
Hyperspectral Image Classification with Imbalanced Data Based on Semi-Supervised Learning

 ,
, 
 ,
,
Abstract
:1. Introduction
- We propose a novel preprocessing solution called NearPseudo, to utilize the natural features of unlabeled data to improve the classification of imbalanced data; NearPseudo generates pseudo-labels for unlabeled samples and creates a feedback mechanism based on a consistency check to increase its reliability.
- Compared to other common processing methods in different imbalanced environments, NearPseudo performs better in hyperspectral image classification, especially in the case of an extremely imbalanced dataset. Simultaneously, NearPseudo can effectively improve the accuracy of most minority classes.
- We report the simplicity and universality of NearPseudo. After balancing by NearPseudo, the classification accuracy of most common classifiers, including RF, classification and regression tree (CART), LR, and k-nearest neighbors (kNN), was improved.
2. Proposed Method
| Algorithm 1: Pseudocode for selecting samples and generating labels for NearPseudo. |
Require:, imbalance training set with known labels, where v is the number of bands, n is the number of training samples. Require:, unlabeled set, where z is the size of the unlabeled set. Require:q, the number of samples in a random subset. Require:k, the number of the nearest neighbour samples we obtain for each iteration. 1: initialization classifier 2: 3: select a random subset 4: select a random sample in minority classes 5: compute distances between and each sample in , search k closet samples. 6: initialization: 7: 8: select nearest neighbour 9: generate its pseudo-label 10: check the consistency 11: add to formulate a new sample 12: 13: is the balance training dataset 14: |
3. Materials and Experimental Setup
3.1. Datasets
3.2. Experimental Setup
3.2.1. Sampling the Imbalanced Data Subset
3.2.2. Processing Method and Classifiers
3.3. Evaluation Criteria
4. Results
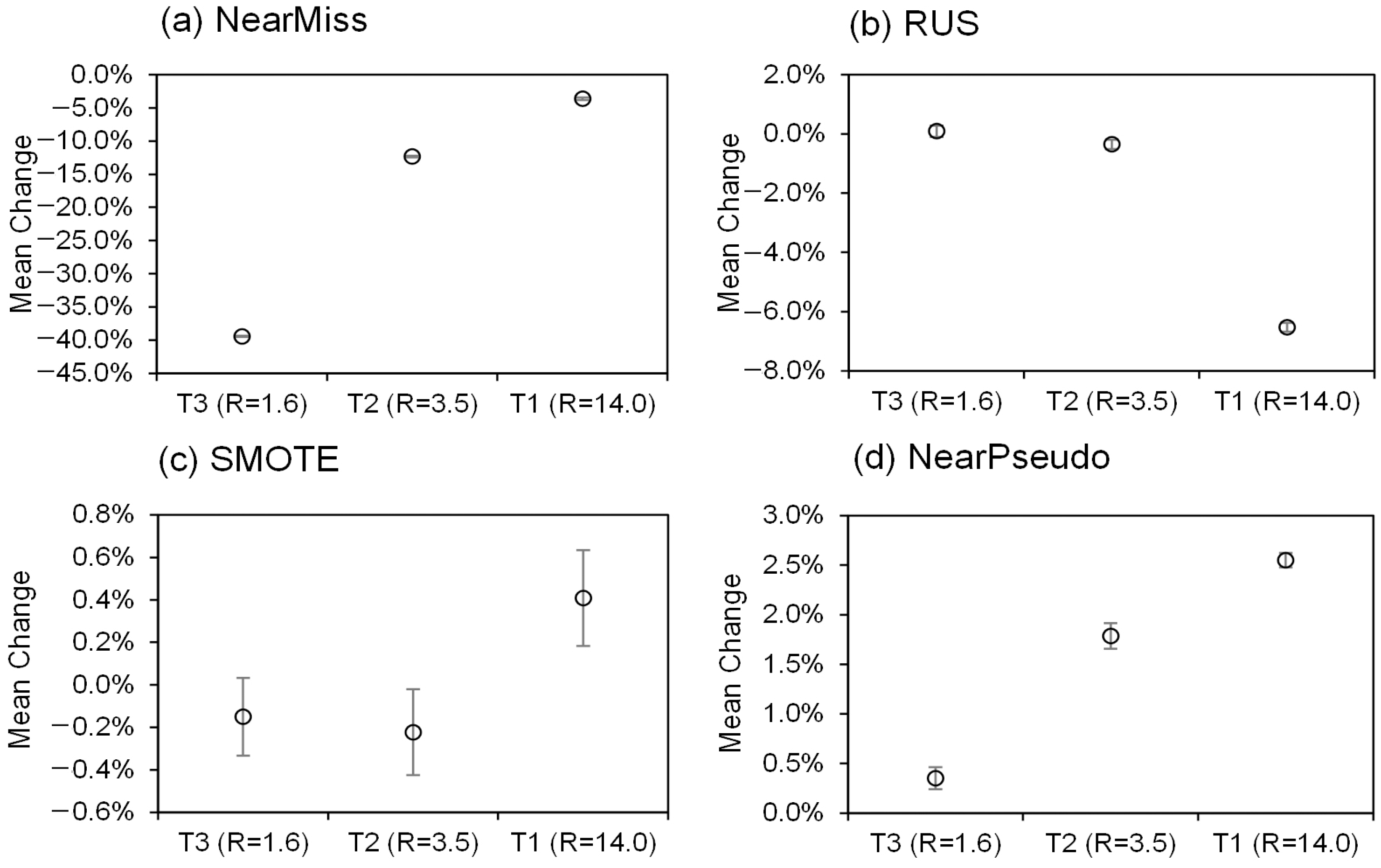
4.1. Comparison of Classification Results
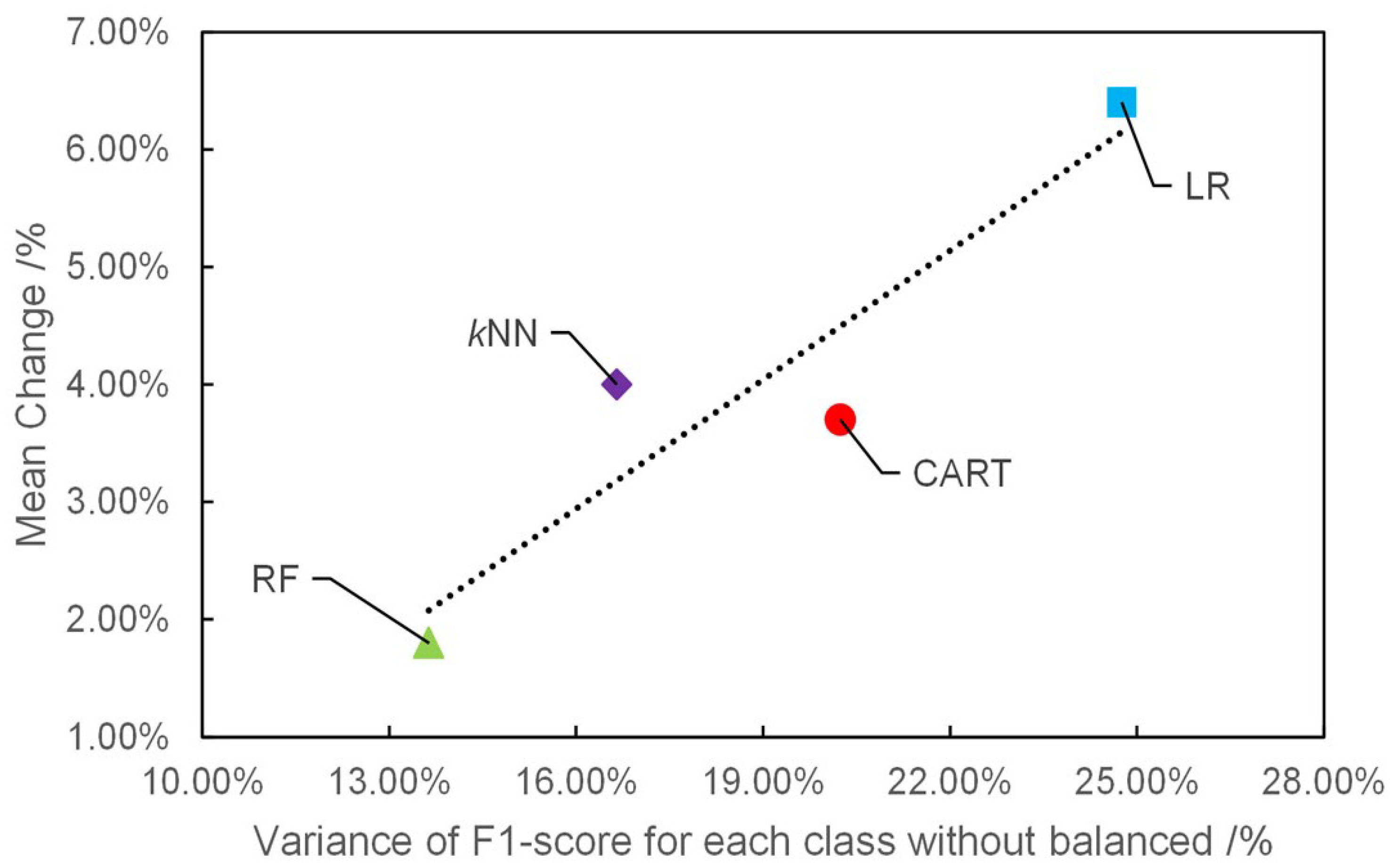
4.2. Comparison of Different Multi-Classification Algorithms
