
A Knowledge Sharing and Individually Guided Evolutionary Algorithm for Multi-Task Optimization Problems




Abstract
:1. Introduction
- (1)
- We propose a novel MTO framework including the partial population information sharing and individual learning schemes to achieve higher search efficiency than existing frameworks.
- (2)
- In order to represent the interests of each individual for solving different tasks, we introduce a new concept of skill membership into the MTO framework.
- (3)
- We divide an MTO search process into vertical and horizontal evolutions, and the latter includes crossovers of individuals belonging to different tasks. Knowledge transfer is guided according to the task performance to suppress the negative transfer of each optimization task.
2. Related Work
3. Proposed Method
3.1. Motivations
3.2. Proposed Framework
- (1)
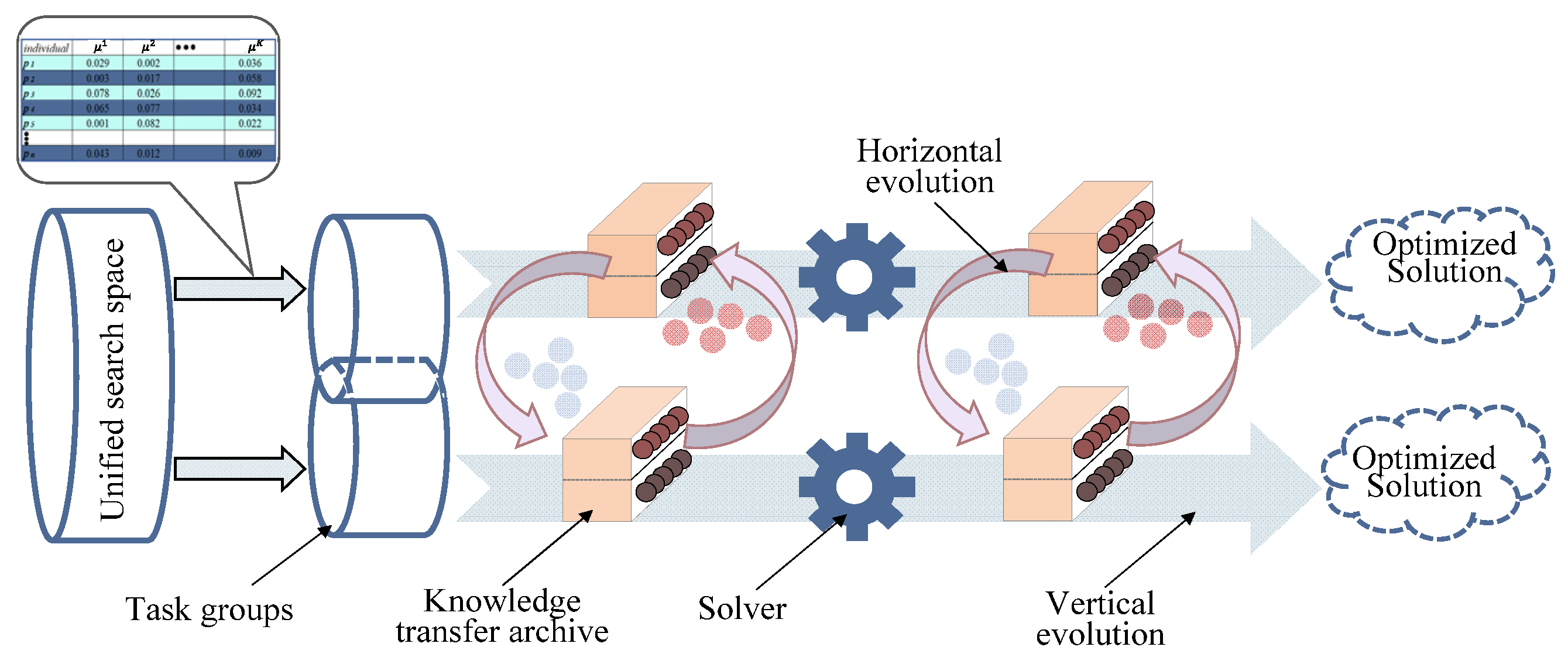
- We divide the optimization process of MTO into vertical and horizontal evolutions. Each task has its sub-population to execute vertical evolution, and each sub-population can be called a task groups. Traditional single-task optimization methods just contain vertical evolutions that find global optimal solutions by a series of operations, e.g., selection, crossover, and mutation. The distinction between the proposed MTO framework and traditional single-task optimizers lies in horizontal evolution among different task groups. Optimization processes of multiple tasks can be influenced by each other via the information interaction.
- (2)
- MTO algorithms are able to perform K optimization problems simultaneously. Suppose that the dimensionality of the jth task is Dj. We define the unified search space with dimensionality D = maxj{Dj} and each individual is encoded with random variables lying within the fixed range [0, 1].
- (3)
- IMTO divides the initial population into K task groups, and each task group can evolve independently. In order to represent the ability to perform each component task, we introduce the concept of skill membership. A candidate may enter multiple task groups as long as it shows high skill membership values on component tasks.
- (4)
- In order to confirm when the optimization information should communicate, we use the convergence rate to guide knowledge transfer. When the convergence rate shows that a task may be trapped into local optima, the knowledge transfer mechanism is triggered.
3.3. Individually Guided Multi-Task Evolutionary Optimization
| Algorithm 1. IMGA |
 |
| Algorithm 2. Horizontal Transfer |
 |
3.4. Computational Complexity
4. Experiments
- (1)
- IMTO can significantly outperform corresponding baseline solvers.
- (2)
- In terms of the optimization knowledge transfer, IMTO outperforms the multifactorial optimization framework.
- (3)
- IMTO can adapt to different task similarities and promise high transfer effectiveness.
4.1. Experimental Setup
4.2. Parametric Analysis
- (1)
- Sensitivity of Ω: Communication rate Ω is used to control knowledge transfer among different tasks. We examine performance sensitivity with respect to this parameter for IMDE. We set it to 0.2, 0.4, 0.6, 0.8, and 1. Table 2 shows the best achieved fitness values in 20 runs versus Ω in IMDE on test suite 1, and the best one is shown in bold. It is clear that IMDE performs well with Ω from 0.2 to 1 with a small difference. Nevertheless, the larger Ω can encourage more individuals to learn from other tasks, thereby consuming more computing resources. To reduce running time on various problems, we employ a relatively small Ω in our algorithms.
