4.2. Uncertainty Sampling
Uncertainty sampling [
28] is a widely employed active learning strategy, often utilized as a baseline approach, as evident in the active learning competition [
29]. This strategy exhibits an exploitative nature, wherein it utilizes the existing model to compute uncertainty measures that serve as indicators of a candidate’s influence on the classification performance. The candidate possessing the highest uncertainty measure is selected for labeling. In the influential study carried out by [
30], a probabilistic classifier was employed on a candidate, enabling the calculation of the posterior probability for its most probable class. The uncertainty measure is determined by the absolute difference between this posterior estimate and 0.5, with lower values indicating higher uncertainty. According to [
31], the formula for selecting
is as follows:
is the instance from the pool of unlabeled data that our model is least confident in, while is the class for which the model calculated the highest posterior estimate, so .
In addition to the confidence-based uncertainty measure, other measures, such as entropy or the margin between a candidate and the decision boundary, are commonly used [
32]. However, as noted in [
32], these measures result in the same ranking and querying of instances for binary classification problems. This practical issue, combined with curiosity about redundancies in training material, motivated us to develop a data selection strategy that is guided by the maximum entropy principle to choose valuable samples.
4.3. Maximum Entropy Principle
The maximum entropy principle is a method based on information theory, aimed at inferring the maximum entropy distribution from a known data distribution in order to minimize bias. In active learning, we used the maximum entropy principle to select the most informative samples for training models and to achieve the best results.
Entropy is defined as the uncertainty of random variables. For discrete random variable
, if it can take the possible value from
, then its entropy is defined as Formula (6).
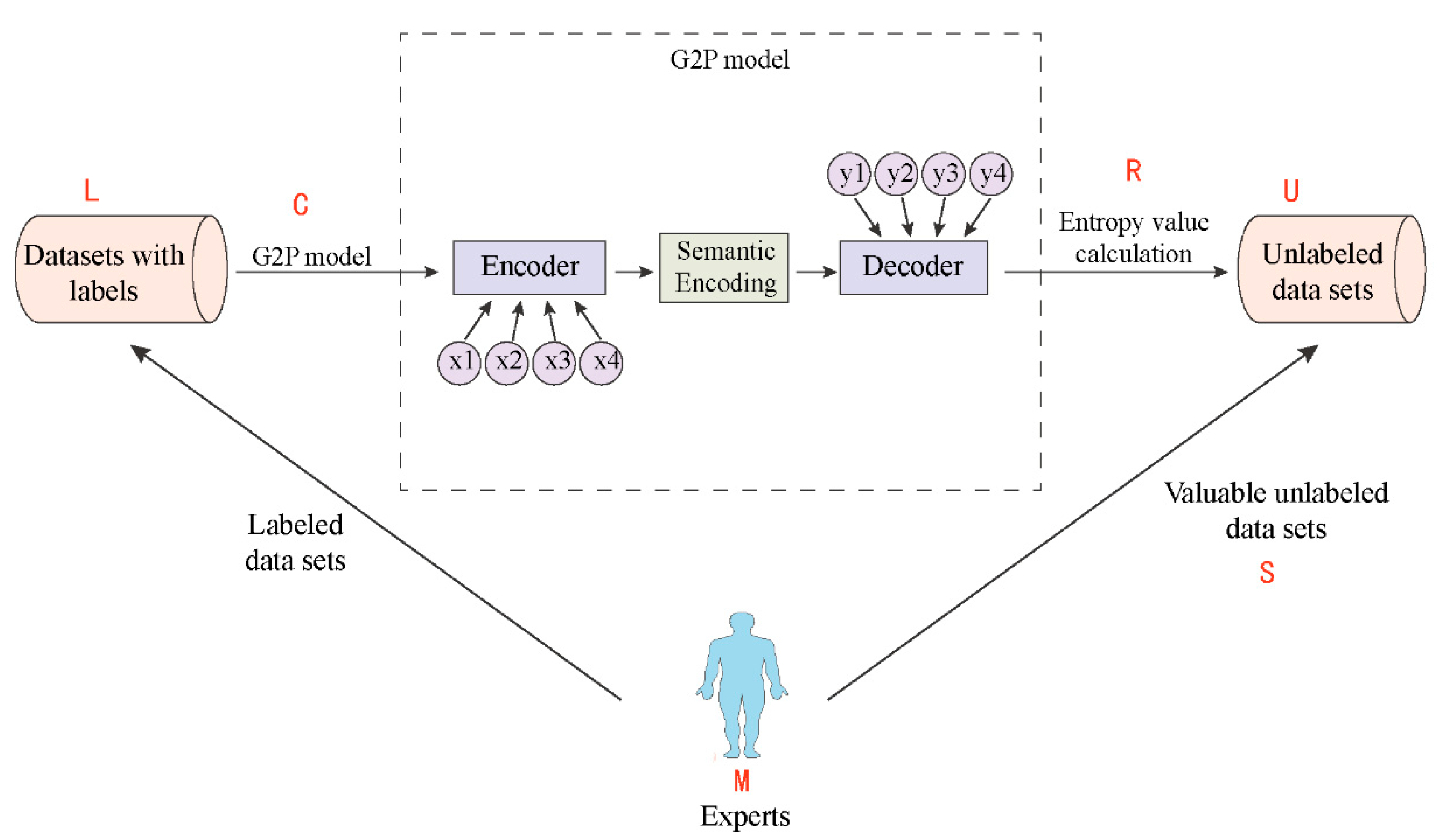
In this work, we used a grapheme-to-phoneme (G2P) model to predict phonemes for unannotated words, and obtained the predicted phonemes sequence along with the maximum probability of each predicted phoneme. To select the samples for labeling, we calculated the entropy value for each sample and ranked them in descending order. The sample with the highest entropy value, which has the greatest potential to improve the model, is then given to an expert for correction and labeling. By using a small number of high-value samples, our approach can improve model performance, greatly reduce the workload of expert labeling, and lower the construction cost of pronunciation dictionaries.
