
COVID-19 Diagnosis from Crowdsourced Cough Sound Data



Abstract
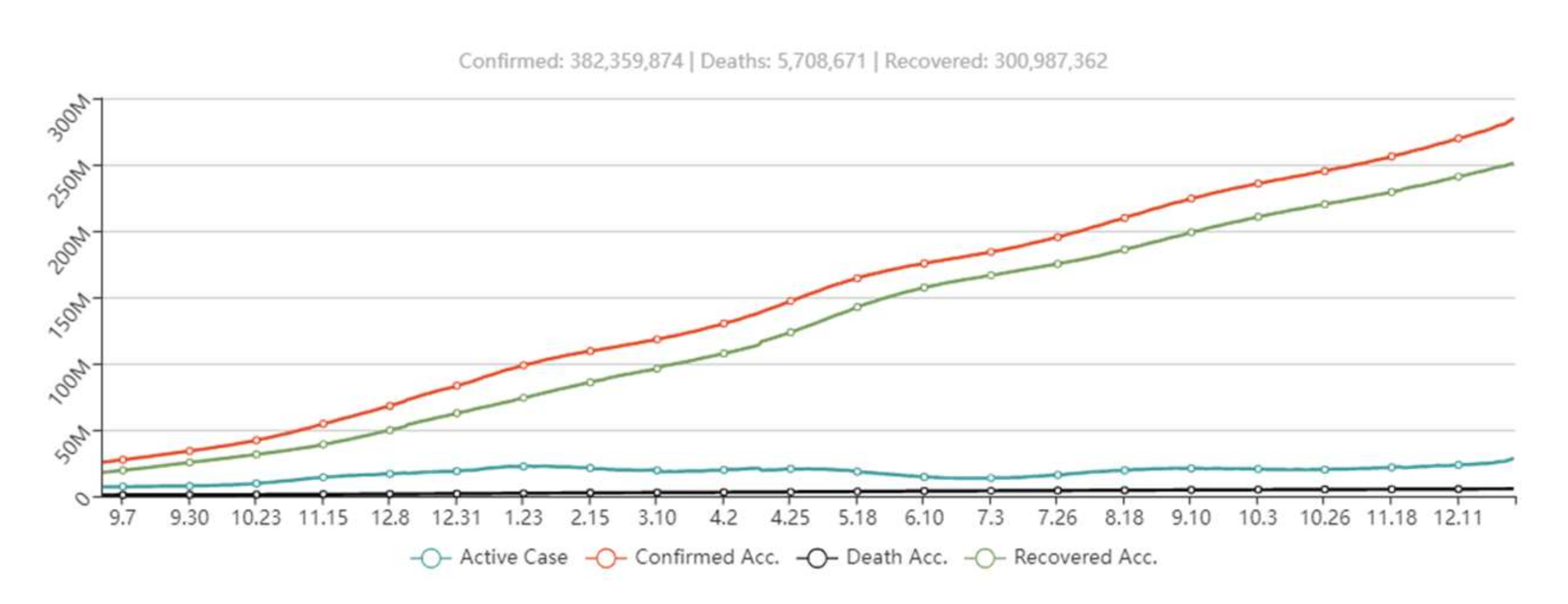
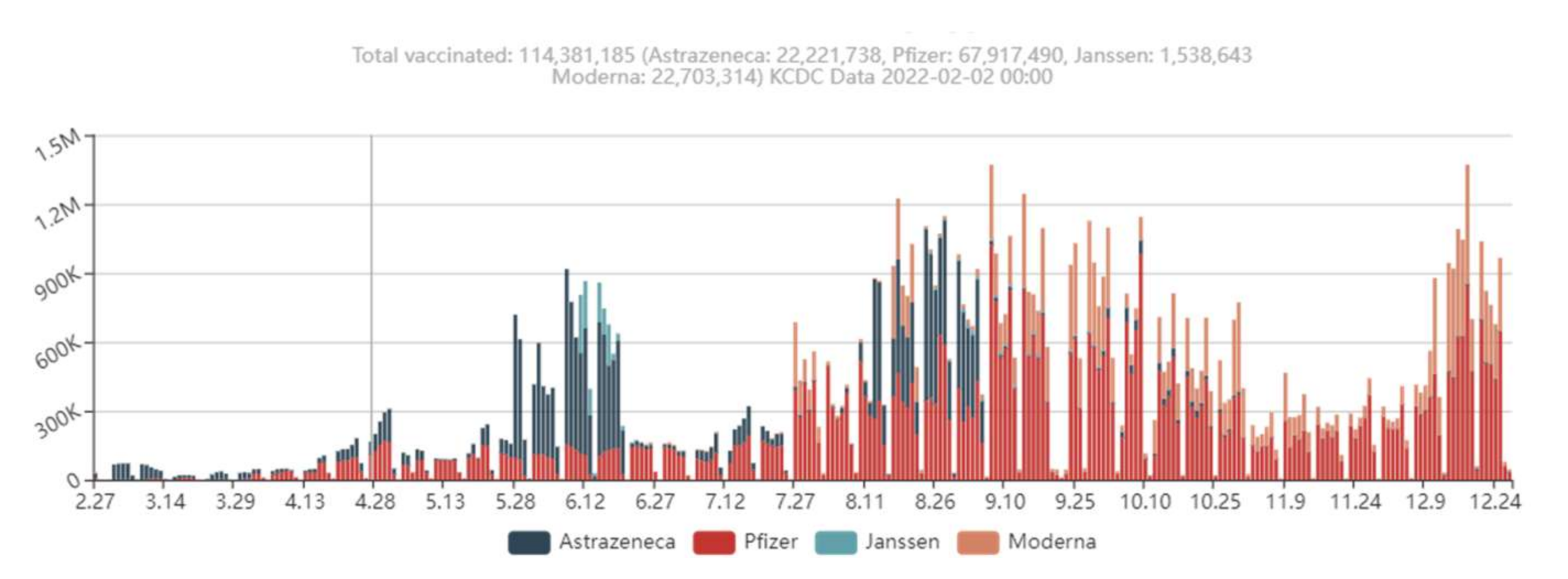
