
Efficient Dynamic Deployment of Simulation Tasks in Collaborative Cloud and Edge Environments


Abstract
:1. Introduction
- We formulate the problem of scheduling simulation tasks in collaborative cloud and edge environments as a MCMF problem and incremental MCMF algorithms are adopted to find the optimal flow quickly when the status of tasks and hosts changes;
- We propose a new heuristic method to reschedule tasks efficiently based on both the newly generated optimal flow and the current deployment decisions of all tasks to minimize both the overall communication cost and the migration cost of all tasks;
- Extensive experiments on Alibaba cluster trace are conducted to illustrate the effectiveness of Pool.
2. Related Works
2.1. Scheduler Structures
2.2. Scheduling Algorithms
3. Problem Statements
3.1. Application Background
3.2. Problem Modeling
4. Design of Pool
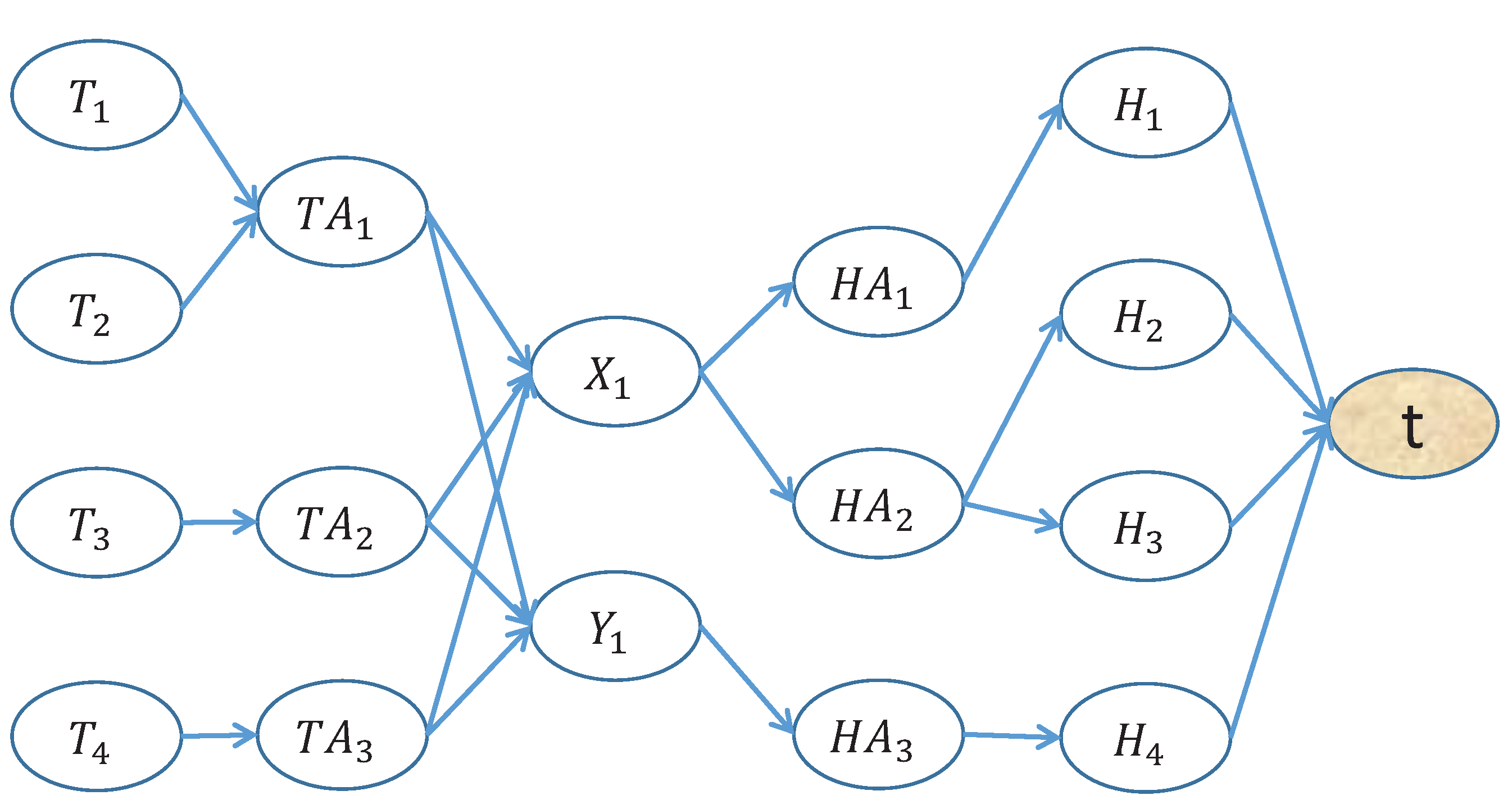
4.1. Basic Framework of Flow-Based Scheduling
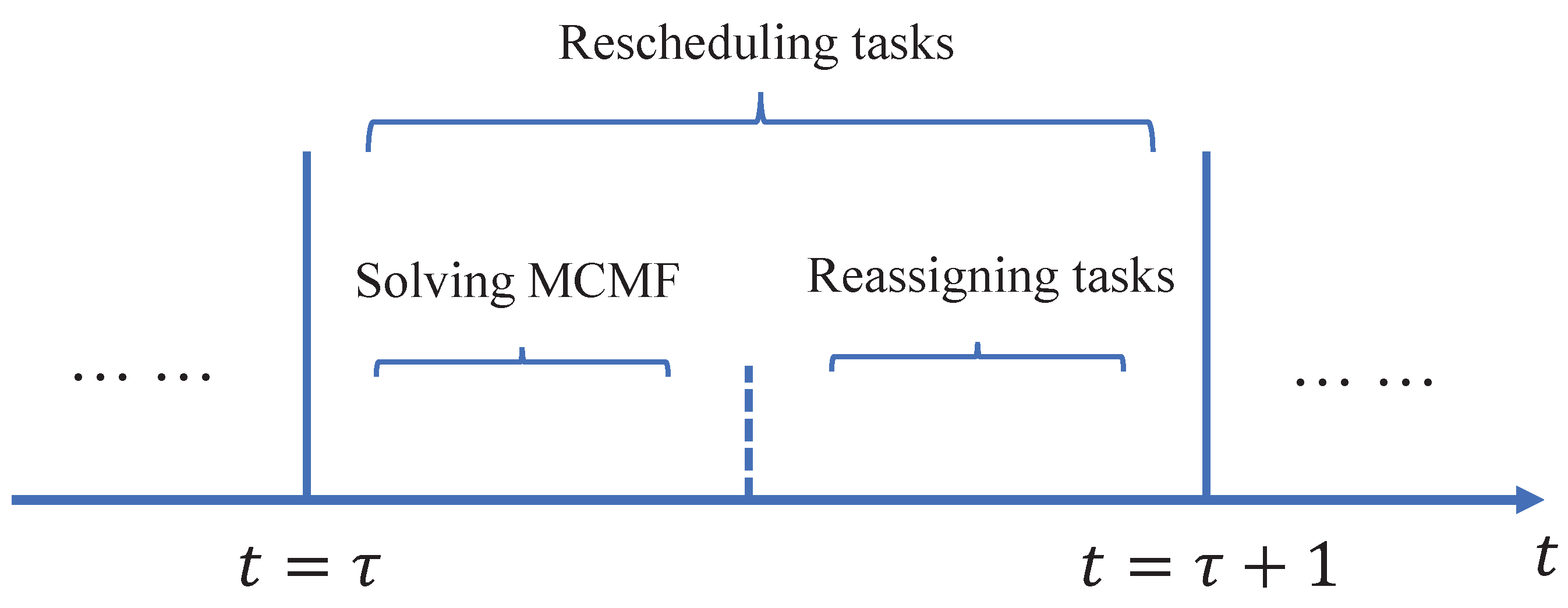
