



Unsupervised Community Detection Algorithm with Stochastic Competitive Learning Incorporating Local Node Similarity
Abstract
:1. Introduction
- (1)
- Determining the initial positions of particles based on node degrees and the Salton similarity index, ensuring fixed and dispersed particle placements to mitigate intense early-stage competition and subsequently accelerate convergence speed;
- (2)
- Incorporating the proposed node similarity measure to enhance the deterministic and directional aspects of particle preferential walk rules; refining the rules for selecting particle resurrection positions; introducing a node affiliation selection step to refine the final community detection results and enhance algorithm stability;
- (3)
- Dynamically adapting the increment of particle control ability according to the particle’s current control range, thereby improving the effectiveness of detecting communities of varying sizes within the network;
- (4)
- The LNSSCL algorithm is experimentally compared with 12 representative algorithms on real network datasets and synthetic networks. The results demonstrate that the proposed algorithm enhances the community detection performance of stochastic competitive learning and, overall, outperforms other algorithms.
2. Related Work
3. Background
3.1. Basic Definition
3.2. Local Node Similarity
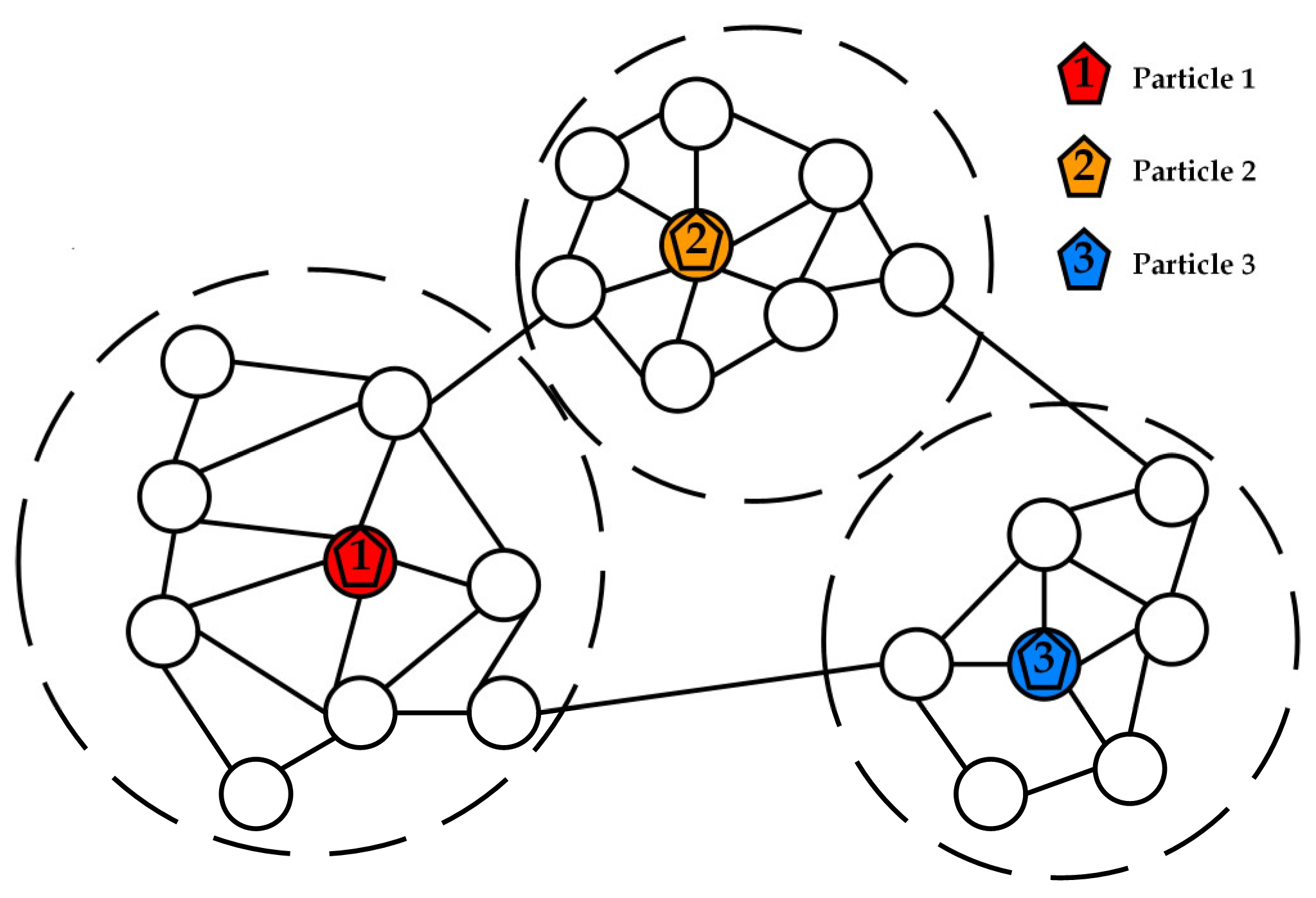
