
A Rule-Based Grapheme-to-Phoneme Conversion System


Abstract
:1. Introduction
2. Problem Formulation
3. Methodology
3.1. Conversion Rules
- For each orthographic string , where and , the grapheme-to-phoneme conversion process is defined as the assignment .
3.2. Conversion Algorithm
- (1)
- Read an input orthographically represented word , where and ;
- (2)
- At the beginning of the orthographically represented word , let ;
- (3)
- Read a single letter of the input word ;
- (4)
- Check the context of the letter in the word :
- Read a string of letters preceding the orthographic letter;
- Read a string of letters following the orthographic letter;
- (5)
- Select the appropriate grapheme-to-phoneme conversion rule table for the orthographic letter ;
- (6)
- Select the appropriate j-th table’s column for the orthographic letter , where ;
- (7)
- Select the appropriate i-th table’s row for the orthographic letter , where ;
- (8)
- Select the appropriate grapheme-to-phoneme conversion rule for the orthographic letter , as defined by the cell in the j-th column and i-th row of the table;
- (9)
- Use the appropriate grapheme-to-phoneme conversion rule for the orthographic letter , as defined by the cell in the j-th column and i-th row of the table:
- In the cell with the table coordinates , phonemic letter letter is saved, corresponding to the orthographic letter with the following context and preceding context ;
- The grapheme-to-phoneme conversion rule for orthographic letter will be implemented by assignment ;
- (10)
- Increment and read the next orthographic letter of the input word ;
- (11)
- Go to step number 3, unless , where n is the length of input word ;
- (12)
- Output the result of the grapheme-to-phoneme conversion of orthographic word where , is a new phonemic representation of the word , where .
| Algorithm 1. The algorithm for grapheme-to-phoneme conversion (implementation of function ). |
| Require:and |
| 1: |
| 2: |
| 3: while () do |
| 4: |
| 5: |
| 6: {% selection of appropriate table} |
| 7: {% number of table rows} |
| 8: {% number of table columns} |
| 9: for all () do |
| 10: if () then |
| 11: {% selection of appropriate table row} |
| 12: end if |
| 13: end for |
| 14: for all() do |
| 15: if () then |
| 16: {% selection of appropriate table column} |
| 17: end if |
| 18: end for |
| 19: {% reading phoneme letter from the table} |
| 20: |
| 21: end while |
| 22: {% string of phonemes} |
| 22: return |
4. Results
- Performing grapheme-to-phoneme conversion of an orthographic text corpus file containing the most frequently used words in Polish (those with different orthographic representations), obtained from resources in the National Corpus of Polish [50];
- Validation and verification of the conversion results for those words using the Polish language dictionary that specifies the correct pronunciation of words in Polish;
- Registering cases of incorrect conversion, errors, and other problems encountered;
- Attempts to solve the problems.
- Errors in the implementation of the algorithm or conversion rules;
- Missing conversion rules in tables (rules not included in the tables) for some orthographic letters in contexts;
- Problems with conversion of foreign words, acronyms and words that are not in the Polish language dictionary.
- Implementation errors in the conversion algorithm and rule tables were corrected by modifying the application source code;
- The problem of missing conversion rules in tables has been solved by adding rules to the tables. It should be noted that the added grapheme-to-phoneme conversion rules cooperate with the rules implemented earlier and known from the literature [36,37]. In order to complete the rule tables, new rules were added for selected letters e.g.: “i”, “n”, “d”, “z”, “ż”, “ć”, “f”, “s” in some contexts, in particular:
- -
- adding or correcting conversion rules for the letter “i” for correct conversion of words: “unii”, “będzie”, “sobie”, “razie”, “diabeł”, and similar contexts;
- -
- adding or correcting conversion rules for the letter “n” for correct conversion of words: “branży” and similar contexts;
- -
- adding or correcting conversion rules for the letter “d” for correct conversion When the letter “d” occurs at the end of a word, e.g.: “od”, “pod”, “przed”, “nad”, “miliard”, “wyjazd”, “Witold”, “grand”, “rajd”, “hołd”, “prawd”;
- -
- adding or correcting conversion rules for the letter “z” for correct conversion of words: “trzeci”, “zamierza”, “poradzę”, “bezzwrotny”, and similar contexts;
- -
- adding or correcting conversion rules for the letter “ż” for correct conversion of words: “tożsamość”, ”manadżer”, and similar contexts;
- -
- adding or correcting conversion rules for the letter “ć” for correct conversion of words: “ćwiczenia”, “dziećmi”, “zadośćuczynić”, “ćwiartki”, and similar contexts;
- -
- adding or correcting conversion rules for the letter “f” for correct conversion of words: “Afganistan”, “Hoffman”, and similar contexts;
- -
- adding or correcting conversion rules for the letter “s” for correct conversion of words: “przeprosin”, “siną”, “Helsinki”, and similar contexts;
- The problem of converting foreign words and acronyms was solved by using the developed dictionary in which the rules for converting foreign words and acronyms were defined. Thus, the rule-based grapheme-phoneme conversion was supplemented by the dictionary method;
| Listing 1. A sample fragment of the input text file containing orthographic text from Adam Mickiewicz’s epic poem “Pan Tadeusz”. |
|
| Listing 2: A fragment of the output file containing phonemic notation as a result of automatic grapheme-to-phoneme conversion of Adam Mickiewicz’s epic poem “Pan Tadeusz”. |
|
Listing 3. A sample fragment of the frequency list file of the phonemic language corpus developed for Polish. |
|
5. Statistical Approach
6. Conclusions
- Automatic conversion of graphemes into phonemes in orthographic texts is not only a technical issue, consisting in developing appropriate algorithms for converting graphemes into phonemes, but also a serious linguistic problem. Only specialists in linguistics and phonetics of a given language are able to formulate appropriate rules for converting graphemes into phonemes for speech [51];
