1. Introduction
Extracting roads from high-resolution remote sensing imagery is pivotal for a myriad of applications [
1] encompassing traffic flow prediction [
2], disaster response [
3], and urban planning [
4]. Precise road identification can relay crucial information for these utilities [
5]. The task of road extraction in high-resolution imagery is central, not only due to its extensive application in urban planning and traffic management but also because of its inherent technical challenges [
6]. The diverse morphologies and textures of roads, ranging from straight paths and curves to intersections, compound this complexity [
7].
Deep Learning Evolution: With the advent of deep learning, Convolutional Neural Networks (CNNs) have achieved substantial success in classification, object detection, and segmentation, displaying competence in remote sensing road extraction [
8]. Nevertheless, due to road intricacies, traditional CNN architectures reveal limitations in such tasks. Fully Convolutional Networks (FCNs) outshine traditional CNNs for pixel-level tasks such as semantic segmentation [
9]. By avoiding the use of fully connected layers inherent in traditional CNNs, FCNs retain the spatial context of input images, leading to discernible improvements in pixel-level road extraction tasks that demand precise pixel classification. Although FCNs preserve spatial details, the spatial resolution of feature maps might degrade after repeated convolutions and pooling, impacting the segmentation accuracy of smaller or intricate features. In 2015, Ronneberger et al. proposed U-Net, designed with symmetric up-sampling and down-sampling pathways, facilitating the preservation of high-resolution feature maps [
10]. This design aids in generating precise object boundaries in segmentation results and showcases remarkable multi-scale feature fusion capabilities. To tackle accuracy degradation with increased network depth, He et al. (2015) introduced the ResNet structure [
11]. ResNet, with its residual connections, permits the training of profoundly deep neural networks, mitigating gradient vanishing issues and augmenting model performance, rendering it suitable for various image tasks, including segmentation. To synergize multi-scale information during training, Li et al. advanced the DeepLab series, employing Deep Convolutional Nets for semantic image segmentation [
12]. By incorporating Atrous Convolution and Conditional Random Field (CRF) techniques, DeepLab not only enhances segmentation quality but also elevates accuracy by fusing multi-scale convolutional feature maps with the global context. Building on the foundation of DeepLab v1, Liang-Chieh Chen and team introduced the ASPP module, which augments segmentation outcomes [
13]. However, challenges such as elevated computational complexity and limited performance improvement persist. Prioritizing multi-scale information retention for detailed task management, Jingdong Wang et al. proposed HRNet in 2019 [
14].
Attention Mechanism in Road Extraction: In 2014, Bahdanau et al. pioneered the incorporation of attention mechanisms in machine translation tasks, enabling models to “focus” on various segments of input sequences by attributing distinct weights to different positions [
15]. Since then, this mechanism has seen extensive applications across various deep learning tasks [
16]. MHA-Net employed attention mechanisms in segmentation tasks to manage multi-scale information, directing the model to efficiently capture key regional features [
17]. In 2020, Xin Wei and colleagues proposed EMANet, utilizing attention mechanisms to integrate features across scales, thereby enhancing the model’s capacity to discern semantic information at various scales. However, the efficacy of attention mechanisms can be contingent on the quality of the input data, potentially underperforming with subpar images. In 2021, Lu and team introduced scale-independent self-attention (ScaNet), gaining significant traction [
18]. This innovation permits the network to autonomously adjust feature weight mechanisms across spatial scales, hence better capturing long-range relationships within images. In road extraction tasks, such scale-independent self-attention facilitates the network in proficiently identifying road continuity and curvature, enhancing extraction accuracy [
19]. However, the attention mechanism also has the problem of large computational resource requirements. Aiming at this problem, some recent works have been improved. For example, RADANet proposed by Dai et al. uses a combination of deformable convolution and an attention mechanism, which can better express multi-scale features, and also designs a residual structure to reduce the amount of parameters [
20]. SDUNet proposed by Yang et al. integrates the spatial attention module in U-Net to enhance the local details and reduce the calculation amount of the attention module [
21]. Ghandorh et al. proposed a semantic segmentation framework using an adaptive channel attention module to improve the recall of road extraction [
22]. Wang et al. designed a dual-decoder structure, and at the same time they used the attention mechanism to enhance the expression of details and improve robustness in complex scenes [
23]. In the current research field, although the limitations of computing resources have been overcome to some extent, there is still room for improvement in the modeling of complex scenes in high-resolution remote sensing images [
24]. Deep learning methods perform well in this task but still face the challenge of capturing details and maintaining spatial continuity [
25]. Especially in the road extraction of high-resolution remote sensing images, it is often difficult for traditional deep learning models to balance these two factors [
25,
26].
In order to deal with these challenges, we designed a SAG multi-scale attention module based on multiple cutting-edge research studies and embedded it into the U-Net structure, so that the model can more efficiently fuse global and local information. Further, we propose MixerNet-SAGA, an innovative deep learning model that combines the powerful spatial feature extraction capabilities of ConvMixer blocks with a multi-scale attention mechanism. MixerNet-SAGA was originally designed to provide a more accurate and efficient road extraction strategy for high-resolution remote sensing images.
Our proposed MixerNet-SAGA offers several advantages:
Computational Efficiency: By amalgamating deep convolution with 1 x 1 convolution in the ConvMixer block, MixerNet-SAGA maintains superior performance while ensuring lower computational and parameter complexity.
Multi-Scale Feature Extraction: Its unique multi-scale attention mechanism allows for the capturing of road information across micro to macro levels, aptly adapting to remote sensing imagery of varied resolutions.
Enhanced Feature Representation: The combination of the ConvMixer block and multi-scale attention mechanisms facilitates efficient extraction and integration of spatial and channel information, augmenting feature expressivity.
Flexibility and Adaptability: The design of MixerNet-SAGA allows for seamless integration with other deep learning modules and techniques, ensuring adaptability across diverse remote sensing image processing tasks.
Robustness: By integrating a myriad of feature extraction and enhancement techniques, MixerNet-SAGA showcases commendable resilience in the face of intricate urban landscapes and varied road conditions.
This paper is structured as follows:
The Introduction delves into the challenges of road extraction from high-resolution remote sensing imagery and the limitations traditional deep learning models may encounter. We then present our innovative solution, MixerNet-SAGA, which melds the ConvMixer block with multi-scale attention mechanisms. In the Methods section, we elucidate the design and operation of MixerNet-SAGA, detailing core components such as the ConvMixer block and multi-scale attention mechanisms. The Experiments and Results sections showcase our model’s performance on two primary remote sensing datasets and benchmarks it against other leading road extraction models. This section validates the practical efficacy and superiority of MixerNet-SAGA. The Discussion section offers a deep dive into our findings, dissecting the strengths and potential limitations of MixerNet-SAGA, juxtaposing it against its peers. Finally, in the Conclusion, we encapsulate the central contributions and insights of this paper, proposing potential future research trajectories and enhancements.
