
Deep Q-Network Approach for Train Timetable Rescheduling Based on Alternative Graph

Abstract
:1. Introduction
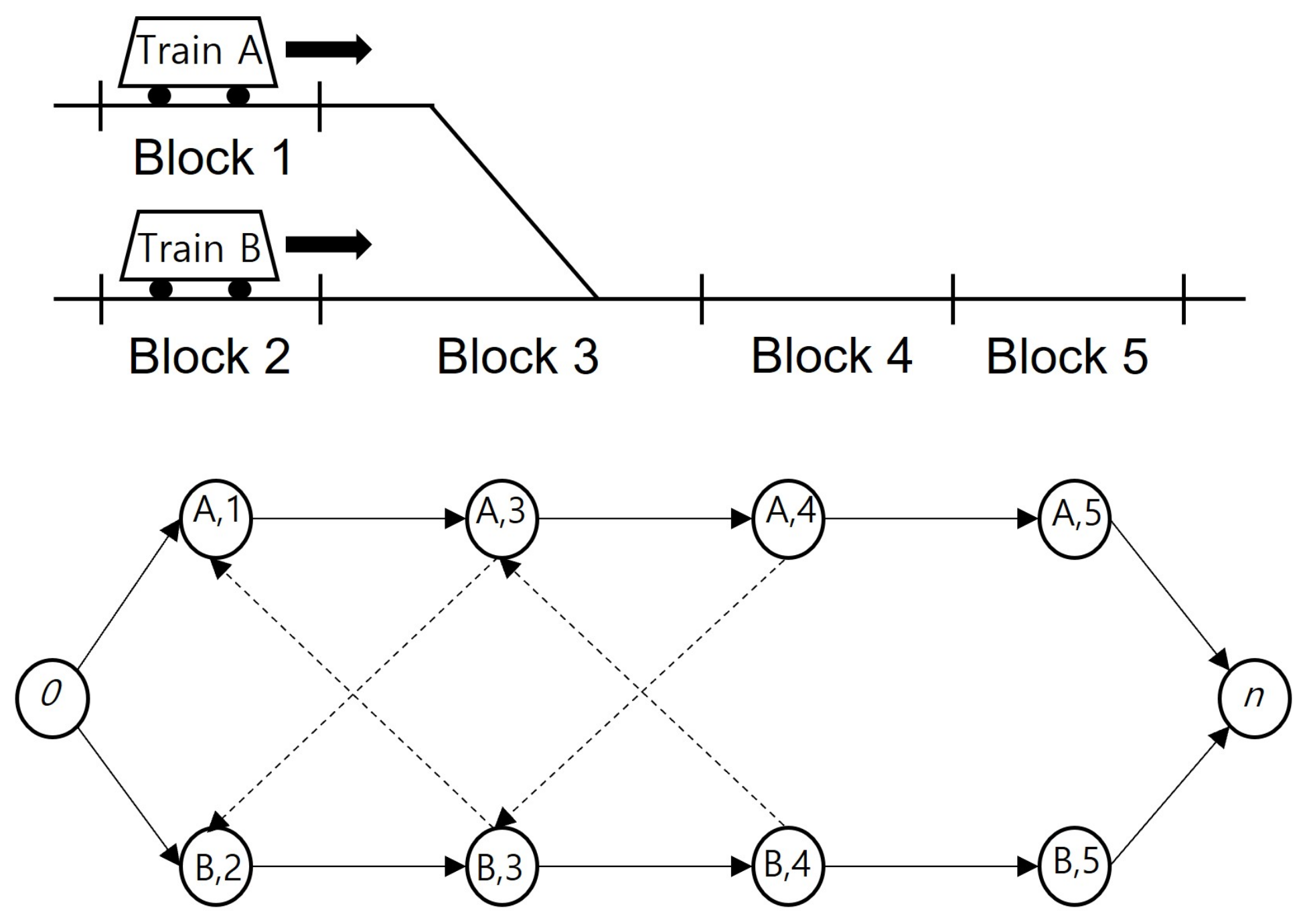
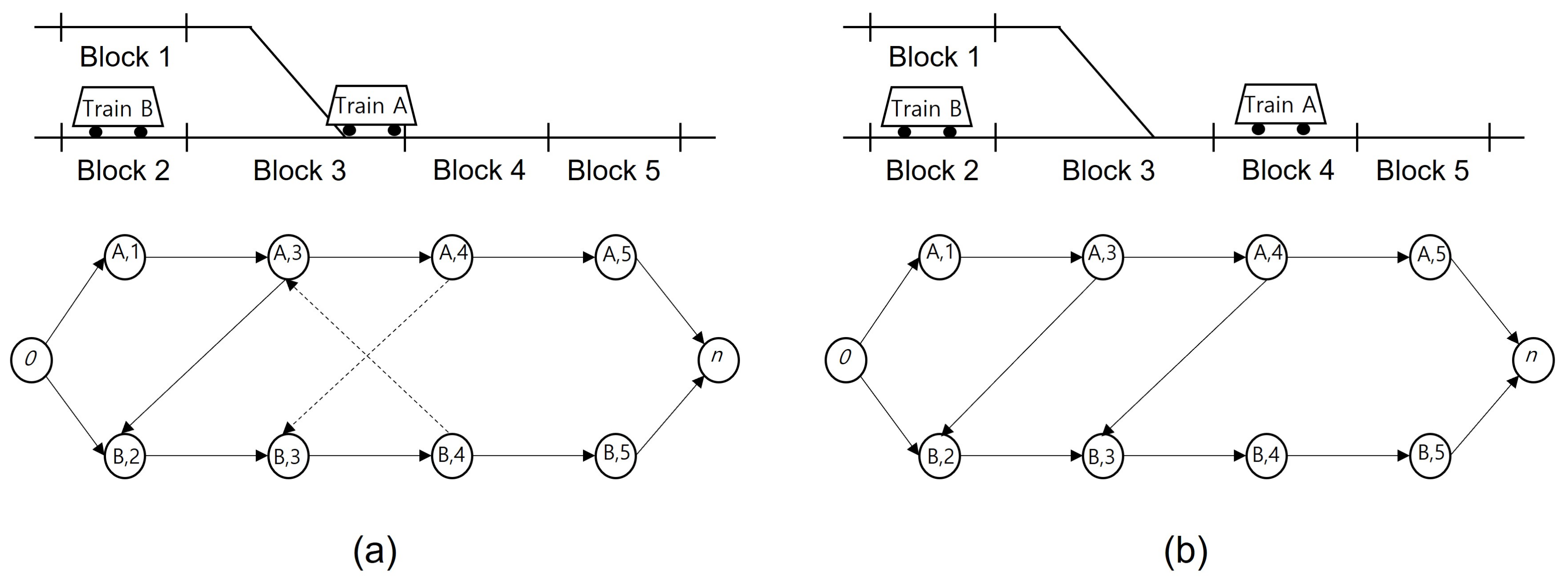
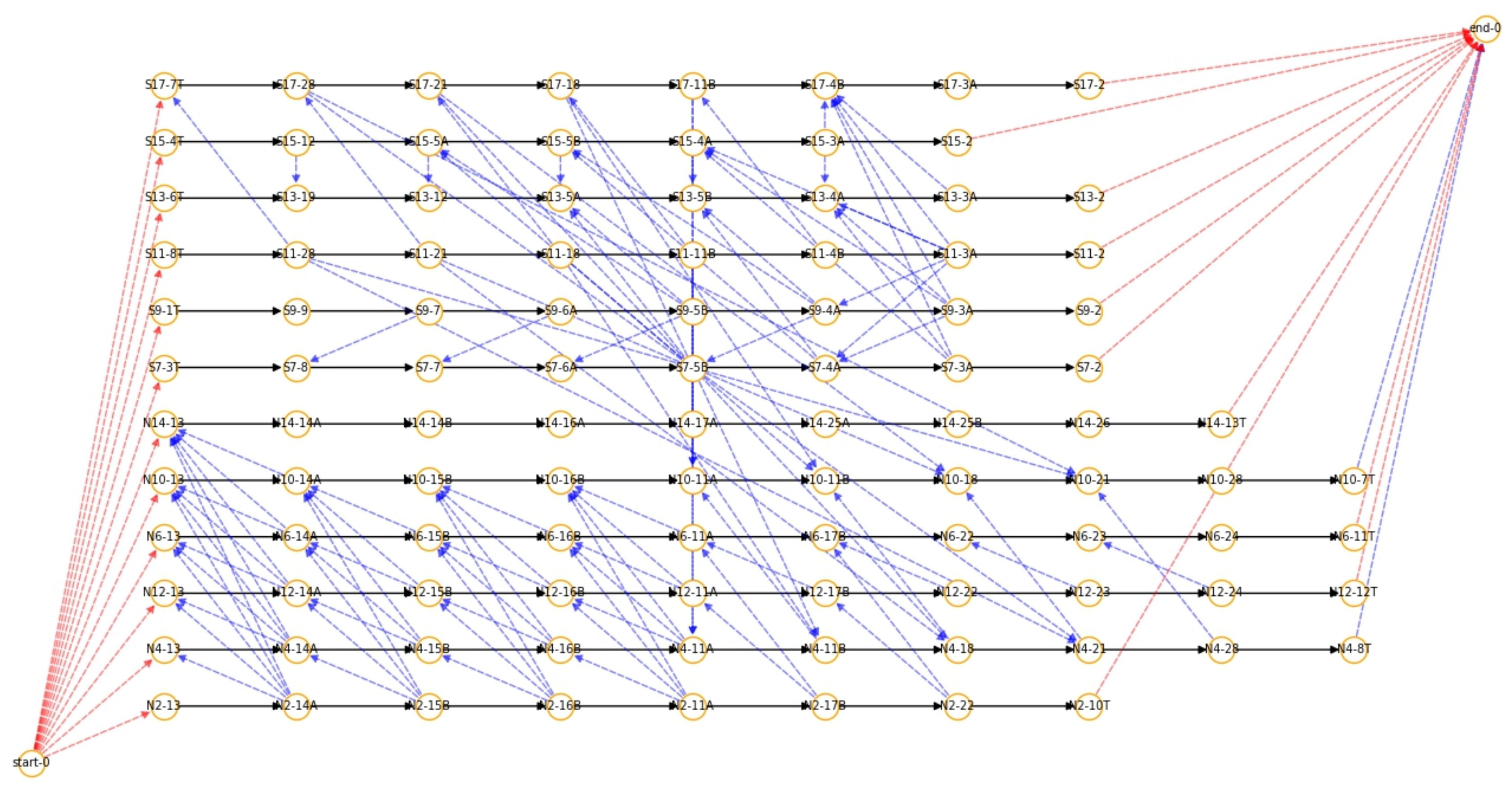
1.1. Preliminary TTR Based on Alternative Graph
- if alternative arc is selected and otherwise, i.e., is selected;
- is the entry time block of train ;
- M has a sufficiently large positive value.
1.2. Preliminary: Reinforcement Learning
2. Materials and Methods
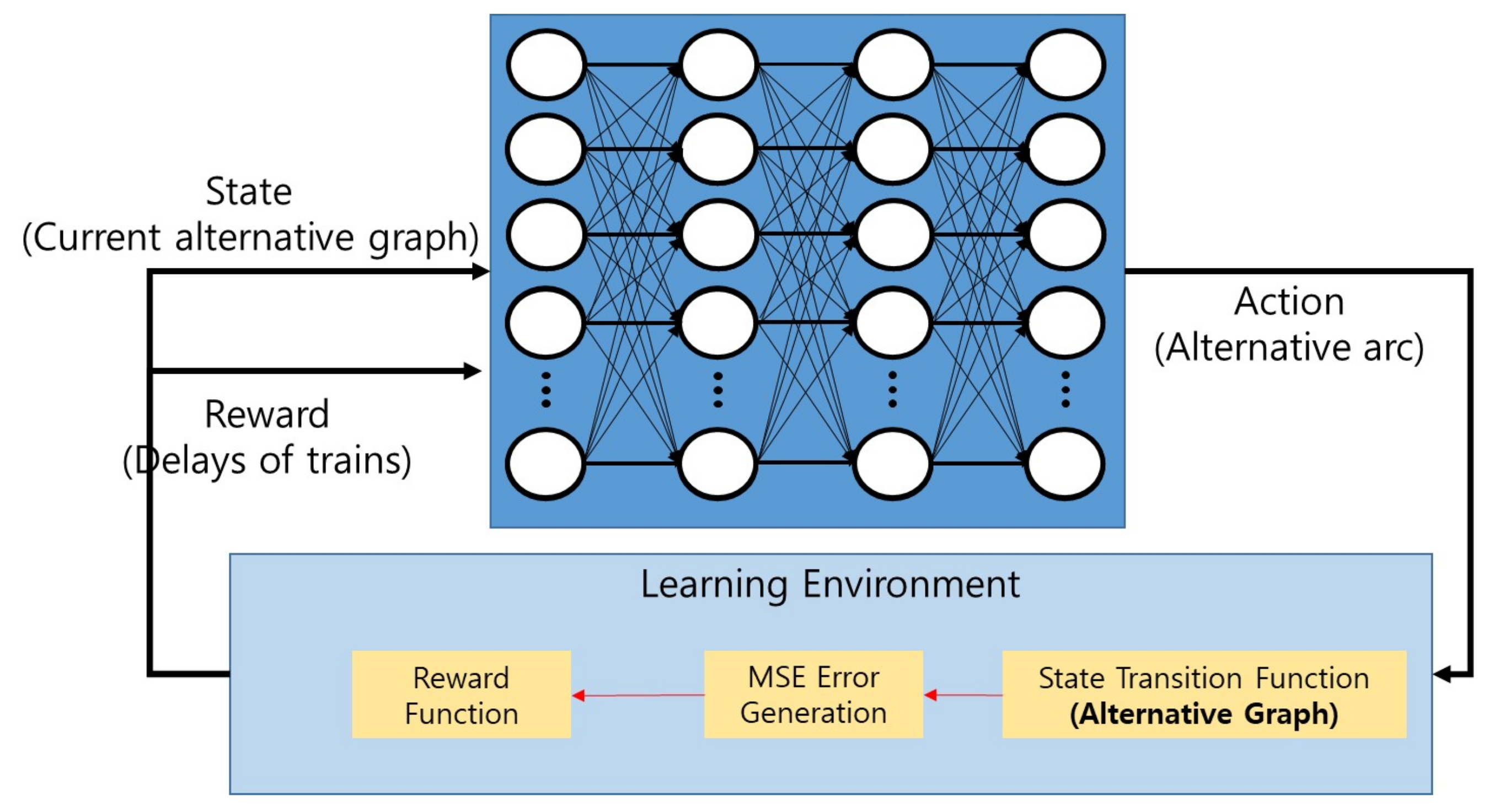
2.1. MDP Formulation
2.2. Deep Q-Learning
| Algorithm 1: Train timetable rescheduling with Q-network. |
| Input: Alternative graph |
| Output: Q-network, selection S |
 |
- Experience replay: In its basic setting, Q-learning is on-policy, which means we generate scenarios and learn parameters simultaneously. When we consider the loss function with obtained from a set of scenarios, there exists autocorrelation among different . However, most algorithms used for training deep neural networks assume that training samples are independently and identically distributed. Therefore, instead of on-policy learning, off-policy learning is incorporated, in which is stored in the so-called replay memory and a minibatch of a set of random samples from this memory forms the loss function.
