transmitter to the
V2V link vehicle receiver on the
channel.
indicates the interference channel gain of the
V2I link vehicle transmitter to the
V2V link receiver on the
subcarrier. In summary, the SINR of the V2V link
occupying the
subchannel can be represented as:
where
denotes the interference power received by the
V2V link from other V2V links and from all V2I links:
indicates the interference power between V2V links;
represents V2I link interference power. Therefore, the transmission rate of the
V2V link on the
channel can be expressed as:
To account for overall link performance and high-priority link interference requirements, we maximize an objective function that is a weighted sum of two terms and subtract one term. The first term is the sum rate of V2I links, the second term is the sum rate of V2V links and the third term is the total interference of priority links. Meanwhile, to reflect the advantages of high-priority links without affecting the performance of other links, we introduce some constraints.
Therefore, the overall optimize problem is:
where
,
and
are the weight constant used to define the priority between the three targets,
refers to the total interference received by a priority link,
represents the maximum total interference that we set.
and
, respectively represent the rates of V2I link and V2V link when the random spectrum allocation scheme is used.
4. Simulations
This paper designs a simulator according to the evaluation method defined for urban cases in Annex A of 3GPP TR 36.885 [
29], which describes in detail the vehicle fading model, density, speed, direction of movement, vehicle passage, V2V data flow, etc. The simulation considers the topology scene of the Internet of vehicles in the two-way and one-way lane area of 375 m wide and 649 m long at the intersection. There is a BS in the center of the scene, and the starting position and driving direction of vehicles are randomly initialized within the region. Other simulation parameters of the system are shown in