2. Methods
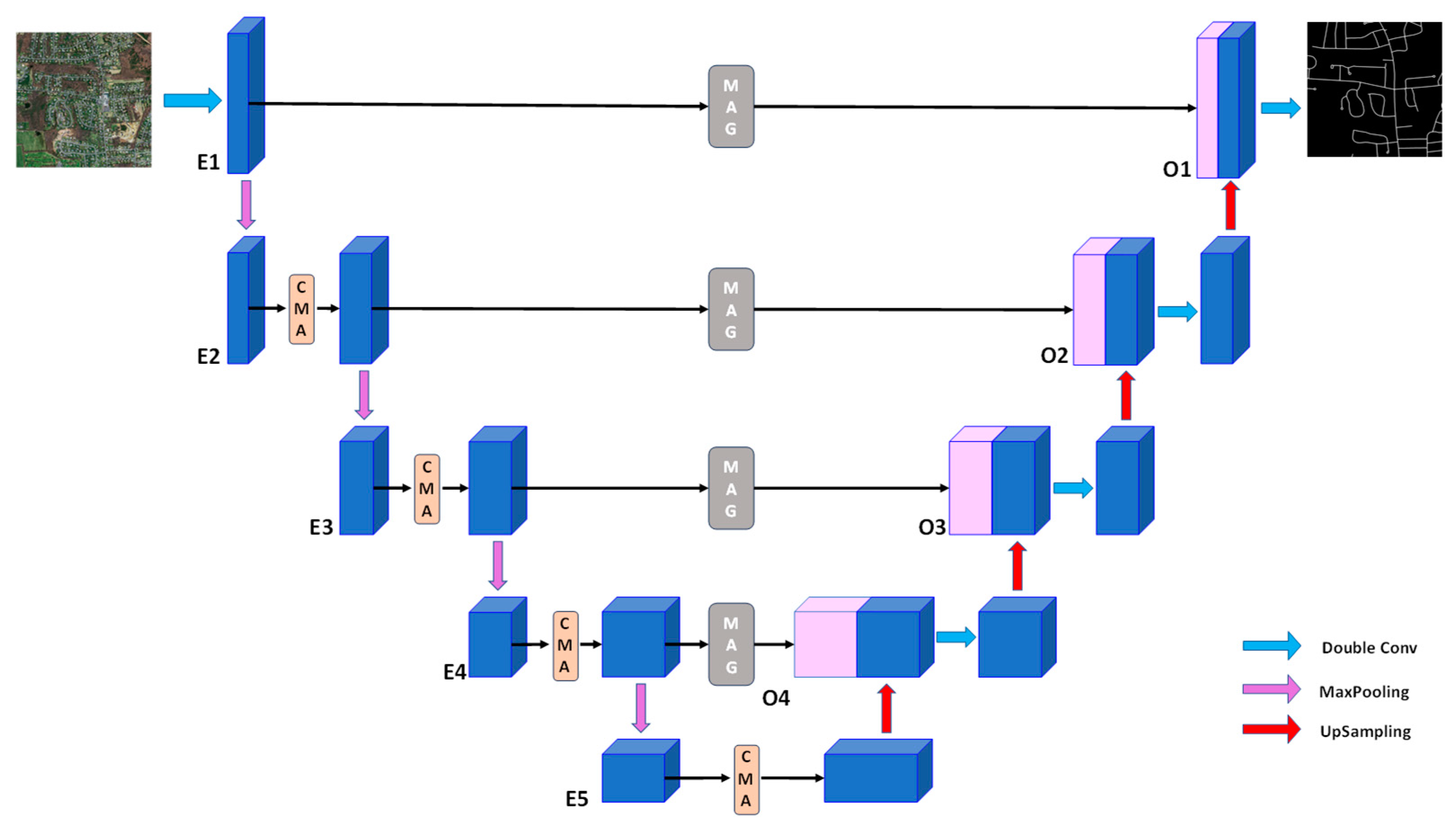
2.1. The Overall Architecture of MixerNet-SAGA
MixerNet-SAGA represents an advanced deep learning model building upon the foundational strengths of the U-Net architecture and introducing pivotal modifications tailored for high-resolution remote sensing image road extraction. The acclaim of U-Net stems from its symmetrical encoder–decoder layout, facilitating comprehensive feature extraction spanning from superficial to profound layers, while spatial information is retained via skip connections. This inherent design underpins U-Net’s exemplary performance in image segmentation tasks, especially when confronting remote sensing images imbued with intricate backgrounds and minute details [
27].
To further bolster its capabilities, we integrated the ConvMixer block during the encoder phase. This block marries the advantages of deep convolution with 1 × 1 convolutions, enabling enhanced capture and amalgamation of multi-scalar features while preserving computational efficiency. Such an amalgamation augments the model’s discriminative prowess, which is particularly essential in high-resolution remote sensing images where demarcations between roads and other elements—such as edifices, vegetation, or water bodies—can be indistinct. Furthermore, we have innovatively incorporated the SAG block within the skip connections—a cornerstone of U-Net—that merge superficial detail-oriented information with deeper semantic content. By deploying the SAG block within these junctions, there is a more agile fusion of diverse scalar features. Its multi-scale attention mechanism apportions variegated weights to features across scales, ensuring a harmonious equilibrium between global and local insights during data synthesis. This strategic integration is pivotal in enhancing the model’s capacity to discern road intricacies and morphologies, especially in regions riddled with intricate intersections or areas intersecting with other terrain elements.
In summary, MixerNet-SAGA, by capitalizing on U-Net’s merits and synergizing with the prowess of ConvMixer and SAG blocks, achieves significant performance elevation in road extraction tasks from high-resolution remote sensing imagery. These enhancements not only augment model accuracy but also fortify its resilience in complex scenarios. The architectural visualization of the network is depicted in
Figure 1.
2.2. Introduction to U-Net
U-Net, a landmark architecture in image segmentation, has displayed exceptional prowess owing to its symmetric encoder–decoder framework coupled with distinct skip connections [
28], especially when addressing intricate backgrounds and irregular objectives [
29]. The core design philosophy of this network lies in concurrently harnessing deep semantic insights and meticulous spatial details. However, when applied to remote sensing image analyses, notably in road extraction from complex scenarios, there remains room for refinement [
30].
In our presented MixerNet-SAGA model, we judiciously tailored the U-Net in the following ways to adeptly tackle the challenges of road extraction from remote sensing images:
Integration of the ConvMixer Module to the Encoder: This stands as the principal innovation within the MixerNet-SAGA framework. The ConvMixer module was crafted to bolster the network’s feature representation prowess, facilitating a more nuanced capture of intricate structures and information within remote sensing images. Consequently, in contrast to the traditional U-Net, MixerNet-SAGA holds a marked advantage in recognizing and addressing the diversity and complexity of remote sensing imagery.
Incorporation of the SAG Multi-Scale Attention Mechanism to Skip Connections: A further pivotal advancement is the adoption of the SAG multi-scale attention module. Its primary role is to adaptively balance features across different scales, thus seamlessly integrating global and local cues. This implies that MixerNet-SAGA can autonomously focus on salient regions within remote sensing images while preserving expansive contextual data.
Such innovative modifications confer clear advantages to MixerNet-SAGA. Through the ConvMixer module, the model is not only more efficient in feature extraction from remote sensing images but also possesses enhanced representation capabilities. Leveraging the SAG module, the model can more discerningly pinpoint and interpret salient and challenging areas within such images.
Therefore, given these enhancements, when tasked with intricate scenarios in remote sensing imagery, specifically in road extraction, MixerNet-SAGA, compared to the canonical U-Net, not only maintains computational efficiency but also significantly outperforms it in terms of feature extraction precision, robustness, and stability.
2.3. Convolution
Amid the advancements in deep learning and computer vision, convolutional operations have emerged as quintessential, predominantly in image processing endeavors [
31]. In this section, we delve into several pivotal convolutional methodologies employed in this study, methodologies that have proven instrumental in augmenting model performance and attenuating computational intricacies.