4.2. Obtaining Optimal Flow Incrementally
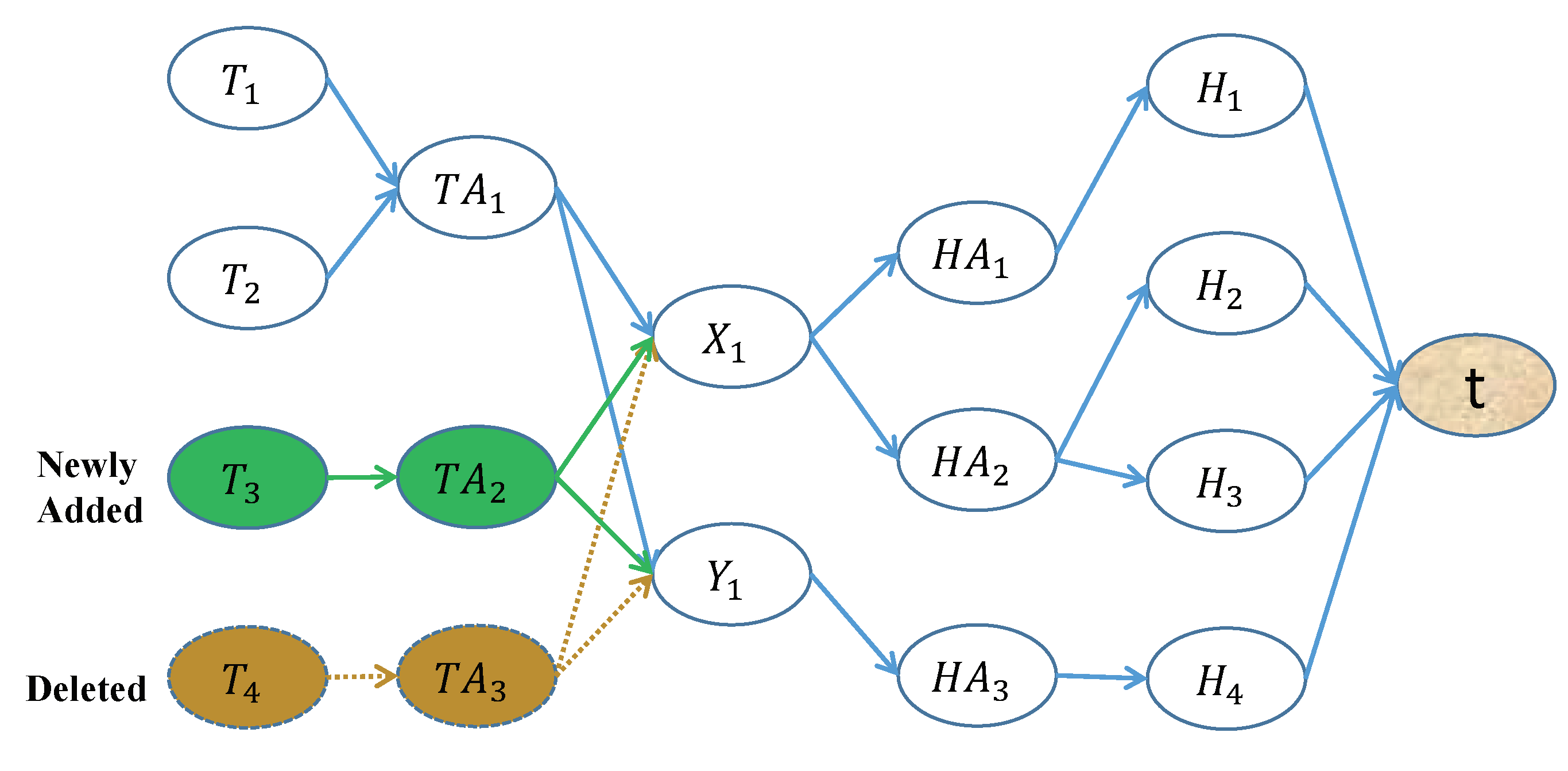
4.2.1. Changes of Tasks and Hosts
4.2.2. Solving MCMF Incrementally
4.3. Reassigning of Tasks
| Algorithm 1: Rescheduling of tasks in Pool |
 |
4.4. Time Complexity of Pool
5. Experiments and Analysis
5.1. Parameter Settings
5.2. Experiment Environment
