
RepNet: A Lightweight Human Pose Regression Network Based on Re-Parameterization

Abstract
:1. Introduction
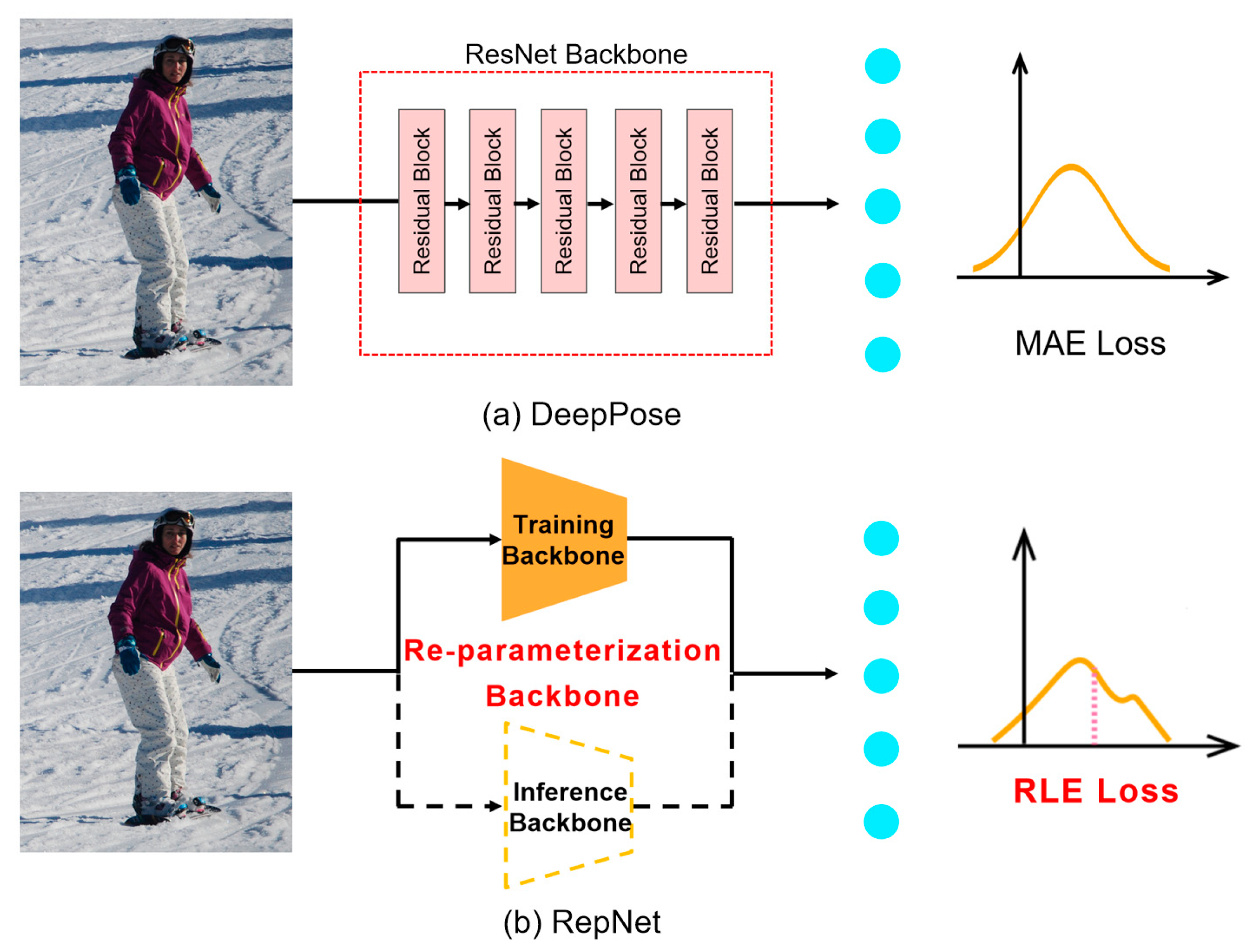
- In this paper, we propose a lightweight human pose regression framework that uses an end-to-end network design without a post-processing module, and can directly specify the coordinates of keypoints. The multi-parameterized module is adopted to reconstruct the main part of the convolution, while the well-designed training structure is used to improve the training performance. Simplifying the structure of the network also improves the reasoning efficiency;
- To solve the problem of the loss of precision in a simple model, the advanced idea of residual likelihood estimation is introduced in this paper. Good estimation performance can be realized by learning the underlying data distribution. RepNet achieves 63.4 AP with a parameter of 7.17 M on the COCO dataset, and the real-time performance can reach 70 FPS on RTX 3090.
