
Deep Image Clustering Based on Label Similarity and Maximizing Mutual Information across Views


Abstract
:1. Introduction
- An end-to-end clustering network model is proposed to jointly learn representations and cluster assignments while preventing the network from falling into trivial solutions.
- An extended MI method is proposed. It calculates the MI between features from multiple views of the same image, forcing the instance-level feature to capture invariant essential information and thus reducing the intra-class diversities in the representation feature space.
2. Related Work
2.1. Deep Clustering
2.2. Mutual Information
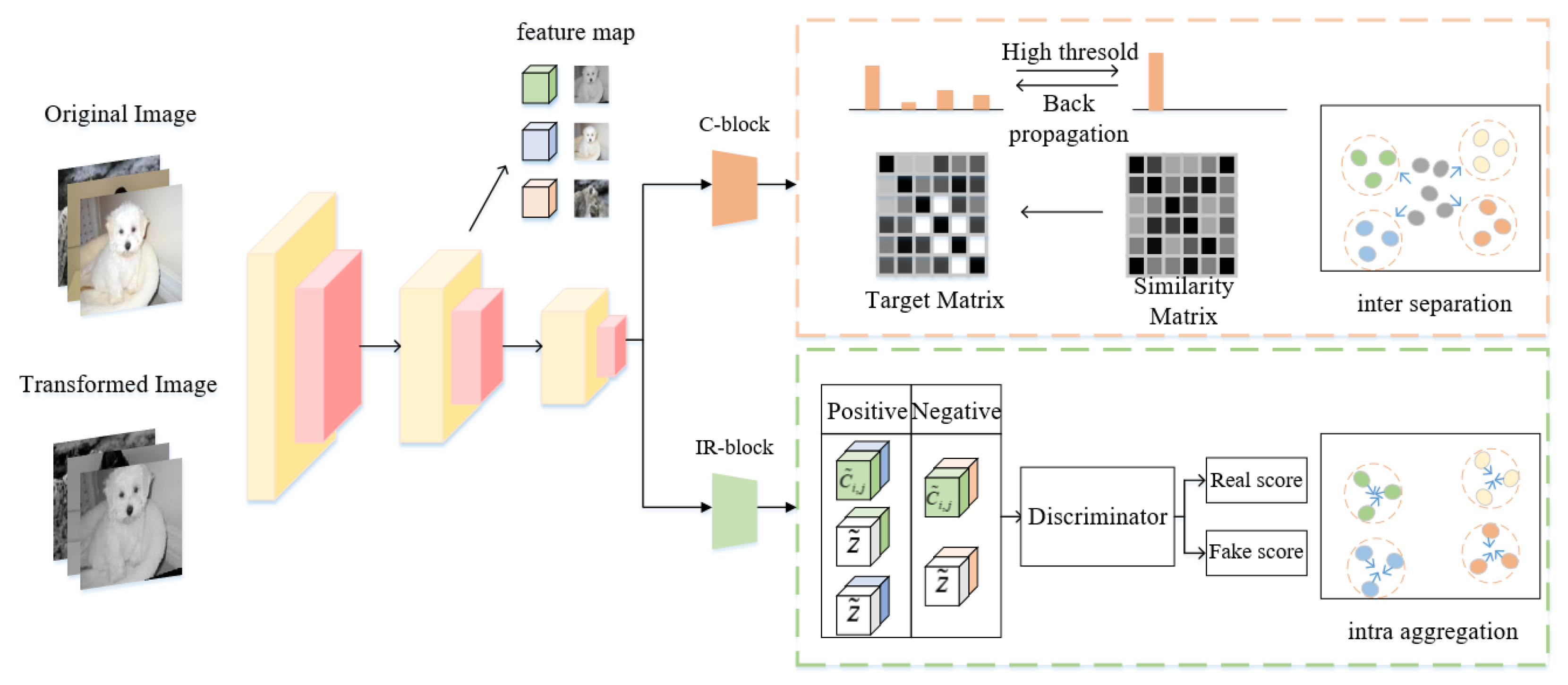
3. Deep Image Clustering under Similarity and Mutual Information
3.1. Clustering Module
3.2. Fine-Tuning through Cluster-Standard Samples
3.3. Extended Mutual Information
3.4. Maximize Entropy Loss
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Compared Methods
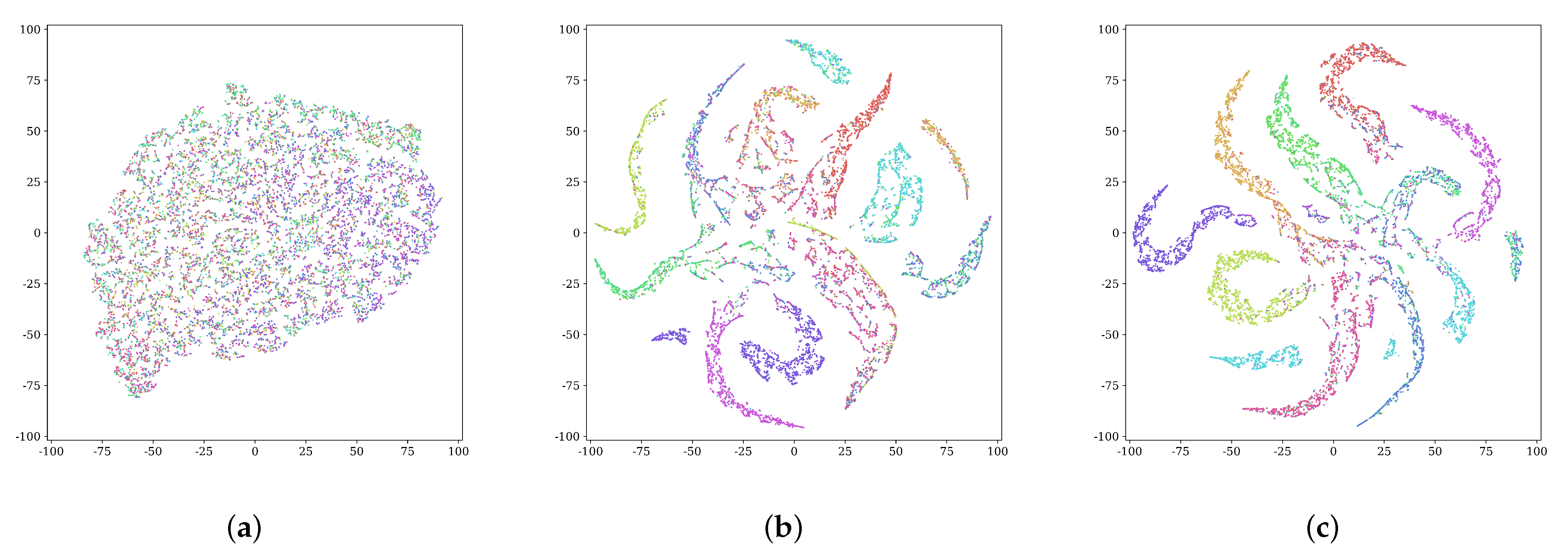
4.5. Results and Analysis
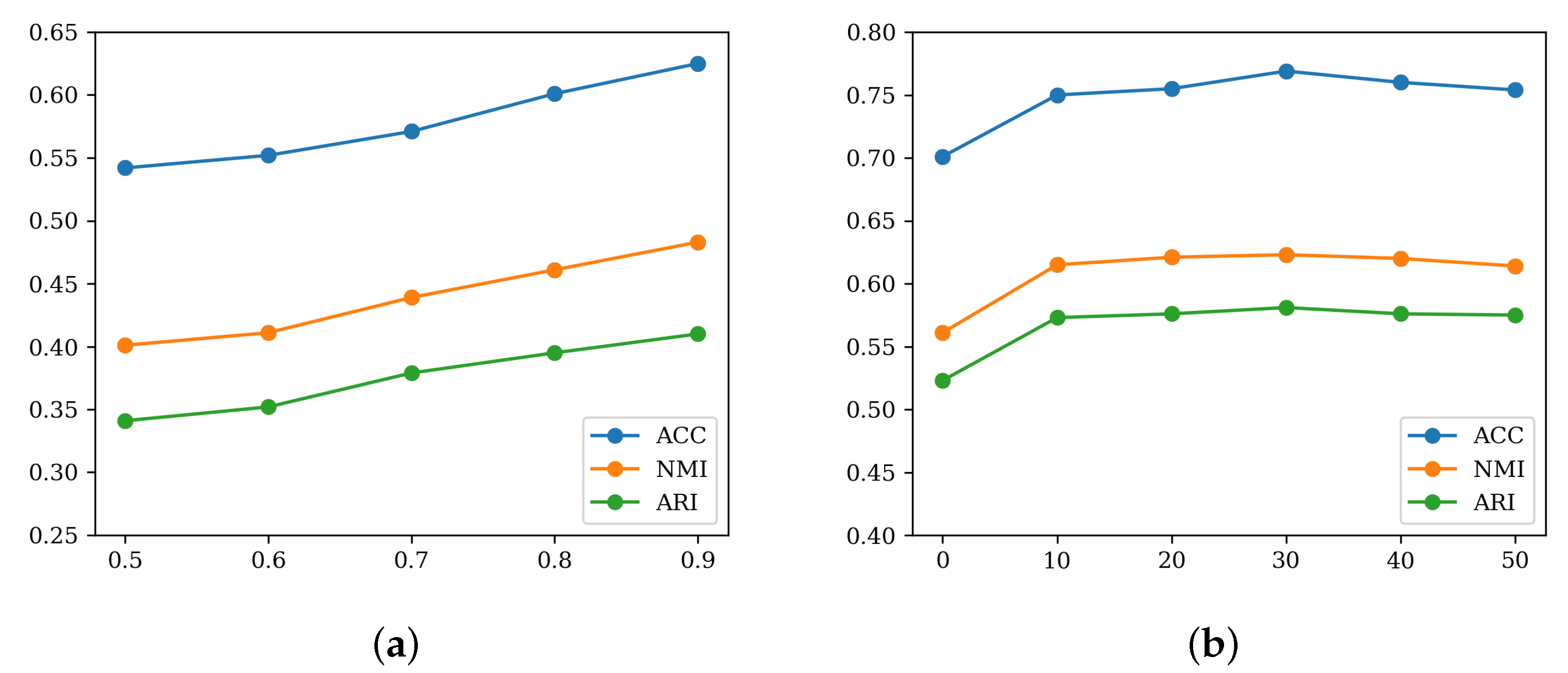
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, C.; Dai, Y.; Lin, R.; Shi, W. Deep clustering by maximizing mutual information in variational auto-encoder. Knowl.-Based Syst. 2020, 205, 106260. [Google Scholar] [CrossRef]
- Tang, X.; Dong, C.; Zhang, W. Contrastive Author-aware Text Clustering. Pattern Recognit. 2022, 130, 108787. [Google Scholar] [CrossRef]
- Jiang, G.; Peng, J.; Wang, H.; Ze, M.; Xian, F. Tensorial Multi-view Clustering via Low-rank Constrained High-order Graph Learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 30, 5307–5318. [Google Scholar] [CrossRef]
- Wang, H.; Jiang, G.; Peng, J.; Ruo, D.; Xian, F. Towards Adaptive Consensus Graph: Multi-view Clustering via Graph Collaboration. IEEE Trans. Multimed. 2022, 10, 1–13. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Los Angeles, CA, USA, 21 June–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [Green Version]