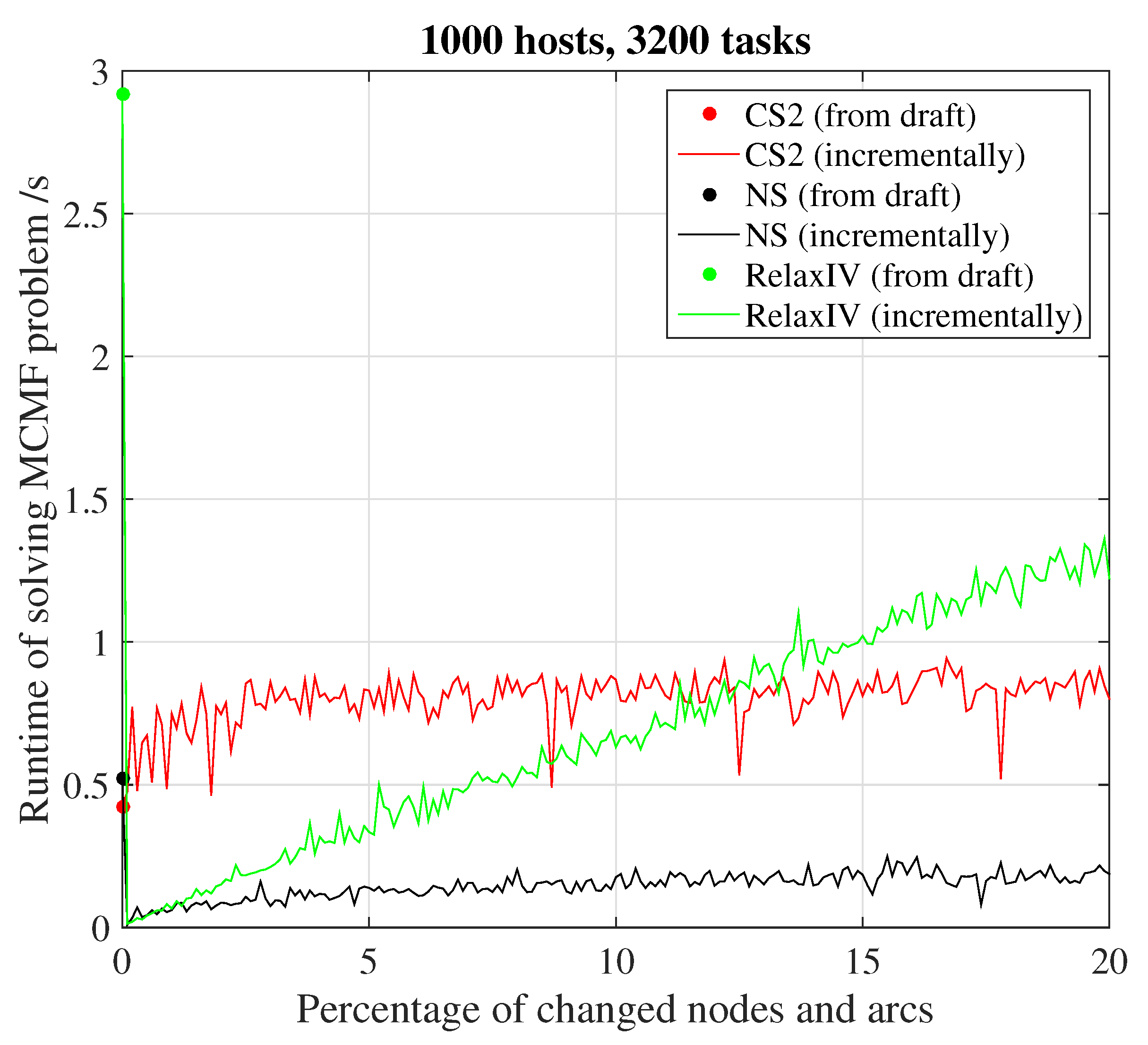
5.3. Time Performance
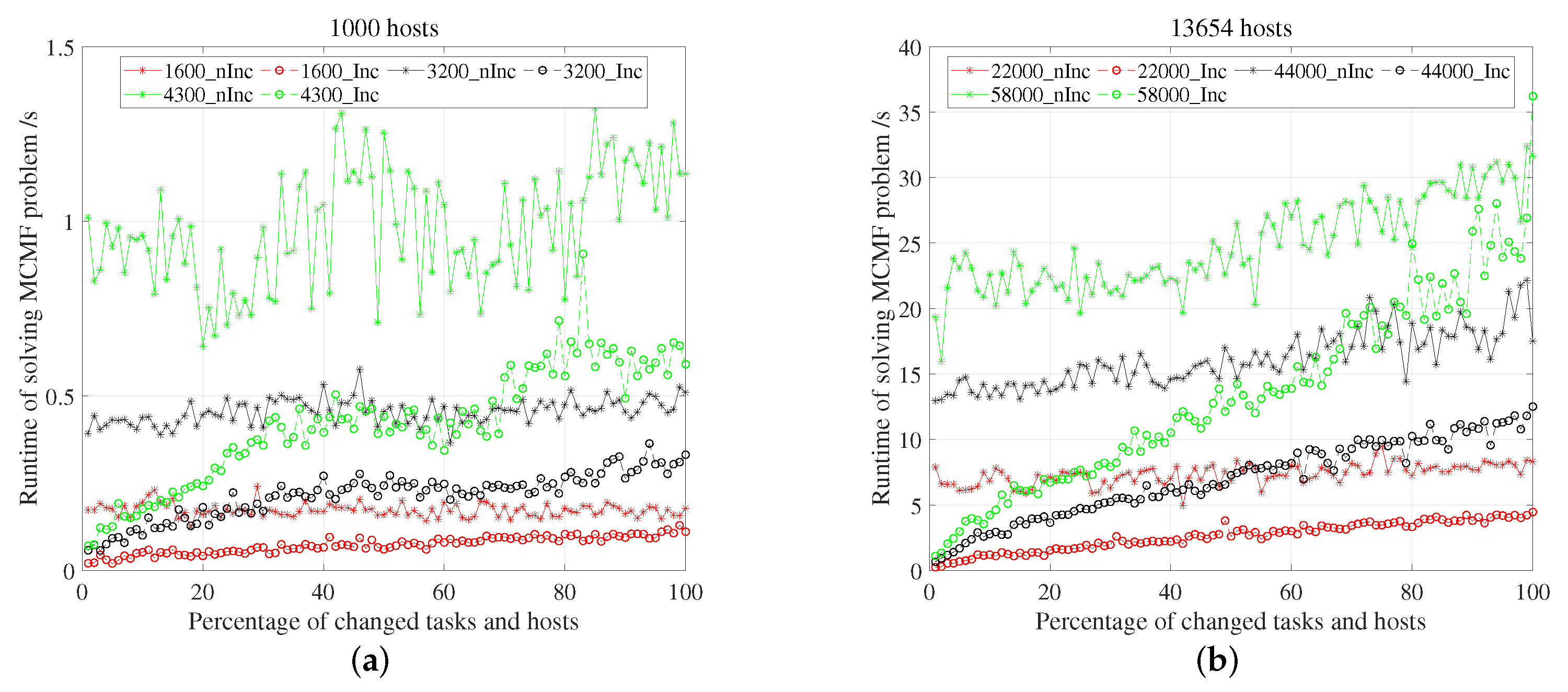
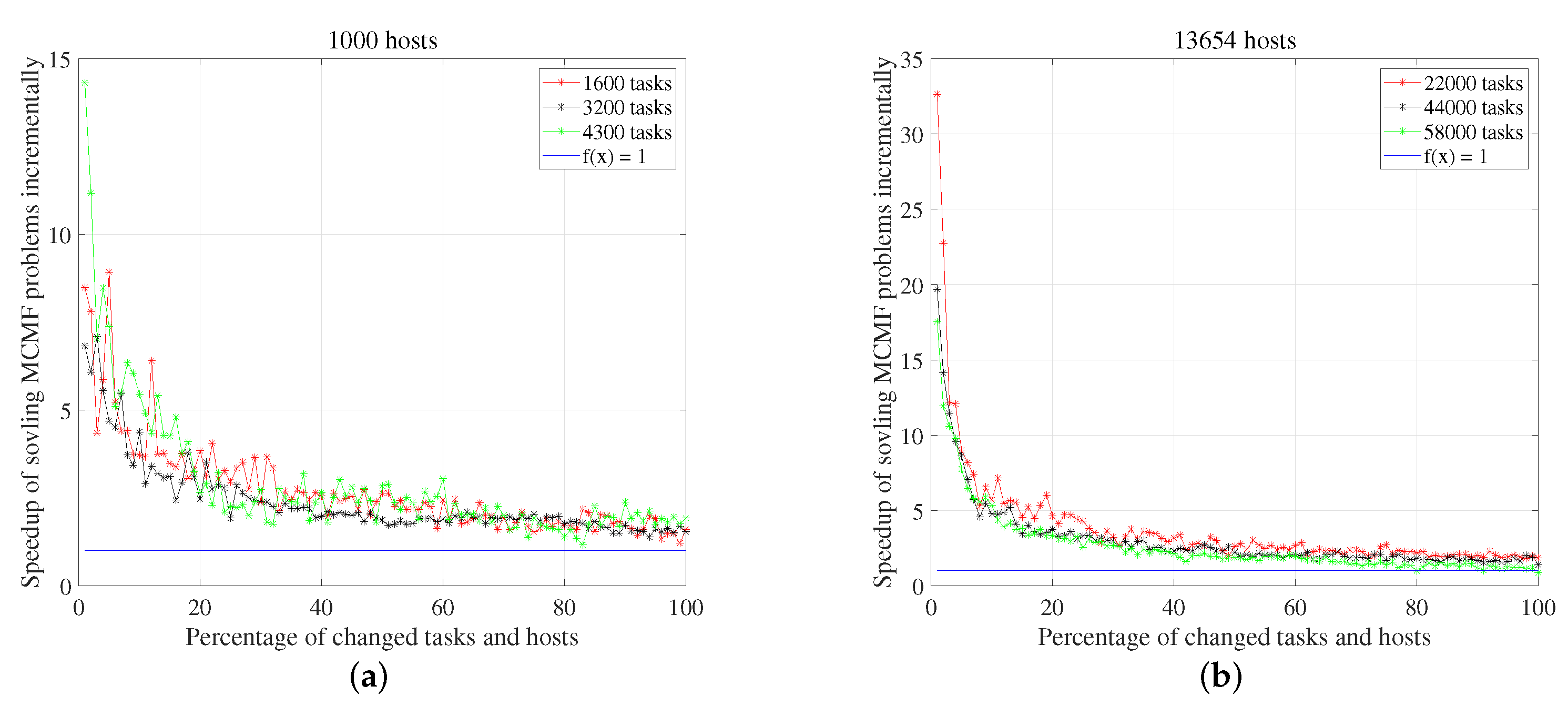
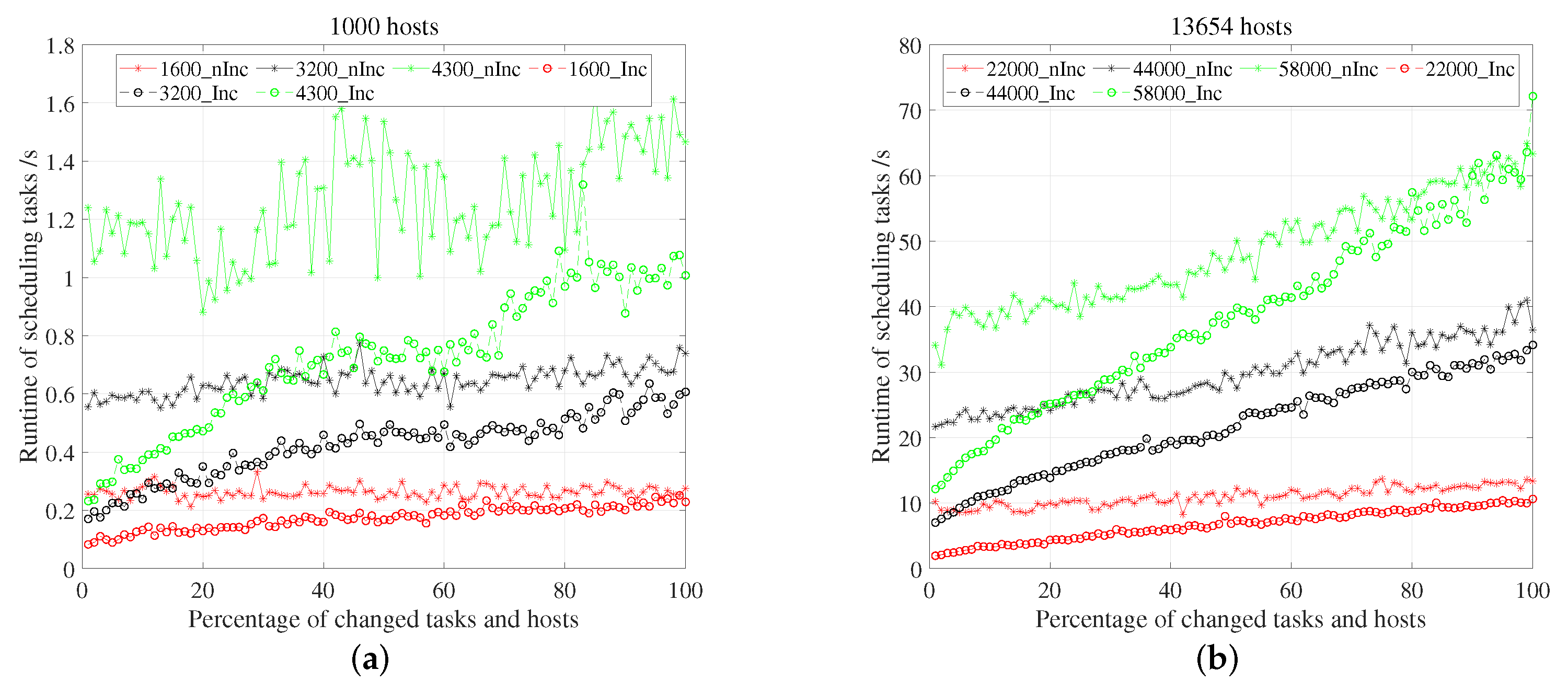
5.3.1. Time in Solving MCMF Problem
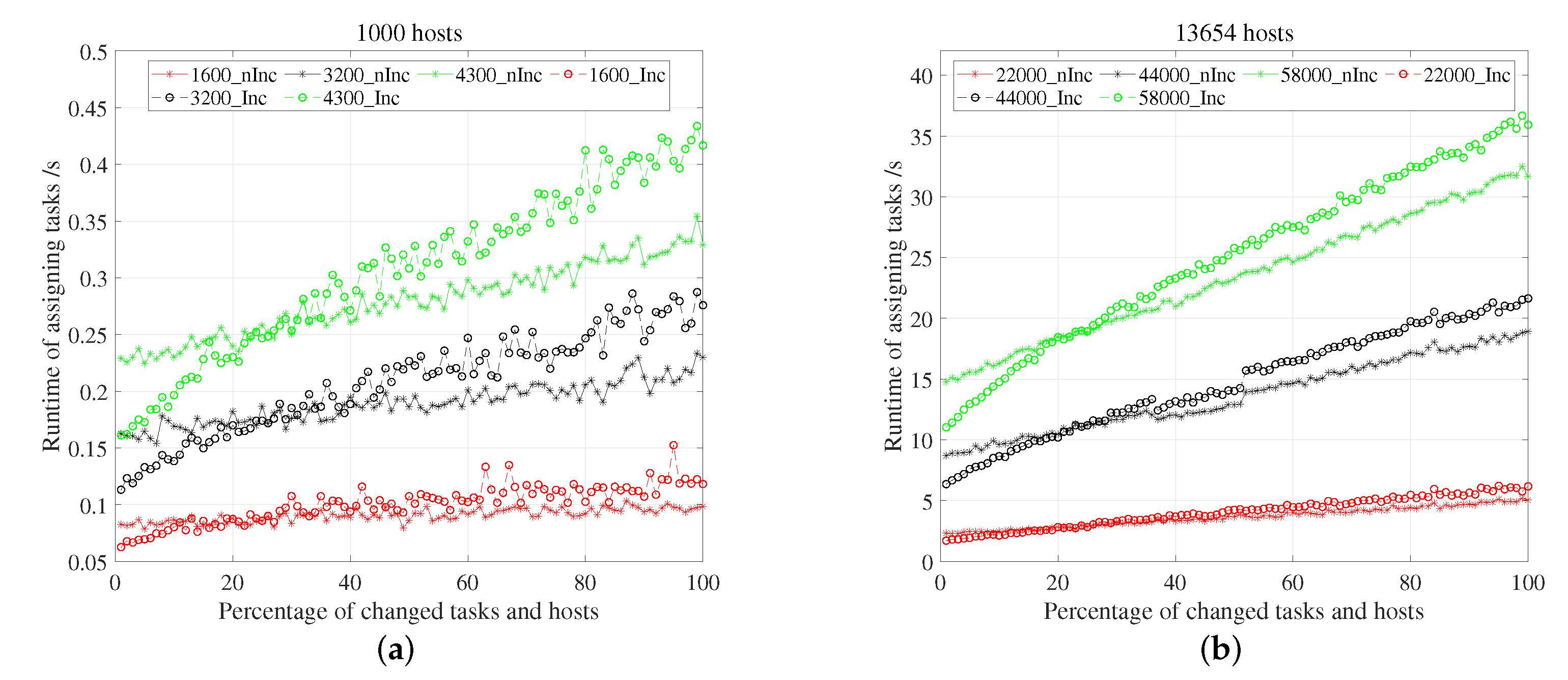
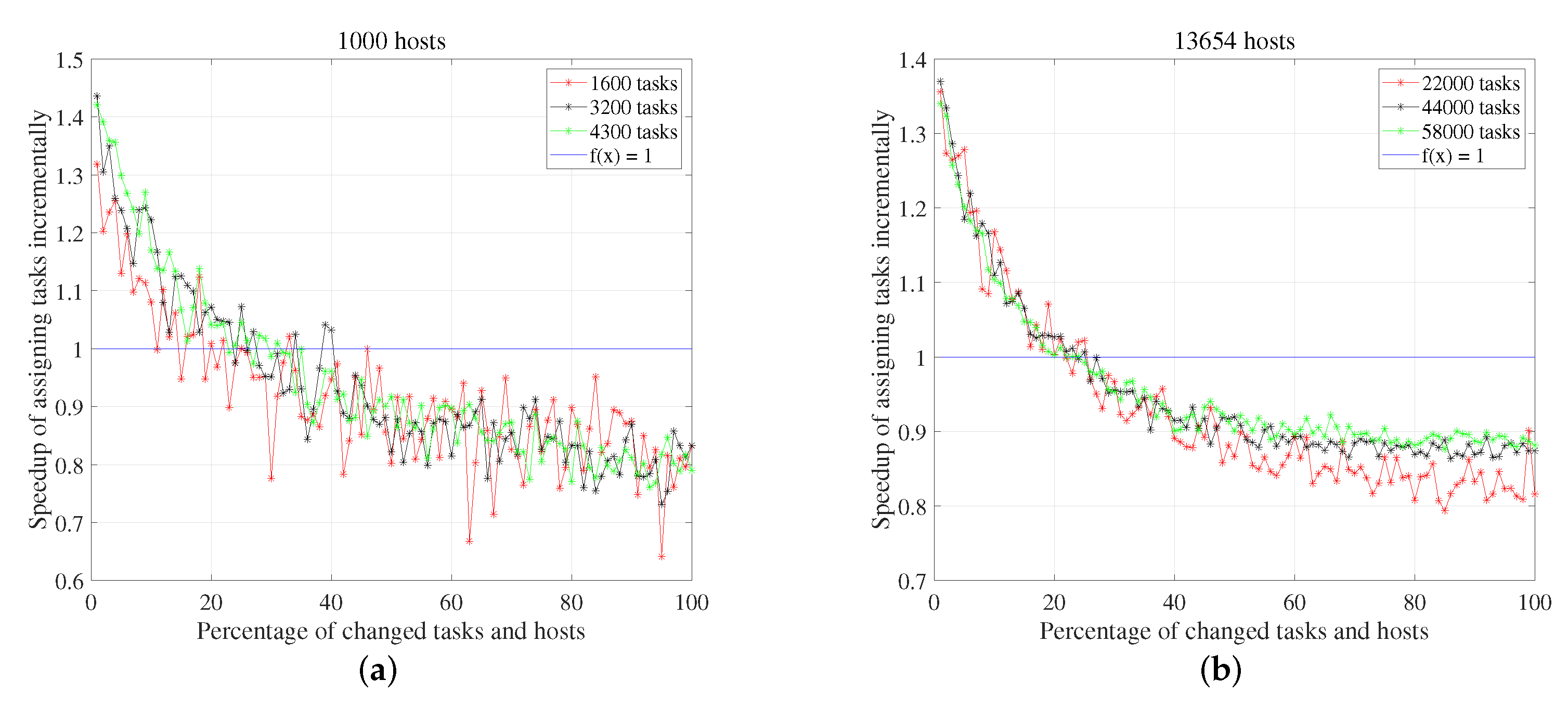
5.3.2. Time in Reassigning Tasks
