
A Data Feature Extraction Method Based on the NOTEARS Causal Inference Algorithm

Abstract
:1. Introduction
2. Related Work
3. Proposed Methods Based on Causal Inference
3.1. Mathematical Representation of Causal Network
3.2. NOTEARS Causal Discovery Algorithm
| Algorithm 1: NOTEARS algorithm. |
| Input: minimization speed , penalty growth rate , initial solution , optimization accuracy .
Output: Return the threshold matrix to build causal network
|
3.3. Calculation of Causal Strength between Nodes
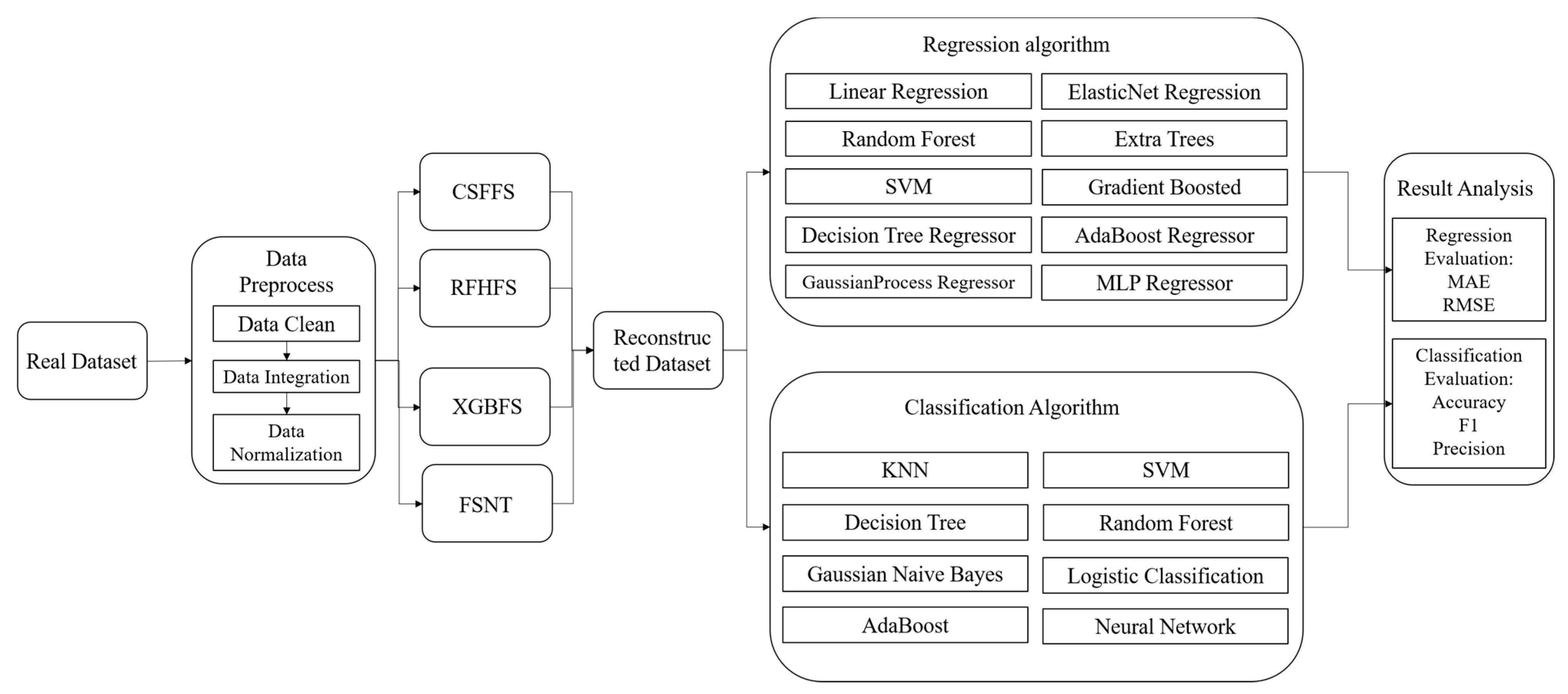
4. Experiment Setup
4.1. Experimental Setup
- (1)
- For each sample belonging to a minority class label, calculate its distance from sample points of other minority class labels in the multidimensional space. Obtain the k nearest neighboring points to the sample by performing the K-nearest neighbors (KNN) algorithm on the sample points of the minority class label.