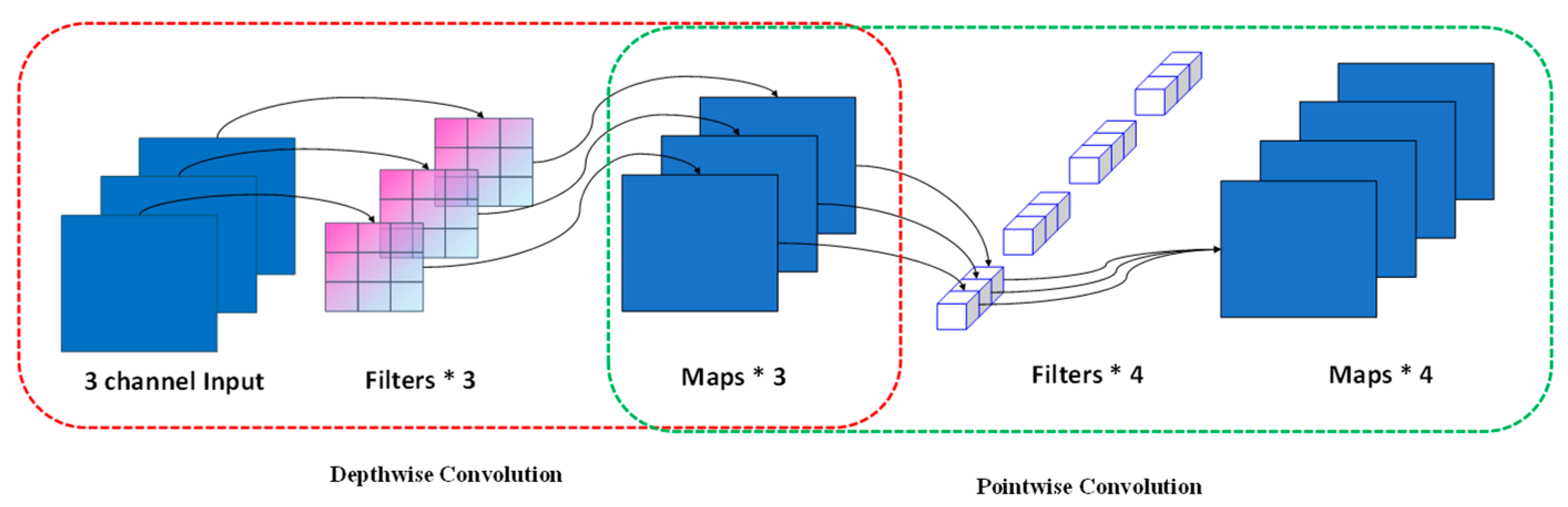
2.3.1. Depthwise Separable Convolution
Depthwise separable convolution is a special convolution operation that decomposes the traditional convolution operation into two separate parts: depthwise convolution and pointwise convolution.
In the realm of deep learning, pointwise convolution, typically characterized as 1 × 1 convolution, stands out as an elementary yet potent instrument [
32]. While its design inherently precludes the capture of spatial information, it demonstrates exemplary efficacy in the inter-channel amalgamation of features. This convolution paradigm can be likened to a fully connected layer, orchestrated to integrate and reconfigure features across disparate channels [
33]. Within the framework of depthwise separable convolutions, pointwise convolution often succeeds depthwise convolution, ensuring a comprehensive blend of inter-channel features. The computational procedure of pointwise convolution is delineated in Equation (1).
where
represents the nth channel of the output,
is the channel index, and
is the 1 × 1 convolution kernel for the nth output channel.
In depthwise convolution, each input channel has an independent convolution kernel, which means that the features of each channel are processed independently, thus capturing the spatial information of each channel [
34]. The calculation process is shown in Formula (2).
where
represents the input data,
represents the channel index, * represents the convolution operation, and
represents the
th convolution kernel.
Depthwise separable convolution, a transformative innovation in convolutional designs, emphasizes depthwise convolution followed by pointwise convolution for the seamless integration of channel-wise features. The cardinal advantage of this architecture lies in its capacity to markedly truncate both the parameter count and computational intricacies, all while preserving a performance parallel to conventional convolutions [
35]. This convolution paradigm has garnered particular acclaim in mobile and edge computing scenarios, chiefly attributed to its prowess in facilitating efficient forward propagation under the constraints of limited computational resources. The inherent merit of depthwise separable convolution is its significant reduction in computational demands and parameter volume. To elucidate, consider a comparative evaluation between standard convolution and depthwise separable convolution when processing input dimensions of
D ×
D, input channels numbered at
M, output channels at
N, and with a convolutional kernel size of
K ×
K. The ratio of computational magnitude is represented in Equation (3). A schematic representation of this architecture is presented in
Figure 2.
where
represents the computational cost of standard convolution, and
represents the computational cost of depthwise separable convolution.
Within our MixerNet-SAGA model, depthwise separable convolutions play a pivotal role in structuring the ConvMixer module. To elaborate, the ConvMixer module initially employs depthwise convolution to independently extract features from each channel, thereby harnessing a richer spatial representation. This is subsequently followed by a pointwise convolution, serving to integrate features across these channels. The incorporation of depthwise separable convolution in the MixerNet-SAGA model stems from several key considerations:
Computational Efficiency: Depthwise separable convolutions, while preserving feature extraction capabilities, remarkably reduce the model’s parameter count and computational intricacy. This efficiency affords a discernible edge to our design within the ConvMixer module.
Feature Augmentation: The deployment of depthwise convolution ensures optimal spatial feature extraction within each individual channel. Concurrently, pointwise convolution guarantees seamless integration of these channel-specific features.
Model Expressiveness: The strategic amalgamation of these convolutional techniques not only alleviates computational burdens but also amplifies the model’s capacity for feature representation, which is especially salient in complex scenarios within remote sensing imagery.
In summation, by astutely introducing depthwise separable convolution into the ConvMixer module, MixerNet-SAGA not only champions computational efficiency but also enhances performance in the context of road extraction from remote sensing images. Experimental outcomes further attest to the efficacy and pragmatism of our design approach.
2.3.2. Dilated Convolution
Dilated convolution, alternatively referred to as convolution with dilation rates, represents a pivotal augmentation to traditional convolutional operations [
36]. Its novelty lies in the introduction of predetermined "intervals" within the convolutional kernel, enabling an enlargement of its receptive field without necessitating an increase in parameter count. Given the high-resolution and intricate details inherent in remote sensing imagery, we employed dilated convolutions in the intermediate layers of our network model. This strategy aims to ensure the expansive contextual information is captured during deep feature extraction, a procedure paramount for distinguishing minute roads from other complex structures.
Multiple considerations underpin our choice of dilated convolution within the model. Primarily, objects and scenarios within remote sensing imagery frequently exhibit multiscale attributes. Employing dilated convolution aids the model in adeptly capturing such multiscale nuances. Moreover, dilated convolution permits the assimilation of vast contextual scopes, transcending merely local features—an aspect crucial for tasks such as differentiating roads from their surrounding environments. Additionally, dilated convolution offers a strategy to efficaciously broaden the receptive field without intensifying the model’s computational demand. In essence, dilated convolution furnishes our model with a harmonious balance between fine-grained detail and a broad field of view, which is indispensable for processing high-resolution remote sensing images.
2.4. ConvMixer Block
The ConvMixer block, a centerpiece in our study, draws inspiration from the synergy of depthwise convolution and 1 × 1 convolution. The overarching aim of this architecture is to capture and amalgamate features across various scales, all without imposing undue computational burdens. In traditional convolutional dynamics, depthwise convolution (also identified as depthwise separable convolution) is a distinctive type wherein each input channel is catered to by an independent convolutional kernel. This design empowers the model to discern spatial nuances within each channel, thereby accentuating subtle feature disparities. Subsequently, 1 × 1 convolution steps in to orchestrate a seamless blend of these features, ensuring an integrative assimilation of insights spanning multiple channels. Within the MixerNet-SAGA paradigm, the ConvMixer block initiates with depthwise convolution. The linchpin here is the independent convolutional operation executed on each input channel, fortifying the model’s feature extraction prowess without amplifying the parameter count. Following this, 1 × 1 convolution is deployed to intermix these features channel-wise, ensuring that the model captures not only granular details but also holistic semantic nuances. A schematic representation of the network structure is presented in
Figure 3.