:1. Introduction
2. Related work
2.1. Cough Data
2.2. Cough Testing
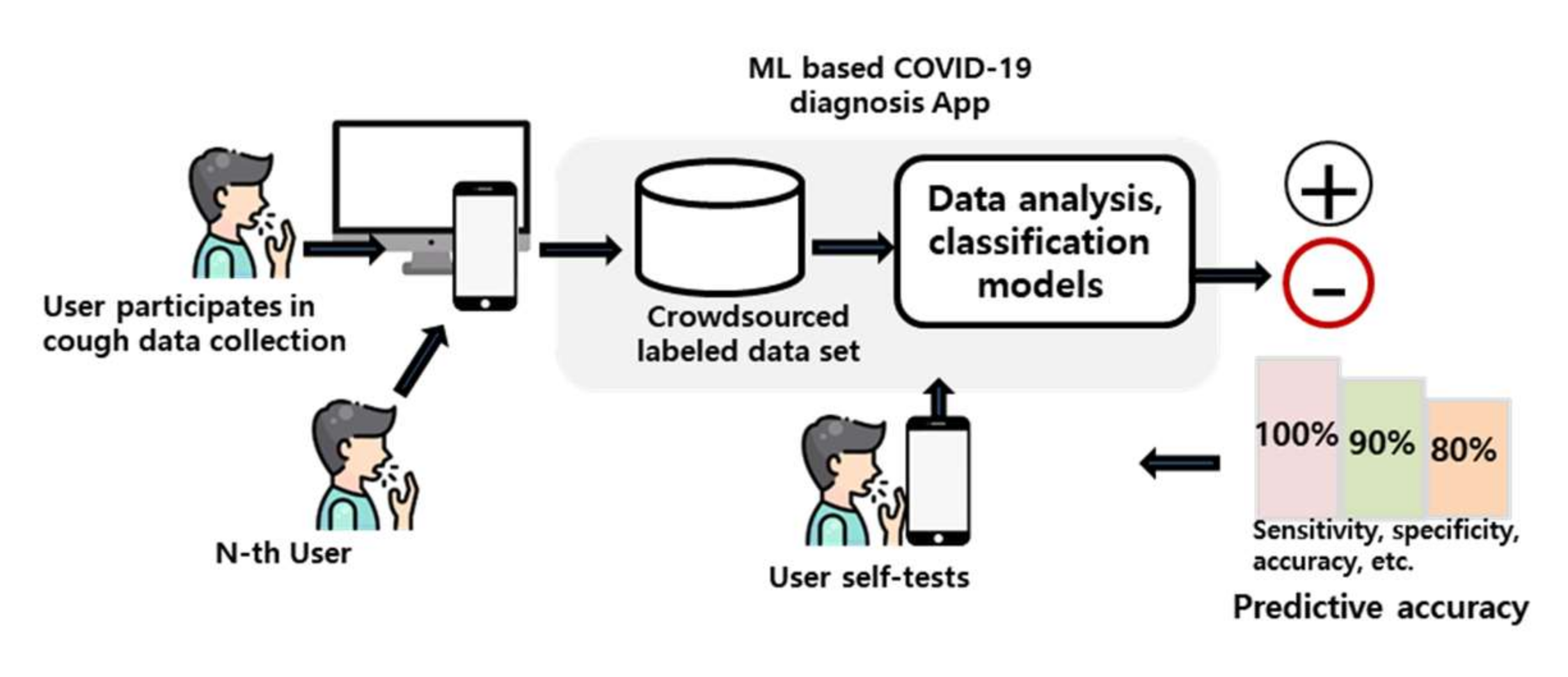
3. Proposed Method
3.1. Data
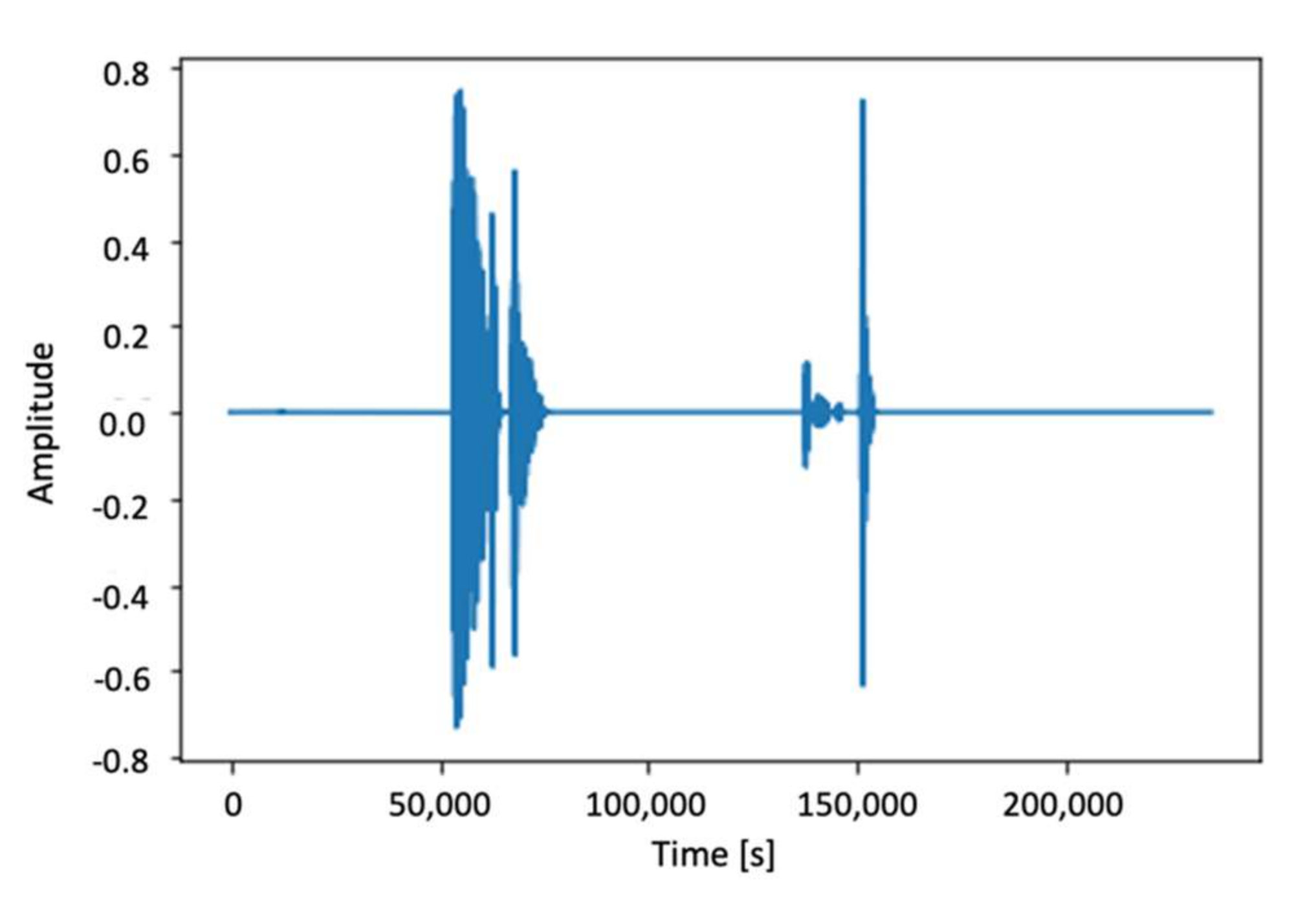
