1. Introduction
Recently, human action detection has become increasingly important in a variety of industries, such as healthcare for elders. A wide variety of devices for human activity recognition have been proposed, including cameras, wearable devices, lidar, and radar.
Tufek et al. [
1] recognized daily activities using wearable sensors, which were implemented with accelerometers, gyroscopes, and wireless radio frequency modules. A three-layer long short-term memory (LSTM) model with a data balancing algorithm was used on the UCI HAR benchmark dataset, and the ETEXWELD dataset was collected. Although the model achieved high accuracy rates, wearable devices must be worn on body parts, such as the chest, during data collection, which can be quite cumbersome during actual use.
Li et al. [
2] proposed vision-based fall detection methods that worked on recorded videos or real-time video streams. Three algorithmic pipelines for multi-level tasks were designed, where the pipelines consisted of the frame-level algorithm pipeline (FLAP), the sequence-level algorithm pipeline (SLAP), and the video-level algorithm pipeline (VLAP), and each pipeline focused on a different feature representation. For example, for the sequence level fall detection (SLFD) task, the authors proposed a dynamic pose motion (DPM) representation to capture a flexible motion extraction module. However, such approaches that use cameras have the problem of privacy invasion.
Lidar and radar have often been compared in the study of human activity recognition. Luo et al. [
3] proposed using a 2D lidar to recognize human activities by classifying people’s motion trajectories. They used spatial transformation and Gaussian noise for trajectory augmentation. Then, two neural networks, including an LSTM network and a temporal convolutional network (TCN), were used on trajectory samples collected from a kitchen. These two networks outperformed the hidden Markov model (HMM), dynamic time warping (DTW), and support vector machine (SVM) by a wide margin.
Radar has several advantages over lidar. First, it is not strongly affected by weather conditions. The radio waves used in radar have a small degree of absorption, so this technology can work well even under bad weather conditions, whereas lidar is vulnerable to weather, such as fog and snow. Second, miniaturization technology is also more highly developed for radar than for lidar. Therefore, radar has been widely used in the defense field, such as in fighter jets, which must operate even in bad weather.
One disadvantage of radar is that it produces rather sparse data, because the radio waves emitted by radar have weak straightness. In addition to wavelength problems, inherent noise is also a cause of the sparsity in radar data [
4]. Accordingly, many studies have investigated ways to effectively combine radar with camera sensors to perform more accurate detection and object identification than is possible using radar alone. With the impressive growth of machine learning and deep learning techniques, new methods for processing sparse radar data have been proposed.
Singh et al. [
5] selected voxelization to pre-process radar data and achieved greater than 90% accuracy with deep learning classifiers. Sengupta et al. [
6] also adopted a voxelization method, and in order to predict skeletal key points, mmPose-NLP (Natural Language Processing) architecture, which employed extracted features from the voxelized data, was presented.
Excluding voxelization, artificial sampling and grouping methods for radar data have also been considered. An et al. [
7] collected the following five radar data elements: the spatial coordinates of the point (x, y, z), Doppler velocity, and signal intensity. They transformed raw radar data into a 3D five-channel stacked feature map instead of using voxelization. These feature maps were fed to a simple convolution neural network (CNN) model called MARS to predict 19 human joints. The 2D form can also be used. Alujaim et al. [
8] measured seven different human motions using a 2D planar phased array. The motions were processed using a deep convolutional neural network (DCNN) and achieved above 90% accuracy on both the training and validation datasets. Sun et al. [
9] attempted to produce dense and smooth point clouds. They resampled the number of points in a frame to achieve a fixed number of points in each frame. The Agglomerative Hierarchical Clustering (AHC) was used for upsampling, while the K-means algorithm was used for downsampling. In the AHC algorithm, each cluster’s centroid was added to the point cloud as a new point until reaching a fixed number of points in an experiment. On the other hand, the K-means algorithm made the fixed number of points (K) per frame and selected the centroids of the clusters as the data points in the point cloud. However, in this method, there is a problem that duplicate values occur when the number of point clouds in the collected data is less than half of the fixed number of points.
In this paper, we introduce a new model to solve these challenges without using a combination of radar and other sensors or converting radar data into regular voxels.
