
Federated Learning for Clients’ Data Privacy Assurance in Food Service Industry

 , ,
, ,  , ,
, ,  ,
,
Abstract
:1. Introduction
2. Material
2.1. Data Collection Technology
2.2. Data Collection
3. Methodology
3.1. Federated Averaging (FedAvg)
3.2. FedML
3.3. Contamination Classification
Classification Model Architecture
3.4. Contamination Segmentation
3.4.1. Semantic Segmentation and Pixel-Level Annotation
3.4.2. Semantic Segmentation Model Architecture
4. Experimental Settings
5. Results and Discussion
5.1. Federated Learning Classification Model Performance
5.2. Federated Learning Semantic Segmentation Model Performance
5.3. Privacy and Performance Trade-Off
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pires, S.M.; Desta, B.N.; Mughini-Gras, L.; Mmbaga, B.T.; Fayemi, O.E.; Salvador, E.M.; Gobena, T.; Majowicz, S.E.; Hald, T.; Hoejskov, P.S. Burden of foodborne diseases: Think global, act local. Curr. Opin. Food Sci. 2021, 39, 152–159. [Google Scholar] [CrossRef] [PubMed]
- CDC. Estimates of Foodborne Illness in the United States. Available online: https://www.cdc.gov/foodborneburden/index.html (accessed on 1 August 2023).
- Dewey-Mattia, D.; Manikonda, K.; Hall, A.J.; Wise, M.E.; Crowe, S.J. Surveillance for foodborne disease outbreaks—United States, 2009–2015. MMWR Surveill. Summ. 2018, 67, 1. [Google Scholar] [CrossRef]
- Abban, S.; Jakobsen, M.; Jespersen, L. Attachment behaviour of Escherichia coli K12 and Salmonella Typhimurium P6 on food contact surfaces for food transportation. Food Microbiol. 2012, 31, 139–147. [Google Scholar] [CrossRef]
- Quan, Y.; Kim, H.-Y.; Shin, I.-S. Bactericidal activity of strong acidic hypochlorous water against Escherichia coli O157: H7 and Listeria monocytogenes in biofilms attached to stainless steel. Food Sci. Biotechnol. 2017, 26, 841–846. [Google Scholar] [CrossRef] [PubMed]
- Verran, J.; Redfern, J.; Smith, L.; Whitehead, K. A critical evaluation of sampling methods used for assessing microorganisms on surfaces. Food Bioprod. Process. 2010, 88, 335–340. [Google Scholar] [CrossRef]
- Keresztes, J.C.; Goodarzi, M.; Saeys, W. Real-time pixel based early apple bruise detection using short wave infrared hyperspectral imaging in combination with calibration and glare correction techniques. Food Control 2016, 66, 215–226. [Google Scholar] [CrossRef]
- Coelho, P.A.; Torres, S.N.; Ramírez, W.E.; Gutiérrez, P.A.; Toro, C.A.; Soto, J.G.; Sbarbaro, D.G.; Pezoa, J.E. A machine vision system for automatic detection of parasites Edotea magellanica in shell-off cooked clam Mulinia edulis. J. Food Eng. 2016, 181, 84–91. [Google Scholar] [CrossRef]
- Dutta, M.K.; Singh, A.; Ghosal, S. A computer vision based technique for identification of acrylamide in potato chips. Comput. Electron. Agric. 2015, 119, 40–50. [Google Scholar] [CrossRef]
- Al-Sarayreh, M.; Reis, M.M.; Yan, W.Q.; Klette, R. A sequential CNN approach for foreign object detection in hyperspectral images. In Computer Analysis of Images and Patterns; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; pp. 271–283. [Google Scholar]
- Jayasinghe, L.; Wijerathne, N.; Yuen, C. A deep learning approach for classification of cleanliness in restrooms. In Proceedings of the 2018 International Conference on Intelligent and Advanced System (ICIAS), Kuala Lumpur, Malaysia, 13–14 August 2018; pp. 1–6. [Google Scholar]
- Gorji, H.T.; Shahabi, S.M.; Sharma, A.; Tande, L.Q.; Husarik, K.; Qin, J.; Chan, D.E.; Baek, I.; Kim, M.S.; MacKinnon, N. Combining deep learning and fluorescence imaging to automatically identify fecal contamination on meat carcasses. Sci. Rep. 2022, 12, 2392. [Google Scholar] [CrossRef]
- Taheri Gorji, H.; Van Kessel, J.A.S.; Haley, B.J.; Husarik, K.; Sonnier, J.; Kashani Zadeh, H.; Chan, D.E.; Qin, J.; Baek, I.; Kim, M.S. Deep Learning and Multiwavelength Fluorescence Imaging for Cleanliness Assessment and Disinfection in Food Services. Front. Sens. 2022, 3, 25. [Google Scholar]
- Husarik, K.; Gorji, H.T.; Qin, J.; Chan, D.E.; Baek, I.; Kim, M.S.; Thompson, M.S.; MacKinnon, N.; Sokolov, S.; Vasefi, F. Cleanliness assessment in long-term care facilities using deep learning and multiwavelength fluorescence imaging. In Proceedings of the Sensing for Agriculture and Food Quality and Safety XV, Orlando, FL, USA, 30 April–5 May 2023; pp. 41–53. [Google Scholar]