Table 1. The hardware environment of the simulator is Intel Core I9-10900F processor + 32G memory + Nvidia GeForce RTX3090 graphics card. Tensorflow 1.12.0 and Keras 2.24 are used to build and train the neural network.
The above algorithm adopts a five-layer fully connected neural network. According to literature [
22], the hidden layers of DNN and DQN are set as 3 in this paper. The number of neurons in the three hidden layers of DNN is set to 16, 32 and 16, respectively. The number of neurons in the three hidden layers of DQN was set to 1200, 800 and 600, respectively.
Here, the RELU activation function
is used for both DNN and DQN, and the linear function is set to the activation function for the output layer in DNN and DQN. In addition, the RMSProp optimizer [
30] was used for renewal network parameters, and the study rate was 0.001. The loss function is set as Huber loss [
31]. In addition, the exploration rate of the whole neural network was set as linear decay from 1 to 0.01 during training. The number of steps T of each training set is set to 1000, and the update frequency of the target network Q is set to 500 steps. The discount rate
for training is set to 0.05. The size of the empirical memory unit is set to be
, and the size of the small sample data is set to 512.
In order to facilitate performance comparison, the corresponding weights of total V2I link rates and total V2V link rates are set to
= 0.1,
= 1 in accordance with reference [
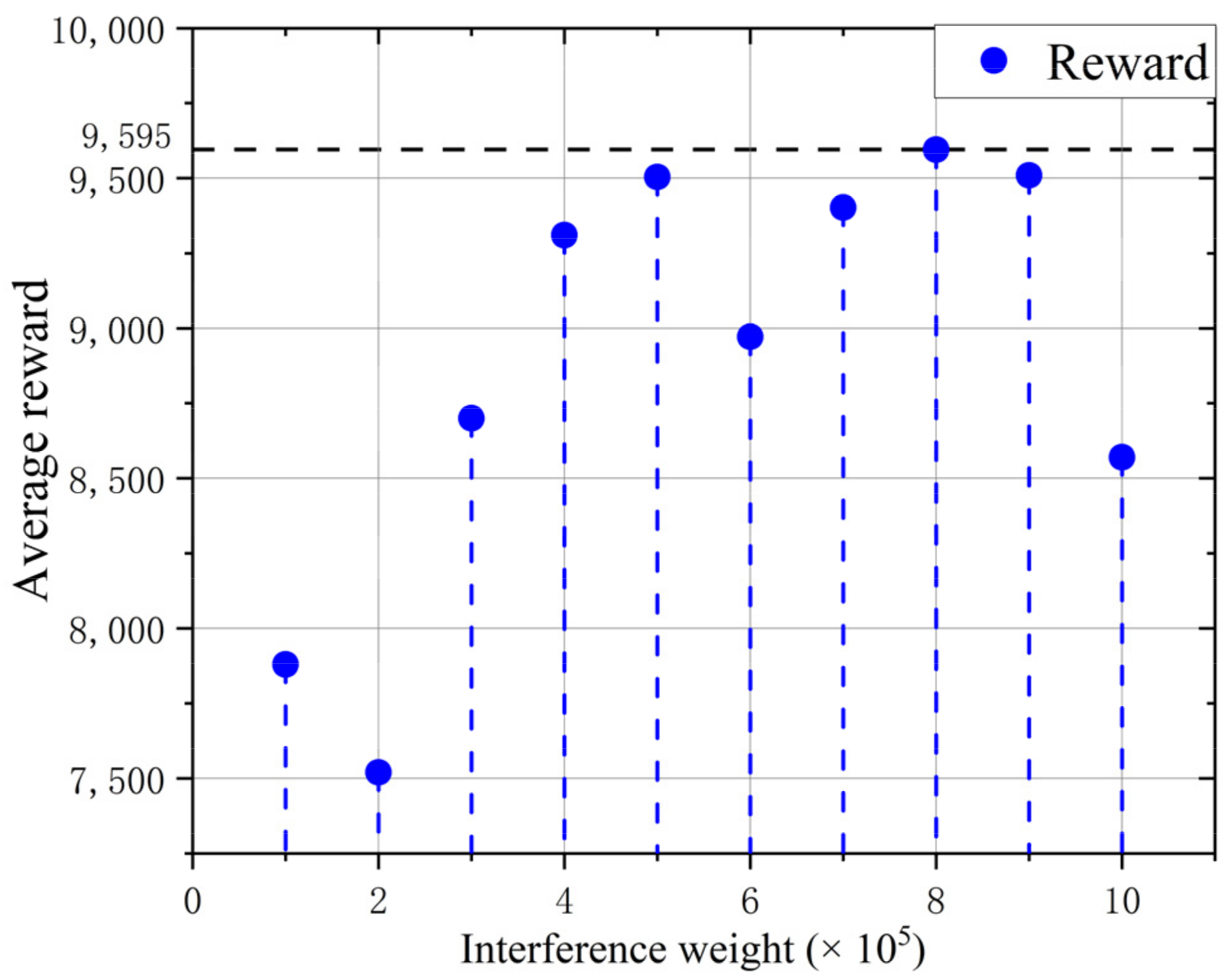
22] in the experiment. This algorithm introduces interference weight of priority link
to distinguish link priorities. If