- (2)
- Sensitivity of γ: Randomly chosen ratio γ is another control parameter utilized in IMTO. To discuss performance sensitivity to γ in IMTO, we test its different settings on test suite 1. Table 3 shows the best achieved fitness values in 20 runs versus γ in IMDE on test suite 1, and the best one is shown in bold. IMDE is easily trapped into local optima when only choosing better-performing individuals. However, adding some randomly selected individuals can have better convergence performance. It is clear that IMDE performs best when γ is set to 0.2. We thus set γ to 0.2 in our experiments.
4.3. Comparison with MFO
4.4. Comparison with Baseline Solvers
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hua, Y.; Liu, Q.; Hao, K.; Jin, Y. A survey of evolutionary algorithms for multi-objective optimization problems with irregular pareto fronts. IEEE/CAA J. Autom. Sin. 2021, 8, 303–318. [Google Scholar] [CrossRef]
- Tian, Y.; Li, X.; Ma, H.; Zhang, X.; Tan, K.C.; Jin, Y. Deep reinforcement learning based adaptive operator selection for evolutionary multi-objective optimization. IEEE Trans. Emerg. Topics Comput. Intell. 2022, 1–14. [Google Scholar] [CrossRef]
- Deng, Q.; Kang, Q.; Zhang, L.; Zhou, M.; An, J. Objective space-based population generation to accelerate evolutionary algorithms for large-scale many-objective optimization. IEEE Trans. Evol. Comput. 2022. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Yang, S.; Branke, J. Evolutionary dynamic optimization: A survey of the state of the art. Swarm Evol. Comput. 2012, 6, 1–24. [Google Scholar] [CrossRef]
- Wang, B.-C.; Li, H.-X.; Li, J.; Wang, Y. Composite differential evolution for constrained evolutionary optimization. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1482–1495. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, K.; Xu, L.; Sheng, W.; Kang, Q. Evolving ensembles using multi-objective genetic programming for imbalanced classification. Knowl.-Based Syst. 2022, 255, 109611. [Google Scholar] [CrossRef]
- Sun, Y.; Yen, G.G.; Yi, Z. IGD Indicator-based Evolutionary Algorithm for Many-objective Optimization Problems. IEEE Trans. Evol. Comput. 2019, 23, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Xu, H.; Zeng, W.; Zeng, X.; Yen, G.G. An evolutionary algorithm based on minkowski distance for many-objective optimization. IEEE Trans. Cybern. 2019, 49, 3968–3979. [Google Scholar] [CrossRef]
- Hong, W.; Tang, K.; Zhou, A.; Ishibuchi, H.; Yao, X. A scalable indicator-based evolutionary algorithm for large-scale multiobjective optimization. IEEE Trans. Evol. Comput. 2019, 23, 525–537. [Google Scholar] [CrossRef]
- Chen, S.-Y.; Song, M.H. Energy-saving dynamic bias current control of active magnetic bearing positioning system using adaptive differential evolution. IEEE Trans. Syst. Man, Cybern. Syst. 2019, 49, 942–953. [Google Scholar] [CrossRef]
- Wang, X.; Choi, T.-M.; Liu, H.; Yue, X. A novel hybrid ant colony optimization algorithm for emergency transportation problems during post-disaster scenarios. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 545–556. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Y.; Wang, Y.; Zhang, J.; Chen, C.L.P.; Zheng, Z. Multiobjective vehicle routing problems with simultaneous delivery and pickup and time windows: Formulation, instances, and algorithms. IEEE Trans. Cybern. 2016, 46, 582–594. [Google Scholar] [CrossRef] [PubMed]
- Pan, Z.; Wang, L.; Wang, J.; Lu, J. Deep reinforcement learning based optimization algorithm for permutation flow-shop scheduling. IEEE Trans. Emerg. Topics Comput. Intell. 2021, 1–12. [Google Scholar] [CrossRef]
- Kang, Q.; Song, X.; Zhou, M. A collaborative resource allocation strategy for decomposition-based multiobjective evolutionary algorithms. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 2416–2423. [Google Scholar] [CrossRef]
- Fu, Y.; Ding, M.; Zhou, C.; Hu, H. Route planning for unmanned aerial vehicle (UAV) on the sea using hybrid differential evolution and quantum-behaved particle swarm optimization. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 1451–1465. [Google Scholar] [CrossRef]
- Lin, Q.; Fang, Z.; Chen, Y.; Tan, K.C.; Li, Y. Evolutionary architectural search for generative adversarial networks. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 783–794. [Google Scholar] [CrossRef]
- Chen, Y.; Zhong, J.; Feng, L.; Zhng, J. An adaptive archive-based evolutionary framework for many-task optimization. IEEE Trans. Emerg. Topics Comput. Intell. 2020, 4, 369–384. [Google Scholar] [CrossRef]
- Yao, S.; Kang, Q.; Zhou, M.; Rawa, M.; Albeshri, A. Discriminative manifold distribution alignment for domain adaptation. IEEE Trans. Syst. Man, Cybern. Syst. 2022. [Google Scholar] [CrossRef]
- Kang, Q.; Yao, S.; Zhou, M.; Zhang, K.; Abusorrah, A. Effective visual domain adaptation via generative adversarial distribution matching. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3919–3929. [Google Scholar] [CrossRef]
- Yao, S.; Kang, Q.; Zhou, M.; Rawa, M.; Abusorrah, A. A survey of transfer learning for machinery diagnostics and prognostics. Artif. Intell. Rev. 2022, 1–52. [Google Scholar] [CrossRef]
- Gupta, A.; Ong, Y.-S.; Feng, L. Multifactorial evolution: Toward evolutionary multitasking. IEEE Trans. Evol. Comput. 2016, 20, 343–357. [Google Scholar] [CrossRef]
- Wang, X.; Kang, Q.; Zhou, M.; Yao, S.; Abusorrah, A. Domain adaptation multitask optimization. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Qin, A.K.; Gong, M.; Zhou, D. Self-regulated evolutionary multitask optimization. IEEE Trans. Evol. Comput. 2020, 24, 16–28. [Google Scholar] [CrossRef]