3.3. Stochastic Competitive Learning
4. LNSSCL Algorithm
4.1. Determining Particle Initialization Positions
4.2. Incorporating Node Local Similarity into Particle Preferential Movement Rule
4.3. Dynamically Adjusting Particle Control Capacity Increment
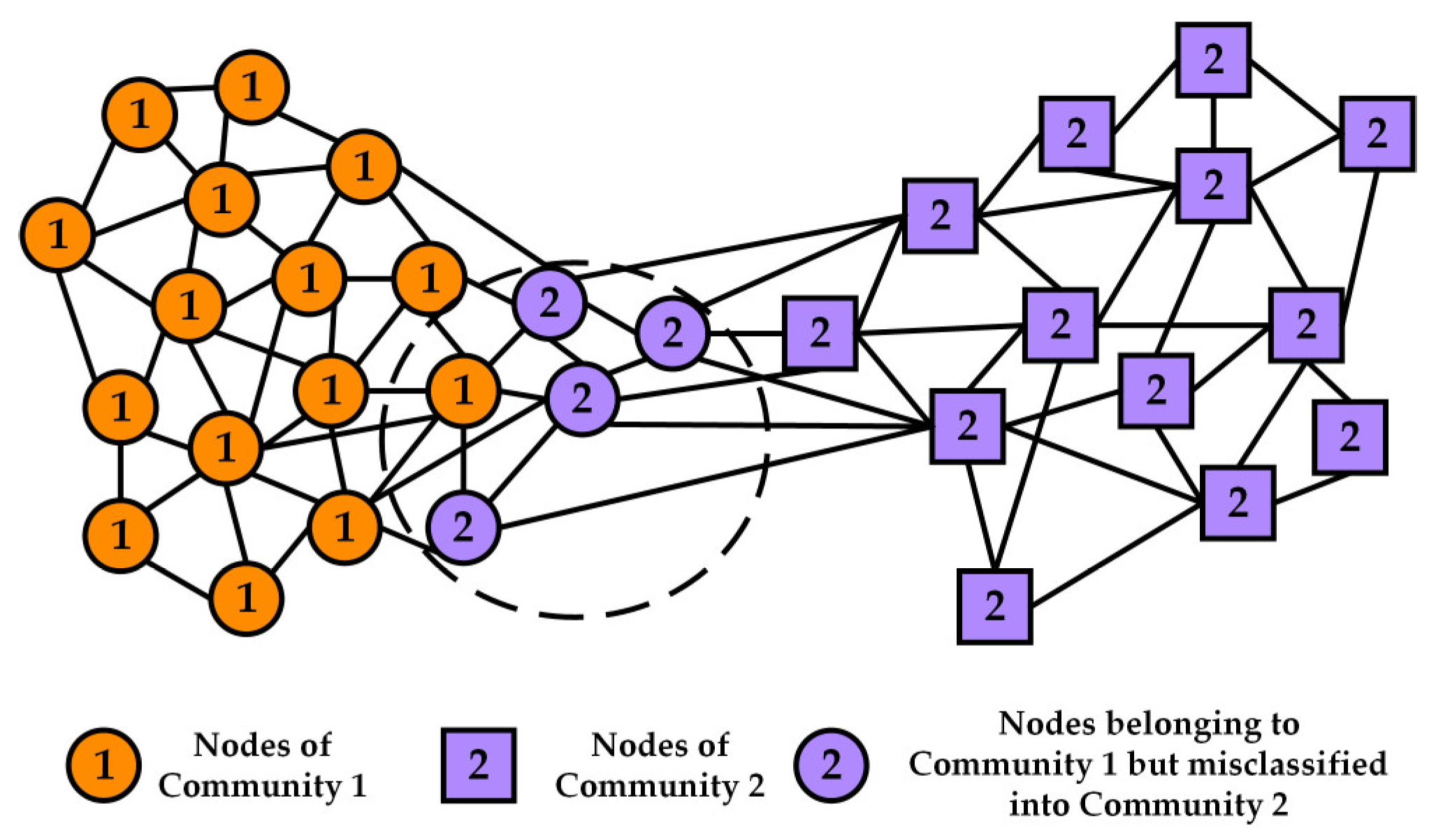
4.4. Determining Particle Resurrection Locations and Node Affiliation Selection
4.5. Algorithm Description
| Algorithm 1 LNSSCL algorithm |
| Input: Graph The probability of preferential walk for particles , |
| Particle energy increment , Convergence factor |
| Output: The number of communities , The set of communities |
| 1: |
| 2: |
| 3: repeat |
| 1: for each particle do: |
| 5: calculate the initial positions of particles using Equation (10) |
| 6: end for |
| 7: repeat |
| 8: for to do: |
| 9: calculate the particle’s random walk probability using Equation (4) |
| 10: calculate the particle’s preferential walk probability using Equation (11), (12), and (13) |
| 11: calculate the particle’s walk probability using Equation (3) |
| 12: particles walk based on the walk probability and dynamically adjust the particle’s control increment using Equation (15) |
| 13: if : |
| 14: particle performs the revival step by jumping to the node within their control range that possesses the maximum control capability for revival and re-energization. |
| 15: end if |
| 16: end for |
| 17: update , , , |