is too small, it cannot reflect the superiority of the high-priority link. In contrast, high-priority links overoccupy common link resources, affecting fairness and significantly degrading overall performance. Through the experimental test from
Figure 3, the selection
can distinguish the priority well and take into account the overall performance of the system.
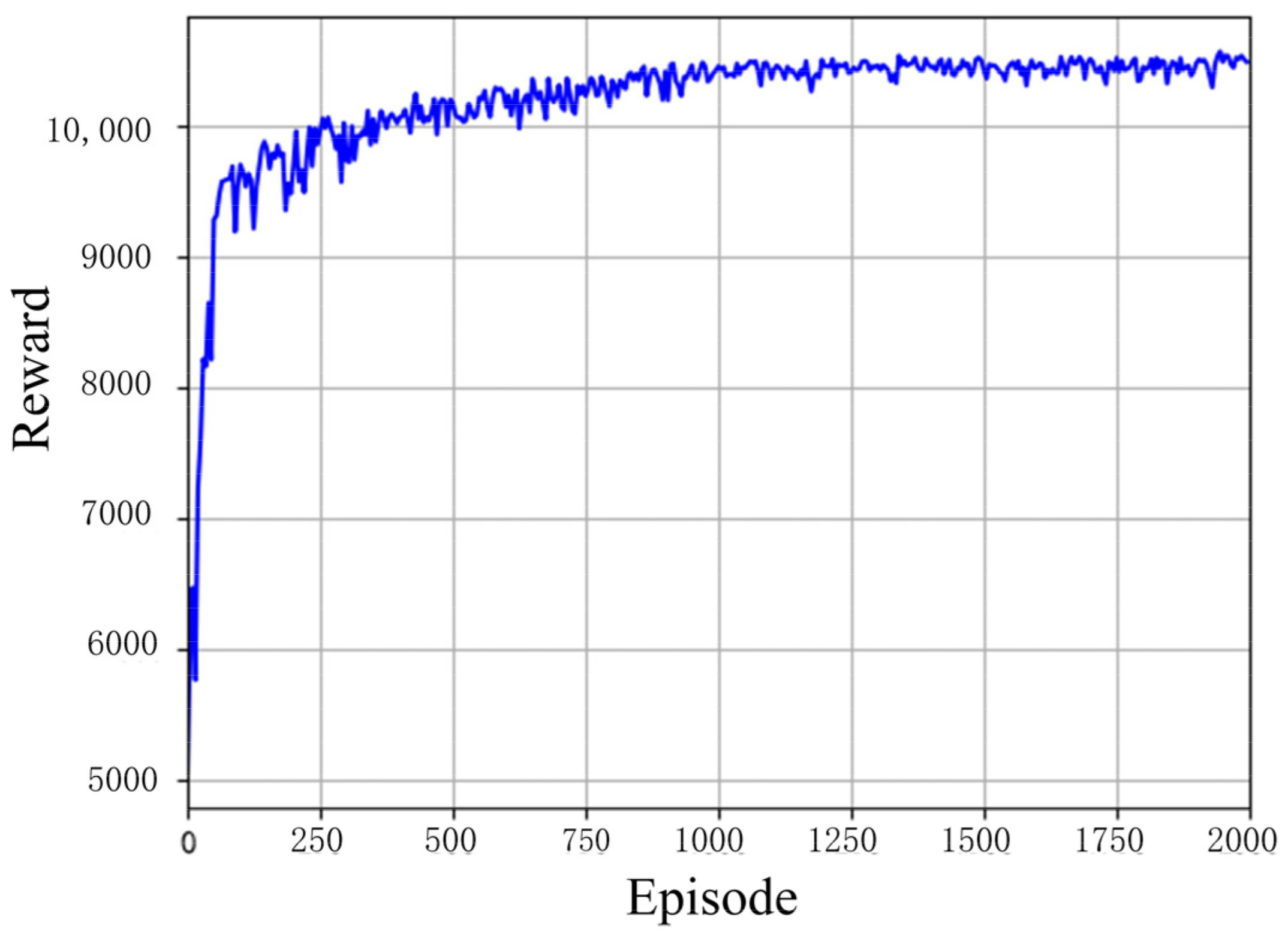
In
Figure 4, the reward for each episode increases as the training set increases, and eventually converges. However, the reason why rewards occasionally get smaller on the way is that greedy strategies are adopted in the training, which may lead to poor results in the exploration of unknown environments. However, as the exploration rate decreases in the later training period, the rewards per episode are not particularly bad and tend to converge, indicating the stability of the training process.
5. Discussion
The following four comparison schemes are considered in the simulation:
Scheme of this paper;
Random action.
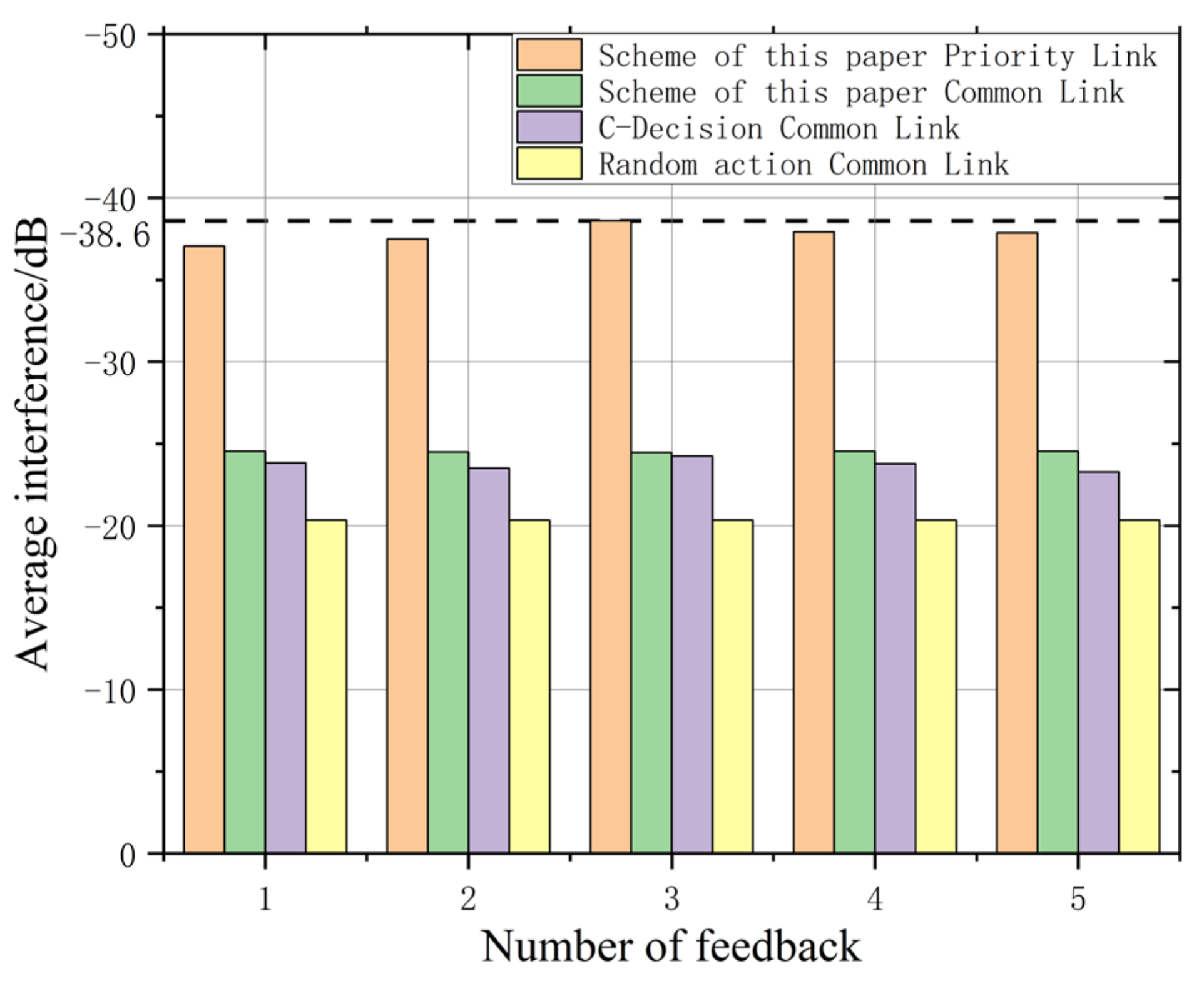
Firstly, the influence of feedback number on V2V link is considered.
As shown in
Figure 5, when the number of feedback is 3, the average total interference received by the high-priority link in this scheme is the smallest, obviously reflecting the advantage of priority, and the average total interference received by the ordinary link is also slightly lower than that received by C-Decision. Priority discrimination is implemented on the premise that the average performance (that is, the overall performance) does not degrade, or priority discrimination ensures fairness. Then, with the increase of the feedback number, the average total interference of each V2V link basically remains unchanged and is larger than the total interference of the feedback number 3. In summary, the number of feedback is set as 3 in the simulation.