- Huang, S.; Zhong, J.; Yu, W. Surrogate-assisted evolutionary framework with adaptive knowledge transfer for multi-task optimization. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1930–1944. [Google Scholar] [CrossRef]
- Dang, Q.; Gao, W.; Gong, M. An efficient mixture sampling model for gaussian estimation of distribution algorithm. Inf. Sci. 2022, 608, 1157–1182. [Google Scholar] [CrossRef]
- Gupta, A.; Ong, Y.-S.; Feng, L. Insights on transfer optimization: Because experience is the best teacher. IEEE Trans. Emerg. Topics. Comput. Intell. 2018, 2, 51–64. [Google Scholar] [CrossRef]
- Zhou, L.; Feng, L.; Tan, K.C.; Zhong, J.; Zhu, Z.; Liu, K.; Chen, C. Toward adaptive knowledge transfer in multifactorial evolutionary computation. IEEE Trans. Cybern. 2021, 51, 2563–2576. [Google Scholar] [CrossRef]
- Ding, J.; Yang, C.; Jin, Y.; Chai, T. Generalized multitasking for evolutionary optimization of expensive problems. IEEE Trans. Evol. Comput. 2019, 23, 44–58. [Google Scholar] [CrossRef]
- Feng, L.; Zhou, W.; Zhou, L.; Jiang, S.W.; Zhong, J.H.; Da, B.S.; Zhu, Z.X.; Wang, Y. Evolutionary multitasking via explicit autoencoding. IEEE Trans. Cybern. 2019, 49, 3457–3470. [Google Scholar] [CrossRef]
- Gupta, A.; Ong, Y.-S.; Feng, L.; Tan, K.C. Multiobjective multifactorial optimization in evolutionary multitasking. IEEE Trans. Cybern. 2017, 47, 1652–1665. [Google Scholar] [CrossRef]
- Dang, Q.; Gao, W.; Gong, M. Multiobjective multitasking optimization assisted by multidirectional prediction method. Complex Intell. Syst. 2022, 8, 1663–1679. [Google Scholar] [CrossRef]
- Dang, Q.; Gao, W.; Gong, M. Dual transfer learning with generative filtering model for multiobjective multitasking optimization. Memetic Comput. 2022, 1–27. [Google Scholar] [CrossRef]
- Feng, L.; Zhou, W.; Zhou, L.; Jiang, S.W.; Zhong, J.H.; Da, B.S.; Zhu, Z.X.; Wang, Y. An empirical study of multifactorial PSO and multifactorial DE. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 921–928. [Google Scholar]
- Bali, K.K.; Ong, Y.S.; Gupta, A.; Tan, P.S. Multifactorial evolutionary algorithm with online transfer parameter estimation: MFEA-II. IEEE Trans. Evol. Comput. 2020, 24, 69–83. [Google Scholar] [CrossRef]
- Bali, K.K.; Gupta, A.; Ong, Y.-S.; Tan, P.S. Cognizant multitasking in multiobjective multifactorial evolution: MO-MFEA-II. IEEE Trans. Cybern. 2021, 51, 1784–1796. [Google Scholar] [CrossRef]
- Liu, D.; Huang, S.; Zhong, J. Surrogate-assisted multi-tasking memetic algorithm. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Bali, K.K.; Gupta, A.; Feng, L.; Ong, Y.S.; Siew, T.P. Linearized domain adaptation in evolutionary multitasking. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 1295–1302. [Google Scholar]
- Tang, J.; Chen, Y.; Deng, Z.; Xiang, Y.; Joy, C.P. A group-based approach to improve multifactorial evolutionary algorithm. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3870–3876. [Google Scholar]
- Zhang, J.; Zhou, W.; Chen, X.; Yao, W.; Cao, L. Multisource Selective Transfer Framework in Multiobjective Optimization Problems. IEEE Trans. Evol. Comput. 2020, 24, 424–438. [Google Scholar]
- Martinez, A.D.; Osaba, E.; Ser, J.D.; Herrera, F. Simultaneously evolving deep reinforcement learning models using multifactorial optimization. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Feng, L.; Huang, Y.; Zhou, L.; Zhong, J.; Gupta, A.; Tang, K.; Tan, K.C. Explicit evolutionary multitasking for combinatorial optimization: A case study on capacitated vehicle Routing Problem. IEEE Trans. Cybern. 2021, 51, 3143–3156. [Google Scholar] [CrossRef]
- Li, G.; Zhang, Q.; Gao, W. Multipopulation evolution framework for multifactorial optimization. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Kyoto, Japan, 6 July 2018; pp. 215–216. [Google Scholar]
- Cheng, M.-Y.; Gupta, A.; Ong, Y.-S.; Ni, Z.-W. Coevolutionary multitasking for concurrent global optimization: With case studies in complex engineering design. Eng. Appl. Artif. Intell. 2017, 64, 13–24. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Ghahramani, M.; Qiao, Y.; Zhou, M.; O’Hagan, A.; Sweeney, J. AI-based modeling and data-driven evaluation for smart manufacturing processes. IEEE/CAA J. Autom. Sin. 2020, 7, 1026–1037. [Google Scholar] [CrossRef]
- Wang, Y.; Zuo, X. An Effective Cloud Workflow Scheduling Approach Combining PSO and Idle Time Slot-Aware Rules. IEEE/CAA J. Autom. Sin. 2021, 8, 1079–1094. [Google Scholar] [CrossRef]
- Cao, Y.; Zhang, H.; Li, W.; Zhou, M.; Zhang, Y.; Chaovalitwongse, W.A. Comprehensive learning particle swarm optimization algorithm with local search for multimodal functions. IEEE Trans. Evol. Computat. 2019, 23, 718–731. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential evolution: A survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2011, 15, 4–31. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, X. Antenna array design by artificial bee colony algorithm with similarity induced search method. IEEE Trans. Magn. 2019, 55, 1–4. [Google Scholar] [CrossRef]
- Da, B.; Ong, Y.; Feng, L.; Qin, A.K.; Gupta, A.; Zhu, Z.; Ting, C.; Tang, K.; Yao, X. Evolutionary Multitasking for Single-Objective Continuous Optimization: Benchmark Problems, Performance Metric, and Baseline Results. 2017. Available online: https://arxiv.org/abs/1706.03470 (accessed on 27 December 2022).