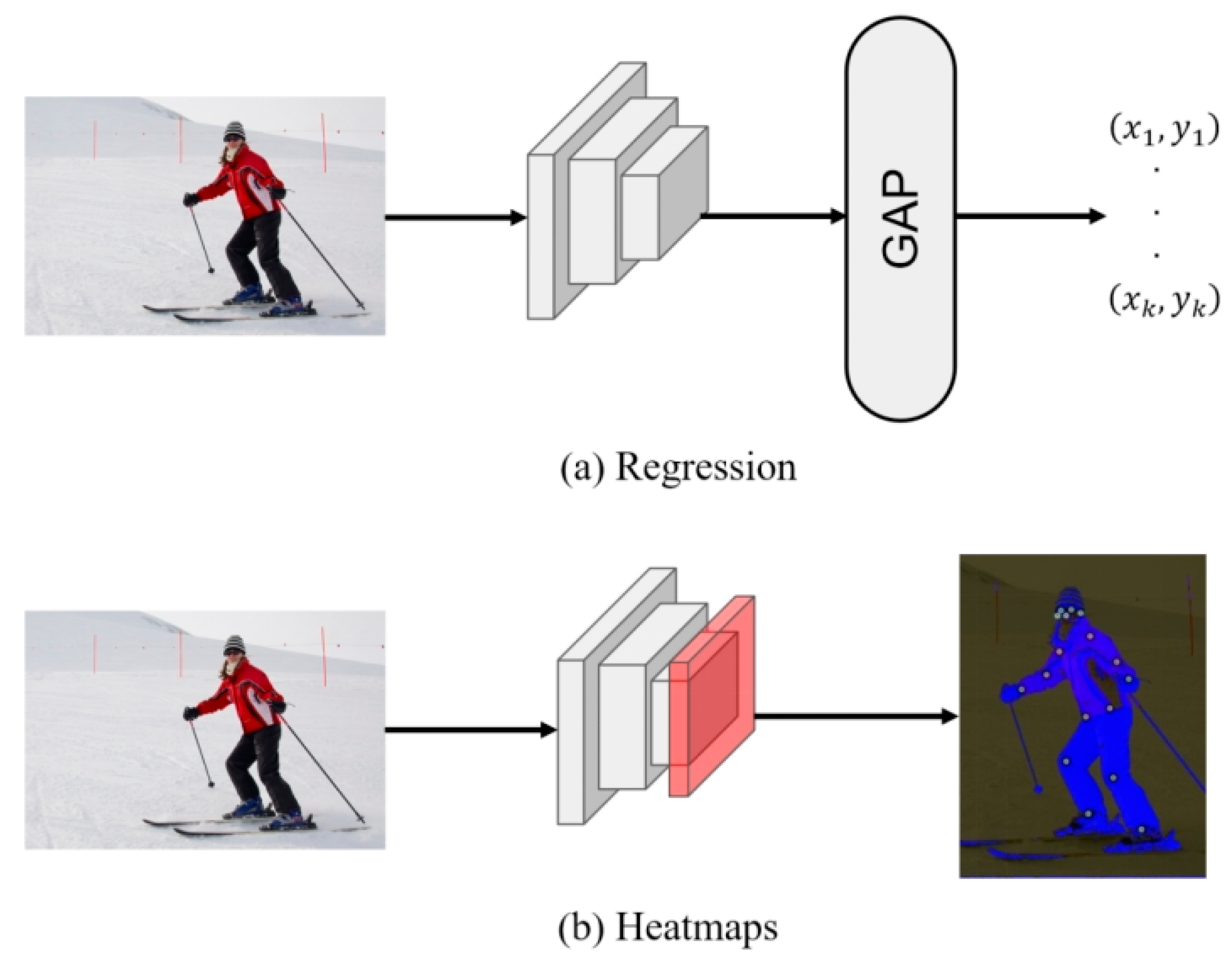
2. Related Work
3. Method
3.1. Networking Architecture
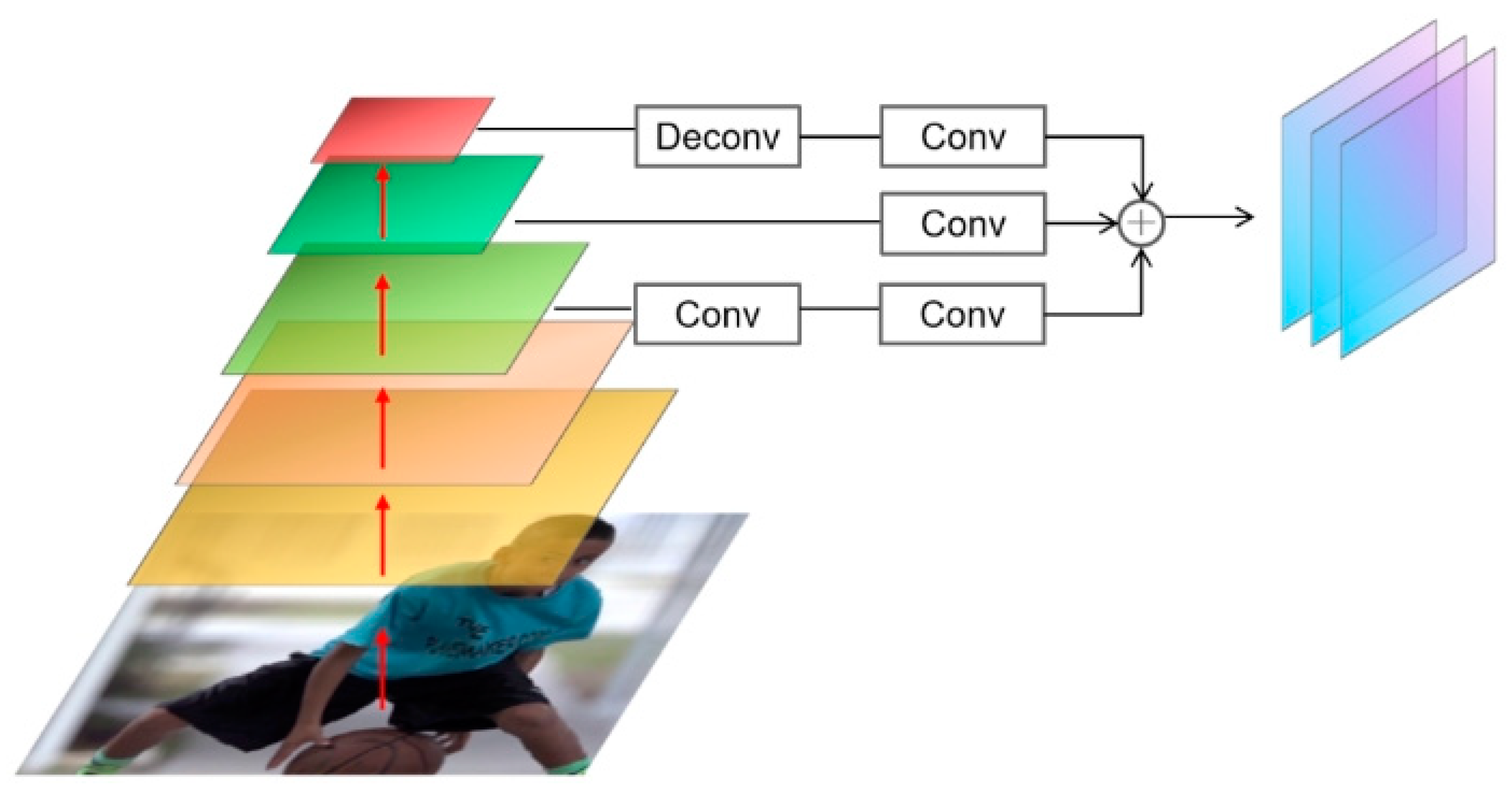
3.2. Multi-Parameter Trunk and Multi-Level Feature Fusion
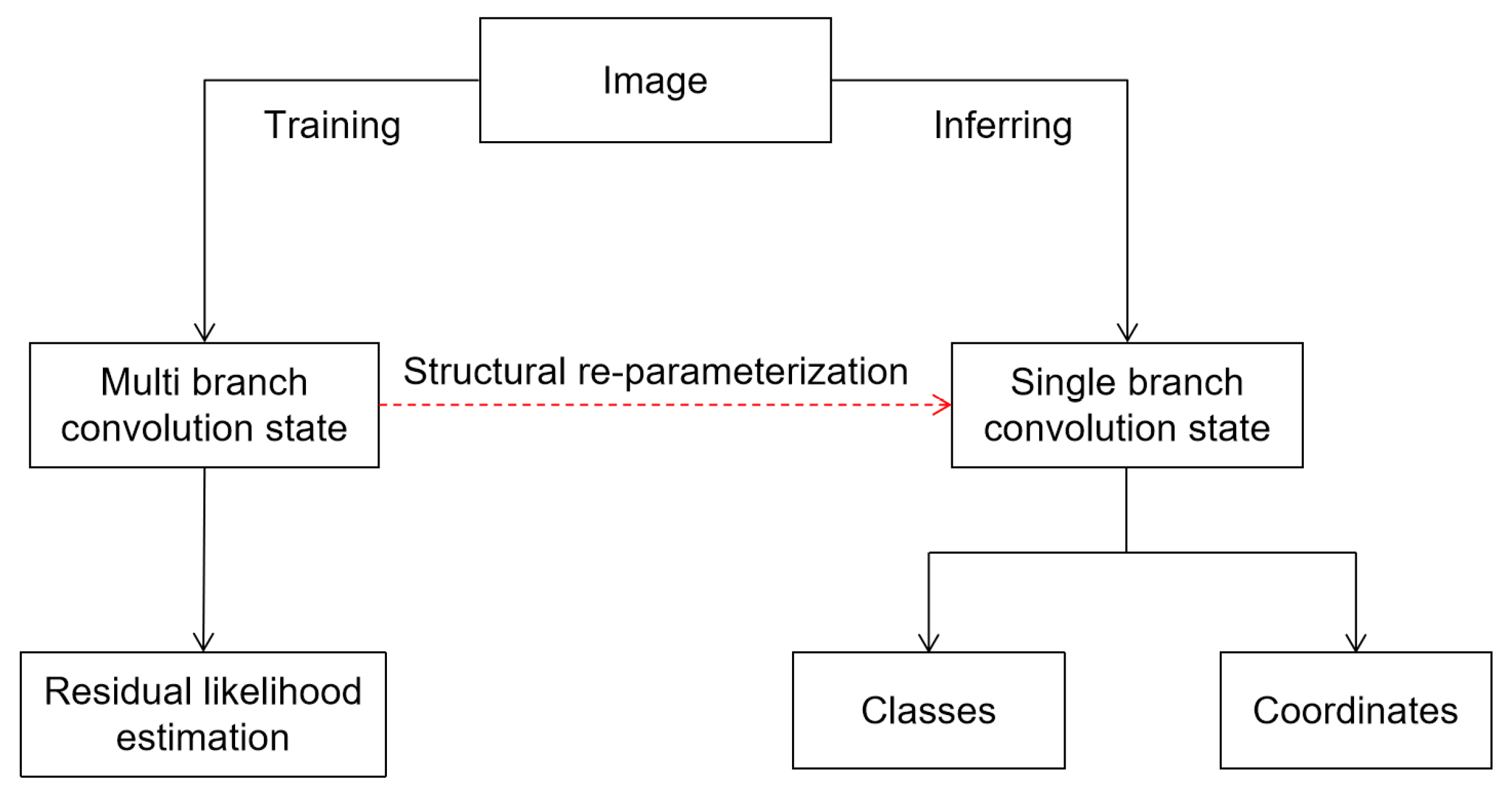
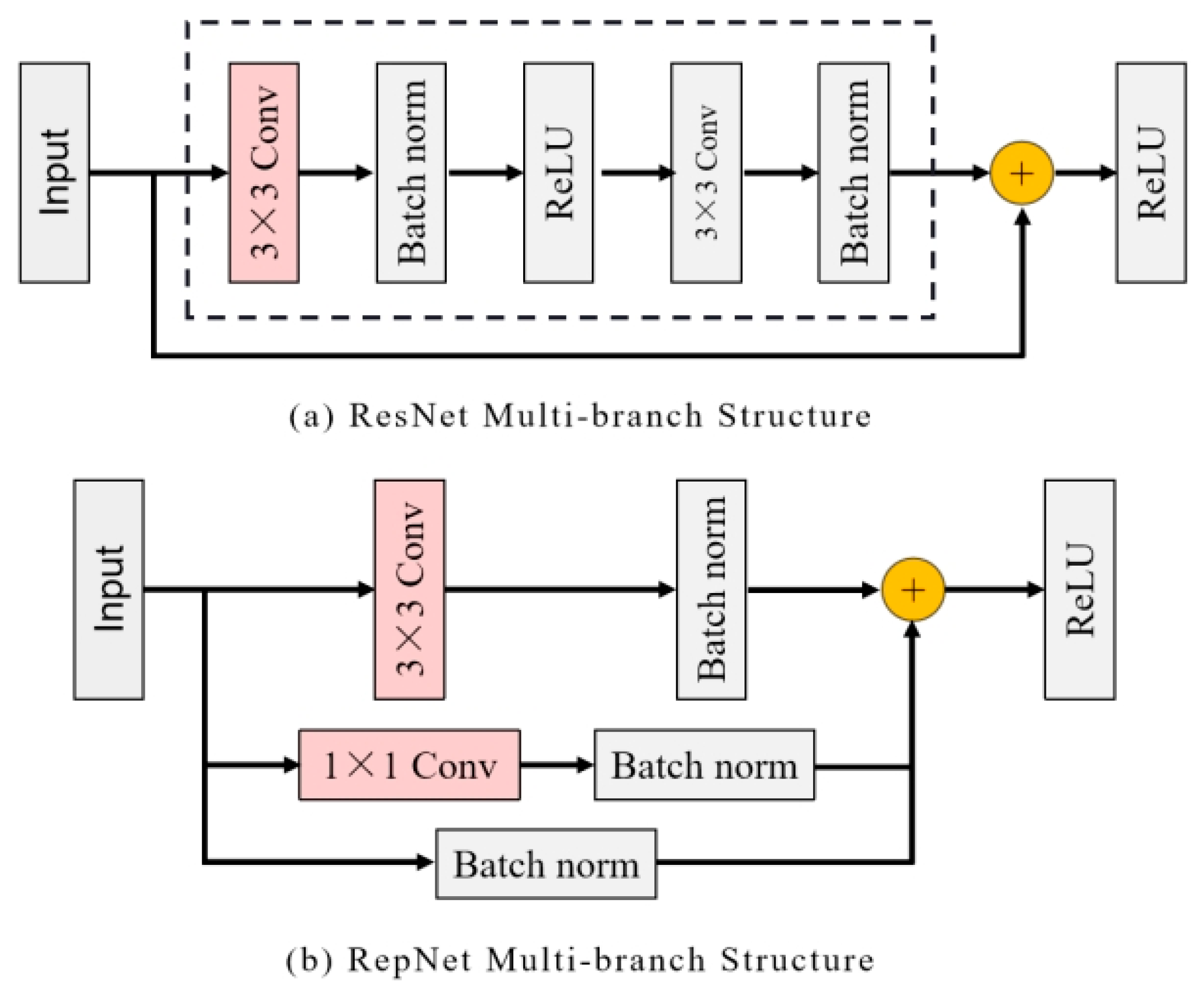
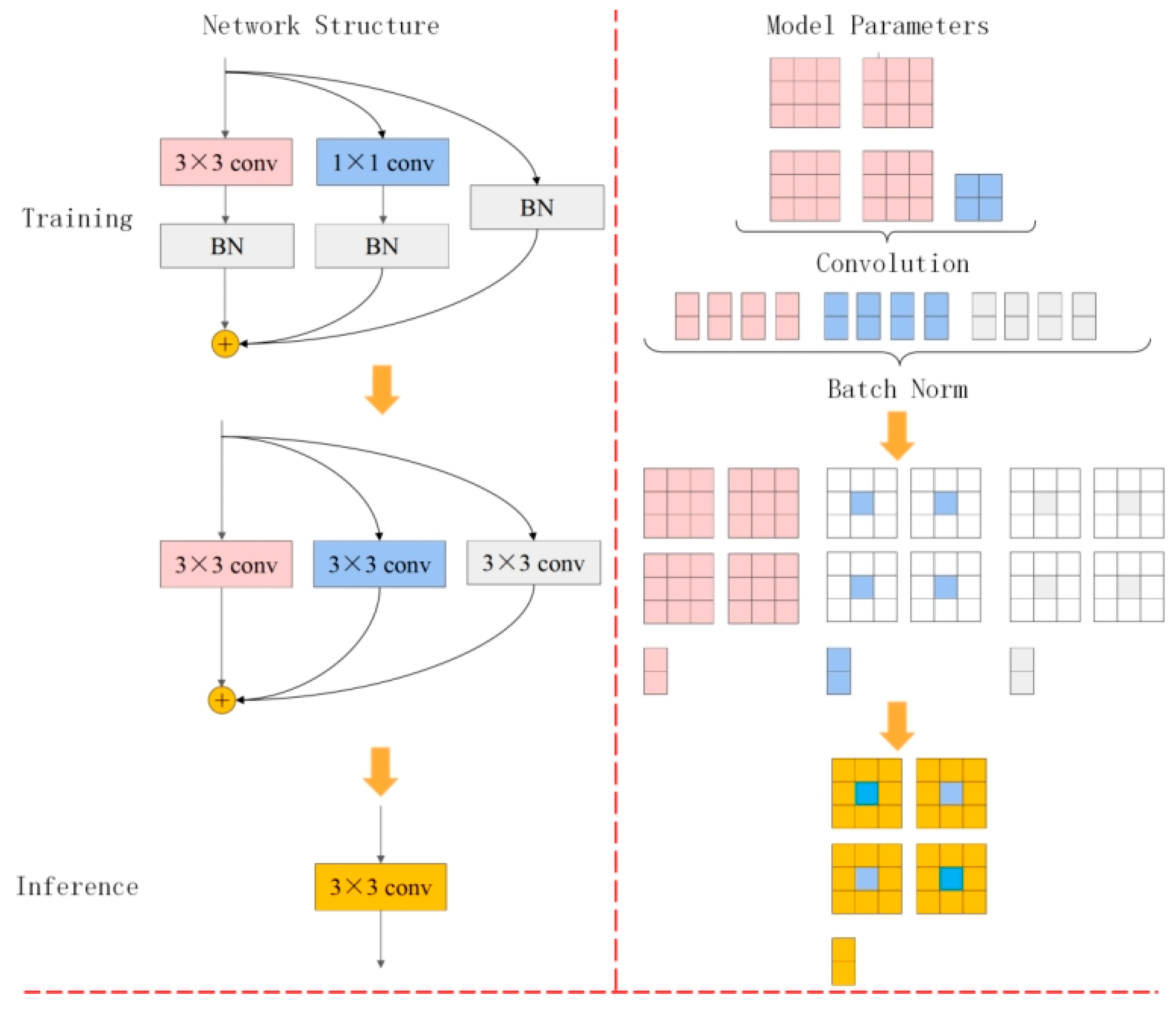
3.2.1. Multi-Branch Structure during Training
3.2.2. Re-Parameter Structure in Inferring
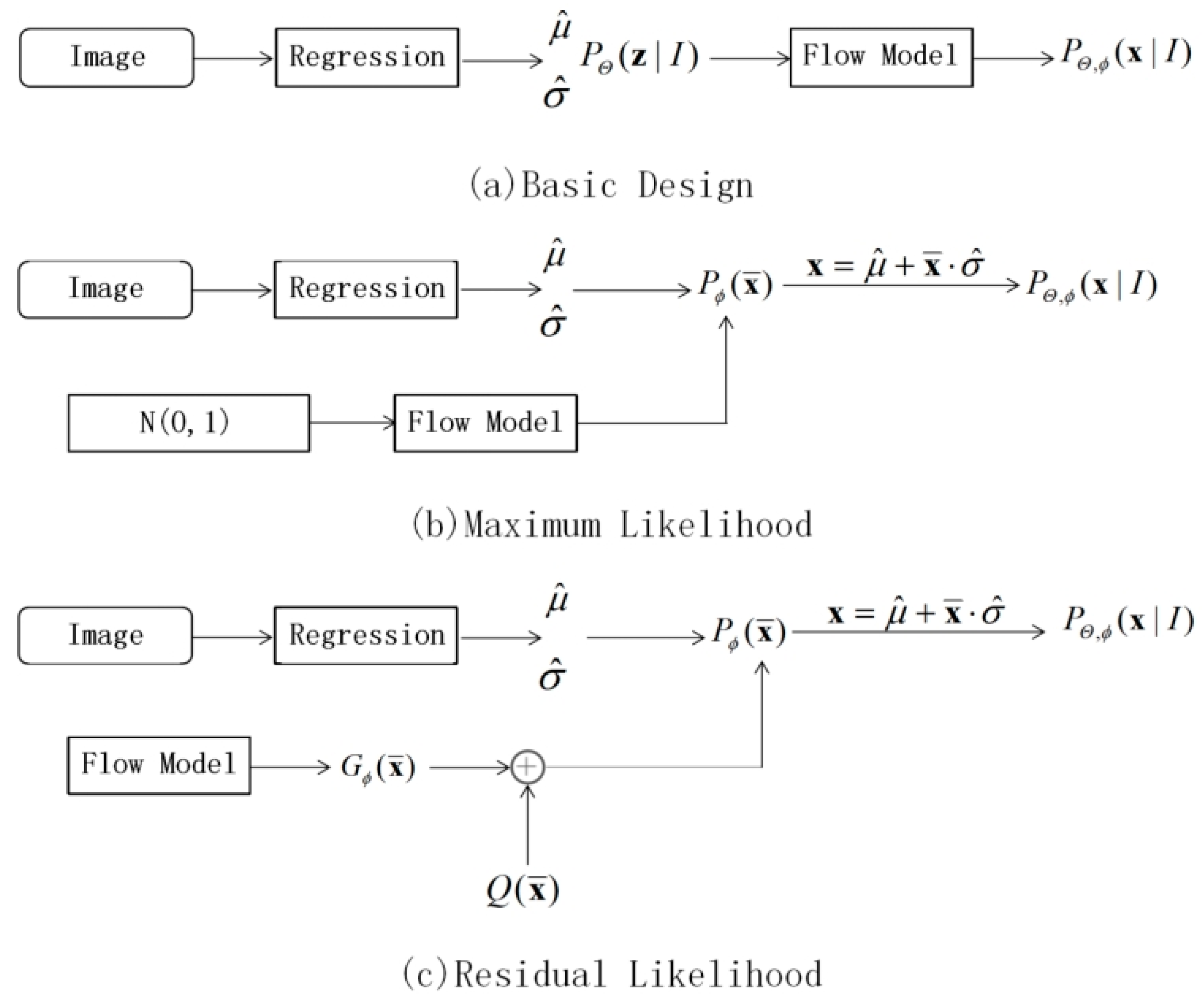
3.3. Residual Log-Likelihood Estimation
3.3.1. Maximum Likelihood Estimation
3.3.2. Flow Generation Model
4. Experiment
4.1. Implementation Details
4.2. Experiment Results
4.3. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep learning-based human pose estimation: A survey. arXiv 2020, arXiv:2012.13392. [Google Scholar] [CrossRef]
- Munea, T.L.; Jembre, Y.Z.; Weldegebriel, H.T.; Chen, L.; Huang, C.; Yang, C. The progress of human pose estimation: A survey and taxonomy of models applied in 2D human pose estimation. IEEE Access 2020, 8, 133330–133348. [Google Scholar] [CrossRef]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3. 6M: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, American, 2–7 February 2018; Volume 32. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 12026–12035. [Google Scholar]