First, we address the sparsity of radar data. Most previous studies have proposed voxelization-based approaches. However, the voxelization process involves high computational cost. Furthermore, to improve the generality of the proposed model, a new method that only requires the 3D coordinates of radar data and demands low computation is proposed. Other data, such as Doppler and intensity data, do not need to be pre-processed, and therefore do not incur a high computational cost. We develop a pre-trained model that represents 25 human body joints to map point clouds to Kinect data [
7]. The pre-trained model is used to extract 3D human joint coordinate estimates from radar data. Second, considering each joint point as a vertex of a graph, and the line connecting the adjacent joints as an edge in the graph, we propose a classification model based on graph neural networks (GNNs) [
10] using these estimates. The main contributions of this paper are as follows:
We propose a novel human activity recognition model that uses estimated 3D human joint coordinate data from sparse radar data with low computational cost, rather than other complex pre-processing methods, such as voxelization.
We design a spatial-temporal graph convolutional network (ST-GCN)-based model to predict human activities by optimized spatio-temporal feature extraction.
We demonstrate improved performance by our model on the task of human activity recognition. Our model achieves 96% accuracy, which is better than the accuracy of the existing baseline models [
5].
This paper is organized as follows.
Section 2 describes relevant previous work.
Section 3 introduces the dataset used in this research and explains our proposed model. The performance results are discussed in
Section 4. Finally,
Section 5 provides the conclusions drawn from the presented approach and describes our future work.
2. Related Work
Many studies have been conducted using mmWave radar to detect human action. Most of these studies have focused on pre-processing data to improve the classification. Because the format of the data received by radar differs depending on the experimental setting [
11,
12] or the data collection tool used, the pre-processing method is not unified.
Singh et al. [
5] used a TI IWR1443 mmWave radar and collected radar data using a robot operating system (ROS) package [
13] as follows: the number of point clouds, spatial coordinates of the points (x, y, z), range, velocity, Doppler bin, bearing, and intensity. They selected voxelization to pre-process these data, and each sample had the dimensions 60 × 10 × 32 × 32 (depth = 10). These dimensions were decided empirically by testing the model performance. After voxelization, five classifiers were evaluated: SVM, multi-layer perceptron (MLP), LSTM, and CNN combined with LSTM. Overall, all proposed machine learning approaches showed a high performance of up to 90.47%. However, the dimensionality of each input sample (60 × 10 × 32 × 32 = 614,400) meant that the voxelization method resulted in significant increases in the memory requirements.
Sengupta et al. [
6] also pre-processed radar data in a voxelized form. One difference from [
5] is that Sengupta et al. regarded this process as equivalent to the tokenization of natural language processing (NLP). After extracting features from the voxelized data, skeletal key points were predicted using a proposed mmPose-NLP architecture. They compared these predictions with the ground truth obtained from Kinect. However, the problem of high computation cost remains, because the process takes two steps: voxelization of the radar point cloud data, and conversion back to real-world 3D coordinates using a voxel dictionary.
An et al. [
7] used TI IWR1443 Boost mmWave radar and a MATLAB runtime implementation from TI [
14] for data acquisition. The raw radar data were transformed, without voxelization, into a 3D five-channel stacked feature map by the pre-processing method proposed. The channels of the feature map consisted of the spatial coordinates (x, y, z), Doppler velocity, and signal intensity. Because the authors fixed the number of point clouds to 64 per frame, 64 rows were converted to an 8 × 8 square matrix in the row-major order. These feature maps were regarded as images commonly used in CNNs. They were then fed to a simple CNN model called MARS, which predicted 19 human joints. In contrast to previous studies, there was no complicated pre-processing [
15,
16,
17] or large model that caused an increase in the number of parameters. Therefore, the computational cost was relatively low.
Instead of 3D, a 2D form also could be used. Human motion detection using a 2D planar array was proposed in [
8]. Seven human motions, including bowing, kicking, punching, walking, running, sitting down, and standing, were measured using a 2D planar phased-array FMCW radar. A DCNN was used to process the array and capture the time-varying signatures of the point clouds. The training accuracy was 100%, and the validation accuracy was 80%.