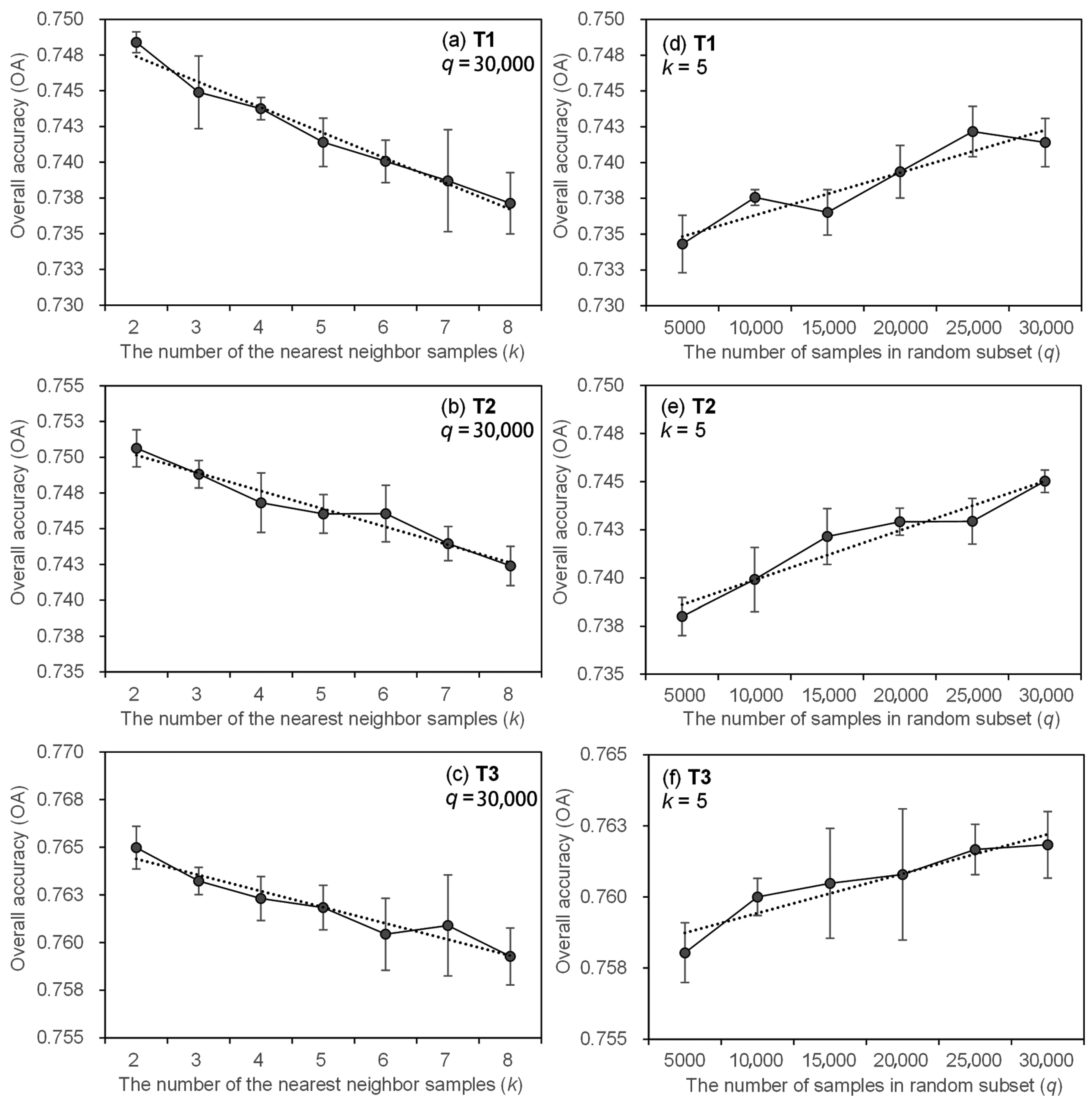
4.3. Impact of Different Hyperparameters
5. Discussion
5.1. Effect of NearPseudo on Different Multi-Classification Algorithms
5.2. Effect of Hyperparameters on Performance
5.3. Limitations
6. Conclusions
- Compared with other methods, NearPseudo exhibits enhanced efficiency and superiority in balancing data with semi-supervised learning. In addition, NearPseudo is more suitable for extremely imbalanced datasets. After using NearPseudo, the RF accuracies of the sub-training set T1, T2, and T3 were improved by 2.6%, 1.9%, and 0.4%, respectively.
- The classification performance of most minority classes can be improved by using NearPseudo. After using NearPseudo, the average accuracy of minority classes with fewest samples in T1, T2, and T3 were improved by 2.6%, 4.7%, and 1.0%, respectively.
- The classification performance of most multi-classifiers with imbalanced data can be improved by using NearPseudo. After using NearPseudo, the accuracy of RF, kNN, LR, and CART increased by 1.8%, 4.0%, 6.4% and 3.7% in sub-training sets T2, respectively.