- Effective solutions for automatic grapheme-to-phoneme conversion in one language may not help solve the same problems for a different language. There is not only one language and technical problem of automatic conversion of graphemes to phonemes to be solved, but many different problems with different levels of difficulty that should be solved for each language separately [51];
- A separate, but very important problem is the evaluation of grapheme-to-phoneme conversion processes [53,71]. Evaluation and validation of grapheme-to-phoneme conversion implementations is a laborious and time-consuming process. All problems registered for the G2P implementation discussed in this paper were positively resolved;
- The author of the paper analysed for comparison the only available application for the Polish language, named Transcriber [41]. The application was implemented in the C++ programming language. The implemented method uses a dictionary of 5018 words and 767 defined conversion rules. For comparison, the software presented by the author in this paper was implemented in Python programming language, 975 conversion rules were implemented and the dictionary is very limited and plays only a supporting role. This means that TransFon has implemented 208 more transcription rules, which is over 27% more. The application failed to compile due to the lack of inclusion in the source code of the appropriate libraries that were used by the programmer to create the application. This made it impossible to evaluate the correctness of the application and seriously hindered the comparison with the software created by the author of the paper; However, based on the analysis of the application’s source code, you can see that the principle of the application is also rule-based, but the author of the Transcriber application tried to refine and improve the application’s performance by adding new words to the dictionary (exceptions). The author of the TransFon application, on the other hand, tried to add and supplement transcription rules in a similar way as is known in the literature. This is evidenced by the dictionary size used in both applications;
- The G2P system presented here could be used for Polish corpus development;
- The G2P implementation presented here did not exploit any similar pre-existing tools [48];
- Developing an algorithm for automatic conversion of graphemes into phonemes for the Polish language and implementing it in the Python programming language with numerous improvements;
- Development of a software for automatic conversion of graphemes into phonemes called TransFon, which enables automatic conversion of graphemes into phonemes of any orthographic text files in the Polish language;
- Application of the developed methods to create phoneme-based language corpora using the automatic conversion of graphemes to phonemes;
- Statistical analysis of the occurrence frequency of particular grapheme-to-phoneme conversion rules in Polish;
- Comparison of the results obtained with those published in the literature and discussion.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar]
- Lee, F. Automatic grapheme-to-phone translation of english. J. Acoust. Soc. Am. 1967, 41, 1594A. [Google Scholar]
- Bagshaw, P. Phonemic transcription by analogy in text-to-speech synthesis: Novel word pronunciation and lexicon compression. Comput. Speech Lang. 1998, 12, 119–142. [Google Scholar]
- Kawaguchi, Y.; Takagaki, T.; Tomimori, N.; Tsuruga, Y. Corpus-Based Perspectives in Linguistics. In Usage-Based Linguistic Informatics; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Kłosowski, P. Speech Processing Application Based on Phonetics and Phonology of the Polish Language. In Communications in Computer and Information Science, Proceedings of the 17th International Conference Computer Networks, Ustron, Poland, 15–19 June 2010; Kwiecien, A., Gaj, P., Stera, P., Eds.; Computer Nerworks; Springer: Berlin, Germany, 2010; Volume 79, pp. 236–244. [Google Scholar]
- Kłosowski, P. Improving speech processing based on phonetics and phonology of Polish language. Prz. Elektrotech. 2013, 89, 303–307. [Google Scholar]
- Izydorczyk, J.; Kłosowski, P. Acoustic properties of Polish vowels. Bull. Polish Acad. Sci. Tech. Sci. 1999, 47, 29–37. [Google Scholar]
- Izydorczyk, J.; Kłosowski, P. Base acoustic properties of Polish speech. In Proceedings of the International Conference Programable Devices and Systems PDS2001 IFAC Workshop (IFAC 2001), Gliwice, Poland, 22–23 November 2001; pp. 61–66. [Google Scholar]
- Kłosowski, P.; Dustor, A.; Izydorczyk, J.; Kotas, J.; Slimok, J. Speech Recognition Based on Open Source Speech Processing Software. In Communications in Computer and Information Science, Proceedings of the 21st International Science Conference on Computer Networks (CN), Brunow, Poland, 23–27 June 2014; Kwiecien, A., Gaj, P., Stera, P., Eds.; Computer Networks, CN; Springer: Berlin, Germany, 2014; Volume 431, pp. 308–317. [Google Scholar]
- Dustor, A.; Kłosowski, P. Biometric Voice Identification Based on Fuzzy Kernel Classifier. In Communications in Computer and Information Science, Proceedings of the 20th International Conference on Computer Networks (CN), Lwowek Slaski, Poland, 17–21 Jun 2013; Kwiecien, A., Gaj, P., Stera, P., Eds.; Computer Networks, CN; Springer: Berlin, Germany, 2013; Volume 370, pp. 456–465. [Google Scholar]
- Dustor, A.; Kłosowski, P.; Izydorczyk, J. Influence of Feature Dimensionality and Model Complexity on Speaker Verification Performance. In Communications in Computer and Information Science, Proceedings of the 21st International Science Conference on Computer Networks (CN), Brunow, Poland, 23–27 June 2014; Kwiecien, A., Gaj, P., Stera, P., Eds.; Computer Networks, CN; Springer: Berlin, Germany, 2014; Volume 431, pp. 177–186. [Google Scholar]
- Dustor, A.; Kłosowski, P.; Izydorczyk, J. Speaker recognition system with good generalization properties. In Proceedings of the 2014 International Conference on Multimedia Computing and Systems (ICMCS), Marrakech, Morocco, 14–16 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 206–210. [Google Scholar]
- Dustor, A.; Kłosowski, P.; Izydorczyk, J.; Kopanski, R. Influence of Corpus Size on Speaker Verification. In Communications in Computer and Information Science, Proceedings of the 22nd International Conference on Computer Networks (CN), Brunow, Poland, 16–19 June 2015; Gaj, P., Kwiecien, A., Stera, P., Eds.; Computer Networks, CN; Springer: Berlin, Germany, 2015; Volume 522, pp. 242–249. [Google Scholar]