| 18: |
| 19: until Equation (7) is satisfied |
| 20: calculating and record the average maximum control capability indicator for particles using Equation (8). |
| 21: |
| 22: until reaches its maximum value |
| 23: assign the number of particles corresponding to step 22 to |
| 24: for each node do: |
| 25: Assign the corresponding community label to node based on the mag- nitude relationship of |
| 26: end for |
| 27: for each node do: |
| 28: get the set of neighboring nodes for node and count the frequen- cy of appearance of community labels for each neighboring node |
| 29: if the most frequently occurring neighboring community label is unique: |
| 30: the label of node is updated to the most frequently occurring community label. |
| 31: else: |
| 32: calculate the power score of each most frequent community using Equation (16) |
| 33: the label of node is updated to the community label with the highest community effectiveness score |
| 34: end if |
| 35: end for |
| 36: return , |
4.6. Time Complexity Analysis
5. Experiments and Discussions
5.1. Experimental Environment and Initial Parameters
5.2. Datasets
5.3. Evaluation Index
5.4. Experimental Results and Analysis
5.4.1. Experimental Results and Analysis on Labeled Real Network Datasets
5.4.2. Experimental Results and Analysis on Unlabeled Real Network Datasets
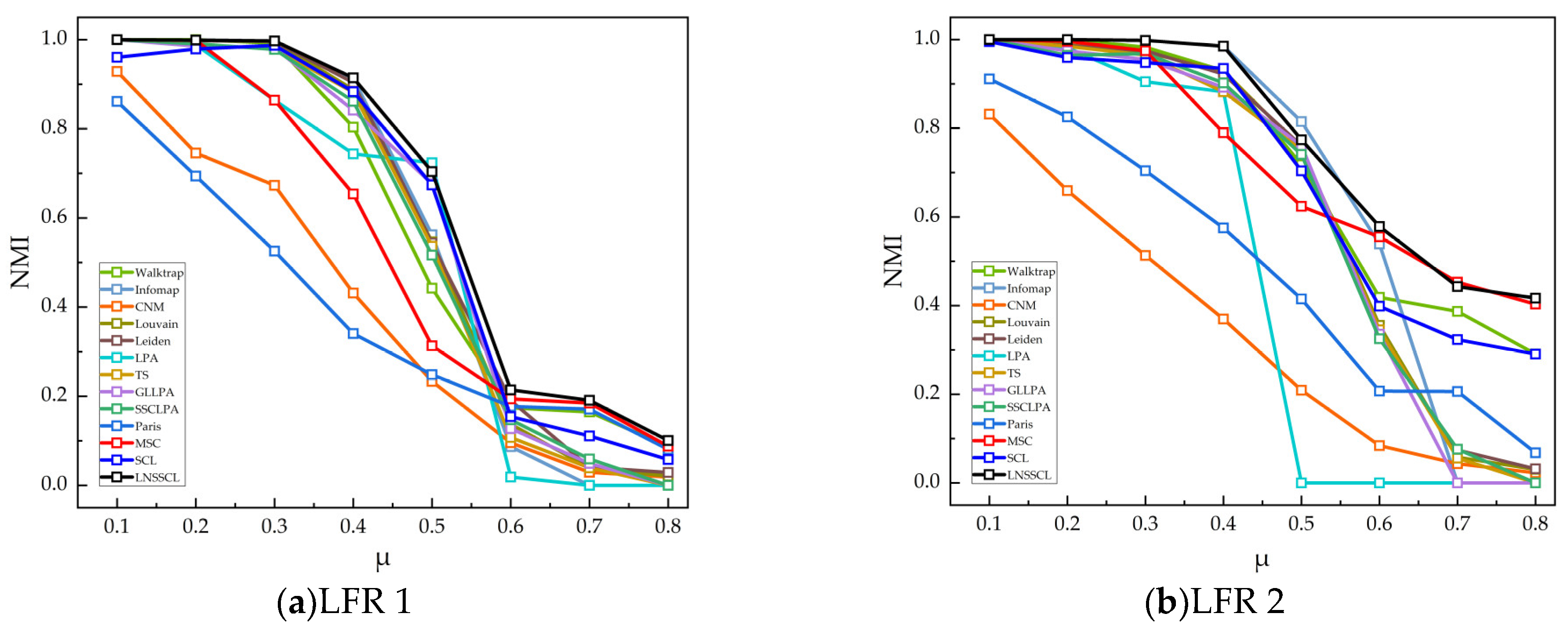
