
Revolutionizing Small-Scale Retail: Introducing an Intelligent IoT-based Scale for Efficient Fruits and Vegetables Shops

 , and
, and
Abstract
:1. Introduction
- This article highlights the challenges faced by small-scale retail shops in Pakistan. It discusses issues such as the manual processes, limited resources, and inefficient management systems that hinder the growth and profitability of these businesses.
- A solution to the aforementioned problems is proposed in the article by suggesting the adoption of global trends such as digitalization and automation. The need for small-scale retail shops in Pakistan to leverage technology to streamline their operations, enhance efficiency, and improve customer experience is emphasized.
- A concise overview of the existing literature related to the detection and classification of fruits and vegetables is provided in the article. The techniques and algorithms utilized for achieving accurate identification and classification of different fruits and vegetables are discussed. Furthermore, the literature related to weighing systems is also explored.
- The process of collecting the necessary dataset for training the model is described in the article. How the dataset should be aligned with the scenario expected during testing or real-time implementation of the model is explained. The collection methods may include the passive capturing of images of fruits and vegetables from different angles, under varying lighting conditions, and with different orientations.
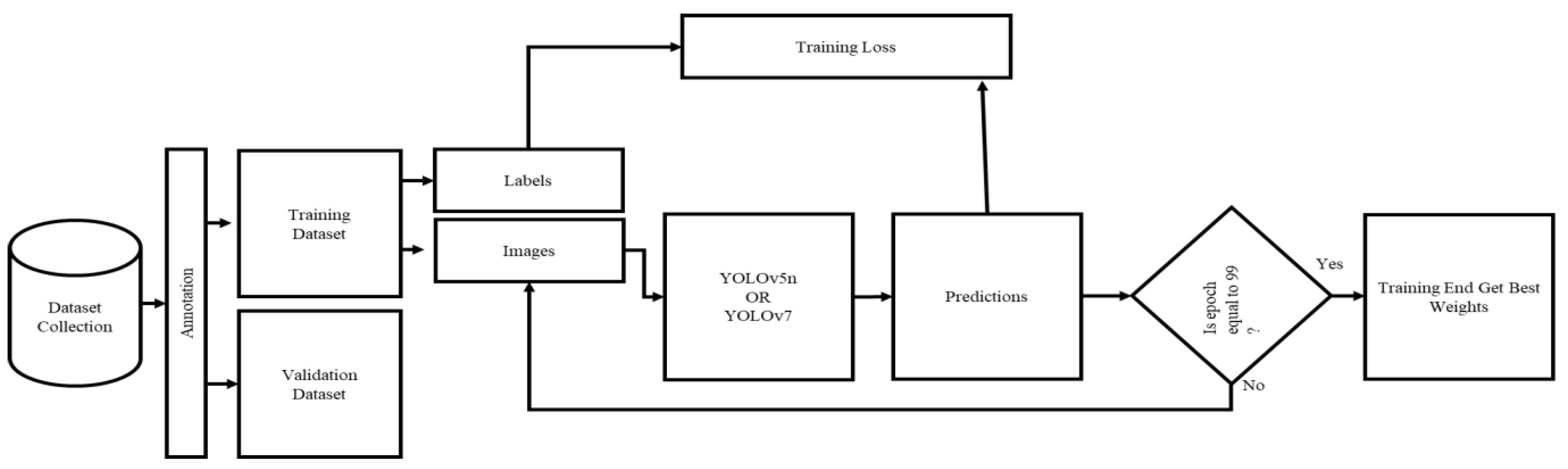
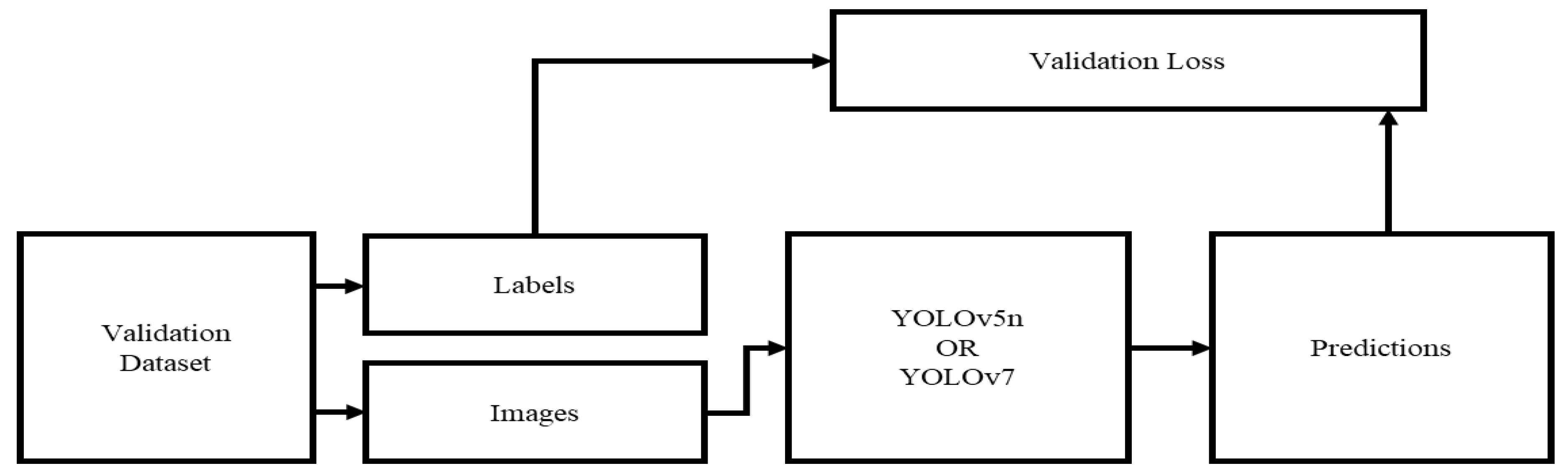
- Step-by-step instructions for training the model using the collected dataset are provided in the article. Preprocessing steps, including data annotation and splitting, are covered. Furthermore, the model validation process is explained.
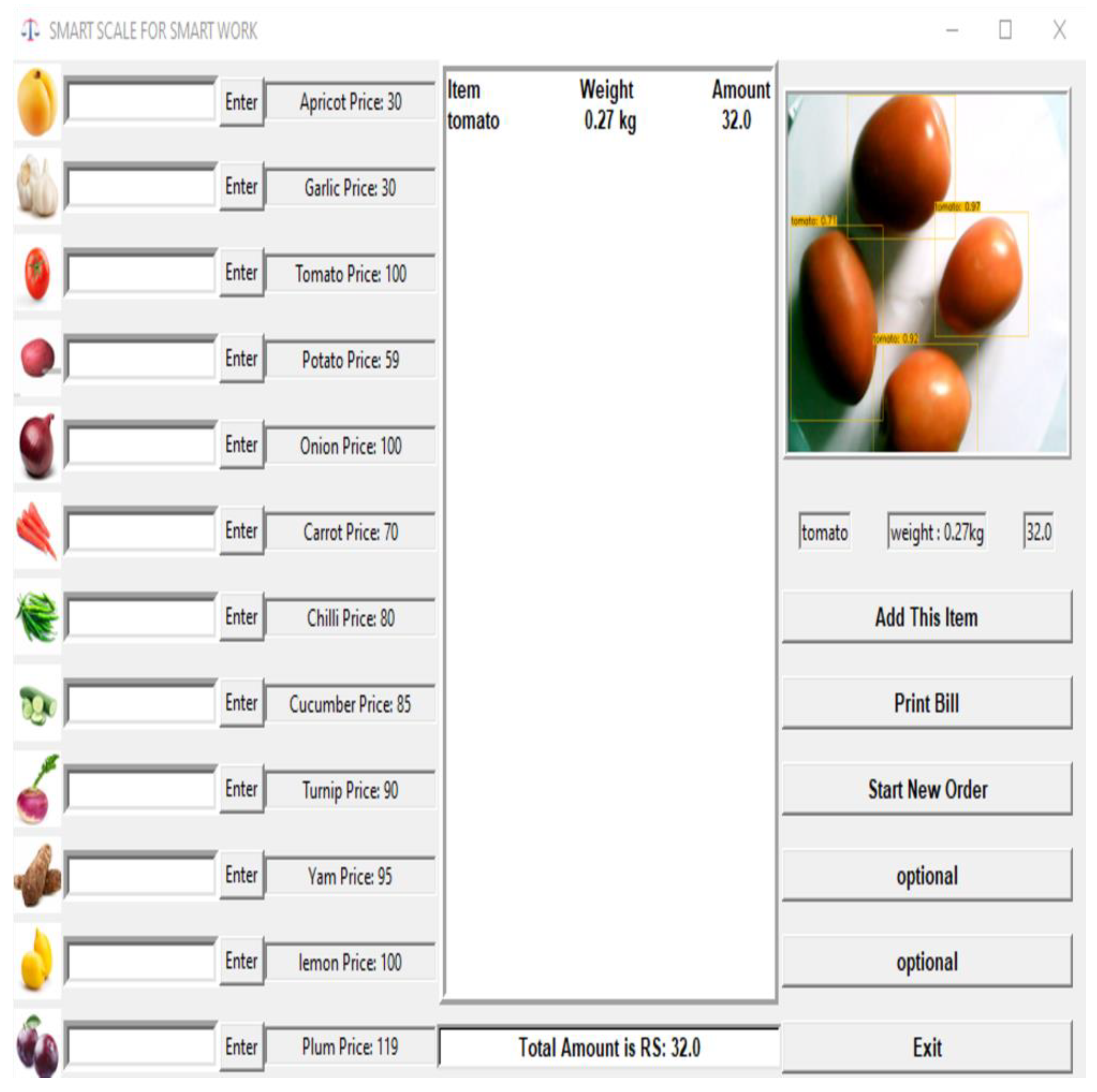
- Finally, an overview of a user-friendly graphical user interface (GUI) for the proposed prototype was provided. The GUI is designed to simplify the interaction between the users and the automated system. An intuitive interface is provided for tasks such as order initiation, prize editing, item addition, and order completion bill, aiming to enhance user experience and streamline the process.