- Ghareeb, A.; Rida, S.Z. Image quality measures based on intuitionistic fuzzy similarity and inclusion measures. J. Intell. Fuzzy Syst. 2018, 34, 4057–4065. [Google Scholar] [CrossRef]
- Xiao, Z.; Shi, Z.; Yong, L.; Ji, Z.; Li, Y.; Yue, F. Low-rank sparse subspace for spectral clustering. IEEE Trans. Knowl. Data Eng. 2018, 31, 1532–1543. [Google Scholar]
- Wang, H.; Wang, Y.; Zhang, Z.; Xian, F.; Li, Z.; Ming, X. Kernelized multiview subspace analysis by self-weighted learning. IEEE Trans. Multimed. 2020, 23, 3828–3840. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Jun, H.; Gui, D.; Jian, S. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Kaur, P.; Harnal, S.; Tiwari, R.; Alharithi, F.S.; Almulihi, A.H.; Noya, I.D.; Goyal, N. A hybrid convolutional neural network model for diagnosis of COVID-19 using chest X-ray images. Int. J. Environ. Res. Public Health 2021, 18, 12191. [Google Scholar] [CrossRef]
- Hui, W.; Jin, P.; Guang, J.; Feng, X.; Xian, F. Discriminative feature and dictionary learning with part-aware model for vehicle re-identification. Neurocomputing 2021, 438, 55–62. [Google Scholar]
- Wang, H.; Peng, J.; Zhao, Y.; Fu, X. Multi-path deep cnns for fine-grained car recognition. IEEE Trans. Veh. Technol. 2020, 69, 10484–10493. [Google Scholar] [CrossRef]
- Wang, H.; Peng, J.; Chen, D.; Jiang, G.; Zhao, T.; Fu, X. Attribute-guided feature learning network for vehicle reidentification. IEEE Multimed. 2020, 27, 112–121. [Google Scholar] [CrossRef]
- Chugh, H.; Gupta, S.; Garg, M.; Gupta, D.; Mohamed, H.G.; Noya, I.D.; Singh, A.; Goyal, N. An Image Retrieval Framework Design Analysis Using Saliency Structure and Color Difference Histogram. Sustainability 2022, 14, 10357. [Google Scholar] [CrossRef]