This previous work shows that human activity recognition by radar must focus on obtaining reliable data from a radar. Most of the methods involved voxelization, but more simple methods without voxelization, as used in [
7,
8], have also been suggested.
As described in [
6,
7,
18], once radar data are converted to a human joint position, there are many classification models that could be applied. Because each joint corresponds to a vertex of a graph, and the bone connecting adjacent joints corresponds to an edge, this human joint (or skeleton) form can be regarded as a graph structure. Thus, human activity recognition can be implemented using a GNN-based model [
10].
Yan et al. [
19] proposed the ST-GCN to recognize human activities through skeleton data. ST-GCN allowed the same human joints to be connected along the time axis, so that the graph structure included temporal information in addition to spatial information. Using this approach, the relationship between skeleton joints within one activity was automatically learned, which helped to classify human activity. To verify the necessity of features in the spatio-temporal domain, a basic GCN-based model [
20] was tested, and the results are compared in
Section 4.
3. Methodology
In this section, we introduce a human activity recognition model that used 3D human joint coordinate estimates from sparse radar data. First, we demonstrate how the sparsity of radar data was addressed. Due to the limitations of radio wavelength and inherent noise, radar data were sparse. We focus on this problem first.
Another problem authors consider is that data formats are related to the data collection tools used. Therefore, many prior studies designed a pre-processing method to fit each type of dataset.
Considering these two problems, we developed a more general method that used only the 3D coordinates of radar data, called point clouds, and so can be used for any dataset. Using this process, reliable features were extracted from sparse radar data. Second, we presented an ST-GCN-based model. To extract additional features in the spatio-temporal domain from joint coordinate estimates, we fed these joint estimates to an ST-GCN [
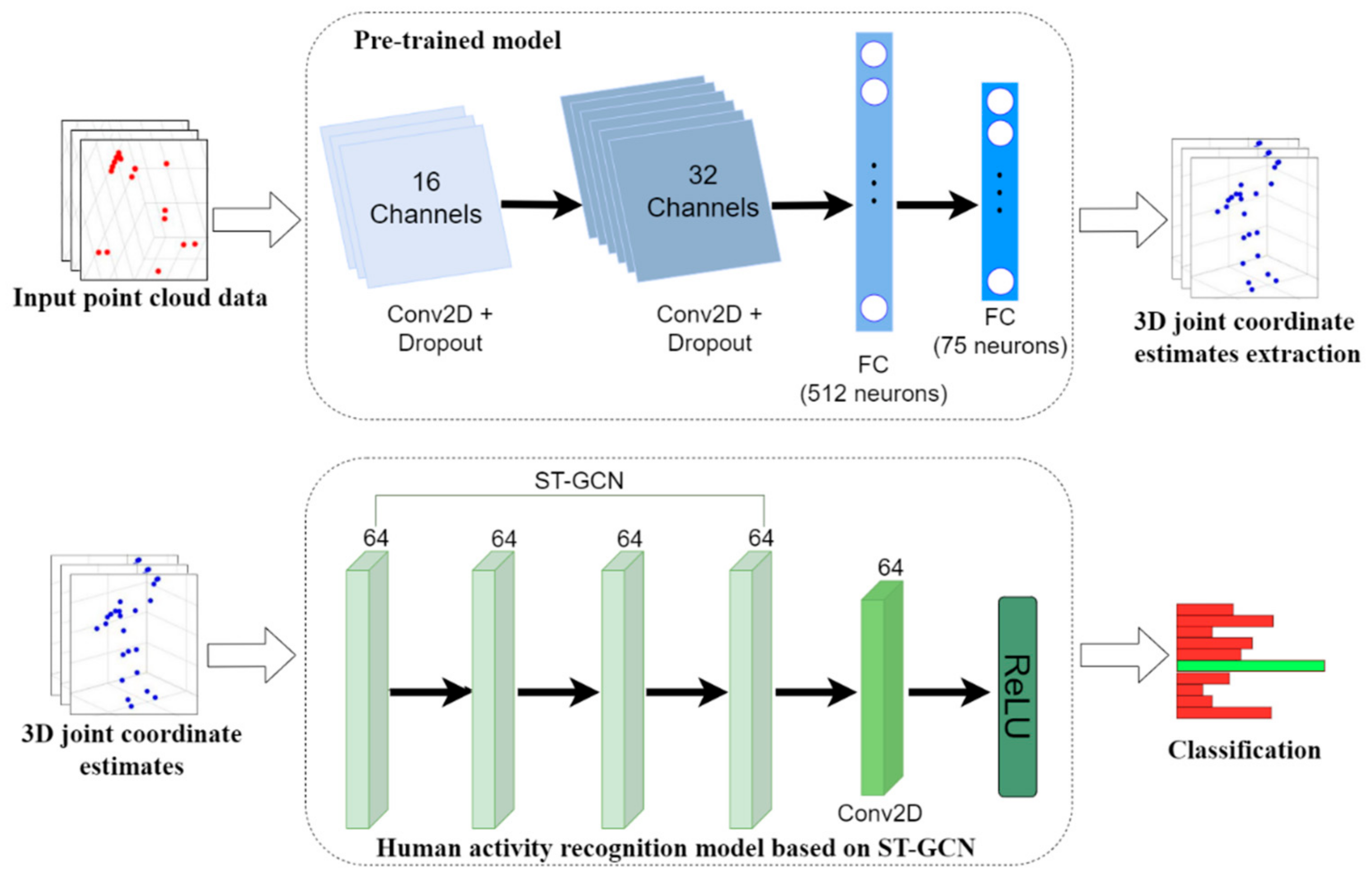
19]. The entire architecture is illustrated in
Figure 1.
3.1. Datasets
MARS. First of all, we selected the MARS dataset [
7] (MARS is available at
https://github.com/SizheAn/MARS, accessed on 25 October 2021). A MARS dataset was collected using both an IWR1443 Boost mmWave radar and a Kinect V2 sensor. Each participant engaged in one action listed in