Table 2 lists the performance comparison of the four schemes when the number of feedback is 3 and there is no input noise and feedback noise. Input noise refers to the Gaussian white noise received by each V2V during local observation, and feedback noise refers to the noise generated when DNN’s output is fed back to DQN’s input. Because the last four schemes consider the links equally, they do not distinguish the priority links, so we treat the average rate as the priority link rate. For the scheme in this paper, the average total interference received by the high-priority link is significantly smaller than that received by the common link, that is, the priority link has a better information transmission environment, reflecting the advantage of priority. The average total interference received by the ordinary link is slightly lower than that of C-Decision, SOLEN scheme and GNN-RL scheme and better than that of random scheme. In addition, the average rate of the V2V link in this scheme is improved by about 2.12% compared with C-Decision, which is higher than the SOLEN scheme and obviously better than the GNN-RL scheme and random action scheme. Similarly, the average rate of the V2I link in this scheme increases by about 7.51% compared with C-Decision, slightly higher than the SOLEN scheme and higher than the GNN-RL scheme and random action scheme. In summary, the scheme presented in this paper obviously shows the advantage of priority and is superior to C-Decision, GNN-RL and random spectrum allocation schemes in performance. While the proposed scheme is only slightly better than the SOLEN scheme, the proposed scheme does not need to obtain the CSI of all links in the base station. The scheme in this paper has no such limitation. It indicates that the scheme in this paper is more suitable for the Internet of vehicles environment with urgent business needs in real life.
Finally, we study the influence of input noise and feedback noise on priority-enabled schemes.