- Gao, K.; Zhang, Y.; Su, R.; Yang, F.; Suganthan, P.N.; Zhou, M. Solving traffic signal scheduling problems in heterogeneous traffic network by using meta-heuristics. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3272–3282. [Google Scholar] [CrossRef]
- Fu, Y.; Zhou, M.; Guo, X.; Qi, L. Scheduling dual-objective stochastic hybrid flow shop with deteriorating jobs via bi-population evolutionary algorithm. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 5037–5048. [Google Scholar] [CrossRef]
- Guo, X.W.; Zhou, M.C.; Liu, S.X.; Qi, L. Lexicographic multiobjective scatter search for the optimization of sequence-dependent selective disassembly subject to multiresource constraints. IEEE Trans. Cybern. 2020, 50, 3307–3317. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Gravina, R.; Li, Y.; Alsamhi, S.; Sun, F.; Fortino, G. Multi-user activity recognition: Challenges and opportunities. Inf. Fusion 2020, 63, 121–135. [Google Scholar] [CrossRef]
- Li, W.; He, L.; Cao, Y. Many-objective evolutionary algorithm with reference point-based fuzzy correlation entropy for energy-efficient job shop scheduling with limited workers. IEEE Trans. Cybern. 2022, 52, 10721–10734. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, S.; Zhou, M.; Yu, Y. A multi-layered gravitational search algorithm for function optimization and real-world problems. IEEE/CAA J. Autom. Sin. 2021, 8, 94–109. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, L.; Zhang, L.; Wu, D. A survey on negative transfer. IEEE/CAA J. Autom. Sin. 2022, 8, 94–109. [Google Scholar] [CrossRef]
- Huang, Z.; Yang, S.; Zhou, M.; Li, Z.; Gong, Z.; Chen, Y. Feature Map Distillation of Thin Nets for Low-Resolution Object Recognition. IEEE Trans. on Image Process. 2022, 31, 1364–1379. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task Set | Category | Task Component | Dimensionality | Search Space | Inter-Task Similarity |
|---|---|---|---|---|---|
| P1 | CI+HS | Griewank (T1) Rastrigin (T2) | 50 50 | [−100, 100] [−50, 50] | 1.00 |
| P2 | CI+MS | Ackley (T1) Rastrigin (T2) | 50 50 | [−50, 50] [−50, 50] | 0.22 |
| P3 | CI+LS | Ackley (T1) Schwefel (T2) | 50 50 | [−50, 50] [−500, 500] | 0.00 |
| P4 | PI+HS | Rastrigin (T1) Sphere (T2) | 50 50 | [−50, 50] [−100, 100] | 0.86 |
| P5 | PI+MS | Ackey (T1) Rosenbrock (T2) | 50 50 | [−50, 50] [−50, 50] | 0.21 |
| P6 | PI+LS | Ackey (T1) Weierstrass (T2) | 50 25 | [−50, 50] [−0.5, 0.5] | 0.07 |
| P7 | NI+HS | Rosenbrock (T1) Rastrigin (T2) | 50 50 | [−50, 50] [−50, 50] | 0.94 |
| P8 | NI+MS | Griewank (T1) Weierstrass (T2) | 50 50 | [−100, 100] [−0.5, 0.5] | 0.36 |
| P9 | NI+LS | Rastrigin (T1) Schwefel (T2) | 50 50 | [−50, 50] [−500, 500] | 0.00 |
| Task Set | IMDE (Ω = 0.2) | IMDE (Ω = 0.4) | IMDE (Ω = 0.6) | IMDE (Ω = 0.8) | IMDE (Ω = 1) | |
|---|---|---|---|---|---|---|
| P1 | T1 T2 | 1.20 × 10−4 (3.63 × 10−4) 5.03 × 101 (1.30 × 101) |
2.02 × 10−3 (3.43 × 10−3) 4.32 × 101 (7.83 × 100) |
1.92 × 10−3 (3.95 × 10−3) 3.22 × 101 (1.10 × 101) |
6.99 × 10−4 (2.69 × 10−3) 3.48 × 101 (9.85 × 100) |
4.44 × 10−4 (1.62 × 10−3) 2.84 × 101 (6.67 × 100) |
| P2 | T1 T2 |
4.74 × 10−3 (9.54 × 10−3) 4.43 × 101 (1.15 × 101) |
8.84 × 10−2 (2.64 × 10−1) 3.98 × 101 (1.13 × 101) |
1.11 × 10−1 (3.27 × 10−1) 3.78 × 101 (1.46 × 101) | 9.05 × 10−4 (3.38 × 10−3) 3.04 × 101 (7.59 × 100) |
1.02 × 10−2 (3.95 × 10−2) 2.88 × 101 (9.50 × 100) |
| P4 | T1 T2 |
8.10 × 101 (9.75 × 100) 2.44 × 10−6 (7.82 × 10−6) |
7.29 × 101 (2.27 × 101) 8.06 × 10−4 (2.91 × 10−3) |
7.46 × 101 (1.22 × 101) 4.97 × 10−5 (2.15 × 10−4) |
7.40 × 101 (1.45 × 101) 1.46 × 10−6 (4.66 × 10−6) | 6.77 × 101 (1.66 × 101) 1.23 × 10−4 (5.35 × 10−4) |
| P5 | T1 T2 | 6.74 × 10−5 (9.91 × 10−5) 6.48 × 101 (2.97 × 101) |
7.29 × 10−5 (5.01 × 10−5) 9.82 × 101 (3.15 × 101) |
3.14 × 10−4 (5.71 × 10−4) 7.82 × 101 (2.97 × 101) |
1.32 × 10−4 (2.92 × 10−4) 6.96 × 101 (2.81 × 101) |