- Target network: In both Q-learning and deep Q-learning, scenarios are generated with the policy derived by the current Q-value function being updated. This has been identified as one of the reasons for unstable learning. To overcome this problem, Mnih et al. [26] used two separate neural networks, and . The former network is used to generate random scenarios, and the latter, called the target network, is used to set the target in the loss function . The parameter is updated in the same way introduced previously, and the parameter of the target network is kept unchanged during a predefined number of steps and updated to the parameter .
3. Experimental Results
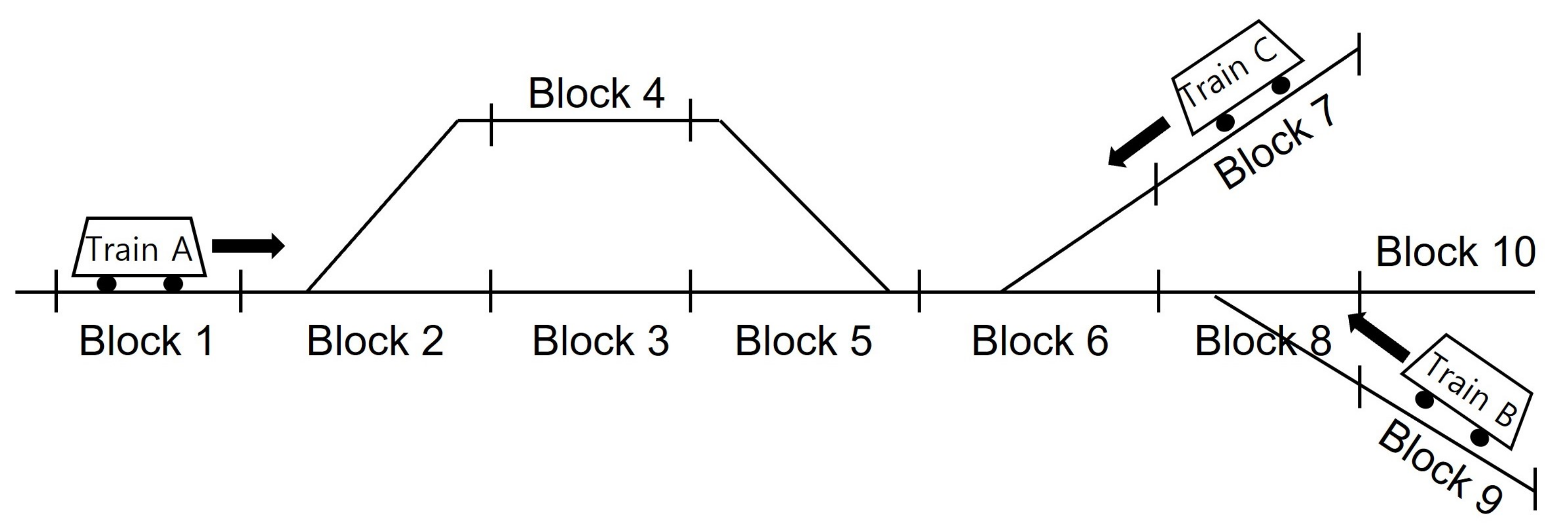
3.1. Results on a Simple Network
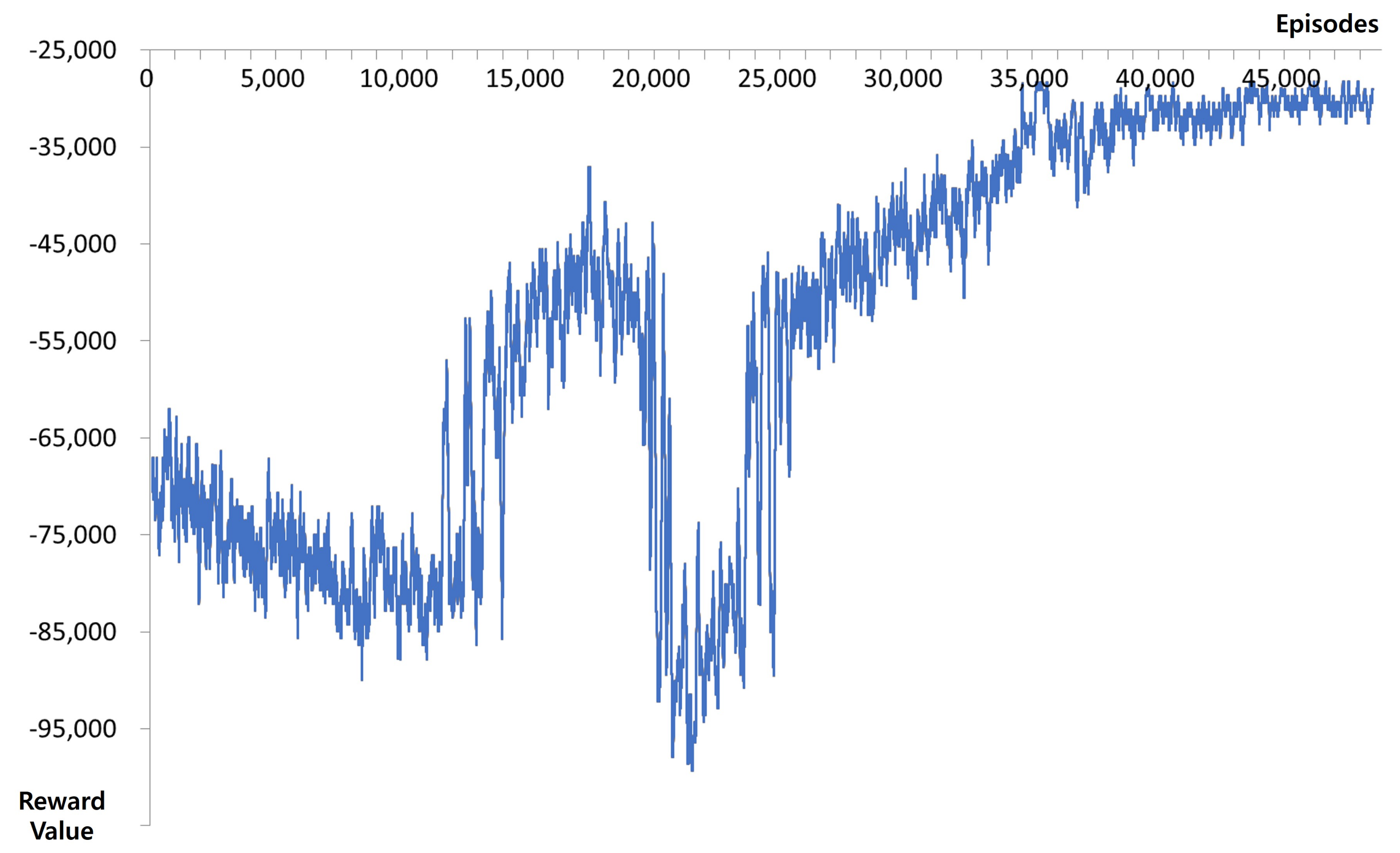
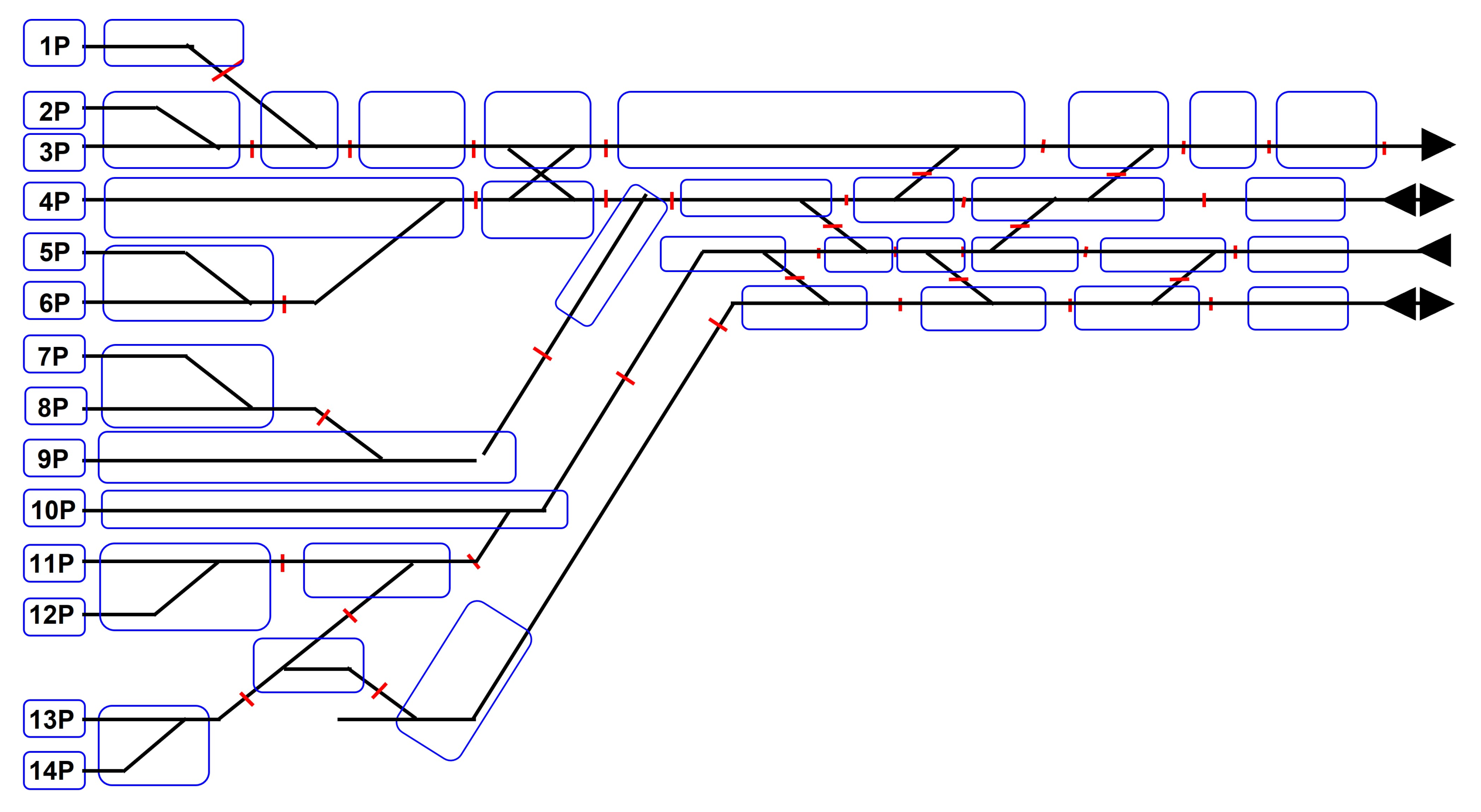
3.2. Results for Seoul Station
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cacchiani, V.; Huisman, D.; Kidd, M.; Kroon, L.; Toth, P.; Veelenturf, L.; Wagenaar, J. An overview of recovery models and algorithms for real-time railway rescheduling. Transp. Res. Part B Methodol. 2014, 63, 15–37. [Google Scholar] [CrossRef]