- Kłosowski, P.; Dustor, A.; Izydorczyk, J. Speaker verification performance evaluation based on open source speech processing software and timit speech corpus. In Communications in Computer and Information Science, Proceedings of the 22nd International Conference on Computer Networks (CN), Brunow, Poland, 16–19 June 2015; Gaj, P., Kwiecien, A., Stera, P., Eds.; Computer Networks, CN; Springer: Berlin, Germany, 2015; Volume 522, pp. 400–409. [Google Scholar]
- Kłosowski, P.; Dustor, A. Automatic Speech Segmentation for Automatic Speech Translation. In Communications in Computer and Information Science, Proceedings of the 20th International Conference on Computer Networks (CN), Lwowek Slaski, Poland, 17–21 June 2013; Kwiecien, A., Gaj, P., Stera, P., Eds.; Computer Networks, CN; Springer: Berlin, Germany, 2013; Volume 370, pp. 466–475. [Google Scholar]
- Bellegarda, J.R.; Monz, C. State of the art in statistical methods for language and speech processing. Comput. Speech Lang. 2016, 35, 163–184. [Google Scholar]
- Kłosowski, P. Statistical analysis of Polish language corpus for speech recognition application. In Proceedings of the 20th IEEE International Conference Signal Processing Algorithms, Architectures, Arrangements, and Applications, Poznań, Poland, 21–23 September 2016; pp. 304–309. [Google Scholar]
- Kłosowski, P. Polish language modelling for speech recognition application. In Proceedings of the 21th IEEE International Conference Signal Processing Algorithms, Architectures, Arrangements, and Applications, Poznan, Poland, 20–22 September 2017; pp. 313–318. [Google Scholar]
- Kłosowski, P. Statistical analysis of orthographic and phonemic language corpus for word-based and phoneme-based Polish language modelling. EURASIP J. Audio Speech Music Process. 2017, 2017, 5. [Google Scholar]
- Kłosowski, P. Deep learning for natural language processing and language modelling. In Proceedings of the 22th IEEE International Conference Signal Processing Algorithms, Architectures, Arrangements, and Applications, Poznan, Poland, 19–21 September 2018; pp. 223–228. [Google Scholar]
- Kłosowski, P. Polish language modelling based on deep learning methods and techniques. In Proceedings of the 23th IEEE International Conference Signal Processing Algorithms, Architectures, Arrangements, and Applications, Poznan, Poland, 18–20 September 2019; pp. 223–228. [Google Scholar]
- Adda-Decker, M. Corpus for automatic speech recognition. Rev. Fr. Linguist. Appl. 2007, 12, 71–84. [Google Scholar]
- Drgas, S.; Dabrowski, A. Speaker recognition based on multilevel speech signal analysis on Polish corpus. Multimed. Tools Appl. 2015, 74, 4195–4211. [Google Scholar]
- Furui, S. Recent progress in corpus-based spontaneous speech recognition. IEICE Trans. Inf. Syst. 2005, 88, 366–375. [Google Scholar]
- Lecouteux, B.; Linares, G.; Oger, S. Integrating imperfect transcripts into speech recognition systems for building high-quality corpora. Comput. Speech Lang. 2012, 26, 67–89. [Google Scholar]
- Coulmas, F. The Blackwell’s Encyclopedia of Writing Systems; Blackwells: Oxford, UK, 1996. [Google Scholar]
- Przybysz, P.; Kasprzak, W. The generation of letter-to-sound rules for grapheme-to-phoneme conversion. In Proceedings of the 2013 6th International Conference on Human System Interactions (HSI), Sopot, Poland, 6–8 June 2013; pp. 292–297. [Google Scholar]
- International Phonetic Association. Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet; A Regents Publication; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Sussex, R.; Cubberley, P. The Slavic Languages. In Cambridge Language Surveys; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Wells, J. SAMPA computer readable phonetic alphabet. In Handbook of Standards and Resources for Spoken Language Systems, Vol. Part IV, Section B; Gibbon, D., Moore, R., Winski, R., Eds.; Mouton de Gruyter: Berlin, Germany; New York, NY, USA, 1997. [Google Scholar]
- Kučera, H. Mechanical phonemic transcription and phoneme frequency count of czech. Int. J. Slav. Lingguistic Phon. 1963, 6, 36–50. [Google Scholar]
- Bhimani, B.; Dolby, J. Acoustic phonetic transcription of written English. In Annual Report: Automatic Indexing and Abstracting; AIP Publishing: Palo Alto, CA, USA, 1966. [Google Scholar]
- Pratt, B.; Silva, G. Phontrns: A Procedure which Uses a Computer for Transcribing French Text info Phonetic Symbols; Monash University: Melbourne, Australia, 1967. [Google Scholar]
- Ungerhruer, G.; Kästner, W. Untersuchungen zur Transformation Deutcher Schirifttexte in Entsprechende Phonemtexte mit Hilfe Elektronischer Rechenmaschinen; Forschungsbericht; Institut für Phonetic und Kommunikationsforshung der Universität Bonn: Bonn, Germany, 1966. [Google Scholar]
- Doroszewski, W. Speech and writing (in Polish: Mowa a pismo). Porad. Jęz. 1969, 4, 181–188. [Google Scholar]
- Steffen-Batóg, M. The problem of automatic phonemic transcription of written Polish. Biul. Fonogr. 1973, XIV, 75–86. [Google Scholar]
- Steffen-Batóg, M. Automatic Phonemic Transcription of Polish Texts (In Polish: Automatyzacja Transkrypcji Fonematycznej Tekstów Polskich); Wydawnictwo Naukowe PWN: Warszawa, Poland, 1975. [Google Scholar]
- Warmus, M. Software implementation for ODRA 1204 of automatic phonemic transctiption of polish texts (in Polish: Program na maszynę ODRA 1204 dla automatycznej transkrypcji fonematycznej tekstów języka polskiego). In Zastosowanie Maszyn Matematycznych do Badań nad Językiem Naturalnym; Bolc, L., Ed.; Wydawnictwo Uniwersytetu Warszawskiego: Warszawa, Poland, 1973. [Google Scholar]
- Demenko, G.; Wypych, M.; Baranowska, E. Implementation of grapheme-to-phoneme rules and extended SAMPA alphabet in Polish text-to-speech synthesis. Speech Lang. Technol. 2003, 7, 79–97. [Google Scholar]
- Jassem, W. A phonemic transcription and syllable division rule engine. In Onomastica-Copernicus Research Colloquium; University of Edinburg: Edinburgh, UK, 1996. [Google Scholar]
- Koržinek, D.; Brocki, Ł.; Marasek, K. Polish Grapheme-to-Phoneme Tool and Service, CLARIN-PL Digital Repository (2016). Available online: https://clarin-pl.eu/dspace/handle/11321/295 (accessed on 10 January 2022).