- (2)
- Determine the sampling rate based on the proportion of each sample label type. For sample points belonging to a minority class with a relatively small proportion compared to other labels, randomly select a subset of samples from their k neighboring points. These selected samples are denoted as .
- (3)
- For continuous data, and each selected adjacent sample from the previous step, generate a new sample according to Equation (20):where represents a random number between 0 and 1, and .
- (4)
- For discrete data, the new sample value is determined by selecting the discrete value with the highest frequency of occurrence among the nearest neighbor samples.
4.2. Evaluation Metrics
- Mean absolute error (MAE)
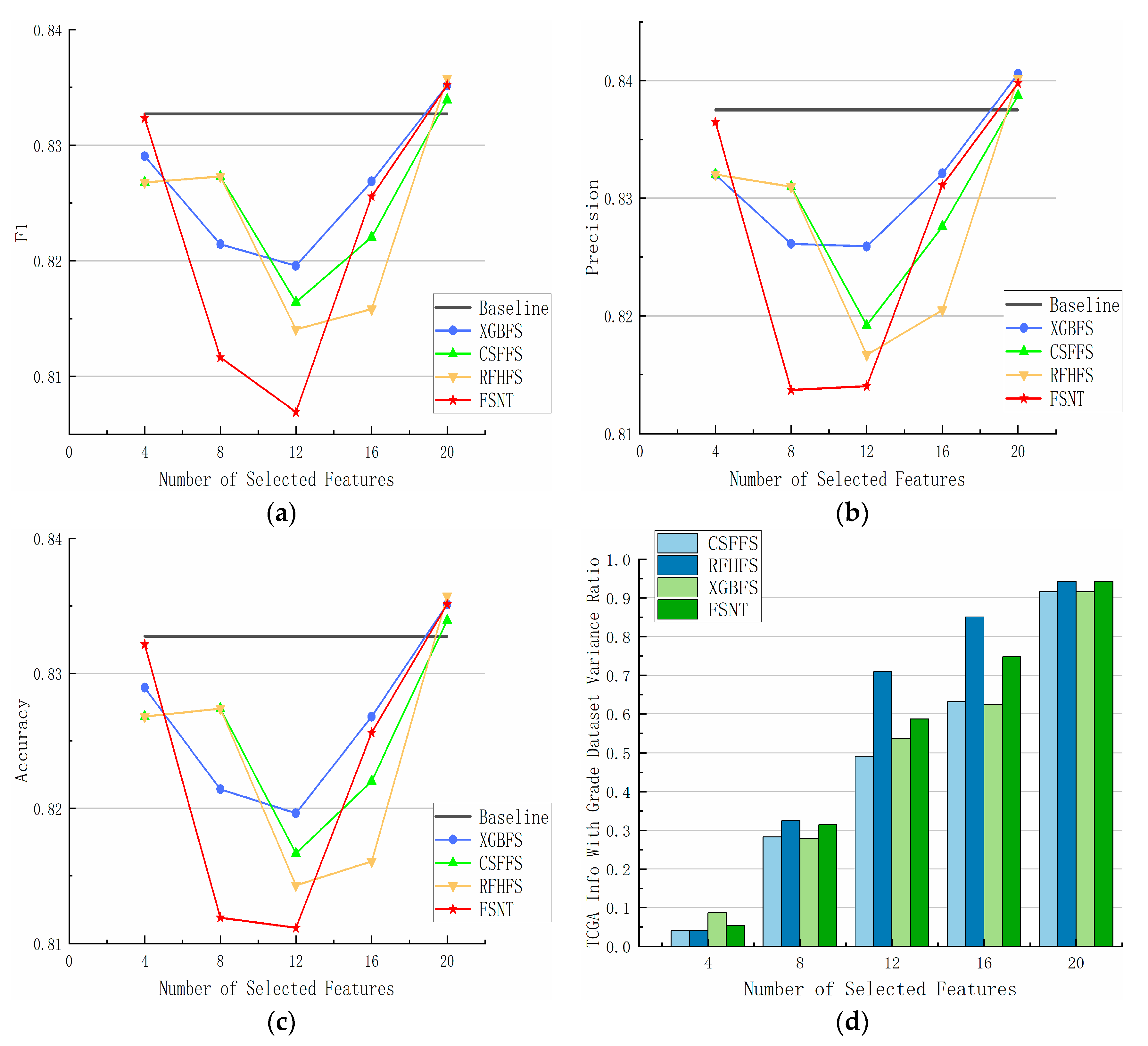
4.3. Analysis of Experimental Results of Classified Datasets with Different Feature Numbers
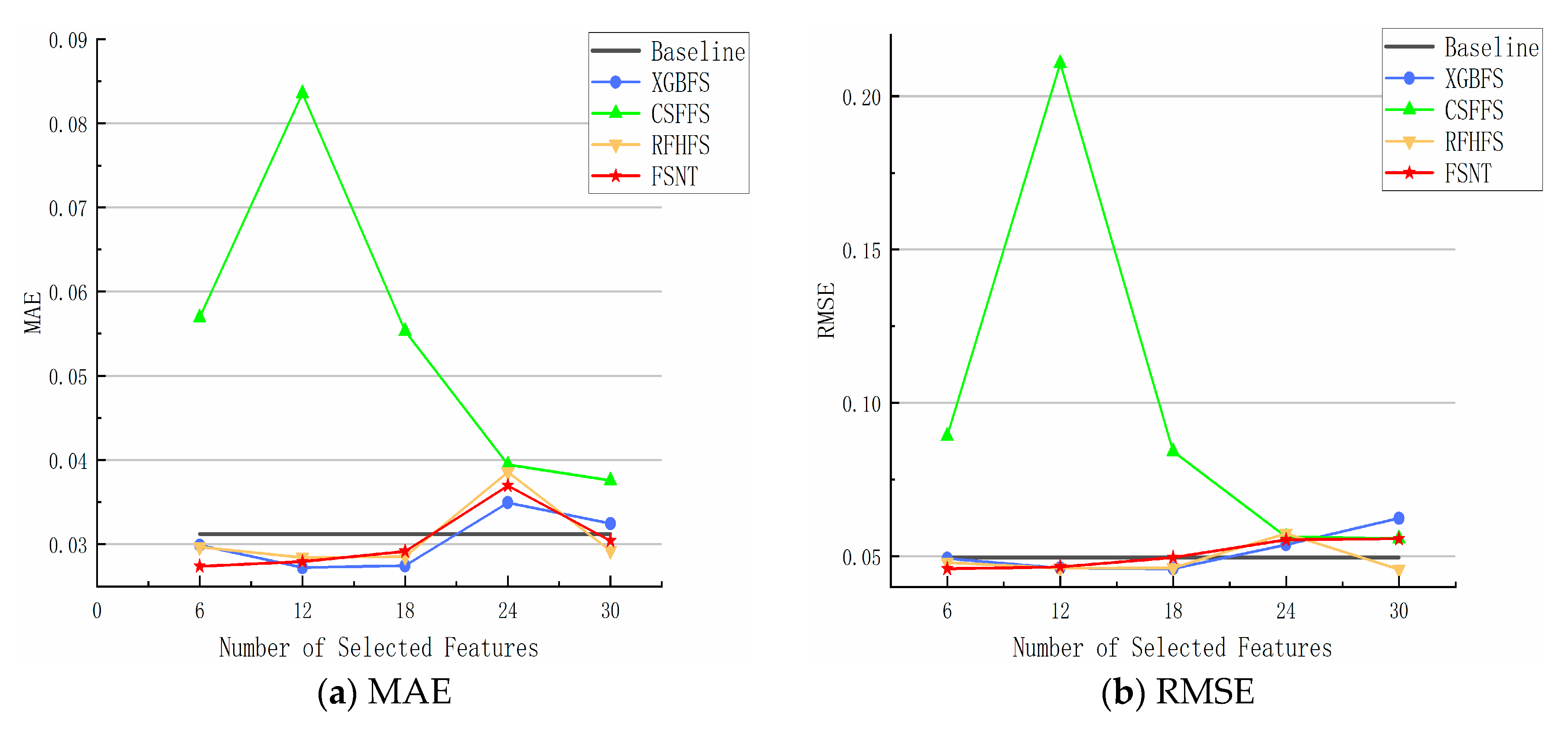
4.4. Analysis of Experimental Results of Regression Datasets with Different Feature Numbers
4.5. Analysis of Experimental Results of Different Datasets with Different Feature Selection Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arcinas, M.M.; Sajja, G.S.; Asif, S.; Gour, S.; Okoronkwo, E.; Naved, M. Role of Data Mining in Education for Improving Students Performance for Social Change. Turk. J. Physiother. Rehabil. 2021, 32, 6519–6526. [Google Scholar]
- Puarungroj, W.; Boonsirisumpun, N.; Pongpatrakant, P.; Phromkhot, S. Application of data mining techniques for predicting student success in English exit exam. In Proceedings of the 12th International Conference on Ubiquitous Information Management and Communication, Langkawi, Malaysia, 5–7 January 2018; pp. 1–6. [Google Scholar]
- Batool, S.; Rashid, J.; Nisar, M.W.; Kim, J.; Mahmood, T.; Hussain, A. A random forest students’ performance prediction (rfspp) model based on students’ demographic features. In Proceedings of the Mohammad Ali Jinnah University International Conference on Computing (MAJICC), Karachi, Pakistan, 15–17 July 2021; pp. 1–4. [Google Scholar]
- Romero, C.; López, M.I.; Luna, J.M.; Ventura, S. Predicting students’ final performance from participation in on-line discussion forums. Comput. Educ. 2013, 68, 458–472. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Aliferis, C.F.; Statnikov, A.; Tsamardinos, I.; Mani, S.; Koutsoukos, X.D. Local causal and markov blanket induction for causal discovery and feature selection for classification part II: Analysis and extensions. J. Mach. Learn. Res. 2010, 11, 235–284. [Google Scholar]