- Propp, C.; Woods, L.; Gorji, H.T.; Husarik, K.; Sueker, M.; Qin, J.; Baek, I.; Kim, M.S.; Chan, D.E.; Sokolov, S. Dual-excitation fluorescence imaging system for contamination detection in food facilities. In Proceedings of the Sensing for Agriculture and Food Quality and Safety XV, Orlando, FL, USA, 30 April–5 May 2023; pp. 135–142. [Google Scholar]
- Woods, L.; Propp, C.; Sueker, M.; Husarik, K.; Gorji, H.T.; Qin, J.; Baek, I.; Kim, M.S.; Chan, D.E.; Sokolov, S. Efficacy of sanitization in healthcare using deep learning and multiwavelength fluorescence imaging. In Proceedings of the Sensing for Agriculture and Food Quality and Safety XV, Orlando, FL, USA, 30 April–5 May 2023; pp. 143–148. [Google Scholar]
- Voigt, P.; Von dem Bussche, A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10, pp. 10–5555. [Google Scholar]
- Gaff, B.M.; Sussman, H.E.; Geetter, J. Privacy and big data. Computer 2014, 47, 7–9. [Google Scholar] [CrossRef]
- Pardau, S.L. The California consumer privacy act: Towards a European-style privacy regime in the United States. J. Tech. Law Policy 2018, 23, 68. [Google Scholar]
- Sueker, M.; Stromsodt, K.; Gorji, H.T.; Vasefi, F.; Khan, N.; Schmit, T.; Varma, R.; Mackinnon, N.; Sokolov, S.; Akhbardeh, A. Handheld Multispectral Fluorescence Imaging System to Detect and Disinfect Surface Contamination. Sensors 2021, 21, 7222. [Google Scholar] [CrossRef] [PubMed]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Rodríguez-Barroso, N.; López, D.J.; Luzón, M.; Herrera, F.; Martínez-Cámara, E. Survey on Federated Learning Threats: Concepts, taxonomy on attacks and defences, experimental study and challenges. arXiv 2022, arXiv:2201.08135. [Google Scholar] [CrossRef]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- Yang, T.; Andrew, G.; Eichner, H.; Sun, H.; Li, W.; Kong, N.; Ramage, D.; Beaufays, F. Applied federated learning: Improving google keyboard query suggestions. arXiv 2018, arXiv:1812.02903. [Google Scholar]
- Ramaswamy, S.; Mathews, R.; Rao, K.; Beaufays, F. Federated learning for emoji prediction in a mobile keyboard. arXiv 2019, arXiv:1906.04329. [Google Scholar]
- Silva, S.; Gutman, B.A.; Romero, E.; Thompson, P.M.; Altmann, A.; Lorenzi, M. Federated learning in distributed medical databases: Meta-analysis of large-scale subcortical brain data. In Proceedings of the 2019 IEEE 16th international symposium on biomedical imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 270–274. [Google Scholar]
- Gao, D.; Ju, C.; Wei, X.; Liu, Y.; Chen, T.; Yang, Q. Hhhfl: Hierarchical heterogeneous horizontal federated learning for electroencephalography. arXiv 2019, arXiv:1909.05784. [Google Scholar]
- Liu, B.; Yan, B.; Zhou, Y.; Yang, Y.; Zhang, Y. Experiments of federated learning for COVID-19 chest X-ray images. arXiv 2020, arXiv:2007.05592. [Google Scholar]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.-Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A survey on federated learning systems: Vision, hype and reality for data privacy and protection. IEEE Trans. Knowl. Data Eng. 2021, 35, 3347–3366. [Google Scholar] [CrossRef]
- Colom-Cadena, M.; Tulloch, J.; Jackson, R.J.; Catterson, J.H.; Rose, J.; Davies, C.; Hooley, M.; Anton-Fernandez, A.; Dunnett, S.; Tempelaar, R. TMEM97 increases in synapses and is a potential synaptic Aβ binding partner in human Alzheimer’s disease. bioRxiv 2021. [Google Scholar] [CrossRef]
- Ziller, A.; Trask, A.; Lopardo, A.; Szymkow, B.; Wagner, B.; Bluemke, E.; Nounahon, J.-M.; Passerat-Palmbach, J.; Prakash, K.; Rose, N. Pysyft: A library for easy federated learning. In Federated Learning Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 111–139. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Parcollet, T.; de Gusmão, P.P.; Lane, N.D. Flower: A friendly federated learning research framework. arXiv 2020, arXiv:2007.14390. [Google Scholar]
- He, C.; Li, S.; So, J.; Zeng, X.; Zhang, M.; Wang, H.; Wang, X.; Vepakomma, P.; Singh, A.; Qiu, H. Fedml: A research library and benchmark for federated machine learning. arXiv 2020, arXiv:2007.13518. [Google Scholar]
- Wen, Y.; Li, W.; Roth, H.; Dogra, P. Federated Learning Powered by NVIDIA Clara. Available online: https://developer.nvidia.com/blog/federated-learning-clara/ (accessed on 12 April 2023).
