
Hybrid Training Strategies: Improving Performance of Temporal Difference Learning in Board Games †


Abstract
:1. Introduction
2. Materials and Methods
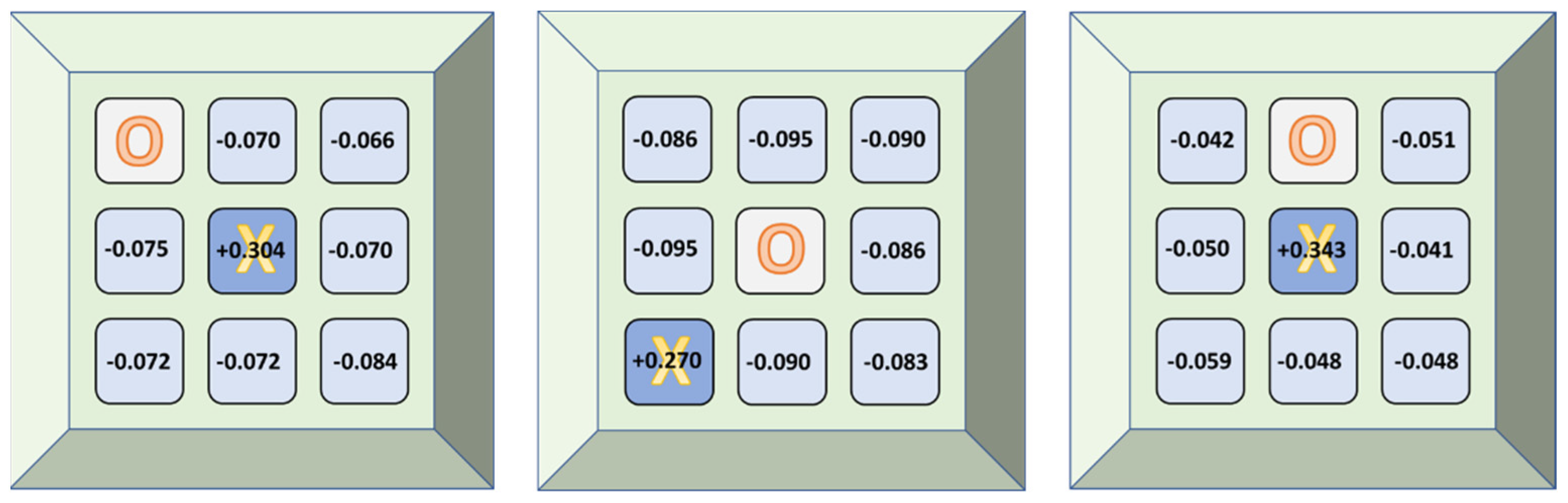
2.1. Tic-Tac-Toe Board Game
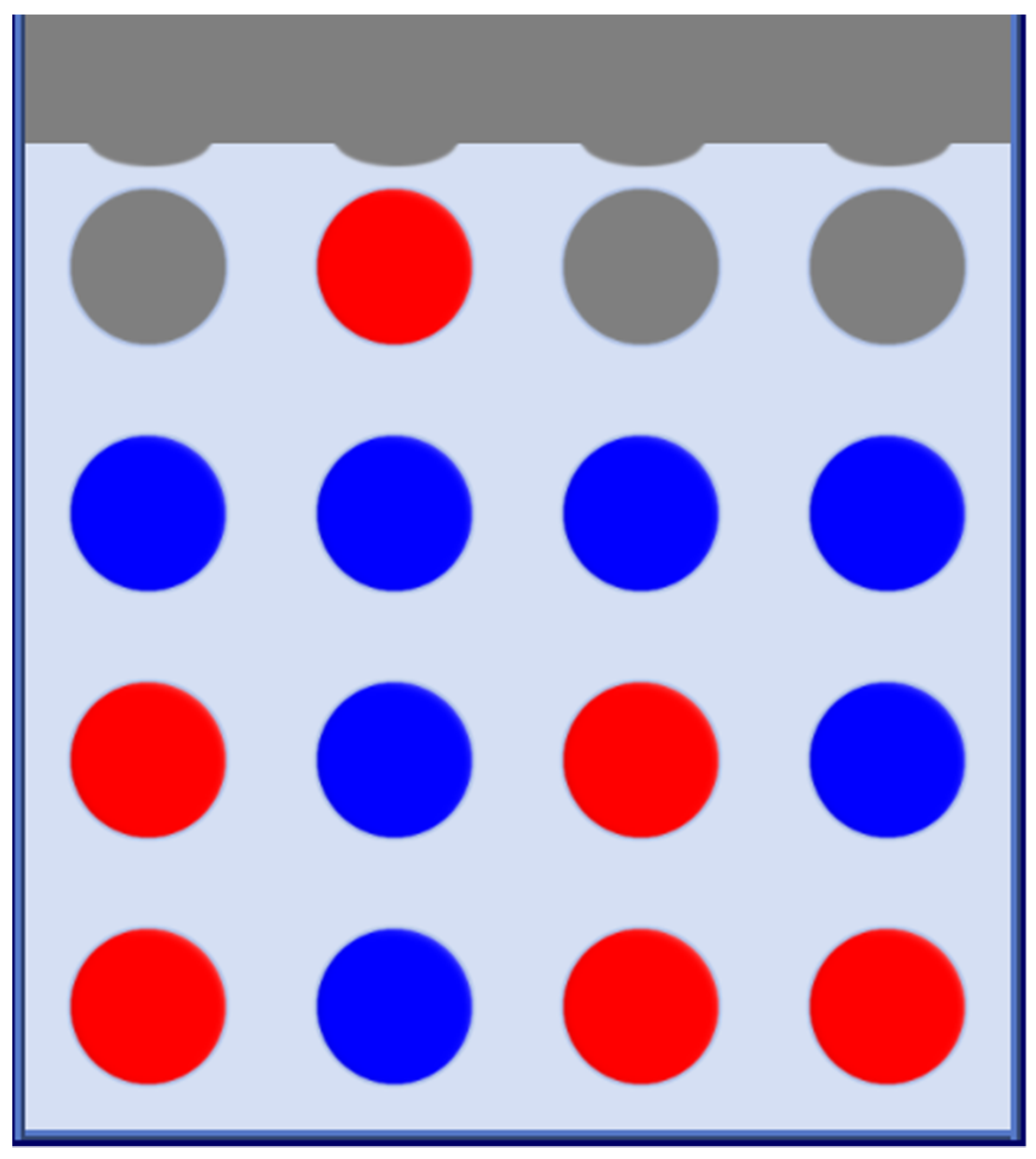
2.2. Connect-4 Board Game
2.3. TD-Learning Agent
// U: Utilities for all possible states
// seq: sequence of states visited in the last game
// n_moves: number of moves in the last game
if (TD_agent_won) {
U[current_state] = 1.0;
}
else if (opponent_won) {
U[current_state] = −1.0;
}
else { // tied up
U[current_state] = 0.2;
}
for (i = 1; i <= n_moves; i++) {
// this is the TD update rule equation
// ALPHA -> learning rate; DF -> discount factor
U[seq[n_moves-i]] += ALPHA*(DF*U[current_state]-U[seq[n_moves-i]]);
current_state = seq[n_moves-i];
}
2.4. Training Strategies
- Attack player. The player will first determine whether there is an imminent chance of winning and if so, will act accordingly. In all other cases, it will act randomly.