2. Literature Review
2.1. Fruits and Vegetables Classifications
2.2. Fruits and Vegetables Detections
2.3. Weighing Scale
3. Methodology
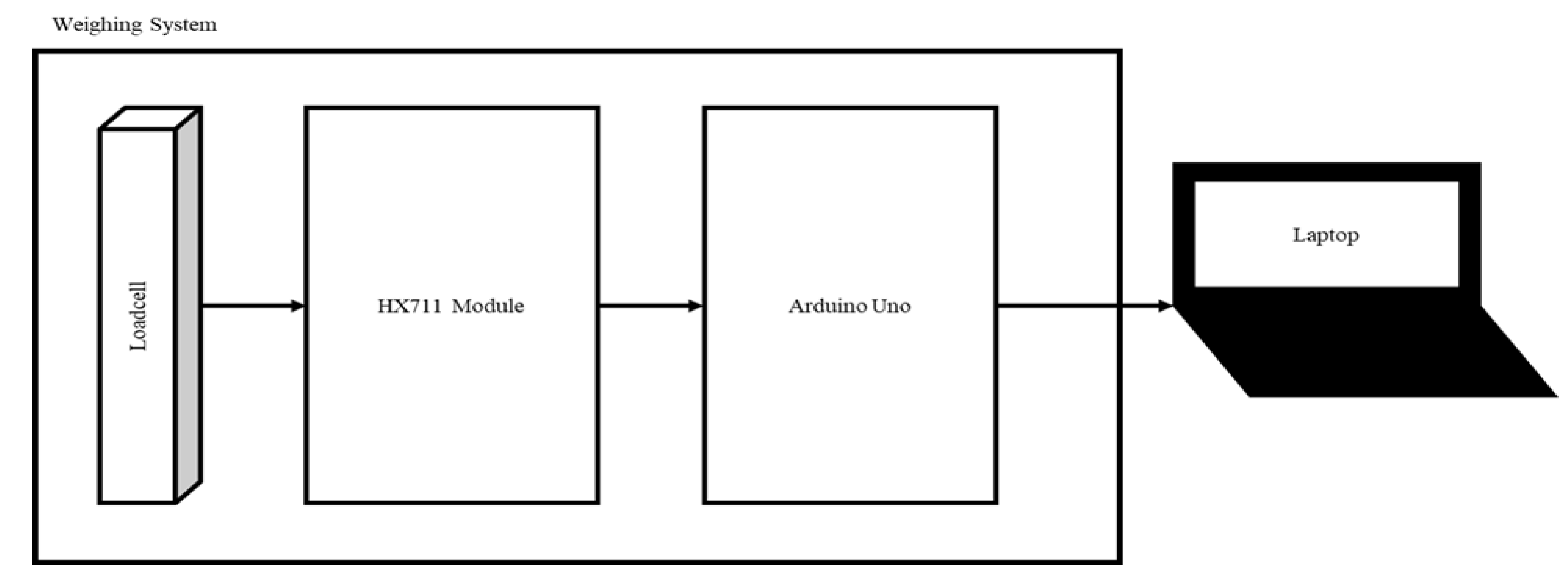
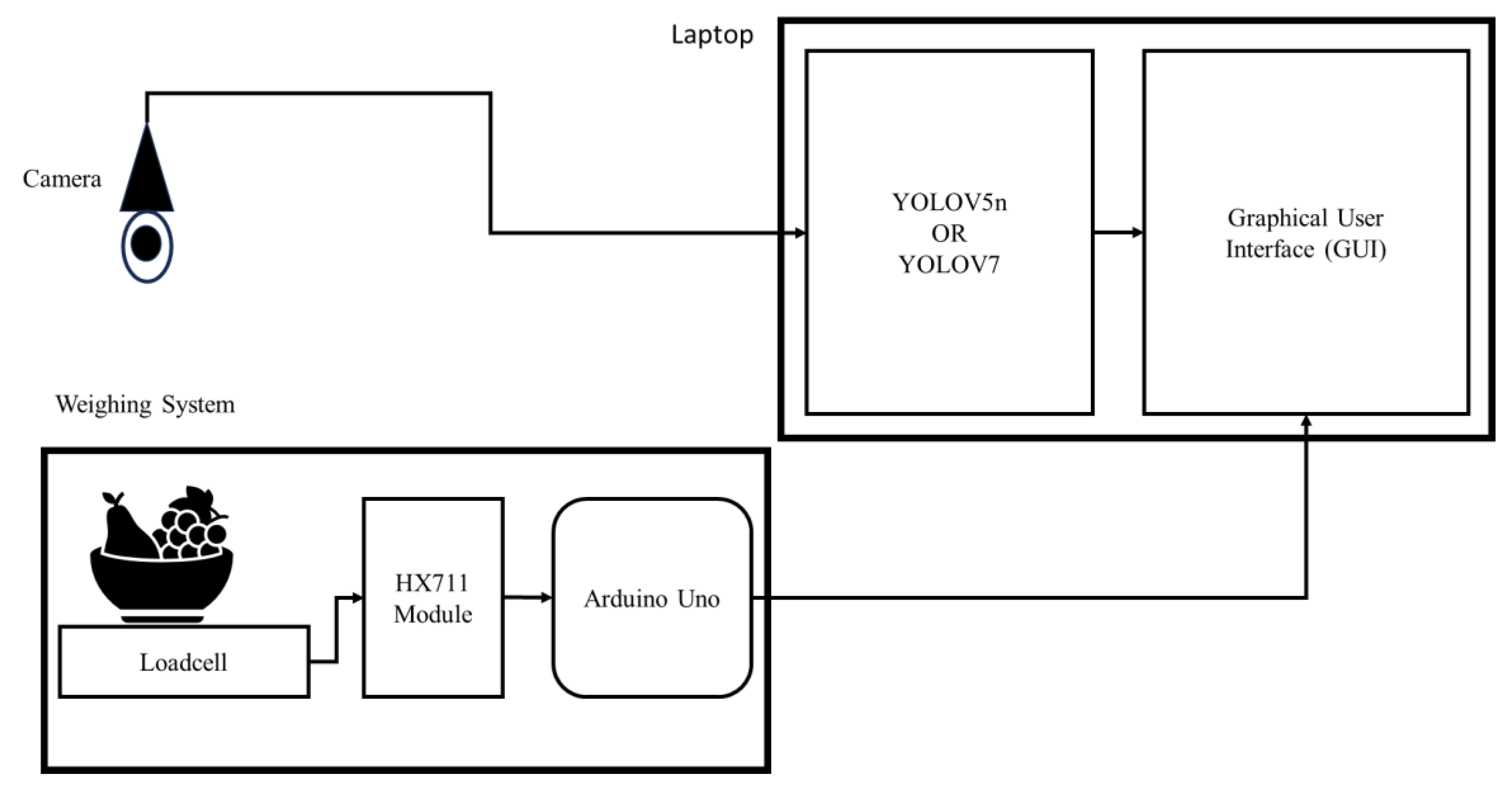
3.1. Hardware Section
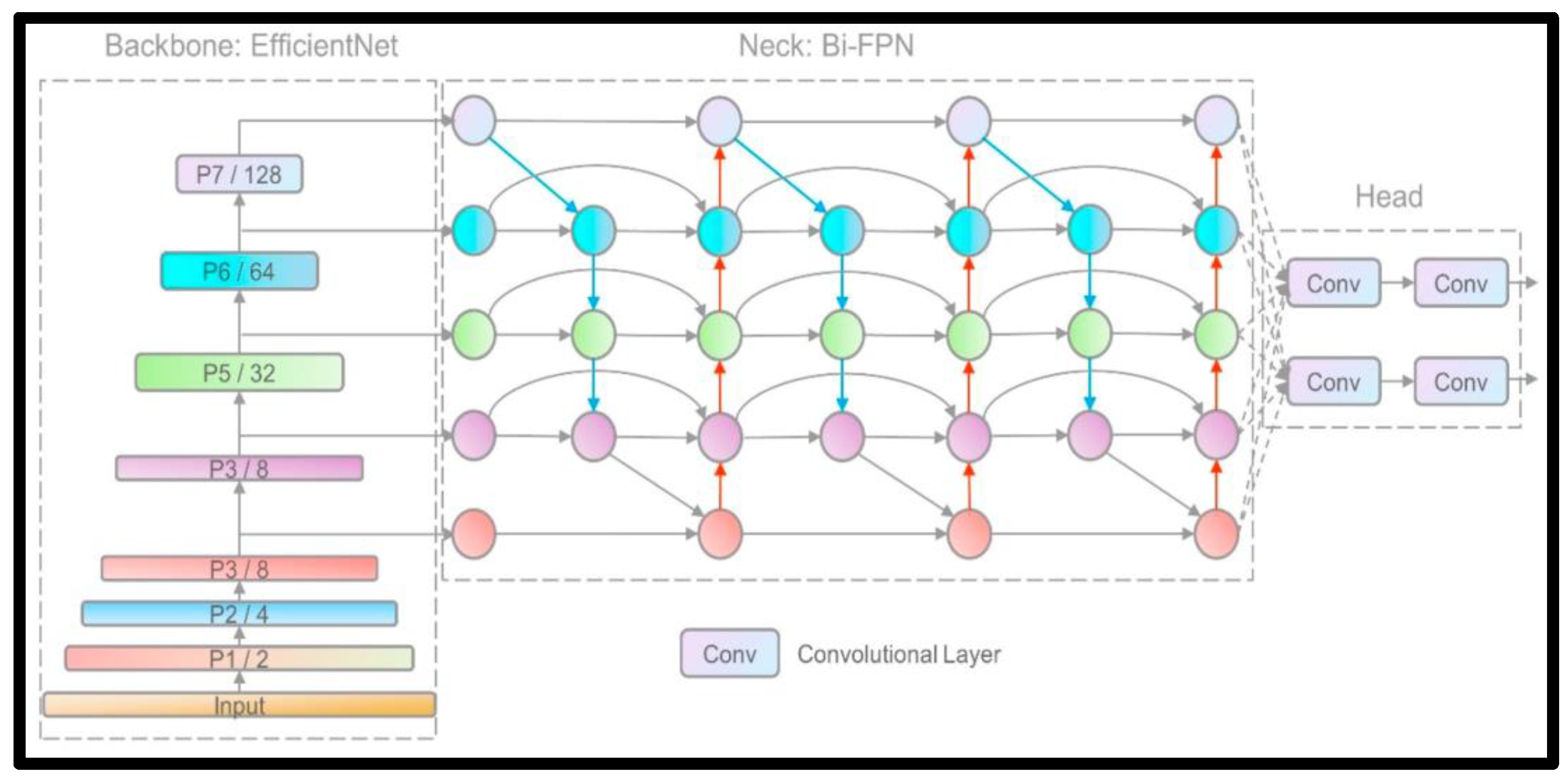
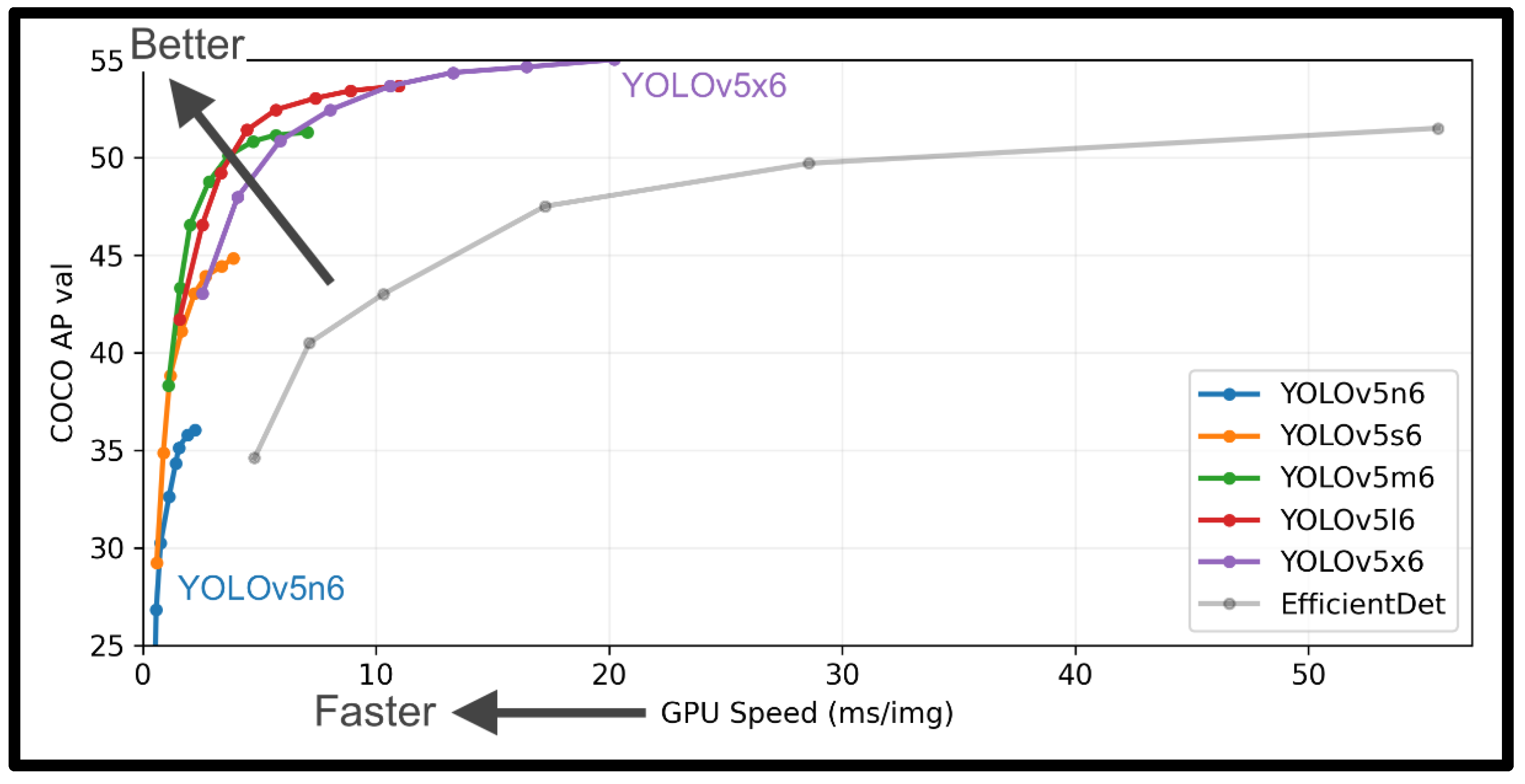
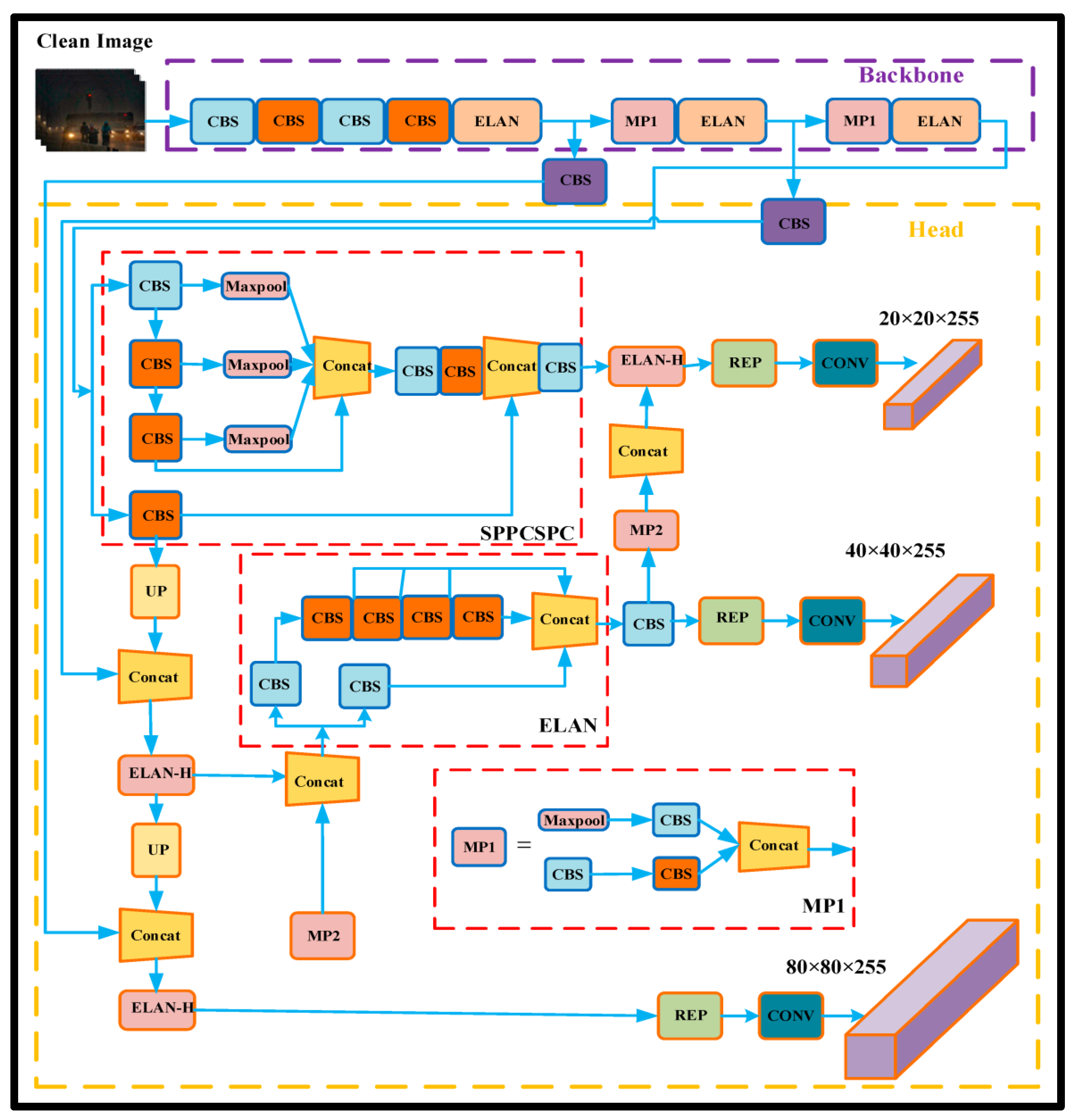