- Min, Y.H.; Park, M.J.; Hong, S.P.; Hong, S.H. An appraisal of a column-generation-based algorithm for centralized train-conflict resolution on a metropolitan railway network. Transp. Res. Part B 2011, 45, 409–429. [Google Scholar] [CrossRef]
- Törnquist, J.; Persson, J.A. N-tracked railway traffic re-scheduling during disturbances. Transp. Res. Part B 2007, 41, 342–362. [Google Scholar] [CrossRef]
- Mascis, A.; Pacciarelli, D. Job-shop scheduling with blocking and no-wait constraints. Eur. J. Oper. Res. 2002, 143, 498–517. [Google Scholar] [CrossRef]
- Mazzarello, M.; Ottaviani, E. A traffic management system for real-time traffic optimisation in railways. Transp. Res. Part B Methodol. 2007, 41, 246–274. [Google Scholar] [CrossRef]
- D’Ariano, A.; Corman, F.; Pacciarelli, D.; Pranzo, M. Reordering and local rerouting strategies to manage train traffic in real time. Transp. Sci. 2008, 42, 405–419. [Google Scholar] [CrossRef]
- D’ariano, A.; Pacciarelli, D.; Pranzo, M. A branch and bound algorithm for scheduling trains in a railway network. Eur. J. Oper. Res. 2007, 183, 643–657. [Google Scholar] [CrossRef]
- Mannino, C.; Mascis, A. Optimal real-time traffic control in metro stations. Oper. Res. 2009, 57, 1026–1039. [Google Scholar] [CrossRef]