- Koržinek, D.; Marasek, K.; Brocki, Ł.; Wołk, K. Polish read speech corpus for speech tools and services. In CLARIN Common Language Resources and Technology Infrastructure, Proceedings of the Selected Papers from the CLARIN Annual Conference 2016, Aix-en-Provence, France, 26–28 October 2016; Number 136; Linköping University Electronic Press, Linköpings Universitet: Linköpings, Sweden, 2017; pp. 54–62. [Google Scholar]
- Skurzok, D.; Ziółko, B.; Ziółko, M. Ortfon2—Tool for orthographic to phonetic transcription. In Proceedings of the 7th Language & Technology Conference, Poznań, Poland, 27–29 November 2015. [Google Scholar]
- Steffen-Batóg, M.; Nowakowski, P. An algorithm for phonetic transcription of orthographic texts in Polish. In Studia Phonetica Posnaniensia; Steffen-Batóg, M., Awedyk, W., Eds.; Wydawnictwo Naukowe UAM: Poznań, Poland, 1993; Volume 3. [Google Scholar]
- Wypych, M. Implementation of phonenic transcription alghorithm (in Polish: Implementacja algorytmu transkrypcji fonematycznej). In Speech and Language Technology; Polskie Towarzystwo Fonetyczne: Poznań, Poland, 1999; Volume 3. [Google Scholar]
- Razavi, M.; Rasipuram, R.; Doss, M.M. Acoustic data-driven grapheme-to-phoneme conversion in the probabilistic lexical modeling framework. Speech Commun. 2016, 82, 1–21. [Google Scholar]
- Kaplan, R.M.; Kay, M. Regular models of phonological rule systems. Comput. Linguist. 1994, 20, 331–378. [Google Scholar]
- Kłosowski, P. Algorithm and implementation of automatic phonemic transcription for Polish. Proceedings of 20th IEEE International Conference Signal Processing Algorithms, Architectures, Arrangements, and Applications, Poznań, Poland, 21–23 September 2016; pp. 298–303. [Google Scholar]
- Python Software Foundation: About Python (2014). Available online: https://www.python.org/about/ (accessed on 10 January 2022).
- Przepiórkowski, A.; Bańko, M.; Górski, R.L. Lewandowska-Tomaszczyk, B. The National Corpus of Polish (in Polish: Narodowy Korpus Języka Polskiego); Wydawnictwo Naukowe PWN: Warszawa, Poland, 2012. [Google Scholar]
- Auzina, I.; Pinnis, M.; Dargis, R. Comparison of Rule-based and Statistical Methods for Grapheme to Phoneme Modelling. In Frontiers in Artificial Intelligence and Applications, Proceedings of the Human Language Technologies—The Baltic Perspective, Baltic HLT 2014, Kaunas, Lithuania, 26–27 September 2014; Utka, A., Grigonyte, G., Kapociute Dzikiene, J., Vaicenoniene, J., Eds.; Vytautas Magnus University ViaConventus: Vilnius, Lithuania, 2014; Volume 268, pp. 57–60. [Google Scholar]
- Decadt, B.; Duchateau, J.; Daelemans, W.; Wambacq, P. Phoneme-to-grapheme conversion for out-of-vocabulary words in large vocabulary speech recognition. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU ’01), Madonna di Campiglio, Italy, 9–13 December 2001; pp. 413–416. [Google Scholar]
- Jouvet, D.; Fohr, D.; Illina, I. Evaluating grapheme-to-phoneme converters in automatic speech recognition context. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4821–4824. [Google Scholar]
- Kheang, S.; Katsurada, K.; Iribe, Y.; Nitta, T. Novel two-stage model for grapheme-to-phoneme conversion using new grapheme generation rules. In Proceedings of the 2014 International Conference of Advanced Informatics: Concept, Theory and Application (ICAICTA), Bandung, Indonesia, 20–21 August 2014; pp. 97–102. [Google Scholar]
- Schlippe, T.; Ochs, S.; Schultz, T. Grapheme-to-phoneme model generation for indo-european languages. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4801–4804. [Google Scholar]
- Przepiórkowski, A.; Górski, R.L.; Lewandowska-Tomaszczyk, B.; Aziński, M. Towards the national corpus of Polish. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco, 28–30 May 2008; European Language Resources Association (ELRA): Paris, France, 2008. [Google Scholar]
- Mickiewicz, A. Pan Tadeusz, Czyli, Ostatni Zajazd na Litwie: Historja Szlachecka z r. 1811 i 1812, We Dwunastu Księgach, Wierszem; Wydawnictwo Zakładu Narodowego Im. Ossolińskich: Warszawa, Poland, 1834; Available online: https://wolnelektury.pl/katalog/lektura/pan-tadeusz.html (accessed on 10 January 2022).