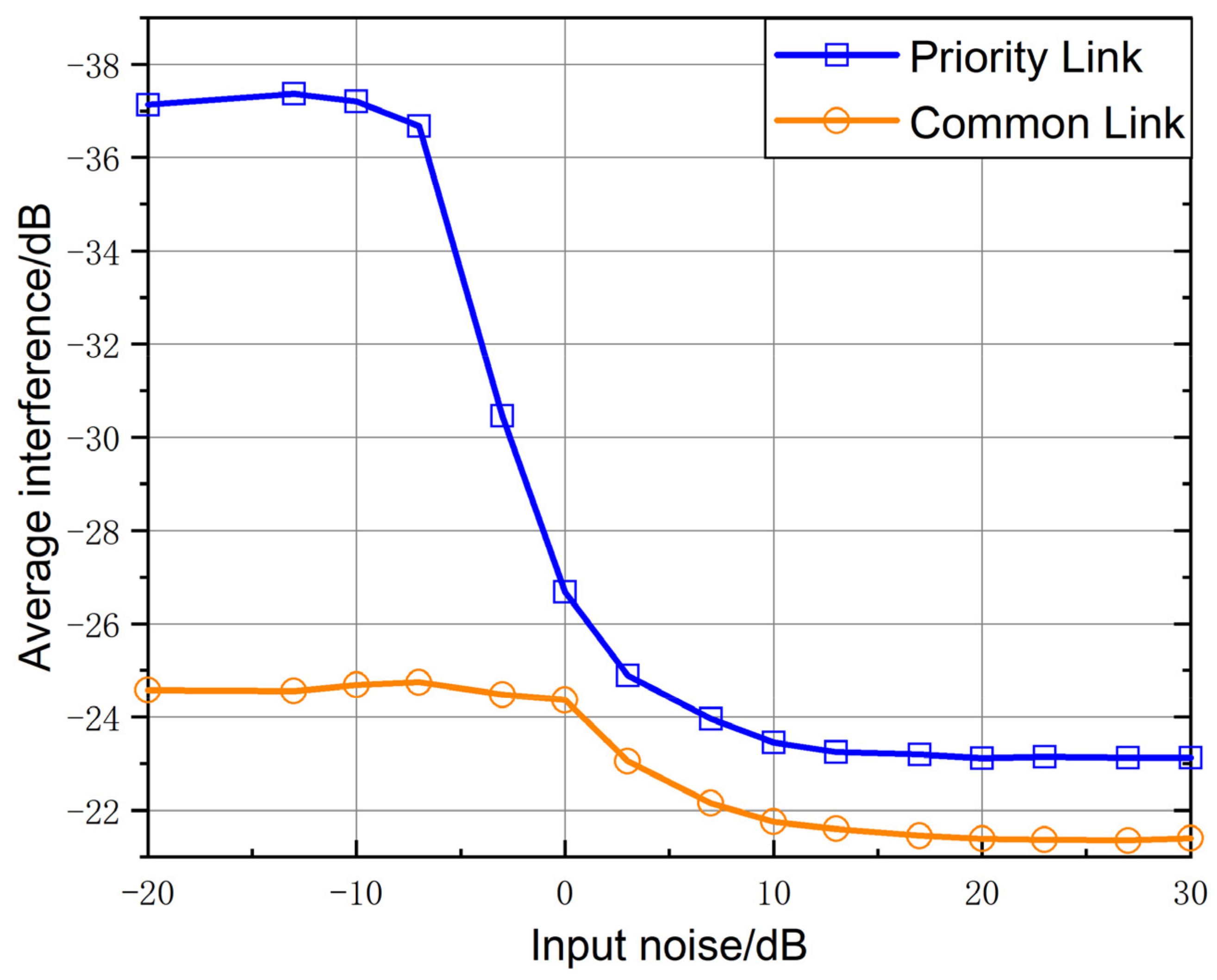
As can be seen from
Figure 6, with the increase of input noise, the average interference received by high-priority V2V links in this scheme rises gradually and tends to be stable when the input noise is greater than 10 dB, while the average total interference received by non-priority links basically remains unchanged. This indicates that the scheme with priority enabled when the input noise is low can obviously show the advantage of priority, and the advantage of priority link gradually decreases with the increase of input noise.