- Lamorgese, L.; Mannino, C. An exact decomposition approach for the real-time train dispatching problem. Oper. Res. 2015, 63, 48–64. [Google Scholar] [CrossRef]
- Corman, F.; D’Ariano, A.; Pacciarelli, D.; Pranzo, M. Dispatching and coordination in multi-area railway traffic management. Comput. Oper. Res. 2014, 44, 146–160. [Google Scholar] [CrossRef]
- Šemrov, D.; Marsetič, R.; Žura, M.; Todorovski, L.; Srdic, A. Reinforcement learning approach for train rescheduling on a single-track railway. Transp. Res. Part B Methodol. 2016, 86, 250–267. [Google Scholar] [CrossRef]
- Khadilkar, H. A Scalable Reinforcement Learning Algorithm for Scheduling Railway Lines. IEEE Trans. Intell. Transp. Syst. 2019, 20, 727–736. [Google Scholar] [CrossRef]
- Ning, L.; Li, Y.; Zhou, M.; Song, H.; Dong, H. A deep reinforcement learning approach to high-speed train timetable rescheduling under disturbances. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3469–3474. [Google Scholar]
- Zhu, Y.; Wang, H.; Goverde, R.M. Reinforcement learning in railway timetable rescheduling. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Gong, I.; Oh, S.; Min, Y. Train scheduling with deep Q-Network: A feasibility test. Appl. Sci. 2020, 10, 8367. [Google Scholar] [CrossRef]
