


Enhancing Retail Transactions: A Data-Driven Recommendation Using Modified RFM Analysis and Association Rules Mining


Abstract
:1. Introduction
2. Theoretical Framework
2.1. Modified RFM Model and Customer Engagement Index (CEI)
2.2. Unsupervised Machine Learning: Clustering and Association Rule Mining
2.3. Supervised Machine Learning: Classification
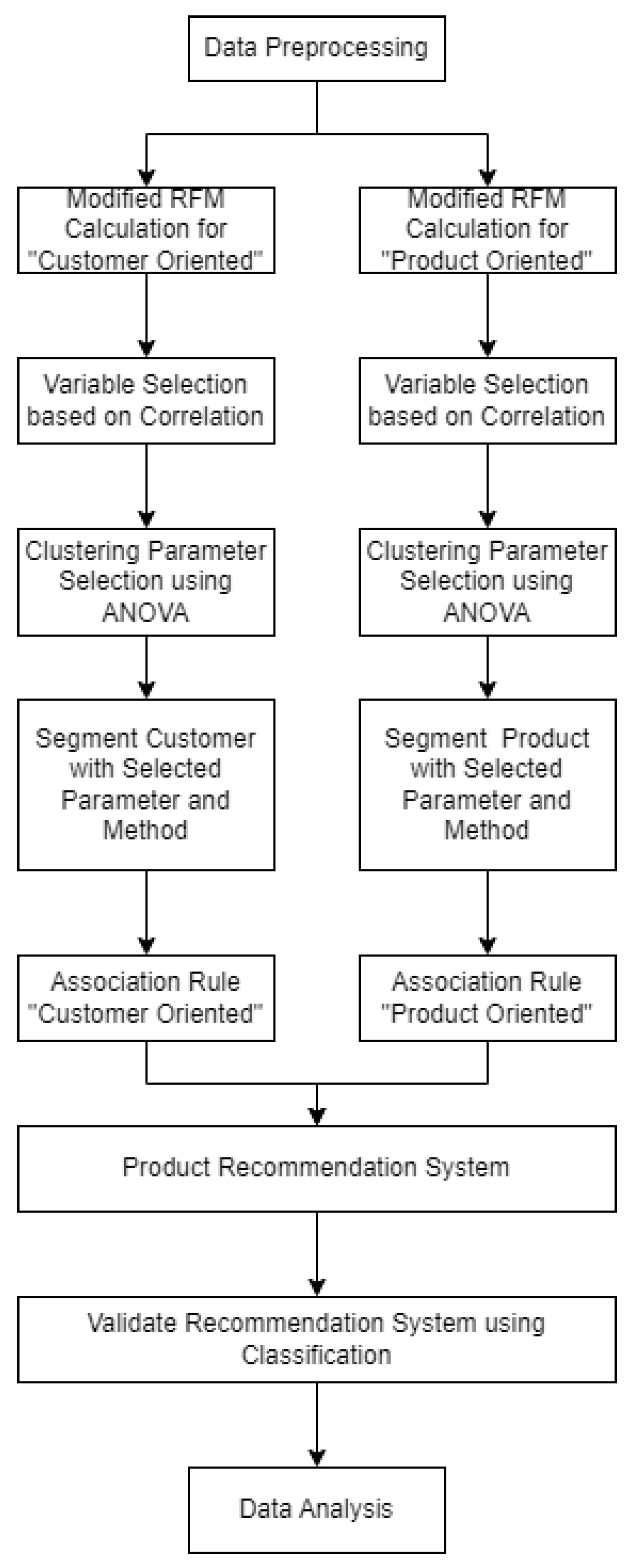
3. Research Methodology
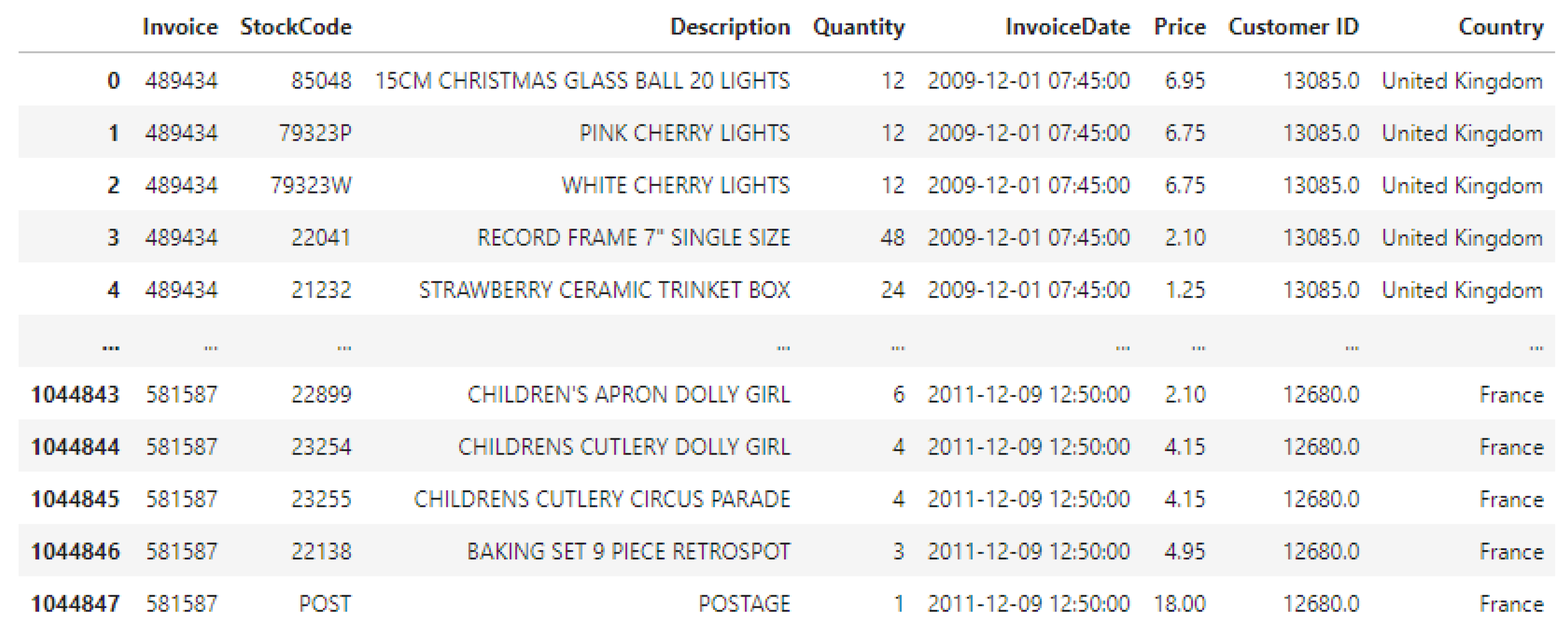
3.1. Data Description and Preprocessing
3.2. Modified RFM Value Calculation
3.3. Clustering Parameter Selection and Clustering
3.4. Association Rules Mining
3.5. Validation for Product Recommendation System
4. Results
4.1. Data Description and Preprocessing
4.2. Modified RFM Value Calculation
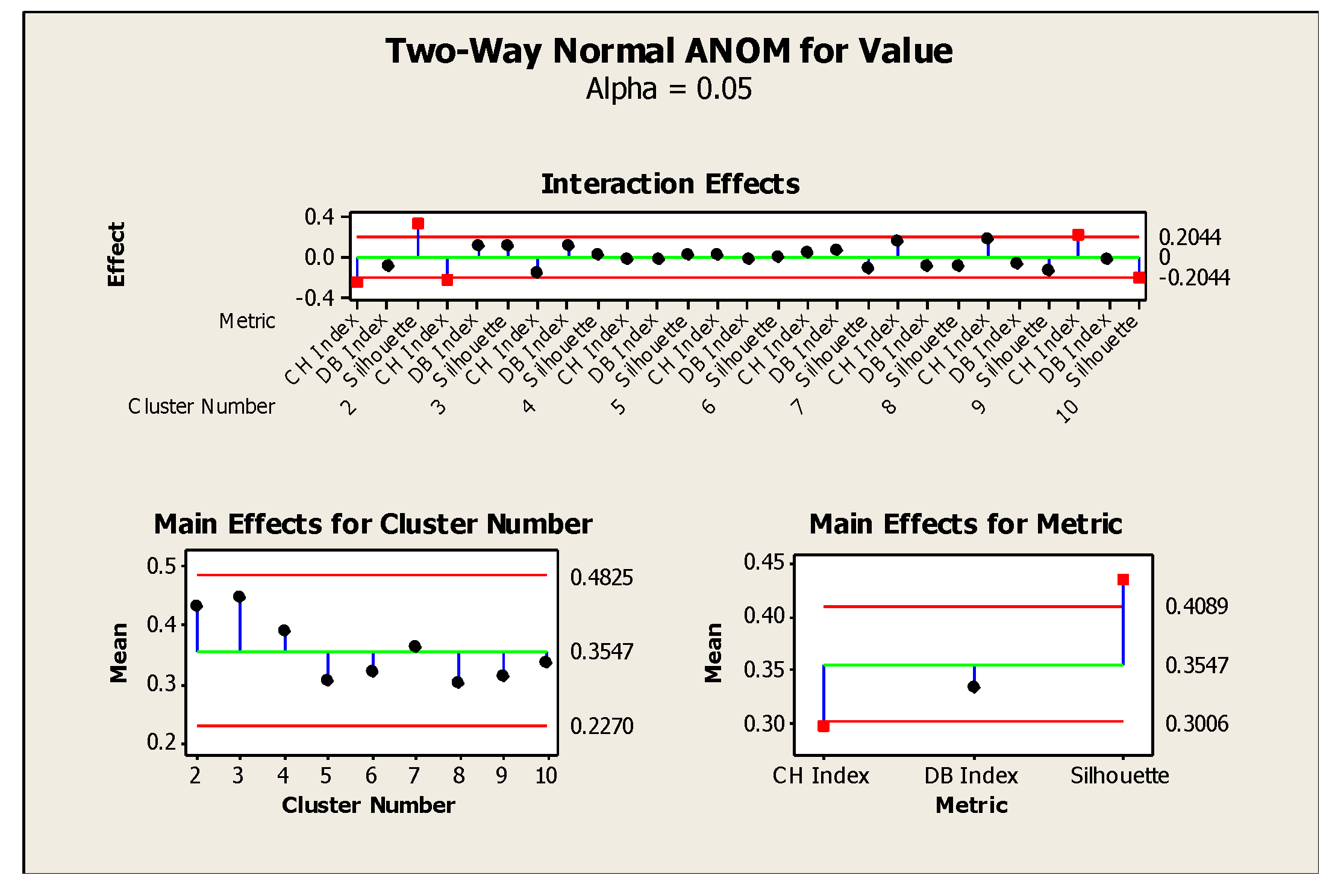
4.3. Clustering Parameter Selection and Result of Cluster
4.4. Association Rules Mining
4.5. Validation for Product Recommendation System
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chevalier, S. Retail E-Commerce Sales Worldwide from 2014 to 2026, Statista, Hamburg. 2022. Available online: https://www.statista.com/statistics/379046/worldwide-retail-e-commerce-sales/ (accessed on 29 August 2023).
- Sabanoglu, T. Estimated Value of the In-Store and e-Commerce Retail Sales Worldwide from 2022 and 2026, Statista, Hamburg. 2022. Available online: https://www.statista.com/statistics/443522/global-retail-sales/ (accessed on 29 August 2023).
- Alfian, T.; Sandi, A.; Raharjo, M.; Putra, J.L.; Ridwan, R. Clustering Kesetiaan Pelanggan E-Ritel Dengan Model Rfm (Recency, Frequency, Monetary) Dan K-Means. J. Pilar Nusa Mandiri 2018, 14, 239. [Google Scholar]
- Chen, D.; Guo, K.; Ubakanma, G. Predicting Customer Profitability over Time Based on RFM Time Series. Int. J. Bus. Forecast. Mark. Intell. 2015, 2, 1. [Google Scholar] [CrossRef]
- Chen, K.; Hu, Y.H.; Hsieh, Y.C. Predicting Customer Churn from Valuable B2B Customers in the Logistics Industry: A Case Study. Inf. Syst. E-Bus. Manag. 2015, 13, 475–494. [Google Scholar] [CrossRef]
- Chen, D.; Guo, K.; Li, B. Predicting Customer Profitability Dynamically over Time: An Experimental Comparative Study. In Proceedings of the Pattern Recognition, Image Analysis, Computer Vision, and Applications: 24th Iberoamerican Congress, CIARP 2019, Havana, Cuba, 28–31 October 2019. [Google Scholar]
