1. Introduction
A knowledge graph is a large-scale knowledge database that stores knowledge in a structured manner. It represents entity-related knowledge in the form of triplets, such as <headEntity,Attribute,attributeValue> or <headEntity,Relation,tailEntity> to display the properties and relationship information of entities clearly and intuitively. Large public knowledge graphs such as DBPedia [
1] and YAGO [
2] have demonstrated their crucial role in tasks such as information retrieval and relationship mining. With the emergence of multi-modal data such as images and videos, researchers have realized that they have more information richness and intuitiveness compared to text data. The excellent performance of large-scale multi-modal pre-training models such as UNITER [
3] and ImageBERT [
4] also proves that using multi-modal data to train models can enable them to achieve excellent representation capability. Therefore, multi-modal knowledge graphs such as MMKG [
5] and RichPedia [
6] have emerged in large numbers. Multi-modal knowledge graphs integrate visual data such as images and videos into traditional knowledge graphs and then treat them as entities or descriptive attributes to further enhance the completeness and richness of knowledge graphs. They can also be applied to multi-modal downstream tasks such as visual question answering and image-text generation, thus enhancing the universality of the knowledge graph.
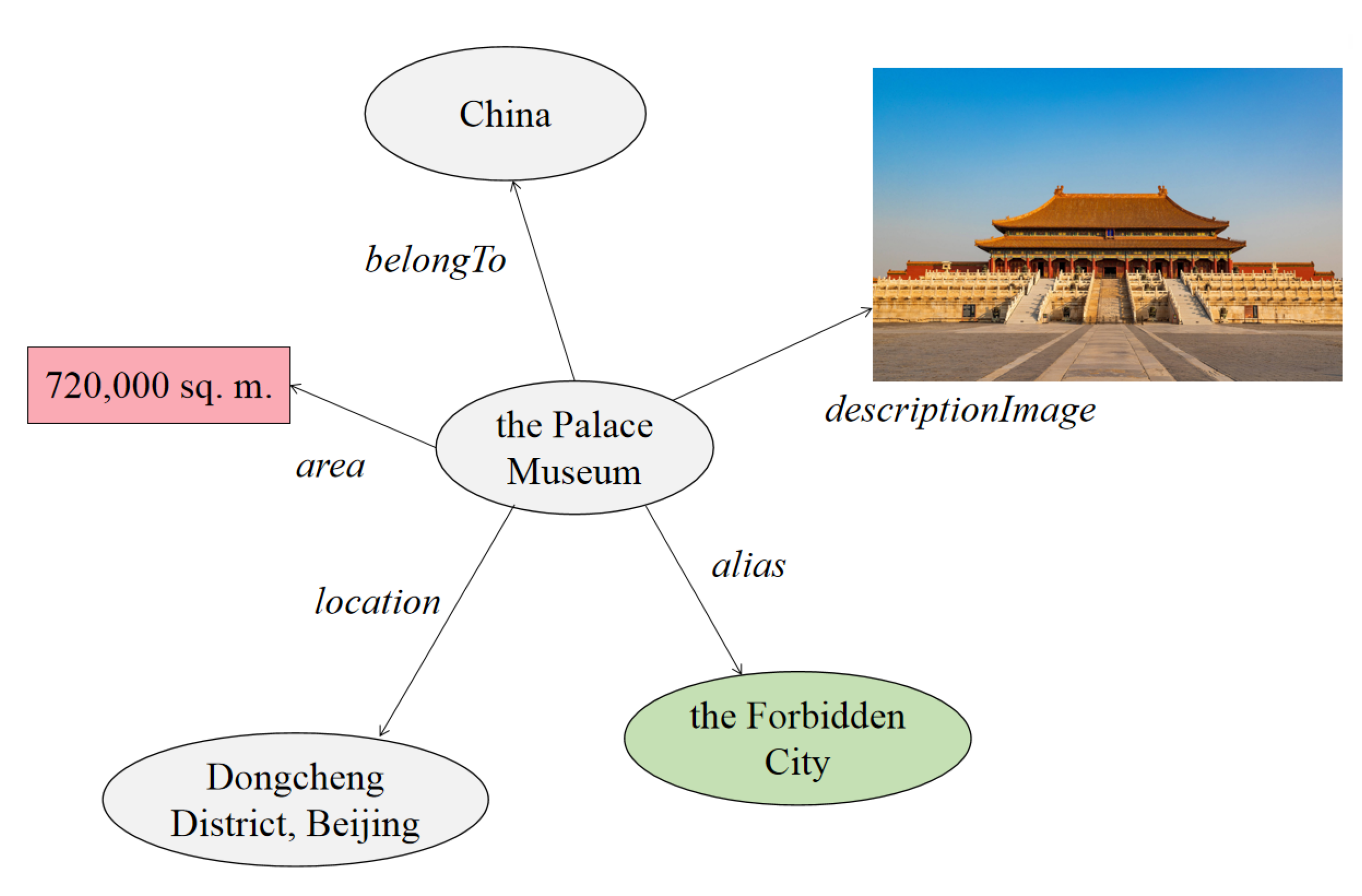
Figure 1 is a simple illustration of a multi-modal knowledge graph.
