


Sparse Subgraph Prediction Based on Adaptive Attention

Abstract
:1. Introduction
- (1)
- First of all, the SSP-AA model incorporates an adaptive attention mechanism to enhance its ability to handle graph-structured data. This approach addresses the limitations of the existing model, specifically in terms of adaptive weight allocation when aggregating neighbor node features;
- (2)
- Moreover, integrating a jumping knowledge module addresses the over-smoothing problem that frequently occurs with increasing depth in GNNs. The jumping knowledge module allows the model to flexibly select and combine features across different layers, enhancing the expressive power of node representations;
- (3)
- Finally, utilizing sparse subgraphs helps to decrease the complexity of the graph structure, retaining crucial node information in the graph while reducing computational overhead in prediction tasks and classification tasks involving large-scale graph-structured data.
2. Related Work
2.1. Graph Neural Network
2.2. Link Prediction Method
2.3. Sparse Subgraph Generation Method
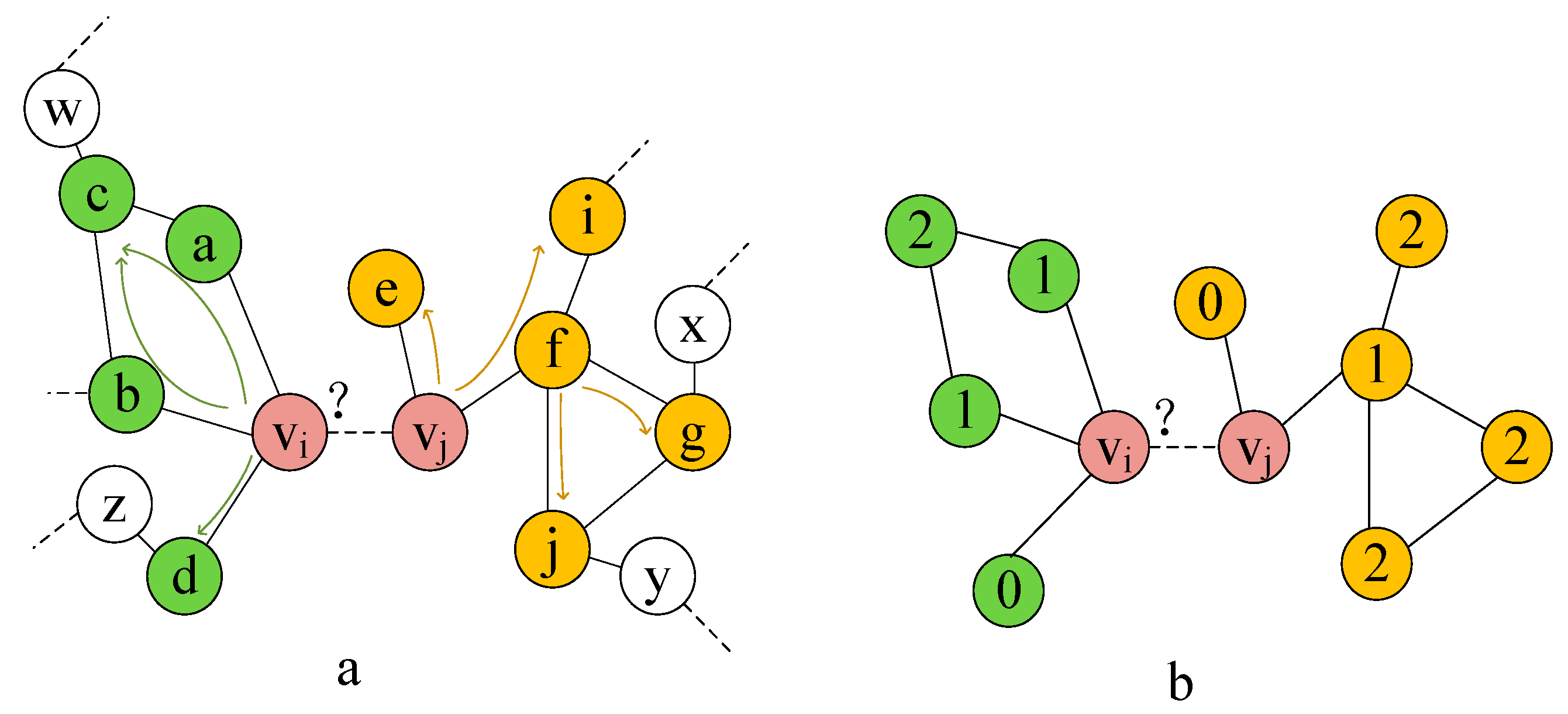
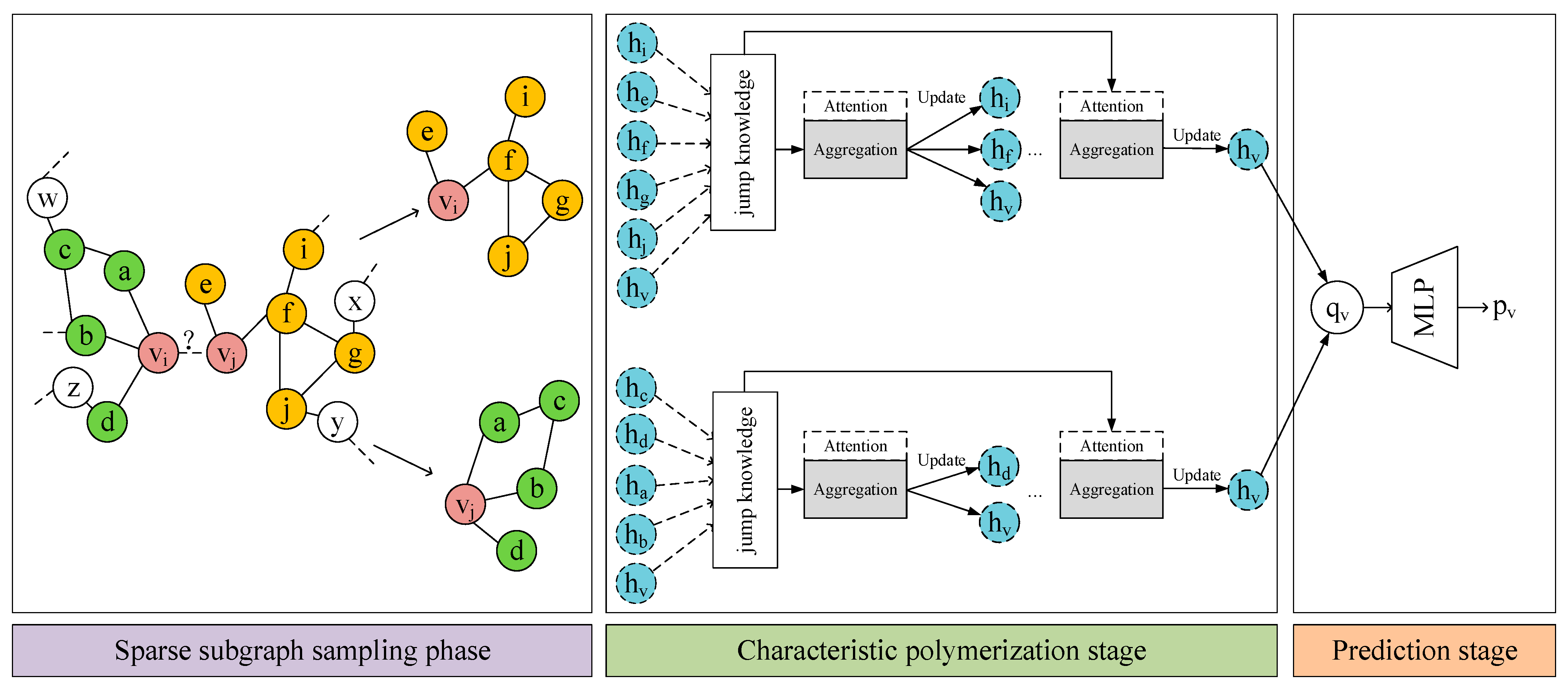
3. The Proposed SSP-AA Model
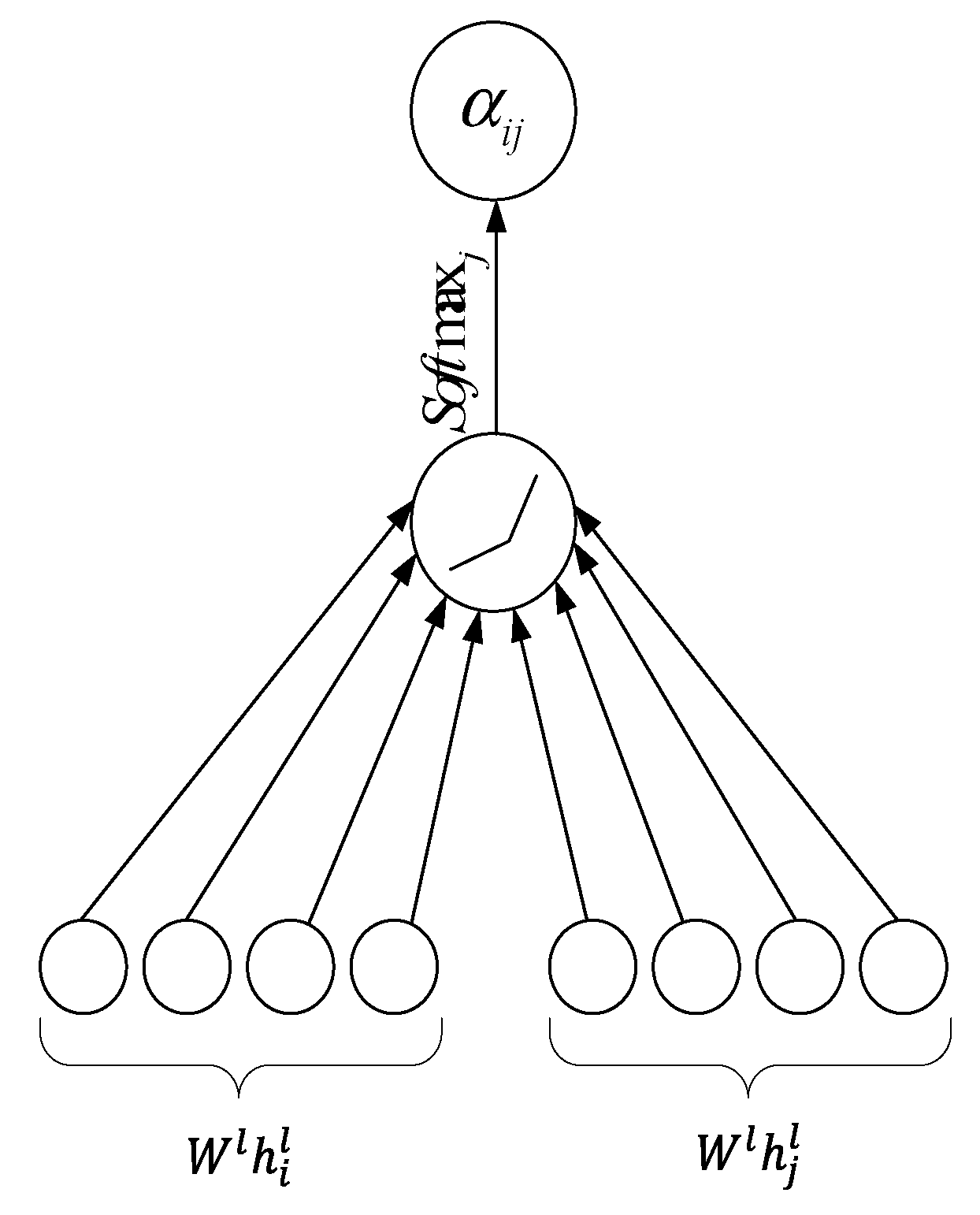
3.1. Adaptive Attention Mechanism
- (1)
- Calculation of the attention mechanism
- (2)
- Normalization of the attention weight
- (3)
- Aggregating Neighbor Node Information
- (4)
- Integrate the attention mechanism into the SSP-AA model