- Defense player. If the TD agent has an imminent chance to win, the player will obstruct it. It will act randomly in any other situation.
- Attack–Defense player. It integrates the previous two players, giving precedence to the attack feature. This player will try to win first; if it fails, it will check to see whether the TD agent will win in the following move and if so, it will obstruct it. Otherwise, it will act randomly.
- Defense–Attack player. It integrates the players (2) and (1), giving precedence to the defense feature. This player will first determine whether the TD agent has a chance to win the next move and if so, will obstruct it. If this is not the case, it will attempt to win if feasible. Otherwise, it will act randomly.
- Combined player. This player will behave as one of the above players, chosen randomly for every game played.
3. Experiments and Results
- The opponent utilized to train the TD agent is always the first player to move. It will represent one of the six training methods described in the preceding section (namely Attack, Defense, Attack–Defense, Defense–Attack, Combined, and Random). Each game’s opening move will always be random.
- The maximum number of training games is set to 2 million. Nevertheless, the training process finishes if there are no games lost during the last 50,000.
- In the TD update rule equation, the value of the learning rate α parameter is set to 0.25 and the value of the discount factor γ parameter is set to 1.
- For every potential state of the game, utilities are initially set to zero in each game.
- The degree of hybridness (random games introduced evenly in all the TD learning agents) is 1 out of 7 (14.286%).
- Following the completion of the training procedure, the TD agent will participate in a series of test games. The values of the utilities assessed by the TD agent during the training phase are constant in these test games.
- The number of test games against a fully random player is fixed to 1 million.
- In the tic-tac-toe game, the number of test games against an expert player is fixed to nine games, as the expert player’s moves are invariant for each game situation. Therefore, the only variable parameter is the first move, which can be made in any of the grid’s nine positions. For the same reason, in the 4 × 4 Connect-4 game, the number of test games against an expert player is fixed to four games, corresponding to the four columns of the board.
- The expert player has been implemented using the Minimax recursive algorithm, which chooses an optimal move for a player assuming that the opponent is also playing optimally [28].
3.1. Tic-Tac-Toe Training Phase Results
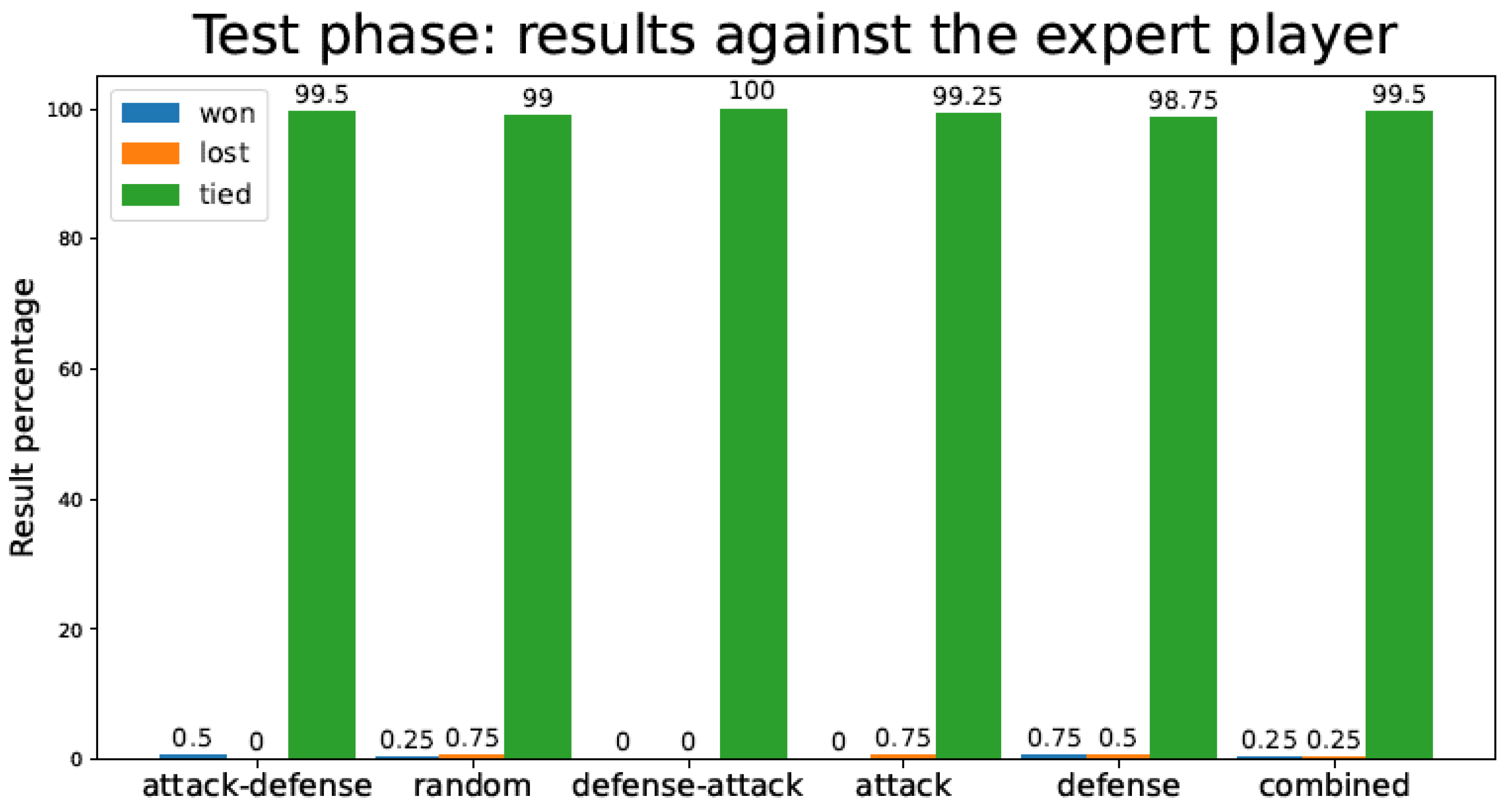
3.2. Tic-Tac-Toe Test Phase Results
3.3. Connect-4 Training Phase Results
3.4. Connect-4 Test Phase Results
3.5. Summary of Results
4. Discussion
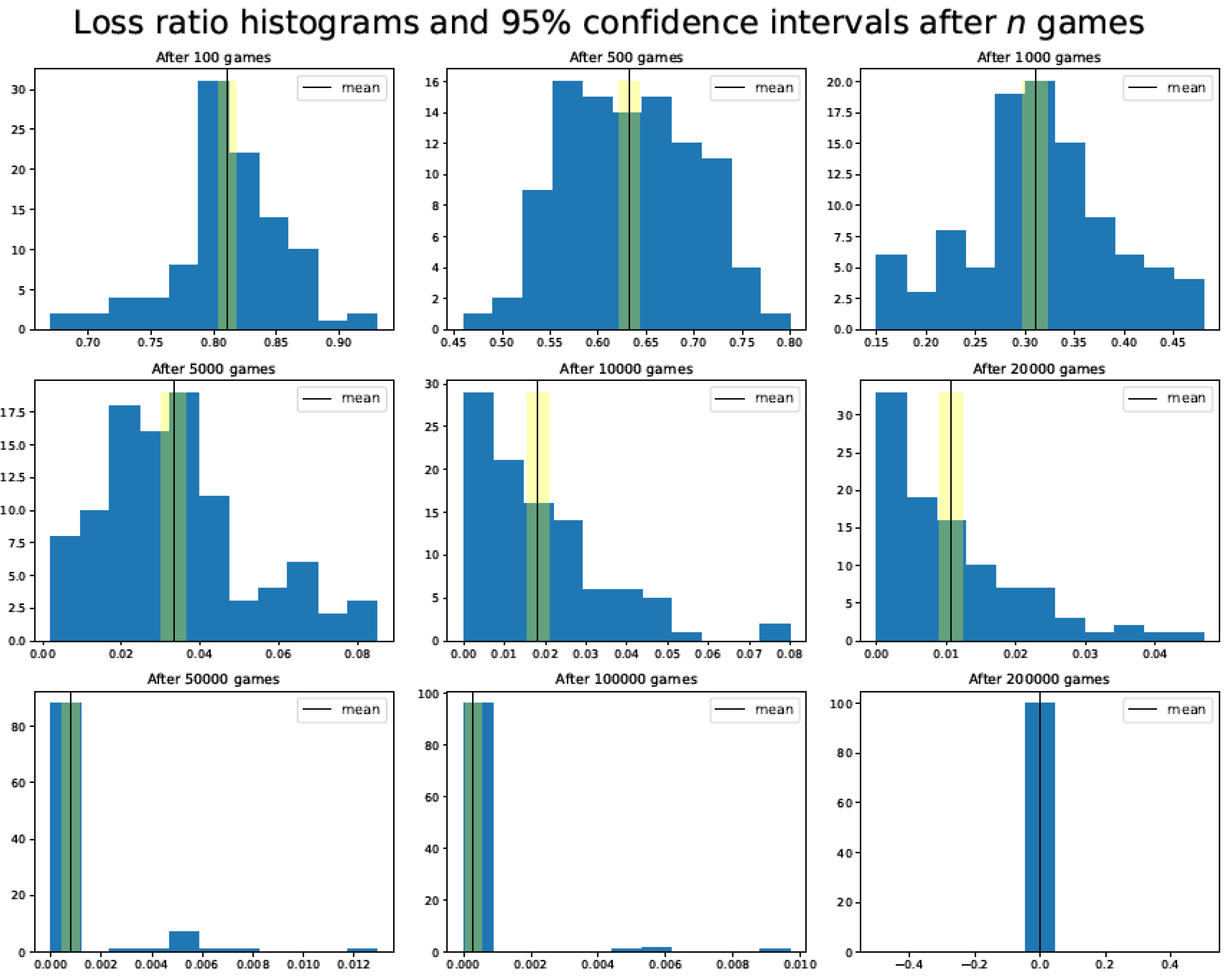
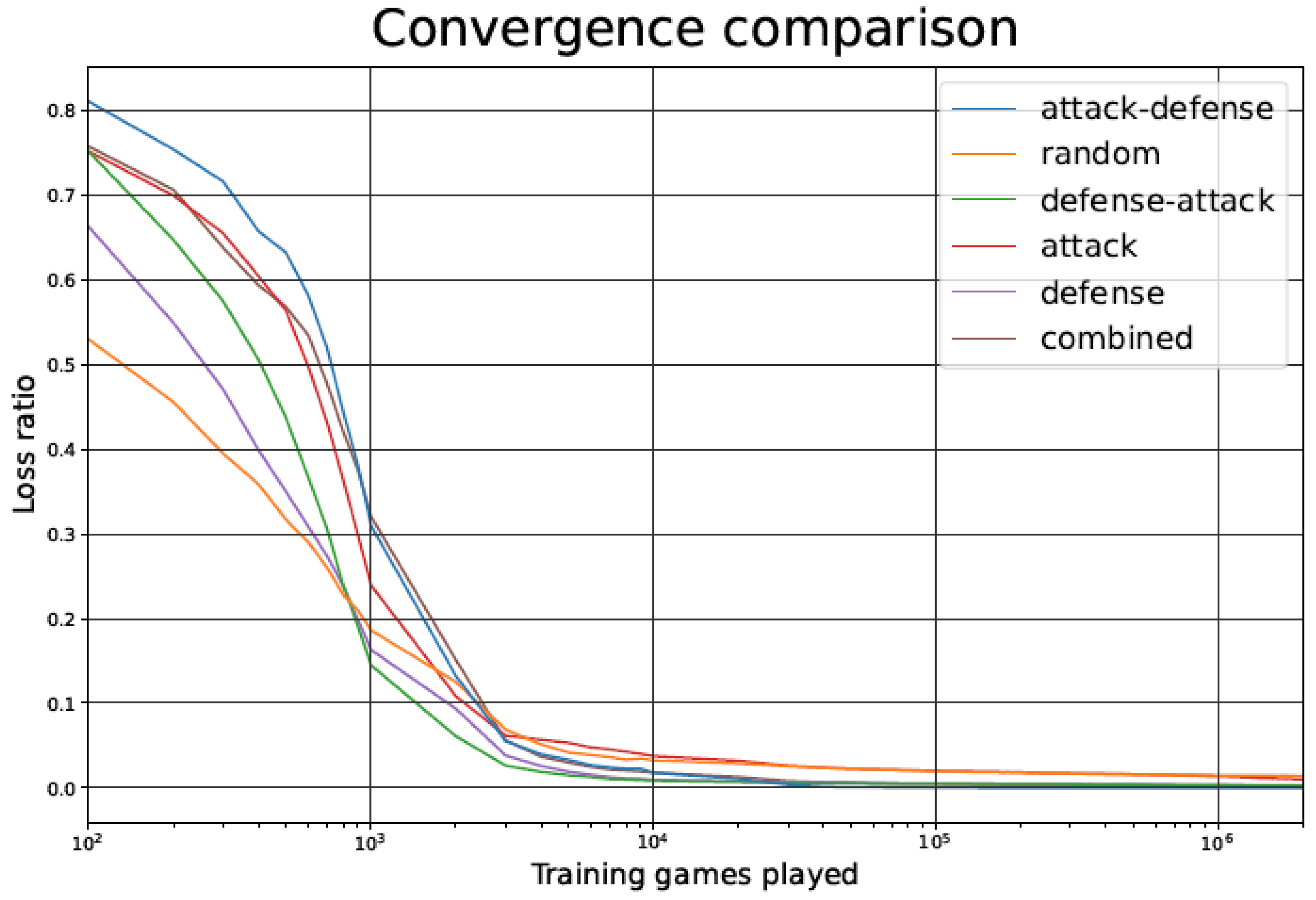
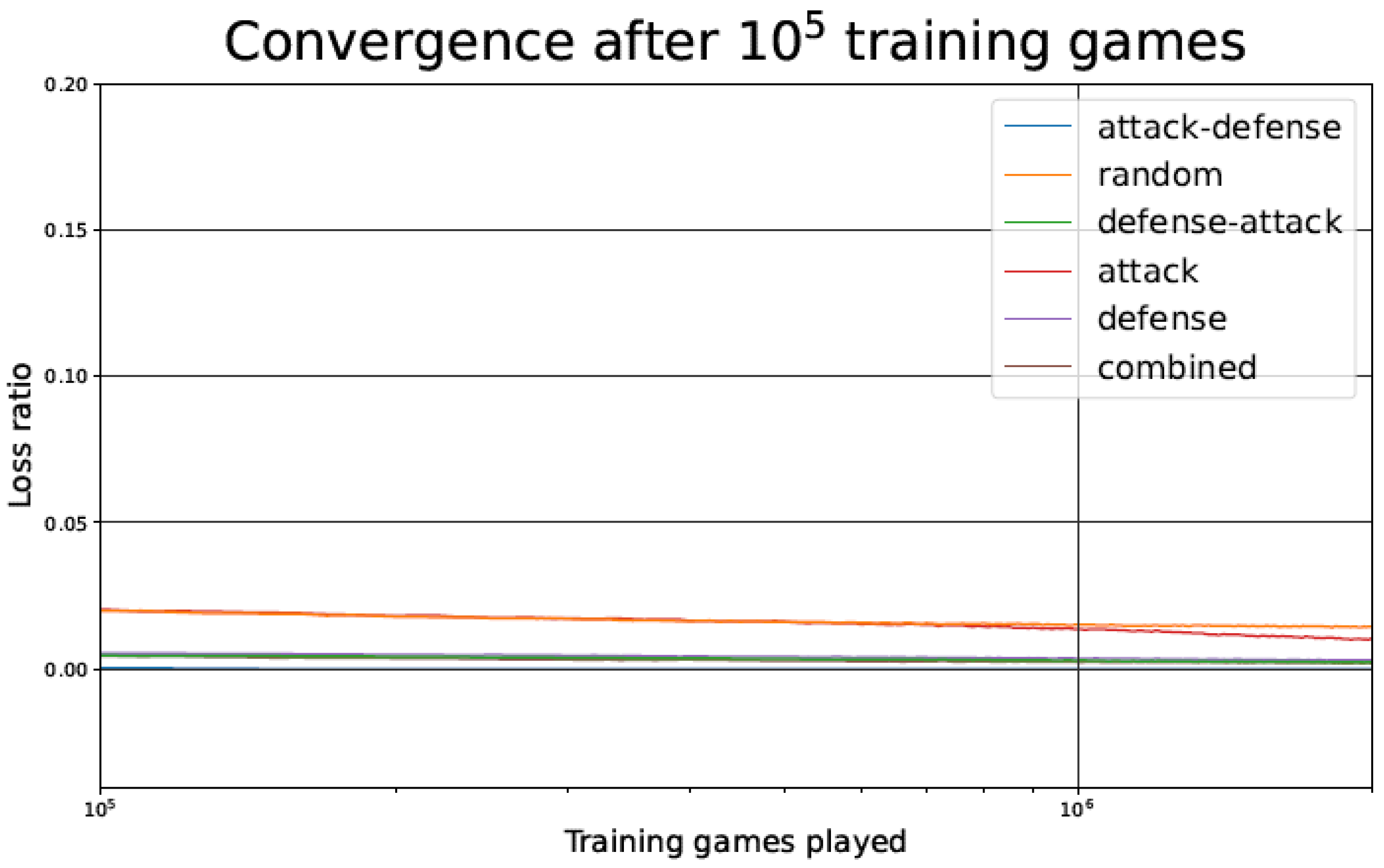
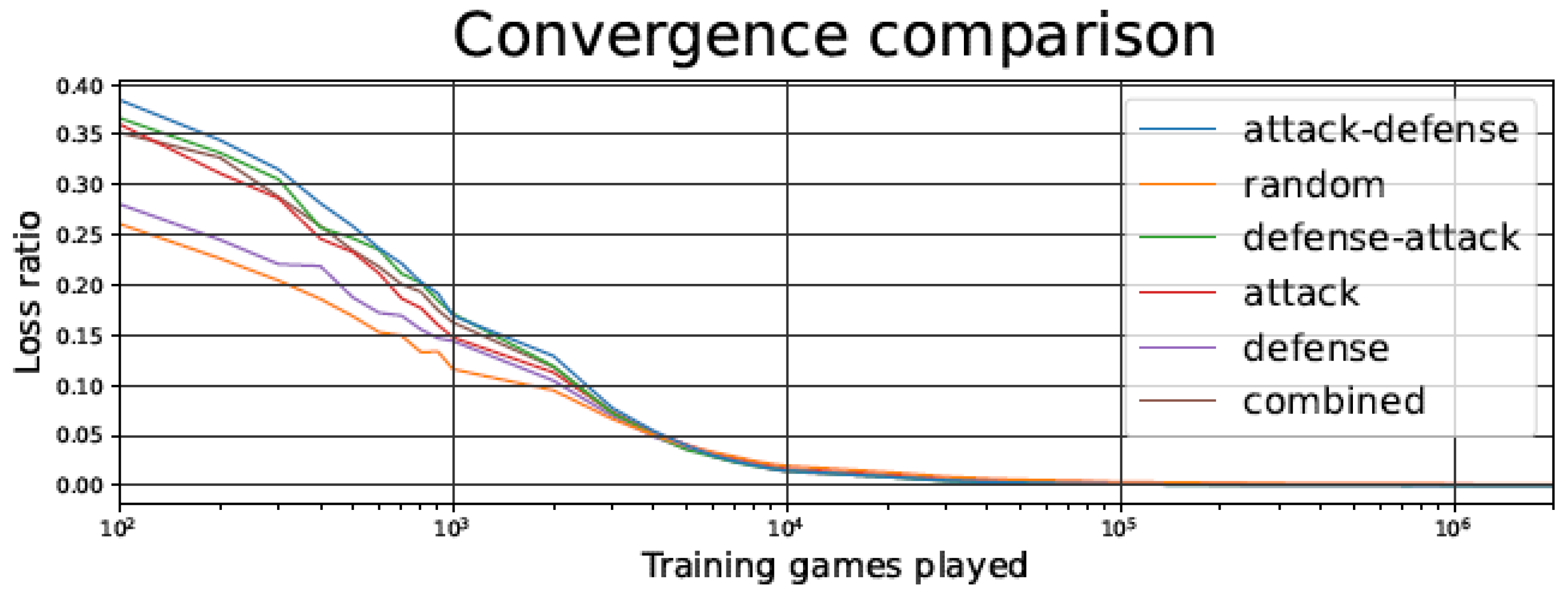
4.1. Loss Ratio during the Training Phase
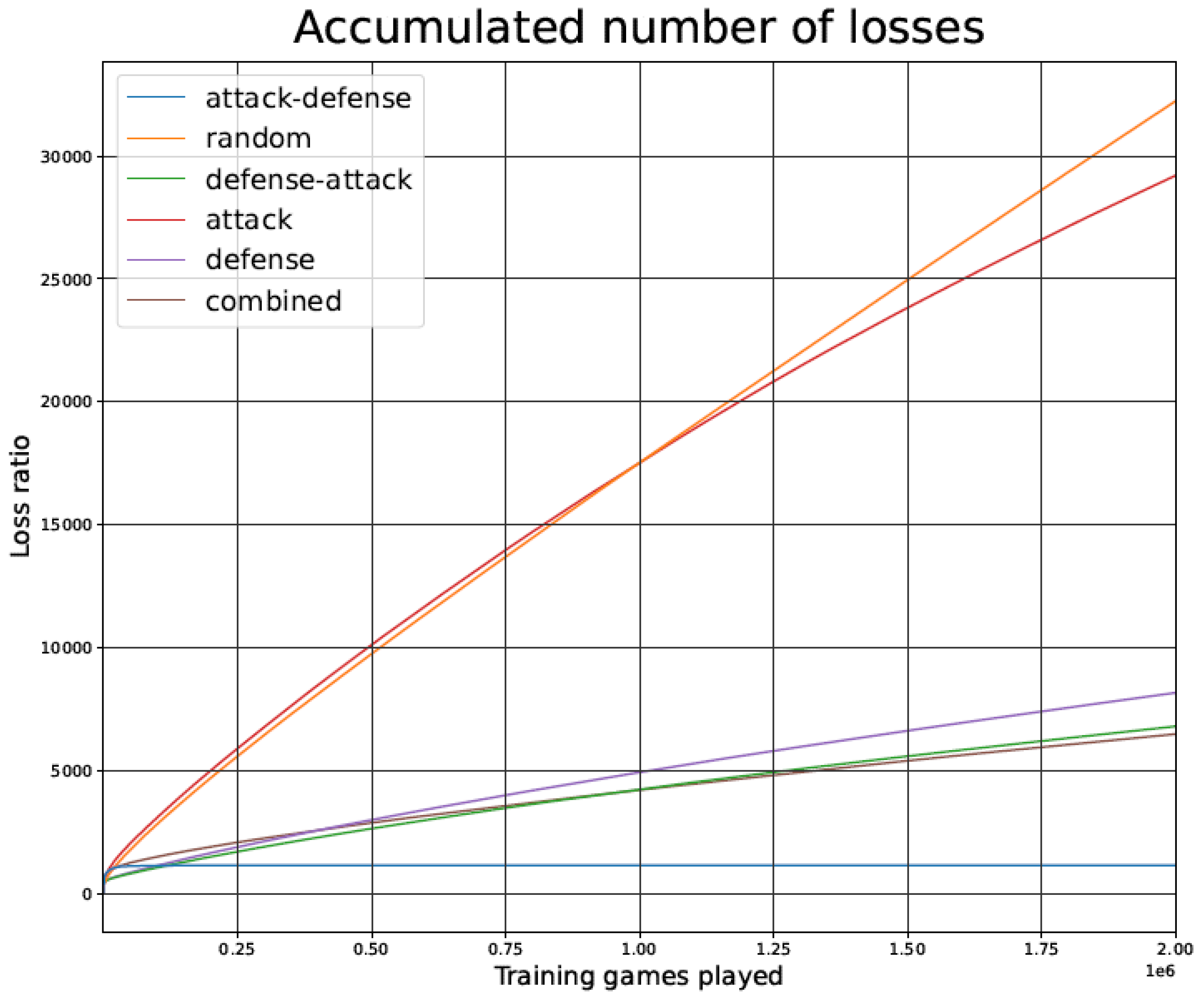
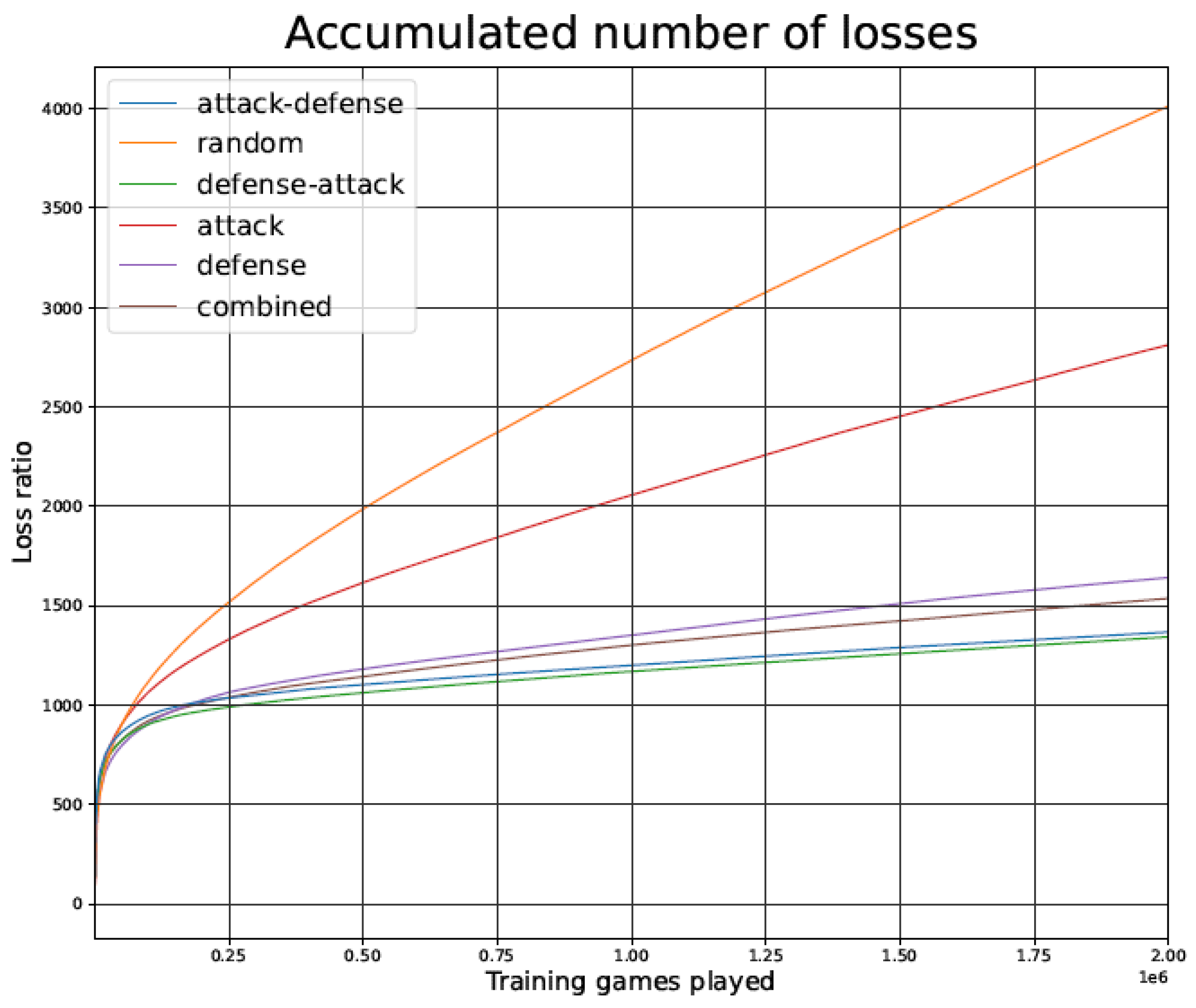
4.2. Games Lost during the Training Phase
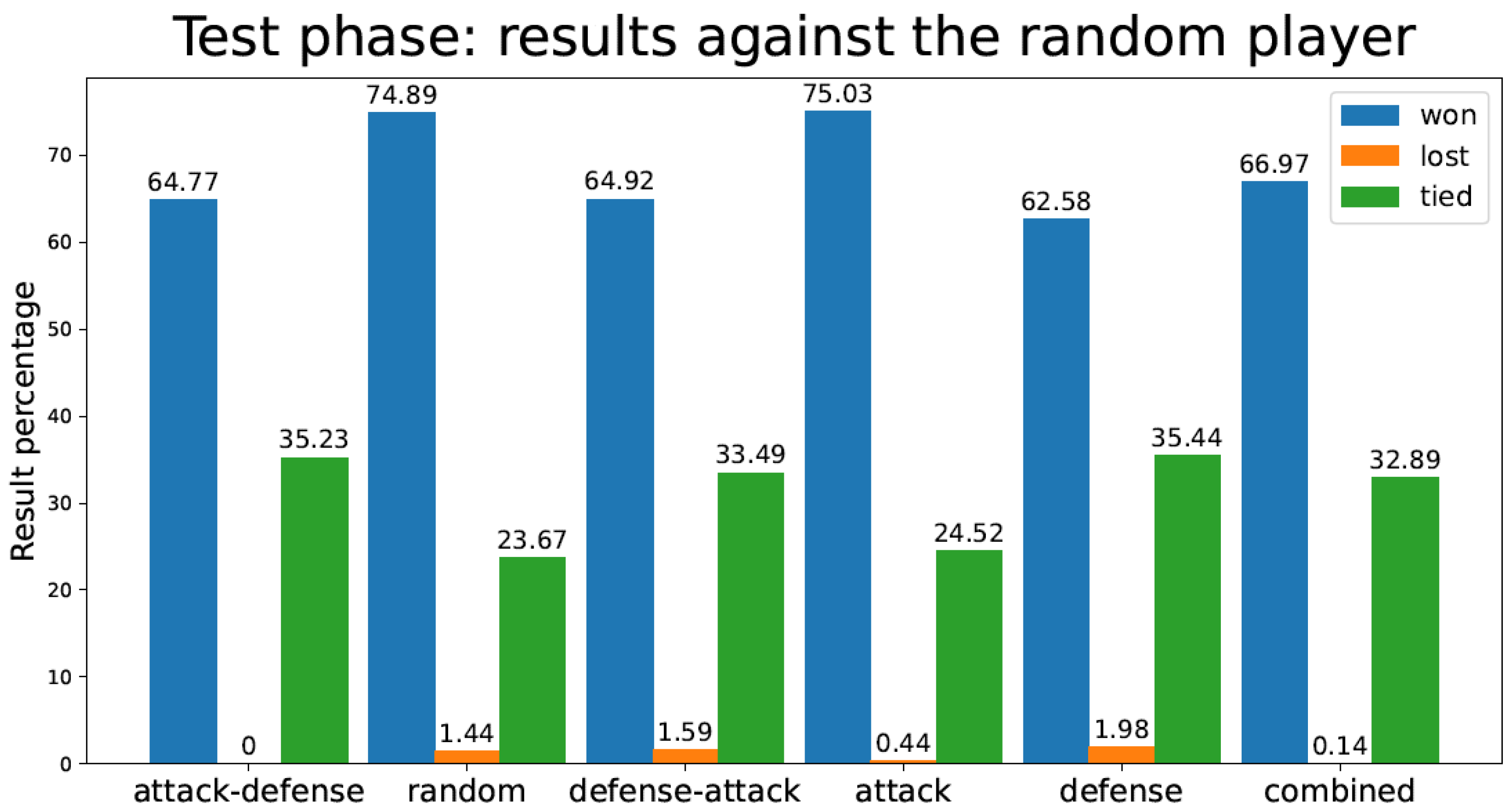