However, due to the constant growth of data and knowledge, multi-modal knowledge graphs are always incomplete. The incompleteness is mainly manifested in two aspects: entity missing and triple missing. Entity missing refers to the absence of entities that should have been included in the knowledge graph, while triple missing refers to the lack of important attributes or relationships of a given entity; both can lead to unsatisfactory downstream task performance based on the knowledge graph. Entity alignment aims to use models and algorithms to determine whether two entities with different sources and representations refer to the same object in reality, thus reducing the number of redundant entities in the knowledge graph and integrating the triple information of aligned entities. Therefore, entity alignment is an important supporting technology for improving multi-modal knowledge graphs. We denote two pre-aligned multi-modal knowledge graphs as and , where are the sets of entities, relations, attributes, visual information, and triples, respectively, of two graphs. Multi-modal entity alignment aims to find aligned entity pairs . The symbol means that the entity from and the entity from have the same semantic; and refer to the same object in reality.
Some researchers have proposed effective models in the field of multi-modal entity alignment. For example, MMEA [
7] models different modal information of entity attributes and conducts knowledge fusion to achieve the effect of modeling and alignment of multi-modal entities. EVA [
8] uses the visual similarity of entities to create an initial seed dictionary, providing a completely unsupervised solution. HMEA [
9] models multi-modal representations in the hyperbolic space to improve the entity representation capability. MSNEA [
10] also extracts visual, relational, and attribute features of entities separately, integrates visual features based on modal enhancement mechanisms to guide multi-modal feature learning, and adaptively allocates attention weights to capture valuable attributes for alignment. MCLEA [
11] jointly models the intra-modality and inter-modality interactions based on contrastive learning after acquiring the attribute features of each modality to improve the model’s representation capability.
Table 1 shows the comparison of main stream multi-modal entity alignment models. However, the previously mentioned models did not fully utilize the entity information of each modality but only relied on the pre-trained encoders for encoding. This limits their ability to extract deep features from the data. For instance, the equivalent entities that refer to the same movie in the real world may have different description images (such as different movie posters) in various knowledge graphs, which may result in low similarity if only a pre-trained visual model is used for encoding. However, there may be similar text in the posters, such as the movie name and slogan. By extracting the text information to supplement the entity image information, the alignment accuracy can be further improved.
To further enhance the utilization of entity multi-modal information, this paper proposes
MEAFE: a
multi-modal
entity
alignment method based on
feature
enhancement. The core idea is to maximize the use of entity visual, textual, and relational modals to enhance the corresponding feature embedding and improve the knowledge representation ability of the model. Firstly, MEAFE enhances the image modality information by cleaning up the low semantic relevant images using a pre-trained multi-modal model, extracting text information possibly present in the entity image using an OCR (Optical Character Recognition) model, and then encodes it with a pre-trained language model as a supplementary representation of the image embedding. Secondly, the GATv2 [
12] network is used instead of traditional graph convolutional networks [
13] or graph attention networks to extract the neighborhood structure features of the entity. Finally, the distribution of the entity’s modal information, including whether the entity has some modal information and its corresponding amount of data, is used as an auxiliary attribute of the entity to enhance the model’s understanding and modeling ability of various modal information. In addition, we introduce the intra-modal contrastive loss and multi-modal alignment loss used in the MCLEA to better align entities in different knowledge graphs. We design and conduct experiments to verify the effectiveness of the model and validate it on DBP15K [
8], which includes three bilingual datasets, and on two cross kg datasets FB15K-DB15K/YAGO15K [
5]. The proposed model achieves state-of-the-art performance, demonstrating the positive effect of multi-modal feature enhancement on entity alignment.