- Guang-yu, L.; Geng, H. The behavior analysis and achievement prediction research of college students based on XGBFS gradient lifting decision tree algorithm. In Proceedings of the 7th International Conference on Information and Education Technology, Aizu-Wakamatsu, Japan, 29–31 March 2019; pp. 289–294. [Google Scholar]
- Wang, C.; Chang, L.; Liu, T. Predicting Student Performance in Online Learning Using a Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the International Conference on Intelligent Information Processing, Bucharest, Romania, 29–30 September 2022; Springer: Cham, Switzerland, 2022; pp. 508–521. [Google Scholar]
- Zheng, X.; Aragam, B.; Ravikumar, P.K.; Xing, E.P. Dags with no tears: Continuous optimization for structure learning. Adv. Neural Inf. Process. Syst. 2018, 31, 9472–9483. [Google Scholar]
- Yu, K.; Guo, X.; Liu, L.; Li, J.; Wang, H.; Ling, Z.; Wu, X. Causality-based Feature Selection: Methods and Evaluations. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Venkatesh, B.; Anuradha, J. A review of feature selection and its methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef] [Green Version]
- Spencer, R.; Thabtah, F.; Abdelhamid, N.; Thompson, M. Exploring feature selection and classification methods for predicting heart disease. Digit. Health 2020, 6, 2055207620914777. [Google Scholar] [CrossRef] [Green Version]
- Dufour, B.; Petrella, F.; Richez-Battesti, N. Understanding social impact assessment through public value theory: A comparative analysis on work integration social enterprises (WISEs) in France and Denmark. Work. Pap. 2020, 41, 112–138. [Google Scholar]
- Chen, T.; Guestrin, C. XGBFS: A Scalable Tree Boosting System. In Proceedings of the KDD ’16: 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Ye-Zi, L.; Zhen-You, W.; Yi-Lu, Z.; Xiao-Zhuo, H. The Improvement and Application of Xgboost Method Based on the Bayesian Optimization. J. Guangdong Univ. Technol. 2018, 35, 23–28. [Google Scholar]
- Srivastava, A.K.; Pandey, A.S.; Houran, M.A.; Kumar, V.; Kumar, D.; Tripathi, S.M.; Gangatharan, S.; Elavarasan, R.M. A Day-Ahead Short-Term Load Forecasting Using M5P Machine Learning Algorithm along with Elitist Genetic Algorithm (EGA) and Random Forest-Based RFHFS Feature Selection. Energies 2023, 16, 867. [Google Scholar] [CrossRef]
