
Few-Shot Knowledge Graph Completion Model Based on Relation Learning


Abstract
:1. Introduction
- (1)
- We introduce the FRL-KGC model, which incorporates a gating mechanism to extract valuable contextual semantics from the head entity, tail entity, and neighborhood information, specifically addressing high-order neighborhood information in the knowledge graph. Furthermore, we leverage the correlation between entity pairs in the reference set to represent relations, reducing the dependency of relation embeddings on the central entity.
- (2)
- We effectively utilize both the structural and textual information of the knowledge graph to capture features related to few-shot relations.
- (3)
- Experimental evaluations are conducted on two publicly available datasets, and the results demonstrate that our proposed model outperforms other KGC models. Additionally, ablation experiments validate the effectiveness of each key module in our model.
2. Related Work
2.1. Translation-Based Methods
2.2. Semantic Matching-Based Methods
2.3. Neural Network-Based Methods
2.4. Few-Shot Learning
3. Preliminaries
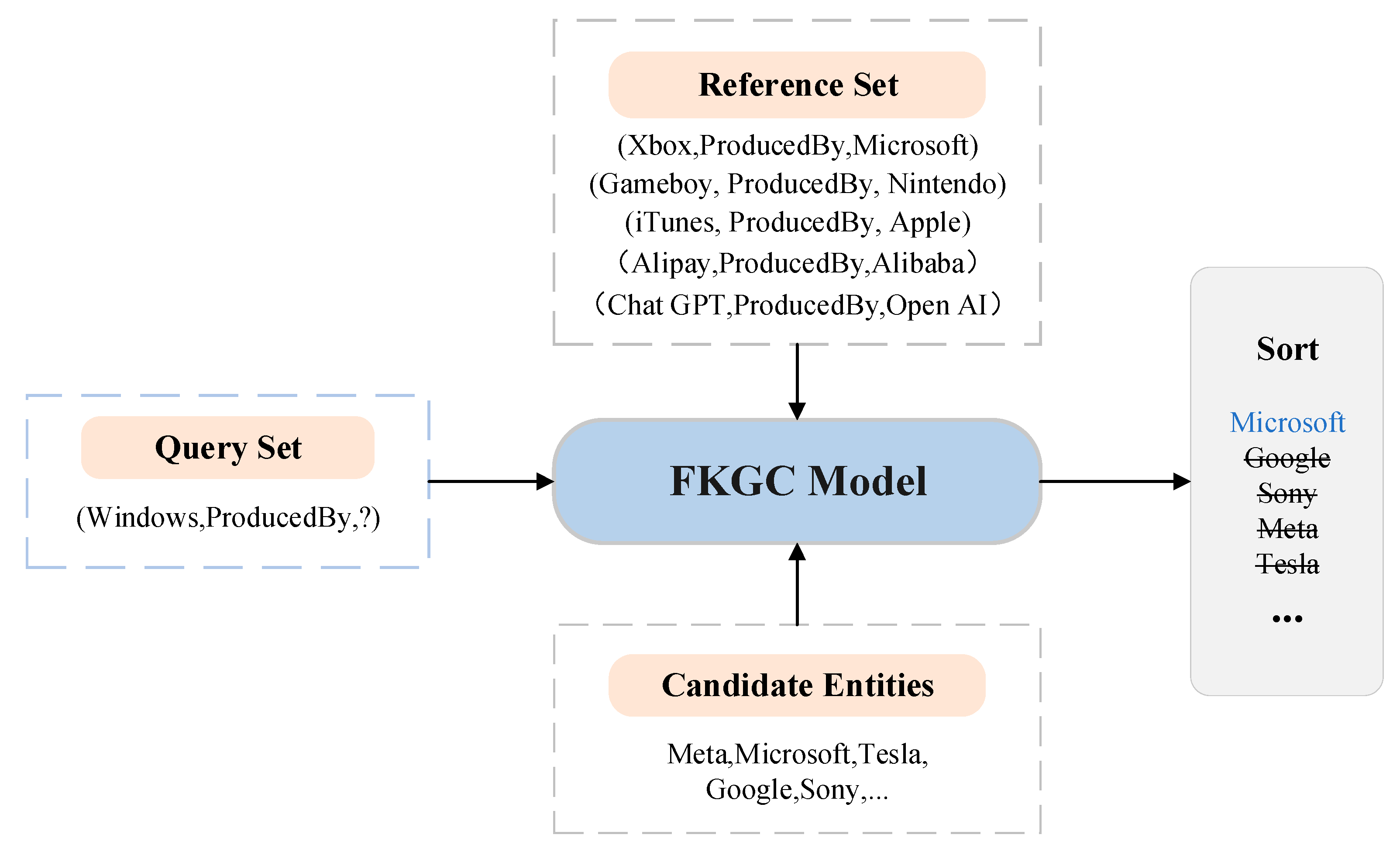
3.1. Problem Formulation
3.2. Few-Shot Learning Settings
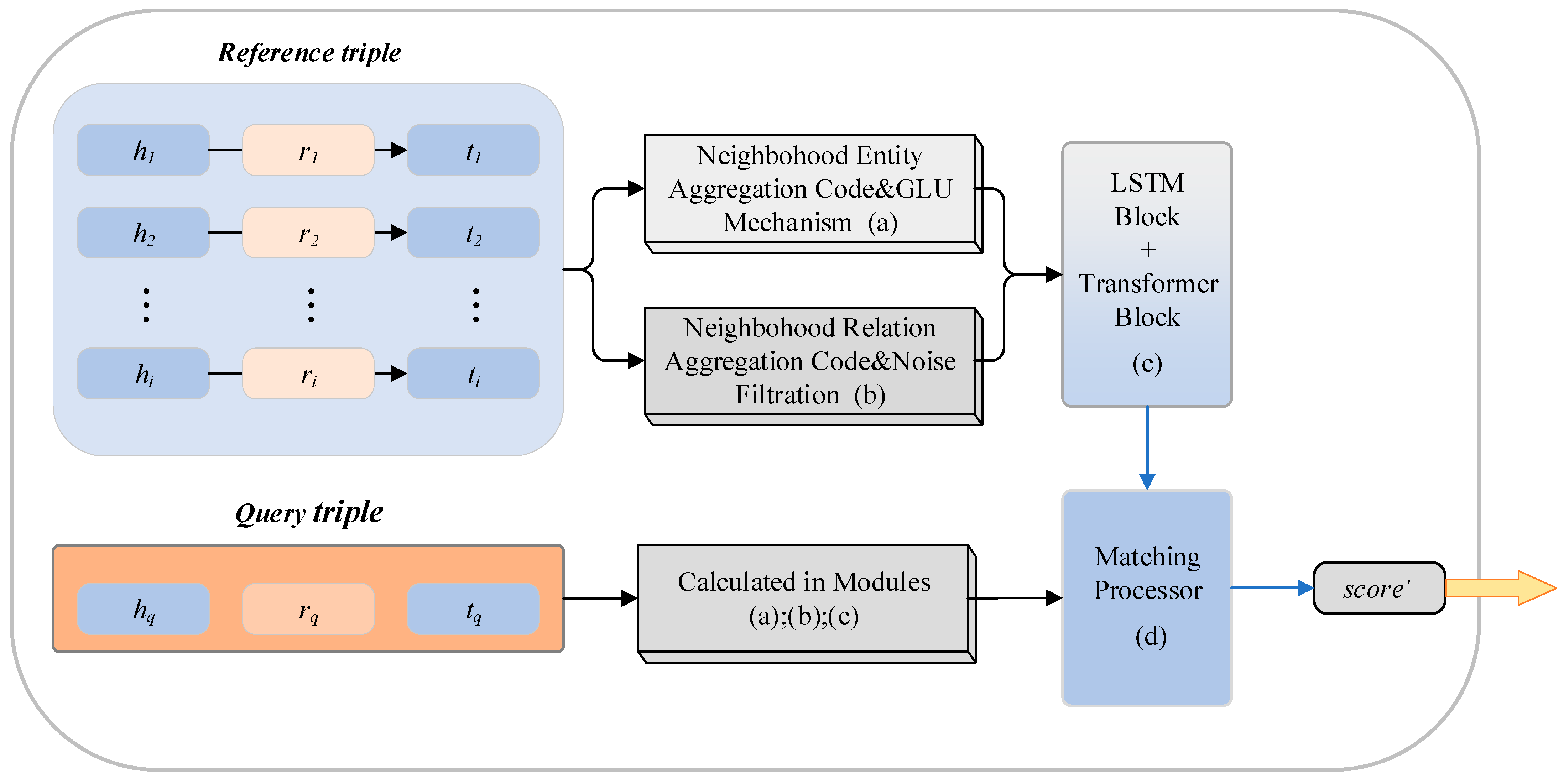
4. Model
- (a)
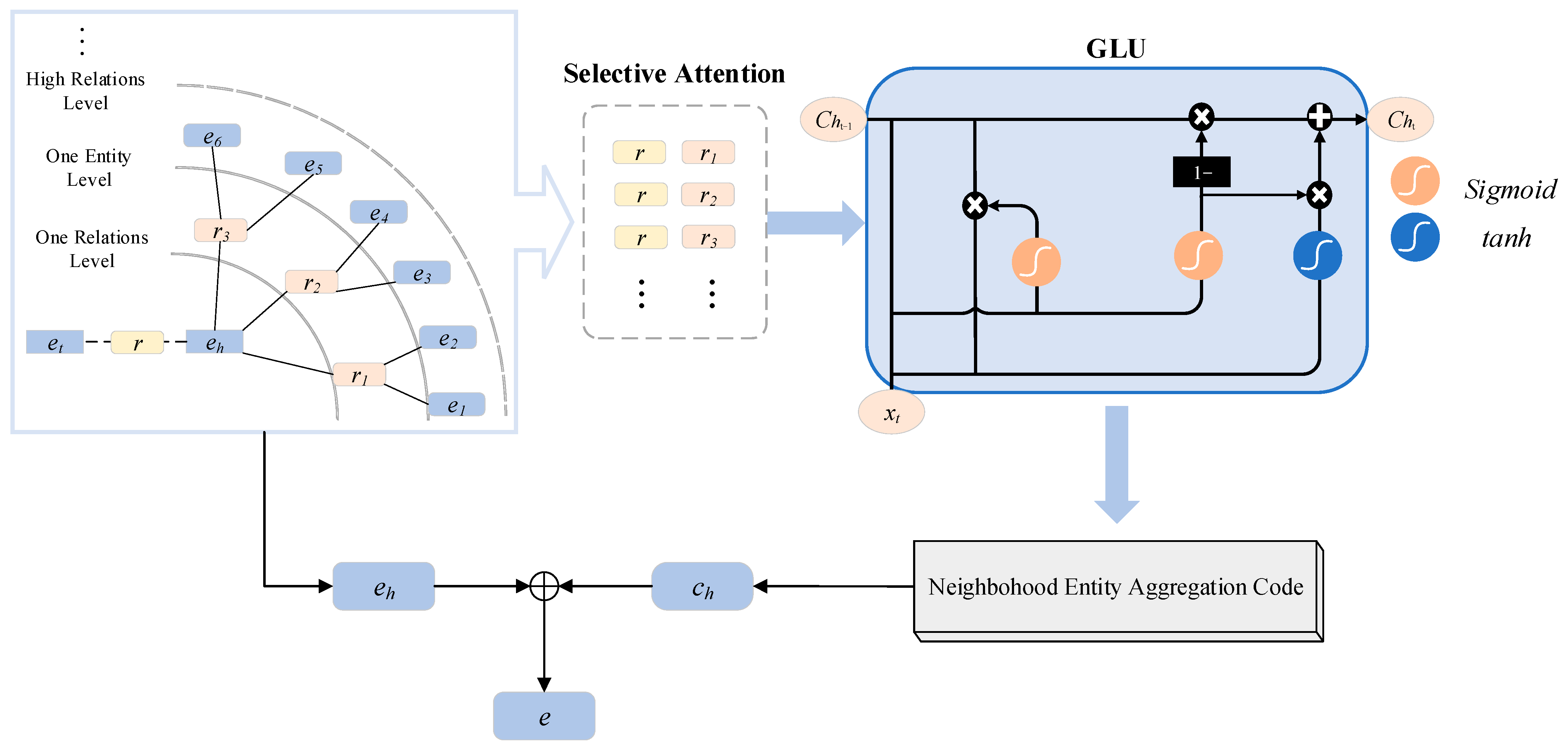
- High-order neighborhood entity encoder based on gate mechanism, which adaptively aggregates neighborhood information for entities.