5.4.3. Experimental Results and Analysis on synthetic networks
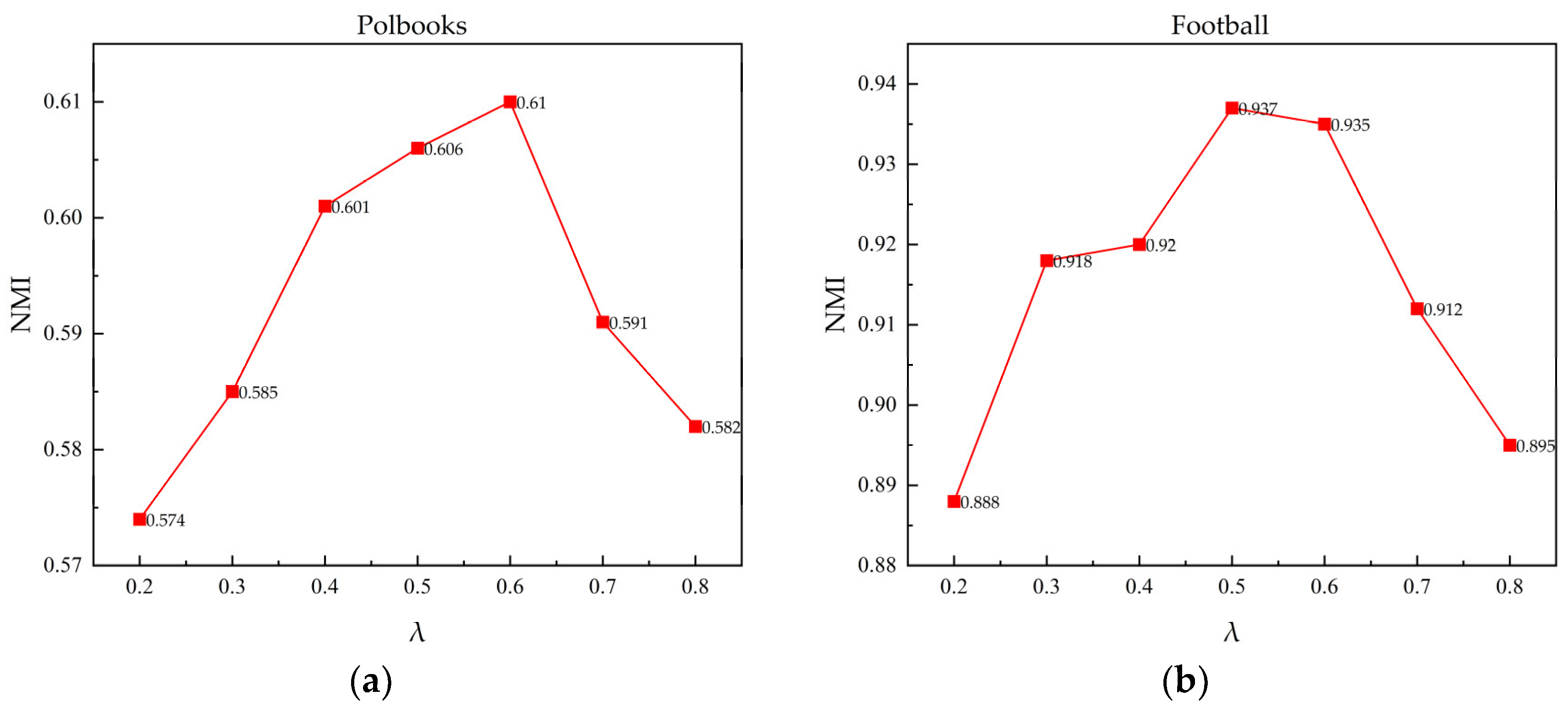
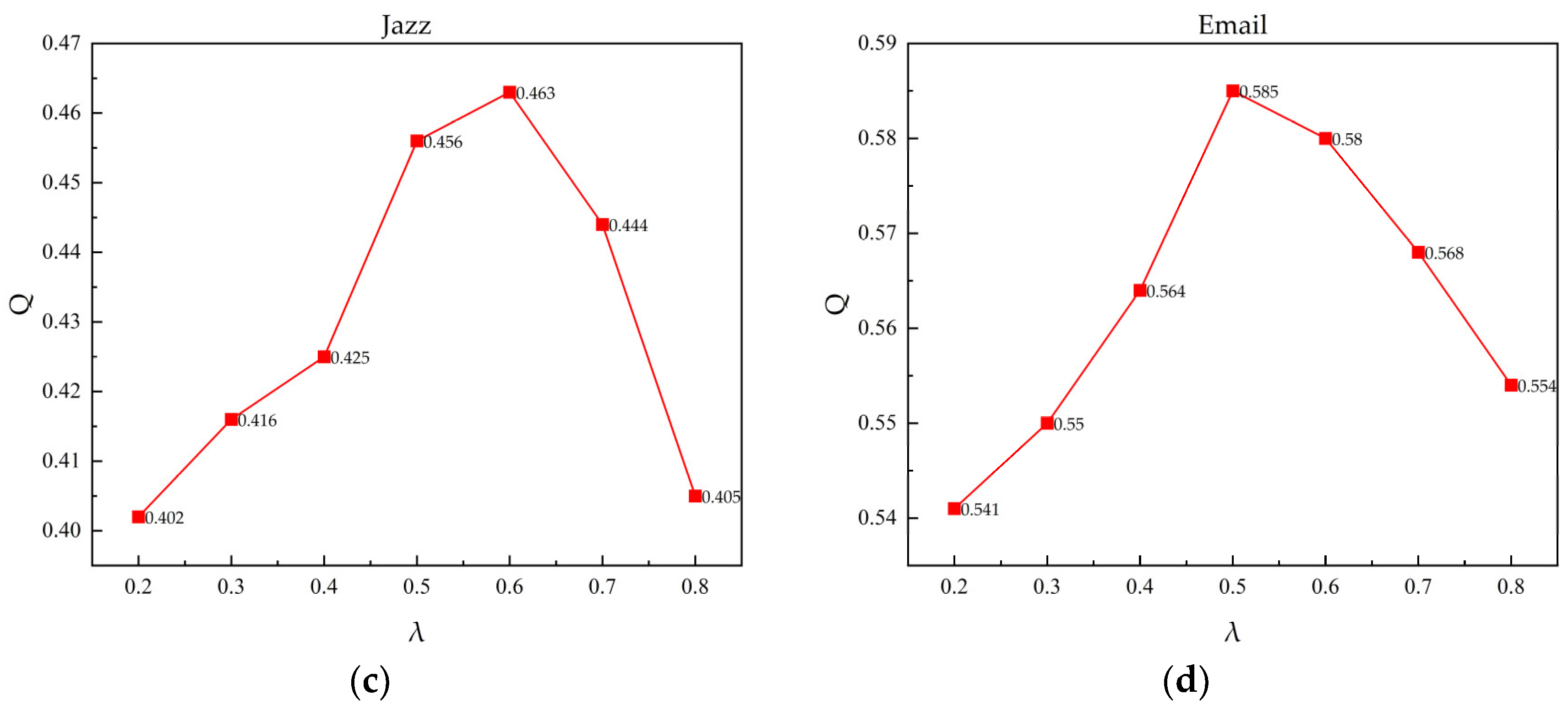
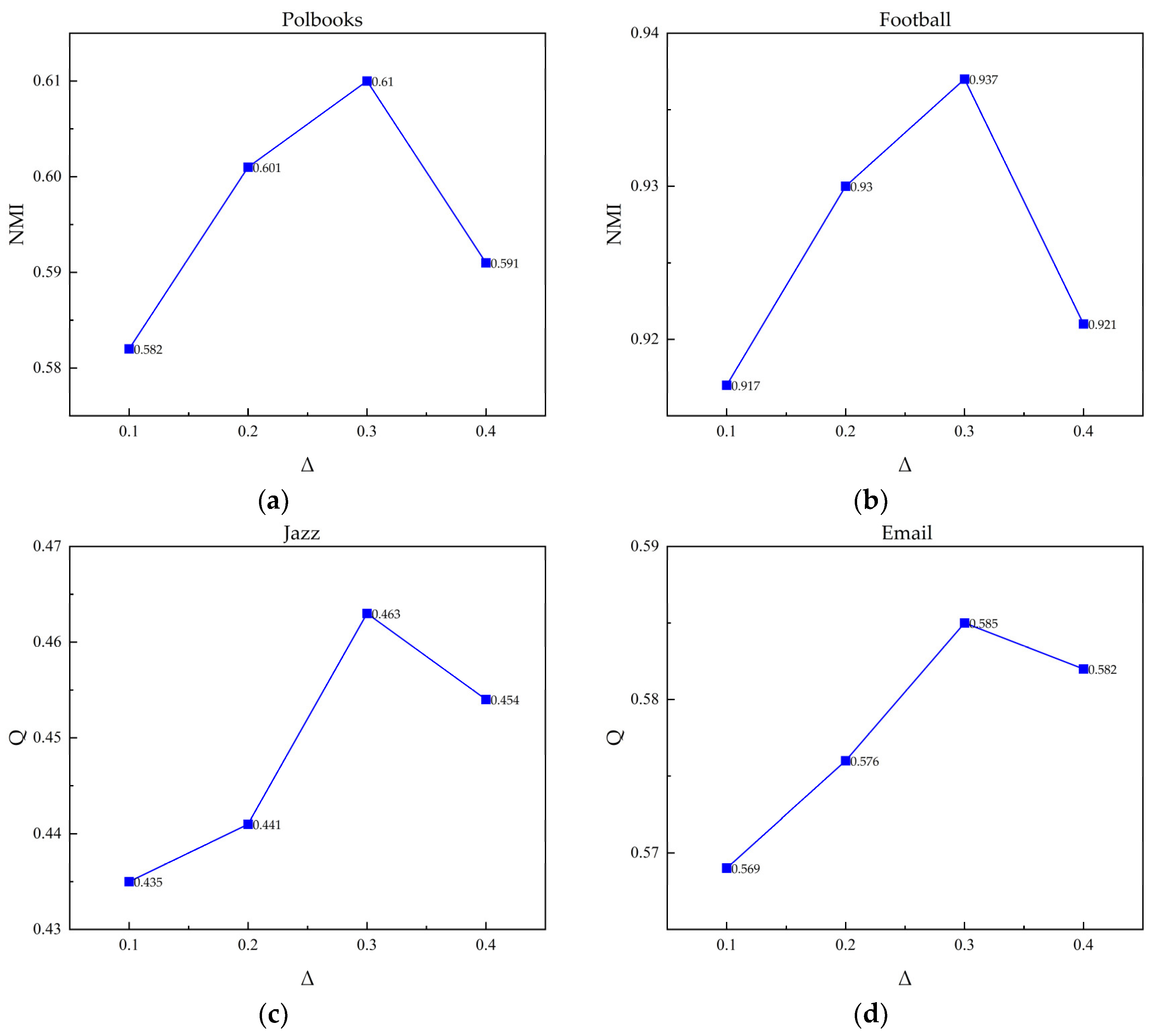
5.4.4. Parameter Sensitivity Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Girvan, M.; Newman, M.E. Community Structure in Social and Biological Networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef]
- Fortunato, S. Community Detection in Graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Fortunato, S.; Hric, D. Community Detection in Networks: A User Guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Javed, M.A.; Younis, M.S.; Latif, S.; Qadir, J.; Baig, A. Community Detection in Networks: A Multidisciplinary Review. J. Netw. Comput. Appl. 2018, 108, 87–111. [Google Scholar] [CrossRef]
- Jin, D.; Yu, Z.; Jiao, P.; Pan, S.; He, D.; Wu, J.; Yu, P.; Zhang, W. A Survey of Community Detection Approaches: From Statistical Modeling to Deep Learning. IEEE Trans. Knowl. Data Eng. 2021, 35, 1149–1170. [Google Scholar] [CrossRef]
- Xing, S.; Shan, X.; Fanzhen, L.; Jia, W.; Jian, Y.; Chuan, Z.; Wenbin, H.; Cecile, P.; Surya, N.; Di, J. A Comprehensive Survey on Community Detection with Deep Learning. IEEE Trans. Neural Netw. Learn. Syst 2022, 1–21. [Google Scholar] [CrossRef]