9.48 × 10−5 (1.79 × 10−4) 7.33 × 101 (3.08 × 101) |
| P7 | T1 T2 |
9.25 × 101 (2.75 × 101) 5.14 × 101 (1.22 × 101) |
8.83 × 101 (4.47 × 101) 4.72 × 101 (1.28 × 101) |
7.78 × 101 (6.08 × 101) 4.10 × 101 (1.22 × 101) | 6.86 × 101 (3.42 × 101) 3.53 × 101 (9.74 × 100) |
8.29 × 101 (4.78 × 101) 3.74 × 101 (9.87 × 100) |
| P8 | T1 T2 | 1.41 × 10−3 (3.33 × 10−3) 5.93 × 100 (2.04 × 100) |
3.39 × 10−3 (7.11 × 10−3) 3.84 × 100 (1.34 × 100) |
1.49 × 10−3 (3.51 × 10−3) 4.41 × 100 (1.28 × 100) |
2.03 × 10−3 (5.95 × 10−3) 4.20 × 100 (1.30 × 100) |
1.62 × 10−3 (3.84 × 10−3) 3.55 × 100 (2.07 × 100) |
| Task Set | IMDE (γ = 0) | IMDE (γ = 0.2) | IMDE (γ = 0.4) | IMDE (γ = 0.6) | IMDE (γ = 0.8) | IMDE (γ = 1.0) | |
|---|---|---|---|---|---|---|---|
| P1 | T1 T2 |
2.12 × 10−3 (4.22 × 10−3) 5.55 × 101 (1.67 × 101) | 1.202 × 10−4 (3.632 × 10−4) 5.032 × 101 (1.302 × 101) |
1.46 × 10−3 (4.21 × 10−3) 4.95 × 101 (1.23 × 101) |
1.51 × 10−3 (2.95 × 10−3) 4.79 × 101 (1.39 × 101) |
1.38 × 10−3 (3.36 × 10−3) 5.08 × 101 (1.34 × 101) |
1.65 × 10−3 (3.22 × 10−3) 5.72 × 101 (1.41 × 101) |
| P2 | T1 T2 |
4.41 × 10−2 (1.92 × 10−1) 4.72 × 101 (1.47 × 101) |
4.742 × 10−3 (9.542 × 10−3) 4.432 × 101 (1.152 × 101) | 1.33 × 10−4 (1.86 × 10−4) 4.80 × 101 (1.48 × 101) |
1.79 × 10−3 (3.96 × 10−3) 5.24 × 101 (1.82 × 101) |
1.48 × 10−1 (3.50 × 10−1) 5.11 × 101 (1.52 × 101) |
1.44 × 10−1 (4.41 × 10−1) 4.95 × 101 (1.20 × 101) |
| P4 | T1 T2 |
8.57 × 101 (2.72 × 101) 1.70 × 10−1 (6.46 × 10−1) |
8.102 × 101 (9.752 × 10+00) 2.442 × 10−6 (7.822 × 10−6) |
8.06 × 101 (1.78 × 101) 1.96 × 10−4 (7.32 × 10−4) |
8.77 × 101 (2.75 × 101) 6.10 × 10−5 (2.57 × 10−4) |
7.98 × 101 (2.01 × 101) 6.76 × 10−5 (2.94 × 10−4) | 7.72 × 101 (2.35 × 101) 3.07 × 10−2 (9.20 × 10−2) |
| P5 | T1 T2 |
3.30 × 10−4 (6.71 × 10−4) 8.93 × 101 (2.67 × 101) | 6.742 × 10−5 (9.912 × 10−5) 6.482 × 101 (2.972 × 101) |
3.30 × 10−4 (8.34 × 10−4) 8.45 × 101 (2.96 × 101) |
1.89 × 10−4 (2.95 × 10−4) 9.97 × 101 (3.19 × 101) |
1.23 × 10−3 (4.55 × 10−3) 9.29 × 101 (2.75 × 101) |
5.44 × 10−4 (1.38 × 10−3) 9.07 × 101 (3.23 × 101) |
| P7 | T1 T2 |
9.93 × 101 (4.71 × 101) 5.82 × 101 (1.06 × 101) |
9.252 × 101 (2.752 × 101) 5.142 × 101 (1.222 × 101) |
1.01 × 102 (5.66 × 101) 5.76 × 101 (9.24 × 100) | 7.44 × 101 (2.56 × 101) 5.53 × 101 (1.41 × 101) |
8.83 × 101 (3.74 × 101) 5.37 × 101 (1.04 × 101) |
7.52 × 101 (4.35 × 101) 5.60 × 101 (1.02 × 101) |
| P8 | T1 T2 |
1.72 × 10−3 (3.97 × 10−3) 6.18 × 100 (2.55 × 100) | 1.412 × 10−3 (3.332 × 10−3) 5.932 × 100 (2.042 × 100) |
2.54 × 10−3 (6.20 × 10−3) 5.47 × 100 (2.95 × 100) |
1.63 × 10−3 (2.92 × 10−3) 6.18 × 100 (3.71 × 100) |
4.27 × 10−3 (6.69 × 10−3) 5.11 × 100 (2.06 × 100) |
3.24 × 10−3 (6.19 × 10−3) 5.15 × 100 (2.67 × 100) |
| Task Set | IMGA | MFEA | IMPSO | MFPSO | IMDE | MFDE | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GA-Based | PSO-Based | DE-Based | |||||||||||
| Fitness | Time | Fitness | Time | Fitness | Time | Fitness | Time | Fitness | Time | Fitness | Time | ||
| P1 | T1 T2 | 1.11 × 10−1 (5.27 × 10−2) 3.39 × 102 (4.72 × 101) | 4.02 |
3.35 × 10−1 + (4.88 × 10−2) 2.27 × 102 − (5.33 × 101) | 18.57 | 4.99 × 10−3 (6.57 × 10−3) 3.26 × 102 (6.26 × 101) | 3.49 |
5.20 × 10−1 + (1.42 × 10−1) 3.32 × 102 ≈ (2.54 × 101) | 21.79 | 1.20 × 10−4 (3.63 × 10−4) 5.03 × 101 (1.30 × 101) | 4.87 |
8.77 × 10−4 + (2.63 × 10−3) 3.69 × 100 − (1.14 × 101) | 20.29 |
| P2 | T1 T2 | 3.83 × 100 (8.78 × 10−1) 4.16 × 102 (3.65 × 101) | 4.24 |
8.00 × 100 + (6.38 × 10−1) 4.52 × 102 + (5.68 × 101) | 19.00 | 3.93 × 10−1 (4.54 × 10−1) 3.73 × 101 (1.20 × 101) | 3.43 |
5.32 × 100 + (6.68 × 10−1) 3.97 × 102 + (4.24 × 101) | 19.03 | 4.74 × 10−3 (9.54 × 10−3) 4.43 × 101 (1.15 × 101) | 5.47 |
1.08 × 10−1 + (3.28 × 10−1) 7.47 × 10−1 − (2.83 × 100) | 18.87 |
| P3 | T1 T2 | 2.08 × 101 (4.19 × 10−1) 1.30 × 104 (6.82 × 102) | 4.40 |