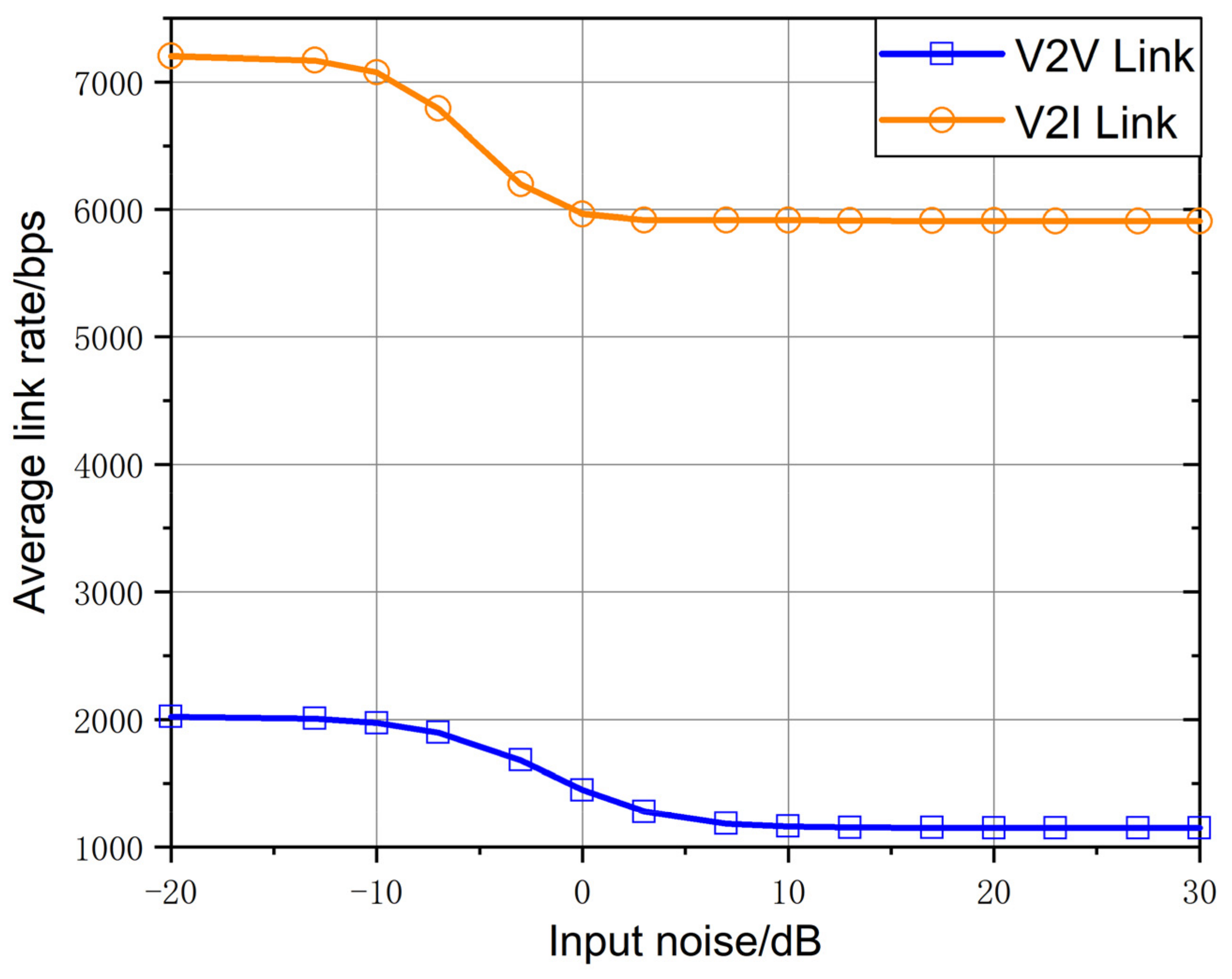
As shown in
Figure 7, in this scheme, the average rate of the V2I link decreases with the increase of input noise, and tends to be stable when the input noise is greater than 3 dB. When the input noise is large, the rate of the V2I link can still maintain 56.78%. Similarly, the average rate of V2V links decreases with the increase of input noise, and remains stable when the input noise is greater than 10 dB. When the input noise is large, the average rate of V2V links remains 82.04%. V2I links maintain better performance than V2V links.