- Duan, H.; Zhao, Y.; Chen, K.; Lin, D.; Dai, B. Revisiting Skeleton-based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 2969–2978. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–29 June 2014; pp. 3686–3693. [Google Scholar]
- Li, J.; Wang, C.; Zhu, H.; Mao, Y.; Fang, H.S.; Lu, C. CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 19–20 June 2019; pp. 10863–10872. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative Embedding: End-to-End Learning for Joint Detection and Grouping. Adv. Neural Inf. Process. Syst. 2016. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7291–7299. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5386–5395. [Google Scholar]
- Newell, A.; Yang, K.; Jia, D. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam; Amsterdam, The Netherlands, 11–14 October 2016, Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 19–20 June 2019; pp. 5703–5963. [Google Scholar]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1653–1660. [Google Scholar]
- Zhou, X.; Wang, D.; Krhenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Sirisha, M.; Sudha, S.V. Object Detection Using Deep Learning CenterNet Model with Multi-Head External Attention Mechanism. Int. J. Image Graph. 2022, 2450021. [Google Scholar] [CrossRef]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-Aware Coordinate Representation for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7093–7102. [Google Scholar]
- Huang, J.; Zhu, Z.; Guo, F.; Huang, G. The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5700–5709. [Google Scholar]
- Li, J.; Bian, S.; Zeng, A.; Wang, C.; Pang, B.; Liu, W.; Lu, C. Human pose regression with residual log-likelihood estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11025–11034. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human Pose Estimation with Iterative Error Feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4733–4742. [Google Scholar]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral Human Pose Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 529–545. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, 23 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor DETR: Query Design for Transformer-Based Object Detection. arXiv 2021, arXiv:2109.07107. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. TransPose: Keypoint Localization via Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11802–11812. [Google Scholar]
