
Applying Deep Learning Models to Analyze Users’ Aspects, Sentiment, and Semantic Features for Product Recommendation


Abstract
:1. Introduction
- We propose a novel ADLRP method herein, which could effectively extract the aspect, sentiment, and semantic features from text reviews and combine these features with ratings for rating prediction. Our method integrates both implicit and explicit information to analyze user preferences and product features, and thus achieves better predictive performance.
- A blend of features can achieve more accurate user preferences and product evaluation features, thereby enabling merchants to better understand users’ preferences and provide them with more accurate product recommendations.
- The deep learning methods and attention mechanism used in our method can effectively extract and train the user and product features to improve the accuracy of rating prediction.
2. Related Works
2.1. Deep Learning Methods
2.1.1. Convolutional Neural Network
2.1.2. Recurrent Neural Network
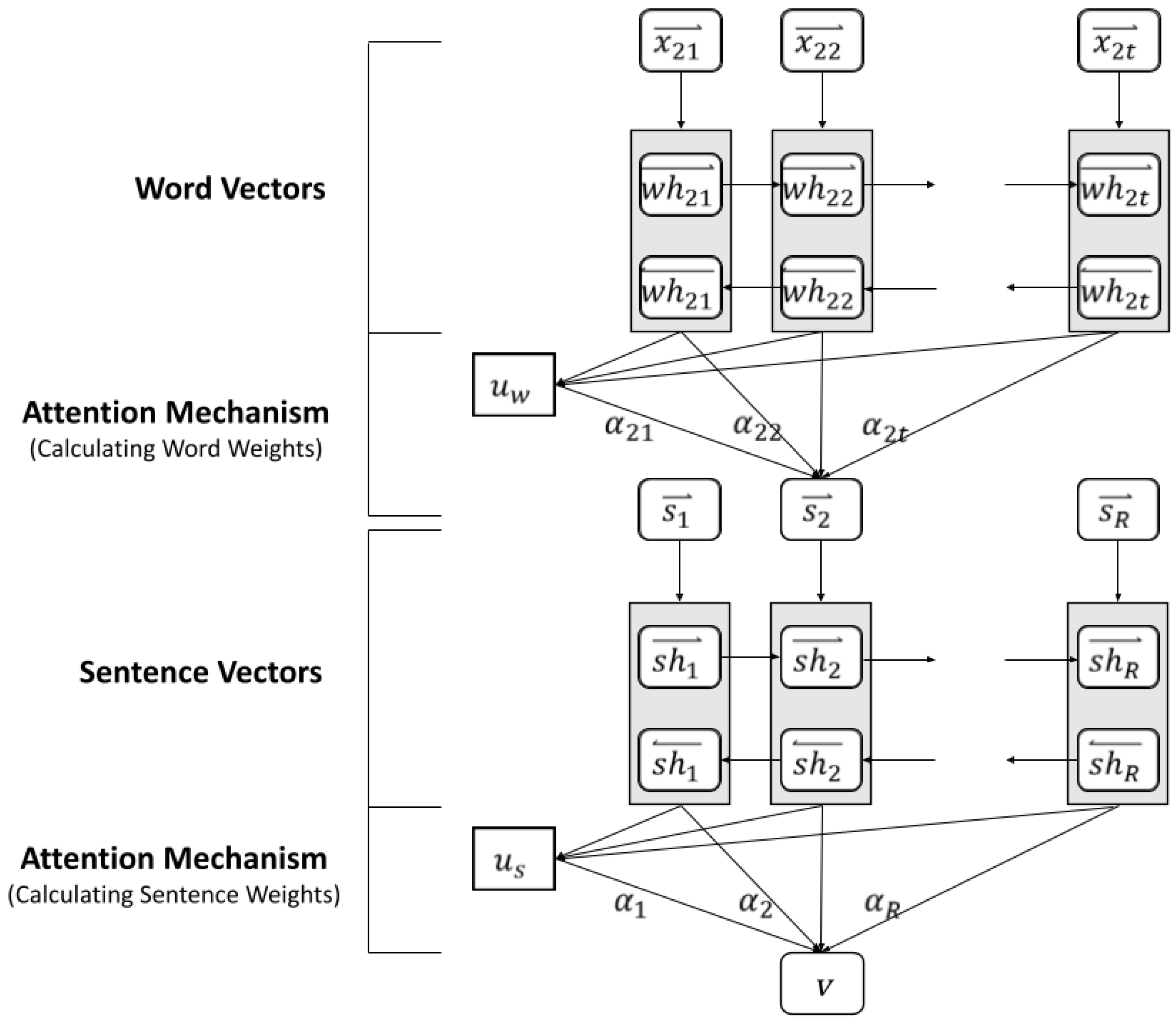
2.1.3. Attention Mechanism
2.2. Semantic and Sentiment Analysis
2.3. Matrix Factorization
3. The Proposed Method
3.1. Research Overview
3.2. Aspect Detection
3.3. Sentiment Analysis
3.3.1. Aspect Sentiment Intensity
3.3.2. Aspect Sentiment Vector
3.4. Semantic Analysis
3.5. User Preference Model
3.6. Product Evaluation Model
3.7. Rating Prediction
4. Experiment Evaluation
4.1. Data Collection
4.2. Evaluation Indicators
4.3. Experimental Results
4.3.1. Explanation of Experimental Methods
- Aspect-based Deep Learning Rating Prediction (ADLRP): The method proposed in this study. User and product reviews are analyzed, and aspect, aspect sentiment, aspect semantics, and other feature vectors are created. Through the training of the CNN, user latent factors and product latent factors are generated, and then matrix factorization is applied to predict ratings.