- (b)
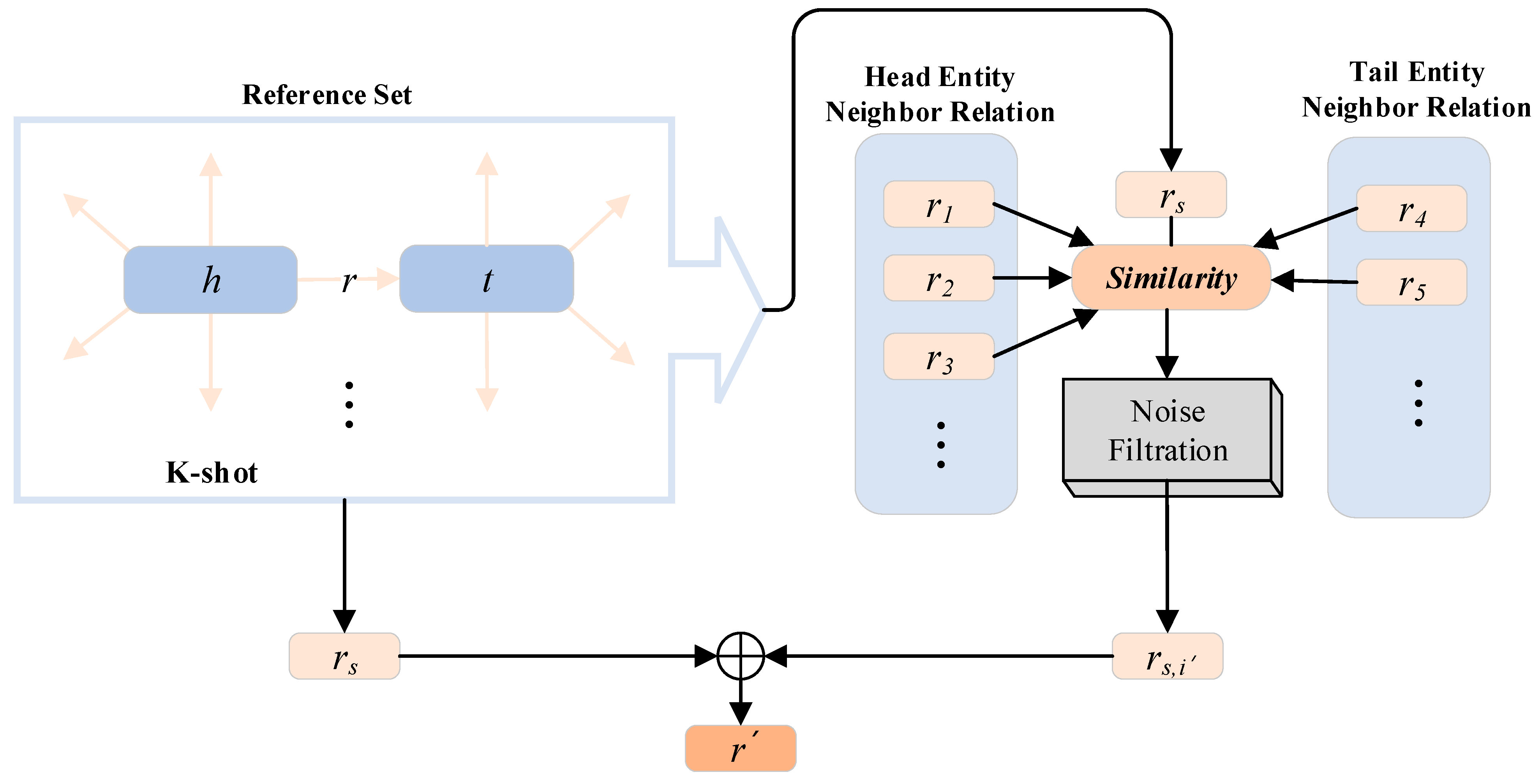
- Relation representation encoder, which utilizes the relation information of reference entity pairs’ neighbors to reduce the dependency of relations on entity embeddings and improve generalization.
- (c)
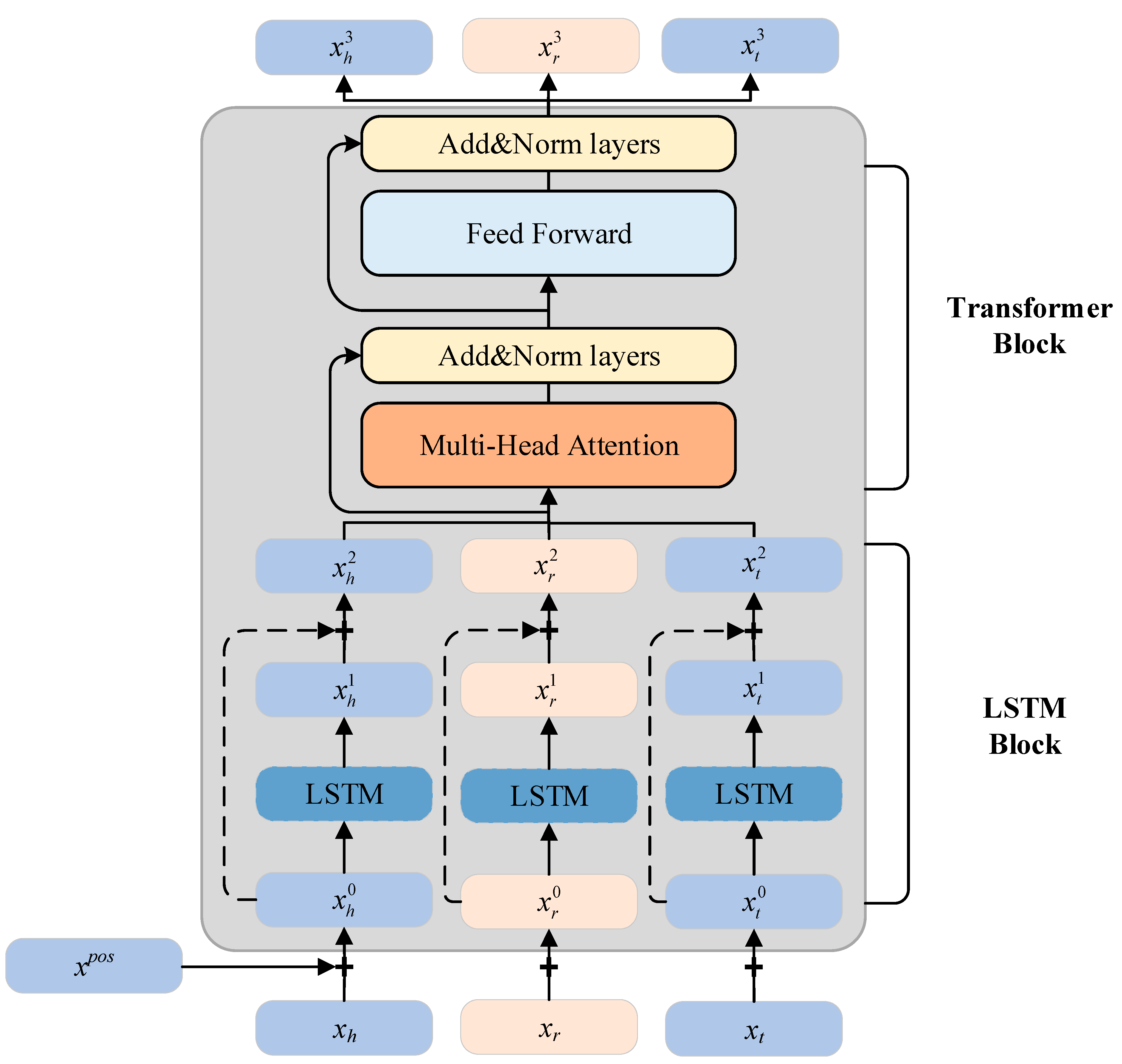
- Transformer learner, which combines LSTM units and Transformer modules to further learn the representation of task relations.