- Li, K.; Wang, S.; Zhang, X.; Xu, Y.; Xu, W.; Tu, Z. Pose Recognition with Cascade Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 1914–1953. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. TokenPose: Learning Keypoint Tokens for Human Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11313–11322. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using real nvp. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4724–4732. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 10440–10450. [Google Scholar]
- Fangyun, W.; Xiao, S.; Hongyang, L.; Jingdong, W.; Stephen, L. Point-set anchors for object detection, instance segmentation and pose estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Phase | Output Size | Channel Numbers of RepNet-A | Channel Numbers of RepNet-B |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 |
| Method | Backbone | Input Size | AP | AP50 | AP75 | APM | APL | AR |
|---|---|---|---|---|---|---|---|---|
| Heatmap-based | ||||||||
| OpenPose | PAF | — | 65.3 | 85.2 | 71.3 | 62.2 | 70.7 | — |
| CPM | CPM | 65.1 | 86.4 | 72.9 | 61.9 | 71.6 | 71.0 | |
| Lite-HRNet | Lite-HRNet | 67.5 | 88.0 | 75.3 | 64.6 | 73.3 | 73.5 | |
| SimpleBaseline | ResNet-50 | 72.2 | 89.3 | 78.9 | 68.1 | 79.7 | 77.6 | |
| HRNet | HRNet | 75.8 | 90.6 | 82.7 | 71.9 | 82.8 | 81.0 | |
| Regression-based | ||||||||
| DeepPose | ResNet-50 | 54.0 | 82.3 | 65.9 | 55.2 | 65.0 | 68.5 | |