2.11 × 101≈ (7.66 × 10−2) 9.46 × 103 − (6.91 × 102) | 19.06 | 2.10 × 101 (5.53 × 10−2) 1.64 × 104 (3.28 × 102) | 2.61 |
2.13 × 101 + (5.07 × 102) 1.54 × 104 − (8.39 × 102) | 18.89 | 2.12 × 101 (3.86 × 10−2) 9.68 × 103 (2.25 × 103) | 5.79 | 2.12 × 101
≈ (3.33 × 10−2) 1.15 × 104 + (1.45 × 103) | 18.98 |
| P4 | T1 T2 | 1.95 × 102 (4.43 × 101) 7.64 × 103 (6.35 × 102) | 4.25 |
7.78 × 102 + (1.00 × 102) 2.58 × 102 − (8.90 × 101) | 19.17 | 3.23 × 102 (8.88 × 101) 3.38 × 10−4 (2.65 × 10−4) | 2.60 |
7.72 × 102 + (1.09 × 102) 3.53 × 103 + (8.34 × 102) | 21.91 | 8.10 × 101 (9.75 × 100) 2.44 × 10−6 (7.82 × 10−6) | 4.79 |
8.13 × 101
≈ (1.71 × 101) 1.64 × 10−5 + (1.30 × 10−5) | 20.00 |
| P5 | T1 T2 | 3.59 × 100 (7.93 × 10−1) 2.49 × 104 (2.25 × 104) | 4.09 |
7.21 × 100 + (5.99 × 10−1) 7.37 × 104 + (4.33 × 104) | 18.80 | 2.52 × 10−1 (3.81 × 10−1) 6.67 × 101 (3.11 × 101) | 2.63 |
3.69 × 100 + (6.01 × 10−1) 8.39 × 103 + (3.85 × 103) | 20.70 | 6.74 × 10−5 (9.91 × 10−5) 6.48 × 101 (2.97 × 101) | 5.14 |
2.80 × 10−3 + (5.52 × 10−3) 6.52 × 101 ≈ (2.28 × 101) | 19.47 |
| P6 | T1 T2 | 3.74 × 100 (8.99 × 10−1) 5.52 × 100 (8.98 × 10−1) | 19.46 |
2.10 × 101 + (7.61 × 10−2) 2.17 × 101 + (2.49 × 100) | 27.67 | 3.10 × 10−1 (5.02 × 10−1) 2.19 × 101 (3.61 × 100) | 18.20 |
1.02 × 101 + (1.34 × 100) 7.87 × 100 − (1.47 × 100) | 46.21 | 3.06 × 10−1 (5.67 × 10−1) 1.88 × 100 (2.37 × 100) | 30.13 |
7.71 × 10−1 + (1.08 × 100) 2.61 × 10−1 ≈ (6.59 × 10−1) | 33.32 |
| P7 | T1 T2 | 2.25 × 103 (1.74 × 103) 5.78 × 102 (2.49 × 102) | 4.47 |
7.75 × 104 + (3.70 × 104) 4.30 × 102 − (6.03 × 101) | 18.42 | 8.56 × 101 (8.06 × 101) 7.09 × 101 (3.80 × 101) | 3.57 |
1.05 × 105 + (4.72 × 104) 3.77 × 102 + (6.90 × 101) | 21.59 | 9.25 × 101 (2.75 × 101) 5.14 × 101 (1.22 × 101) | 5.55 |
1.17 × 102
≈ (1.17 × 102) 2.65 × 101 − (1.92 × 101) | 18.78 |
| P8 | T1 T2 | 4.21 × 10−2 (1.28 × 10−2) 3.07 × 101 (5.12 × 10−1) | 33.23 |
1.04 × 100 + (4.22 × 102) 2.86 × 101 − (2.66 × 100) | 38.55 | 5.33 × 10−3 (6.56 × 10−3) 5.26 × 101 (3.80 × 100) | 35.86 |
1.06 × 100 + (3.68 × 10−2) 2.91 × 101 − (2.01 × 100) | 70.41 | 1.41 × 10−3 (3.33 × 10−3) 5.93 × 100 (2.04 × 100) | 51.45 |
1.67 × 10−3 + (3.99 × 10−3) 2.81 × 100 − (1.20 × 100) | 63.82 |
| P9 | T1 T2 | 3.36 × 102 (8.16 × 102) 1.75 × 104 (5.37 × 102) | 5.69 |
7.33 × 102 + (7.24 × 101) 9.81 × 103 − (6.92 × 102) | 17.90 | 3.55 × 102 (6.91 × 101) 1.60 × 104 (4.90 × 102) | 3.71 |
2.43 × 103 + (6.27 × 102) 1.57 × 104 ≈ (5.88 × 102) | 22.33 |
3.22 × 102 (1.06 × 102) 5.86 × 103 (5.84 × 102) | 6.23 | 1.01 × 102 − (2.66 × 101) 4.24 × 103 − (8.61 × 102) | 24.75 |
| +/−/≈ | 11/6/1 | 13/3/2 | 7/6/5 | ||||||||||
| Task Set | IMGA | MFEA | IMPSO | MFPSO | IMDE | MFDE | |
|---|---|---|---|---|---|---|---|
| GA-Based | PSO-Based | DE-Based | |||||
| P1 | T1 T2 | 6.226 × 102
(1.999 × 10−1) 6.279 × 102 (1.476 × 10−1) |
6.241 × 102
(2.565 × 10−1) + 6.272 × 102 (1.722 × 10−1) − | 6.232 × 102
(2.039 × 10−1) 6.262 × 102 (2.346 × 10−1) |
6.235 × 102
(2.507 × 10−1) + 6.270 × 102 (2.411 × 10−1) + | 6.217 × 102
(1.503 × 10−1) 6.246 × 102 (1.351 × 10−1) | 6.217 × 102
(1.236 × 10−1)
≈ 6.246 × 102 (1.217 × 10−1) ≈ |
| P2 | T1 T2 | 7.112 × 102
(2.545 × 10−3) 7.194 × 102 (6.928 × 10−2) |
7.113 × 102
(1.519 × 10−2) + 7.177 × 102 (1.642 × 10−2) − | 7.112 × 102
(2.068 × 10−4) 7.176 × 102 (3.411 × 10−13) |
7.113 × 102
(6.677 × 10−2) + 7.178 × 102 (1.976 × 10−1) + | 7.112 × 102
(7.461 × 10−10) 7.176 × 102 (1.450 × 10−9) | 7.112 × 102
(6.483 × 10−8) + 7.176 × 102 (1.465 × 10−7) + |
| P3 | T1 T2 | 2.887 × 106
(2.510 × 104) 5.787 × 107 (1.480 × 106) |
2.974 × 106
(2.537 × 104) + 3.597 × 107 (2.123 × 105) − | 2.834 × 106
(0.000 × 100) 3.474 × 107 (7.451 × 10−9) |
2.878 × 106
(6.454 × 104) + 3.637 × 107 (1.434 × 106) + | 2.834 × 106
(2.792 × 10−3) 3.474 × 107 (2.889 × 10−2) | 2.834 × 106
(8.790 × 10−2) + 3.474 × 107 (1.096 × 100) + |
| P4 | T1 T2 | 1.304 × 103