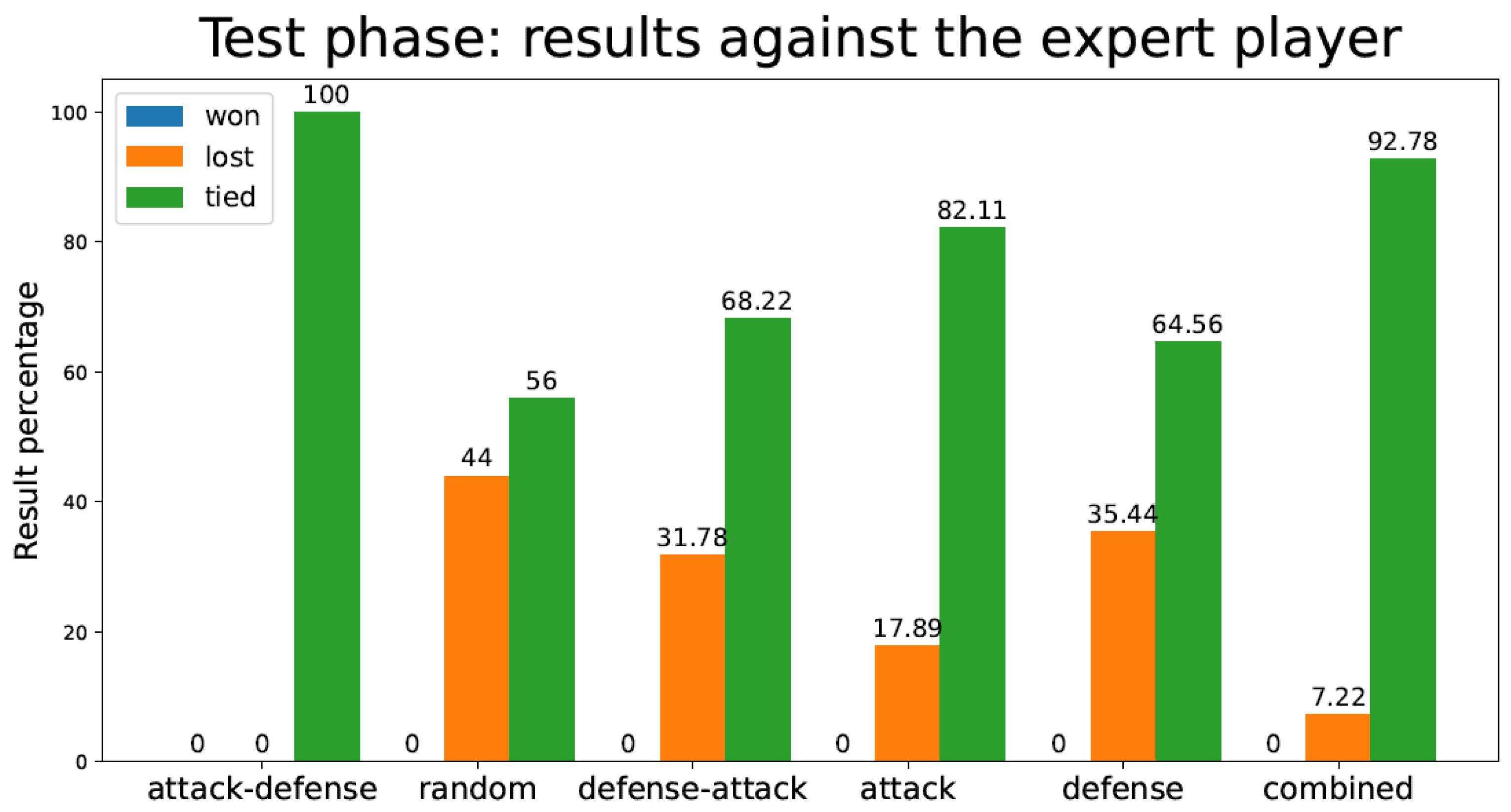
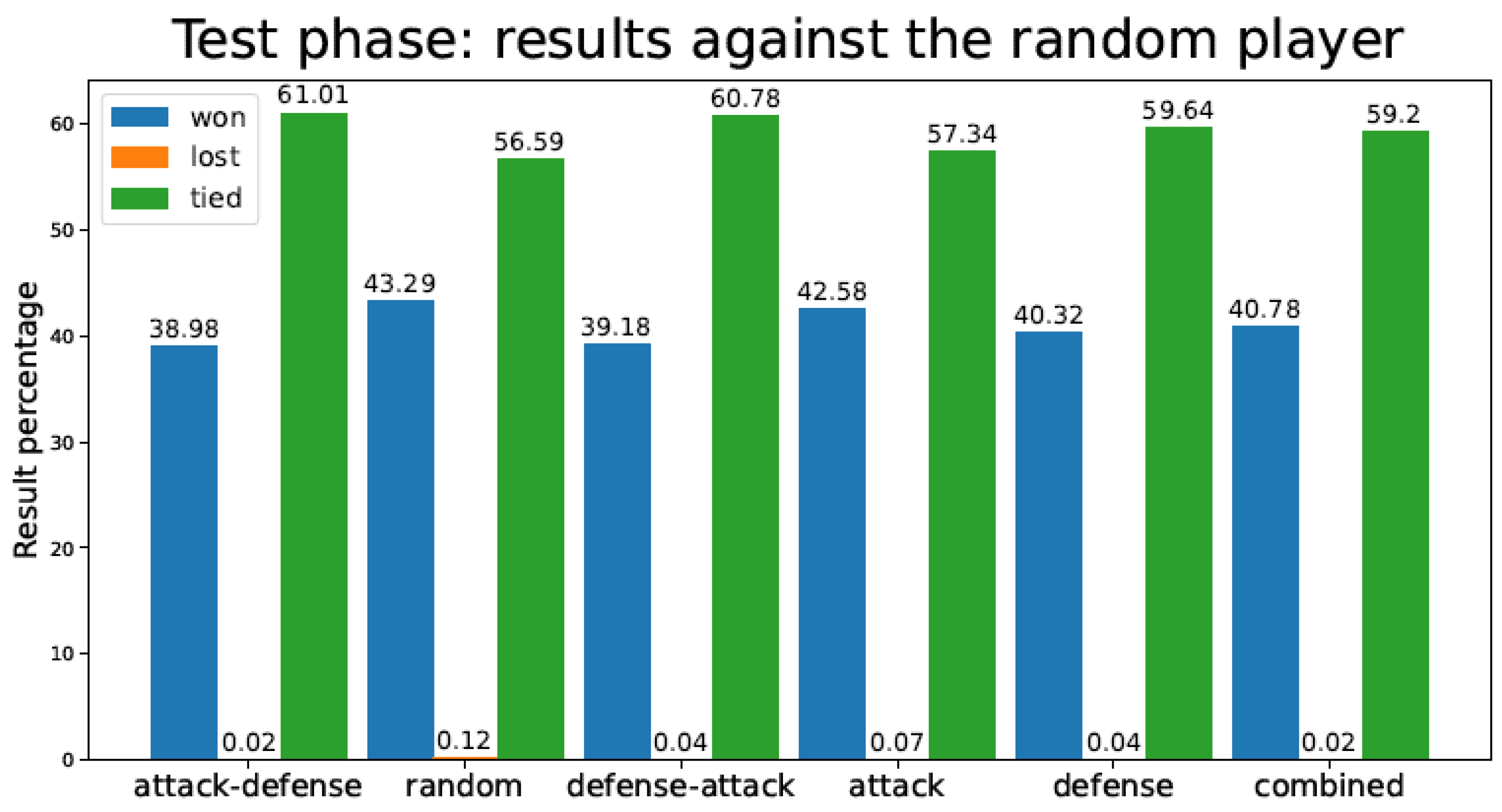
4.3. Games Lost during the Test Phase
4.4. The Attack–Defense Strategy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; pp. 10–15, 156. [Google Scholar]
- Konen, W.; Bartz-Beielstein, T. Reinforcement learning for games: Failures and successes. In Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers, Montreal, QC, Canada, 8–12 July 2009; pp. 2641–2648. [Google Scholar]
- Samuel, A. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Tesauro, G. Temporal difference learning of backgammon strategy. In Proceedings of the 9th International Workshop on Machine Learning, San Francisco, CA, USA, 1–3 July 1992; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1992; pp. 451–457. [Google Scholar] [CrossRef]
- Tesauro, G. Practical Issues in Temporal Difference Learning. Reinforcement Learning; Springer: Berlin/Heidelberg, Germany, 1992; pp. 33–53. [Google Scholar]
- Wiering, M.A. Self-Play and Using an Expert to Learn to Play Backgammon with Temporal Difference Learning. J. Intell. Learn. Syst. Appl. 2010, 2, 57–68. [Google Scholar] [CrossRef] [Green Version]
- Konen, W. Reinforcement Learning for Board Games: The Temporal Difference Algorithm; Technical Report; Research Center CIOP (Computational Intelligence, Optimization and Data Mining), TH Koln—Cologne University of Applied Sciences: Cologne, Germany, 2015. [Google Scholar] [CrossRef]
- Gatti, C.J.; Embrechts, M.J.; Linton, J.D. Reinforcement learning and the effects of parameter settings in the game of Chung Toi. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; pp. 3530–3535. [Google Scholar] [CrossRef]