- Lin, R.H.; Chuang, W.W.; Chuang, C.L.; Chang, W.S. Applied Big Data Analysis to Build Customer Product Recommendation Model. Sustainability 2021, 13, 4985. [Google Scholar] [CrossRef]
- Raorane, A.A.; Kulkarni, R.V.; Jitkar, B.D. Association Rule-Extracting Knowledge Using Market Basket Analysis. Res. J. Recent Sci. 2012, 2277, 2502. [Google Scholar]
- Liu, H.-W.; Wu, J.-Z.; Wu, F.-L. An App-Based Recommender System Based on Contrasting Automobiles. Processes 2023, 11, 881. [Google Scholar] [CrossRef]
- Hughes, A.M. Boosting Response with RFM. Mark. Tools 1996, 5, 4–10. [Google Scholar]
- Yeh, I.-C.; Yang, K.-J.; Ting, T.-M. Knowledge Discovery on RFM Model Using Bernoulli Sequence. Expert. Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Chang, H.-C.; Tsai, H.-P. Group RFM Analysis as a Novel Framework to Discover Better Customer Consumption Behavior. Expert. Syst. Appl. 2011, 38, 14499–14513. [Google Scholar] [CrossRef]
- Miglautsch, J.R. Thoughts on RFM Scoring. J. Database Mark. Cust. Strategy Manag. 2000, 8, 67–72. [Google Scholar] [CrossRef]
- Peker, S.; Kocyigit, A.; Eren, P.E. LRFMP Model for Customer Segmentation in the Grocery Retail Industry: A Case Study. Mark. Intell. Plan. 2017, 35, 544–559. [Google Scholar] [CrossRef]
- Jen, L.; Chou, C.H.; Allenby, G.M. The importance of modeling temporal dependence of timing and quantity in direct marketing. J. Mark. Res. 2009, 46, 482–493. [Google Scholar]
- Su, Z.X.; Liu, Y.Z.; Liu, H. A Customer Value-Based Framework for Database Marketing. J. Inf. Manag. 2013, 20, 341–366. [Google Scholar]
- Nainggolan, R.; Perangin-angin, R.; Simarmata, E.; Tarigan, A.F. Improved the Performance of the K-Means Cluster Using the Sum of Squared Error (SSE) Optimized by Using the Elbow Method. J. Phys. Conf. Ser. 2019, 1361, 012015. [Google Scholar] [CrossRef]
- Mahesh, B. Machine Learning Algorithms—A Review. Int. J. Sci. Res. 2019, 9, 381–386. [Google Scholar] [CrossRef]