The contributions of this paper are as follows: (1) To address the issue of insufficient utilization of visual information in traditional multi-modal entity alignment models, we propose using pre-trained multi-modal models and OCR models to enhance the visual representation ability, enabling models to extract more entity-related knowledge from visual images. (2) To address the issue of the weak adaptability of vanilla graph attention networks in entity alignment tasks, which affects alignment accuracy, we propose using the dynamic GATv2 instead to improve the ability to extract structural features. (3) We propose the use of the modal distribution information of entities as a supplementary part of entity features in order to improve the model’s understanding and modeling ability for multi-modal information.
2. Materials and Methods
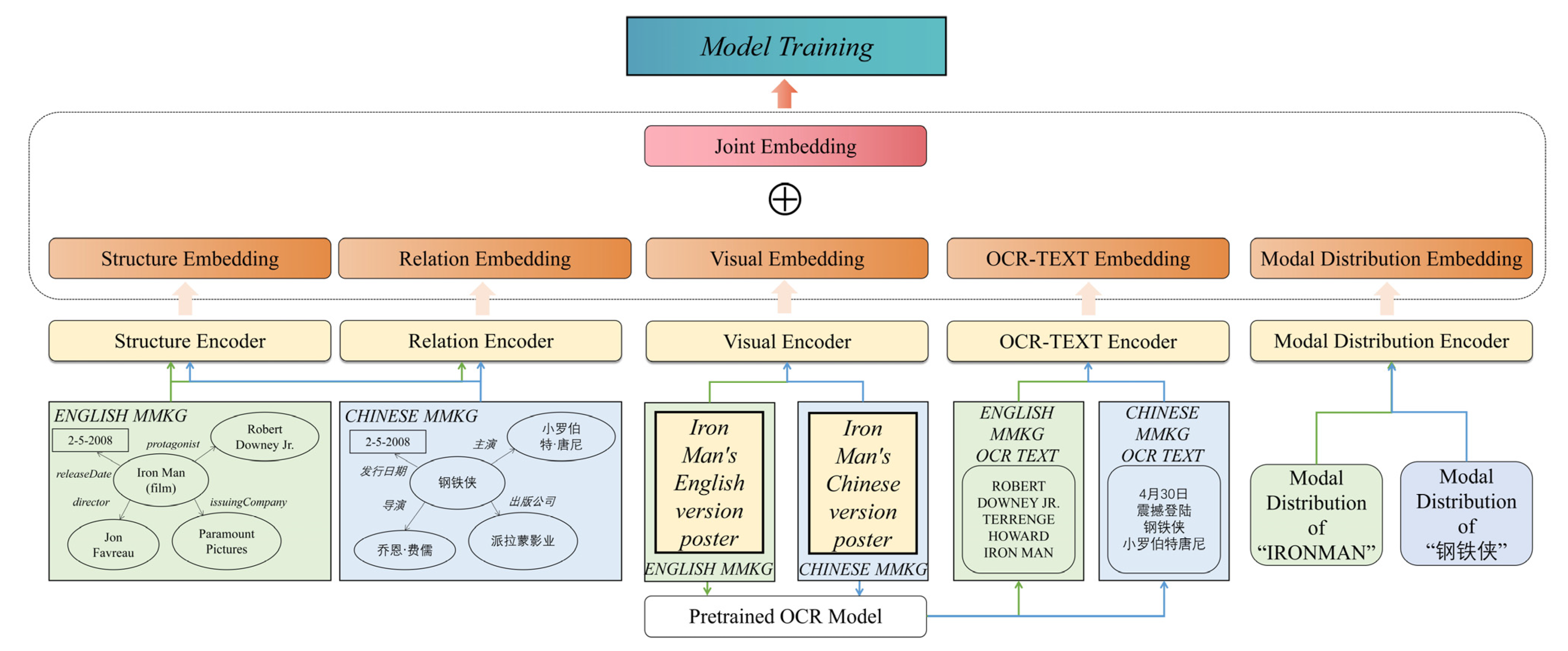
This paper proposes MEAFE, a multi-modal entity alignment method based on feature enhancement, which enhances image and structural features with multi-modal pre-training models, OCR models, and GATv2 networks based on traditional models that only use each modal encoder to initially obtain entity representations. Additionally, MEAFE utilizes the entity modal distribution information to improve the understanding and joint modeling ability of the model for various entity attributes. The overall architecture of the model is shown in
Figure 2. MEAFE first uses the encoders of each modality, and the feature enhancement method proposed in this paper to obtain embedding of each modality and then performs weighted aggregation for multi-modal information fusion to generate the multi-modal joint representation of entities.