- Chickering, D.M.; Meek, C.; Heckerman, D. Large-sample learning of bayesian networks is NP-hard. In Proceedings of the Nineteenth Conference on Uncertainty in Artificial Intelligence, Acapulco, Mexico, 7–10 August 2003; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2002. [Google Scholar] [CrossRef]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Chickering, M. Optimal structure identification with greedy search. J. Mach. Learn. Res. 2003, 3, 507–554. [Google Scholar]
- Kalisch, M.; Bühlman, P. Estimating high-dimensional directed acyclic graphs with the PC-algorithm. J. Mach. Learn. Res. 2007, 8, 613–636. [Google Scholar]
- Shimizu, S. LiNGAM: Non-Gaussian methods for estimating causal structures. Behaviormetrika 2014, 41, 65–98. [Google Scholar] [CrossRef]
- Scheines, R.; Ramsey, J. Measurement error and causal discovery//CEUR workshop proceedings. NIH Public Access 2016, 1792, 1. [Google Scholar]
- Kang, D.G. Comparison of statistical methods and deterministic sensitivity studies for investigation on the influence of uncertainty parameters: Application to LBLOCA. Reliab. Eng. Syst. Saf. 2020, 203, 107082. [Google Scholar] [CrossRef]
- Janzing, D.; Balduzzi, D.; Grosse-Wentrup, M.; Schölkopf, B. Quantifying causal influences. Ann. Stat. 2013, 41, 2324–2358. [Google Scholar] [CrossRef]
- Liu, Y.; Bi, J.W.; Fan, Z.P. Multi-class sentiment classification: The experimental comparisons of feature selection and machine learning algorithms. Expert Syst. Appl. 2017, 80, 323–339. [Google Scholar] [CrossRef] [Green Version]
- Gao, W.; Hu, L.; Zhang, P. Feature selection by maximizing part mutual information. In Proceedings of the ACM International Conference Proceeding Series (ICPS), Shanghai, China, 28–30 November 2018. [Google Scholar] [CrossRef]
- Mansur, A.B.F.; Yusof, N. The Latent of Student Learning Analytic with K-mean Clustering for Student Behaviour Classification. J. Inf. Syst. Eng. Bus. Intell. 2018, 4, 156–161. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Lin, K. Predicting and evaluating the online news popularity based on random forest. J. Phys. Conf. Ser. 2021, 1994, 012040. [Google Scholar] [CrossRef]
- Martins, M.V.; Tolledo, D.; Machado, J.; Baptista, L.M.; Realinho, V. Early Prediction of Student’s Performance in Higher Education: A Case Study. In Trends and Applications in Information Systems and Technologies: Volume 1 9; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 166–175. [Google Scholar]