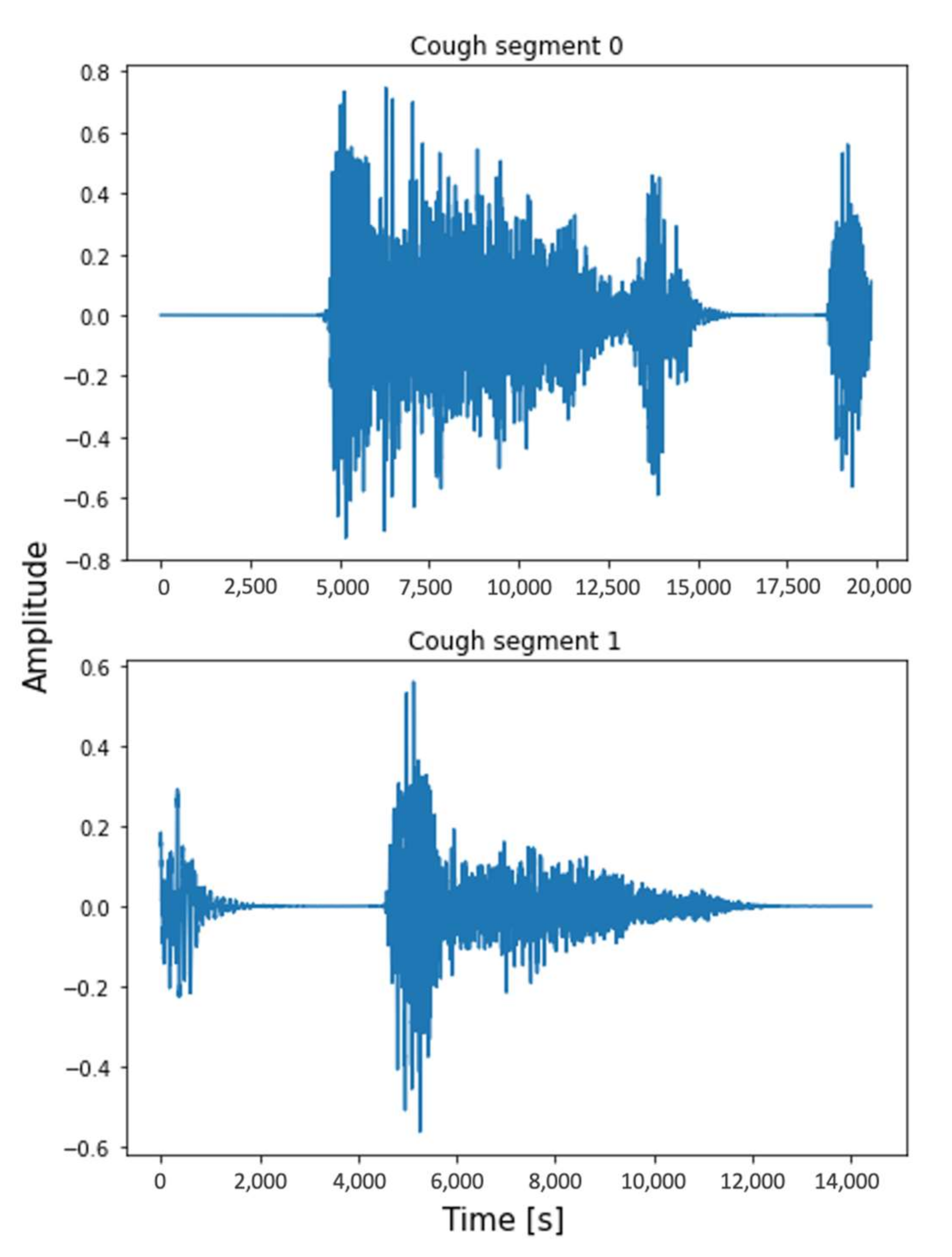
3.2. Preprocessing
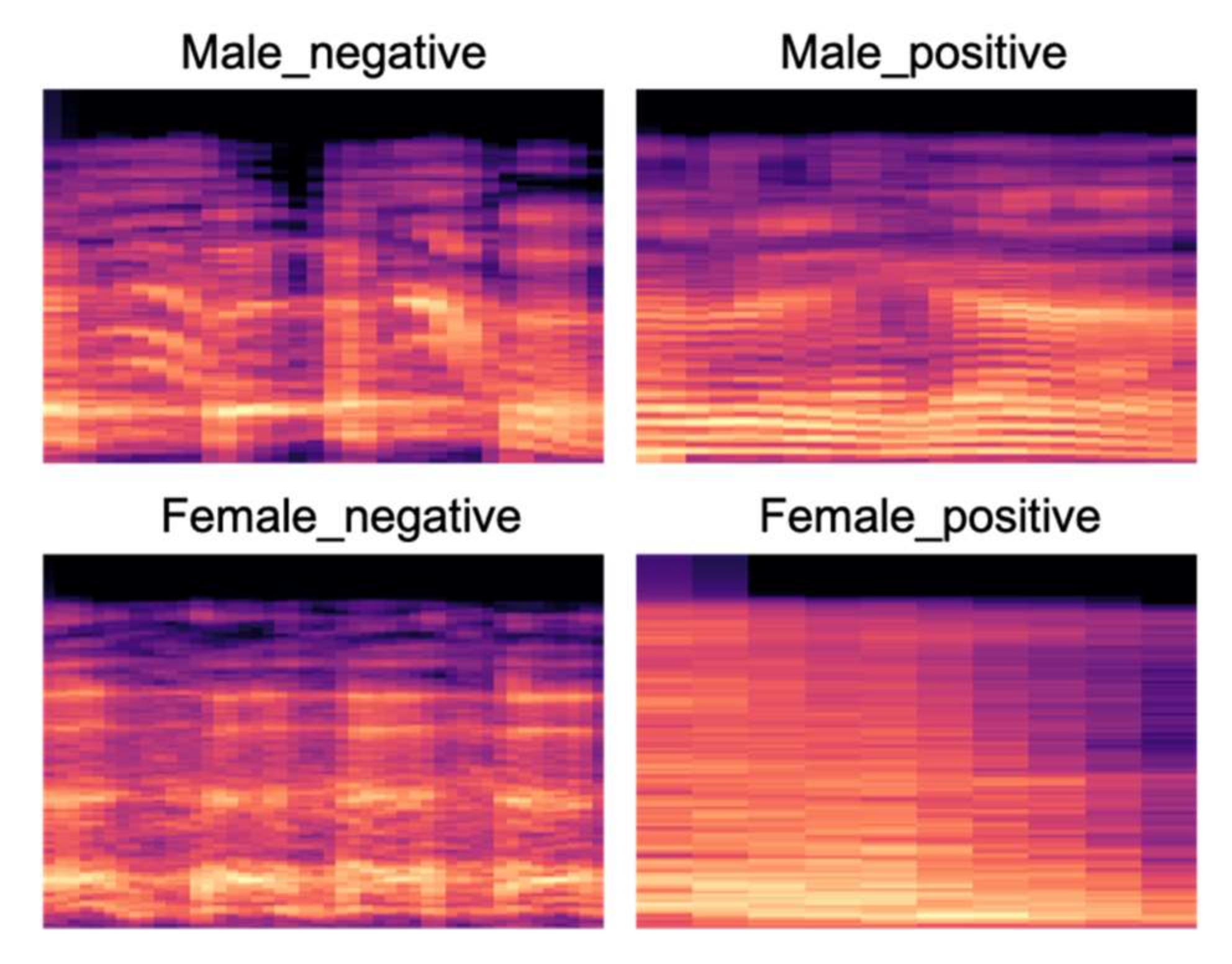
3.3. Audio Features
- 13 MFCCs;