- Deep Collaborative Neural Networks-CNN (DeepCoNN-CNN): DeepCoNN-CNN [10] analyzes user reviews and product reviews, and then uses a CNN to generate user latent factors and product latent factors. Finally, the matrix factorization method is used to predict the ratings.
- Deep Collaborative Neural Networks-DNN (DeepCoNN-DNN): Similar to DeepCoNN-CNN, this method uses multilayer perceptron (MLP) to replace the CNN in DeepCoNN-CNN. This multilayer perceptron consists of two input layers (user and product reviews are input, respectively), three hidden layers, two fully connected layers (user latent factors and product latent factors are generated, respectively), and a final matrix decomposition layer for predicting ratings.
- AutoRec: AutoRec is based on collaborative filtering and Auto-Encoder to infer user ratings for unrated products, as based on the user-item matrix [48]. Auto-Encoder is an unsupervised learning algorithm and a three-layer artificial neural network with an input layer, a hidden layer, and an output layer.
- Matrix Factorization (MF): As a latent factor model, the matrix decomposition method mainly decomposes the user-item matrix into user and product latent factor matrices [16]. These two latent factor matrices are then inner-produced to calculate the predicted user-item ratings.
- Non-Negative Matrix Factorization (NMF): Similar to the MF method, NMF is a matrix decomposition method under the restriction that all elements of the matrix are non-negative [51]. As the true rating of users is non-negative, NFM ensures that the decomposed latent factors are also non-negative.
- Singular Value Decomposition (SVD++): Singular Value Decomposition (SVD) is a common matrix decomposition technique. In the collaborative filtering method, SVD decomposes the user feature matrix and item feature matrix to predict the ratings, based on the existing user-item matrix. SVD++ [47], an extension of SVD, adds users’ latent factors to the user-item matrix to increase prediction accuracy.
- Aspect-aware Latent Factor Model (ALFM): The latent topics are extracted from reviews by using the aspect-aware topic model (ATM) to model users’ preferences and items’ features in different aspects [52]. Then, based on the latent factors, the aspect importance of a user towards an item is evaluated and linearly combined with the aspect ratings in the ALFM method to calculate the overall ratings.
4.3.2. Effect of Aspect Number on Rating Prediction
- Assume that the number of input aspects was n. The number of filters F was adjusted from 2 to n and increased to the power of 2. Based on the prediction accuracy, the optimal number of filters was decided.
- The moving pace S was set from 1 to 6 to determine the optimal moving pace.
- For the activation functions of the convolutional layer and fully connected layer, three activation functions: Sigmoid, tanH, and ReLu, were set, respectively. The best activation function was decided based on the experimental results.
- The optimizers were set as Adadelta, Adagrad, SGD, and Adam, respectively. The optimal optimizer was decided based on the experimental results.