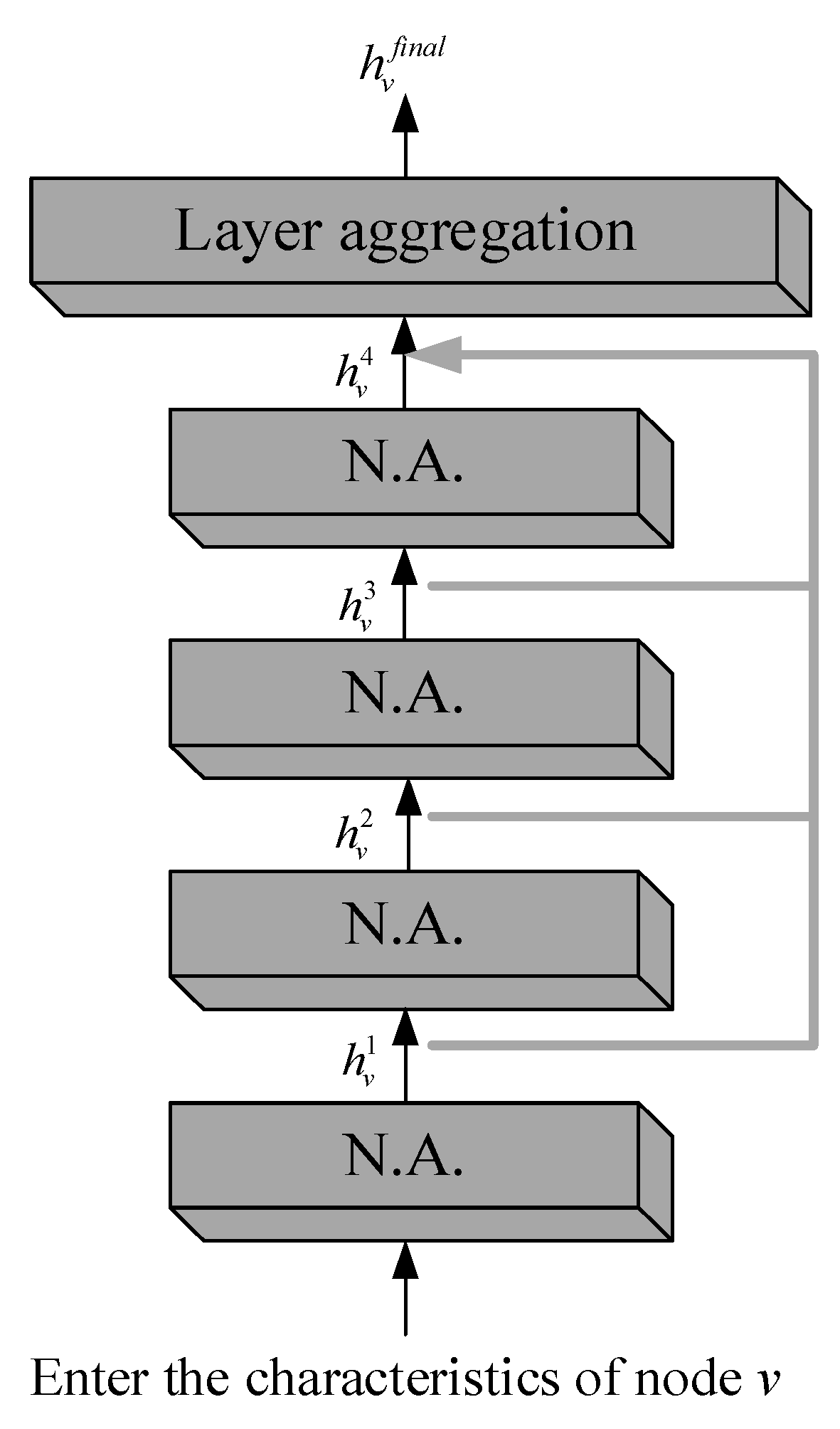
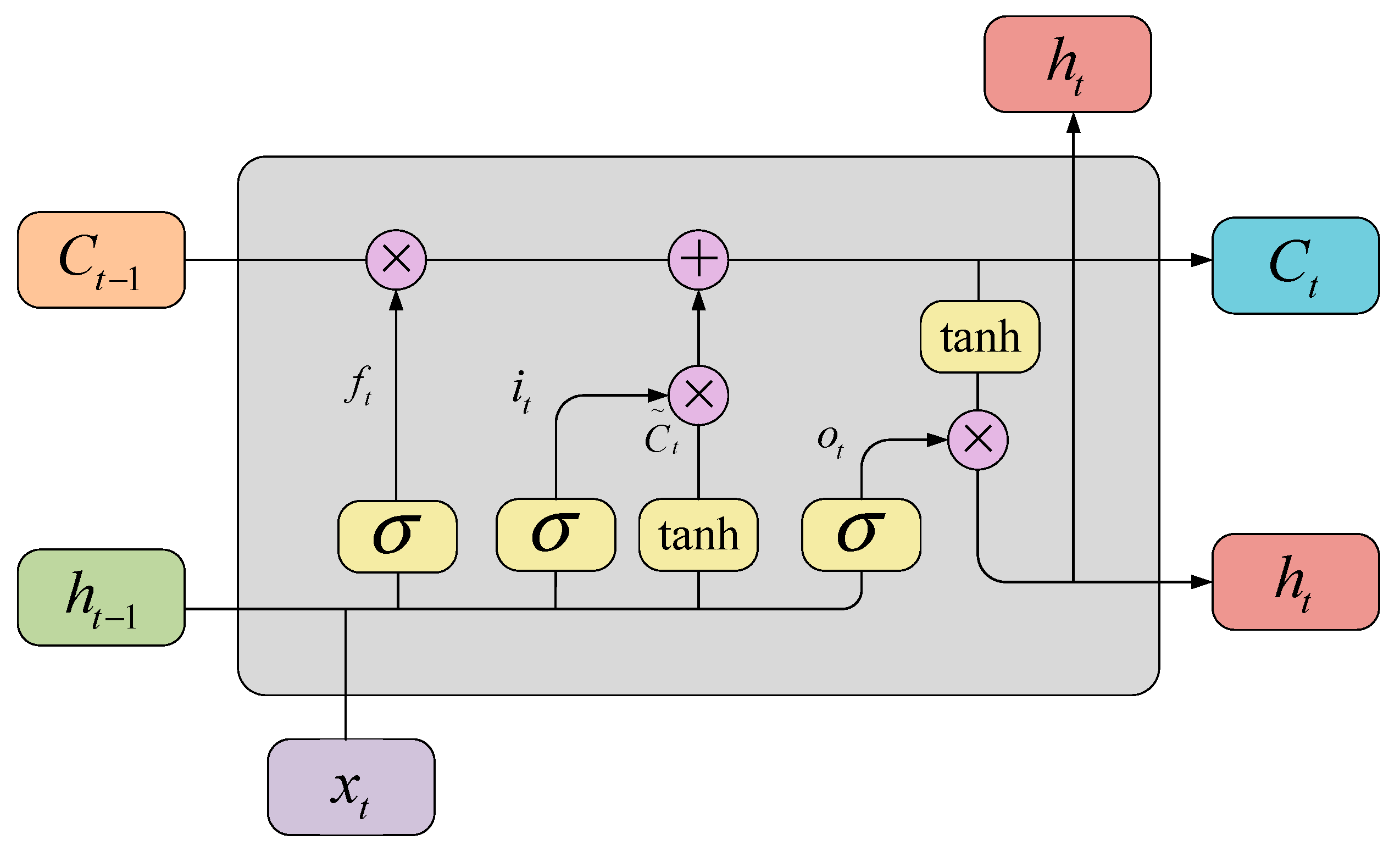
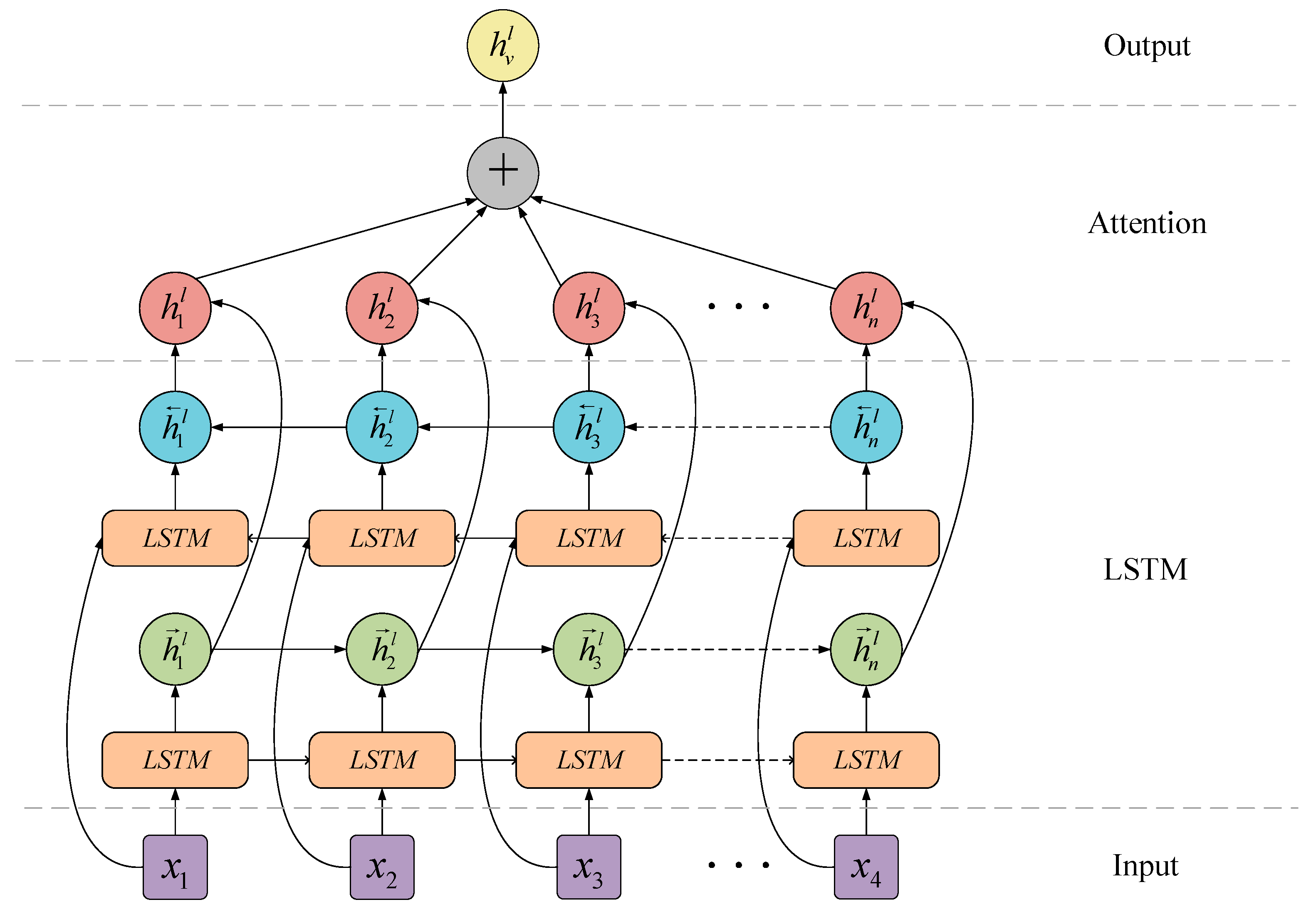
3.2. Jump Knowledge Module
- (1)
- Long Short-Term Memory (LSTM) of the polymerization method
- (2)
- Attention-based aggregation method
3.3. Framework of the Model
4. Experiment
4.1. Dataset
- USAir: A dataset that describes the flight route map of US airlines. Nodes represent airports, and edges represent direct connections between flights;
- Celegans: A dataset that describes the nervous system of Caenorhabditis elegans. Nodes represent neurons, and edges represent synaptic connections between neurons;
- NS: A dataset that describes a large-scale scientific collaboration network. Nodes represent scientists, and edges represent collaborative relationships between scientists (co-authored papers);
- Power: A dataset that describes the power system in the Western United States. Nodes represent power plants and substations, and edges represent transmission lines;
- Yeast: A dataset that describes the yeast protein interaction network. Nodes represent yeast proteins, and edges represent interactions between proteins;
- Ecoli: A dataset that describes the Escherichia coli protein interaction network. Nodes represent E. coli proteins, and edges represent interactions between proteins;
- PB: A dataset that describes the political blog network. Nodes represent blogs, and edges represent hyperlinks between blogs.