- Wang, B.; Gu, Y.; Zheng, D. Community Detection in Error-Prone Environments Based on Particle Cooperation and Competition with Distance Dynamics. Phys. A Stat. Mech. Its Appl. 2022, 607, 128178. [Google Scholar] [CrossRef]
- Grossberg, S. Competitive Learning: From Interactive Activation to Adaptive Resonance. Cogn. Sci. 1987, 11, 23–63. [Google Scholar] [CrossRef]
- Kohonen, T. The Self-Organizing Map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Kohonen, T.; Kohonen, T. Learning Vector Quantization. Self-Organ. Maps 1995, 30, 175–189. [Google Scholar]
- Hecht-Nielsen, R. Counterpropagation Networks. Appl. Opt. 1987, 26, 4979–4984. [Google Scholar] [CrossRef] [PubMed]
- Kosko, B. Stochastic Competitive Learning. In Proceedings of the 1990 IJCNN International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; IEEE: New York, NY, USA, 1990; pp. 215–226. [Google Scholar]
- Quiles, M.G.; Zhao, L.; Alonso, R.L.; Romero, R.A. Particle Competition for Complex Network Community Detection. Chaos Interdiscip. J. Nonlinear Sci. 2008, 18, 033107. [Google Scholar] [CrossRef] [PubMed]
- Silva, T.C.; Zhao, L. Stochastic Competitive Learning in Complex Networks. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 385–398. [Google Scholar] [CrossRef] [PubMed]
- Silva, T.C.; Zhao, L. Detecting and Preventing Error Propagation via Competitive Learning. Neural Netw. 2013, 41, 70–84. [Google Scholar] [CrossRef] [PubMed]