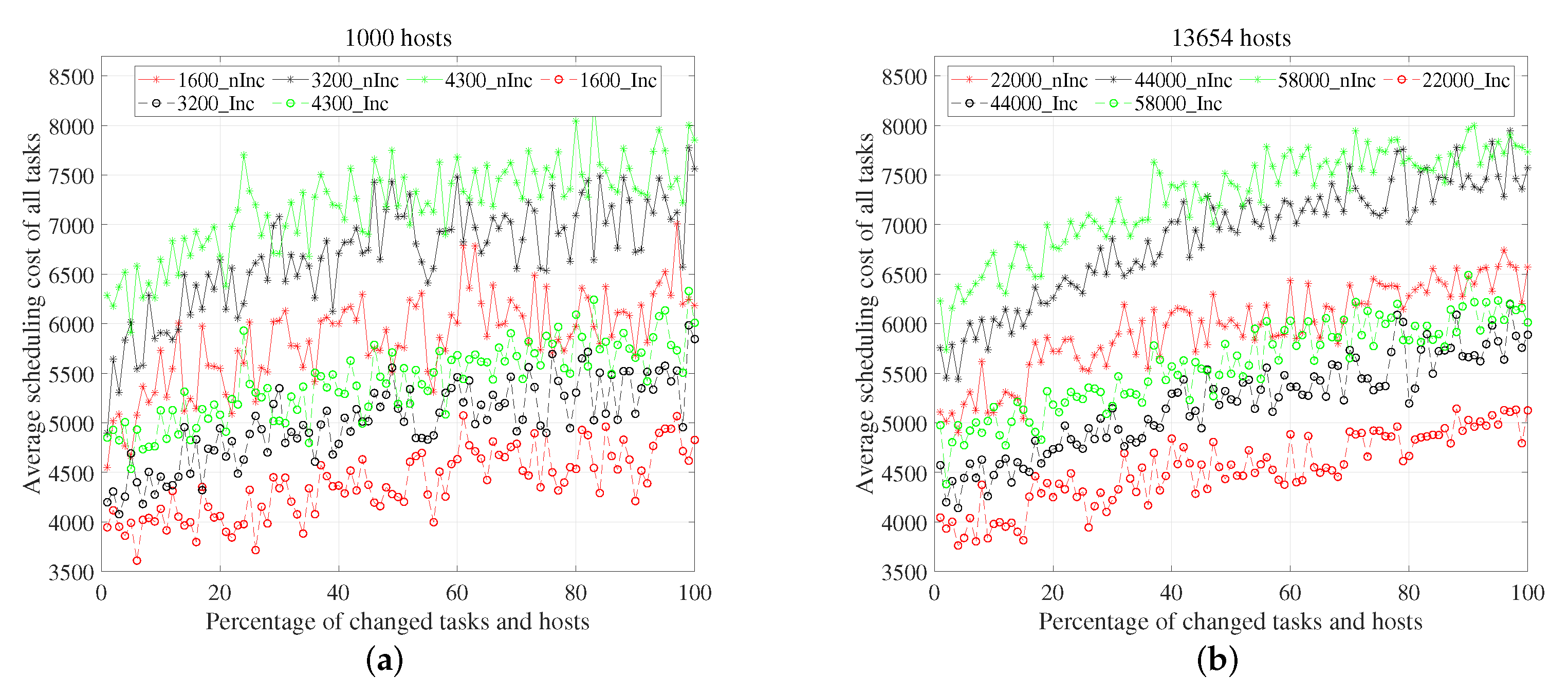
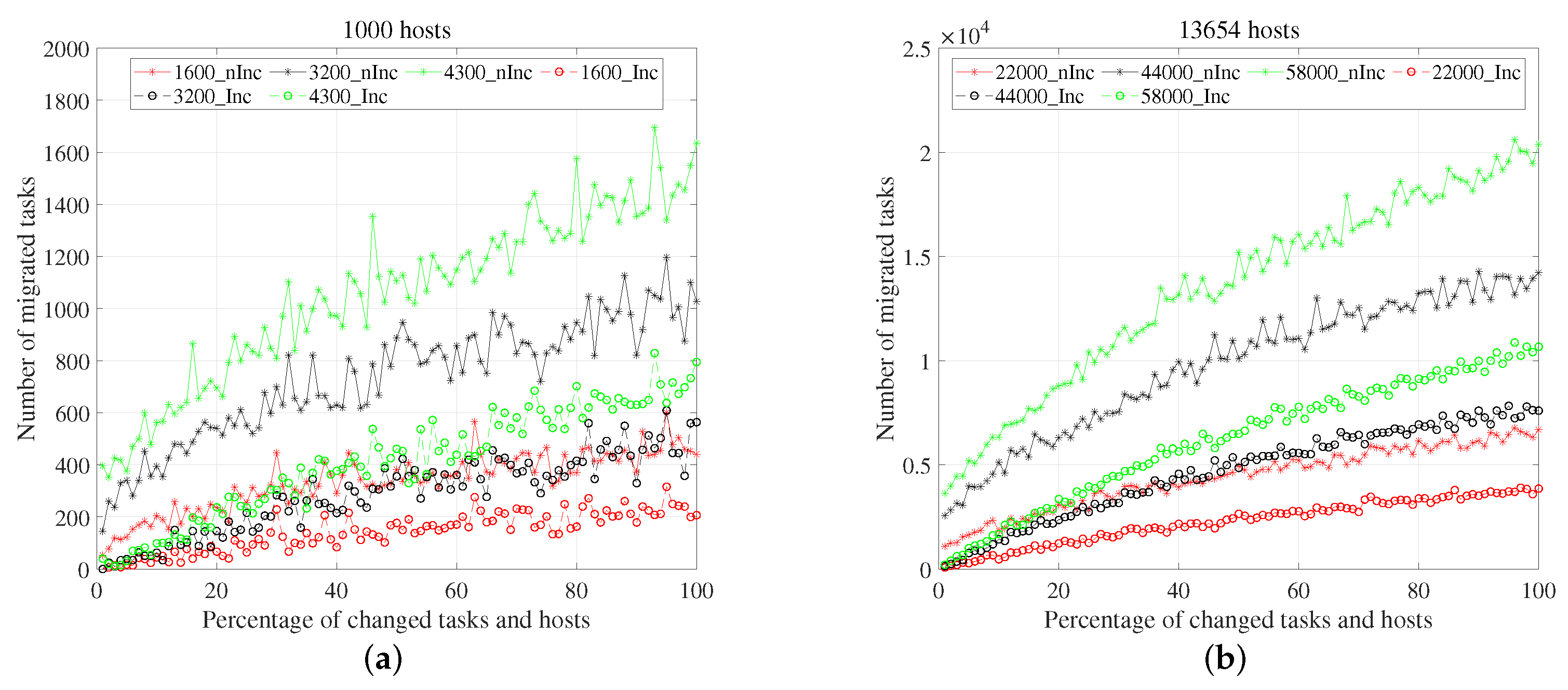
5.4. Deployment Quality
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peter Mell, T.G. The NIST Definition of Cloud Computing. Available online: https://csrc.nist.gov/publications/detail/sp/800-145/final (accessed on 24 November 2021).