- The performance of NearPseudo increases with hyperparameter q and decreases with hyperparameter k.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| x | Scalars |
| Vectors | |
| Training dataset | |
| Unlabeled dataset | |
| n | The number of total samples for |
| The number of supplement samples | |
| v | The number of bands/features |
| m | The number of categorizations |
| z | The number of total samples for |
| q | The number of random subset samples |
| k | The number of nearest neighbor samples |
| OA | Overall accuracy |
| AF | Average F1-score |
| LR | Logistic regression |
| RF | Random forest |
| CART | Classification and regression tree |
| kNN | k-nearest neighbors |
| SMOTE | Synthetic minority oversampling technique |
| RUS | Random undersampling |
| AMMIS | Airborne multi-modular imaging spectrometer |
| VNIR | Visible near-infrared |
| SWIR | Shortwave infrared |
| LWIR | Long wave infrared |
References
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Du, Q.; Li, Y.; Li, W. Hyperspectral Image Classification with Imbalanced Data Based on Orthogonal Complement Subspace Projection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3838–3851. [Google Scholar] [CrossRef]
- Sun, T.; Jiao, L.; Feng, J.; Liu, F.; Zhang, X. Imbalanced Hyperspectral Image Classification Based on Maximum Margin. IEEE Geosci. Remote Sens. Lett. 2015, 12, 522–526. [Google Scholar] [CrossRef]
- Nalepa, J.; Myller, M.; Kawulok, M. Training- and Test-Time Data Augmentation for Hyperspectral Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2020, 17, 292–296. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from Class-Imbalanced Data: Review of Methods and Applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Yijing, L.; Haixiang, G.; Xiao, L.; Yanan, L.; Jinling, L. Adapted Ensemble Classification Algorithm Based on Multiple Classifier System and Feature Selection for Classifying Multi-Class Imbalanced Data. Knowl.-Based Syst. 2016, 94, 88–104. [Google Scholar] [CrossRef]
- Japkowicz, N.; Stephen, S. The Class Imbalance Problem: A Systematic Study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Mor-Yosef, S.; Arnon, S.; Modan, B.; Navot, D.; Schenker, J. Ranking the Risk Factors for Cesarean: Logistic Regression Analysis of a Nationwide Study. Obstet. Gynecol. 1990, 75, 944–947. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Jia, S.; Jiang, S.; Lin, Z.; Li, N.; Xu, M.; Yu, S. A survey: Deep learning for hyperspectral image classification with few labeled samples. Neurocomputing 2021, 448, 179–204. [Google Scholar] [CrossRef]
- Jia, J.; Chen, J.; Zheng, X.; Wang, Y.; Guo, S.; Sun, H.; Jiang, C.; Karjalainen, M.; Karila, K.; Duan, Z.; et al. Tradeoffs in the Spatial and Spectral Resolution of Airborne Hyperspectral Imaging Systems: A Crop Identification Case Study. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An Insight into Classification with Imbalanced Data: Empirical Results and Current Trends on Using Data Intrinsic Characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Loyola-González, O.; Martínez-Trinidad, J.F.; Carrasco-Ochoa, J.A.; García-Borroto, M. Study of the Impact of Resampling Methods for Contrast Pattern Based Classifiers in Imbalanced Databases. Neurocomputing 2016, 175, 935–947. [Google Scholar] [CrossRef]
- Beyan, C.; Fisher, R. Classifying Imbalanced Data Sets Using Similarity Based Hierarchical Decomposition. Pattern Recognit. 2015, 48, 1653–1672. [Google Scholar] [CrossRef] [Green Version]