- Min, E.; Guo, X.; Liu, Q.; Zhang, G.; Cui, J.; Long, J. A survey of clustering with deep learning: From the perspective of network architecture. IEEE Access 2018, 6, 39501–39514. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde, D.; Ozair, S. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Yu, Y.; Zhou, W. Mixture of GANs for clustering. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3047–3053. [Google Scholar]
- Ghasedi, K.; Wang, X.; Deng, C.; Huang, H. Balanced self-paced learning for generative adversarial clustering network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4391–4400. [Google Scholar]
- Mukherjee, S.; Asnani, H.; Lin, E.; Kannan, S. Clustergan: Latent space clustering in generative adversarial networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 22 February–1 March 2019; pp. 4610–4617. [Google Scholar]
- Cao, W.; Zhang, Z.; Liu, C.; Li, R. Unsupervised discriminative feature learning via finding a clustering-friendly embedding space. Pattern Recognit. 2022, 129, 108768. [Google Scholar] [CrossRef]
- Chang, J.; Wang, L.; Meng, G.; Xiang, S.; Pan, C. Deep adaptive image clustering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5879–5887. [Google Scholar]
- Wu, J.; Long, K.; Wang, F.; Qian, C.; Li, C.; Lin, Z.; Zha, H. Deep comprehensive correlation mining for image clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 8150–8159. [Google Scholar]
- Xu, J.; Henriques, J.F.; Vedaldi, A. Invariant information clustering for unsupervised image classification and segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9865–9874. [Google Scholar]
- Yang, B.; Fu, X.; Sidiropoulos, N.D.; Hong, M. Towards k-means-friendly spaces: Simultaneous deep learning and clustering. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 3861–3870. [Google Scholar]
- Fard, M.M.; Thonet, T.; Gaussier, E. Deep k-means: Jointly clustering with k-means and learning representations. Pattern Recognit. Lett. 2020, 138, 185–192. [Google Scholar] [CrossRef]
- Lv, J.; Kang, Z.; Lu, X.; Xu, Z. Pseudo-supervised deep subspace clustering. IEEE Trans. Image Process. 2021, 30, 5252–5263. [Google Scholar] [CrossRef] [PubMed]