| Integral | ResNet-50 | 63.3 | 85.9 | 70.3 | 59.3 | 71.5 | 72.9 | |
| PointSetNet | ResNeXt | — | 65.7 | 85.4 | 71.8 | — | — | — |
| CenterNet | Hourglass | — | 64.0 | — | — | — | — | — |
| RepNet-A | RepVGG | 63.4 | 85.1 | 69.9 | 60.2 | 69.6 | 68.7 | |
| RepNet-B | RepVGG | 66.1 | 86.5 | 73.5 | 62.7 | 72.4 | 71.1 | |
| Methods | Parameter Acquisition | GFLOPs | AP | AR | GPU Speed | CPU Speed | Model Size |
|---|---|---|---|---|---|---|---|
| OpenPose | 49.8 M | 136.0 | 65.3 | — | 656 ms | 881 ms | 199.5 M |
| Integral | 34.0 M | 7.28 | 63.3 | 72.9 | 28 ms | 288 ms | 136.7 M |
| DeepPose | 23.58 M | 4.04 | 54.0 | 68.5 | 24 ms | 189 ms | 97.0 M |
| Lite-HRNet | 1.76 M | 0.42 | 67.5 | 73.5 | 182 ms | 347 ms | 7.2 M |
| MobileNet | 2.36 M | 0.31 | 59.3 | 64.4 | 22 ms | 359 ms | 16.1 M |
| ShuffleNet | 1.02 M | 0.14 | 51.1 | 56.6 | 26 ms | 128 ms | 4.1 M |
| YOLOv7-pose | 80.2 M | 101.6 | 71.4 | 77.6 | 30 ms | 561 ms | 153 M |
| RepNet-A | 7.17 M | 1.49 | 63.4 | 68.7 | 14 ms | 32 ms | 27.4 M |
| RepNet-B | 11.65 M | 2.32 | 66.1 | 71.1 | 15 ms | 40 ms | 44.5 M |
| Method | Backbone | Hea | Sho | Elb | Wri | Hip | Kne | Ank | Mean | Mean0.1 |
|---|---|---|---|---|---|---|---|---|---|---|
| Heatmap-based | ||||||||||