- Wenzhi, L.; Pizurica, A.; Bellens, R.; Gautama, S.; Philips, W. Generalized Graph-Based Fusion of Hyperspectral and LiDAR Data Using Morphological Features. IEEE Geosci. Remote Sens. Lett. 2015, 12, 552–556. [Google Scholar] [CrossRef]
- Kwan, C.; Gribben, D.; Ayhan, B.; Li, J.; Bernabe, S.; Plaza, A. An Accurate Vegetation and Non-Vegetation Differentiation Approach Based on Land Cover Classification. Remote Sens. 2020, 12, 3880. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Abdi, L.; Hashemi, S. To Combat Multi-Class Imbalanced Problems by Means of over-Sampling Techniques. IEEE Trans. Knowl. Data Eng. 2016, 28, 238–251. [Google Scholar] [CrossRef]
- Lin, K.B.; Weng, W.; Lai, R.K.; Lu, P. Imbalance Data Classification Algorithm Based on SVM and Clustering Function. In Proceedings of the 9th International Conference on Computer Science and Education (ICCCSE), Vancouver, BC, USA, 22–24 August 2014; pp. 544–548. [Google Scholar] [CrossRef]
- Estabrooks, A.; Jo, D.T.; Japkowicz, N. A Multiple Resampling Method for Learning from Imbalanced Data Sets. Comput. Intell. 2004, 20, 18–36. [Google Scholar] [CrossRef] [Green Version]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A Systematic Review on Imbalanced Data Challenges in Machine Learning: Applications and Solutions. ACM Comput. Surv. 2019, 52. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Zhang, J.; Mani, I. KNN Approach to Unbalanced Data Distributions: A Case Study Involving Information Extraction. In Proceedings of the ICML’2003 Workshop on Learning from Imbalanced Datasets, Washington, DC, USA, 21 August 2003. [Google Scholar]
- Galar, M.; Fernández, A.; Barrenechea, E.; Herrera, F. EUSBoost: Enhancing Ensembles for Highly Imbalanced Data-Sets by Evolutionary Undersampling. Pattern Recognit. 2013, 46, 3460–3471. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B. Introduction to Semi-Supervised Learning. Synth. Lect. Artif. Intell. Mach. Learn. 2009, 3, 1–130. [Google Scholar] [CrossRef] [Green Version]
- Grandvalet, Y.; Bengio, Y. Semi-Supervised Learning by Entropy Minimization. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 13–18 December 2004. [Google Scholar]
- Cui, B.; Xie, X.; Hao, S.; Cui, J.; Lu, Y. Semi-Supervised Classification of Hyperspectral Images Based on Extended Label Propagation and Rolling Guidance Filtering. Remote Sens. 2018, 10, 515. [Google Scholar] [CrossRef] [Green Version]
- Dopido, I.; Li, J.; Marpu, P.R.; Plaza, A.; Bioucas Dias, J.M.; Benediktsson, J.A. Semisupervised Self-Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4032–4044. [Google Scholar] [CrossRef] [Green Version]
- Camps-Valls, G.; Bandos Marsheva, T.V.; Zhou, D. Semi-Supervised Graph-Based Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3044–3054. [Google Scholar] [CrossRef]
- Shao, Y.; Sang, N.; Gao, C.; Ma, L. Spatial and Class Structure Regularized Sparse Representation Graph for Semi-Supervised Hyperspectral Image Classification. Pattern Recognit. 2018, 81, 81–94. [Google Scholar] [CrossRef]
- Lu, X.; Wu, H.; Yuan, Y.; Yan, P.; Li, X. Manifold Regularized Sparse NMF for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2815–2826. [Google Scholar] [CrossRef]
- Wang, Z.; Du, B.; Zhang, L.; Zhang, L. A Batch-Mode Active Learning Framework by Querying Discriminative and Representative Samples for Hyperspectral Image Classification. Neurocomputing 2016, 179, 88–100. [Google Scholar] [CrossRef]