- DoD. Defense Modeling and Simulation Reference Architecture, Version 1.0. 2020. Available online: https://www.msco.mil/MSReferences/PolicyGuidance.aspx (accessed on 24 November 2021).
- Fujimoto, R.; Bock, C.; Chen, W.; Page, E.; Panchal, J.H. Research Challenges in Modeling and Simulation for Engineering Complex Systems; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Taylor, S.J. Distributed simulation: State-of-the-art and potential for operational research. Eur. J. Oper. Res. 2019, 273, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Fujimoto, R.M.; Malik, A.W.; Park, A. Parallel and distributed simulation in the cloud. SCS M&S Mag. 2010, 3, 1–10. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Miao, Z.; Yong, P.; Mei, Y.; Quanjun, Y.; Xu, X. A discrete PSO-based static load balancing algorithm for distributed simulations in a cloud environment. Future Gener. Comput. Syst. 2021, 115, 497–516. [Google Scholar] [CrossRef]
- Verma, A.; Pedrosa, L.; Korupolu, M.; Oppenheimer, D.; Tune, E.; Wilkes, J. Large-Scale Cluster Management at Google with Borg. In Proceedings of the Tenth European Conference on Computer Systems, EuroSys ’15, Bordeaux, France, 21–24 April 2015; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Yang, Y.; Zhang, K.; Zhou, X.; Qiu, T.; Li, K.; Bao, Y. Rhythm: Component-Distinguishable Workload Deployment in Datacenters. In Proceedings of the Fifteenth European Conference on Computer Systems, EuroSys ’20, Heraklion, Greece, 27–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Delgado, P.; Didona, D.; Dinu, F.; Zwaenepoel, W. Job-Aware Scheduling in Eagle: Divide and Stick to Your Probes. In Proceedings of the Seventh ACM Symposium on Cloud Computing, SoCC ’16, Santa Clara, CA, USA, 5–7 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 497–509. [Google Scholar] [CrossRef] [Green Version]
- Fu, Z.; Tang, Z.; Yang, L.; Liu, C. An Optimal Locality-Aware Task Scheduling Algorithm Based on Bipartite Graph Modelling for Spark Applications. IEEE Trans. Parallel Distrib. Syst. 2020, 3, 2406–2420. [Google Scholar] [CrossRef]
- Hu, Z.; Li, B.; Chen, C.; Ke, X. FlowTime: Dynamic Scheduling of Deadline-Aware Workflows and Ad-Hoc Jobs. In Proceedings of the IEEE International Conference on Distributed Computing Systems, Vienna, Austria, 2–6 July 2018. [Google Scholar]
- Liu, C.; Li, K.; Li, K. A Game Approach to Multi-Servers Load Balancing with Load-Dependent Server Availability Consideration. IEEE Trans. Cloud Comput. 2021, 9, 1–13. [Google Scholar] [CrossRef]
- Talbi, E.G. Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 74. [Google Scholar] [CrossRef]
- Ghodsi, A.; Zaharia, M.; Hindman, B.; Konwinski, A.; Shenker, S.; Stoica, I. Dominant Resource Fairness: Fair Allocation of Multiple Resource Types. In Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation, NSDI’11, Boston, MA, USA, 30 March–1 April 2011; USENIX Association: San Jose, CA, USA, 2011; pp. 323–336. [Google Scholar]
- Govil, A.K. Priority Assignment in waiting line problem. Trab. Estad. Investig. Oper. 1971, 22, 97–103. [Google Scholar] [CrossRef]
- Isard, M.; Prabhakaran, V.; Currey, J.; Wieder, U.; Talwar, K.; Goldberg, A. Quincy: Fair Scheduling for Distributed Computing Clusters. In Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, SOSP ’09, Big Sky, MT, USA, 11–14 October 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 261–276. [Google Scholar] [CrossRef]
- Gog, I.; Schwarzkopf, M.; Gleave, A.; Watson, R.N.M.; Hand, S. Firmament: Fast, Centralized Cluster Scheduling at Scale. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, OSDI’16, Savannah, GA, USA, 2–4 November 2016; USENIX Association: San Jose, CA, USA, 2016; pp. 99–115. [Google Scholar]
- Wu, H.; Zhang, W.; Xu, Y.; Xiang, H.; Zhang, Z. Aladdin: Optimized Maximum Flow Management for Shared Production Clusters. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019. [Google Scholar]
- Jin, T.; Cai, Z.; Li, B.; Zheng, C.; Jiang, G.; Cheng, J. Improving Resource Utilization by Timely Fine-Grained Scheduling. In Proceedings of the Fifteenth European Conference on Computer Systems, EuroSys ’20, Heraklion, Greece, 27–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Delimitrou, C.; Sanchez, D.; Kozyrakis, C. Tarcil: Reconciling Scheduling Speed and Quality in Large Shared Clusters. In Proceedings of the Sixth ACM Symposium on Cloud Computing, SoCC ’15, Kohala Coast, HI, USA, 27–29 August 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 97–110. [Google Scholar] [CrossRef] [Green Version]
- Park, J.W.; Tumanov, A.; Jiang, A.; Kozuch, M.A.; Ganger, G.R. 3Sigma: Distribution-based cluster scheduling for runtime uncertainty. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018. [Google Scholar]
- Boutin, E.; Ekanayake, J.; Lin, W.; Shi, B.; Zhou, J.; Qian, Z.; Wu, M.; Zhou, L. Apollo: Scalable and Coordinated Scheduling for Cloud-Scale Computing. In Proceedings of the 11th USENIX Conference on Operating Systems Design and Implementation, Broomfield, CO, USA, 6–8 October 2014; OSDI’14. USENIX Association: San Jose, CA, USA, 2014; pp. 285–300. [Google Scholar]
- Forestiero, A.; Mastroianni, C.; Meo, M.; Papuzzo, G.; Sheikhalishahi, M. Hierarchical approach for green workload management in distributed data centers. In Proceedings of the European Conference on Parallel Processing, Porto, Portugal, 25–29 August 2014; pp. 323–334. [Google Scholar]
- Curino, C.; Krishnan, S.; Karanasos, K.; Rao, S.; Fumarola, G.M.; Huang, B.; Chaliparambil, K.; Suresh, A.; Chen, Y.; Heddaya, S.; et al. Hydra: A Federated Resource Manager for Data-Center Scale Analytics. In Proceedings of the 16th USENIX Conference on Networked Systems Design and Implementation, NSDI’19, Boston, MA, USA, 26–28 February 2019; USENIX Association: San Jose, CA, USA, 2019; pp. 177–191. [Google Scholar]