- Hamidieh, K. A data-driven statistical model for predicting the critical temperature of a superconductor. Comput. Mater. Sci. 2018, 154, 346–354. [Google Scholar] [CrossRef] [Green Version]
- Tasci, E.; Zhuge, Y.; Kaur, H.; Camphausen, K.; Krauze, A.V. Hierarchical Voting-Based Feature Selection and Ensemble Learning Model Scheme for Glioma Grading with Clinical and Molecular Characteristics. Int. J. Mol. Sci. 2022, 23, 14155. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Groß, J. Multiple Linear Regression; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Xue, H.; Chen, S.; Yang, Q. Structural regularized support vector machine: A framework for structural large margin classifier. IEEE Trans. Neural Netw. 2011, 22, 573–587. [Google Scholar] [CrossRef]
- Zemel, R.S.; Pitassi, T. A Gradient-Based Boosting Algorithm for Regression Problems. In Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Xu, M.; Watanachaturaporn, P.; Varshney, P.K.; Arora, M.K. Decision tree regression for soft classification of remote sensing data. Remote Sens. Environ. Interdiscip. J. 2005, 97, 322–336. [Google Scholar] [CrossRef]
- Collins, M.; Schapire, R.E.; Singer, Y. Logistic regression, AdaBoost and Bregman distances. Mach. Learn. 2002, 48, 253–285. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Kashi, H.; Emamgholizadeh, S.; Ghorbani, H. Estimation of soil infiltration and cation exchange capacity based on multiple regression, ANN (RBF, MLP), and ANFIS models. Commun. Soil Sci. Plant Anal. 2014, 45, 1195–1213. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Kesavaraj, G.; Sukumaran, S. A study on classification techniques in data mining. In Proceedings of the 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013. [Google Scholar]
- Saravanan, K.; Sasithra, S. Review on Classification Based on Artificial Neural Networks. Int. J. Ambient. Syst. Appl. 2014, 2, 11–18. [Google Scholar]
- Cheng, W.; Hüllermeier, E. Combining Instance-Based Learning and Logistic Regression for Multilabel Classification. Mach. Learn. 2009, 76, 211–225. [Google Scholar] [CrossRef] [Green Version]
- Schapire, R.E. Explaining adaboost. In Empirical Inference: Festschrift in Honor of Vladimir N. Vapnik; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Gao, J.; Nuyttens, D.; Lootens, P.; He, Y.; Pieters, J.G. Recognising weeds in a maize crop using a random forest machine-learning algorithm and near-infrared snapshot mosaic hyperspectral imagery. Biosyst. Eng. 2018, 170, 39–50. [Google Scholar] [CrossRef]