- 5 spectral features: spectral centroid, spectral bandwidth, 7 spectral contrast features, spectral flatness, and spectral roll-off;
- 12 chroma features: 12-dimensional chroma vector.
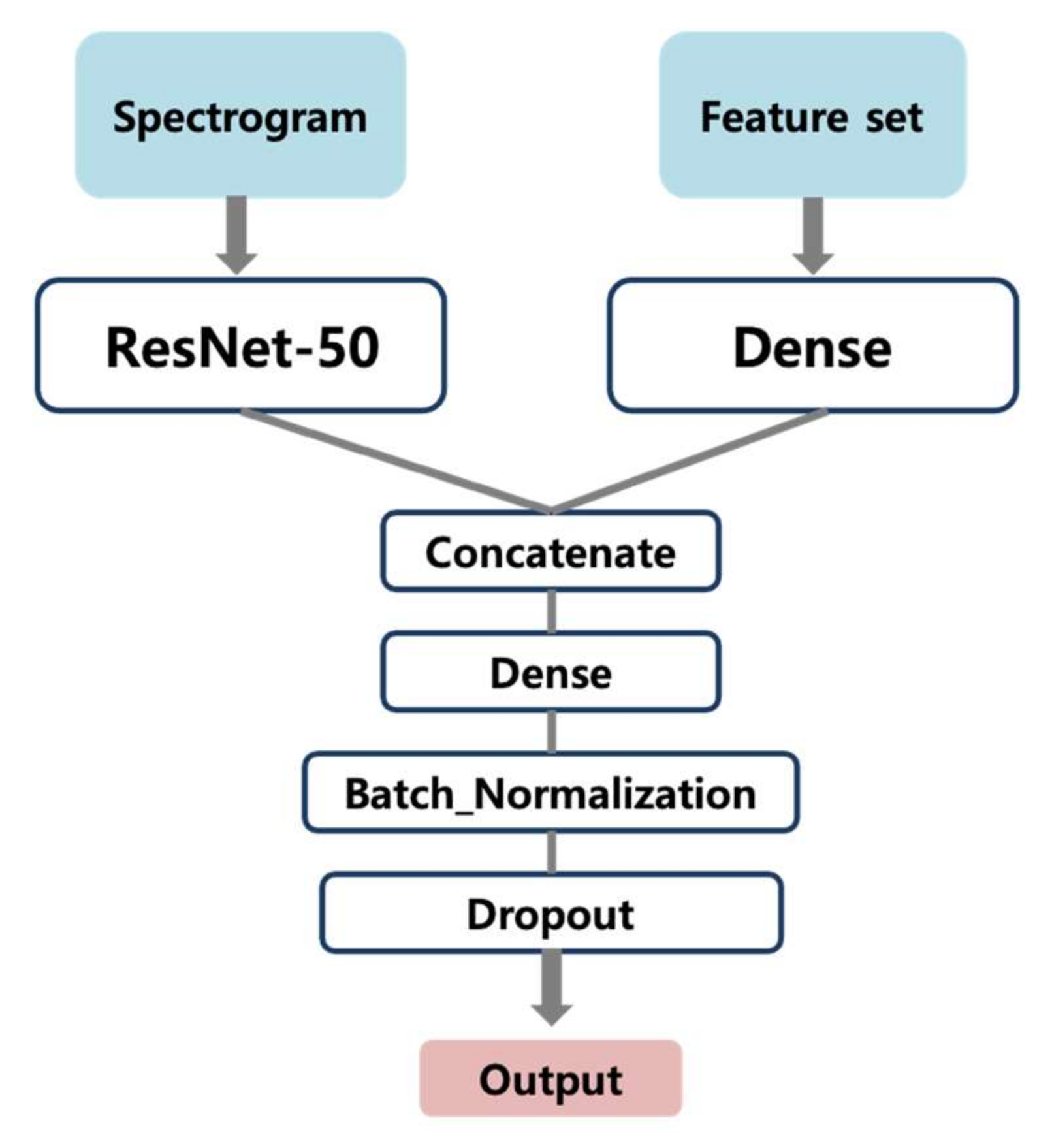
3.4. Model
4. Experiments
4.1. Experimental Design
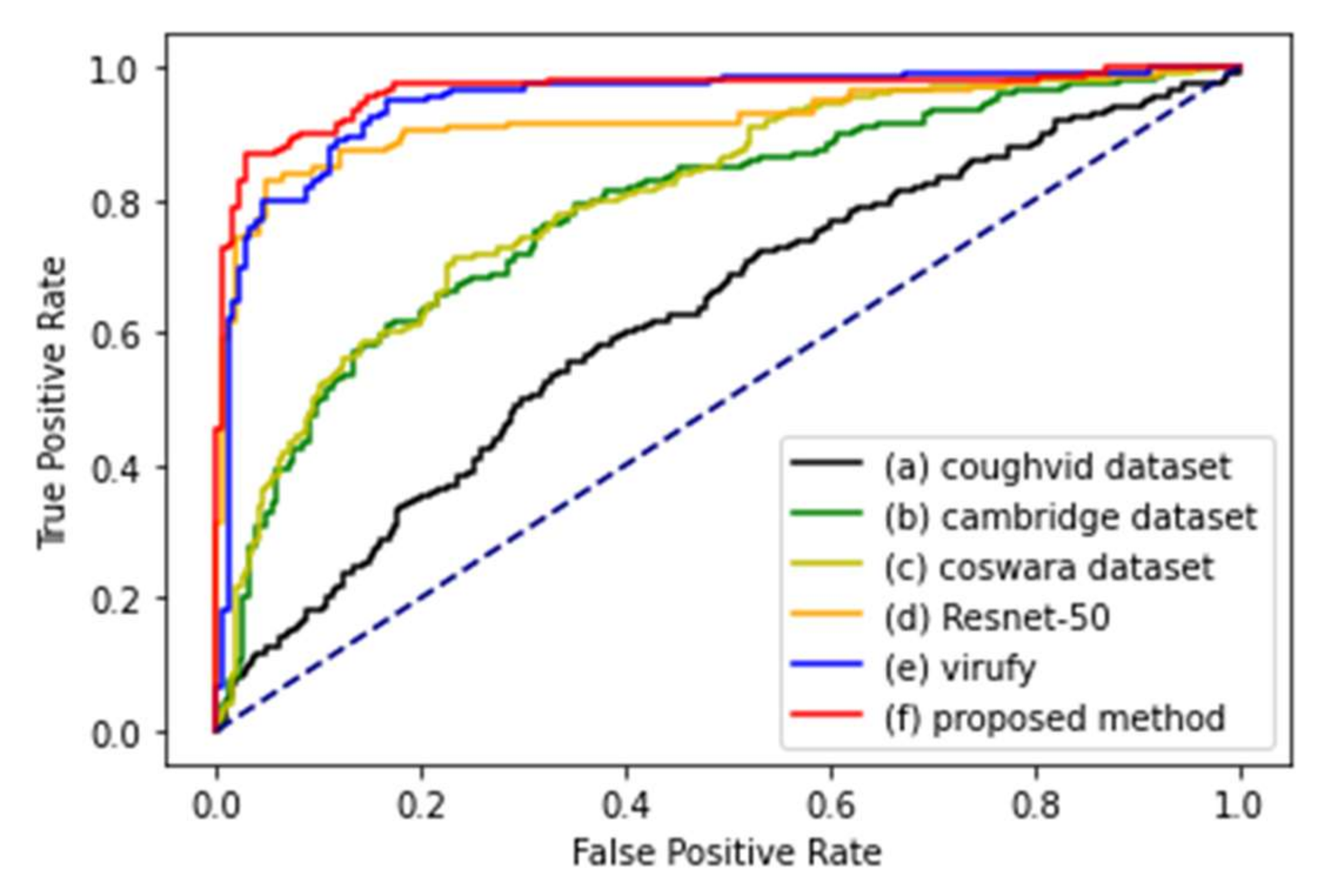
4.2. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- COVID-19 Dashboard. Available online: https://coronaboard.kr/en/ (accessed on 2 February 2022).