- (d)
- Matching process computation, which utilizes the semantic embeddings of relations outputted by the Transformer learner to calculate the similarity with the query relation, predicting new triplets.
4.1. Entity Encoder Based on Gate Mechanism
4.2. Relation Representation Encoder
4.3. Transformer Learning Framework
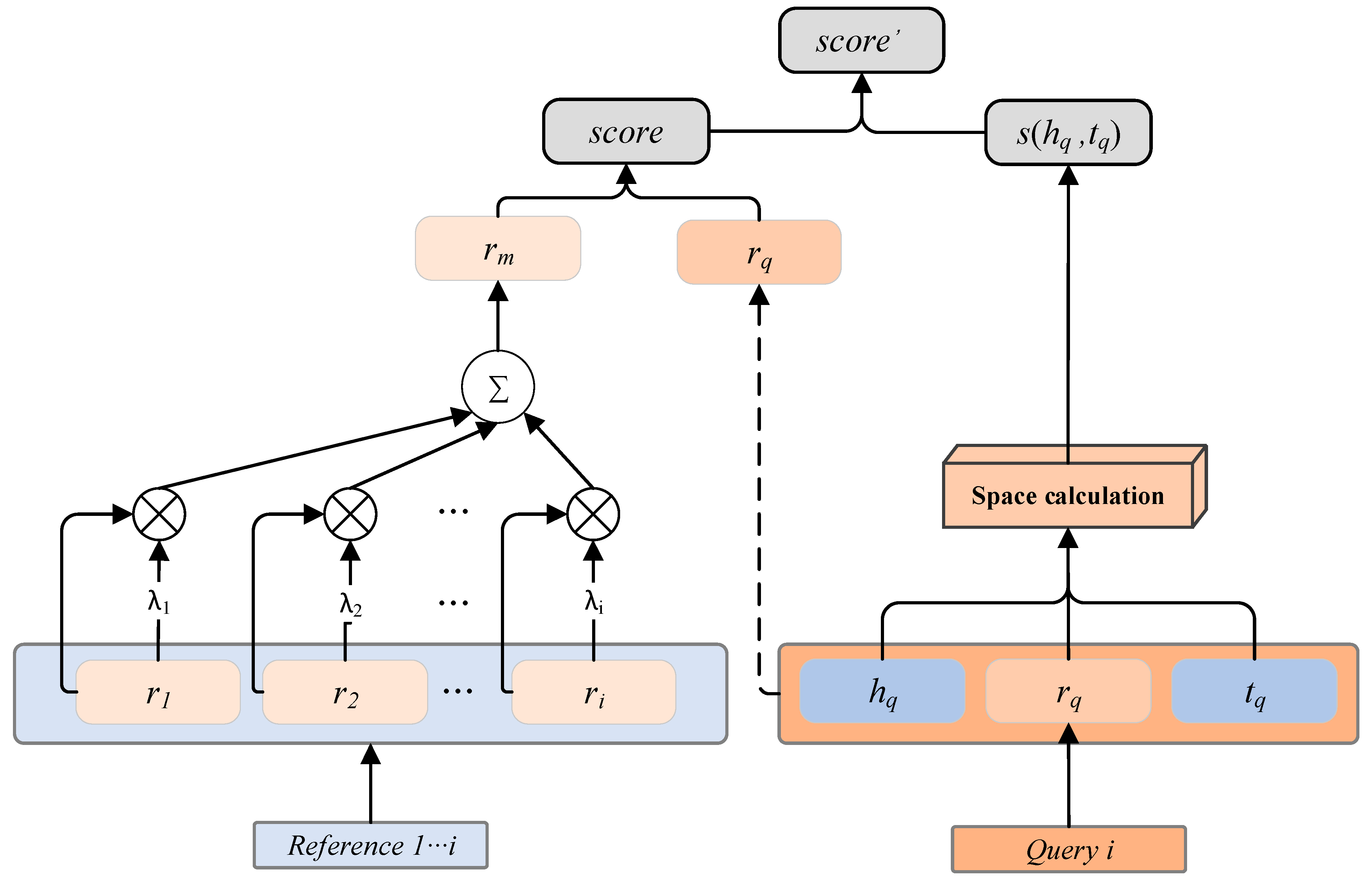
4.4. Matching Process Computation
4.5. Loss Function
| Algorithm 1 The Training Process of FRL-KGC Model |
| Input: Training Task Set , TransE knowledge graph embedding vector, Initialization parameter of matrix model, Reference sample size; |
| Output: Optimization parameters of the model ,, |
| 1 For epoch in 1 to M do |
| 2 Shuffle() // Disrupt tasks in |
| 3 For in do |
| 4 // Extract entity pairs of relation from as a small sample reference set |
| 5 For in do |
| 6 Enhance the embedding vector representation of head and tail entities, and update the representation of few-show relations. |
| 7 End For |
| 8 Process triples through Transformer learners |
| 9 // Build a regular triplet query set |
| 10 // Pollute the tail entity of a positive triplet to obtain a negative triplet |
| 11 Calculate matching scores |
| 12 Accumulate the batch loss |
| 13 Update // Update using the Adam optimizer |
| 14 End for |
| 15 End For |
5. Experiments
5.1. Datasets and Evaluation Indicators
5.2. Baseline Methods
5.3. Implementation Details
5.4. Results
- (1)
- Compared with traditional knowledge graph embedding methods, FRL-KGC achieves the best performance on both datasets. The experimental results demonstrate that FRL-KGC can effectively predict missing entities in few-shot relations.
- (2)
- On both datasets, the FRL-KGC model outperforms the best results of the baseline models on four evaluation metrics. Compared with the best-performing MetaR (In-train) model on the NELL-One dataset, the FRL-KGC model improves the MRR, Hits@10, Hits@5, and Hits@1 metrics by 2.9%, 1.9%, 3.1%, and 4.3%, respectively. The performance improvements on the Wiki-One dataset are 3.3%, 4.3%, 3.4%, and 3.2%, respectively. It is worth noting that only one setting in either Pre-train or In-train performs well on a single dataset. This indicates that our model has better generalization ability across different datasets. Furthermore, FRL-KGC can leverage the contextual semantics and structural information of entities in KG to improve the performance of few-shot knowledge graph completion.
5.5. Ablation Study
- (a)