- Zhang, Z.; Pasolli, E.; Crawford, M.M.; Tilton, J.C. An Active Learning Framework for Hyperspectral Image Classification Using Hierarchical Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 640–654. [Google Scholar] [CrossRef]
- He, Z.; Liu, H.; Wang, Y.; Hu, J. Generative Adversarial Networks-Based Semi-Supervised Learning for Hyperspectral Image Classification. Remote Sens. 2017, 9, 1042. [Google Scholar] [CrossRef] [Green Version]
- Zhan, Y.; Hu, D.; Wang, Y.; Yu, X. Semisupervised Hyperspectral Image Classification Based on Generative Adversarial Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 212–216. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Tao, C.; Wang, H.; Qi, J.; Li, H. Semisupervised Variational Generative Adversarial Networks for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 914–927. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, X.; Bo, Y.; Chen, J. Semisupervised Hyperspectral Image Classification with Cluster-Based Conditional Generative Adversarial Net. IEEE Geosci. Remote Sens. Lett. 2020, 17, 539–543. [Google Scholar] [CrossRef]
- Zeng, H.; Liu, Q.; Zhang, M.; Han, X.; Wang, Y. Semi-Supervised Hyperspectral Image Classification with Graph Clustering Convolutional Networks. arXiv 2020, arXiv:2012.10932. [Google Scholar]
- Sha, A.; Wang, B.; Wu, X.; Zhang, L. Semisupervised Classification for Hyperspectral Images Using Graph Attention Networks. IEEE Geosci. Remote Sens. Lett. 2021, 18, 157–161. [Google Scholar] [CrossRef]
- Wang, H.; Cheng, Y.; Chen, C.L.P.; Wang, X. Semisupervised Classification of Hyperspectral Image Based on Graph Convolutional Broad Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2995–3005. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the ICML 2013 Workshop: Challenges in Representation Learning (WREPL), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Dong, A.; Chung, F.l.; Wang, S. Semi-supervised classification method through oversampling and common hidden space. Inf. Sci. 2016, 349–350, 216–228. [Google Scholar] [CrossRef]
- Fu, J.; Lee, S. Certainty-based active learning for sampling imbalanced datasets. Neurocomputing 2013, 119, 350–358. [Google Scholar] [CrossRef]
- Oh, S.H. Error back-propagation algorithm for classification of imbalanced data. Neurocomputing 2011, 74, 1058–1061. [Google Scholar] [CrossRef]
- Yi, C.; Lifu, Z.; Yueming, W.; Wenchao, Q.; Senlin, T.; Peng, Z. Aerial hyperspectral remote sensing classification dataset of Xiongan New Area (Matiwan Village). J. Remote Sens. 2020, 24, 1299–1306. [Google Scholar] [CrossRef]
- Tai, X.; Li, R.; Zhang, B.; Yu, H.; Kong, X.; Bai, Z.; Deng, Y.; Jia, L.; Jin, D. Pollution Gradients Altered the Bacterial Community Composition and Stochastic Process of Rural Polluted Ponds. Microorganisms 2020, 8, 311. [Google Scholar] [CrossRef] [Green Version]
- Jia, J.; Zheng, X.; Guo, S.; Wang, Y.; Chen, J. Removing Stripe Noise Based on Improved Statistics for Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Jia, J.; Wang, Y.; Chen, J.; Guo, R.; Shu, R.; Wang, J. Status and Application of Advanced Airborne Hyperspectral Imaging Technology: A Review. Infrared Phys. Technol. 2020, 104, 103115. [Google Scholar] [CrossRef]