3.2. Deep Learning Model
3.3. Collection and Annotation of Dataset
3.4. Training
3.5. Graphical User Interface
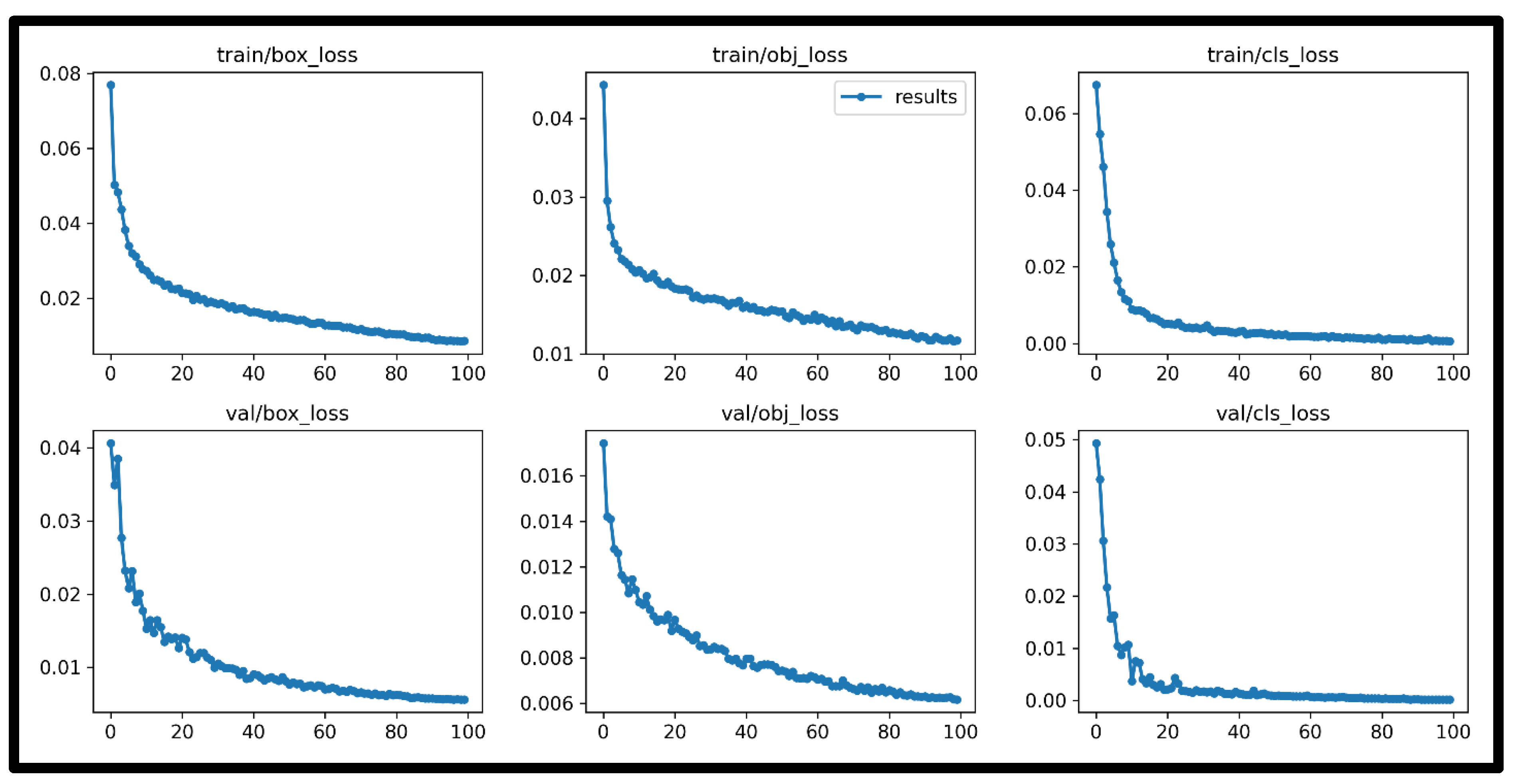
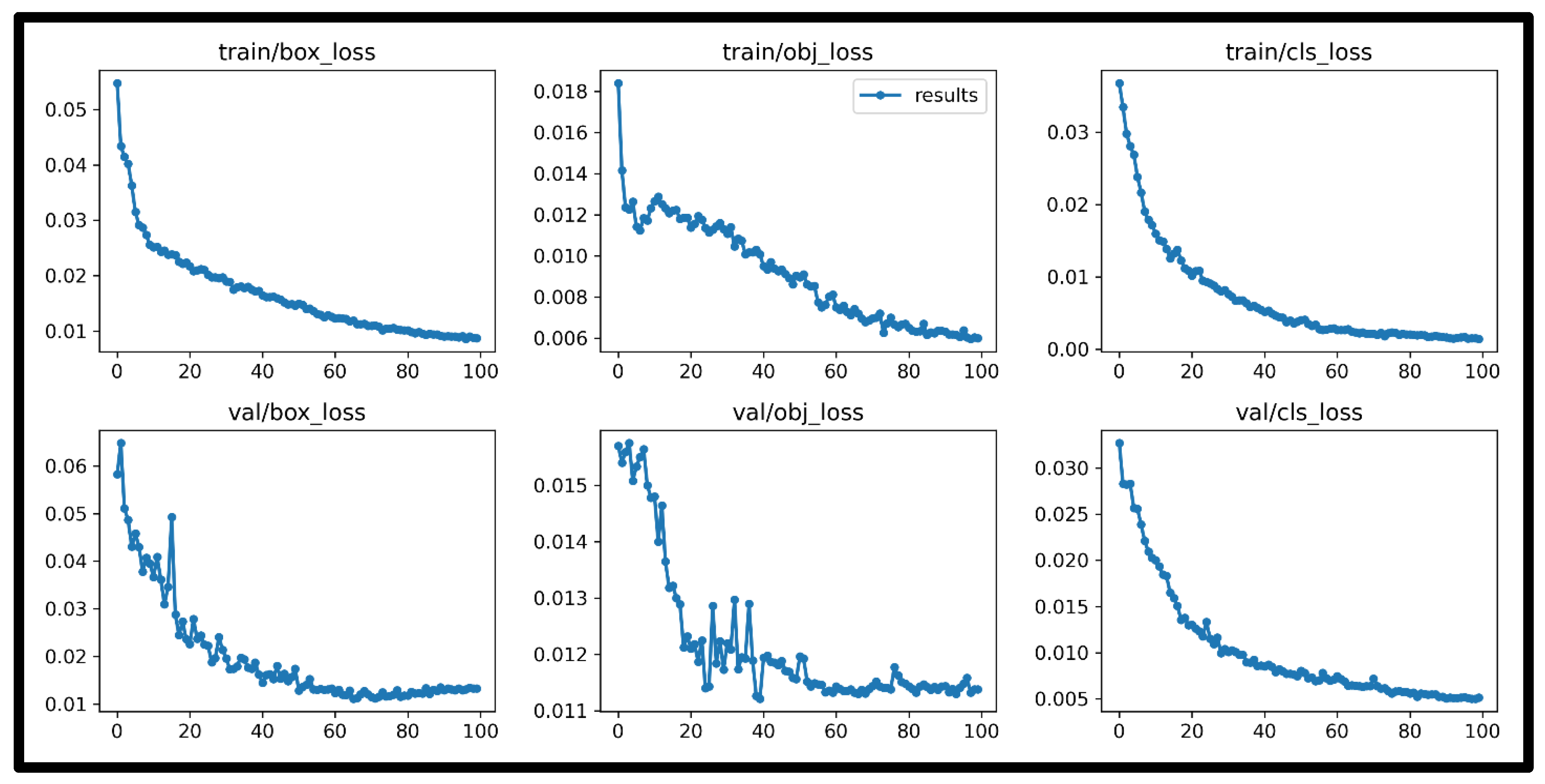
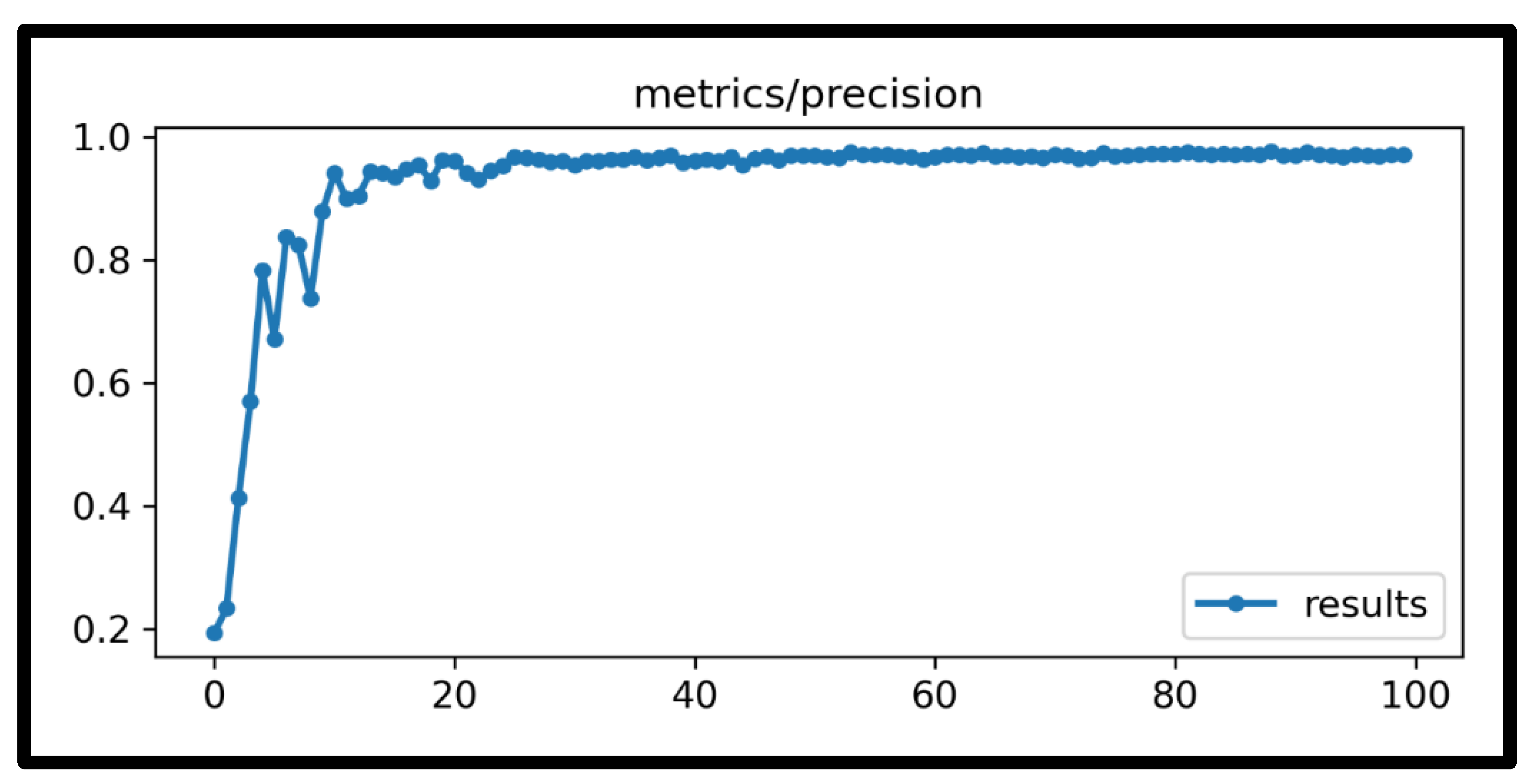
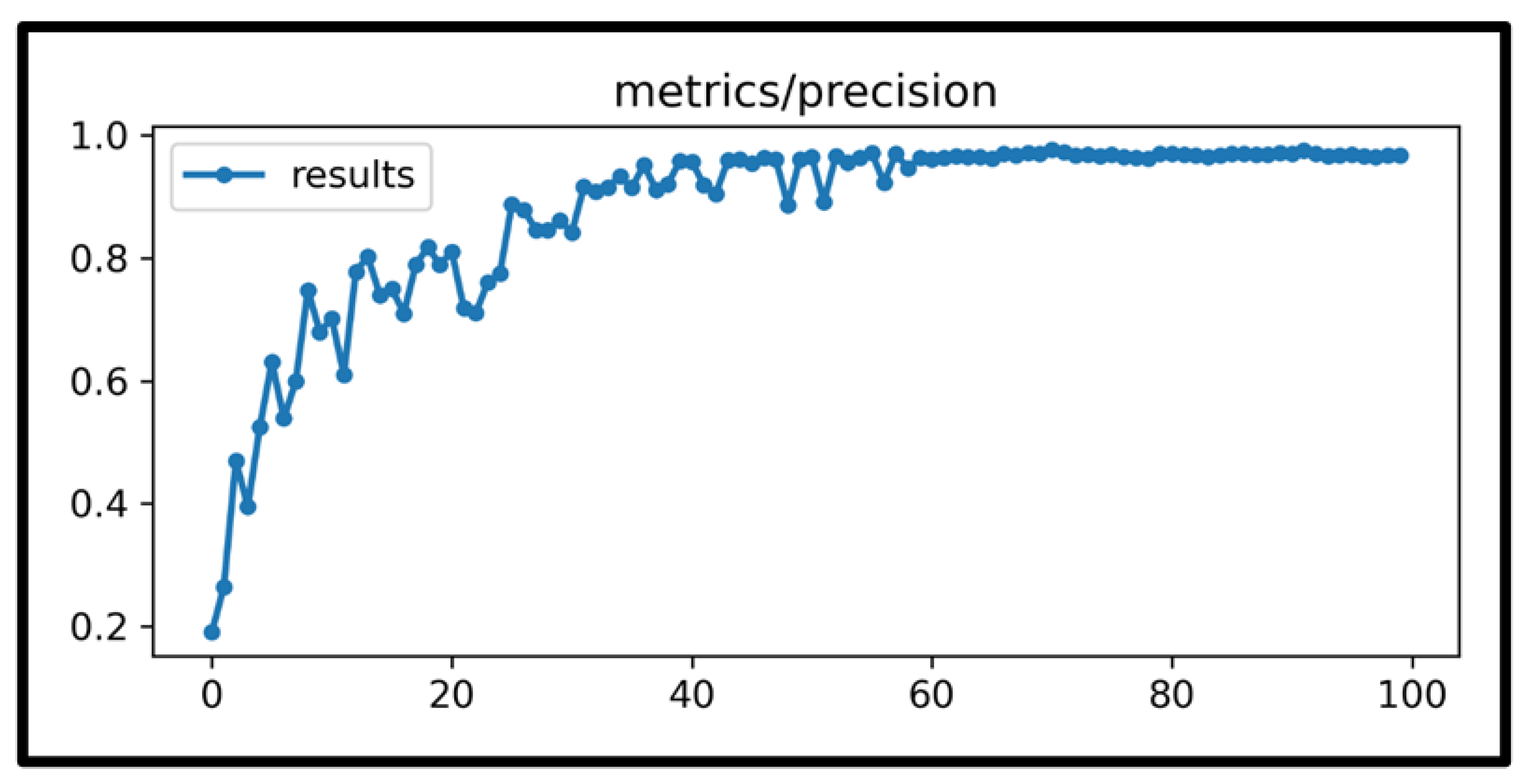
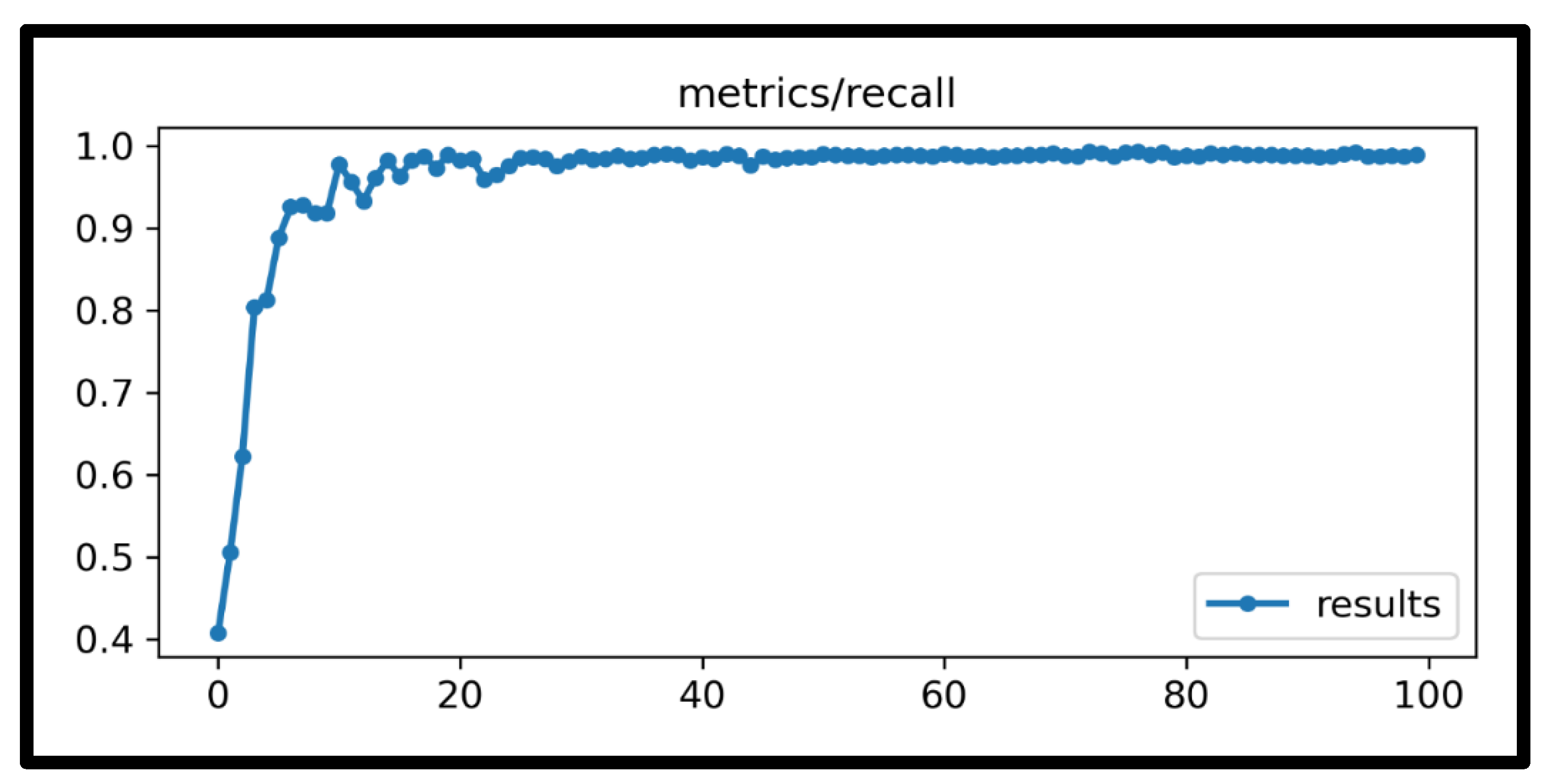
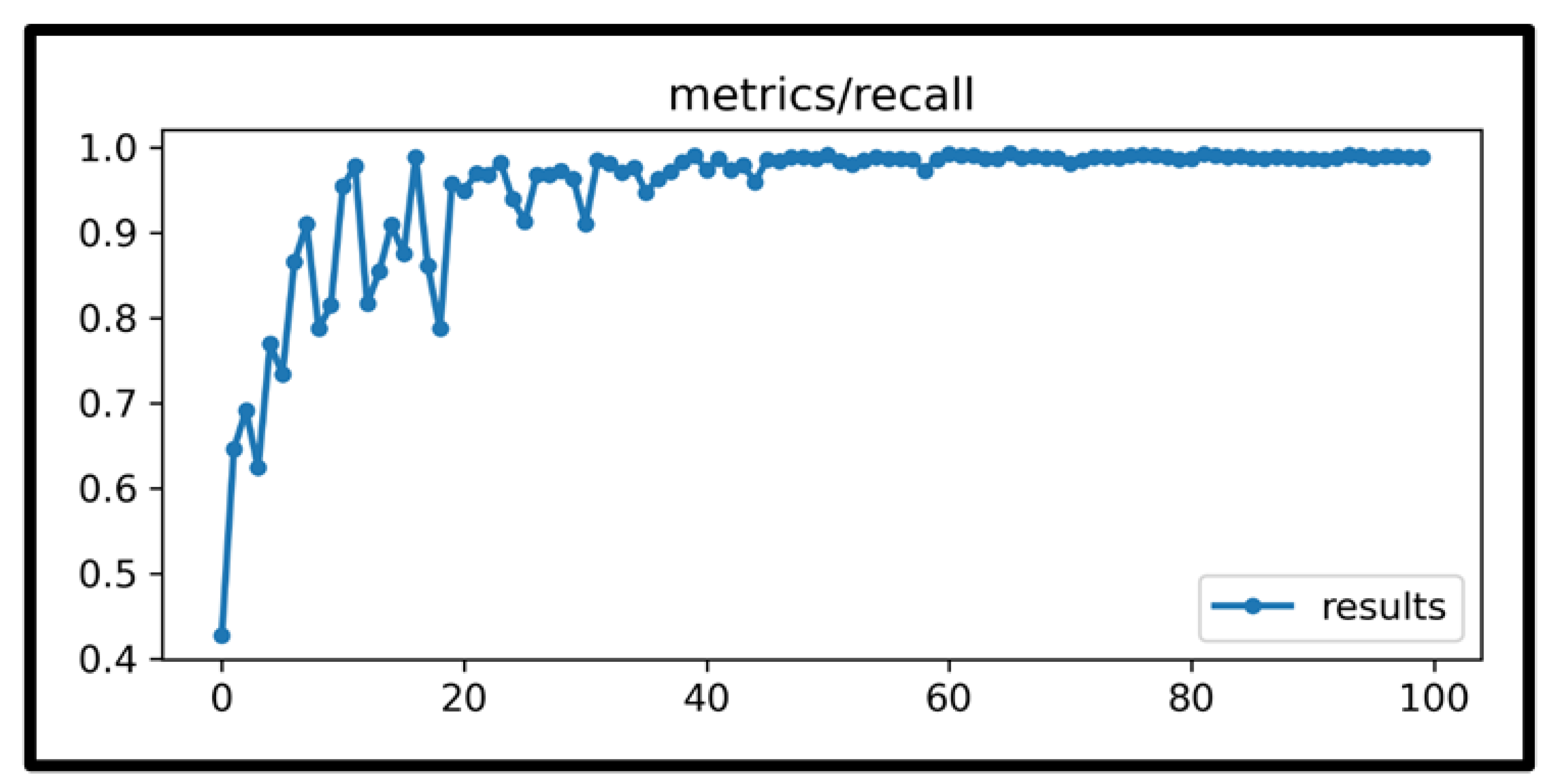