- Ney, H. Corpus-based statistical methods in speech and language processing. In Text, Speech and Language Technology, Proceedings of the 2nd European Summer School on Language and Speech Communication, Utrecht, The Netherlands, 1994; Corpus-Based Methods in Language and Speech Processing; Young, S., Bloothooft, G., Eds.; Kluwer Academic Publishers: London, UK, 1997; Volume 2, pp. 4–26. [Google Scholar]
- Zipf, G.K. Human behavior and the principle of least effort. J. Clin. Psychol. 1950, 6, 306. [Google Scholar]
- Tambovtsev, Y.; Martindale, C. Phoneme Frequencies Follow a Yule Distribution. SKASE J. Theor. Linguist. 2008, 4, 1–11. [Google Scholar]
- Yule, G.U. A mathematical theory of evolution, based on the conclusions of Dr. J. C. Willis, F.R.S. Philos. Trans. R. Soc. Lond. B Biol. Sci. 1925, 213, 21–87. [Google Scholar]
- Cylwik, N.; Wagner, A.; Demenko, G. The euronounce corpus of non-native polish for asr-based pronunciation tutoring system. In Proceedings of the 2nd ISCA Workshop of Speech and Language Technology in Education, Warwickshire, UK, 3–5 September 2009. [Google Scholar]
- Demenko, G. Korpusowe Badania JęZyka MóWionego; Akademicka Oficyna Wydawnicza EXIT: Warszawa, Polish, 2015; ISBN 9788378370437. [Google Scholar]
- Demenko, G.; Bachan, J.; Wagner, A.; Wyroślak, P. Speech corpus creation for automatic analysis of phonetic convergence. In Studientexte zur Sprachkommunikation, Proceedings of 27th Conference on Electronic Speech Signal Processing (ESSV), Leipzig, Germany, 2–4 March 2016; Oliver, J., Ed.; Hochschule für Telekommunikation Leipzig (HfTL): Leipzig, Germany, 2016; pp. 183–190. [Google Scholar]
- Demenko, G.; Grocholewski, S.; Klessa, K.; Rau, Z. Polish language resources for speech technology: Jurisdic lvcsr corpora. In Human Language Technologies as a Challenge for Computer Science and Linguistics, Proceedings of the 4th Language & Technology Conference, Poznań, Poland, 6–8 November 2009; Zygmunt, V., Ed.; Adam Mickiewicz University: Poznań, Poland, 2009; pp. 165–169. [Google Scholar]
- Demenko, G.; Klessa, K.; Szymański, M.; Breuer, S.; Hess, W. Polish unit selection speech synthesis with boss: Extensions and speech corpora. Int. J. Speech Technol. 2010, 13, 85–99. [Google Scholar]
- Demenko, G.; Szymański, M.; Cecko, R.; Lange, M.; Klessa, K.; Owsianny, M. Development of large vocabulary continuous speech recognition using phonetically structured speech corpus. In Proceedings of the 17th International Congress of Phonetic Sciences (ICPhS XVII), Hong Kong, China, 17–21 August 2011; pp. 568–571. [Google Scholar]
- Kosaner, O.; Birant, C.C.; Aktas, O. Improving Turkish language training materials: Grapheme-to-phoneme conversion for adding phonemic transcription into dictionary entries and course books. In Procedia Social and Behavioral Sciences, Proceedings of the 13th International Educational Technology Conference, Lisbon, Portugal, 30 October–1 November 2014; Isman, A., Siraj, S., Kiyici, M., Eds.; Volume 103, pp. 473–484.
- Lee, J.; Kim, B.; Lee, G.G. Hybrid Approach to Grapheme to Phoneme Conversion for Korean. In Proceedings of the InterSpeech 2009: 10th Annual Conference of the International Speech Communication Association 2009, Brighton, UK, 6–10 September 2009; Volume 1–5, pp. 1299–1302. [Google Scholar]
- de Jesus Aguiar Pontes, J.; Furui, S. Predicting the phonetic realizations of word-final consonants in context—A challenge for French grapheme-to-phoneme converters. Speech Commun. 2010, 52, 847–862. [Google Scholar]