- Liu, Y.; Fan, T.; Chen, T.; Xu, Q.; Yang, Q. FATE: An industrial grade platform for collaborative learning with data protection. J. Mach. Learn. Res. 2021, 22, 1–6. [Google Scholar]
- Caldas, S.; Duddu, S.M.K.; Wu, P.; Li, T.; Konečný, J.; McMahan, H.B.; Smith, V.; Talwalkar, A. Leaf: A benchmark for federated settings. arXiv 2018, arXiv:1812.01097. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Yang, T.-J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Brand Finance. Food Safety. 2018. Available online: https://brandirectory.com/download-report/Food%20Safety%20Report.pdf (accessed on 4 July 2022).
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated learning: A survey on enabling technologies, protocols, and applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- Open Data Institute. Why Businesses Aren’t Sharing More Data. Available online: https://theodi.org/article/why-businesses-arent-sharing-more-data/ (accessed on 21 March 2023).
- Stitzlein, C.; Fielke, S.; Waldner, F.; Sanderson, T. Reputational risk associated with big data research and development: An interdisciplinary perspective. Sustainability 2021, 13, 9280. [Google Scholar] [CrossRef]
- Murthy, S.; Bakar, A.A.; Rahim, F.A.; Ramli, R. A comparative study of data anonymization techniques. In Proceedings of the 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing,(HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Washington, DC, USA, 27–29 May 2019; pp. 306–309. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the Theory and Applications of Models of Computation: 5th International Conference, TAMC 2008, Xi’an, China, 25–29 April 2008; pp. 1–19. [Google Scholar]
- Bhanot, R.; Hans, R. A review and comparative analysis of various encryption algorithms. Int. J. Secur. Its Appl. 2015, 9, 289–306. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