- Yıldız, E.; Güngör Şen, C.; Işık, E.E. A Hyper-Personalized Product Recommendation System Focused on Customer Segmentation: An Application in the Fashion Retail Industry. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 571–596. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of Internal Clustering Validation Measures. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, NSW, Australia, 13–17 December 2010; pp. 911–916. [Google Scholar]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining Association Rules between Sets of Items in Large Databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data—SIGMOD, New York, NY, USA, 1 June 1993; ACM Press: New York, NY, USA, 1993; pp. 207–216. [Google Scholar]
- Ray, S. A Quick Review of Machine Learning Algorithms. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 35–39. [Google Scholar]
- Awotunde, J.B.; Folorunso, S.O.; Imoize, A.L.; Odunuga, J.O.; Lee, C.-C.; Li, C.-T.; Do, D.-T. An Ensemble Tree-Based Model for Intrusion Detection in Industrial Internet of Things Networks. Appl. Sci. 2023, 13, 2479. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Zhou, Y.; Qiu, G. Random Forest for Label Ranking. Expert. Syst. Appl. 2018, 112, 99–109. [Google Scholar] [CrossRef]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Singh, N.; Bhatnagar, S. Machine Learning for Prediction of Drug Targets in Microbe Associated Cardiovascular Diseases by Incorporating Host-pathogen Interaction Network Parameters. Mol. Inform. 2022, 41, 2100115. [Google Scholar] [CrossRef] [PubMed]
- Stojčić, M.; Banjanin, M.K.; Vasiljević, M.; Nedić, D.; Stjepanović, A.; Danilović, D.; Puzić, G. Predictive Modeling of Delay in an LTE Network by Optimizing the Number of Predictors Using Dimensionality Reduction Techniques. Appl. Sci. 2023, 13, 8511. [Google Scholar] [CrossRef]
- Chen, D.; Sain, S.L.; Guo, K. Data Mining for the Online Retail Industry: A Case Study of RFM Model-Based Customer Segmentation Using Data Mining. J. Database Mark. Cust. Strategy Manag. 2012, 19, 197–208. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Notes |
|---|---|
| Invoice | Bill ID for each of the customer’s transaction |
| StockCode | Product ID number |
| Description | Product name |
| Quantity | Number of products being purchased by the customer |
| InvoiceDate | Customer purchasing time |