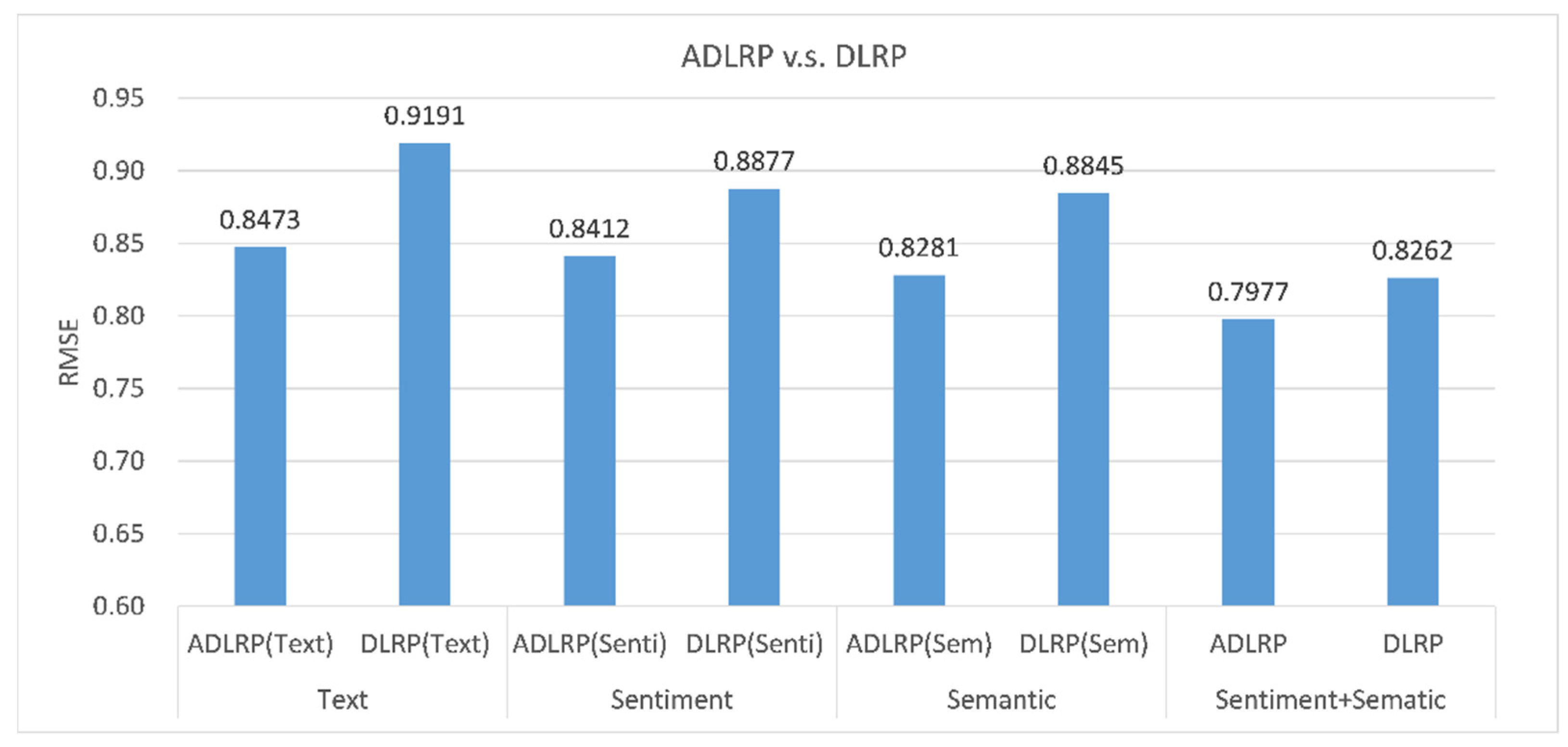
4.3.3. Effects of Aspect, Sentiment, and Semantic Features on Rating Prediction
- ADLRP (Text): This method only considers aspect vectors for rating predictions.
- ADLRP (Sem): This method integrates the aspect vectors (i.e., Section 3.2) and aspect semantic vectors (i.e., Section 3.5) for rating prediction.
- ADLRP (Senti): This method integrates the aspect vectors (i.e., Section 3.2) and aspect sentiment vectors (Section 3.3.2) for rating prediction.
- ADLRP: This method integrates aspect vectors, sentiment vectors, and semantic vectors, and uses a CNN for rating prediction.