2.1. Neighborhood Structure Embedding
Most entity alignment models use graph convolutional networks (GCNs) or graph attention networks (GATs) to structurally model the relationship triples of entities. The formula for using a vanilla GAT [
14] to obtain entity structure embedding is shown as follows:
where
is the original feature of
entityi;
means similarity coefficient between entities;
is the shared weight matrix;
is the single-layer feed forward neural network;
is the activation function;
means matrix splicing;
means the importance of
entityj to
entityi;
is the hidden state of
entityi by aggregating all its one-hop neighbors
; and
softmax and
LeakyReLU are corresponding nonlinear functions.
However, when applied to the entity alignment task, the vanilla graph attention network has two problems: the shared weight matrix and the static property.
Firstly, in the entity alignment task, there are often significant differences between the entity nodes in the knowledge graph and their adjacent nodes. For example, the target entity node and its attribute nodes usually have significant structural differences. Applying shared weight matrices to different types of nodes can make it difficult for the model to correctly distinguish between entity nodes and adjacent nodes, resulting in a reduction in the model’s representational capacity. To address this problem, MEAFE uses two different weight matrices,
and
, to calculate different entity nodes, which enhances the discrimination ability of the GAT for nodes, and then the network can better extract features. The modified attention coefficient calculation formula is as follows:
Secondly, from the finiteness of the relationship between adjacent nodes and entity nodes and the monotonicity of
and
, it can be seen that there exists node
for any node
to maximize
, so that the vanilla graph attention network always tends to give node
the largest attention coefficient while ignoring the different relationships between different input nodes; that is, given a group of nodes and a pre-trained GAT layer, the attention function
has the same maximum tendency node
, so the vanilla GAT is more suitable for mapping all inputs to the constant mapping of the same output. However, it is difficult to build a better model when different query inputs have different correlations with different nodes in the entity alignment task. To put it further, as shown in Formula (3), vanilla graph attention network continuously uses
and
to perform a linear transformation on vectors, then continuously uses
and
to perform the nonlinear transformation; both can only use once transform override, which, in turn, contributes to the static of vanilla graph attention network. To address this problem, MEAFE attempts to apply dynamic graph attention networks [
12] in the multi-modal entity alignment task.
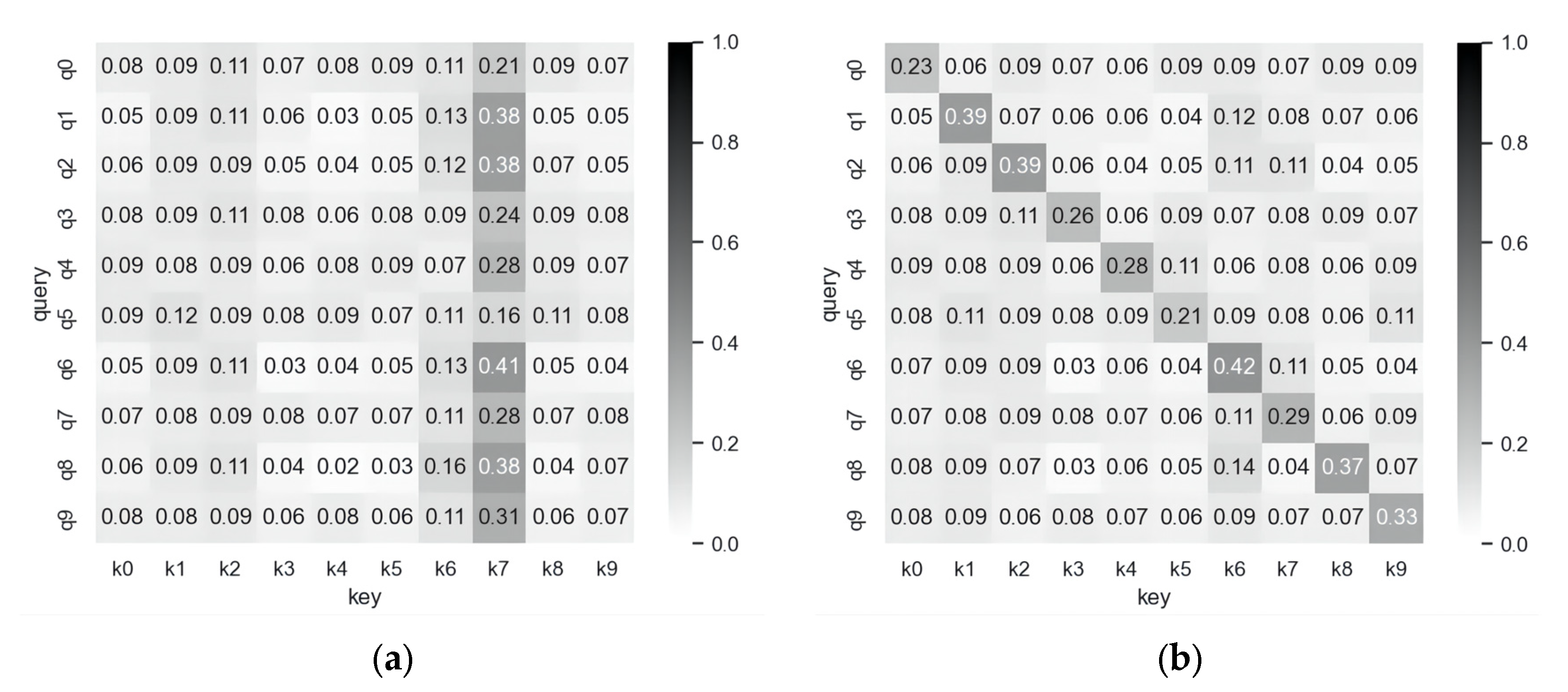