(2.390 × 10−4) 1.305 × 103 (2.121 × 10−3) |
3.400 × 105
(4.295 × 102) + 8.574 × 105 (1.582 × 103) + | 1.304 × 103
(2.274 × 10−13) 1.305 × 103 (4.547 × 10−13) | 1.304 × 103
(2.450 × 10−3) − 1.305 × 103 (3.531 × 10−3) − | 1.304 × 103
(2.119 × 10−11) 1.305 × 103 (1.993 × 10−11) | 1.304 × 103
(1.346 × 10−9) + 1.305 × 103 (1.320 × 10−9) + |
| P5 | T1 T2 | 3.374 × 105
(4.217 × 102) 9.640 × 105 (8.560 × 103) |
3.400 × 105
(4.230 × 102) + 8.574 × 105 (1.548 × 103) − | 3.366 × 105
(4.285 × 10−2) 8.491 × 105 (2.755 × 10−10) |
3.384 × 105
(2.654 × 103) + 8.618 × 105 (8.758 × 103) + | 3.366 × 105
(3.049 × 100) 8.491 × 105 (7.984 × 10−5) | 3.366 × 105
(2.084 × 10−3) − 8.491 × 105 (7.594 × 10−3) + |
| P6 | T1 T2 | 1.868 × 108
(1.105 × 105) 2.815 × 109 (6.530 × 106) |
1.892 × 108
(3.407 × 105) + 2.671 × 109 (2.557 × 106) − | 1.867 × 108
(5.960 × 10−8) 2.653 × 109 (4.768 × 10−7) |
1.885 × 108
(1.482 × 106) + 2.674 × 109 (1.551 × 107) + | 1.867 × 108
(1.422 × 10−2) 2.653 × 109 (1.088 × 10−1) | 1.867 × 108
(1.120 × 100) + 2.653 × 109 (9.594 × 100) + |
| P7 | T1 T2 | 6.221 × 104
(9.702 × 101) 1.724 × 104 (1.394 × 102) |
6.284 × 104
(1.462 × 102) + 1.495 × 104 (2.677 × 101) − | 6.201 × 104
(4.659 × 10−1) 1.478 × 104 (7.520 × 100) |
6.323 × 104
(9.237 × 102) + 1.481 × 104 (4.567 × 101) + | 6.201 × 104
(1.970 × 100) 1.477 × 104 (7.585 × 10−1) | 6.201 × 104
(5.445 × 10−4) + 1.477 × 104 (2.106 × 100) ≈ |
| P8 | T1 T2 | 5.201 × 102
(6.791 × 10−2) 5.214 × 102 (5.860 × 10−2) |
5.203 × 102
(9.244 × 10−2) + 5.202 × 102 (8.411 × 10−2) − |
5.208 × 102
(1.072 × 10−1) 5.207 × 102 (1.176 × 10−1) | 5.205 × 102
(1.066 × 10−1) − 5.206 × 102 (1.349 × 10−1) ≈ | 5.202 × 102
(5.078 × 10−2) 5.202 × 102 (5.740 × 10−2) | 5.202 × 102
(1.028 × 10−1)
≈ 5.202 × 102 (6.809 × 10−2) ≈ |
| P9 | T1 T2 | 1.898 × 104
(3.961 × 100) 1.624 × 103 (1.820 × 10−1) |
1.902 × 104
(9.390 × 100) + 1.622 × 103 (7.316 × 10−2) − | 1.897 × 104
(2.119 × 100) 1.622 × 103 (1.012 × 10−1) |
1.906 × 104
(1.112 × 102) + 1.622 × 103 (1.118 × 10−1) ≈ | 1.897 × 104
(1.770 × 100) 1.622 × 103 (1.113 × 10−1) | 1.897 × 104
(1.125 × 102)
≈ 1.622 × 103 (8.822 × 10−2) ≈ |
| P10 | T1 T2 | 1.947 × 109
(1.414 × 106) 7.516 × 108 (4.203 × 106) |
1.957 × 109
(1.920 × 106) + 6.781 × 108 (6.624 × 105) − | 1.945 × 109
(2.384 × 10−7) 6.728 × 108 (1.192 × 10−7) |
1.972 × 109
(1.430 × 107) + 6.740 × 108 (2.580 × 106) + | 1.945 × 109
(1.043 × 10−1) 6.728 × 108 (7.069 × 10−2) | 1.945 × 109
(8.881 × 100) + 6.728 × 108 (4.084 × 100) + |
| +/−/≈ | 11/9/0 | 15/3/2 | 12/1/7 | ||||
| Task Set | IMGA | GA | IMDE | DE | IMPSO | PSO | IMABC | ABC | |
|---|---|---|---|---|---|---|---|---|---|
| GA-Based | DE-Based | PSO-Based | ABC-Based | ||||||
| P1 | T1 T2 | 1.11 × 10−1 (5.27 × 10−2) 3.39 × 102 (4.72 × 101) |
9.22 × 10−1 + (4.21 × 10−1) 9.23 × 102 + (7.73 × 102) | 1.20 × 10−4 (3.63 × 10−4) 5.03 × 101 (1.30 × 101) |
2.49 × 10−3
≈ (5.33 × 10−3) 4.03 × 102 + (1.84 × 101) | 4.99 × 10−3 (6.57 × 10−3) 3.26 × 102 (6.26 × 101) |
4.80 × 10−2 + (1.13 × 10−2) 4.90 × 102 + (7.21 × 101) | 2.47 × 10−1 (1.22 × 10−1) 2.06 × 102 (6.73 × 101) |
1.75 × 100 + (1.32 × 10−1) 1.33 × 103 + (1.47 × 102) |
| P2 | T1 T2 | 3.83 × 100 (8.78 × 10−1) 4.16 × 102 (3.65 × 101) |
1.55 × 101 + (3.39 × 100) 7.14 × 103 + (7.28 × 103) | 4.74 × 10−3 (9.54 × 10−3) 4.43 × 101 (1.15 × 101) |
2.33 × 10−1 + (4.46 × 10−1) 4.04 × 102 + (2.66 × 101) | 3.93 × 10−1 (4.54 × 10−1) 3.73 × 101 (1.20 × 101) |
8.16 × 100 + (1.44 × 100) 5.14 × 102 + (1.11 × 102) | 1.28 × 100 (8.18 × 101) 1.25 × 102 (8.33 × 101) |
2.12 × 101 + (3.61 × 10−2) 1.31 × 103 + (1.30 × 102) |
| P3 | T1 T2 |
2.08 × 101 (4.19 × 10−1) 1.30 × 104 (6.82 × 102) | 2.00 × 101 − (4.14 × 10−2) 1.79 × 104 + (6.29 × 102) | 2.12 × 101 (3.86 × 10−2) 9.68 × 103 (2.25 × 103) | 2.12 × 101 + (2.77 × 10−2) 9.81 × 103 ≈ (1.72 × 103) |