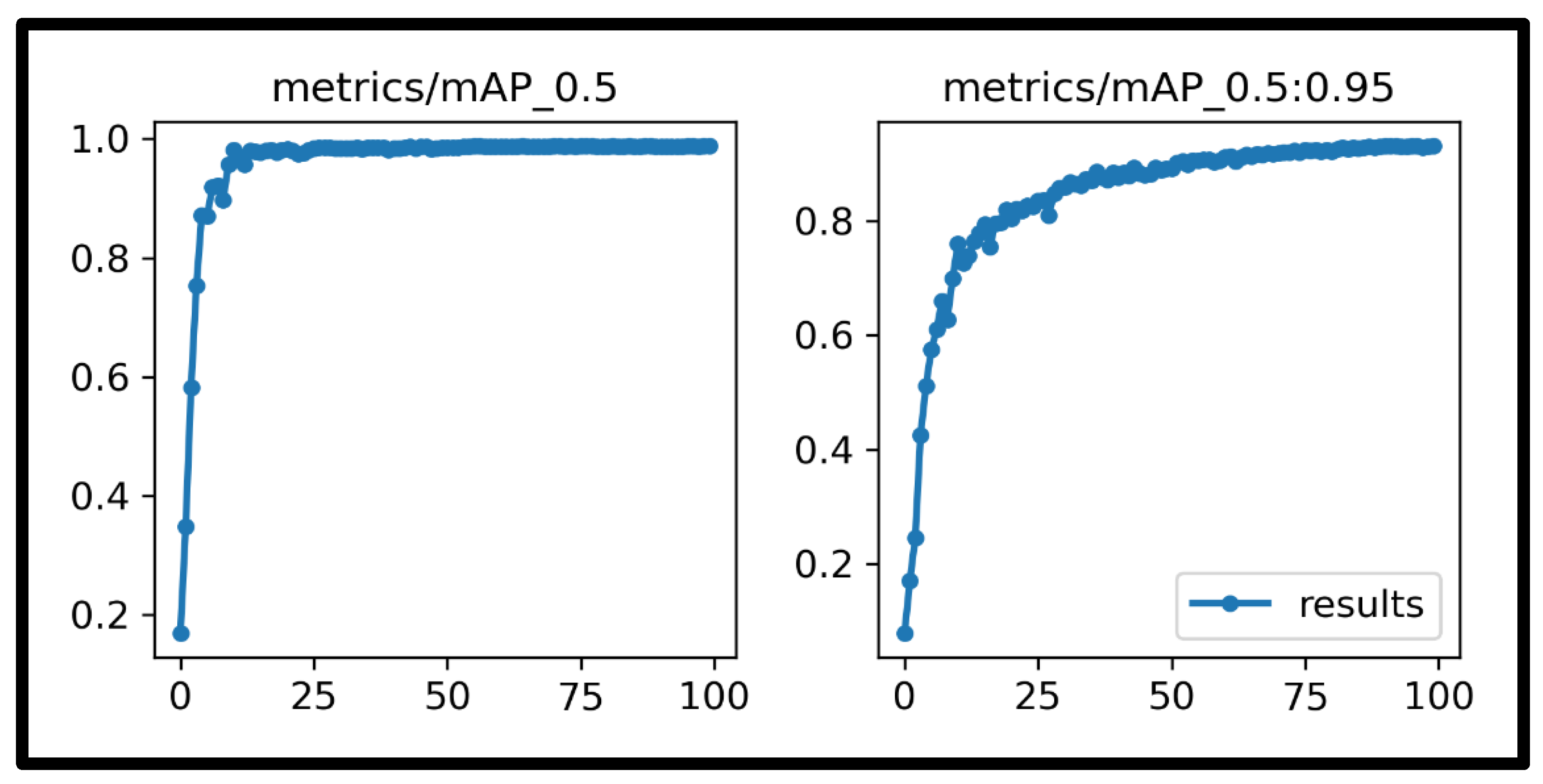
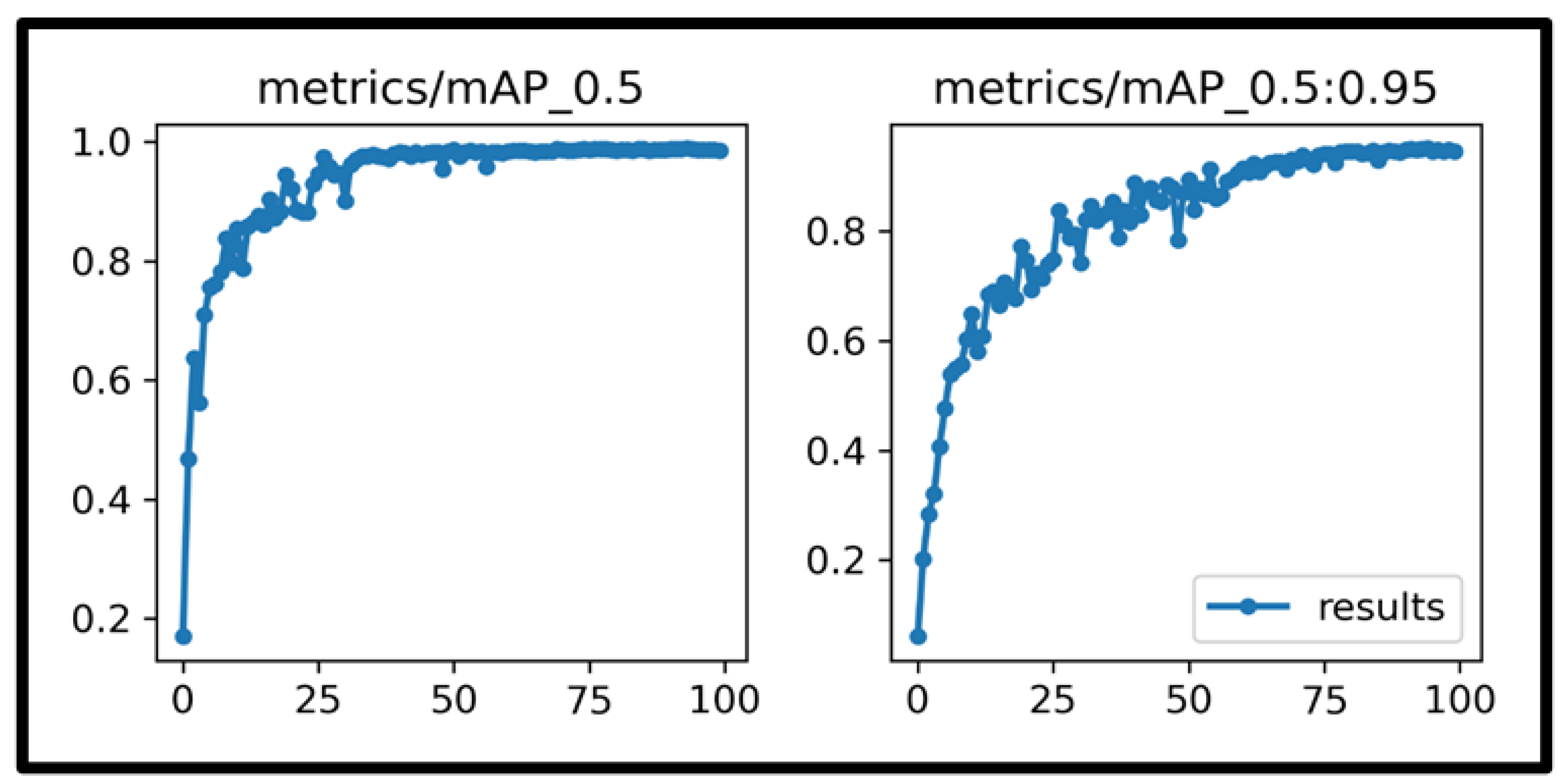
4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chaudhry, I.S.; Malik, S. The Impact of Socioeconomic and Demographic Variables on Poverty: A Village Study. Lahore J. Econ. 2009, 14, 39–68. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Murthy, C.B.; Hashmi, M.F.; Bokde, N.D.; Geem, Z.W. Investigations of object detection in images/videos using various deep learning techniques and embedded platforms—A comprehensive review. Appl. Sci. 2020, 10, 3280. [Google Scholar] [CrossRef]
- Forsyth, D. Object detection with discriminatively trained part-based models. Computer 2014, 47, 6–7. [Google Scholar] [CrossRef]
- Hayat, S.; Kun, S.; Tengtao, Z.; Yu, Y.; Tu, T.; Du, Y. A Deep Learning Framework Using Convolutional Neural Network for Multi-Class Object Recognition. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 194–198. [Google Scholar] [CrossRef]
- Derpanis, K. The Harris Corner Detector. York Univ., No. March, pp. 2–3, 2004. Available online: http://windage.googlecode.com/svn/trunk/Mindmap/Tracking/Papers/[2004] (accessed on 20 March 2023).
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. LNCS 3951—SURF: Speeded Up Robust Features. Comput. Vision–ECCV 2006, pp. 404–417. Available online: http://link.springer.com/chapter/10.1007/11744023_32 (accessed on 20 March 2023).