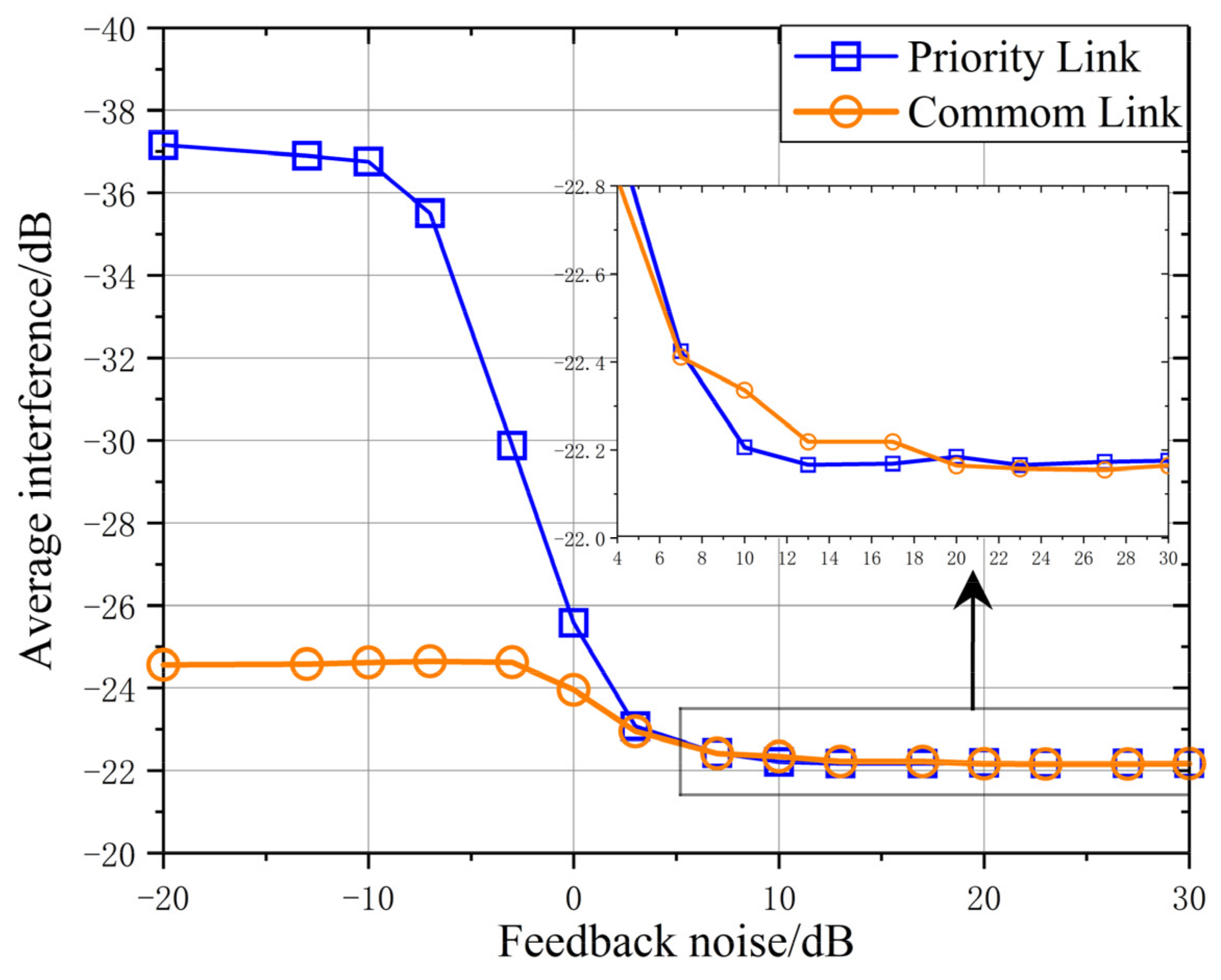
It can be seen from
Figure 8 that the average interference received by the high-priority link increases with the increase of feedback noise, and there is no significant difference between the high-priority link and the ordinary link when the feedback noise is greater than 3 dB. This indicates that the effective information of link differentiation cannot be resolved when the feedback noise is high, but the priority can still be reflected when the feedback noise is low. When the feedback noise is greater than 10 dB, the average interference received by both of them is basically stable.