- To investigate the effectiveness of the high-order neighborhood entity encoder based on a gating mechanism, modifications are made as follows: A1_a encodes only first-order neighborhood entities for output; A1_b removes the gating mechanism and uses the average embedding of neighborhood entities instead of ch.
- (b)
- To study the effectiveness of the relation representation encoder, modifications are made as follows: A2_a simply uses the average embedding of the reference entity pairs as the representation of the relation.
- (c)
- To examine the effectiveness of the Transformer learner, modifications are made as follows: A3_a removes the LSTM module; A3_b removes the Transformer module.
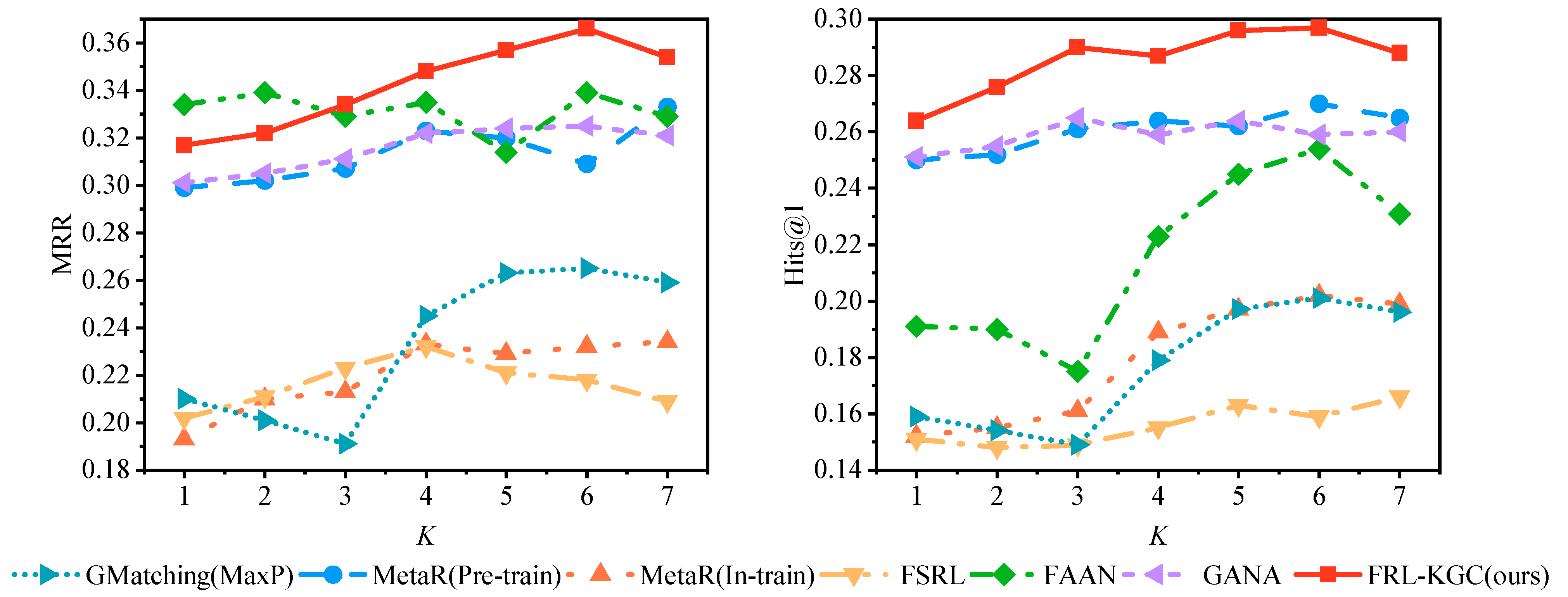
5.6. Impact of Few-Shot Size
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Mitchell, T.; Cohen, W.; Hruschka, E.; Talukdar, P.; Yang, B.; Betteridge, J.; Carlson, A.; Dalvi, B.; Gardner, M.; Kisiel, B.; et al. Never-ending learning. Commun. ACM 2018, 61, 103–115. [Google Scholar] [CrossRef]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Hao, Y.; Zhang, Y.; Liu, K.; He, S.; Liu, Z.; Wu, H.; Zhao, J. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 221–231. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Chami, I.; Wolf, A.; Juan, D.C.; Sala, F.; Ravi, S.; Ré, C. Low-Dimensional Hyperbolic Knowledge Graph Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6901–6914. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; p. 28. [Google Scholar]
- Yang, B.; Yih, W.T.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR) 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1811–1818. [Google Scholar]
- Zhang, N.; Deng, S.; Sun, Z.; Wang, G.; Chen, X.; Zhang, W.; Chen, H. Long-tail Relation Extraction via Knowledge Graph Embeddings and Graph Convolution Networks. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 3–5 June 2019; pp. 3016–3025. [Google Scholar]
- Xiong, W.; Yu, M.; Chang, S.; Guo, X.; Wang, W.Y. One-shot relational learning for knowledge graphs. Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics. arXiv 2018, arXiv:1808.09040. [Google Scholar]
- Zhang, C.; Yao, H.; Huang, C.; Jiang, M.; Li, Z.; Chawla, N.V. Few-shot knowledge graph completion. Proc. AAAI Conf. Artif. Intell. 2020, 34, 3041–3048. [Google Scholar] [CrossRef]
- Sheng, J.; Guo, S.; Chen, Z.; Yue, J.; Wang, L.; Liu, T.; Xu, H. Adaptive Attentional Network for Few-Shot Knowledge Graph Completion. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1681–1691. [Google Scholar]
- Chen, M.; Zhang, W.; Zhang, W.; Chen, Q.; Chen, H. Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4217–4226. [Google Scholar]