- Watson, J.; Whiting, P.F.; Brush, J.E. Interpreting a covid-19 test result. BMJ 2020, 369, m1808. [Google Scholar] [CrossRef] [PubMed]
- Ondoa, P.; Kebede, Y.; Loembe, M.M.; Bhiman, J.N.; Tessema, S.K.; Sow, A.; Sall, A.A.; Nkengasong, J. COVID-19 testing in Africa: Lessons learnt. Lancet Microbe 2020, 1, e103–e104. [Google Scholar] [CrossRef]
- Bae, S.; Lee, Y.W.; Lim, S.Y.; Lee, J.-H.; Lim, J.S.; Lee, S.; Park, S.; Kim, S.-K.; Lim, Y.-J.; Kim, E.O.; et al. Adverse Reactions Following the First Dose of ChAdOx1 nCoV-19 Vaccine and BNT162b2 Vaccine for Healthcare Workers in South Korea. J. Korean Med. Sci. 2021, 36, e115. [Google Scholar] [CrossRef] [PubMed]
- Rajinikanth, V.; Dey, N.; Joseph, A.N.; Hassanien, R.A.E.; Santosh, K.C.; Raja, N. Harmony-search and otsu based system for coronavirus disease (COVID-19) detection using lung ct scan images. arXiv 2020, arXiv:2004.03431v1. [Google Scholar]
- Yildirim, M.; Cinar, A. A Deep Learning Based Hybrid Approach for COVID-19 Disease Detections. Trait. Signal 2020, 37, 461–468. [Google Scholar] [CrossRef]
- Mouawad, P.; Dubnov, T.; Dubnov, S. Robust Detection of COVID-19 in Cough Sounds. SN Comput. Sci. 2021, 2, 34. [Google Scholar] [CrossRef]
- Imran, A.; Posokhova, I.; Qureshi, H.N.; Masood, U.; Riaz, M.S.; Ali, K.; John, C.N.; Hussain, I.; Nabeel, M. AI4COVID-19: AI enabled preliminary diagnosis for COVID-19 from cough samples via an app. Inform. Med. Unlocked 2020, 20, 100378. [Google Scholar] [CrossRef]
- Hassan, A.; Shahin, I.; Alsabek, M.B. COVID-19 Detection System using Recurrent Neural Networks. In Proceedings of the 2020 International Conference on Communications, Computing, Cybersecurity, and Informatics (CCCI), Sharjah, United Arab Emirates, 3–5 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Nessiem, M.A.; Mohamed, M.M.; Coppock, H.; Gaskell, A.; Schuller, B.W. Detecting COVID-19 from Breathing and Coughing Sounds using Deep Neural Networks. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021; pp. 183–188. [Google Scholar] [CrossRef]
- Laguarta, J.; Hueto, F.; Subirana, B. COVID-19 Artificial Intelligence Diagnosis Using Only Cough Recordings. IEEE Open J. Eng. Med. Biol. 2020, 1, 275–281. [Google Scholar] [CrossRef]
- Brown, C.; Chauhan, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Spathis, D.; Xia, T.; Cicuta, P.; Mascolo, C. Exploring Automatic Diagnosis of COVID-19 from Crowdsourced Respiratory Sound Data. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 3474–3484. [Google Scholar] [CrossRef]
- Fakhry, A.; Jiang, X.; Xiao, J.; Chaudhari, G.; Han, A.; Khanzada, A. Virufy: A Multi-Branch Deep Learning Network for Automated Detection of COVID-19. arXiv 2021, arXiv:2103.01806. [Google Scholar]
- Bagad, P.; Dalmia, A.; Doshi, J.; Nagrani, A.; Bhamare, P.; Mahale, A.; Rane, S.; Agarwal, N.; Panicker, R. Cough Against COVID: Evidence of COVID-19 Signature in Cough Sounds. arXiv 2020, arXiv:2009.08790v2. Available online: https://arxiv.org/abs/2009.08790v2 (accessed on 19 April 2021).
- Pahar, M.; Klopper, M.; Warren, R.; Niesler, T. COVID-19 Cough Classification using Machine Learning and Global Smartphone Recordings. arXiv 2020, arXiv:2012.01926v2. Available online: https://arxiv.org/abs/2012.01926v2 (accessed on 16 August 2021). [CrossRef] [PubMed]
- Oletic, D.; Bilas, V. Energy-Efficient Respiratory Sounds Sensing for Personal Mobile Asthma Monitoring. IEEE Sens. J. 2016, 16, 8295–8303. [Google Scholar] [CrossRef]
- Sotoudeh, H.; Tabatabaei, M.; Tasorian, B.; Tavakol, K.; Sotoudeh, E.; Moini, A. Artificial Intelligence Empowers Radiologists to Differentiate Pneumonia Induced by COVID-19 versus Influenza Viruses. Acta Inform. Medica 2020, 28, 190–195. [Google Scholar] [CrossRef] [PubMed]
- Laguarta, J.; Hueto, F.; Rajasekaran, P.; Sarma, S.; Subirana, B. Longitudinal speech biomarkers for automated Alzheimer’s detection. Front. Comput. Sci. 2021, 3, 624694. [Google Scholar] [CrossRef]
- Chatrzarrin, H.; Arcelus, A.; Goubran, R.; Knoefel, F. Feature extraction for the differentiation of dry and wet cough sounds. In Proceedings of the 2011 IEEE International Symposium on Medical Measurements and Applications, Bari, Italy, 30–31 May 2011; pp. 162–166. [Google Scholar] [CrossRef]
- Sharma, N.; Krishnan, P.; Kumar, R.; Ramoji, S.; Chetupalli, S.R.; Nirmala, R.; Ghosh, P.K.; Ganapathy, S. Coswara—A Database of Breathing, Cough, and Voice Sounds for COVID-19 Diagnosis. arXiv 2020, arXiv:2005.10548. Available online: http://arxiv.org/abs/2005.10548 (accessed on 14 January 2021).