4.2. Comparison Method
- CN: Evaluates the similarity between two nodes by calculating the number of common neighbors between them. Pairs of nodes with more common neighbors are more likely to form connections in the graph;
- AA: Utilizes the concept of common neighbors to assign weights to neighbors, weighted according to the degree of the neighbor nodes. Common neighbors with lower degrees are assigned higher weights, as they could potentially be more predictive features;
- GCN: Learns the representations of nodes in the graph by performing convolution operations on the features of the node and its neighbors, thereby capturing the local structural information in the graph;
- GIN: Employs an iterative message-passing mechanism to update node representations by aggregating information from neighbor nodes, aiming to capture the global structural information of the graph;
- MF: Discovers latent node features by decomposing the adjacency matrix; these latent features can capture implicit relationships between nodes and thus can be used for predicting future connections;
- n2v: Generates node sequences by performing random walks in the graph. These sequences are used as input to train a skip-gram model, thus learning the vector representations of nodes in the graph, which can be used for link prediction tasks;
- ScaLed: By aggregating information from neighbor nodes in the graph, this method can capture the local structure of the graph and use this information to predict future connections.
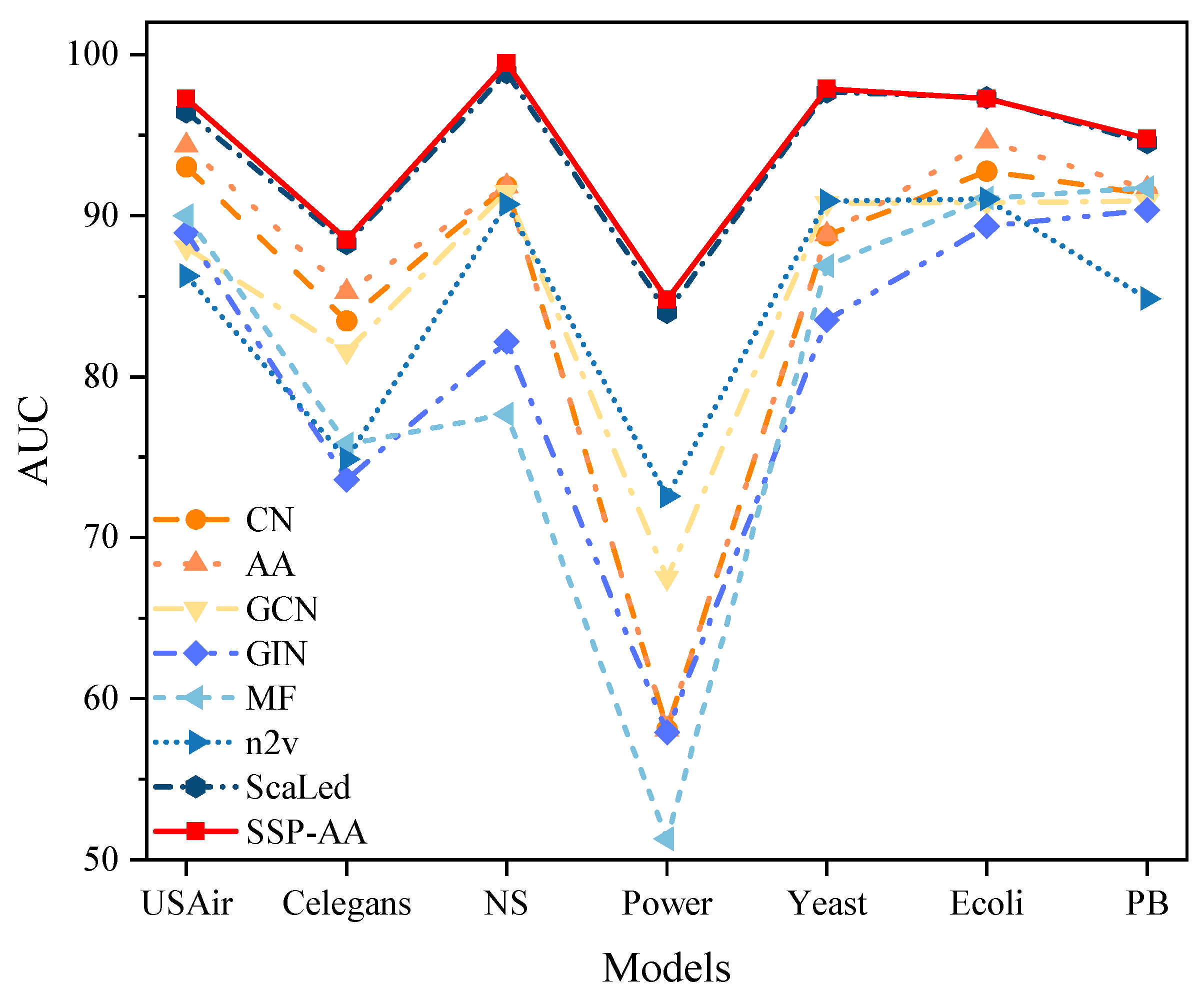
4.3. Comparison of Link Prediction Results
4.4. Ablation Experiments
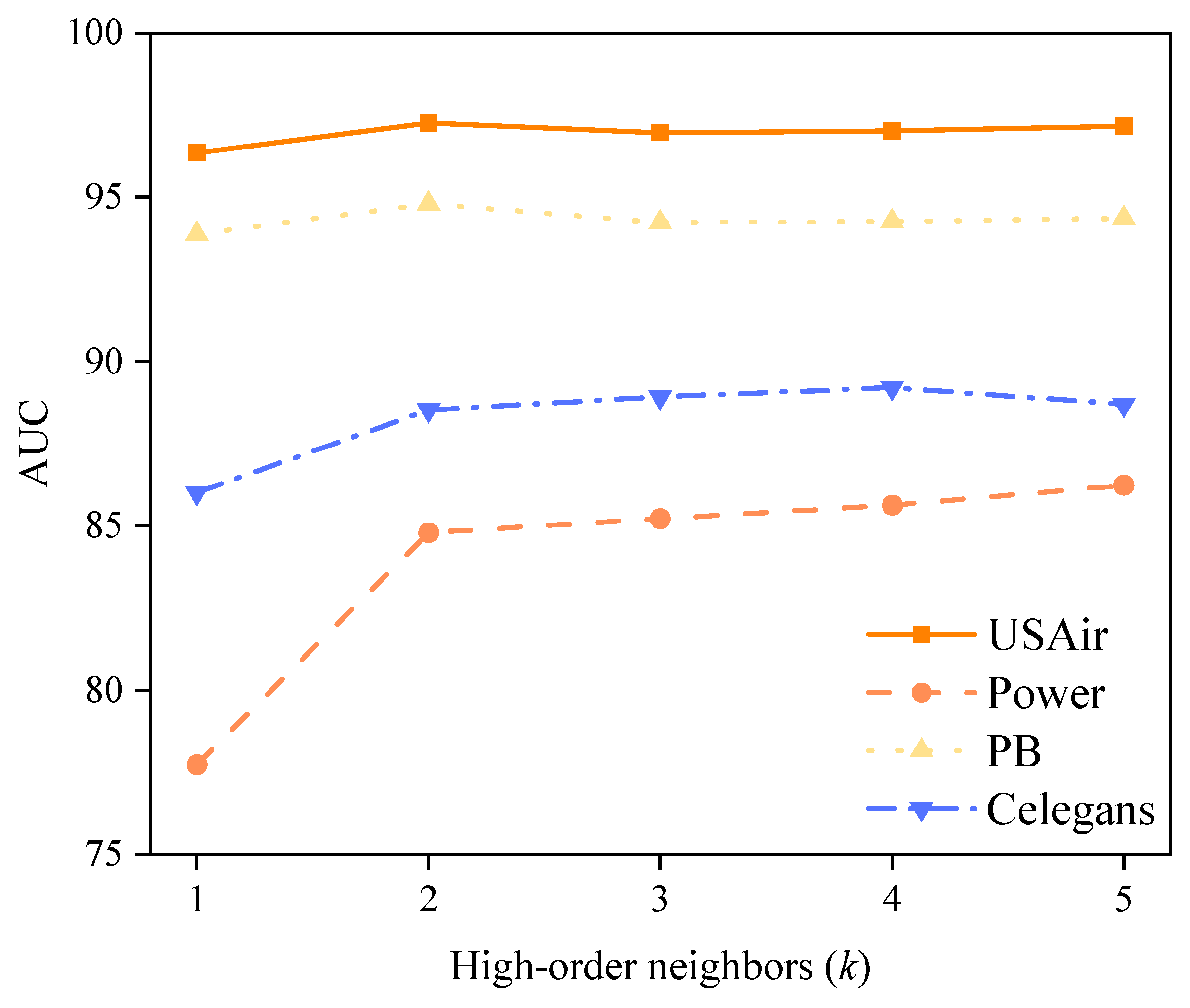
4.5. Parameter Analysis Experiment
5. Summary and Outlook
- (1)
- Explore the application of graph augmentation techniques to the subgraphs within the SSP-AA model to further enhance its learning capability;
- (2)
- Further study the methods based on subgraphs by considering the use of edge personalization in neighborhood subgraphs for sampling subgraphs with more target node-specific information;
- (3)
- Explore integrating other advanced attention mechanisms and graph neural network modules into the SSP-AA model to better cope with complex graph structure data and real-world application scenarios;
- (4)
- For different tasks and datasets, research methods to adaptively adjust the model structure and parameters to automatically discover the optimal graph neural network configuration;
- (5)
- Explore extending this method to various large-scale knowledge graphs, such as clinical medical research, industrial Internet, network anomaly detection, and other various networks.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, W.; Fey, M.; Zitnik, M.; Dong, Y.; Ren, H.; Liu, B.; Catasta, M.; Leskovec, J. Open graph benchmark: Datasets for machine learning on graphs. Adv. Neural Inf. Process. Syst. 2020, 33, 22118–22133. [Google Scholar]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous graph neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 793–803. [Google Scholar]
- You, Y.; Chen, T.; Shen, Y.; Wang, Z. Graph contrastive learning automated. In Proceedings of the International Conference on Machine Learning PMLR, Virtual Event, 8–24 July 2021; pp. 12121–12132. [Google Scholar]
- Yun, S.; Kim, S.; Lee, J.; Kang, J.; Kim, H.J. Neo-gnns: Neighborhood overlap-aware graph neural networks for link prediction. Adv. Neural Inf. Process. Syst. 2021, 34, 13683–13694. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph wavenet for deep spatial-temporal graph modeling. arXiv 2019, arXiv:1906.00121. [Google Scholar]