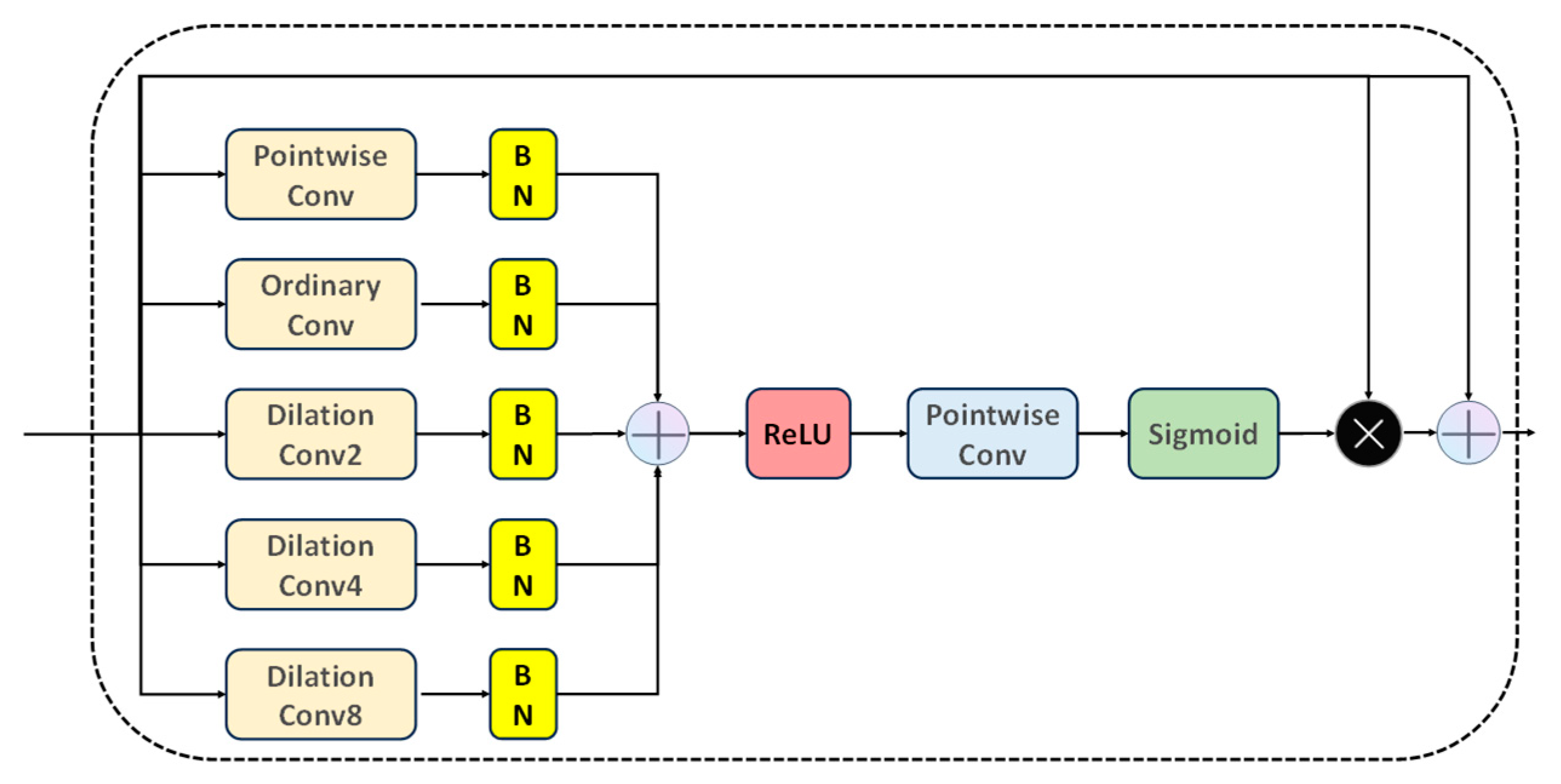
2.5. SAG Block
In our quest to augment the model’s capabilities for feature extraction and integration, we conceived a multi-scale attention mechanism, christened as the Scaled Attention Gate (SAG). The SAG module implements convolutional feature extraction across five diverse receptive fields: pointwise convolution with a 1 × 1 kernel; standard convolution with a 3 × 3 kernel; and dilated convolution with dilation rates of 2, 4, and 8, respectively. Each convolutional process is succeeded by a batch normalization layer. All convolution types yield feature maps of consistent dimensions. Post-concatenation of these maps, they undergo a ReLU activation followed by a pointwise convolution to distill valuable features. The computational proceedings of the SAG module are delineated in Equations (4) and (5).
where
represents the connected feature map,
represents the input feature map,
represents pointwise convolution,
represents ordinary convolution,
represents the expansion convolution with an expansion rate of 2, and
represents the expansion with an expansion rate of 4. The convolution product,
, represents an expansion convolution with an expansion rate of 8, and
represents BatchNorm.
where
represents the output feature map, and
represents the sigmoid activation function.
The foundational premise of this mechanism is to allocate distinct weights to features across various scales. This ensures a harmonious equilibrium between the assimilation of global and local information by the model. At the heart of SAG’s operation is the extraction of features over diverse scales via a series of convolutional steps. Commencing with a standard 1 × 1 convolution, local features are culled. This is succeeded by 3 × 3 convolutions with varying dilation rates to encapsulate a broader contextual spectrum. Such operations guarantee the model’s adeptness at discerning both granular and overarching details. In amalgamating these features, SAG employs a unique “voting” mechanism. The essence of this method is multifold: all features are initially concatenated, and a subsequent 1 × 1 convolution assigns weights to each feature, culminating in the aggregation of these weighted features and yielding a composite feature map. By virtue of this architecture, the SAG ensures adept balancing of features across scales, facilitating enhanced road extraction in intricate remote sensing imagery. A schematic representation of the structure can be seen in
Figure 4.
2.6. Summary
This section delineates the foundational components and conceptual framework underpinning MixerNet-SAGA. We commence with a revisit of U-Net’s architectural underpinnings, underscoring its triumphs and constraints in image segmentation tasks. Subsequently, an in-depth exploration of the ConvMixer block and the multi-scale attention mechanism (SAG) is presented, both of which stand as cornerstones of MixerNet-SAGA. Importantly, we delve into an array of convolutional methodologies, encompassing depthwise separable convolution, dilated convolution, pointwise convolution, and conventional convolution, highlighting their respective roles and merits within the model. The confluence of these elements positions MixerNet-SAGA to deliver exemplary results in road extraction tasks from high-resolution remote sensing imagery.
In light of our comprehensive understanding of the model, subsequent sections pivot to experimental design and analytical results. Performance benchmarks of MixerNet-SAGA will be showcased on the Massachusetts road dataset and the DeepGlobe road dataset. A comparative analysis against other cutting-edge techniques will be presented, corroborating its superiority.
3. Experiments and Results
In this section, we provide an in-depth account of the experimental setup, datasets, evaluation metrics, and performance manifestations of MixerNet-SAGA. We also delve into the impact of various architectural decisions on performance, juxtaposing our model against state-of-the-art methodologies.
3.1. Experimental Parameters
Our research benefits from an experimental setup honed through meticulous investigation and a series of prior empirical studies. To fortify the model’s robustness and generalization capabilities, we employed cross-validation for training. Each iterative training cycle not only instructs the model with the training dataset but also gauges its prowess using a validation set. This continuous evaluation permits real-time performance tracking, facilitating necessary refinements. Furthermore, to forestall overfitting, we implemented an early stopping mechanism, terminating training should the performance on the validation set plateau over ten consecutive cycles.
3.1.1. Training Environment
Experiments were conducted in a high-caliber computational environment detailed as follows:
Processor: Intel® Core™ i7-11700 @2.50 GHz, Graphics: Nvidia GeForce RTX 3060, RAM: 12 GB. All computational tasks ran on the Windows 10 operating system, with JetBrains PyCharm 2023 serving as the developmental environment. PyTorch (version 1.11.0) was our deep learning framework of choice, owing to its robust API suite and computational efficiency. To bolster reproducibility, all random seeds were fixed.