- Delgado, P.; Dinu, F.; Kermarrec, A.M.; Zwaenepoel, W. Hawk: Hybrid Datacenter Scheduling. In Proceedings of the Usenix Conference on Usenix Technical Conference, Santa Clara, CA, USA, 8–10 July 2015. [Google Scholar]
- Saleh, H.; Nashaat, H.; Saber, W.; Harb, H.M. IPSO task scheduling algorithm for large scale data in cloud computing environment. IEEE Access 2018, 7, 5412–5420. [Google Scholar] [CrossRef]
- Passino, K.M. Biomimicry of bacterial foraging for distributed optimization and control. IEEE Control. Syst. Mag. 2002, 22, 52–67. [Google Scholar] [CrossRef]
- Tang, L.; Li, Z.; Ren, P.; Pan, J.; Lu, Z.; Su, J.; Meng, Z. Online and offline based load balance algorithm in cloud computing. Knowl. Based Syst. 2017, 138, 91–104. [Google Scholar] [CrossRef]
- Pourghaffari, A.; Barari, M.; Sedighian Kashi, S. An efficient method for allocating resources in a cloud computing environment with a load balancing approach. Concurr. Comput. Pract. Exp. 2019, 31, e5285. [Google Scholar] [CrossRef]
- Kabir, M.S.; Kabir, K.M.; Islam, R. Process of load balancing in cloud computing using genetic algorithm. Electr. Comput. Eng. Int. J. 2015, 4. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Garg, R. Load balancing based task scheduling with ACO in cloud computing. In Proceedings of the 2017 International Conference on Computer and Applications (ICCA), Doha, United Arab Emirates, 6–7 September 2017; pp. 174–179. [Google Scholar]
- Cplex-Optimizer. Available online: https://www.ibm.com/analytics/cplex-optimizer (accessed on 24 November 2021).
- Garefalakis, P.; Karanasos, K.; Pietzuch, P.; Suresh, A.; Rao, S. Medea: Scheduling of long running applications in shared production clusters. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018. [Google Scholar]
- Manco, F.; Lupu, C.; Schmidt, F.; Mendes, J.; Kuenzer, S.; Sati, S.; Yasukata, K.; Raiciu, C.; Huici, F. My VM is Lighter (and Safer) than Your Container. In Proceedings of the 26th Symposium on Operating Systems Principles, SOSP ’17, Shanghai, China, 28–31 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 218–233. [Google Scholar] [CrossRef] [Green Version]
- The First DIMACS International Algorithm Implementation Challenge: Problem Definitions and Specifications; Technical Report; Centre for Discrete Mathematics and Theoretical Computer Science (DIMACS): New Brunswick, NJ, USA, 1991.
- Király, Z.; Kovács, P. Efficient implementations of minimum-cost flow algorithms. Acta Univ. Sapientiae Inform. 2012, 4, 67–118. [Google Scholar]
- Klein, M. A Primal Method for Minimal Cost Flows with Applications to the Assignment and Transportation Problems. Manag. Sci. 1967, 14, 205–220. [Google Scholar] [CrossRef] [Green Version]
- Orlin, J.B. A polynomial time primal network simplex algorithm for minimum cost flows. Math. Program. 1997, 78, 109–129. [Google Scholar] [CrossRef]
- Bertsekas, D.; Tseng, P. Relaxation Method for Minimum Cost Ordinary Network Flow Problems. Oper. Res. 1988, 36, 93–115. [Google Scholar] [CrossRef] [Green Version]
- Ahuja, R.K.; Magnanti, T.L.; Orlin, J.B. Network flows—Theory, algorithms and applications. J. Oper. Res. Soc. 1993, 45, 791–796. [Google Scholar]
- Goldberg, A.V. An Efficient Implementation of a Scaling Minimum-Cost Flow Algorithm. J. Algorithms 1997, 22, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Gleave, A. Fast and Scalable Cluster Scheduling Using Flow Networks; Computer Science Tripos Part II Dissertation; Computer Laboratory St John’s College, University of Cambridge: Cambridge, UK, 2015. [Google Scholar]
- Alibaba Cluster. Available online: https://github.com/alibaba/clusterdata (accessed on 24 November 2021).
- Antonio Frangioni, C.G.; Bertsekas, D.P. MCFClass Project. Available online: https://frangio68.github.io/Min-Cost-Flow-Class/ (accessed on 24 November 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Hosts | No. of Tasks | ||
|---|---|---|---|
| Low Load | Medium Load | High Load | |
| 1000 | 1600 | 3200 | 4300 |
| 13,654 | 22,000 | 44,000 | 58,000 |
| Symbol | Value | Description |
|---|---|---|
| 20 | Number of data centers | |
| 100 | Number of edge nodes | |
| 100 | Number of regions | |
| MB | Volume of interactive data between user and task i | |
| MB | Total volume of interactive data for task i | |
| Image size for task i | ||
| Task size for task i | ||
| (50,200) ms/MB | Unit transferring cost between region r and datacentre c | |
| (10,30) ms/MB | Unit transferring cost between region r and edge e | |
| (50,200) ms/MB | Unit transferring cost between edge e and datacentre c | |
| (50,200) ms/MB | Unit transferring cost between datacentre k and l |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Jiao, P.; Peng, Y.; Yin, Q. Efficient Dynamic Deployment of Simulation Tasks in Collaborative Cloud and Edge Environments. Appl. Sci. 2022, 12, 1646. https://doi.org/10.3390/app12031646
Zhang M, Jiao P, Peng Y, Yin Q. Efficient Dynamic Deployment of Simulation Tasks in Collaborative Cloud and Edge Environments. Applied Sciences. 2022; 12(3):1646. https://doi.org/10.3390/app12031646
Chicago/Turabian StyleZhang, Miao, Peng Jiao, Yong Peng, and Quanjun Yin. 2022. "Efficient Dynamic Deployment of Simulation Tasks in Collaborative Cloud and Edge Environments" Applied Sciences 12, no. 3: 1646. https://doi.org/10.3390/app12031646
APA StyleZhang, M., Jiao, P., Peng, Y., & Yin, Q. (2022). Efficient Dynamic Deployment of Simulation Tasks in Collaborative Cloud and Edge Environments. Applied Sciences, 12(3), 1646. https://doi.org/10.3390/app12031646