| Lite-HRNet | Lite-HRNet | 96.2 | 94.6 | 86.9 | 80.6 | 87.1 | 82.0 | 76.9 | 86.9 | 31.2 |
| Simple- Baseline | Mobile- Net | 95.2 | 93.4 | 85.8 | 78.4 | 85.9 | 79.3 | 74.3 | 85.4 | 27.1 |
| Simple- Baseline | ResNet-50 | 96.3 | 95.2 | 88.6 | 83.3 | 87.3 | 83.5 | 78.9 | 88.2 | 32.8 |
| HRNet | HRNet-W32 | 97.1 | 95.9 | 90.3 | 86.4 | 89.1 | 87.1 | 83.3 | 90.3 | — |
| TransPose | HRNet-W32 | — | — | — | — | — | — | — | 90.3 | 41.6 |
| Regression-based | ||||||||||
| DeepPose | ResNet-50 | 93.5 | 92.9 | 82.7 | 73.9 | 85.6 | 75.4 | 66.1 | 82.5 | 20.5 |
| RLE | ResNet-50 | — | — | — | — | — | — | — | 85.5 | 26.7 |
| PRTR | ResNet-50 | 94.6 | 93.1 | 83.1 | 74.1 | 84.7 | 74.7 | 69.4 | 82.8 | 22.6 |
| PRTR | ResNet-152 | 96.1 | 94.4 | 86.1 | 78.5 | 87.6 | 81.8 | 74.6 | 86.3 | 26.8 |
| RepNet-A | RepVGG | 95.7 | 94.4 | 86.3 | 78.2 | 88.0 | 79.7 | 72.6 | 85.8 | 27.6 |
| RepNet-B | RepVGG | 95.7 | 95.0 | 87.0 | 79.7 | 88.1 | 81.5 | 74.7 | 86.7 | 29.2 |
| Method | Stage | The Number of Parameters | GFLOPs | Reasoning Speed (GPU/CPU) | Size of Model |
|---|---|---|---|---|---|
| RepNet-A | Training | 7.96 M | 1.49 | 36 ms/81 ms | 38.14 M |
| Reasoning | 7.16 M | 1.34 | 26 ms/50 ms | 27.38 M | |
| RepNet-B | Training | 12.95 M | 2.59 | 40 ms/115 ms | 57.52 M |
| Reasoning | 11.64 M | 2.32 | 28 ms/67 ms | 44.47 M |