- Gatti, C.J.; Linton, J.D.; Embrechts, M.J. A brief tutorial on reinforcement learning: The game of Chung Toi. In Proceedings of the ESANN 2011 Proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2011; ISBN 978-2-87419-044-5. [Google Scholar]
- Silver, D.; Sutton, R.; Muller, M. Reinforcement learning of local shape in the game of go. Int. Jt. Conf. Artif. Intell. (IJCAI) 2007, 7, 1053–1058. [Google Scholar]
- Schraudolph, N.; Dayan, P.; Sejnowski, T. Temporal Difference Learning of Position Evaluation in the Game of Go. Adv. Neural Inf. Processing Syst. 1994, 6, 1–8. [Google Scholar]
- Van der Ree, M.; Wiering, M.A. Reinforcement learning in the game of othello: Learning against a fixed opponent and learning from self-play. In Proceedings of the 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL), Singapore, 16–19 April 2013; pp. 108–115. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall Press: Upper Saddle River, NJ, USA, 2009; ISBN 0136042597/9780136042594. [Google Scholar]
- Sutton, R.S. Learning to Predict by the Methods of Temporal Differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Pool, D.; Mackworth, A. Artificial Intelligence: Foundations of Computational Agents, 2nd ed.; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Szubert, M.; Jaskowski, W.; Krawiec, K. Coevolutionary temporal difference learning for Othello. In Proceedings of the Proceedings of the 5th International Conference on Computational Intelligence and Games (CIG’09), Piscataway, NJ, USA, 7 September 2009; IEEE Press: Piscataway, NJ, USA, 2009; pp. 104–111. [Google Scholar]