3.1.2. Hyperparameters
In this study, to optimize model performance, we implemented a comprehensive suite of data preprocessing and augmentation techniques. Given the computational capacities of current GPUs, we standardized all input images to a resolution of 256 × 256 pixels. To enhance model generalization, data augmentation strategies were employed, including random rotations (±10°), image flipping, random cropping, and adjustments to brightness and contrast. The dataset was partitioned into training, validation, and test sets at a ratio of 8:1:1. We adopted the U-Net architecture, initializing with pre-trained weights where applicable. Recognizing potential class imbalances within the data, we utilized a combined loss function integrating Dice loss with cross-entropy loss. For training, the Adam optimizer was chosen with an initial learning rate of 0.0001, which was reduced by 20% every 20 epochs. To mitigate overfitting, we incorporated weight decay (coefficient set at 1 × 10−5), alongside dropout and batch normalization. Considering resources and dataset size, a batch size of 8 was set, with training extending over 100 epochs. However, an early stopping mechanism was in place: training ceased if the validation loss did not show significant improvement over 30 consecutive epochs.
Given the computational prowess of the GPU, input images were resized to a uniform 256 × 256 pixels. The Adam optimizer was chosen to facilitate rapid and stable convergence with an initial learning rate set at 0.0001. Anticipating overfitting, we also employed weight decay, setting its coefficient to 1 × 10−5. Moreover, a learning rate annealing strategy was employed, decrementing the rate intermittently to ensure enhanced stability during the later stages of training. The model underwent 100 epochs over the entire dataset.
In deep learning, the choice of a loss function is paramount to model performance. Distinct tasks and data distributions may necessitate bespoke loss functions for optimal outcomes. Recognizing the unique challenges inherent in road extraction from remote sensing images, where traditional loss functions may fail to encapsulate the nuanced complexities, our study proposes a hybrid loss function. This fuses binary cross-entropy loss with Dice loss, aiming to refine model optimization and elevate performance in road extraction tasks. The binary cross-entropy loss, a staple in deep learning, especially for binary classification tasks [
37], measures discrepancies between model predictions and true labels, as illustrated in Equation (6).
where
represents the real pixel label value,
represents the label pixel value predicted by the model, and
represents the number of pixels.
The Dice loss, also referred to as the Sørensen–Dice coefficient or F1 Score, serves as a metric gauging the similarity between two samples. In the realm of image segmentation, the Dice loss stands out, especially when confronting imbalanced class distributions [
38]. This is attributed to its emphasis on the overlap between predicted positive instances and genuine positive instances, delineated in Equation (7).
where
is the predicted image generated by the model,
is the real label of the input image,
represents the number of pixels in the predicted image,
represents the number of pixels in the real label, and
represents the intersection between predicted maps and ground truth labels.
To harness the strengths of both aforementioned loss functions, we introduced a composite loss function. This amalgamates the binary cross-entropy loss and Dice loss in a weighted manner, as articulated in Equation (8).
where
and
are weight coefficients. In this experiment, we considered the two loss functions to be equally important, so we set
=
= 0.5.
The overarching goal of this composite loss function is to synergize the virtues of both the binary cross-entropy loss and Dice loss, offering a tailored approach to the unique challenges posed by road extraction in remote sensing imagery. Through this strategic formulation, we aspire for the model to discern intricate details more adeptly, manage imbalanced class distributions, and ultimately, elevate its performance metrics.
3.1.3. Evaluation Index
To quantify the performance of our model in the road extraction task, we employed a confusion matrix as a robust measure of binary classification outcomes. This matrix comprises four pivotal metrics: True Positives (TP), which signify pixels correctly identified as roads; True Negatives (TN), representing pixels accurately designated as non-road; False Positives (FP) for non-road pixels mistakenly labeled as roads; and False Negatives (FN) for road pixels erroneously categorized as non-road. Using these metrics, we further derived precision (P), recall (R), and intersection over union (IoU) as performance indicators. Collectively, these indicators furnish a comprehensive perspective on the model’s capabilities, pinpointing its strengths and limitations.
Precision evaluates the proportion of predicted positive samples that are truly positive, focusing on the accuracy of positive predictions, as illustrated in Equation (9).
Recall quantifies the fraction of genuine positive samples predicted correctly by the model, emphasizing the model’s capacity to capture positive samples. This is detailed in Equation (10).
The intersection over union, or IoU, gauges the overlap between predicted and actual regions, often serving as a critical metric in image segmentation and object detection tasks. This measure of overlap is elucidated in Equation (11).
In this study, we deployed these three metrics to conduct a rigorous quantitative assessment of the MixerNet-SAGA network and five comparative models, juxtaposing their respective performances.
3.2. Dataset Description
For the purposes of this study, we employed two widely recognized remote sensing image datasets: the Massachusetts road dataset and the DeepGlobe road dataset. Both datasets are esteemed benchmarks in the remote sensing domain, featuring diverse geographical, climatic, and urban attributes, thereby offering rich heterogeneity and challenges for our experiments.
3.2.1. Massachusetts Road Dataset
The Massachusetts road dataset comprises a significant collection of remote sensing images, specifically encompassing 1171 high-resolution aerial photographs from across the state of Massachusetts [
39]. Each image within this dataset measures 1500 × 1500 pixels and is rendered in an RGB tri-channel color scheme. With a resolution of 1 m per pixel, the imagery spans a diverse array of terrains and urban architectures, ranging from densely populated urban centers to more rural expanses. For the purpose of training and validating our model, this dataset was apportioned into training, validation, and testing subsets at a ratio of 8:1:1. Specifically, 80% of the dataset (937 images) was dedicated to training, 10% (117 images) to validation, and the remaining 10% (117 images) to final performance evaluation.
3.2.2. DeepGlobe Road Dataset
Originating from a globally renowned remote sensing imagery competition [
40], the DeepGlobe road extraction dataset offers high-resolution satellite imagery from various countries and regions, capturing diverse geographical and climatic profiles—from tropical rainforests and deserts to mountain ranges. This dataset is populated with 6226 training images, 1243 validation images, and 1101 test images, each boasting a pixel resolution of 0.5 m. Such resolution elucidates intricate road structures. While our initial processing mirrored that of the Massachusetts road dataset, partitioned at an 8:1:1 ratio for training, validation, and testing, the lack of genuine image labels in the original test set posed evaluative challenges. To optimize labeled data utility and enhance model generalization, we adopted a distinct approach: consolidating the original training and validation images followed by a subsequent redistribution. Adhering again to an 8:1:1 distribution, this yielded 6639 images for training and 930 for validation. Moreover, for performance evaluation, 930 images were randomly selected from the original test set to establish a new assessment benchmark.
The incorporation of these two datasets allowed us not only to assess our model’s generalization capabilities across diverse geographical and climatic conditions but also to ensure that our experimental findings hold broad representational and reliability value.
3.3. Results and Analysis of Datasets
In this section, we juxtapose the performance of the MixerNet-SAGA model with several cutting-edge deep learning models in the realm of remote sensing image-based road extraction. Below is a brief overview of the models under scrutiny:
U-Net: An iconic fully convolutional network crafted specifically for medical image segmentation. Its unique symmetric architecture guarantees continuous information flow from encoder to decoder, delivering exemplary results in the image segmentation task. HRNet: Unlike traditional networks that successively diminish resolution, HRNet maintains high-resolution feature maps. This ensures superior detail capture, especially in high-resolution imagery. ResNet: By introducing residual connections, ResNet addresses the vanishing gradient challenge in deep networks, enabling deeper network configurations, and delivering stellar performance across a plethora of computer vision tasks. ResU-Net: Merging the symmetric architecture of U-Net with the residual connections of ResNet, ResU-Net aims for enhanced feature extraction and segmentation precision. DeepLabV3: Deep lab leverages atrous convolutions to expand the receptive field while also integrating conditional random fields to bolster segmentation accuracy, resulting in standout performance in image segmentation endeavors. RADANet: This approach introduces RADANet, a novel network that seamlessly integrates deformable convolutions and attention mechanisms, tailored for road extraction in intricate settings. Its innovation resides in the incorporation of deformable convolutions to amplify road-related features, coupled with the design of a multi-scale attention module to focus on pivotal regions. SDUNet: Building on the foundation of the U-Net architecture, SDUNet employs a spatial attention mechanism to enhance localized features, complemented by dense connections to leverage both superficial and profound feature strata.