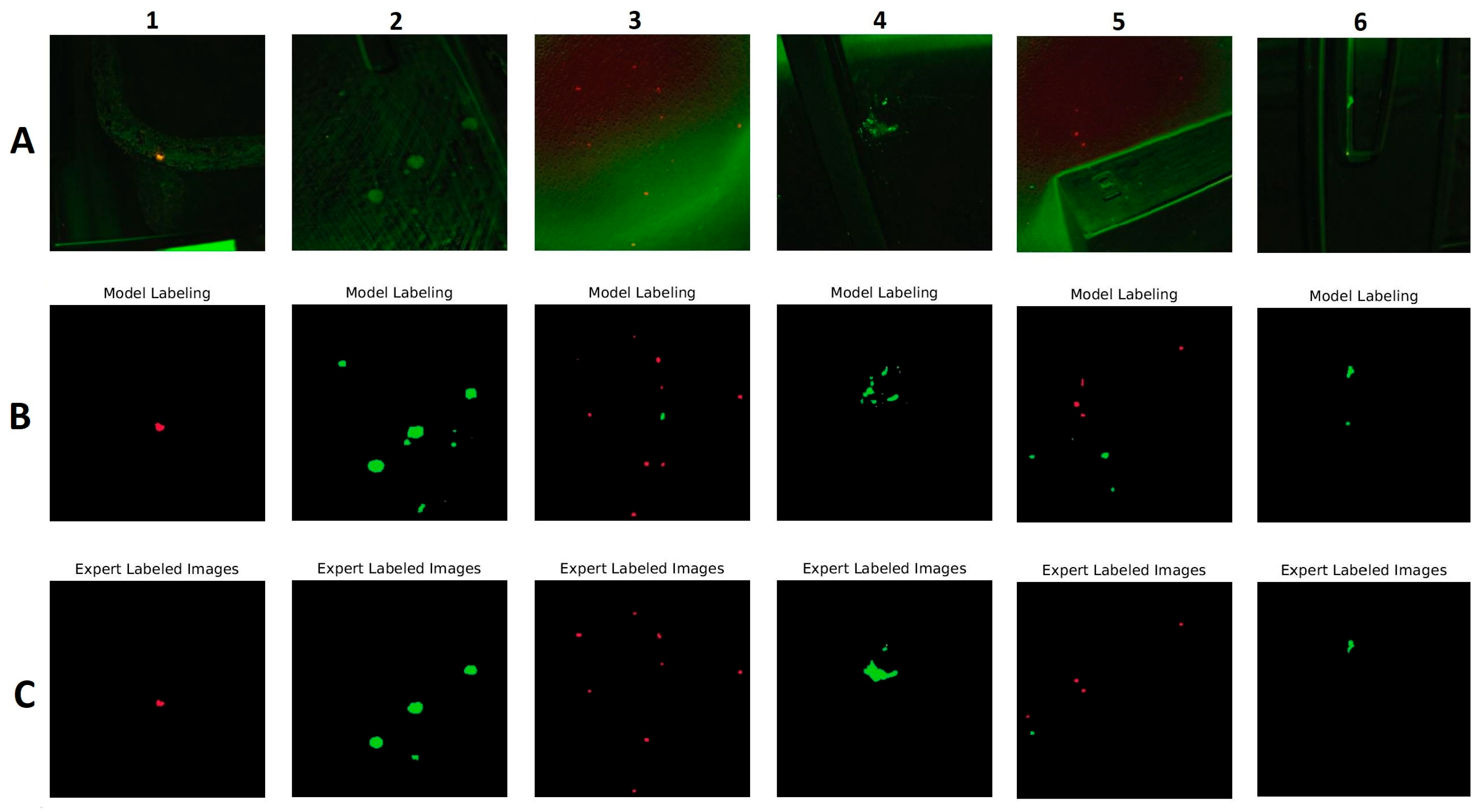{kind=link}
{kind=link}
{kind=link}
| No. of Clients | No. of “Clean” Frames | No. of “Contamination” Frames | Total No. of Frames | |
|---|---|---|---|---|
| Training/ Validation | 1 | 708 | 3242 | 3950 |
| 2 | 1585 | 7207 | 8792 | |
| 3 | 2740 | 1815 | 4555 | |
| 4 | 3893 | 2574 | 6467 | |
| 5 | 2679 | 2320 | 4999 | |
| 6 | 11,897 | 8629 | 20,526 | |
| 7 | 11,041 | 6486 | 17,527 | |
| 8 | 1315 | 4250 | 5565 | |
| External Testing | 9 | 6354 | 7606 | 13,960 |
| 10 | 1973 | 2753 | 4726 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taheri Gorji, H.; Saeedi, M.; Mushtaq, E.; Kashani Zadeh, H.; Husarik, K.; Shahabi, S.M.; Qin, J.; Chan, D.E.; Baek, I.; Kim, M.S.; et al. Federated Learning for Clients’ Data Privacy Assurance in Food Service Industry. Appl. Sci. 2023, 13, 9330. https://doi.org/10.3390/app13169330
Taheri Gorji H, Saeedi M, Mushtaq E, Kashani Zadeh H, Husarik K, Shahabi SM, Qin J, Chan DE, Baek I, Kim MS, et al. Federated Learning for Clients’ Data Privacy Assurance in Food Service Industry. Applied Sciences. 2023; 13(16):9330. https://doi.org/10.3390/app13169330
Chicago/Turabian StyleTaheri Gorji, Hamed, Mahdi Saeedi, Erum Mushtaq, Hossein Kashani Zadeh, Kaylee Husarik, Seyed Mojtaba Shahabi, Jianwei Qin, Diane E. Chan, Insuck Baek, Moon S. Kim, and et al. 2023. "Federated Learning for Clients’ Data Privacy Assurance in Food Service Industry" Applied Sciences 13, no. 16: 9330. https://doi.org/10.3390/app13169330
APA StyleTaheri Gorji, H., Saeedi, M., Mushtaq, E., Kashani Zadeh, H., Husarik, K., Shahabi, S. M., Qin, J., Chan, D. E., Baek, I., Kim, M. S., Akhbardeh, A., Sokolov, S., Avestimehr, S., MacKinnon, N., Vasefi, F., & Tavakolian, K. (2023). Federated Learning for Clients’ Data Privacy Assurance in Food Service Industry. Applied Sciences, 13(16), 9330. https://doi.org/10.3390/app13169330