- Krawiec, K.; Szubert, M. Learning n-tuple networks for Othello by coevolutionary gradient search. In Proceedings of the GECCO’2011, Dublin, Ireland, 12–16 July 2011; ACM: New York, NY, USA, 2011; pp. 355–362. [Google Scholar]
- Lucas, S.M. Learning to play Othello with n-tuple systems. Aust. J. Intell. Inf. Process. 2008, 4, 1–20. [Google Scholar]
- Thill, M.; Bagheri, S.; Koch, P.; Konen, W. Temporal Difference Learning with Eligibility Traces for the Game Connect-4. In Proceedings of the IEEE Conference on Computational Intelligence and Games (CIG), Dortmund, Germany, 26–29 August 2014. [Google Scholar]
- Steeg, M.; Drugan, M.; Wiering, M. Temporal Difference Learning for the Game Tic-Tac-Toe 3D: Applying Structure to Neural Networks. In Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 8–10 December 2015; pp. 564–570. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Conde, J.; Cuenca-Jiménez, P.; Cañas, J.M. An Efficient Training Strategy for a Temporal Difference Learning Based Tic-Tac-Toe Automatic Player. In Inventive Computation Technologies, International Conference on Inventive Computation Technologies ICICIT 2019, Coimbatore, India, 29–30 August 2019; Lecture Notes in Networks and Systems; Smys, S., Bestak, R., Rocha, Á., Eds.; Springer: Cham, Switzerland, 2019; Volume 98. [Google Scholar] [CrossRef]
- Baum, P. Tic-Tac-Toe. Master’s Thesis, Computer Science Department, Southern Illinois University, Carbondale, IL, USA, 1975. [Google Scholar]