Figure 3 shows the attention tendencies of static and dynamic graph attention networks. The main reason for the limited attention of the static graph attention network is that it simply uses the learnable matrices
and
continuously, so that it can degenerate into a single linear layer. Therefore, the dynamic graph attention network attempts to apply the nonlinear function
first and then input the feedforward neural network
in the calculation of the attention mechanism. The expression is modified as follows:
In the dynamic graph attention network, each query has a different order for the attention coefficients of the keys, so it has a stronger representation ability. Moreover, the dynamic graph attention network avoids the simple continuous use of the learnable matrix and , thus preventing the feedforward neural network and the weight matrix from degenerating and decomposing into a single linear layer, realizing a general approximate attention function, and improving the robustness of the model while obtaining stronger representation ability.
Therefore, the dynamic graph attention network can significantly optimize the acquisition of the weight between nodes for the entity alignment tasks in the case of more complex relationships between nodes and different requirements for the ranking of nodes in different neighborhoods, thus improving the entity alignment effect.
2.2. Relation, Attribute, and Name Embeddings
To better utilize the triples of the given aligned entity pairs for model training, we extract the information of entity relationships, attributes, and entity names as external knowledge to assist in model training.
We follow the modeling approach of the MCLEA model for the relation, attribute, and name information of entities, treating the three types of entity information as bag-of-words features. Additionally, inputting them into three separate feedforward neural networks for training results in relationships, attributes, and name embedding. These embeddings are calculated as [
15]:
where
is the relation, attribute, and name embeddings of
entityi;
and
are the learnable weights of the bias matrix;
is the bag-of-words relation feature;
is the bag-of-words attribute feature; and
is the name feature obtained by averaging the pre-trained GloVe [
16] vectors of name strings.
2.3. Visual Embeddings
MEAFE uses a pre-trained visual model (PVM), e.g., ResNet-152 [
17], as a visual encoder to encode the described image of the entities. Additionally, it then uses the final layer output of it as the image feature. After that, the image feature is inputted into a feedforward layer to achieve the original visual embedding:
where
is the original visual embedding of
entityi;
and
are the learnable weights of the bias matrix of corresponding feedforward neural network;
PVM means pre-trained visual model;
Imgi means the visual image of
entityi.