| Method | The Number of Parameters | GFLOPs | Mean | [email protected] | Reasoning Speed (GPU/CPU) |
|---|---|---|---|---|---|
| ResNet + Direct Regression | 23.57 M | 4.04 | 82.5 | 20.5 | 33 ms/274 ms |
| ResNet + RLE | 23.69 M | 4.04 | 86.1 | 27.7 | 33 ms/277 ms |
| Multi-parameterized Structure + RLE | 7.16 M | 1.34 | 85.8 | 27.6 | 26 ms/50 ms |
| Method | Input Size | [email protected] |
|---|---|---|
| SimpleBaseline | 32.8 | |
| 15.7 | ||
| RepNet | 27.6 | |
| 17.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhou, Q. RepNet: A Lightweight Human Pose Regression Network Based on Re-Parameterization. Appl. Sci. 2023, 13, 9475. https://doi.org/10.3390/app13169475
Zhang X, Zhou Q. RepNet: A Lightweight Human Pose Regression Network Based on Re-Parameterization. Applied Sciences. 2023; 13(16):9475. https://doi.org/10.3390/app13169475
Chicago/Turabian StyleZhang, Xinjing, and Qixun Zhou. 2023. "RepNet: A Lightweight Human Pose Regression Network Based on Re-Parameterization" Applied Sciences 13, no. 16: 9475. https://doi.org/10.3390/app13169475
APA StyleZhang, X., & Zhou, Q. (2023). RepNet: A Lightweight Human Pose Regression Network Based on Re-Parameterization. Applied Sciences, 13(16), 9475. https://doi.org/10.3390/app13169475