- Crowley, K.; Siegler, R.S. Flexible strategy use in young children’s tic-tac-toe. Cogn. Sci. 1993, 17, 531–561. [Google Scholar] [CrossRef]
- Allen, J.D. A Note on the Computer Solution of Connect-Four. Heuristic Program. Artif. Intell. 1989, 1, 134–135. [Google Scholar]
- Allis, V.L. A Knowledge-Based Approach of Connect-Four. Master’s Thesis, Vrije Universiteit, Amsterdam, The Netherlands, 1988. [Google Scholar]
- Tromp, J. Solving Connect-4 in Medium Board Sizes. ICGA J. 2008, 31, 110–112. [Google Scholar] [CrossRef]
- Swaminathan, B.; Vaishali, R.; Subashri, R. Analysis of Minimax Algorithm Using Tic-Tac-Toe. In Intelligent Systems and Computer Technology; Hemanth, D.J., Kumar, V.D.A., Malathi, S., Eds.; IOS Press: Amsterdam, The Netherlands, 2020. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | Tic-Tac-Toe Training Games | Tic-Tac-Toe Time (s) | Connect-4 Training Games | Connect-4 Time (s) |
|---|---|---|---|---|
| Attack–Defense | 99,100 | 1.32 | 949,300 | 18.48 |
| Random | 2,000,000 | 13.84 | 1,780,700 | 27.45 |
| Defense–Attack | 2,000,000 | 30.68 | 1,017,400 | 24.26 |
| Attack | 1,776,300 | 19.63 | 1,461,200 | 28.9 |
| Defense | 2,000,000 | 26.35 | 1,248,700 | 24.39 |
| Combined | 1,184,200 | 13.79 | 1,022,500 | 21.17 |
| Strategy | Tic-Tac-Toe TD Agent Becomes Perfect Player | Connect-4 TD Agent Becomes Perfect Player |
|---|---|---|
| Attack–Defense | 100% of runs | 35% of runs |
| Random | 0% of runs | 15% of runs |
| Defense–Attack | 0% of runs | 10% of runs |
| Attack | 19% of runs | 28% of runs |
| Defense | 0% of runs | 11% of runs |
| Combined | 50% of runs | 34% of runs |