To further explore useful information in entity images, MEAFE additionally uses a multi-modal pre-training model to perform semantic matching on the description images of entities and remove the description images with poor semantic connections. Then, an OCR model is used to extract possible text information from the images as auxiliary knowledge for the visual encoding obtained only by using pre-trained visual models.
We use the multi-modal pre-training model CLIP [
18] to encode entity names and images separately and calculate their similarities. For entity images, we directly use CLIP for image encoding, while for entity names, we modify them to “A photo of entity name” for text encoding, and then delete images with a similarity below the set threshold.
For the cleaned entity image set, we use the pre-trained PaddleOCR (
https://github.com/PaddlePaddle/PaddleOCR, accessed on 28 December 2022) model to extract possible text information and retain the detected text with a confidence level higher than
. It can output the text that may exist in the detected image as a list. We then use the pre-trained multi-language BERT [
19] to encode the text, taking the pooler output of its last layer as the OCR feature. After obtaining the OCR encoding, we input it into a feedforward neural network for learning to obtain the final OCR embedding:
where
is the OCR embedding of
entityi;
and
are the learnable weights of the bias matrix of corresponding feedforward neural network;
OCR means pre-trained PaddleOCR model;
BERT is text encoder we used;
Imgi means the visual image of
entityi.
2.4. Modal Distribution Embeddings
To better understand the multi-modal information of entities and conduct more reasonable multi-modal joint modeling, we additionally embed the types of modal information and some countable attribute information of each entity by one-hot coding as
, such as the number of triples and associated relationships, and then feed it into feedforward network. The specific modeling method is as follows:
where
is the modal distribution embedding of
entityi;
and
are the learnable weights of the bias matrix of corresponding feedforward neural network.
2.5. Joint Embeddings
MEAFE then implements a weighted aggregation to integrate the multi-modal features into a multi-modal joint embedding
:
where
is the set of modal type of entity;
is a trainable attention weight for the modality of
M;
means matrix concatenate.
3. Experiment and Discussion
To verify the entity alignment effect of MEAFE and the effectiveness of the improved method proposed herein, we designed and performed experiments based on five different multi-modal entity alignment datasets, and then analyzed and discussed the experimental results.
3.1. Datasets
We adopted five multi-modal entity alignment datasets for training and evaluation, including three bilingual datasets DBP15K (ZH/JA/FR-EN) (
https://github.com/nju-websoft/JAPE, accessed on 5 May 2022) [
8] and two cross kg datasets FB15K-DB15K/YAGO15K (
https://github.com/mniepert/mmkb, accessed on 4 March 2023) [
5]. The specific statistics of the datasets are shown in
Table 2 and
Table 3. As for DBP15K, 30% aligned entity pairs are given as the training set, while for cross kg datasets, 20%, 50%, and 80% aligned entity pairs are given [
5].
3.2. Implementation Details
The hidden size of each layer of GATv2 (the embedding size of
) was 300, while the embedding size of the other modalities was 100. We used the AdamW [
20] optimizer, and set the learning rate to 5 × 10
−4. The number of training epochs was 1000 with early stopping. The batch size was 512. The hyperparameters of
were set to 80%.
For visual embedding, we used pre-processed visual features as the initial entity image features [
7,
8]. The visual features of DBP15K were pre-trained by a model that uses ResNet-152 as the backbone, and the visual features of FB15K-DB15K/YAGO15K were pre-trained by a model that uses VGG-16 [
21] as the backbone. We used ViT-B/32 as the pre-trained model of CLIP for semantic matching and image set cleaning; we used ch_PP-OCRv3_rec_infer (
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar, accessed on 9 December 2022) for OCR; and we used bert-base-multilingual-cased (
https://huggingface.co/bert-base-multilingual-cased, accessed on 20 November 2022) for OCR text encoding. Not all entities of datasets have descriptive images or can detect text information from the image, and for entities without visual information or OCR information, we treated random vectors as
and
.
When performing model training and validation with DBP15K, we only modified the graph attention network of the MEAFE due to the absence of an original entity image. However, when using FB15K-DB15K/YAGO15K, due to the large number of entities, the attention coefficient calculation of the dynamic graph puts forward high requirements on the hardware, so we only increased and . For pre-aligned entities, we treated the FB15K entity images from different sources as the original images from FB15K versus DB15K/YAGO15K, respectively.