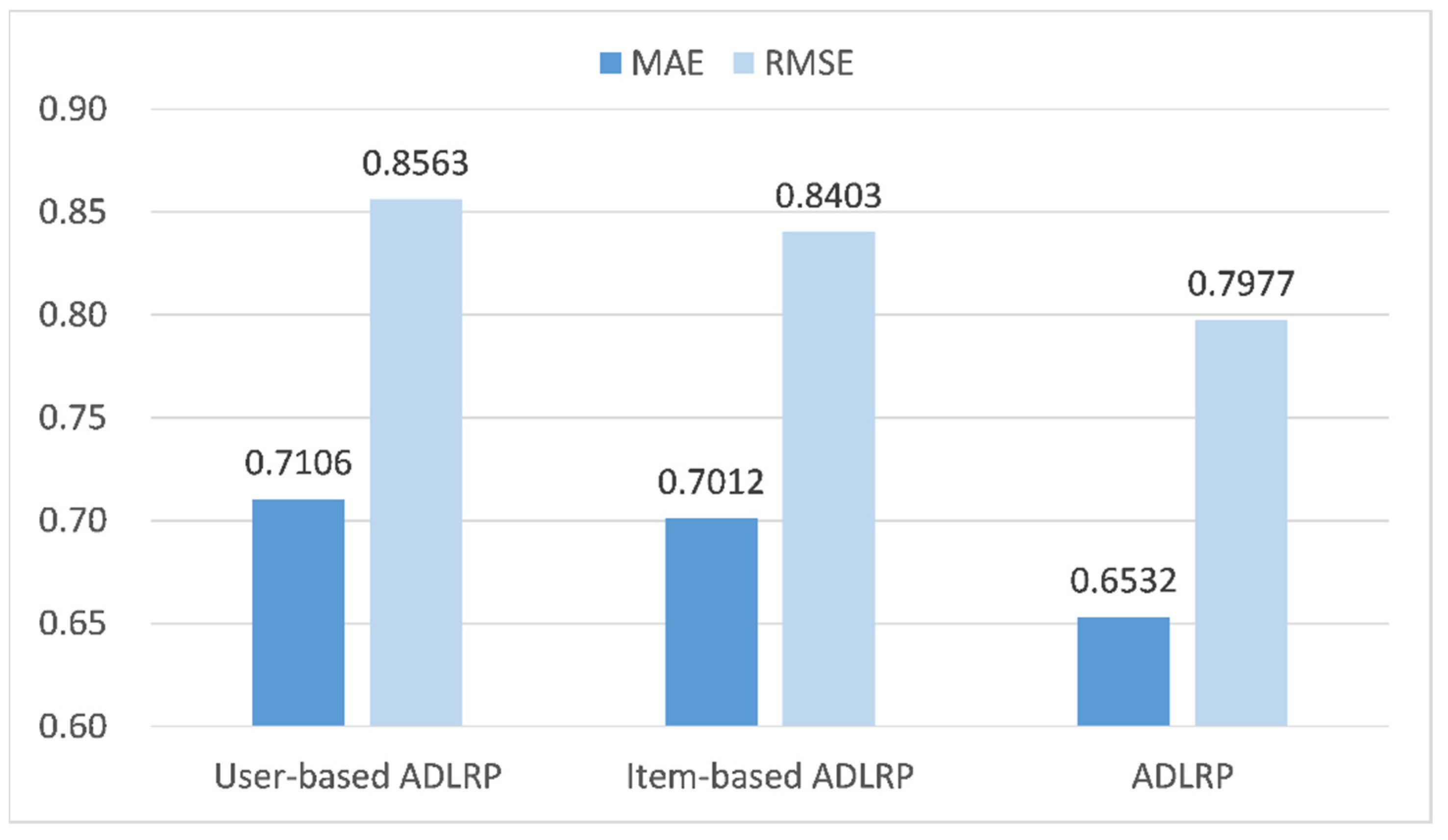
4.3.4. Comparison of User-Based and Product-Based Prediction Methods
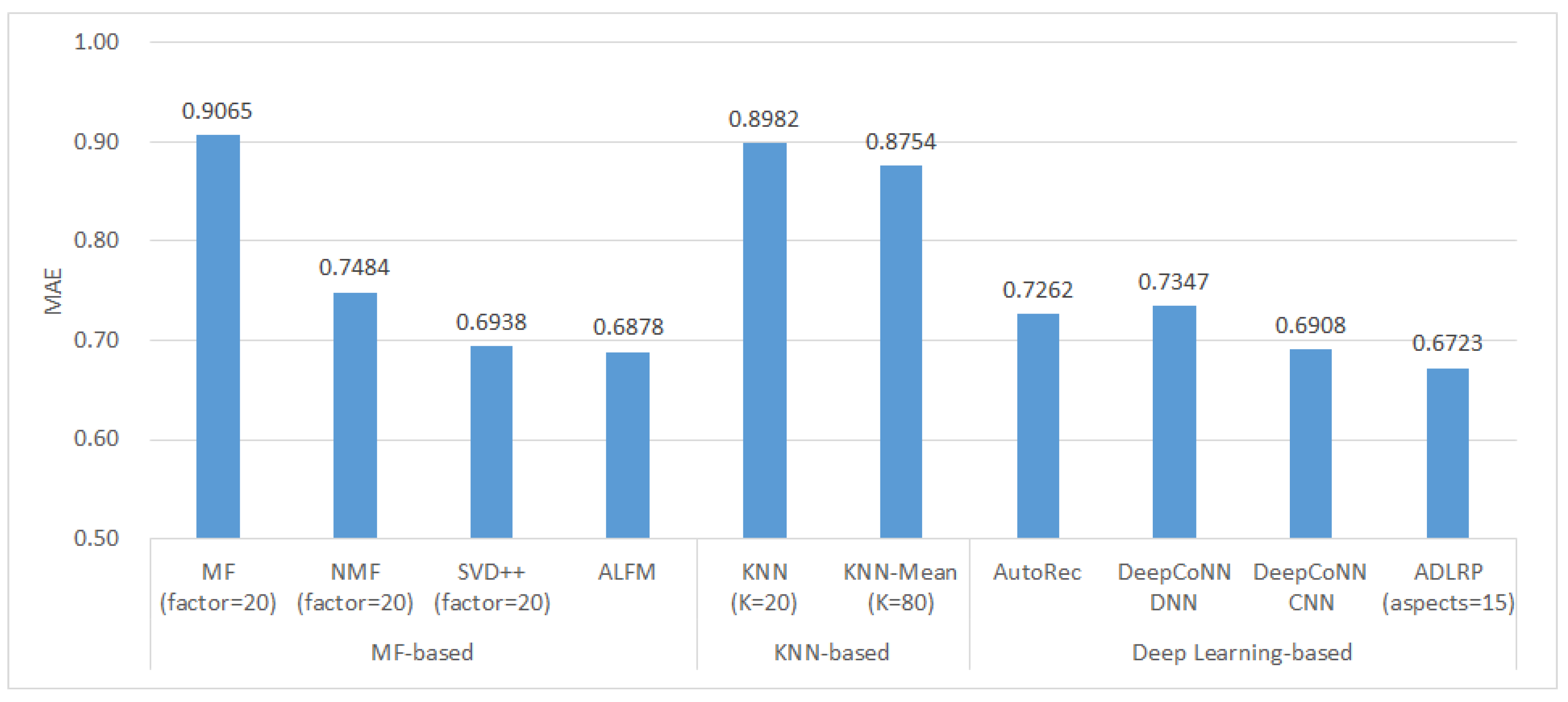
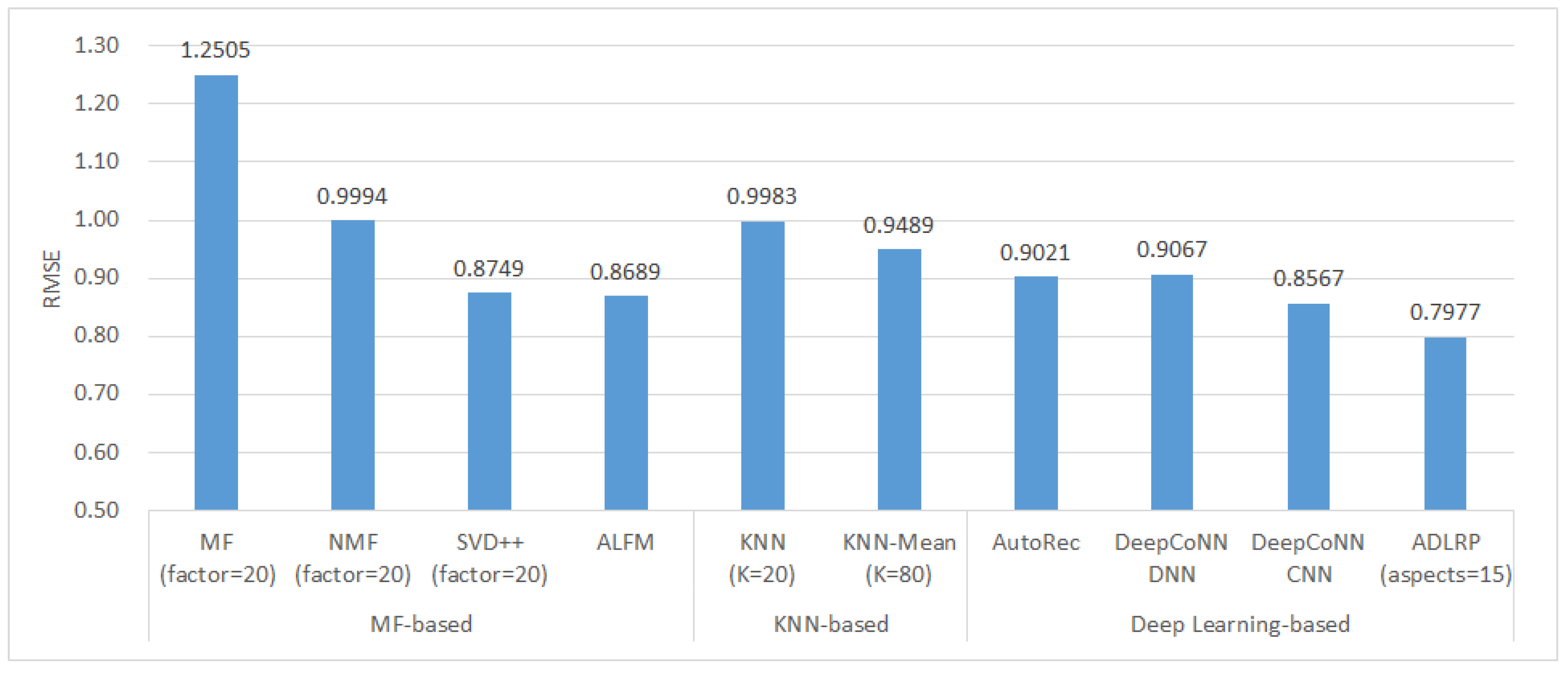
4.3.5. Comparison of Rating Prediction Methods
- Matrix factorization methods: MF, NMF, SVD++, and ALFM.
- Nearest neighbor methods: KNN and KNN-Mean.
- Deep learning methods: AutoRec, DeepCoNN-DNN, DeepCoNN-CNN, and ADLRP.
5. Conclusions and Future Studies
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Konstan, J.A.; Miller, B.N.; Maltz, D.; Herlocker, J.L.; Gordon, L.R.; Riedl, J. GroupLens: Applying Collaborative Filtering to Usenet News. Commun. ACM 1997, 40, 77–87. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Borchers, A.; Riedl, J. An algorithmic framework for performing collaborative filtering. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 230–237. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Reidl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the Tenth International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Melville, P.; Mooney, R.J.; Nagarajan, R. Content-boosted collaborative filtering for improved recommendations. In Proceedings of the Eighteenth National Conference on Artificial Intelligence, Edmonton, AB, Canada, 28 July–1 August 2002; pp. 187–192. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Jo, Y.; Oh, A.H. Aspect and sentiment unification model for online review analysis. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 815–824. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A.F. Aspect Extraction for Opinion Mining with a Deep Convolutional Neural Network. Knowl.-Based Syst. 2016, 108, 42–49. [Google Scholar] [CrossRef]
- Li, Q.; Li, X.; Lee, B.; Kim, J. A Hybrid CNN-Based Review Helpfulness Filtering Model for Improving E-Commerce Recommendation Service. Appl. Sci. 2021, 11, 8613. [Google Scholar] [CrossRef]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Representation learning of users and items for review rating prediction using attention-based convolutional neural