- Niu, G.; Li, Y.; Tang, C.; Geng, R.; Dai, J.; Liu, Q.; Wang, H.; Sun, J.; Huang, F.; Si, L. Relational learning with gated and attentive neighbor aggregator for few-shot knowledge graph completion. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 213–222. [Google Scholar]
- Liu, Y.; Yang, S.; Xu, Y.; Miao, C.; Wu, M.; Zhang, J. Contextualized graph attention network for recommendation with item knowledge graph. IEEE Trans. Knowl. Data Eng. 2021, 35, 181–195. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Santa Cruz, CA, USA, 14–18 November 2015; p. 29. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Xiao, H.; Huang, M.; Zhu, X. TransG: A Generative Model for Knowledge Graph Embedding. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2316–2325. [Google Scholar]
- Shi, B.; Weninger, T. Open-world knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1957–1964. [Google Scholar]
- Guo, L.; Sun, Z.; Hu, W. Learning to exploit long-term relational dependencies in knowledge graphs. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2505–2514. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Sun, G.; Zhang, C.; Woodlan, P.C. Transformer language models with LSTM-based cross-utterance information representation. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Toronto, ON, Canada, 6–11 June 2021; pp. 7363–7367. [Google Scholar]
- Gao, T.; Han, X.; Liu, Z.; Sun, M. Hybrid attention-based prototypical networks for noisy few-shot relation classification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6407–6414. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 81–87. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kazemi, S.M.; Poole, D. Simple embedding for link prediction in knowledge graphs. Adv. Neural Inf. Process. Syst. 2018, 31, 4289–4300. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. International Conference on Learning Representations. arXiv 2019, arXiv:1902.10197. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| knowledge graph | |
| background knowledge graph ( removes all subgraphs of task relations) | |
| , | entity and relation of a knowledge graph |
| reference set corresponding to relation | |
| query set corresponding to relation | |
| negative query set corresponding to relation | |
| the relation set of background knowledge graph | |
| task relation set | |
| candidate set for the potential tail entity of | |
| set of meta train | |
| set of meta test | |
| embedding features of fact triplets ,, | |
| the higher-order neighbor set of entity | |
| entity representation updated by neighborhood entity encoder | |
| task relation representation updated by relation encoder | |