- Jia, J.; Wang, Y.; Cheng, X.; Yuan, L.; Zhao, D.; Ye, Q.; Zhuang, X.; Shu, R.; Wang, J. Destriping Algorithms Based on Statistics and Spatial Filtering for Visible-to-Thermal Infrared Pushbroom Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4077–4091. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of classification algorithms and training sample sizes in urban land classification with landsat thematic mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Jia, J.; Guo, S.; Chen, J.; Sun, L.; Xiong, Y.; Xu, W. Full Parameter Time Complexity (FPTC): A Method to Evaluate the Running Time of Machine Learning Classifiers for Land Use/Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2222–2235. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman and Hall/CRC: Boca Raton, FL, USA, 1984. [Google Scholar] [CrossRef]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Ross, Q.J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Alnabati, E.; Aderinwale, T.W.; Maddhuri Venkata Subramaniya, S.R.; Terashi, G.; Kihara, D. Detecting protein and DNA/RNA structures in cryo-EM maps of intermediate resolution using deep learning. Nat. Commun. 2021, 12, 2302. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO. | Common Name/Latin Name | T1 | T2 | T3 | TEST |
|---|---|---|---|---|---|
| 1 | Box elder/ | 1200 | 2000 | 2800 | 800 |
| 2 | Willow/ | 2800 | 1600 | 2000 | 800 |
| 3 | Paddy/ | 200 | 2400 | 2600 | 800 |
| 4 | Chinese scholar tree/ | 2400 | 2800 | 1800 | 800 |
| 5 | Ash/ | 2800 | 1600 | 2600 | 800 |
| 6 | Water | 200 | 1200 | 2000 | 800 |
| 7 | Post-harvest field | 1200 | 2000 | 2200 | 800 |
| 8 | Corn/ | 1600 | 800 | 2400 | 800 |
| 9 | Pear/ | 2400 | 2800 | 1800 | 800 |
| 10 | White poplar/ | 800 | 1200 | 2400 | 800 |
| 11 | Weeds | 1600 | 2400 | 2800 | 800 |
| 12 | Peach/ | 1800 | 800 | 1800 | 800 |
| R (Max/Min) | 14.0 | 3.5 | 1.6 | 1.0 | |
| CLA. | Unbalanced | NearMiss | RUS | SMOTE | NearPseudo |
|---|---|---|---|---|---|
| 1 | 66.3 ± 0.3 | 20.6 ± 0.4 | 58.4 ± 0.5 | 66.7 ± 0.4 | 68.9 ± 0.3 |
| 2 | 68.0 ± 0.4 | 18.6 ± 0.4 | 57.2 ± 0.4 | 68.7 ± 0.3 | 71.4 ± 0.5 |
| 3 | 92.0 ± 0.2 | 50.5 ± 0.4 | 91.1 ± 0.2 | 92.8 ± 0.3 | 94.0 ± 0.2 |
| 4 | 59.2 ± 0.4 | 11.3 ± 0.7 | 44.2 ± 1.0 | 60.0 ± 0.6 | 62.7 ± 0.4 |
| 5 | 74.9 ± 0.5 | 21.6 ± 1.4 | 66.1 ± 0.4 | 75.0 ± 0.7 | 78.0 ± 0.2 |
| 6 | 89.3 ± 0.1 | 89.3 ± 0.1 | 92.7 ± 0.2 | 90.4 ± 0.2 | 92.4 ± 0.1 |
| 7 | 92.4 ± 0.1 | 28.6 ± 0.3 | 90.8 ± 0.3 | 92.1 ± 0.1 | 92.4 ± 0.1 |
| 8 | 74.3 ± 0.3 | 29.6 ± 0.6 | 64.2 ± 0.5 | 73.5 ± 0.6 | 73.4 ± 0.3 |
| 9 | 52.7 ± 0.3 | 9.3 ± 0.5 | 44.0 ± 0.5 | 53.2 ± 0.3 | 53.6 ± 0.5 |
| 10 | 54.8 ± 0.4 | 24.7 ± 0.1 | 53.9 ± 0.9 | 55.4 ± 0.4 | 68.0 ± 0.7 |
| 11 | 68.6 ± 0.1 | 20.9 ± 1.5 | 61.4 ± 0.6 | 68.9 ± 0.5 | 68.2 ± 0.2 |
| 12 | 74.8 ± 0.4 | 30.3 ± 0.2 | 63.2 ± 0.7 | 75.3 ± 0.3 | 75.2 ± 0.5 |
| AF | 72.3 ± 0.3 | 29.6 ± 0.6 | 65.6 ± 0.5 | 72.7 ± 0.4 | 74.8 ± 0.3 |
| OA | 72.3 ± 0.1 | 32.9 ± 0.2 | 65.8 ± 0.1 | 72.7 ± 0.2 | 74.8 ± 0.1 |
| CLA. | Unbalanced | NearMiss | RUS | SMOTE | NearPseudo |
|---|---|---|---|---|---|
| 1 | 69.8 ± 0.6 | 53.5 ± 0.3 | 66.1 ± 0.5 | 69.7 ± 0.5 | 70.1 ± 0.6 |
| 2 | 69.1 ± 0.5 | 55.4 ± 0.7 | 65.6 ± 0.4 | 67.7 ± 0.4 | 69.7 ± 0.7 |
| 3 | 94.6 ± 0.1 | 79.8 ± 0.8 | 92.9 ± 0.2 | 94.4 ± 0.2 | 95.3 ± 0.2 |
| 4 | 60.8 ± 0.5 | 43.0 ± 0.4 | 56.7 ± 0.8 | 60.7 ± 0.6 | 62.9 ± 0.5 |
| 5 | 73.2 ± 0.4 | 65.6 ± 0.4 | 72.7 ± 0.5 | 72.6 ± 0.7 | 75.3 ± 0.4 |
| 6 | 94.8 ± 0.2 | 89.5 ± 0.3 | 94.9 ± 0.1 | 94.7 ± 0.1 | 95.7 ± 0.2 |
| 7 | 92.9 ± 0.1 | 74.3 ± 0.8 | 93.1 ± 0.2 | 92.9 ± 0.2 | 93.7 ± 0.2 |
| 8 | 71.5 ± 0.3 | 49.9 ± 0.4 | 72.5 ± 0.4 | 71.2 ± 0.3 | 73.9 ± 0.3 |
| 9 | 53.7 ± 0.3 | 37.3 ± 0.6 | 49.7 ± 0.5 | 54.5 ± 0.5 | 53.6 ± 0.5 |
| 10 | 67.0 ± 0.4 | 58.0 ± 0.3 | 67.1 ± 0.6 | 65.7 ± 0.3 | 69.5 ± 0.5 |