- Ruangkanokmas, P.; Achalakul, T.; Akkarajitsakul, K. Deep Belief Networks with Feature Selection for Sentiment Classification. In Proceedings of the 2016 7th International Conference on Intelligent Systems, Modelling and Simulation (ISMS), Bangkok, Thailand, 25–27 January 2016. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Sample Size | Number of Features | Classification Category |
|---|---|---|---|
| Student-mat | 649 | 33 | 5 |
| Student Archive | 4424 | 36 | 3 |
| TCGA Info with Grade | 839 | 23 | 3 |
| Name | Sample Size | Number of Features |
|---|---|---|
| Student-por | 649 | 33 |
| Superconductivity | 21,263 | 81 |
| Online News Popularity | 39,797 | 61 |
| Datasets | Feature Selection Method | KNN | SVM | DT | RF | Ada | LA | GNB | NN |
|---|---|---|---|---|---|---|---|---|---|
| Student-mat | CSFFS | 0.7128 | 0.6658 | 0.6991 | 0.6639 | 0.6982 | 0.6658 | 0.7972 | 0.8016 |
| XGBFS | 0.7457 | 0.6658 | 0.7098 | 0.7085 | 0.6610 | 0.6658 | 0.7620 | 0.8355 | |
| RFHFS | 0.7233 | 0.6658 | 0.7147 | 0.6648 | 0.7223 | 0.6658 | 0.8070 | 0.6630 | |
| FSNT | 0.6951 | 0.7158 | 0.6658 | 0.6658 | 0.6542 | 0.6658 | 0.8172 | 0.7858 | |
| Baseline | 0.7371 | 0.6658 | 0.7265 | 0.6648 | 0.6768 | 0.7137 | 0.7618 | 0.7403 | |
| Student Archive | CSFFS | 0.6820 | 0.7169 | 0.6849 | 0.7487 | 0.7245 | 0.7318 | 0.6962 | 0.7450 |
| XGB | 0.6930 | 0.7045 | 0.6773 | 0.7427 | 0.7072 | 0.7184 | 0.6894 | 0.7512 | |
| RFHFS | 0.6475 | 0.7036 | 0.6848 | 0.7497 | 0.7240 | 0.7275 | 0.6712 | 0.7452 | |
| FSNT | 0.6814 | 0.7103 | 0.7005 | 0.7498 | 0.7269 | 0.7025 | 0.7081 | 0.7227 | |
| Baseline | 0.6348 | 0.7129 | 0.6965 | 0.7540 | 0.7244 | 0.7365 | 0.6906 | 0.7371 | |
| TCGA Info with Grade | CSFFS | 0.8446 | 0.7470 | 0.8050 | 0.8487 | 0.8660 | 0.8867 | 0.8540 | 0.8576 |
| XGB | 0.8446 | 0.7470 | 0.7867 | 0.8471 | 0.8660 | 0.8867 | 0.8540 | 0.8924 | |
| RFHFS | 0.8199 | 0.7420 | 0.8145 | 0.8546 | 0.8660 | 0.8867 | 0.8509 | 0.8867 | |
| FSNT | 0.8199 | 0.7420 | 0.8166 | 0.8437 | 0.8660 | 0.8867 | 0.8540 | 0.8924 | |
| Baseline | 0.8214 | 0.7424 | 0.8101 | 0.8336 | 0.8660 | 0.8867 | 0.8476 | 0.8924 |