- Orlandic, L.; Teijeiro, T.; Atienza, D. The COUGHVID crowdsourcing dataset, a corpus for the study of large-scale cough analysis algorithms. Sci. Data 2021, 8, 156. [Google Scholar] [CrossRef]
- VGGish. Available online: https://github.com/tensorflow/models/tree/master/research/audioset/vggish (accessed on 14 September 2021).
- Kaiming, H.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.0338. [Google Scholar]
- Librosa Package. Available online: https://librosa.github.io/librosa (accessed on 30 August 2021).
- Mermelstein, P. Distance measures for speech recognition, psychological and instrumental. In Pattern Recognition and Artificial Intelligence; Chen, C.H., Ed.; Academic Press: New York, NY, USA, 1976; pp. 374–388. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Sahu, K.K.; Mishra, A.K.; Martin, K.; Chastain, I. COVID-19 and clinical mimics. Correct diagnosis is the key to appropriate therapy. Monaldi Arch. Chest Dis. 2020, 90, 1327. [Google Scholar] [CrossRef]
- Korpas, J.; Sadlonova, J.; Vrabec, M. Analysis of the Cough Sound: An Overview. Pulm. Pharmacol. 1996, 9, 261–268. [Google Scholar] [CrossRef] [PubMed]
- Meister, J.; Nguyen, K.; Luo, Z. Audio feature ranking for sound-based COVID-19 patient detection. arXiv 2021, arXiv:2104.07128v1. Available online: https://arxiv.org/abs/2104.07128 (accessed on 5 February 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cough_Detection_Score ≥ 0.8 | Cough_Detection_Score ≥ 0.9 | |
|---|---|---|
| Healthy | 5608 | 4702 |
| Symptomatic | 1135 | 949 |
| COVID-19 | 547 | 441 |
| Total | 8295 | 6092 |
| Database | Negative | Positive | Negative Segmented File | Positive Segmented File |
|---|---|---|---|---|
| COUGHVID [21] | 5651 | 441 | 11,981 | 1140 |
| Cambridge [12] | 660 | 204 | 1634 | 586 |
| Coswara [20] | 1372 | 303 | 2353 | 448 |
| Specifications | |
|---|---|
| Operation system | Ubuntu 18.04 LTS |
| Tensorflow | 2.4.1 |
| Cuda | 10.1 |
| CPU | intel Core i7-4770 |
| GPU | GeForce GTX 1080Ti × 1 |
| RAM | 16 GB |
| Database | Features | Model | Performance | |||
|---|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | ||||
| (a) | [21] | MFCC | LSTM | 62% | 60% | 62% |
| (b) | [12] | MFCC | LSTM | 71% | 77% | 65% |
| (c) | [20] | MFCC | LSTM | 73% | 71% | 76% |
| (d) | [21] | Spectrogram | ResNet-50 | 88% | 90% | 88% |
| (e) | [21] | MFCC + spectrogram | ResNet-50 + DNN | 89% | 93% | 86% |
| (f) | [21] | Proposed feature set + spectrogram | ResNet-50 + DNN | 94% | 93% | 94% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, M.-J.; Lee, S.-P. COVID-19 Diagnosis from Crowdsourced Cough Sound Data. Appl. Sci. 2022, 12, 1795. https://doi.org/10.3390/app12041795
Son M-J, Lee S-P. COVID-19 Diagnosis from Crowdsourced Cough Sound Data. Applied Sciences. 2022; 12(4):1795. https://doi.org/10.3390/app12041795
Chicago/Turabian StyleSon, Myoung-Jin, and Seok-Pil Lee. 2022. "COVID-19 Diagnosis from Crowdsourced Cough Sound Data" Applied Sciences 12, no. 4: 1795. https://doi.org/10.3390/app12041795
APA StyleSon, M. -J., & Lee, S. -P. (2022). COVID-19 Diagnosis from Crowdsourced Cough Sound Data. Applied Sciences, 12(4), 1795. https://doi.org/10.3390/app12041795