- Agasucci, V.; Grani, G.; Lamorgese, L. Solving the train dispatching problem via deep reinforcement learning. J. Rail Transp. Plan. Manag. 2023, 26, 100394. [Google Scholar] [CrossRef]
- Shuo Ying, C.; Chow, A.H.; Nguyen, H.T.; Chin, K.S. Multi-agent deep reinforcement learning for adaptive coordinated metro service operations with flexible train composition. Transp. Res. Part B Methodol. 2022, 161, 36–59. [Google Scholar] [CrossRef]
- Li, W.; Ni, S. Train timetabling with the general learning environment and multi-agent deep reinforcement learning. Transp. Res. Part B Methodol. 2022, 157, 230–251. [Google Scholar] [CrossRef]
- Lamorgese, L.; Mannino, C.; Pacciarelli, D.; Krasemann, J.T. Train dispatching. In Handbook of Optimization in the Railway Industry; Springer: Berlin/Heidelberg, Germany, 2018; pp. 265–283. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; The MIT Press: London, UK, 2020. [Google Scholar]
- Powell, W.B. Approximate Dynamic Programming: Solving the Curses of Dimensionality; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: London, UK, 2016. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep Reinforcement Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Watkins, C.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.; Graves, A.; Riedmiller, M.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Pacciarelli, D. Deliverable D3: Traffic Regulation and Co-operation Methodologies-code WP4UR_DV_7001_D. In Proj. COMBINE 2 “Enhanced COntrol Centres Fixed Mov. Block SIgNalling SystEms-2” Number: IST-2001-34705; 2003. [Google Scholar]
- Shuo Ying, C.; Chow, A.H.; Chin, K.S. An actor-critic deep reinforcement learning approach for metro train scheduling with rolling stock circulation under stochastic demand. Transp. Res. Part B Methodol. 2020, 140, 210–235. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Dimension | Type |
|---|---|---|
| The number of total trains () | 1 | Static |
| Physical network () | Static | |
| Junction indicator () | Static | |
| Occupation indicator () | Dynamic | |
| Next occupation indicator () | Dynamic | |
| Upward direction () | Dynamic | |
| Downward direction () | Dynamic | |
| Occupation beginning time () | Dynamic | |
| Occupation ending time () | Dynamic | |
| AG node in-degree () | Dynamic | |
| AG node out-degree () | Dynamic | |
| AG cost () | 1 | Dynamic |
| Hyperparameters | Values |
|---|---|
| The number of hidden layers | 4 |
| The numbers of nodes in each hidden layer | 1024, 512, 256, 128 |
| Decay factor of per episode | 0.9999 |