| representation of triples corresponding to relation | |
| loss function |
| Dataset | # Ent. | # Rel. | # Triples | ||||
|---|---|---|---|---|---|---|---|
| NELL-One | 68,545 | 58 | 181,109 | 67 | 51 | 5 | 11 |
| Wiki-One | 4,838,244 | 22 | 5,859,240 | 183 | 133 | 16 | 34 |
| Model | NELL-One | Wiki-One | ||||||
|---|---|---|---|---|---|---|---|---|
| MRR | Hits@10 | Hits@5 | Hits@1 | MRR | Hits@10 | Hits@5 | Hits@1 | |
| Traditional models | ||||||||
| TransE | 0.176 | 0.316 | 0.234 | 0.109 | 0.134 | 0.188 | 0.158 | 0.106 |
| DistMult | 0.211 | 0.312 | 0.256 | 0.135 | 0.076 | 0.154 | 0.101 | 0.024 |
| ComplEx | 0.186 | 0.299 | 0.231 | 0.119 | 0.081 | 0.182 | 0.121 | 0.032 |
| SimplE | 0.156 | 0.284 | 0.225 | 0.094 | 0.097 | 0.181 | 0.125 | 0.045 |
| RotatE | 0.176 | 0.331 | 0.245 | 0.109 | 0.052 | 0.091 | 0.065 | 0.026 |
| Few-shot models | ||||||||
| GMatching (MaxP) | 0.176 | 0.294 | 0.233 | 0.113 | 0.263 | 0.387 | 0.337 | 0.197 |
| MetaR (Pre-train) | 0.162 | 0.282 | 0.233 | 0.101 | 0.320 | 0.443 | 0.397 | 0.262 |
| MetaR (In-train) | 0.308 | 0.502 | 0.423 | 0.210 | 0.229 | 0.323 | 0.289 | 0.197 |
| FSRL | 0.269 | 0.482 | 0.369 | 0.178 | 0.221 | 0.269 | 0.183 | 0.163 |
| FAAN | 0.265 | 0.416 | 0.347 | 0.187 | 0.314 | 0.451 | 0.384 | 0.245 |
| GANA | 0.296 | 0.497 | 0.412 | 0.194 | 0.324 | 0.437 | 0.375 | 0.264 |
| FRL-KGC (ours) | 0.337 | 0.521 | 0.454 | 0.253 | 0.357 | 0.494 | 0.431 | 0.296 |
| Ablation on Model | Five-Shot on Wiki-One | |||
|---|---|---|---|---|
| MRR | Hits@10 | Hits@5 | Hits@1 | |
| A1_a | 0.314 | 0.443 | 0.386 | 0.258 |
| A1_b | 0.336 | 0.469 | 0.395 | 0.272 |
| A2_a | 0.343 | 0.483 | 0.425 | 0.267 |
| A3_a | 0.331 | 0.453 | 0.383 | 0.279 |
| A3_b | 0.301 | 0.432 | 0.371 | 0.264 |
| FRL-KGC (ours) | 0.357 | 0.494 | 0.431 | 0.296 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Gu, J.; Li, A.; Gao, Y.; Zhang, X. Few-Shot Knowledge Graph Completion Model Based on Relation Learning. Appl. Sci. 2023, 13, 9513. https://doi.org/10.3390/app13179513
Li W, Gu J, Li A, Gao Y, Zhang X. Few-Shot Knowledge Graph Completion Model Based on Relation Learning. Applied Sciences. 2023; 13(17):9513. https://doi.org/10.3390/app13179513
Chicago/Turabian StyleLi, Weijun, Jianlai Gu, Ang Li, Yuxiao Gao, and Xinyong Zhang. 2023. "Few-Shot Knowledge Graph Completion Model Based on Relation Learning" Applied Sciences 13, no. 17: 9513. https://doi.org/10.3390/app13179513
APA StyleLi, W., Gu, J., Li, A., Gao, Y., & Zhang, X. (2023). Few-Shot Knowledge Graph Completion Model Based on Relation Learning. Applied Sciences, 13(17), 9513. https://doi.org/10.3390/app13179513