network. In Proceedings of the 3rd International Workshop on Machine Learning Methods for Recommender Systems, Houston, TX, USA, 27–29 April 2017. [Google Scholar]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint Deep Modeling of Users and Items Using Reviews for Recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Tang, D.; Qin, B.; Liu, T. Learning Semantic Representations of Users and Products for Document Level Sentiment Classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 1014–1023. [Google Scholar]
- Farkhod, A.; Abdusalomov, A.; Makhmudov, F.; Cho, Y.I. LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS) Model. Appl. Sci. 2021, 11, 11091. [Google Scholar] [CrossRef]
- Bradley, M.M.; Lang, P.J. Affective Norms for English Words (ANEW): Instruction Manual and Affective Ratings; University of Florida: Gainesville, FL, USA, 1999; pp. 25–36. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Khan, Z.Y.; Niu, Z.; Sandiwarno, S.; Prince, R. Deep learning techniques for rating prediction: A survey of the state-of-the-art. Artif. Intell. Rev. 2021, 54, 95–135. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Wang, J.; Yu, L.-C.; Lai, K.R.; Zhang, X. Dimensional Sentiment Analysis Using a Regional CNN-LSTM Model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 225–230. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning Long-term Dependencies with Gradient Descent is Difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Wang, Y.; Huang, M.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Cao, R.; Zhang, X.; Wang, H. A Review Semantics Based Model for Rating Prediction. IEEE Access 2020, 8, 4714–4723. [Google Scholar] [CrossRef]
- Liu, W.; Lin, Z.; Zhu, H.; Wang, J.; Sangaiah, A.K. Attention-Based Adaptive Memory Network for Recommendation with Review and Rating. IEEE Access 2020, 8, 113953–113966. [Google Scholar] [CrossRef]
- Hinton, G.E.; McClelland, J.L.; Rumelhart, D.E. Distributed representations. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; David, E.R., James, L.M., Group, C.P.R., Eds.; MIT Press: Cambridge, MA, USA, 1986; Volume 1, pp. 77–109. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Seattle, WA, USA, 18–21 October 2013; pp. 1059–1069. [Google Scholar]