| Price | The amount of money spent by consumers for each product |
| Customer ID | Customer membership ID number |
| Country | Location of delivery |
| Customer ID | Recency (Days) | Frequency (Times) | Monetary (USD) | CEI | Periodicity (Days) |
|---|---|---|---|---|---|
| 12346.0 | 348 | 25 | 170.40 | 0.997 | 60.68 |
| 12347.0 | 25 | 222 | 554.57 | 0.980 | 19.06 |
| 12348.0 | 98 | 51 | 193.10 | 0.994 | 57.55 |
| 12349.0 | 41 | 175 | 1480.44 | 0.986 | 18.66 |
| 12350.0 | 333 | 17 | 65.30 | 0.997 | 0.00 |
| ... | ... | ... | ... | ... | ... |
| 18283.0 | 26 | 938 | 1651.60 | 0.932 | 34.97 |
| 18284.0 | 454 | 28 | 91.09 | 0.996 | 0.00 |
| 18285.0 | 683 | 12 | 100.20 | 0.998 | 0.00 |
| 18286.0 | 499 | 67 | 286.30 | 0.992 | 0.00 |
| 18287.0 | 65 | 155 | 346.34 | 0.985 | 73.21 |
| Description | Recency (Days) | Frequency (Times) | Monetary (USD) | CEI | Periodicity (Days) |
|---|---|---|---|---|---|
| 15 cm Christmas Glass Ball 20 Lights | 76 | 437 | 3387.15 | 0.926 | 8.36 |
| Pink Cherry Lights | 76 | 230 | 1478.00 | 0.926 | 12.53 |
| White Cherry Lights | 76 | 216 | 1378.70 | 0.928 | 1.62 |
| Record Frame 7” Single Size | 76 | 323 | 792.95 | 0.942 | 3.02 |
| Strawberry Ceramic Trinket Box | 76 | 1859 | 2297.12 | 0.608 | 0.92 |
| ... | ... | ... | ... | ... | ... |
| Gin and Tonic Diet Metal Sign | 76 | 37 | 92.94 | 0.991 | 0.45 |
| Set of 6 Ribbons Party | 76 | 13 | 37.17 | 0.997 | 0.96 |
| Silver and Black Orbit Necklace | 76 | 1 | 2.95 | 1.000 | 0.00 |
| Cream Hanging Heart T-light Holder | 76 | 7 | 20.25 | 0.998 | 0.32 |
| Paper Craft, Little Birdie | 76 | 1 | 2.08 | 1.000 | 0.00 |
| Customer | Recency | Frequency | Monetary | CEI | Periodicity |
|---|---|---|---|---|---|
| Recency | 1.00 | −0.22 | −0.17 | 0.20 | −0.30 |
| Frequency | −0.22 | 1.00 | 0.89 | −1.00 | 0.01 |
| Monetary | −0.17 | 0.89 | 1.00 | −0.88 | 0.01 |
| CEI | 0.20 | −1.00 | −0.88 | 1.00 | −0.01 |
| Periodicity | −0.30 | 0.01 | 0.01 | −0.01 | 1.00 |
| Product | Frequency | Monetary | CEI | Periodicity |
|---|---|---|---|---|
| Frequency | 1.00 | 0.02 | −0.99 | −0.23 |
| Monetary | 0.02 | 1.00 | −0.35 | −0.08 |
| CEI | −0.99 | −0.35 | 1.00 | 0.24 |
| Periodicity | −0.23 | −0.08 | 0.24 | 1.00 |
| Model | Metrics | Methods | Cluster Number | ||