Assuming the grapheme sequence corresponding to sample
is [
] and the predicted probability vector corresponding to phoneme sequence is [
], the entropy value
of sample
, is calculated by Equation (7).
Calculate the probability vector
for the predicted phoneme at location
by using Equation (8).
is the weight of the current hidden state .
4.4. Submodular Function
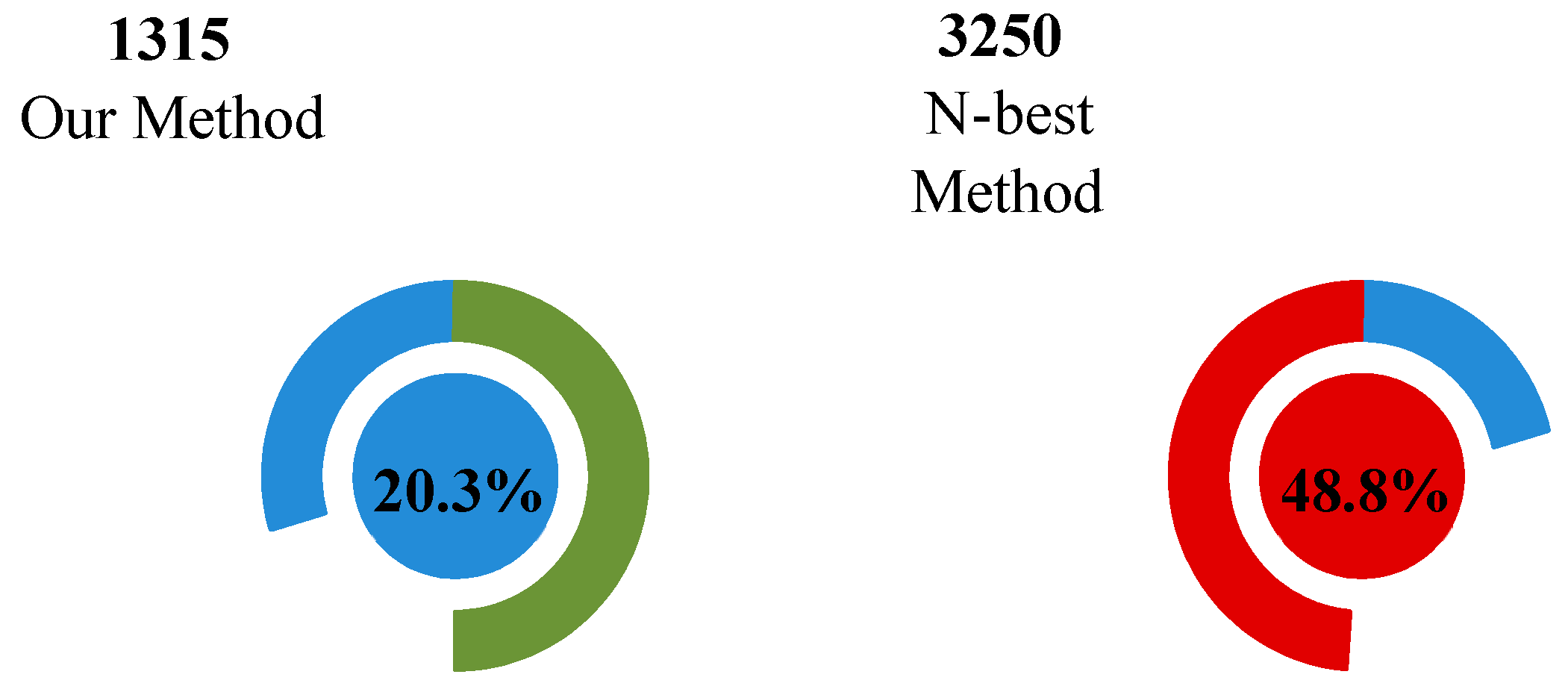
Most active learning methods select one valuable sample at a time for labeling, which is referred to as the non-batch method. However, this method is slow because the recognizer is retrained for each selected sample, and it cannot perform simultaneous multi-expert online labeling. In contrast, batch active learning methods can select multiple unlabeled samples at one time [
32,
33,
34]. However, using only a single sample selection strategy in batch active learning can lead to poor results, as the selected samples may have a high information similarity (e.g., using the N-best method). To select the optimal subset of samples that represent the overall dataset, we optimized the sample selection problem using submodular function theory [
35]. Specifically, we investigated the objective function of the near-optimal set of pronunciation dictionary samples and showed that our function had the submodularity property, which allowed for active learning so as to obtain a near-optimal subset of the corpus using a greedy algorithm. For the classifier, the goal of batch active learning is to form a set
of
unlabeled samples per iteration after user labeling, which is added to training set
. By retraining the classifier, the classifier can achieve the maximum performance improvement.
In active learning, the use of the maximum entropy principle as an evaluation criterion aims to select the most informative data to train the model and to achieve optimal results. This objective function can be represented as follows:
In this equation,
quantifies the uncertainty of the target variable
given a known set of variables
, using the concept of entropy. The probability distribution of the target variable y is denoted by
, and
represents the conditional probability distribution of
given a known set of variables
. The objective of this function is to maximize the uncertainty of the target variable
given a set of samples
. In the process, it is often necessary to select the next sample with the highest information content from a sample set [