| Replay buffer size | 20,000,000 |
| Minibatch size | 256 |
| Discount factor | 0.9 |
| Target Q-network update frequency | 16 |
| M | 99,999 |
| U | MILP | DQN | |||
|---|---|---|---|---|---|
| # of Optimal | Avg. Runtime | # of Optimal | Avg. Runtime | Avg. GAP | |
| 300 | 100 | 0.005 s | 100 | 0.740 s | 0.00 |
| 600 | 100 | 0.005 s | 93 | 0.747 s | 0.01 |
| 900 | 100 | 0.005 s | 80 | 0.744 s | 0.14 |
| 1200 | 100 | 0.005 s | 71 | 0.770 s | 0.25 |
| (U, ) | MILP | DQN | |||
|---|---|---|---|---|---|
| # of Optimal | Avg. Runtime | # of Optimal | Avg. Runtime | Avg. GAP | |
| (300, 10) | 100 | 0.035 s | 82 | 4.582 s | 0.04 |
| (300, 12) | 100 | 0.043 s | 100 | 5.020 s | 0.00 |
| (300, 14) | 100 | 0.061 s | 100 | 6.268 s | 0.00 |
| (300, 16) | 100 | 0.077 s | 100 | 7.083 s | 0.00 |
| (300, 18) | 100 | 0.091 s | 100 | 8.005 s | 0.00 |
| (600, 10) | 100 | 0.035 s | 75 | 4.543 s | 0.11 |
| (600, 12) | 100 | 0.042 s | 100 | 5.154 s | 0.00 |
| (600, 14) | 100 | 0.054 s | 98 | 5.818 s | 0.00 |
| (600, 16) | 100 | 0.069 s | 94 | 6.669 s | 0.01 |
| (600, 18) | 100 | 0.078 s | 100 | 7.498 s | 0.00 |
| (900, 10) | 100 | 0.033 s | 58 | 4.278 s | 0.25 |
| (900, 12) | 100 | 0.044 s | 100 | 5.182 s | 0.00 |
| (900, 14) | 100 | 0.057 s | 93 | 5.957 s | 0.02 |