Table 1 for approximately two minutes. During that time, both Kinect and radar were placed on the same table. MATLAB Runtime from TI was used for the radar data acquisition. In the case of the Kinect V2 sensor, we used MATLAB to process the Kinect data as the 3D coordinates of human joints. The total number of participants was two, and the experimenters adjusted the sampling rate between the IWR1443 Boost mmWave radar and the Kinect V2 in order to map the radar data to the skeleton data by frame.
To the best of our knowledge, this is the first dataset that is provided in raw format without any other pre-processing, such as voxelization. In this work, the ground truth was the participant’s joint positions captured by the Kinect V2 sensor during the experiment.
MMActivity. MMActivity [
5] provides only radar data collected from TI IWR1443 mmWave radar. Five different activities detected using MMActivity are described in
Table 2. Two participants performed each activity in front of the radar for 20 s. In this experiment, the sampling rate was adjusted to obtain 30 frames of data per second. Data, including the 3D coordinates from the participants, range, Doppler bin, bearing, and intensity, were collected. In one frame, 20–30 data items were observed. Data were collected using a robot operating system (ROS) package [
13] and it is available at
https://github.com/nesl/RadHAR, accessed on 30 October 2019).
3.2. Pre-Training for 3D Human Joint Coordinate Estimates
As mentioned in
Section 1, the radar emits radio waves. The radar radiates the transmission signal through the Tx antennas. This signal hits the object and returns back through the Rx antennas. The radar chip then calculates the object’s 3D coordinates, which are converted to a point cloud using a fast Fourier transform. Therefore, the 3D coordinates are necessarily stored. We decided to create a model that used these 3D coordinates to produce a more generally applicable model. We checked the raw 3D coordinates of the radar data. However, they were too sparse to be used to classify human activity. This sparsity problem can occur depending on the movements, because radar usually does not generate data for a static posture well. Thus, a new method that extracts more reliable features from radar data using a pre-trained model was developed.
First, we needed to pre-process the MARS dataset [
7]. In the MARS dataset, the x, y, z, Doppler, and intensity were collected as radar data. Thus, we removed the Doppler and intensity and empirically fixed the number of point clouds to 25 per frame. If there were fewer than 25 points, the rest of the frame was padded with zeros. We then reshaped a 5 × 5 × 3 matrix as shown in
Figure 2, in which three channels represent x, y, and z. This 5 × 5 × 3 matrix in one frame was paired with the Kinect data in the same frame.