- Diallo, B.; Hu, J.; Li, T.; Khan, G.; Liang, X.; Zhao, Y. Deep embedding clustering based on contractive autoencoder. Neurocomputing 2021, 433, 96–107. [Google Scholar] [CrossRef]
- Ren, Y.; Wang, N.; Li, M.; Xu, Z. Deep density-based image clustering. Knowl.-Based Syst. 2020, 197, 105841. [Google Scholar] [CrossRef]
- Yang, J.; Parikh, D.; Batra, D. Joint unsupervised learning of deep representations and image clusters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5147–5156. [Google Scholar]
- Sen, B.; Zhou, P.; Du, L.; Li, X. Active deep image clustering. Knowl.-Based Syst. 2022, 252, 109346. [Google Scholar] [CrossRef]
- Ntelemis, F.; Jin, Y.; Thomas, S.A. Image clustering using an augmented generative adversarial network and information maximization. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7461–7474. [Google Scholar] [CrossRef]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 478–487. [Google Scholar]
- Van Gansbeke, W.; Vandenhende, S.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Scan: Learning to classify images without labels. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 268–285. [Google Scholar]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual information neural estimation. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 531–540. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Krause, A.; Perona, P.; Gomes, R. Discriminative clustering by regularized information maximization. Adv. Neural Inf. Process. Syst. 2010, 23, 531–540. [Google Scholar]
- Hu, W.; Miyato, T.; Tokui, S.; Matsumoto, E.; Sugiyama, M. Learning discrete representations via information maximizing self-augmented training. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1558–1567. [Google Scholar]
- Nowozin, S.; Cseke, B.; Tomioka, R. f-gan: Training generative neural samplers using variational divergence minimization. Adv. Neural Inf. Process. Syst. 2016, 29, 271–279. [Google Scholar]