| (900, 16) | 100 | 0.067 s | 87 | 6.645 s | 0.05 |
| (900, 18) | 100 | 0.078 s | 98 | 7.354 s | 0.00 |
| (1200, 10) | 100 | 0.031 s | 71 | 4.019 s | 0.23 |
| (1200, 12) | 100 | 0.044 s | 98 | 5.180 s | 0.01 |
| (1200, 14) | 100 | 0.051 s | 85 | 5.619 s | 0.10 |
| (1200, 16) | 100 | 0.063 s | 81 | 6.352 s | 0.07 |
| (1200, 18) | 100 | 0.073 s | 88 | 7.184 s | 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, K.-M.; Rho, H.-L.; Park, B.-H.; Min, Y.-H. Deep Q-Network Approach for Train Timetable Rescheduling Based on Alternative Graph. Appl. Sci. 2023, 13, 9547. https://doi.org/10.3390/app13179547
Kim K-M, Rho H-L, Park B-H, Min Y-H. Deep Q-Network Approach for Train Timetable Rescheduling Based on Alternative Graph. Applied Sciences. 2023; 13(17):9547. https://doi.org/10.3390/app13179547
Chicago/Turabian StyleKim, Kyung-Min, Hag-Lae Rho, Bum-Hwan Park, and Yun-Hong Min. 2023. "Deep Q-Network Approach for Train Timetable Rescheduling Based on Alternative Graph" Applied Sciences 13, no. 17: 9547. https://doi.org/10.3390/app13179547
APA StyleKim, K. -M., Rho, H. -L., Park, B. -H., & Min, Y. -H. (2023). Deep Q-Network Approach for Train Timetable Rescheduling Based on Alternative Graph. Applied Sciences, 13(17), 9547. https://doi.org/10.3390/app13179547