3.3. Optimization Objective
We adopted the Intra-modal Contrastive Loss (ICL) and Inter-modal Alignment Loss (IAL) methods proposed by the MCLEA to train [
10] and enable the model to fully capture the dynamics within and between modalities while maintaining semantic proximity and minimizing modal differences [
22]. The ICL and IAL are formulated as follows:
where
and
are the mean Intra-modal Contrastive Loss (ICL) and Inter-modal Alignment Loss (IAL);
is the probability distribution of the modality of
m for positive pair
.
is the correlation probability between entities; it is calculated as shown in Equation (12), where is the encoder of the modality m, and is the hyperparameter. Additionally, and and and represent the output predictions with two directions of joint embedding and the uni-modal embedding of modality m. KL refers to the KL divergence. When calculating the ICL and IAL, is set to 0.1 and 4.0, respectively.
3.4. Evaluation Index
We used Hit@n, the Mean Reciprocal Rank (MRR), and the Mean Rank (MR) to objectively evaluate the entity alignment accuracy of the model. A larger Hit@n and MRR and a smaller MR indicate the better performance of the model.
Hit@n represents the probability that the top
n items of the candidate entity alignment possibility rank have correct results;
MRR represents the average of the reciprocal of correct ranking in the candidate alignment; and
MR represents the average correct ranking in the candidate alignment. The calculation formulas are as follows:
where
S is the total triplet set;
is the entity alignment prediction ranking of the
triplet; and
is the indicator function.
3.5. Configuration
This paper conducts experimental research based on the TensorFlow 2.0 deep learning framework; the compilation environment is Python 3.7.11; and the operating system is Ubuntu 18.04. The experimental hardware is configured with an Intel (R) (Santa Clara, CA, USA) Xeon (R) gold 6132 2.60 GHz CPU, 256 GB of memory, and an NVIDIA (Santa Clara, CA, USA) Geforce 3090 24 GB GPU.
3.6. Results and Analysis
Table 4 and
Table 5 report the performance of MEAFE on bilingual datasets DBP15K (ZH/JA/FR-EN) and cross kg datasets FB15K-DB15K/YAGO15K. MEAFE performs the best across all the datasets against other baselines.
Table 4 reports the performance of MEAFE against the supervised baselines on DBP15K. Compared to MCLEA, MEAFE achieved parity or improvement in all indicators on the DBP15K. Although the improvement is not significant due to the high completion of the model for this dataset, it still proves the adaptability of dynamic graph attention networks for entity alignment tasks, achieving improvements even when only modifying the single-layer network without adding external information.
Table 5 reports the performance of MEAFE against the other baselines on the cross kg datasets FB15K-DB15K/YAGO15K. When the training set ratio was set to 20%, MEAFE compared to the optimal baseline (MCLEA), H@1 increased by 0.172, H@10 improved by 0.112, and MRR by 0.152 on FB15K-DB15K, while H@1 increased by 0.179, H@10 improved by 0.104, and MRR by 0.154 on FB15K-YAGO15K. When the training set ratio was set to 50% and 80%, all indicators also achieved a certain improvement. Additionally, as the proportion of the training set decreased, the extent of improvement in the entity alignment effect increased. The experimental results demonstrate the effectiveness of extracting textual information that may be included in the visual modal information and adding additional embedding of entity modal distribution for multi-modal entity alignment.
We analyzed the fusion weights of various model information during multi-modal fusion, and the results are shown in
Figure 4. On two kg datasets, MEAFE tends to give higher weights to image embedding and structural embedding, which is consistent with our preliminary assumption. Our newly added OCR embedding has similar attention weights to attribute, relation, and name embedding, proving its effectiveness. The attention weight of the modal distribution embedding is lower, possibly due to its lower original embedding dimension.
3.7. Ablation Study
To verify the effectiveness of our proposed correction schemes, we designed additional ablation experiments on FB15K-DB15K/YAGO15K, and the experimental results are shown in
Table 6. Where MEAFE (none), MEAFE (only MD), and MEAFE (only OCR), respectively, refer to MEAFE models that do not add any information, only add modal distribution information, and only add OCR information.