- Niu, C.; Zhang, J.; Wang, G.; Liang, J. Gatcluster: Self-supervised gaussian-attention network for image clustering. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 735–751. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Training Sets | Test Sets | Categories | Image Size |
|---|---|---|---|---|
| CIFAR10 | 50,000 | 10,000 | 10 | 32 × 32 × 3 |
| MNIST | 60,000 | 10,000 | 10 | 28 × 28 × 1 |
| STL-10 | 13,000 | N/A | 10 | 96 × 96 × 3 |
| ImageNet-10 | 13,000 | N/A | 10 | 128 × 128 × 3 |
| Datasets | |||
|---|---|---|---|
| CIFAR10 | 0.1 | 0.5 | 0.2 |
| MNIST | 0.2 | 1 | 0.1 |
| STL-10 | 0.1 | 1 | 0.1 |
| ImageNet-10 | 0.3 | 1 | 0.3 |
| MNIST | CIFAR-10 | STL-10 | ImageNet-10 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NMI | ACC | ARI | NMI | ACC | ARI | NMI | ACC | ARI | NMI | ACC | ARI | |
| K-means | 0.501 | 0.572 | 0.365 | 0.087 | 0.229 | 0.049 | 0.125 | 0.192 | 0.061 | 0.119 | 0.241 | 0.057 |
| SC | 0.662 | 0.695 | 0.521 | 0.103 | 0.247 | 0.085 | 0.098 | 0.159 | 0.048 | 0.151 | 0.274 | 0.076 |
| AE | 0.725 | 0.812 | 0.613 | 0.239 | 0.314 | 0.169 | 0.250 | 0.303 | 0.161 | 0.210 | 0.317 | 0.152 |
| DAE | 0.756 | 0.831 | 0.647 | 0.251 | 0.297 | 0.163 | 0.224 | 0.302 | 0.152 | 0.206 | 0.304 | 0.138 |
| GAN | 0.763 | 0.736 | 0.827 | 0.265 | 0.315 | 0.176 | 0.210 | 0.298 | 0.139 | 0.225 | 0.346 | 0.157 |
| DeCNN | 0.757 | 0.817 | 0.669 | 0.240 | 0.282 | 0.174 | 0.227 | 0.299 | 0.162 | 0.186 | 0.313 | 0.142 |
| VAE | 0.876 | 0.945 | 0.849 | 0.245 | 0.291 | 0.167 | 0.200 | 0.282 | 0.146 | 0.193 | 0.334 | 0.168 |
| DEC | 0.771 | 0.843 | 0.741 | 0.257 | 0.301 | 0.161 | 0.276 | 0.359 | 0.186 | 0.282 | 0.381 | 0.203 |
| JULE | 0.913 | 0.964 | 0.927 | 0.192 | 0.272 | 0.138 | 0.182 | 0.277 | 0.164 | 0.175 | 0.300 | 0.138 |
| DAC | 0.935 | 0.977 | 0.948 | 0.396 | 0.522 | 0.306 | 0.366 | 0.470 | 0.257 | 0.394 | 0.527 | 0.302 |