| 11 | 70.3 ± 0.2 | 59.0 ± 0.5 | 68.7 ± 0.5 | 69.8 ± 0.4 | 70.0 ± 0.2 |
| 12 | 63.5 ± 0.4 | 65.5 ± 0.5 | 73.0 ± 0.3 | 64.3 ± 0.9 | 70.4 ± 0.7 |
| AF | 73.4 ± 0.3 | 60.9 ± 0.5 | 72.8 ± 0.4 | 73.2 ± 0.4 | 75.0 ± 0.4 |
| OA | 73.3 ± 0.1 | 60.9 ± 0.1 | 72.9 ± 0.2 | 73.1 ± 0.2 | 75.1 ± 0.1 |
| CLA. | Unbalanced | NearMiss | RUS | SMOTE | NearPseudo |
|---|---|---|---|---|---|
| 1 | 70.0 ± 0.3 | 63.2 ± 0.5 | 70.0 ± 0.4 | 69.8 ± 0.1 | 71.4 ± 0.4 |
| 2 | 72.3 ± 0.5 | 69.5 ± 0.4 | 72.0 ± 0.4 | 71.9 ± 0.4 | 72.2 ± 0.5 |
| 3 | 95.2 ± 0.2 | 92.0 ± 0.3 | 95.3 ± 0.2 | 95.3 ± 0.1 | 95.5 ± 0.3 |
| 4 | 60.1 ± 0.6 | 58.4 ± 0.4 | 61.6 ± 0.6 | 60.3 ± 0.3 | 62.0 ± 0.3 |
| 5 | 76.8 ± 0.4 | 72.7 ± 0.4 | 77.7 ± 0.5 | 76.7 ± 0.4 | 77.5 ± 0.3 |
| 6 | 95.7 ± 0.2 | 93.9 ± 0.2 | 95.7 ± 0.2 | 95.1 ± 0.1 | 95.7 ± 0.2 |
| 7 | 93.9 ± 0.1 | 90.5 ± 0.3 | 93.4 ± 0.1 | 93.8 ± 0.2 | 94.0 ± 0.2 |
| 8 | 77.2 ± 0.5 | 73.1 ± 0.6 | 76.5 ± 0.4 | 77.0 ± 0.3 | 77.0 ± 0.4 |
| 9 | 52.7 ± 1.1 | 50.5 ± 0.6 | 54.1 ± 0.5 | 52.6 ± 1.0 | 53.4 ± 0.7 |
| 10 | 71.9 ± 0.3 | 66.7 ± 0.4 | 71.6 ± 0.4 | 71.8 ± 0.5 | 71.8 ± 0.6 |
| 11 | 69.4 ± 0.2 | 64.1 ± 0.2 | 69.3 ± 0.3 | 69.1 ± 0.6 | 70.5 ± 0.3 |
| 12 | 74.5 ± 0.3 | 74.8 ± 0.2 | 75.8 ± 0.6 | 74.7 ± 0.6 | 74.8 ± 0.4 |
| AF | 75.8 ± 0.4 | 72.5 ± 0.4 | 76.1 ± 0.4 | 75.7 ± 0.4 | 76.3 ± 0.4 |
| OA | 76.1 ± 0.1 | 72.5 ± 0.1 | 76.2 ± 0.2 | 76.0 ± 0.2 | 76.5 ± 0.1 |
| CLA. | Unbalanced | NearPseudo | ||||||
|---|---|---|---|---|---|---|---|---|
| CART | kNN | LR | RF | CART | kNN | LR | RF | |
| 1 | 45.0% | 62.0% | 52.5% | 69.8% | 48.7% | 64.2% | 54.3% | 70.1% |
| 2 | 45.4% | 60.5% | 63.4% | 69.1% | 49.2% | 62.7% | 64.9% | 69.7% |
| 3 | 90.9% | 93.0% | 95.2% | 94.6% | 89.9% | 93.4% | 95.4% | 95.3% |
| 4 | 39.3% | 50.1% | 49.9% | 60.8% | 41.0% | 52.3% | 48.2% | 62.9% |
| 5 | 54.2% | 66.2% | 67.7% | 73.2% | 59.7% | 68.6% | 71.0% | 75.3% |
| 6 | 90.2% | 92.3% | 93.0% | 94.8% | 91.0% | 93.7% | 93.2% | 95.7% |
| 7 | 88.6% | 91.1% | 91.0% | 92.9% | 89.9% | 92.0% | 92.5% | 93.7% |
| 8 | 47.0% | 54.6% | 45.7% | 71.5% | 58.9% | 65.6% | 65.7% | 73.9% |
| 9 | 39.9% | 46.7% | 43.9% | 53.7% | 37.6% | 46.9% | 50.4% | 53.6% |
| 10 | 44.4% | 55.8% | 68.2% | 67.0% | 52.0% | 64.3% | 68.5% | 69.5% |
| 11 | 55.5% | 60.9% | 56.6% | 70.3% | 56.8% | 64.4% | 59.4% | 70.0% |
| 12 | 46.4% | 57.9% | 8.0% | 63.5% | 57.5% | 68.5% | 66.6% | 70.4% |
| AF | 57.2% | 65.9% | 61.3% | 73.4% | 61.0% | 69.7% | 69.2% | 75.0% |
| OA | 57.0% | 65.8% | 63.1% | 73.3% | 60.7% | 69.8% | 69.5% | 75.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Jia, J.; Chen, J.; Guo, S.; Sun, L.; Zhou, C.; Wang, Y. Hyperspectral Image Classification with Imbalanced Data Based on Semi-Supervised Learning. Appl. Sci. 2022, 12, 3943. https://doi.org/10.3390/app12083943
Zheng X, Jia J, Chen J, Guo S, Sun L, Zhou C, Wang Y. Hyperspectral Image Classification with Imbalanced Data Based on Semi-Supervised Learning. Applied Sciences. 2022; 12(8):3943. https://doi.org/10.3390/app12083943
Chicago/Turabian StyleZheng, Xiaorou, Jianxin Jia, Jinsong Chen, Shanxin Guo, Luyi Sun, Chan Zhou, and Yawei Wang. 2022. "Hyperspectral Image Classification with Imbalanced Data Based on Semi-Supervised Learning" Applied Sciences 12, no. 8: 3943. https://doi.org/10.3390/app12083943
APA StyleZheng, X., Jia, J., Chen, J., Guo, S., Sun, L., Zhou, C., & Wang, Y. (2022). Hyperspectral Image Classification with Imbalanced Data Based on Semi-Supervised Learning. Applied Sciences, 12(8), 3943. https://doi.org/10.3390/app12083943