Compared with models without any additional optimization, adding only OCR information or only MD information encouraged a certain improvement in the entity alignment effect of the model, and both were weaker than models that added both information simultaneously. Due to the richness of OCR information, the improvement is significant, while MEAFE with only MD information was lower in some indicators than MEAFE without any modifications. The possible reason for this situation is that the original features of the entity modal distribution information have a lower dimension and contain less information, making it difficult to significantly affect the entity alignment effect of the local model alone. However, when used as an additional supplement to OCR information, it still improved the model’s understanding and modeling ability for multi-modal information to a certain extent.
4. Conclusions
Aiming at the problem that most existing multi-modal entity alignment models do not effectively utilize the multi-modal information of aligned entity pairs, resulting in poor alignment performance, this paper proposes a multi-modal entity alignment method based on feature enhancement, called MEAFE. Its core idea is to maximize the use of entity visual, textual, and relational modalities to enhance the corresponding feature embedding and improve the knowledge representation ability of the model. MEAFE adopts multi-modal pre-trained models, OCR models, and GATv2 networks to enhance the information extraction ability of entity structural triplets and image descriptions, respectively, to obtain more effective multi-modal representations, and analyzing the modal distribution of entities to enhance the modeling ability and understanding of entity information.
MEAFE can more accurately align entities that refer to the same real object within the multi-modal knowledge graph from different sources, thereby removing redundant entities within the graph and integrating non overlapping attributes of aligned entity pairs. So as to further improve the knowledge richness of the graph, then improving the effectiveness of downstream tasks based on knowledge graphs.
At present, when MEAFE processes the numerical attributes and relationship information of entities (<headEntity,attributeKey,attributeValue>), it only uses bag-of-words to encode the key of numerical triplets and relationship triplets without utilizing their specific value. In our future work, we will strive to improve the model’s ability to analyze and process numerical attribute information of entities to better utilize the values of a large number of numerical relationship triplets as supervisory information for model training.







{kind=link}
{kind=link}
{kind=link}
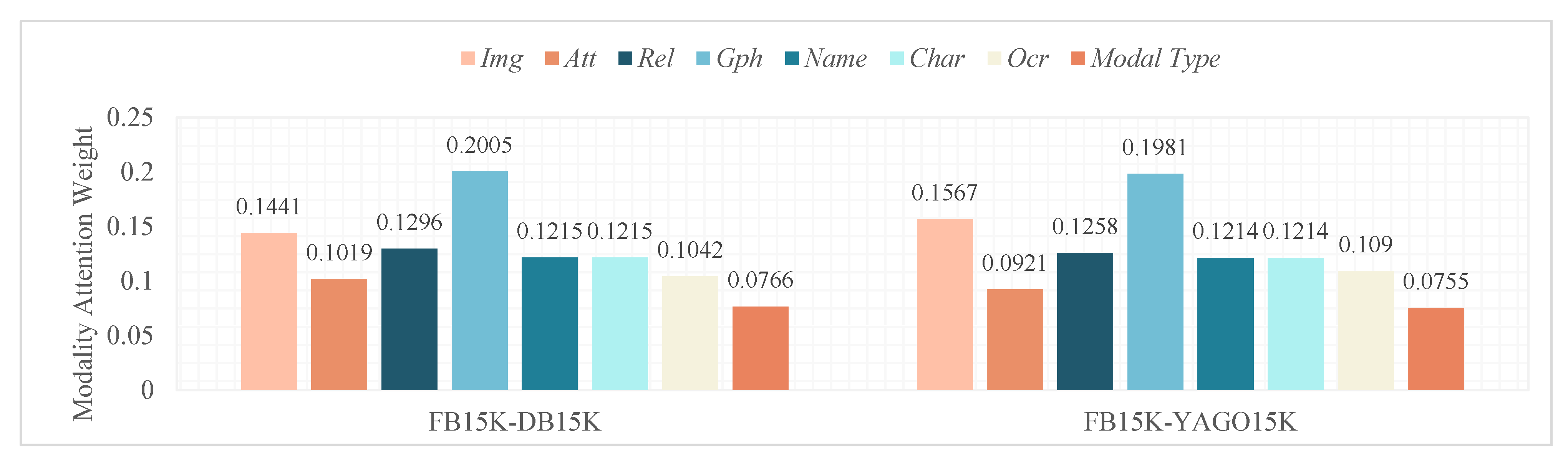{kind=link}