- Kong, L.; Chen, Y.; Zhang, M. Geodesic Graph Neural Network for Efficient Graph Representation Learning. arXiv 2022, arXiv:2210.02636. [Google Scholar]
- Hamilton, W.L. Graph Representation Learning; Synthesis Lectures on Artifical Intelligence and Machine Learning; Morgan & Claypool Publishers: San Rafael, CA, USA, 2020; Volume 14, pp. 1–159. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Sun, F.Y.; Hoffmann, J.; Verma, V.; Tang, J. Infograph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. arXiv 2019, arXiv:1908.01000. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Chen, D.; Lin, Y.; Li, W.; Li, P.; Zhou, J.; Sun, X. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. Proc. AAAI Conf. Artif. Intell. 2020, 34, 3438–3445. [Google Scholar] [CrossRef]
- Teji, B.; Roy, S. Missing Link Identification from Node Embeddings using Graph Auto Encoders and its Variants. In Proceedings of the 2022 OITS International Conference on Information Technology (OCIT), Bhubaneswar, India, 14–16 December 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Seo, Y.; Defferrard, M.; VanderGheynst, P.; Bresson, X. Structured sequence modeling with graph convolutional recurrent networks. In Proceedings of the Neural Information Processing 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, 13–16 December 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 362–373. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Isabona, J. Wavelet generalized regression neural network approach for robust field strength prediction. Wirel. Pers. Commun. 2020, 114, 3635–3653. [Google Scholar] [CrossRef]
- Alfke, D.; Stoll, M. Semi-supervised classification on non-sparse graphs using low-rank graph convolutional networks. arXiv 2019, arXiv:1905.10224. [Google Scholar]
- Boutorh, A.; Marref, K.; Dehiri, N.E. Graph Representation Learning for COVID-19 Drug Repurposing. In Advances in Computing Systems and Applications, Proceedings of the 5th Conference on Computing Systems and Applications, San Diego, CA, USA, 7–10 April 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 61–72. [Google Scholar]
- Lo, W.W.; Layeghy, S.; Sarhan, M.; Gallagher, M.; Portmann, M. E-graphsage: A graph neural network based intrusion detection system for iot. In Proceedings of the NOMS 2022–2022 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; IEEE: New York, NY, USA, 2022; pp. 1–9. [Google Scholar]
- Lan, J.; Lu, J.Z.; Wan, G.G.; Wang, Y.Y.; Huang, C.Y.; Zhang, S.B.; Huang, Y.Y.; Ma, J.N. E-minBatch GraphSAGE: An Industrial Internet Attack Detection Model. Secur. Commun. Netw. 2022, 2022, 5363764. [Google Scholar] [CrossRef]
- Rezaeipanah, A.; Mokhtari, M.J.; Boshkani, M. Providing a new method for link prediction in social networks based on the meta-heuristic algorithm. Int. J. Cloud Comput. Database Manag. 2020, 1, 28–36. [Google Scholar] [CrossRef]
- Gao, L.; Lin, Y. The Application of Particle Swarm Optimization in Neural Networks. J. Phys. Conf. Series. IOP Publ. 2022, 2278, 012027. [Google Scholar] [CrossRef]
- Wang, P.; Wu, C.; Huang, T.; Chen, Y. A Supervised Link Prediction Method Using Optimized Vertex Collocation Profile. Entropy 2022, 24, 1465. [Google Scholar] [CrossRef]
- Xie, Z.; Zhu, R.; Zhang, M.; Liu, J. SparseMult: A Tensor Decomposition model based on Sparse Relation Matrix. In Proceedings of the 2022 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Niagara Falls, ON, Canada, 17–20 November 2022; IEEE: New York, NY, USA, 2022; pp. 761–764. [Google Scholar]