|---|---|---|---|---|---|
| RFM | Silhouette Index Calinski–Harabasz Index Davies–Bouldin Index | K-Means Clustering Ward’s Method | 2 | 3 | 4 |
| 5 | 6 | 7 | |||
| 8 | 9 | 10 | |||
| MPCEI | Silhouette Index Calinski–Harabasz Index Davies–Bouldin Index | K-Means Clustering Ward’s Method | 2 | 3 | 4 |
| 5 | 6 | 7 | |||
| 8 | 9 | 10 | |||
| FMP | Silhouette Index Calinski–Harabasz Index Davies–Bouldin Index | K-Means Clustering Ward’s Method | 2 | 3 | 4 |
| 5 | 6 | 7 | |||
| 8 | 9 | 10 | |||
| Source | DF | F | p-Value |
|---|---|---|---|
| Model | 2 | 149.74 | 0.000 |
| Method | 1 | 6.88 | 0.011 |
| Cluster Number | 8 | 4.7 | 0.000 |
| Metrics | 2 | 423.32 | 0.000 |
| Model and Method | 2 | 0.53 | 0.592 |
| Model and Cluster Number | 16 | 0.8 | 0.680 |
| Model and Metric | 4 | 260.08 | 0.000 |
| Method and Cluster Number | 8 | 0.4 | 0.914 |
| Method and Metric | 2 | 6 | 0.004 |
| Cluster Number and Metric | 16 | 6.57 | 0.000 |
| Model and Method and Cluster Number | 16 | 0.11 | 1.000 |
| Model and Method and Metric | 4 | 0.47 | 0.761 |
| Model and Cluster Number and Metric | 16 | 0.21 | 0.999 |
| Source | DF | F | p |
|---|---|---|---|
| Model | 2 | 136.82 | 0.000 |
| Method | 1 | 4.4 | 0.040 |
| Cluster Number | 8 | 2.01 | 0.059 |
| Metrics | 2 | 357.58 | 0.000 |
| Model and Method | 2 | 0.04 | 0.959 |
| Model and Cluster Number | 16 | 1.48 | 0.135 |
| Model and Metric | 4 | 82.2 | 0.000 |
| Method and Cluster Number | 8 | 0.13 | 0.997 |
| Method and Metric | 2 | 4.55 | 0.014 |
| Cluster Number and Metric | 16 | 19.39 | 0.000 |
| Model and Method and Cluster Number | 16 | 0.07 | 1.000 |
| Model and Method and Metric | 4 | 1.06 | 0.384 |
| Model and Cluster Number and Metric | 16 | 0.59 | 0.881 |
| Cluster 1 (Potential Customer—1160 Cust) | Cluster 2 (Loyal Customer—4710 Cust) | |||||
|---|---|---|---|---|---|---|
| Monetary | CEI Index | Periodicity | Monetary | CEI Index | Periodicity | |
| Min | 3.450 | 0.000 | 2.110 | 0.000 | 0.691 | 0.000 |
| Mean | 538.380 | 0.986 | 132.770 | 399.096 | 0.988 | 16.022 |
| Max | 56,337.290 | 0.999 | 495.750 | 13,916.340 | 1.000 | 72.610 |