- Silva, T.C.; Zhao, L. Uncovering Overlapping Cluster Structures via Stochastic Competitive Learning. Inf. Sci. 2013, 247, 40–61. [Google Scholar] [CrossRef]
- Li, W.; Gu, Y.; Yin, D.; Xia, T.; Wang, J. Research on the Community Number Evolution Model of Public Opinion Based on Stochastic Competitive Learning. IEEE Access 2020, 8, 46267–46277. [Google Scholar] [CrossRef]
- Zamoner, F.W.; Zhao, L. A Network-Based Semi-Supervised Outlier Detection Technique Using Particle Competition and Cooperation. In Proceedings of the 2013 Brazilian Conference on Intelligent Systems, Fortaleza, Brazil, 19–24 October 2013; IEEE: New York, NY, USA, 2013; pp. 225–230. [Google Scholar]
- Breve, F.; Quiles, M.G.; Zhao, L. Interactive Image Segmentation Using Particle Competition and Cooperation. In Proceedings of the 2015 international joint conference on neural networks (IJCNN), Killarney, Ireland, 12–17 July 2015; IEEE: New York, NY, USA, 2015; pp. 1–8. [Google Scholar]
- Breve, F.; Fischer, C.N. Visually Impaired Aid Using Convolutional Neural Networks, Transfer Learning, and Particle Competition and Cooperation. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: New York, NY, USA, 2020; pp. 1–8. [Google Scholar]
- Roghani, H.; Bouyer, A. A Fast Local Balanced Label Diffusion Algorithm for Community Detection in Social Networks. IEEE Trans. Knowl. Data Eng. 2022, 35, 5472–5484. [Google Scholar] [CrossRef]