| IIC | - | 0.992 | - | - | 0.617 | - | - | 0.610 | - | - | - | - |
| DCCM | 0.951 | 0.982 | 0.954 | 0.496 | 0.623 | 0.408 | 0.376 | 0.482 | 0.262 | 0.608 | 0.710 | 0.555 |
| ICGAM | - | 0.990 | - | - | 0.700 | - | - | 0.587 | - | - | - | - |
| EDCN | 0.962 | 0.985 | - | 0.603 | 0.544 | - | 0.357 | 0.482 | - | - | - | - |
| DCSM-oc | 0.950 | 0.981 | 0.959 | 0.451 | 0.589 | 0.368 | 0.431 | 0.576 | 0.342 | 0.561 | 0.701 | 0.523 |
| DCSM | 0.967 | 0.994 | 0.973 | 0.505 | 0.636 | 0.413 | 0.483 | 0.625 | 0.410 | 0.623 | 0.769 | 0.581 |
| Methods | ACC | NMI | ARI |
|---|---|---|---|
| OUR | 0.529 | 0.402 | 0.311 |
| DCCM | 0.391 | 0.297 | 0.213 |
| STL-10 | ImageNet-10 | |||||
|---|---|---|---|---|---|---|
| NMI | ACC | ARI | NMI | ACC | ARI | |
| 0.464 | 0.605 | 0.387 | 0.589 | 0.736 | 0.542 | |
| 0.455 | 0.596 | 0.376 | 0.583 | 0.727 | 0.564 | |
| 0.483 | 0.625 | 0.410 | 0.623 | 0.769 | 0.581 | |
| STL-10 | ImageNet-10 | |||||
|---|---|---|---|---|---|---|
| NMI | ACC | ARI | NMI | ACC | ARI | |
| 0.402 | 0.529 | 0.311 | 0.501 | 0.638 | 0.469 | |
| 0.431 | 0.576 | 0.342 | 0.561 | 0.701 | 0.523 | |
| 0.483 | 0.625 | 0.410 | 0.623 | 0.769 | 0.581 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, F.; Li, K. Deep Image Clustering Based on Label Similarity and Maximizing Mutual Information across Views. Appl. Sci. 2023, 13, 674. https://doi.org/10.3390/app13010674
Peng F, Li K. Deep Image Clustering Based on Label Similarity and Maximizing Mutual Information across Views. Applied Sciences. 2023; 13(1):674. https://doi.org/10.3390/app13010674
Chicago/Turabian StylePeng, Feng, and Kai Li. 2023. "Deep Image Clustering Based on Label Similarity and Maximizing Mutual Information across Views" Applied Sciences 13, no. 1: 674. https://doi.org/10.3390/app13010674
APA StylePeng, F., & Li, K. (2023). Deep Image Clustering Based on Label Similarity and Maximizing Mutual Information across Views. Applied Sciences, 13(1), 674. https://doi.org/10.3390/app13010674