| Cluster 1 (Best Seller—4870 Products) | Cluster 2 (Profitable—391 Products) | Cluster 3 (VIP—18 Products) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Frequency | Monetary | Periodicity | Frequency | Monetary | Periodicity | Frequency | Monetary | Periodicity | |
| Min | 1.000 | 0.017 | 0.000 | 3.000 | 0.480 | 1.239 | 3.000 | 0.570 | 0.425 |
| Mean | 155.932 | 454.953 | 10.050 | 15.163 | 58.806 | 91.096 | 900.722 | 14,780.086 | 249.059 |
| Max | 2045.000 | 12,528.000 | 51.309 | 2099.00 | 10,013.57 | 231.316 | 5016.000 | 146,269.190 | 498.507 |
| Cluster | Antecedents | Consequents | Support | Confidence | Lift |
|---|---|---|---|---|---|
| Potential | Toys | Stationery, Storage | 20.047% | 65.421% | 1.672 |
| Potential | Stationery, Storage | Toys | 20.047% | 51.228% | 1.672 |
| Potential | Bag, Gift | Stationery, Decoration, Kitchen Utensils | 21.443% | 78.506% | 1.630 |
| Potential | Stationery, Decoration, Kitchen Utensils | Bag, Gift | 21.443% | 44.520% | 1.630 |
| Potential | Bag, Decoration, Gift | Stationery, Kitchen Utensils | 21.443% | 81.409% | 1.626 |
| Potential | Stationery, Kitchen Utensils | Bag, Decoration, Gift | 21.443% | 42.835% | 1.626 |
| Potential | Decoration, Kitchen Utensils, Gift | Stationery, Bag | 21.443% | 55.465% | 1.619 |
| Potential | Stationery, Bag | Decoration, Kitchen Utensils, Gift | 21.443% | 62.606% | 1.619 |
| Potential | Decoration, Bag, Kitchen Utensils | Stationery, Gift | 21.443% | 51.945% | 1.614 |
| Potential | Stationery, Gift | Decoration, Bag, Kitchen Utensils | 21.443% | 66.626% | 1.614 |
| Loyal | Stationery, Kitchen Utensils | Bag, Storage | 20.43% | 47.11% | 1.599 |
| Loyal | Bag, Storage | Stationery, Kitchen Utensils | 20.43% | 69.35% | 1.599 |
| Loyal | Bag, Kitchen Utensils | Stationery, Storage | 20.43% | 50.82% | 1.593 |
| Loyal | Stationery, Storage | Bag, Kitchen Utensils | 20.43% | 64.03% | 1.593 |
| Loyal | Stationery, Decoration | Bag, Storage | 20.41% | 46.38% | 1.575 |
| Loyal | Bag, Storage | Stationery, Decoration | 20.41% | 69.30% | 1.575 |
| Loyal | Stationery, Storage | Bag, Decoration | 20.41% | 63.98% | 1.562 |
| Loyal | Bag, Decoration | Stationery, Storage | 20.41% | 49.83% | 1.562 |
| Loyal | Stationery, Bag | Kitchen Utensils, Storage | 20.43% | 71.24% | 1.550 |