- Toth, C.; Helic, D.; Geiger, B.C. Synwalk: Community Detection via Random Walk Modelling. Data Min. Knowl. Discov. 2022, 36, 739–780. [Google Scholar] [CrossRef]
- Pons, P.; Latapy, M. Computing Communities in Large Networks Using Random Walks. In Proceedings of the Computer and Information Sciences-ISCIS 2005: 20th International Symposium, Istanbul, Turkey, 26–28 October 2005; Proceedings 20. Springer: Berlin/Heidelberg, Germany, 2005; pp. 284–293. [Google Scholar]
- Rosvall, M.; Bergstrom, C.T. Maps of Random Walks on Complex Networks Reveal Community Structure. Proc. Natl. Acad. Sci. USA 2008, 105, 1118–1123. [Google Scholar] [CrossRef]
- Yang, X.-H.; Ma, G.-F.; Zeng, X.-Y.; Pang, Y.; Zhou, Y.; Zhang, Y.-D.; Ye, L. Community Detection Based on Markov Similarity Enhancement. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 3664–3668. [Google Scholar] [CrossRef]
- Jokar, E.; Mosleh, M.; Kheyrandish, M. Discovering Community Structure in Social Networks Based on the Synergy of Label Propagation and Simulated Annealing. Multimed. Tools Appl. 2022, 81, 21449–21470. [Google Scholar] [CrossRef]
- You, X.; Ma, Y.; Liu, Z. A Three-Stage Algorithm on Community Detection in Social Networks. Knowl.-Based Syst. 2020, 187, 104822. [Google Scholar] [CrossRef]