- Schraagen, M.; Bloothooft, G. A qualitative evaluation of phoneme-to-phoneme technology. In Proceedings of the 12th Annual Conference of the International-Speech-Communication-Association 2011 (Interspeech 2011), Florence, Italy, 27–31 August 2011; Volume 1–5, pp. 2332–2335. [Google Scholar]
- Żelasko, P.; Ziółko, B.; Jadczyk, T.; Skurzok, D. AGH corpus of Polish speech. Lang. Resour. Eval. 2016, 50, 585–601. [Google Scholar]
- Ziółko, B.; Jadczyk, T.; Skurzok, D.; Żelasko, P.; Gałka, J.; Pȩdzima̧ż, T.; Gawlik, I.; Pałka, S. SARMATA 2.0 automatic Polish language speech recognition system. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; Interspeech: Dresden, Germany, 2015. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phonetic Alphabet | Example of | |||
|---|---|---|---|---|
| No. | Symbols | Occurrence | ||
| [SPA] | [IPA] | [SAMPA] | in Polish | |
| 1 | [e] | [ɛ] | [e] | serce |
| 2 | [a] | [ɑ] | [a] | baba |
| 3 | [o] | [ɔ] | [o] | oko |
| 4 | [t] | [t] | [t] | trawa |
| 5 | [n] | [n] | [n] | noc |
| 6 | [y] | [ɨ] | [I] | syty |
| 7 | [i̯] | [j] | [j] | jajo |
| 8 | [i] | [i] | [i] | wici |
| 9 | [r] | [r] | [r] | rok |
| 10 | [s] | [s] | [s] | sok |
| 11 | [v] | [v] | [v] | wada |
| 12 | [p] | [p] | [p] | praca |
| 13 | [u] | [u] | [u] | buk |
| 14 | [m] | [m] | [m] | mama |
| 15 | [k] | [k] | [k] | kot |
| 16 | [ń] | [ɲ] | [n’] | koń |
| 17 | [d] | [d] | [d] | dudek |
| 18 | [l] | [l] | [l] | lato |
| 19 | [u̯] | [ɫ] | [w] | łysy |
| 20 | [š] | [ʃ] | [S] | szyszka |
| 21 | [f] | [f] | [f] | fala |
| 22 | [z] | [z] | [z] | koza |
| 23 | [c] | [ʦ͡] | [ts] | cacko |
| 24 | [b] | [b] | [b] | baba |
| 25 | [g] | [g] | [g] | godło |
| 26 | [ś] | [ɕ] | [s’] | siano |
| 27 | [ć] | [ʨ͡] | [ts’] | ciasto |
| 28 | [] | [ʝ] | [x] | higiena |
| 29 | [č] | [ʧ͡] | [tS] | czarny |
| 30 | [ž] | [ʒ] | [Z] | każdy |
| 31 | [] | [] | [e ] | ręka |
| 32 | [ḱ] | [c] | [k’] | kino |
| 33 | [] | [ʥ͡] | [dz’] | dziedzic |
| 34 | [ʒ] | [ʣ͡] | [dz] | nadzy |
| 35 | [ź] | [ʑ] | [z’] | ziarno |
| 36 | [ǵ] | [ɟ] | [g’] | magiczny |
| 37 | [] | [ʤ͡] | [dZ] | drożdże |
| … | … | |||||
|---|---|---|---|---|---|---|
| … | … | |||||
| … | … | |||||
| … | … | … | … | … | … | … |
| … | … | |||||
| … | … | … | … | … | … | … |
| … | … | |||||
| … | … |
| a | X |
| X | a |
| ą | |||||||||
| X | o | om | on | on | on | on | oń | oŋ | oŋ |
| u | X - / | / |
|---|---|---|
| X - {a, e} | u | u̯ |
| rze | u | u̯ |
| ie | u | u̯ |
| poza | u | u̯ |
| pra | u | u̯ |
| dna | u | u̯ |
| una | u | u̯ |
| ena | u | u̯ |
| #na | u | u̯ |
| u | X |
|---|---|
| (X - {e, o, #})za | u̯ |
| (X - p){oza, ra} | u̯ |
| (X - {d, u, e, o, a, y, #})na | u̯ |
| u | k | w | ł | cz | sz | {s, m}O | t |
|---|---|---|---|---|---|---|---|
| (X - {z, i})e | u̯ | u̯ | u̯ | u̯ | u | u | u̯ |
| (X - r)ze | u̯ | u̯ | u̯ | u̯ | u | u | u̯ |
| (X -{z, r, n})a | u̯ | u̯ | u | u̯ | u̯ | u̯ | u̯ |
| #za | u | u | u | u | u | u | u̯ |
| eza | u̯ | u | u̯ | u̯ | u̯ | u̯ | u̯ |
| ona | u | u̯ | u̯ | u | u̯ | u̯ | u̯ |
| ana | u | u̯ | u̯ | u̯ | u̯ | u̯ | u̯ |
| yna | u | u̯ | u̯ | u̯ | u̯ | >u̯ | >u̯ |
| u | ||||
|---|---|---|---|---|
| (X - {z, i})e) | u̯ | u̯ | u̯ | u̯ |
| (X - r)ze | u̯ | u̯ | u̯ | u̯ |
| (X -{z, r, n})a | u̯ | u̯ | u̯ | u̯ |
| #za | u | u | u | u |
| eza | u̯ | u̯ | u̯ | u̯ |
| ona | u̯ | u̯ | u̯ | u̯ |
| ana | u̯ | u̯ | u̯ | u̯ |
| yna | u̯ | u̯ | u̯ | u̯ |
| Table Number | Orthographic Letter | No. of Rows | No. of Columns | No. of Cells | No. of Rules |
|---|---|---|---|---|---|
| 1 | z | 34 | 64 | 2079 | 174 |
| 2 | s | 17 | 62 | 976 | 157 |