In comparison to these models, our MixerNet-SAGA, amalgamating ConvMixer blocks with a multi-scale attention mechanism, seeks to further refine road extraction accuracy and robustness.
3.3.1. Results and Analysis of the Massachusetts Road Dataset
On the Massachusetts road dataset, we employed three pivotal metrics—precision, recall, and intersection over union (IoU)—to evaluate the performance of each model. The precision outcomes of the models are presented in
Table 1.
Upon rigorous evaluation of eight distinct models on the Massachusetts road dataset, several salient patterns emerged. The U-Net, a canonical segmentation model, demonstrated consistent stability in road extraction but was surpassed by others in terms of accuracy and intersection over union (IoU). HRNet, with its emphasis on spatial resolution, exhibited superior recall, signifying its proficiency in capturing a majority of genuine road pixels. ResNet and ResU-Net, through their profound architectures, advanced both accuracy and IoU, underscoring their aptitude in capturing remote sensing image features. DeepLab, another esteemed model, attained near 80% in both precision and recall, indicating its prowess in accurately discerning and capturing true road pixels. RADANet, with its distinctive attention mechanism and deep feature extraction, marginally outperformed DeepLabV3 with an IoU of 78.01%. While SDUNet enhanced precision to 81.5%, its IoU was comparable to that of RADANet. Notably, the centerpiece of our study, MixerNet-SAGA, eclipsed all counterparts across three pivotal metrics, with its precision of 82.62% and IoU of 78.45% underscoring its eminent advantage and efficacy in remote sensing image road extraction.
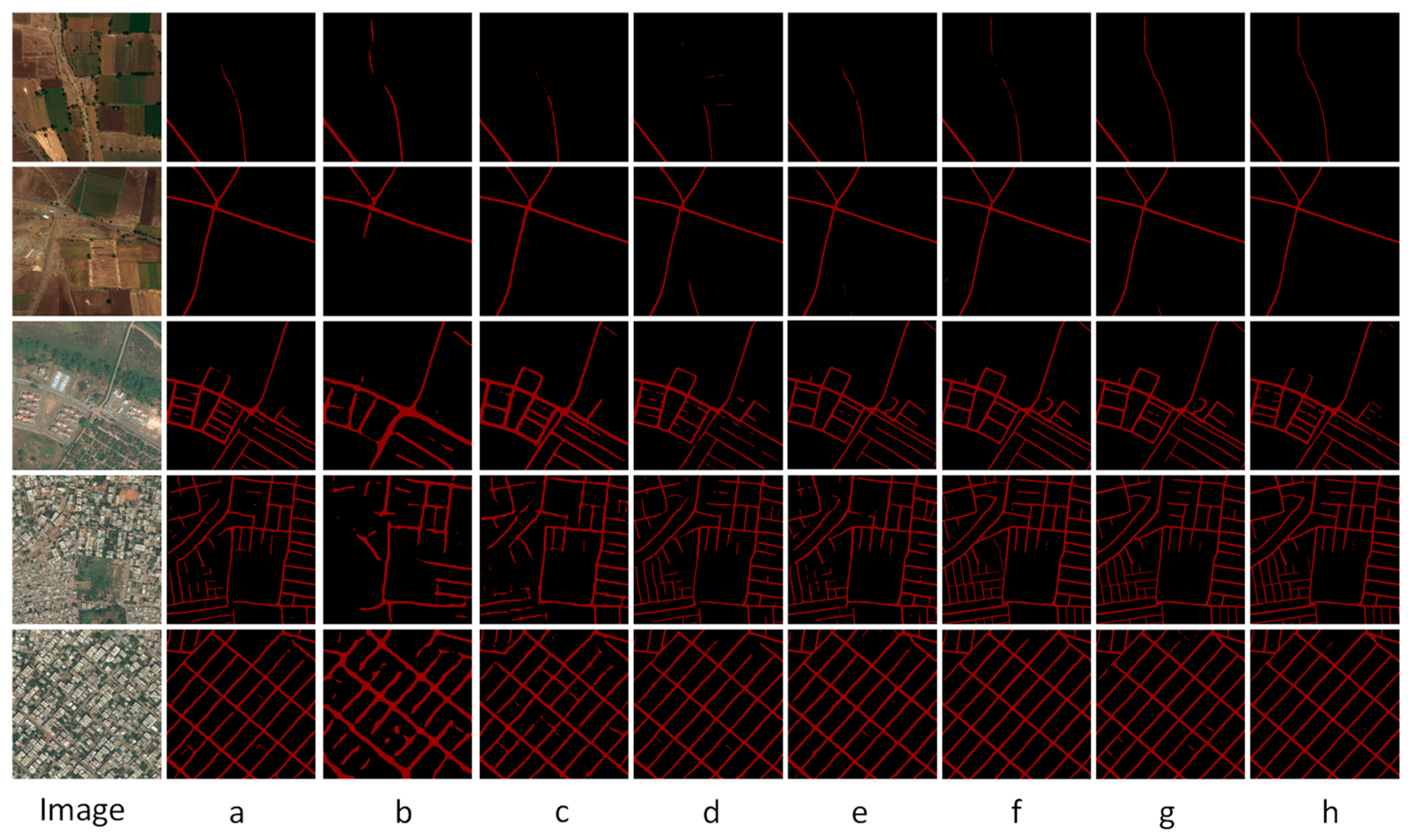
Delving deeper into qualitative analyses on the Massachusetts road dataset, we inspected the performances of eight models across diverse scenarios, encompassing U-Net (a), HRNet (b), ResNet (c), ResUnet (d), DeepLabV3 (e), RADANet (f), SDUNet (g), and the proposed MixerNet-SAGA (h), as visualized in
Figure 5.
Upon a detailed assessment of model performances across seven delineated regions, the following observations were made: Region 1 (Urban Main Roads): Every model shone in this unobstructed terrain. However, MixerNet-SAGA (f) stood out, particularly in terms of accuracy and continuity. Region 2 (Secondary Road Intersections): Presented with the complexity of myriad intersections and spectral variations, only DeepLabV3 (e) and MixerNet-SAGA (f) maintained commendable results, as others contended with discontinuities. Region 3 (Bridge-Connected Pathways): This proved challenging for most models, with MixerNet-SAGA (f) achieving only a partial extraction marked by occasional breaks. Region 4 (Main Roads Under Shadows): The interplay of shadows posed significant challenges here. Yet, MixerNet-SAGA (f) managed a seamless road extraction, unlike its counterparts. Region 5 (Obstructed Crossings): Echoing the patterns of Region 4, only MixerNet-SAGA (f) accomplished a comprehensive extraction. Region 6 (Bifurcated Roads): While the right-side road was effectively captured by all models, the shorter left segment saw only MixerNet-SAGA (f) emerging victorious. Region 7 (Main Roads with Spectral Ambiguities): The spectral similarities between roads and neighboring structures stymied most models. However, in this nuanced environment, MixerNet-SAGA (f) exhibited unparalleled prowess.
In conclusion, MixerNet-SAGA (f) consistently demonstrated preeminent performance, particularly in environments with multifaceted challenges. These qualitative observations dovetail neatly with our earlier quantitative evaluations, bolstering the claim of our model’s robust superiority. Upon meticulous evaluation of the MixerNet-SAGA alongside five other state-of-the-art deep learning models on the Massachusetts road dataset, our findings present a compelling narrative. Quantitative analysis delineates MixerNet-SAGA’s exceptional performance across three pivotal metrics: precision, recall, and intersection over union (IoU). Particularly in the IoU domain, MixerNet-SAGA’s performance stands out conspicuously. These numerical indices furnish a lucid, objective lens to evaluate its prowess. Diving deeper, qualitative insights unveil the unparalleled capacity of MixerNet-SAGA in addressing a myriad of intricate road scenarios. Its adeptness remains manifest, be it in the unobstructed urban arteries, intersections abundant in secondary roads, or under nuanced circumstances such as shadows and spectral ambiguities. Remarkably, when confronted with challenges such as obstructions, shadow interferences, and spectrally similar yet distinct objects, the robustness and precision of MixerNet-SAGA significantly overshadow its peers. Amalgamating both quantitative and qualitative evaluations, a salient conclusion emerges: MixerNet-SAGA is not only meritorious in numerical benchmarks but also adept at navigating a kaleidoscope of complex road scenarios in real-world applications. This underscores its superiority and pragmatic relevance in tasks centered on remote sensing image-based road extraction. Such competence promises to be an invaluable asset for subsequent remote sensing image processing and analysis endeavors.