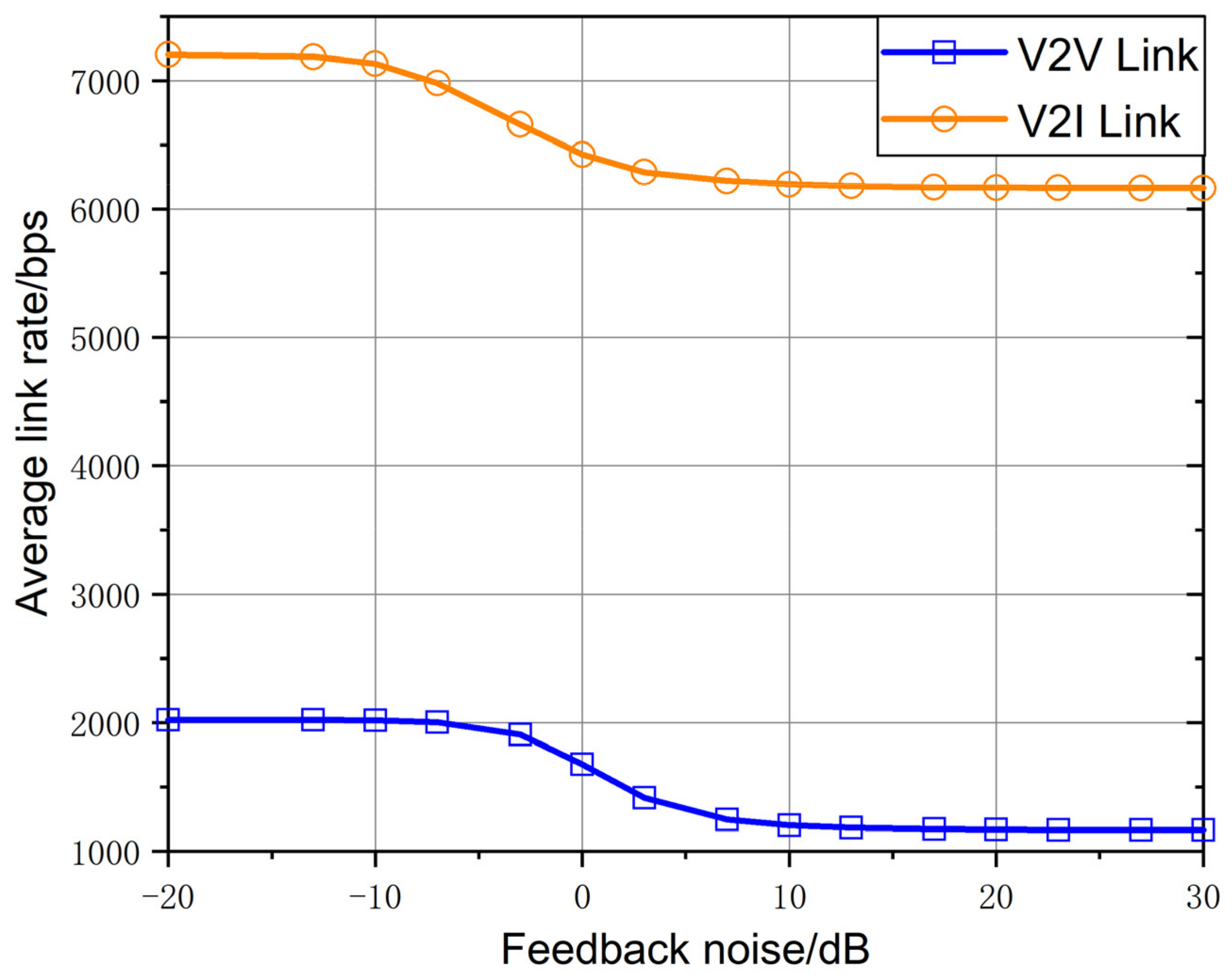
As shown in
Figure 9, with the increase of feedback noise, the average rate of the V2I link in this scheme decreases gradually, and is basically unchanged when the feedback noise is greater than 10 dB. When the input noise is large, the rate can be maintained at 85.55%. The average rate of the V2V link decreases with the increase of feedback noise, and remains stable when the feedback noise is greater than 10 dB. When the input noise is large, the average rate of the V2V link remains 57.59%. The V2I link is less affected by feedback noise.
Compared with the random spectrum allocation scheme, C-Decision and SOLEN algorithm have improved transmission efficiency and anti-interference. However, C-Decision does not differentiate services between V2V links. The SOLEN scheme relies on CSI of all V2V and V2I links. The proposed scheme improves the transmission performance of high-priority links while ensuring the performance of common links, and is superior to C-Decision, SOLEN and traditional random spectrum allocation schemes in overall performance. At the same time, it has good robustness to input noise and feedback noise, and is more suitable for practical vehicle-mounted network scenarios.
At present, the proposed algorithm makes centralized spectrum allocation decisions at the base station. In order to reduce computational complexity, we can consider distributed spectrum resource allocation in the next step, and each V2V link makes local spectrum allocation decisions. In the future, we will also consider improving our algorithm to be more suitable for joint V2I link and V2V link resource allocation problems in the future Internet of vehicles.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}