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Saxena, A. An Introduction to Convolutional Neural Networks. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 10, 943–947. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 8. [Google Scholar] [CrossRef]
- Ghimire, A.; Werghi, N.; Javed, S.; Dias, J. Real-Time Face Recognition System. arXiv 2022, arXiv:2204.08978. [Google Scholar]
- Rangari, A.P.; Chouthmol, A.R.; Kadadas, C.; Pal, P.; Singh, S.K. Deep Learning based smart traffic light system using Image Processing with YOLO v7. In Proceedings of the 2022 4th International Conference on Circuits, Control, Communication and Computing (I4C), Bangalore, India, 21–23 December 2022; pp. 129–132. [Google Scholar] [CrossRef]
- Sangeetha, V.; Prasad, K.J.R. Syntheses of novel derivatives of 2-acetylfuro[2,3-a]carbazoles, benzo[1,2-b]-1,4-thiazepino[2,3-a]carbazoles and 1-acetyloxycarbazole-2- carbaldehydes. Indian J. Chem. Sect. B Org. Med. Chem. 2006, 45, 1951–1954. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Unal, H.B.; Vural, E.; Savas, B.K.; Becerikli, Y. Fruit Recognition and Classification with Deep Learning Support on Embedded System (fruitnet). In Proceedings of the 2020 Innovations in Intelligent Systems and Applications Conference (ASYU), Istanbul, Turkey, 15–17 October 2020. [Google Scholar] [CrossRef]
- Sakai, Y.; Oda, T.; Ikeda, M.; Barolli, L. A vegetable category recognition system using deep neural network. In Proceedings of the 2016 10th International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS), Fukuoka, Japan, 6–8 July 2016; pp. 189–192. [Google Scholar] [CrossRef]
- Ikeda, M.; Oda, T.; Barolli, L. A vegetable category recognition system: A comparison study for caffe and Chainer DNN frameworks. Soft Comput. 2019, 23, 3129–3136. [Google Scholar] [CrossRef]
- Ahmed, M.I.; Mahmud Mamun, S.; Zaman Asif, A.U. DCNN-Based Vegetable Image Classification Using Transfer Learning: A Comparative Study. In Proceedings of the 2021 5th International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 24–25 May 2021; pp. 235–243. [Google Scholar] [CrossRef]
- Gulzar, Y. Fruit Image Classification Model Based on MobileNetV2 with Deep Transfer Learning Technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Albarrak, K.; Gulzar, Y.; Hamid, Y.; Mehmood, A.; Soomro, A.B. A Deep Learning-Based Model for Date Fruit Classification. Sustainability 2022, 14, 6339. [Google Scholar] [CrossRef]
- Ragesh, N.; Giridhar, B.; Lingeshwaran, D.; Siddharth, P.; Peeyush, K.P. Deep learning based automated billing cart. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 779–782. [Google Scholar] [CrossRef]
- Sachin, C.; Manasa, N.; Sharma, V.; Kumaar, N.A.A. Vegetable Classification Using You Only Look Once Algorithm. In Proceedings of the 2019 International Conference on Cutting-Edge Technologies in Engineering (ICon-CuTE), Uttar Pradesh, India, 14–16 November 2019; pp. 101–107. [Google Scholar] [CrossRef]
- Latha, R.; Sreekanth, G.; Rajadevi, R.; Nivetha, S.; Kumar, K.; Akash, V.; Bhuvanesh, S.; Anbarasu, P. Fruits and Vegetables Recognition using YOLO. In Proceedings of the 2022 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 25–27 January 2022; pp. 2–7. [Google Scholar] [CrossRef]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2019, 168, 107036. [Google Scholar] [CrossRef]
- Šumarac, J.; Kljajić, J.; Rodić, A. A Fruit Detection Algorithm for a Plum Harvesting Robot Based on Improved YOLOv7. In International Conference on Robotics in Alpe-Adria Danube Region 2023 May 27; Springer Nature: Cham, Switzerland, 2023; pp. 442–450. [Google Scholar] [CrossRef]
- Tang, Y.; Zhou, H.; Wang, H.; Zhang, Y. Fruit detection and positioning technology for a Camellia oleifera C. Abel orchard based on improved YOLOv4-tiny model and binocular stereo vision. Expert Syst. Appl. 2023, 211, 118573. [Google Scholar] [CrossRef]
- Chidella, N.; Reddy, N.K.; Reddy, N.S.D.; Mohan, M.; Sengupta, J. Intelligent Billing system using Object Detection. In Proceedings of the 2022 1st International Conference on the Paradigm Shifts in Communication, Embedded Systems, Machine Learning and Signal Processing (PCEMS), Nagpur, India, 6–7 May 2022; pp. 11–15. [Google Scholar] [CrossRef]
- Wang, B.; Xie, Y.; Duan, X. An IoT Based Fruit and Vegetable Sales System. In Proceedings of the 2021 5th International Conference on Cloud and Big Data Computing (ICCBDC), Liverpool, UK, 13–15 August 2021; pp. 109–115. [Google Scholar] [CrossRef]
- Nandanwar, V.G.; Kashif, M.; Ankushe, R.S. Portable Weight Measuring Instrument. In Proceedings of the 2017 International Conference on Recent Trends in Electrical, Electronics and Computing Technologies (ICRTEECT), Warangal, India, 30–31 July 2017; pp. 44–48. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. PANet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9196–9205. [Google Scholar] [CrossRef] [Green Version]
- Zhai, N. Detection using Yolov5n and Yolov5s with small balls. Comput. Sci. 2022, 12168, 428–432. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Available online: https://github.com/ultralytics/yolov5/releases (accessed on 20 March 2023).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Qiu, Y.; Lu, Y.; Wang, Y.; Jiang, H. IDOD-YOLOV7: Image-Dehazing YOLOV7 for Object Detection in Low-Light Foggy Traffic Environments. Sensors 2023, 23, 1347. [Google Scholar] [CrossRef] [PubMed]
- Hussain, M.; Al-Aqrabi, H.; Munawar, M.; Hill, R.; Alsboui, T. Domain Feature Mapping with YOLOv7 for Automated Edge-Based Pallet Racking Inspections. Sensors 2022, 22, 6927. [Google Scholar] [CrossRef] [PubMed]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Class Name | Number of Images | Number of instances |
|---|---|---|---|
| 1 | Potato | 368 | 882 |
| 2 | Tomato | 338 | 1027 |
| 3 | Onion | 250 | 868 |
| 4 | Turnip | 246 | 635 |
| 5 | Chili | 314 | 885 |
| 6 | Garlic | 148 | 710 |
| 7 | Carrot | 181 | 301 |
| 8 | Cucumber | 310 | 467 |
| 9 | Apricot | 155 | 823 |
| 10 | Yam | 126 | 731 |
| 11 | Lemon | 68 | 826 |
| 12 | Plum | 118 | 947 |
| Class | Images | Instances | Precision | Recall | F1 Score | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|
| All | 525 | 1818 | 0.972 | 0.988 | 0.979 | 0.988 | 0.932 |
| Potato | 525 | 130 | 0.973 | 1 | 0.986 | 0.992 | 0.983 |
| Tomato | 525 | 254 | 0.964 | 0.984 | 0.973 | 0.992 | 0.988 |
| Onion | 525 | 151 | 0.977 | 1 | 0.988 | 0.995 | 0.973 |
| Turnip | 525 | 126 | 0.947 | 0.986 | 0.966 | 0.988 | 0.942 |
| Chili | 525 | 192 | 0.897 | 0.891 | 0.893 | 0.945 | 0.691 |
| Garlic | 525 | 155 | 0.975 | 1 | 0.987 | 0.991 | 0.921 |
| Carrot | 525 | 66 | 0.967 | 1 | 0.983 | 0.98 | 0.821 |
| Cucumber | 525 | 106 | 0.984 | 1 | 0.991 | 0.993 | 0.935 |
| Apricot | 525 | 171 | 0.998 | 1 | 0.998 | 0.995 | 0.995 |
| Yam | 525 | 136 | 0.997 | 1 | 0.998 | 0.995 | 0.946 |
| Lemon | 525 | 203 | 0.997 | 1 | 0.998 | 0.995 | 0.995 |
| Plum | 525 | 128 | 0.989 | 1 | 0.994 | 0.995 | 0.991 |
| Class | Images | Instances | Precision | Recall | F1 Score | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|
| All | 525 | 1818 | 0.972 | 0.986 | 0.978 | 0.987 | 0.951 |
| Potato | 525 | 130 | 0.974 | 1 | 0.986 | 0.991 | 0.989 |
| Tomato | 525 | 254 | 0.951 | 1 | 0.974 | 0.993 | 0.988 |
| Onion | 525 | 151 | 0.998 | 1 | 0.998 | 0.995 | 0.984 |
| Turnip | 525 | 126 | 0.952 | 0.984 | 0.967 | 0.988 | 0.919 |
| Chili | 525 | 192 | 0.921 | 0.854 | 0.886 | 0.929 | 0.741 |
| Garlic | 525 | 155 | 0.975 | 0.998 | 0.986 | 0.994 | 0.923 |
| Carrot | 525 | 66 | 0.949 | 1 | 0.97 | 0.984 | 0.948 |
| Cucumber | 525 | 106 | 0.966 | 1 | 0.982 | 0.992 | 0.977 |
| Apricot | 525 | 171 | 0.996 | 1 | 0.997 | 0.995 | 0.995 |
| Yam | 525 | 136 | 0.999 | 1 | 0.999 | 0.995 | 0.962 |
| Lemon | 525 | 203 | 0.994 | 1 | 0.996 | 0.996 | 0.994 |
| Plum | 525 | 128 | 0.99 | 1 | 0.994 | 0.995 | 0.995 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zargham, A.; Haq, I.U.; Alshloul, T.; Riaz, S.; Husnain, G.; Assam, M.; Ghadi, Y.Y.; Mohamed, H.G. Revolutionizing Small-Scale Retail: Introducing an Intelligent IoT-based Scale for Efficient Fruits and Vegetables Shops. Appl. Sci. 2023, 13, 8092. https://doi.org/10.3390/app13148092
Zargham A, Haq IU, Alshloul T, Riaz S, Husnain G, Assam M, Ghadi YY, Mohamed HG. Revolutionizing Small-Scale Retail: Introducing an Intelligent IoT-based Scale for Efficient Fruits and Vegetables Shops. Applied Sciences. 2023; 13(14):8092. https://doi.org/10.3390/app13148092
Chicago/Turabian StyleZargham, Abdullah, Ihtisham Ul Haq, Tamara Alshloul, Samad Riaz, Ghassan Husnain, Muhammad Assam, Yazeed Yasin Ghadi, and Heba G. Mohamed. 2023. "Revolutionizing Small-Scale Retail: Introducing an Intelligent IoT-based Scale for Efficient Fruits and Vegetables Shops" Applied Sciences 13, no. 14: 8092. https://doi.org/10.3390/app13148092
APA StyleZargham, A., Haq, I. U., Alshloul, T., Riaz, S., Husnain, G., Assam, M., Ghadi, Y. Y., & Mohamed, H. G. (2023). Revolutionizing Small-Scale Retail: Introducing an Intelligent IoT-based Scale for Efficient Fruits and Vegetables Shops. Applied Sciences, 13(14), 8092. https://doi.org/10.3390/app13148092