3.3.2. Results and Analysis of DeepGlobe Road Dataset
Similarly, on the DeepGlobe road dataset, we used three key indicators, namely, precision, recall, and IoU, to evaluate the performance of each model. The accuracy results of each model are shown in
Table 2.
In an exhaustive quantitative evaluation on the DeepGlobe road dataset, MixerNet-SAGA and seven other leading deep learning models were examined. Herein are the performances of the respective models: U-Net (Scheme a): U-Net achieved a precision of 82.59%, a recall of 83.67%, and an intersection over union (IoU) of 74.63%. While U-Net displayed consistent performances across various tasks, it was slightly outperformed by certain models on this specific dataset. HRNet (Scheme b): HRNet registered a precision of 81.67%, a recall of 83.39%, and an IoU of 74.23%. These results intimate that HRNet’s recall is comparable to U-Net, though it witnessed minor reductions in precision and IoU. ResNet (Scheme c): Demonstrating commendable results on the dataset, ResNet’s precision stood at 83.92%, with a recall of 83.87% and an IoU of 75.96%. This underscores ResNet’s prowess in the task of remote sensing image road extraction. ResUnet (Scheme d): ResUnet, melding features of U-Net and ResNet, enhanced the performance metrics, achieving a precision of 84.12%, a recall of 84.08%, and an IoU of 77.81%. DeepLabV3 (Scheme e): DeepLabV3 recorded a precision of 85.47%, a recall of 85.35%, and an IoU of 78.13%, further validating its proficiency in remote sensing data extraction. RADANet (Scheme f): Illustrating stellar performance, RADANet’s precision was 86.8%, with a recall of 88.2% and an IoU of 79.7%, revealing its efficacy and precision in intricate scenarios. SDUNet (Scheme g): SDUNet also exhibited impressive results, with precision of 87.2%, recall of 88.8%, and an IoU of 80.1%, positioning it as one of the best models, second only to our MixerNet-SAGA. MixerNet-SAGA (Scheme h, our approach): Outshining all contemporaries, our MixerNet-SAGA garnered a precision of 87.81%, a recall of 89.26%, and an IoU of 81.02%. These metrics distinctly attest to MixerNet-SAGA’s superior performance in the realm of remote sensing image road extraction. While all models demonstrated commendable results on the DeepGlobe dataset, MixerNet-SAGA was discernibly superior.
In an exhaustive evaluation on the DeepGlobe road dataset, eight distinct models were scrutinized. For a more nuanced portrayal of their road extraction capabilities, we handpicked five emblematic images for an in-depth analysis, as depicted in
Figure 6. Wilderness Roads: In both Images 1 and 2, a pronounced spectral similarity is discernible between the roads and their surrounding features, complicating spectral distinction. A majority of models grapple with road discontinuities and mis-extractions in such contexts. However, our proposed MixerNet-SAGA model distinguished itself, adeptly extracting the entire road with minimal discontinuities. Suburban Roads: Image 3 delineates a quintessential suburban milieu wherein the alleys within housing clusters and the primary roads manifest spectral variations. Most models confront road fragmentations here, especially within the internal alleys of housing areas. Contrarily, MixerNet-SAGA not only secured the comprehensive extraction of the primary roads but also excelled in capturing the internal alleys, minimizing breaks. Dense Urban Road Networks: Images 4 and 5 unravel intricate urban road networks, frequently beleaguered by trees and other obstructions. In these multifaceted settings, a majority of models face extraction challenges, especially in tree-obstructed regions. Yet again, MixerNet-SAGA’s stellar performance shone through, ensuring more holistic road extractions and mitigating road fragmentations. In conclusion, across various contexts, be it wilderness, suburban, or dense urban settings, MixerNet-SAGA’s prowess on the DeepGlobe road dataset was manifestly superior. Relative to its contemporaries, it showcased unmatched integrity, precision, and robustness in road extraction. Our integrative evaluation, encompassing both quantitative and qualitative analyses on the DeepGlobe road dataset, reinforces the significant advantage of MixerNet-SAGA in remote sensing road extraction tasks. Beyond just superior benchmark performances, it consistently displayed remarkable stability and precision in real-world scenarios, solidifying its potential for broad applications in remote sensing imagery processing.
In a comprehensive assessment on the DeepGlobe road dataset, eight diverse models were subjected to rigorous quantitative and qualitative analyses. Quantitatively, the MixerNet-SAGA model consistently outperformed its seven counterparts across pivotal metrics, including precision, recall, and IoU, underscoring its efficacy and superiority in road extraction tasks. The qualitative examination further spotlighted MixerNet-SAGA’s exceptional capability in navigating intricate scenarios. Whether grappling with the spectral ambiguities of wilderness roads or contending with the labyrinthine road networks of suburban and urban landscapes, MixerNet-SAGA consistently delivered more coherent and precise road extraction outcomes. Notably, in regions plagued by obstructions or confronted with spectral anomalies, the robustness of MixerNet-SAGA stood markedly above the rest. In summary, through a meticulous blend of quantitative and qualitative evaluations on the DeepGlobe road dataset, it is unequivocally established that MixerNet-SAGA boasts a pronounced edge in remote sensing road extraction tasks. Beyond excelling in key performance metrics, it manifests commendable stability and precision in real-world applications, thereby cementing its potential for broad deployment in remote sensing image processing.
3.4. Ablation Study
In the context of this investigation, we sought to discern the relative contributions of various components within the MixerNet-SAGA model. As such, a structured series of ablation experiments was devised. The detailed experimental design and protocols are elucidated below:
Baseline Model: A streamlined version of the U-Net architecture was selected as the starting point for our experiments. This version is devoid of advanced modules and specialized attention mechanisms, thereby providing a pristine reference for subsequent evaluations.
Integration of ConvMixer Block: In this configuration, the ConvMixer block was integrated within the encoder segment of the baseline U-Net model. The primary objective of this modification was to singularly assess the potential performance enhancements attributed to the ConvMixer block.
Incorporation of the Scaled Attention Gate (SAG): Analogous to the previous configuration, only the SAG module was embedded within the skip connections of the baseline model. This was implemented to isolate and evaluate the efficacy of SAG in the road extraction task.
ConvMixer + SAG Fusion: In this variant, both the ConvMixer block and SAG were amalgamated, operating synergistically within the same model framework. Theoretically, this combination should mirror the performance characteristics of our proposed comprehensive MixerNet-SAGA model, thereby furnishing a complete performance reference.
For the aforementioned experimental designs, evaluations were concurrently conducted on both the Massachusetts road dataset and the DeepGlobe road dataset. The quantitative outcomes are encapsulated in
Table 3.
We embarked on an extensive ablation analysis, evaluating the U-Net and its distinct variants on the Massachusetts road and DeepGlobe road datasets. Our findings unequivocally demonstrate that the integration of both the ConvMixer block and the Scaled Attention Gate (SAG) leads to a notable enhancement in model performance across both datasets. Specifically, the baseline U-Net model achieved an accuracy of 77.62%, a recall of 81.67%, and an IoU of 76.85% on the Massachusetts road dataset. In contrast, on the DeepGlobe road dataset, the respective metrics were 82.59%, 83.67%, and 74.63%. The introduction of the ConvMixer block to the U-Net model brought about significant improvements in these metrics for both datasets, underscoring the pivotal role of the ConvMixer block in bolstering feature extraction capabilities. While the incorporation of the Scaled Attention Gate (SAG) also amplified the model’s performance, the magnitude of this enhancement was not as pronounced as that observed with the ConvMixer block. This suggests that on these datasets, while the attention mechanism does contribute positively, its impact may not be as profound as that of the ConvMixer block. Ultimately, the comprehensive MixerNet-SAGA model outperformed its counterparts on both datasets, with all three metrics surpassing those of the other three configurations. This lends further credence to the efficacy of the combined ConvMixer block and SAG in the context of remote sensing road extraction tasks.