36]. The criterion for such a selection is to choose a sample that maximizes the uncertainty of the target variable
, because this sample can provide the most informative new data that will facilitate a better understanding of the relationship between the target variable
and the input variables. This, in turn, helps improve the performance of the model by enhancing its ability to learn from the data.
Regarding submodular functions, they are a special class of functions that possess important properties of monotonicity and diminishing marginal returns. In other words, function satisfies the following two conditions:
1. Monotonicity: For any sets and element, the function f satisfies the inequality .
2. Diminishing marginal returns: For any set and element , the function satisfies the inequality for any subset , such that .
Now, we will prove that the maximum entropy function
is a submodular function. Firstly, let us prove the monotonicity of
. For any
and element
, we have:
As the logarithmic function is a concave function, according to Jensen’s inequality, we have the following:
Therefore, we have the following:
Next, we prove that
satisfies the property of diminishing marginal returns. For any
and element
, we need to prove the following:
where
and
.
According to the definition of
, we have the following:
Therefore, we can rewrite the above equation as follows:
Adding
to both sides of the above equation, we obtain the following:
After simplification, we obtain the following:
We decompose the exponents of each of the two terms on the right-hand side of the above equation as follows:
Substituting into the above equation, we obtain the following:
By applying the concavity of the logarithmic function and Jensen’s inequality, we can obtain the following:
As the function is convex, according to Jensen’s inequality, we have the following:
Substituting into the above equation, we obtain the following:
Simplifying the above equation, we obtain the following:
Therefore, we demonstrate that is a marginally diminishing function. As is a continuous function that satisfies the marginal diminishing property and range restriction, it is a submodular function.
In this way, we demonstrate that is a submodular function, allowing us to use a greedy algorithm for selecting an optimal subset of samples. Specifically, we can select the next sample to query by computing the marginal gain for each element. We iteratively add elements to the sample set until the desired size is reached.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}