2.10 × 101 (5.53 × 10−2) 1.64 × 104 (3.28 × 102) | 2.08 × 101 − (1.28 × 10−1) 1.68 × 104 + (5.75 × 102) | 2.12 × 101 (3.57 × 10−2) 3.20 × 10119 (1.32 × 10120) | 2.12 × 101
≈ (3.43 × 10−2) 1.72 × 10122 + (4.00 × 10122) |
| P4 | T1 T2 | 1.95 × 102 (4.43 × 101) 7.64 × 103 (6.35 × 102) |
8.63 × 102 + (2.95 × 102) 1.02 × 104 + (7.25 × 102) | 8.10 × 101 (9.75 × 100) 2.44 × 10−6 (7.82 × 10−6) |
3.98 × 102 + (2.01 × 101) 4.64 × 10−6 + (1.81 × 10−5) | 3.23 × 102 (8.88 × 101) 3.38 × 10−4 (2.65 × 10−4) |
4.62 × 102 + (7.88 × 101) 7.95 × 10−1 + (2.54 × 10−1) | 6.29 × 102 (4.97 × 101) 2.50 × 102 (1.06 × 102) |
1.38 × 103 + (2.19 × 102) 2.89 × 103 + (4.87 × 102) |
| P5 | T1 T2 | 3.59 × 100 (7.93 × 10−1) 2.49 × 104 (2.25 × 104) |
1.69 × 101 + (3.94 × 100) 1.02 × 109 + (9.87 × 108) | 6.74 × 10−5 (9.91 × 10−5) 6.48 × 101 (2.97 × 101) |
1.67 × 10−1 + (4.40 × 10−1) 4.09 × 104 + (1.61 × 105) |
2.52 × 10−1 (3.81 × 10−1) 6.67 × 101 (3.11 × 101) | 4.80 × 10−2 − (1.35 × 100) 4.90 × 102 + (1.07 × 102) | 2.64 × 10−1 (6.23 × 10−2) 1.07 × 102 (5.57 × 100) |
2.12 × 101 + (4.47 × 10−2) 8.49 × 108 + (2.22 × 108) |
| P6 | T1 T2 | 3.74 × 100 (8.99 × 10−1) 5.52 × 100 (8.98 × 10−1) |
1.47 × 101 + (3.81 × 100) 3.58 × 101 + (1.45 × 100) |
3.06 × 10−1 (5.67 × 10−1) 1.88 × 100 (2.37 × 100) | 2.25 × 10−1
≈ (4.21 × 10−1) 2.51 × 100 ≈ (2.67 × 100) | 3.10 × 10−1 (5.02 × 10−1) 2.19 × 101 (3.61 × 100) |
8.29 × 100 + (1.31 × 100) 2.14 × 101 ≈ (3.77 × 100) | 2.12 × 101 (4.34 × 10−2) 2.00 × 101 (4.47 × 100) | 2.12 × 101≈ (3.51 × 10−2) 3.15 × 101 + (1.61 × 100) |
| P7 | T1 T2 | 2.25 × 103 (1.74 × 103) 5.78 × 102 (2.49 × 102) |
4.25 × 106 + (9.03 × 106) 1.60 × 103 + (1.25 × 103) | 9.25 × 101 (2.75 × 101) 5.14 × 101 (1.22 × 101) |
1.21 × 104 + (3.03 × 104) 4.01 × 102 + (1.82 × 101) | 8.56 × 101 (8.06 × 101) 7.09 × 101 (3.80 × 101) |
3.47 × 102 + (1.81 × 102) 4.87 × 102 + (9.55 × 101) | 5.78 × 102 (1.66 × 102) 2.67 × 102 (3.88 × 101) |
8.29 × 108 + (1.76 × 108) 1.30 × 103 + (1.25 × 102) |
| P8 | T1 T2 | 4.21 × 10−2 (1.28 × 10−2) 3.07 × 101 (5.12 × 10−1) |
1.06 × 100 + (3.91 × 10−1) 7.86 × 101 + (1.90 × 100) | 1.41 × 10−3 (3.33 × 10−3) 5.93 × 100 (2.04 × 100) |
9.94 × 10−3 + (2.17 × 10−2) 6.71 × 100 ≈ (1.44 × 100) | 5.33 × 10−3 (6.56 × 10−3) 5.26 × 101 (3.80 × 100) |
5.57 × 10−2 + (1.68 × 10−2) 4.41 × 101 ≈ (1.42 × 101) | 1.01 × 100 (3.17 × 10−2) 2.37 × 101 (1.15 × 100) |
1.79 × 100 + (1.32 × 10−1) 7.38 × 101 + (1.76 × 100) |
| P9 | T1 T2 | 3.36 × 102 (8.16 × 102) 1.75 × 104 (5.37 × 102) |
8.94 × 102 + (3.07 × 102) 1.81 × 104 + (6.28 × 102) | 3.22 × 102 (1.06 × 102) 5.86 × 103 (5.84 × 102) |
3.97 × 102 + (2.92 × 101) 9.33 × 103 + (1.57 × 103) | 3.55 × 102 (6.91 × 101) 1.60 × 104 (4.90 × 102) |
4.64 × 102 + (1.33 × 102) 1.70 × 104 + (5.97 × 102) |
2.23 × 103 (3.87 × 102) 3.08 × 10120 (1.33 × 10121) | 1.28 × 103 − (1.86 × 102) 1.22 × 10122 + (4.80 × 10122) |
| +/−/≈ | 17/1/0 | 13/0/5 | 14/2/2 | 15/1/2 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Kang, Q.; Zhou, M.; Fan, Z.; Albeshri, A. A Knowledge Sharing and Individually Guided Evolutionary Algorithm for Multi-Task Optimization Problems. Appl. Sci. 2023, 13, 602. https://doi.org/10.3390/app13010602
Wang X, Kang Q, Zhou M, Fan Z, Albeshri A. A Knowledge Sharing and Individually Guided Evolutionary Algorithm for Multi-Task Optimization Problems. Applied Sciences. 2023; 13(1):602. https://doi.org/10.3390/app13010602
Chicago/Turabian StyleWang, Xiaoling, Qi Kang, Mengchu Zhou, Zheng Fan, and Aiiad Albeshri. 2023. "A Knowledge Sharing and Individually Guided Evolutionary Algorithm for Multi-Task Optimization Problems" Applied Sciences 13, no. 1: 602. https://doi.org/10.3390/app13010602
APA StyleWang, X., Kang, Q., Zhou, M., Fan, Z., & Albeshri, A. (2023). A Knowledge Sharing and Individually Guided Evolutionary Algorithm for Multi-Task Optimization Problems. Applied Sciences, 13(1), 602. https://doi.org/10.3390/app13010602