| Strategy | Tic-Tac-Toe TD Agent Test Games Lost Against Random Player | Connect-4 TD Agent Test Games Lost Against Random Player |
|---|---|---|
| Attack–Defense | 0 | 175.78 |
| Random | 14,400.85 | 1,196.59 |
| Defense–Attack | 15,883.17 | 367.06 |
| Attack | 4,435.57 | 734.06 |
| Defense | 19,805.04 | 448.16 |
| Combined | 1425 | 199.37 |
| Strategy | Tic-Tac-Toe TD Agent Test Games Lost Against Expert Player | Connect-4 TD Agent Test Games Lost Against Expert Player |
|---|---|---|
| Attack–Defense | 0 | 0 |
| Random | 3.96 | 0.05 |
| Defense–Attack | 2.86 | 0 |
| Attack | 1.61 | 0.03 |
| Defense | 3.19 | 0.02 |
| Combined | 0.65 | 0.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernández-Conde, J.; Cuenca-Jiménez, P.; Cañas, J.M. Hybrid Training Strategies: Improving Performance of Temporal Difference Learning in Board Games. Appl. Sci. 2022, 12, 2854. https://doi.org/10.3390/app12062854
Fernández-Conde J, Cuenca-Jiménez P, Cañas JM. Hybrid Training Strategies: Improving Performance of Temporal Difference Learning in Board Games. Applied Sciences. 2022; 12(6):2854. https://doi.org/10.3390/app12062854
Chicago/Turabian StyleFernández-Conde, Jesús, Pedro Cuenca-Jiménez, and José M. Cañas. 2022. "Hybrid Training Strategies: Improving Performance of Temporal Difference Learning in Board Games" Applied Sciences 12, no. 6: 2854. https://doi.org/10.3390/app12062854
APA StyleFernández-Conde, J., Cuenca-Jiménez, P., & Cañas, J. M. (2022). Hybrid Training Strategies: Improving Performance of Temporal Difference Learning in Board Games. Applied Sciences, 12(6), 2854. https://doi.org/10.3390/app12062854