The pre-trained model that the authors [
7] used consisted of 2 consecutive convolution layers with 16 and 32 channels, and 2 consecutive fully connected layers with 512 neurons and 75 neurons, as shown in
Figure 1. Originally, because the final output of the pre-trained model [
7] contained 57 neurons, 19 human joint estimates were obtained. It was confirmed that 6 joints were dropped from given raw dataset in the training, validation, and test sets, even though the raw dataset included 25 joints. The differences between the 19 joints used in [
7] and the 25 joints are illustrated in
Figure 3. As shown in
Figure 3, the removed joints were the six points as follows: left hand, right hand, a tip of the left hand, left thumb, a tip of the right hand, and right thumb. To investigate the effectiveness of the 25 joints, 2 consecutive frames are visualized in
Figure 4. The activity was a left upper limb extension on the MARS dataset [
7].
However, for the data shown in
Figure 4, distinguishing between the left activity and the right activity was very difficult with 19 joints. In addition to this simple visual diagram, the ablation study showed that the 25 joints give a more suitable feature representation of human joints, so we decided to use the 25 joints to provide more detailed information relevant to activity classification. Therefore, the number of neurons in the last layer was modified to extract more features from the radar data. We identified the frame numbers that were randomly selected in [
7] and created new training, validation, and test sets that included the 25 joints.
The model was pre-trained with this pre-processed data using a batch size of 64 for 110 epochs. The other parameters were the same as were used in [
7], and Adam was used as the optimizer with an initial learning rate of 0.001. After pre-training, we tested the model’s performance using the point cloud data in MMActivity [
5]. The x, y, and z data sorted in frame order were converted to 3D human joint coordinate estimates. The MMActivity [
5] dataset did not collect reference data from the Kinect root-mean-squared error sensor. Hence, the loss function metrics for evaluation, such as the MAE and RMSE, could not be defined in this process. The reconstructed 25 joints in boxing, jack, jumping, squats, and walk activities of the MMActivity dataset [
5] are shown in
Figure 5. The left figure represents the point cloud generated by radar in each activity and the right figure represents the 25 human joint coordinate estimates from the pre-trained model. The successful reconstruction of 25 human joints from the point cloud was observed.
3.3. Proposed Human Activity Recognition Model
We propose a novel human activity recognition model that combines this pre-processing method with GNNs. Human activity recognition was conducted using these joint estimates as inputs to the GNNs. Two models were developed. One was a combination of 3D human joint estimates and a GCN, and the other was a combination of 3D human joint estimates and an ST-GCN.
3.3.1. Human Activity Recognition Model Based on GCN
Among the many models that work on graph data, the GCN is the most basic, powerful type of neural network. The inspiration behind the GCN was the CNN. CNNs have two important characteristics [
21]. The first is weight sharing. In a CNN, learnable filters at each layer scan a certain receptive field of the image. As the filter moves through the image, the filter does not change, so every neighborhood of the image is processed by the same learnable filter. This process is known as weight sharing. Second, because of the weight sharing, the pixels of the activation map that is output by the convolutional layers are correlated. In the GCN, the features of the nodes determine the classification of the graph. Therefore, the node features are updated with the same weight (weight sharing), as shown in Equation (1):
According to [
20],
is the adjacency matrix of the undirected graph with added self-connections.
is the identity matrix, and the degree matrix
is a layer-specific trainable weight matrix, and this same weight matrix is applied throughout the
, where
is the matrix of activations in the
layer.
3.3.2. Human Activity Recognition Model Based on ST-GCN
ST-GCN shows good performance in general, and it considers spatial and temporal dependencies. In the graph
G = (
V,
E),
V is the node set of joints, and
E denotes both spatial edges connecting the body joints in one frame and temporal edges connecting each body joint over consecutive frames. We assume that the number of joints is
N, the number of frames is
T, and
V = {
vti|
t = 1,…,
T,
i = 1,…,
N}. Based on [
22] and using a specific criterion, we group one root node and its neighbors into a partition set
. Then, a spatial-temporal block is expressed as follows:
where
, and the rest of the notations are the same as in a GCN. A 2D-convolutional layer is also added.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}