- Berahmand, K.; Nasiri, E.; Rostami, M.; Forouzandeh, S. A modified DeepWalk method for link prediction in attributed social network. Computing 2021, 103, 2227–2249. [Google Scholar] [CrossRef]
- Arsov, N.; Mirceva, G. Network embedding: An overview. arXiv 2019, arXiv:1911.11726. [Google Scholar]
- Ge, J.; Shi, L.L.; Liu, L.; Shi, H.; Panneerselvam, J. Intelligent link prediction management based on community discovery and user behavior preference in online social networks. Wirel. Commun. Mob. Comput. 2021, 2021, 3860083. [Google Scholar] [CrossRef]
- Meilicke, C.; Chekol, M.W.; Ruffinelli, D.; Stuckenschmidt, H. An introduction to AnyBURL. In Proceedings of the KI 2019: Advances in Artificial Intelligence, 42nd German Conference on AI, Kassel, Germany, 23–26 September 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 244–248. [Google Scholar]
- Ott, S.; Meilicke, C.; Samwald, M. SAFRAN: An interpretable, rule-based link prediction method outperforming embedding models. arXiv 2021, arXiv:2109.08002. [Google Scholar]
- Chen, W.; Li, J.; Jiang, J. Heterogeneous combat network link prediction based on representation learning. IEEE Syst. J. 2020, 15, 4069–4077. [Google Scholar] [CrossRef]
- Anand, S.; Rahul Mallik, A.; Kumar, S. Integrating node centralities, similarity measures, and machine learning classifiers for link prediction. Multimed. Tools Appl. 2022, 81, 38593–38621. [Google Scholar] [CrossRef]
- Yu, X.; Ye, X.; Zhang, S. Floating pollutant image target extraction algorithm based on immune extremum region. Digit. Signal Process. 2022, 123, 103442. [Google Scholar] [CrossRef]
- Ngo, L.; Cha, J.; Han, J.H. Deep neural network regression for automated retinal layer segmentation in optical coherence tomography images. IEEE Trans. Image Process. 2019, 29, 303–312. [Google Scholar] [CrossRef] [PubMed]
- Veličković, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep graph infomax. arXiv 2018, arXiv:1809.10341. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, X.; Zhang, P.; He, Y.; Chao, C.; Yan, C. Subgraph neighboring relations infomax for inductive link prediction on knowledge graphs. arXiv 2022, arXiv:2208.00850. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Zhou, Y.; Wu, C.; Tan, L. Biased random walk with restart for link prediction with graph embedding method. Phys. A Stat. Mech. Its Appl. 2021, 570, 125783. [Google Scholar] [CrossRef]
- Kim, D.; Oh, A. How to find your friendly neighborhood: Graph attention design with self-supervision. arXiv 2022, arXiv:2204.04879. [Google Scholar]
- Xu, K.; Li, C.; Tian, Y.; Sonobe, T.; Kawarabayashi, K.I.; Jegelka, S. Representation learning on graphs with jumping knowledge networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 5453–5462. [Google Scholar]
- Yang, F.; Zhang, H.; Tao, S.; Hao, S. Graph representation learning via simple jumping knowledge networks. Appl. Intell. 2022, 52, 11324–11342. [Google Scholar] [CrossRef]
- Jia, Z.; Lin, S.; Gao, M.; Zaharia, M.; Aiken, A. Improving the accuracy, scalability, and performance of graph neural networks with roc. Proc. Mach. Learn. Syst. 2020, 2, 187–198. [Google Scholar]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Symeonidis, P.; Zioupos, A. Matrix and Tensor Factorization Techniques for Recommender Systems; Springer International Publishing: New York, NY, USA, 2016. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Louis, P.; Jacob, S.A.; Salehi-Abari, A. Sampling Enclosing Subgraphs for Link Prediction. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 4269–4273. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Definitions |