- Porcel, C.; Moreno, J.M.; Herrera-Viedma, E. A Multi-Disciplinar Recommender System to Advice Research Resources in University Digital Libraries. Expert Syst. Appl. 2009, 36, 12520–12528. [Google Scholar] [CrossRef]
- Kamyab, M.; Liu, G.; Adjeisah, M. Attention-Based CNN and Bi-LSTM Model Based on TF-IDF and GloVe Word Embedding for Sentiment Analysis. Appl. Sci. 2021, 11, 11255. [Google Scholar] [CrossRef]
- Dang, C.N.; Moreno-García, M.N.; De la Prieta, F. Using Hybrid Deep Learning Models of Sentiment Analysis and Item Genres in Recommender Systems for Streaming Services. Electronics 2021, 10, 2459. [Google Scholar] [CrossRef]
- Baccianella, S.; Esuli, A.; Sebastiani, F. SentiWordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC'10), Valletta, Malta, 17–23 May 2010; pp. 2200–2204. [Google Scholar]
- Cambria, E.; Olsher, D.; Rajagopal, D. SenticNet 3: A common and common-sense knowledge base for cognition-driven sentiment analysis. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1515–1521. [Google Scholar]
- Dong, Z.; Dong, Q.; Hao, C. HowNet and the Computation of Meaning. In Proceedings of the 23rd International Conference on Computational Linguistics: Demonstrations, Beijing, China, 23–27 August 2010; pp. 53–56. [Google Scholar]
- Hamouda, A.; Rohaim, M. Reviews classification using SentiWordNet lexicon. Online J. Comput. Sci. Inf. Technol. (OJCSIT) 2011, 2, 120–123. [Google Scholar]
- Baltrunas, L.; Ludwig, B.; Ricci, F. Matrix factorization techniques for context aware recommendation. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 301–304. [Google Scholar]
- Zhang, X.; Liu, H.; Chen, X.; Zhong, J.; Wang, D. A novel hybrid deep recommendation system to differentiate user’s preference and item’s attractiveness. Inf. Sci. 2020, 519, 306–316. [Google Scholar] [CrossRef]