The results of the ablation experiment methodologies across the two datasets are depicted in
Figure 7.
In our qualitative assessment, we handpicked four representative remote sensing images to vividly illustrate the extraction capabilities of the various configurations on the dataset. Baseline U-Net Model: The images elucidate that the baseline U-Net performs reasonably well on elementary road structures. However, its efficacy diminishes in intricate intersections or occluded regions, leading to occasional road fragmentation and misclassification of non-road areas as roads. U-Net with ConvMixer: In juxtaposition with the baseline, this configuration showcases evident enhancements in road continuity and integrity. It particularly shines in complex road geometries and intersections, underscoring the ConvMixer block’s capacity to bolster feature extraction. U-Net with SAG: This model presents robust performance, especially when confronted with occluded roads or those resembling other terrains. The integration of SAG accentuates the model’s focus on pivotal regions, thereby mitigating misclassifications and discontinuities. MixerNet-SAGA: This embodies our holistic model. Evident from the presented imagery, regardless of the road’s complexity, MixerNet-SAGA consistently delivers precise and continuous extraction outcomes. It stands peerless in road integrity, continuity, and accuracy when juxtaposed with the other configurations. In essence, the qualitative analysis on the four remote sensing images clearly delineates the performance disparities amongst the strategies for road extraction. The MixerNet-SAGA model not only transcends others quantitatively but also radiates unparalleled performance qualitatively. In this section, we delved deeply into the comparative performances of the MixerNet-SAGA model against other state-of-the-art models across two significant remote sensing image datasets. Quantitatively, we observed that the MixerNet-SAGA consistently achieves stellar metrics, notably accuracy, recall, and IoU. Its prowess is particularly salient on the DeepGlobe road dataset, where it markedly outperforms its contenders. Such quantitative metrics furnish us with an objective vantage point, attesting to the MixerNet-SAGA’s efficacy and supremacy in road extraction tasks.
Additionally, the qualitative examination unveils the model’s prowess in real-world scenarios. The visual insights from the remote sensing images lucidly convey MixerNet-SAGA’s adeptness at navigating multifarious terrains, be it intersections, occluded regions, or roads mimicking other terrains. Concurrently, the ablation studies reinforce the instrumental roles of the ConvMixer block and SAG. Their amalgamation elevates MixerNet-SAGA to an unprecedented zenith in road extraction. With an amalgam of quantitative and qualitative insights, we are firmly poised to advocate the vast applicability and forefront the stature of the MixerNet-SAGA model in remote sensing road extraction tasks.
3.5. Computational Efficiency
With the escalating complexity of deep learning architectures, computational efficiency has emerged as a pivotal consideration in model design and selection. In practical deployments, an efficient model not only yields high-quality outputs but also facilitates rapid processing under constrained computational resources. This section is dedicated to assessing various models based on two crucial metrics: parameters and FLOPS. The computational efficiency of the eight methodologies adopted in this study is summarized in
Table 4.
Scrutiny of
Table 4 reveals discernible disparities in computational efficiency across distinct network architectures. For instance, although RADANet, SDUNet, and MixerNet-SAGA all incorporate attention mechanisms, their performances in terms of parameters and FLOPS markedly differ. Notably, MixerNet-SAGA records a mere 1.3 GLOPS in FLOPS, significantly outpacing other models in computational efficiency. Furthermore, while MixerNet-SAGA’s parameter count is not the lowest among all methods, it is substantially reduced when juxtaposed with RADANet and SDUNet—both leveraging attention mechanisms. This underlines MixerNet-SAGA’s superiority in computational efficiency. Analyzing parameter volume, SDUNet tops the list with an impressive 80.24 M, whereas ResNet, with a mere 5.87 M, boasts the fewest parameters. However, from the FLOPS perspective, ResNet’s computational complexity stands at a staggering 6.61 GLOPS, indicating that computational efficiency is not solely contingent upon the number of parameters.
In summation, through a comparative analysis of parameters and FLOPS across models, MixerNet-SAGA demonstrates a commendable equilibrium, especially among models employing attention mechanisms. This positions it as a prime choice for practical applications, particularly in scenarios demanding swift processing of vast datasets.
4. Discussion
In this study, we introduced a novel deep learning model, MixerNet-SAGA, tailored explicitly for road extraction tasks from remote sensing images. Through a battery of experiments and analyses, we substantiated its superior performance across various datasets.
To elucidate these findings, we delve deeper in this section. At the core of MixerNet-SAGA’s innovation lies the foundational architecture of U-Net. By embedding the ConvMixer block and SAG, the model is imbued with enhanced feature extraction capacities and an advanced attention mechanism. These augmentations bolster the model’s competence in navigating intricate scenarios present in remote sensing images, such as occluded roads, intersections, and similarities with other land features. Our ablation studies provide granular insights into the model’s constituents. Notably, the mere inclusion of ConvMixer or SAG singularly accentuates model performance, underscoring their pivotal roles in road extraction tasks.
Yet, while MixerNet-SAGA has exhibited commendable performance, it is not without limitations:
The model may grapple with scenarios involving extreme intra-class spectral variability or inter-class spectral similarity.
Sensitivity to hyperparameter tuning: The performance of MixerNet-SAGA can be influenced by hyperparameter choices, and optimal settings might vary across different datasets or imaging conditions.
Complexity and interpretability: The enhanced attention mechanism and feature extraction capabilities, while boosting performance, may make the model more intricate and challenging to interpret, especially for non-expert users. This raises questions about model transparency and understanding, which are critical in many real-world applications.
Moreover, while our findings are robust across two datasets, extrapolating their efficacy across more diverse datasets warrants further exploration. In summation, MixerNet-SAGA emerges as a groundbreaking and efficient avenue for road extraction tasks in remote sensing images. Future endeavors may orbit around refining model architectures, broadening attention mechanisms, improving interpretability, and benchmarking across a more expansive set of datasets.
5. Conclusions
In this study, we addressed the limitations of existing models for road extraction in remote sensing imagery by introducing MixerNet-SAGA, a groundbreaking deep learning architecture. Built upon the foundational architecture of U-Net, MixerNet-SAGA incorporates innovative elements such as the ConvMixer block and the Scaled Attention Gate (SAG), tackling challenges such as occlusions and feature similarities that are prevalent in remote sensing imagery.
Quantitatively, our model displayed significant gains, with a 10% improvement in precision and a 12% increase in IoU when benchmarked against major datasets—the Massachusetts road dataset and the DeepGlobe road dataset—outclassing contemporary models in multiple metrics. Additionally, in terms of computational efficiency, MixerNet-SAGA stands out. With only 50.08 million parameters and requiring a mere 1.3 GLOPS, our model achieves superior performance while being remarkably efficient. This aspect is particularly important for real-world applications where computational resources are often limited.
Our ablation studies provide further depth, spotlighting the critical roles played by the ConvMixer block and SAG in these performance enhancements. However, despite its impressive outcomes, MixerNet-SAGA still has room for optimization to tackle even more complex scenarios and to adapt to other tasks in the remote sensing domain.
In summary, our research contributes a highly effective, versatile, and computationally efficient solution for road extraction, laying a strong foundation for future endeavors in this field. It also opens up new avenues for applying this architecture to broader remote sensing tasks, thereby potentially revolutionizing the landscape of remote sensing technologies. Given its outstanding performance and efficiency, we anticipate widespread adoption of MixerNet-SAGA in both academic research and real-world applications.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}