| 3 | r | 11 | 22 | 210 | 91 |
| 4 | u | 15 | 15 | 196 | 88 |
| 5 | d | 12 | 46 | 495 | 83 |
| 7 | i | 14 | 13 | 156 | 80 |
| 6 | ć | 12 | 19 | 198 | 40 |
| 8 | ż | 13 | 16 | 180 | 36 |
| 9 | c | 11 | 28 | 270 | 36 |
| 10 | t | 6 | 26 | 125 | 31 |
| 11 | k | 4 | 17 | 48 | 18 |
| 12 | f | 6 | 13 | 60 | 16 |
| 13 | w | 2 | 15 | 14 | 14 |
| 14 | ź | 3 | 9 | 16 | 13 |
| 15 | ś | 6 | 10 | 45 | 12 |
| 16 | p | 2 | 12 | 11 | 11 |
| 17 | b | 2 | 11 | 10 | 10 |
| 18 | g | 2 | 10 | 9 | 9 |
| 19 | ę | 2 | 10 | 9 | 9 |
| 20 | ą | 2 | 10 | 9 | 9 |
| 21 | n | 3 | 9 | 16 | 8 |
| 22 | y | 4 | 3 | 6 | 6 |
| 23 | l | 3 | 3 | 4 | 4 |
| 24 | P | 3 | 3 | 4 | 4 |
| 25 | h | 2 | 2 | 1 | 1 |
| 26 | ł | 2 | 2 | 1 | 1 |
| 27 | ń | 2 | 2 | 1 | 1 |
| 28 | m | 2 | 2 | 1 | 1 |
| 29 | j | 2 | 2 | 1 | 1 |
| 30 | ó | 2 | 2 | 1 | 1 |
| 31 | o | 2 | 2 | 1 | 1 |
| 32 | e | 2 | 2 | 1 | 1 |
| 33 | a | 2 | 2 | 1 | 1 |
| 34 | q | 2 | 2 | 1 | 1 |
| 35 | v | 2 | 2 | 1 | 1 |
| 36 | x | 2 | 2 | 1 | 1 |
| 37 | # | 2 | 2 | 1 | 1 |
| 38 | @ | 2 | 2 | 1 | 1 |
| 39 | - | 2 | 2 | 1 | 1 |
| 40 | / | 2 | 2 | 1 | 1 |
| TOTAL | 5162 | 975 |
| i | A-{i} | A | e | e | ab |
| {c,n} | 1 | ||||
| dz | 1 | ||||
| b | j | ||||
| z | 1 | ||||
| d | j |
| n | ż |
| X | ŋ |
| d | S |
| A | t |
| {r, z, l, n, ł, w} | t |
| z | X | a | {ą,ę} | z |
| tr | 1 | |||
| r | 1 | |||
| d | 1 | |||
| e | s |
| ż | sa | er |
| A | ž | |
| d | 1 |
| ć | wic | m | u | wi |
| X | ć | ć | ||
| e | ć | |||
| ś | ć |
| f | ga | f |
| X | v | f |
| s | in | iną | in |
| A | ś | ||
| # | ś | ś | |
| l | s |
| No. | Parameter | Value |
|---|---|---|
| 1 | Number of unique words checked | 1,943,458 |
| 2 | Number of G2P conversion errors for unique words | 33,638 |
| 3 | The WER value for unique words | 1.731% |
| 4 | Number of words in the corpus | 230,300,300 |
| 5 | Number of G2P conversion errors for words in the corpus | 3,707,890 |
| 6 | The WER value for the corpus | 1.610% |
| 7 | Number of checked unique words phonemes | 16,293,828 |
| 8 | Number of G2P conversion errors for phonemes | 34,324 |
| 9 | The PER value for unique words | 0.211% |
| 10 | Number of phonemes in the corpus | 1,263,992,460 |
| 11 | Number of G2P conversion errors for phonemes in the corpus | 3,713,206 |
| 12 | The PER value for the corpus | 0.294% |
| No. | Parameter | Value |
|---|---|---|
| 1 | Number of unique words checked | 1,943,458 |
| 2 | Number of G2P conversion errors for unique words | 7525 |
| 3 | The WER value for unique words | 0.387% |
| 4 | Number of words in the corpus | 230,300,300 |
| 5 | Number of G2P conversion errors for words in the corpus | 69,802 |
| 6 | The WER value for the corpus | 0.030% |
| 7 | Number of checked unique words phonemes | 16,282,255 |
| 8 | Number of G2P conversion errors for phonemes | 8063 |
| 9 | The PER value for unique words | 0.050% |
| 10 | Number of phonemes in the corpus | 1,263,415,734 |
| 11 | Number of G2P conversion errors for phonemes in the corpus | 73,786 |
| 12 | The PER value for the corpus | 0.006% |
| Value | Value | ||
|---|---|---|---|
| No. | Parameter | before | after |
| Improvements | Improvements | ||
| 1 | The WER value for unique words | 1.731% | 0.387% |
| 2 | The WER value for the corpus | 1.610% | 0.030% |
| 3 | The PER value for unique words | 0.211% | 0.050% |
| 4 | The PER value for the corpus | 0.294% | 0.006% |
| No. | Rule | Orthographic | Row | Column | Phoneme |
|---|---|---|---|---|---|
| Name | Letter | Number | Number | Letters | |
| L | R | C | P | ||
| 1 | ą_1_1_o | ą | 1 | 1 | [o] |