- Wu, D.; Shang, M.; Luo, X.; Wang, Z. An L₁-and-L₂-Norm-Oriented Latent Factor Model for Recommender Systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–14. [Google Scholar] [CrossRef]
- Luo, X.; Yuan, Y.; Chen, S.; Zeng, N.; Wang, Z. Position-Transitional Particle Swarm Optimization-incorporated Latent Factor Analysis. IEEE Trans. Knowl. Data Eng. 2020, 1. [Google Scholar] [CrossRef]
- Wu, D.; He, Q.; Luo, X.; Shang, M.; He, Y.; Wang, G. A Posterior-neighborhood-regularized Latent Factor Model for Highly Accurate Web Service QoS Prediction. IEEE Trans. Serv. Comput. 2019, 1. [Google Scholar] [CrossRef]
- Wu, D.; Luo, X.; Shang, M.; He, Y.; Wang, G.; Wu, X. A Data-Characteristic-Aware Latent Factor Model for Web Services QoS Prediction. IEEE Trans. Knowl. Data Eng. 2020, 1. [Google Scholar] [CrossRef]
- Zhang, Y.; Ai, Q.; Chen, X.; Croft, W.B. Joint Representation Learning for Top-N Recommendation with Heterogeneous Information Sources. In Proceedings of the ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1449–1458. [Google Scholar]
- Yin, W.; Schütze, H.; Xiang, B.; Zhou, B. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs. Trans. Assoc. Comput. Linguist. 2016, 4, 259–272. [Google Scholar] [CrossRef]
- Li, F.; Wu, B.; Xu, L.; Shi, C.; Shi, J. A fast distributed stochastic Gradient Descent algorithm for matrix factorization. In Proceedings of the 3rd International Conference on Big Data, Streams and Heterogeneous Source Mining: Algorithms, Systems, Programming Models and Applications, New York, NY, USA, 24 August 2014; pp. 77–87. [Google Scholar]
- Zhuang, Y.; Chin, W.-S.; Juan, Y.-C.; Lin, C.-J. A fast parallel SGD for matrix factorization in shared memory systems. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 249–256. [Google Scholar]
- Koren, Y. Factorization Meets the Neighborhood: A Multifaceted Collaborative Filtering Model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders Meet Collaborative Filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Park, Y.; Park, S.; Jung, W.; Lee, S.-G. Reversed CF: A Fast Collaborative Filtering Algorithm Using a K-nearest Neighbor Graph. Expert Syst. Appl. 2015, 42, 4022–4028. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, W.; Ford, J.; Makedon, F. Learning from incomplete ratings using non-negative matrix factorization. In Proceedings of the SIAM International Conference on Data Mining, Bethesda, MD, USA, 20–22 April 2006; pp. 549–553. [Google Scholar]
- Cheng, Z.; Ding, Y.; Zhu, L.; Kankanhalli, M. Aspect-Aware Latent Factor Model: Rating Prediction with Ratings and Reviews. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 639–648. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect Number | F | S | O | MAE | RMSE | ||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | tanH | ReLu | Adam | 0.7528 | 0.9191 |
| 4 | 4 | 2 | tanH | ReLu | Adam | 0.7015 | 0.9148 |
| 6 | 6 | 2 | tanH | ReLu | Adam | 0.7195 | 0.9324 |
| 10 | 2 | 2 | tanH | ReLu | Adam | 0.6772 | 0.8384 |
| 15 | 2 | 4 | tanH | ReLu | Adam | 0.6532 | 0.7977 |
| 20 | 2 | 5 | tanH | ReLu | Adam | 0.6611 | 0.8441 |
| 25 | 1 | 4 | tanH | ReLu | Adam | 0.6673 | 0.8462 |
| 35 | 1 | 5 | tanH | ReLu | Adam | 0.6714 | 0.8585 |
| 45 | 45 | 5 | tanH | ReLu | Adam | 0.7543 | 0.9580 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, C.-H.; Tseng, K.-C. Applying Deep Learning Models to Analyze Users’ Aspects, Sentiment, and Semantic Features for Product Recommendation. Appl. Sci. 2022, 12, 2118. https://doi.org/10.3390/app12042118
Lai C-H, Tseng K-C. Applying Deep Learning Models to Analyze Users’ Aspects, Sentiment, and Semantic Features for Product Recommendation. Applied Sciences. 2022; 12(4):2118. https://doi.org/10.3390/app12042118
Chicago/Turabian StyleLai, Chin-Hui, and Kuo-Chiuan Tseng. 2022. "Applying Deep Learning Models to Analyze Users’ Aspects, Sentiment, and Semantic Features for Product Recommendation" Applied Sciences 12, no. 4: 2118. https://doi.org/10.3390/app12042118
APA StyleLai, C. -H., & Tseng, K. -C. (2022). Applying Deep Learning Models to Analyze Users’ Aspects, Sentiment, and Semantic Features for Product Recommendation. Applied Sciences, 12(4), 2118. https://doi.org/10.3390/app12042118