|---|---|
| G | Undirected Graph |
| V | Nodes in the Undirected Graph |
| E | Edges in the Undirected Graph |
| h | Node Features |
| H | A Set of Node Features |
| W | Weight Matrix |
| l | The lst Layer of the Model |
| Weight Vector | |
| b | Adjusted Weight Bias Term |
| eij | The Original Attention Score Between Nodes i and j |
| σ | Non-linear Activation Function |
| Dataset Name | Number of Nodes | Edge Number | Average Degree |
|---|---|---|---|
| USAir | 332 | 2126 | 12.81 |
| Celegans | 297 | 2148 | 14.46 |
| NS | 1461 | 2742 | 3.75 |
| Power | 4941 | 6594 | 2.67 |
| Yeast | 2375 | 11,693 | 9.85 |
| Ecoli | 1805 | 14,660 | 16.24 |
| PB | 1222 | 4732 | 27.36 |
| Models | USAir | Celegans | NS | Power | Yeast | Ecoli | PB |
|---|---|---|---|---|---|---|---|
| CN | 93.02 ± 1.16 | 83.46 ± 1.22 | 91.81 ± 0.78 | 58.10 ± 0.53 | 88.75 ± 0.70 | 92.76 ± 0.70 | 91.35 ± 0.47 |
| AA | 94.34 ± 1.31 | 85.26 ± 1.14 | 91.83 ± 0.75 | 58.10 ± 0.54 | 88.81 ± 0.68 | 94.61 ± 0.52 | 91.68 ± 0.45 |
| GCN | 88.03 ± 2.84 | 81.58 ± 1.42 | 91.48 ± 1.28 | 67.51 ± 1.21 | 90.80 ± 0.95 | 90.82 ± 0.56 | 90.9 ± 0.72 |
| GIN | 88.93 ± 2.04 | 73.60 ± 3.17 | 82.16 ± 2.70 | 57.93 ± 1.28 | 83.51 ± 0.67 | 89.34 ± 1.45 | 90.35 ± 0.78 |
| MF | 89.99 ± 1.74 | 75.81 ± 2.73 | 77.66 ± 3.02 | 51.30 ± 2.25 | 86.88 ± 1.37 | 91.07 ± 0.39 | 91.74 ± 0.22 |
| n2v | 86.27 ± 1.39 | 74.86 ± 1.38 | 90.69 ± 1.20 | 72.58 ± 0.71 | 90.91 ± 0.58 | 91.02 ± 0.17 | 84.84 ± 0.73 |
| ScaLed | 96.44 ± 0.93 | 88.27 ± 1.17 | 98.88 ± 0.50 | 83.99 ± 0.84 | 97.68 ± 0.17 | 97.31 ± 0.14 | 94.53 ± 0.57 |
| SSP-AA | 97.26 ± 0.77 | 88.52 ± 0.49 | 99.48 ± 0.09 | 84.79 ± 0.25 | 97.89 ± 0.10 | 97.26 ± 0.40 | 94.80 ± 0.12 |
| Modules | Index | Celegans | NS |
|---|---|---|---|
| SSP-AA | AUC | 88.52 ± 0.49 | 99.48 ± 0.09 |
| No Jumping Knowledge | AUC | 88.33 ± 0.45 | 99.18 ± 0.09 |
| No Adaptive Attention | AUC | 87.63 ± 0.67 | 98.31 ± 0.32 |
| Modules | Index | Yeast | PB |
|---|---|---|---|
| SSP-AA | AUC | 97.89 ± 0.10 | 94.80 ± 0.12 |
| Not based on subgraphs | AUC | 93.39 ± 1.28 | 91.26 ± 0.89 |
| Data | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| USAir | 96.27 ± 0.97 | 96.65 ± 1.13 | 97.25 ± 0.78 | 97.37 ± 0.39 | 97.29 ± 0.61 | 97.54 ± 0.54 | 97.48 ± 0.3 | 97.53 ± 0.51 |
| Celegans | 86.32 ± 1.32 | 87.14 ± 0.96 | 88.54 ± 0.47 | 88.62 ± 0.62 | 88.56 ± 0.7 | 88.59 ± 0.66 | 88.35 ± 0.65 | 88.49 ± 0.64 |
| Ecoli | 96.03 ± 0.82 | 96.35 ± 0.56 | 97.27 ± 0.37 | 97.12 ± 0.41 | 97.19 ± 0.25 | 97.21 ± 0.39 | 97.36 ± 0.29 | 97.45 ± 0.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Gao, Y.; Li, A.; Zhang, X.; Gu, J.; Liu, J. Sparse Subgraph Prediction Based on Adaptive Attention. Appl. Sci. 2023, 13, 8166. https://doi.org/10.3390/app13148166
Li W, Gao Y, Li A, Zhang X, Gu J, Liu J. Sparse Subgraph Prediction Based on Adaptive Attention. Applied Sciences. 2023; 13(14):8166. https://doi.org/10.3390/app13148166
Chicago/Turabian StyleLi, Weijun, Yuxiao Gao, Ang Li, Xinyong Zhang, Jianlai Gu, and Jintong Liu. 2023. "Sparse Subgraph Prediction Based on Adaptive Attention" Applied Sciences 13, no. 14: 8166. https://doi.org/10.3390/app13148166
APA StyleLi, W., Gao, Y., Li, A., Zhang, X., Gu, J., & Liu, J. (2023). Sparse Subgraph Prediction Based on Adaptive Attention. Applied Sciences, 13(14), 8166. https://doi.org/10.3390/app13148166