| 2 | ą_1_2_om | ą | 1 | 2 | [om] |
| 3 | ą_1_3_on | ą | 1 | 3 | [on] |
| 4 | ą_1_4_on | ą | 1 | 4 | [on] |
| 5 | ą_1_5_on | ą | 1 | 5 | [on] |
| 6 | ą_1_6_on | ą | 1 | 6 | [on] |
| 7 | ą_1_7_on’ | ą | 1 | 7 | [on’] |
| 8 | ą_1_8_o~ | ą | 1 | 8 | [o~] |
| 9 | ą_1_9_o~ | ą | 1 | 9 | [o~] |
| No. | Number of | Frequency | Rule |
|---|---|---|---|
| Occurr. of | of Occurr. | Name | |
| 1843069533 | in % | ||
| i | |||
| 1 | 230609384 | 12.512 | @_1_1_ |
| 2 | 230606397 | 12.512 | #_1_1_ |
| 3 | 120713048 | 6.550 | a_1_1_a |
| 4 | 107031055 | 5.807 | e_1_1_e |
| 5 | 102221066 | 5.546 | o_1_1_o |
| 6 | 52025013 | 2.823 | y_3_2_I |
| 7 | 50492927 | 2.740 | i_12_11_i |
| 8 | 47433333 | 2.574 | r_1_1_r |
| 9 | 44069532 | 2.391 | t_1_1_t |
| 10 | 43352871 | 2.352 | n_1_1_n |
| 11 | 38974957 | 2.115 | m_1_1_m |
| 12 | 38920693 | 2.112 | w_1_1_v |
| 13 | 34811970 | 1.889 | P_1_1_ |
| 14 | 31876002 | 1.730 | j_1_1_j |
| 15 | 30407964 | 1.650 | u_1_1_u |
| 16 | 28149906 | 1.527 | n_1_7_n’ |
| 17 | 26241250 | 1.424 | p_1_1_p |
| 18 | 24158723 | 1.311 | z_2_23_ |
| 19 | 23770872 | 1.290 | ł_1_1_w |
| 20 | 21373108 | 1.160 | k_1_2_k |
| 21 | 21286163 | 1.155 | l_1_1_l |
| 22 | 20689142 | 1.123 | d_1_1_d |
| 23 | 16884069 | 0.916 | s_1_2_s |
| 24 | 16046642 | 0.871 | i_3_2_ |
| 25 | 15310336 | 0.831 | c_1_3_ts |
| 26 | 15178089 | 0.824 | b_1_1_b |
| 27 | 14222227 | 0.772 | h_1_1_x |
| 28 | 13675210 | 0.742 | p_1_4_p |
| 29 | 12853330 | 0.697 | c_1_1_ |
| 30 | 12487271 | 0.678 | z_11_52_ |
| ⋯ | ⋯ | ⋯ | ⋯ |
| No. | Number of | Frequency | Letter |
|---|---|---|---|
| Occurr. of | of Occurr. | ||
| 1345943574 | in % | ||
| i | |||
| 1 | 120646654 | 8.96245 | a |
| 2 | 111589675 | 8.28964 | i |
| 3 | 106665716 | 7.92385 | e |
| 4 | 102135976 | 7.58735 | o |
| 5 | 76298546 | 5.66797 | z |
| 6 | 75403146 | 5.60146 | n |
| 7 | 61445747 | 4.56461 | w |
| 8 | 61016675 | 4.53273 | r |
| 9 | 57237441 | 4.25198 | s |
| 10 | 53549355 | 3.97801 | c |
| 11 | 53399610 | 3.96688 | t |
| 12 | 52240953 | 3.88081 | y |
| 13 | 45634859 | 3.39007 | k |
| 14 | 44605635 | 3.31361 | d |
| 15 | 41733129 | 3.10022 | p |
| 16 | 38973075 | 2.89518 | m |
| 17 | 31851311 | 2.36613 | j |
| 18 | 31481368 | 2.33865 | u |
| 19 | 28274720 | 2.10044 | l |
| 20 | 23763998 | 1.76535 | ł |
| 21 | 19865437 | 1.47574 | b |
| 22 | 18405166 | 1.36726 | g |
| 23 | 15475239 | 1.14961 | ę |
| 24 | 14222227 | 1.05652 | h |
| 25 | 13906034 | 1.03303 | ą |
| 26 | 12130116 | 0.90111 | ż |
| 27 | 11204643 | 0.83236 | ó |
| 28 | 9280005 | 0.68938 | ś |
| 29 | 6119384 | 0.45459 | ć |
| 30 | 4087022 | 0.30361 | f |
| 31 | 2474196 | 0.18380 | ń |
| 32 | 826516 | 0.06140 | ź |
| 33 | 114138 | 0.00848 | v |
| 34 | 65450 | 0.00486 | x |
| 35 | 11434 | 0.00085 | q |
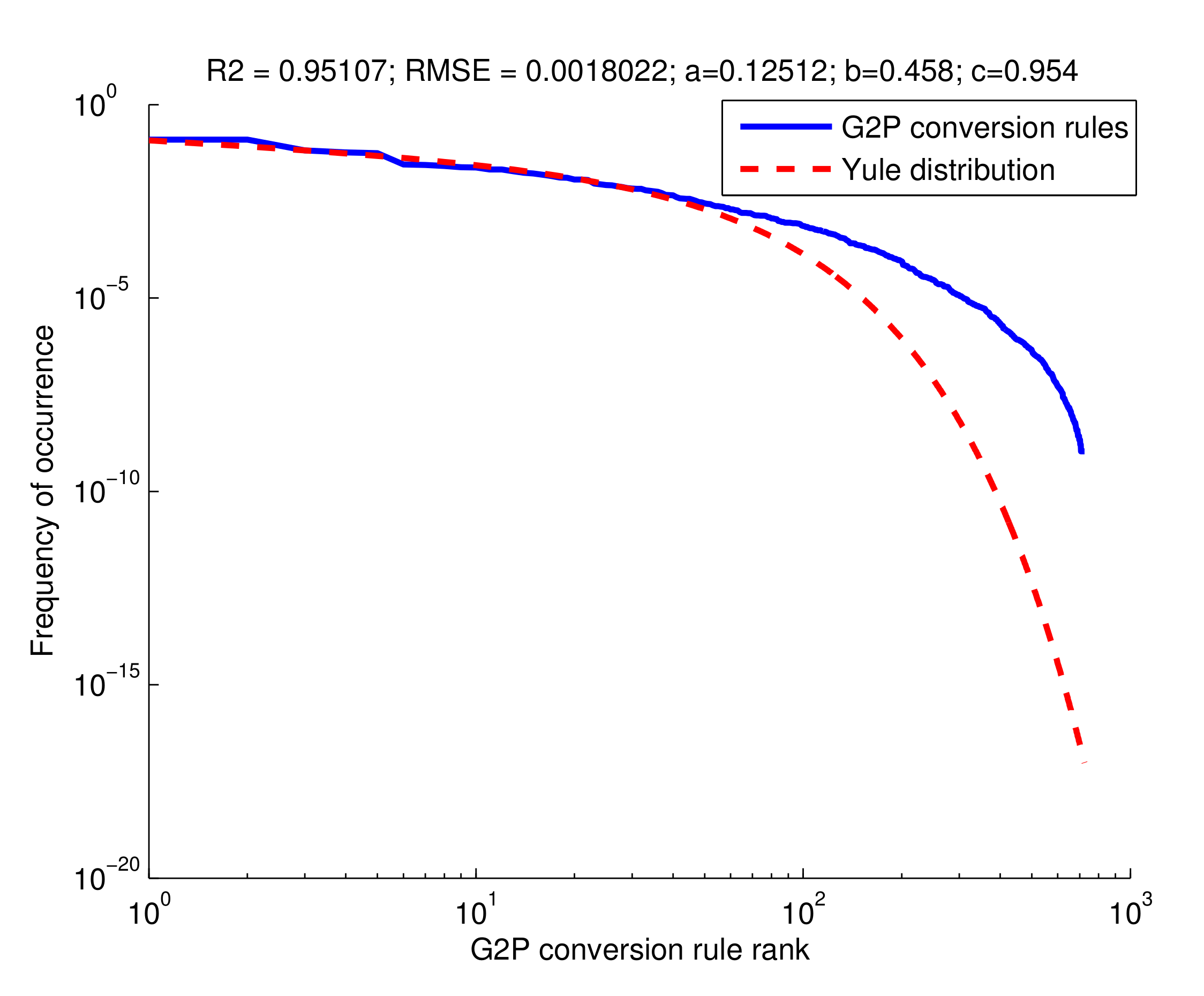
| No. | Yule’s Equation | ||
|---|---|---|---|
| 1 | 0.97509 | 2.9071 · 10−3 | |
| 2 | 0.95107 | 1.8022 · 10−3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kłosowski, P. A Rule-Based Grapheme-to-Phoneme Conversion System. Appl. Sci. 2022, 12, 2758. https://doi.org/10.3390/app12052758
Kłosowski P. A Rule-Based Grapheme-to-Phoneme Conversion System. Applied Sciences. 2022; 12(5):2758. https://doi.org/10.3390/app12052758
Chicago/Turabian StyleKłosowski, Piotr. 2022. "A Rule-Based Grapheme-to-Phoneme Conversion System" Applied Sciences 12, no. 5: 2758. https://doi.org/10.3390/app12052758
APA StyleKłosowski, P. (2022). A Rule-Based Grapheme-to-Phoneme Conversion System. Applied Sciences, 12(5), 2758. https://doi.org/10.3390/app12052758