| Loyal | Kitchen Utensils, Storage | Stationery, Bag | 20.43% | 44.44% | 1.550 |
| Cluster | Antecedents | Consequents | Support | Confidence |
|---|---|---|---|---|
| Best-Seller | Loyal | Potential | 91.62% | 93.22% |
| Best-Seller | Potential | Loyal | 91.62% | 98.88% |
| Profitable | Potential | Loyal | 88.52% | 100% |
| Profitable | Loyal | Potential | 88.52% | 88.52% |
| VIP | Potential | Loyal | 88.52% | 100% |
| VIP | Loyal | Potential | 88.52% | 88.52% |
| Classifier | Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Random Forest Classifier | Training | 0.094 | 0.44 | 0.1 | 0.12 |
| Testing | 0.042 | 0.1 | 0.06 | 0.07 | |
| Decision Tree + Bagging Algorithm | Training | 0.088 | 0.4 | 0.1 | 0.12 |
| Testing | 0.051 | 0.1 | 0.07 | 0.07 | |
| Decision Tree + AdaBoost Algorithm | Training | 0.096 | 0.43 | 0.13 | 0.12 |
| Testing | 0.051 | 0.11 | 0.09 | 0.09 | |
| K-Nearest Neighbor | Training | 0.06 | 0.25 | 0.1 | 0.13 |
| Testing | 0.025 | 0.24 | 0.08 | 0.11 |
| Product | Customer | Amount of Transaction | Percentage |
|---|---|---|---|
| Best-Seller | Loyal | 582,581 | 74.74 |
| Potential | 176,809 | 22.68 | |
| VIP | Loyal | 2674 | 0.34 |
| Potential | 1171 | 0.15 | |
| Profitable | Loyal | 13,194 | 1.69 |
| Potential | 3019 | 0.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, A.H.-L.; Gunawan, S. Enhancing Retail Transactions: A Data-Driven Recommendation Using Modified RFM Analysis and Association Rules Mining. Appl. Sci. 2023, 13, 10057. https://doi.org/10.3390/app131810057
Chen AH-L, Gunawan S. Enhancing Retail Transactions: A Data-Driven Recommendation Using Modified RFM Analysis and Association Rules Mining. Applied Sciences. 2023; 13(18):10057. https://doi.org/10.3390/app131810057
Chicago/Turabian StyleChen, Angela Hsiang-Ling, and Sebastian Gunawan. 2023. "Enhancing Retail Transactions: A Data-Driven Recommendation Using Modified RFM Analysis and Association Rules Mining" Applied Sciences 13, no. 18: 10057. https://doi.org/10.3390/app131810057
APA StyleChen, A. H. -L., & Gunawan, S. (2023). Enhancing Retail Transactions: A Data-Driven Recommendation Using Modified RFM Analysis and Association Rules Mining. Applied Sciences, 13(18), 10057. https://doi.org/10.3390/app131810057