| Dataset | Feature Selection Method | LR | ENR | RF | ET | SVM | GBR | DTR | ABR | GPR | MLLPR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Student-por | CSFFS | 2.8401 | 3.0566 | 3.0000 | 3.0553 | 2.9342 | 2.8461 | 3.9514 | 2.9749 | 3.1705 | 3.1648 |
| XGBFS | 2.8081 | 3.0566 | 2.9088 | 2.9186 | 2.8815 | 2.7792 | 3.6470 | 2.9224 | 3.1947 | 2.9115 | |
| RFHFS | 2.8374 | 3.0670 | 3.0013 | 3.0578 | 2.9390 | 2.8909 | 4.0737 | 3.1024 | 3.1925 | 2.9329 | |
| FSNT | 3.0641 | 3.0126 | 2.8695 | 3.1101 | 2.8602 | 3.0243 | 3.5585 | 3.1701 | 3.1086 | 3.1230 | |
| Baseline | 2.8081 | 3.0566 | 2.9088 | 2.9186 | 2.8815 | 2.7792 | 3.6470 | 2.9224 | 3.1947 | 2.9115 | |
| Online News Popularity | CSFFS | 0.1038 | 0.1035 | 0.1114 | 0.1045 | 0.5056 | 0.1158 | 0.1391 | 0.1350 | 0.1421 | 2.0169 |
| XGBFS | 0.1029 | 0.1035 | 0.1116 | 0.1048 | 0.5056 | 0.1154 | 0.1335 | 0.1541 | 0.1595 | 1.7150 | |
| RFHFS | 0.1035 | 0.1035 | 0.1115 | 0.1047 | 0.5056 | 0.1185 | 0.1338 | 0.1411 | 0.1633 | 1.8974 | |
| FSNT | 0.1041 | 0.1035 | 0.1112 | 0.1050 | 0.5056 | 0.1186 | 0.1462 | 0.1317 | 0.1409 | 2.0082 | |
| Baseline | 0.1035 | 0.1035 | 0.1120 | 0.1046 | 0.5056 | 0.0179 | 0.1313 | 0.1561 | 0.1158 | 2.1284 | |
| Superconductivity | CSFFS | 0.1062 | 0.1009 | 0.0311 | 0.0263 | 0.0789 | 0.0300 | 0.0346 | 0.0343 | 0.0526 | 0.0625 |
| XGBFS | 0.1800 | 0.1009 | 0.0414 | 0.0245 | 0.0698 | 0.0365 | 0.0480 | 0.0420 | 0.0260 | 0.0544 | |
| RFHFS | 0.0112 | 0.1009 | 0.0349 | 0.0232 | 0.0805 | 0.0313 | 0.0508 | 0.0444 | 0.0273 | 0.0523 | |
| FSNT | 0.0110 | 0.1009 | 0.0450 | 0.0225 | 0.0687 | 0.0428 | 0.1436 | 0.0466 | 0.0391 | 0.0363 | |
| Baseline | 0.0494 | 0.1009 | 0.0375 | 0.0260 | 0.0748 | 0.0321 | 0.0524 | 0.0331 | 0.0408 | 0.0484 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Li, J.; Zhu, G. A Data Feature Extraction Method Based on the NOTEARS Causal Inference Algorithm. Appl. Sci. 2023, 13, 8438. https://doi.org/10.3390/app13148438
Wang H, Li J, Zhu G. A Data Feature Extraction Method Based on the NOTEARS Causal Inference Algorithm. Applied Sciences. 2023; 13(14):8438. https://doi.org/10.3390/app13148438
Chicago/Turabian StyleWang, Hairui, Junming Li, and Guifu Zhu. 2023. "A Data Feature Extraction Method Based on the NOTEARS Causal Inference Algorithm" Applied Sciences 13, no. 14: 8438. https://doi.org/10.3390/app13148438
APA StyleWang, H., Li, J., & Zhu, G. (2023). A Data Feature Extraction Method Based on the NOTEARS Causal Inference Algorithm. Applied Sciences, 13(14), 8438. https://doi.org/10.3390/app13148438