- Dabaghi-Zarandi, F.; KamaliPour, P. Community Detection in Complex Network Based on an Improved Random Algorithm Using Local and Global Network Information. J. Netw. Comput. Appl. 2022, 206, 103492. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Jin, R.; Tao, J.; Chen, L.; Wu, X. Gllpa: A Graph Layout Based Label Propagation Algorithm for Community Detection. Knowl.-Based Syst. 2020, 206, 106363. [Google Scholar] [CrossRef]
- Chin, J.H.; Ratnavelu, K. Community Detection Using Constrained Label Propagation Algorithm with Nodes Exemption. Computing 2022, 104, 339–358. [Google Scholar] [CrossRef]
- Fei, R.; Wan, Y.; Hu, B.; Li, A.; Li, Q. A Novel Network Core Structure Extraction Algorithm Utilized Variational Autoencoder for Community Detection. Expert Syst. Appl. 2023, 222, 119775. [Google Scholar] [CrossRef]
- Li, H.-J.; Wang, L.; Zhang, Y.; Perc, M. Optimization of Identifiability for Efficient Community Detection. New J. Phys. 2020, 22, 063035. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link Prediction in Complex Networks: A Survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Silva, T.C.; Amancio, D.R. Network-Based Stochastic Competitive Learning Approach to Disambiguation in Collaborative Networks. Chaos: Interdiscip. J. Nonlinear Sci. 2013, 23, 013139. [Google Scholar] [CrossRef]
- Silva, T.C.; Zhao, L. Case Study of Network-Based Unsupervised Learning: Stochastic Competitive Learning in Networks. In Machine Learning in Complex Networks; Springer International Publishing: Cham, Switzerland, 2016; pp. 241–290. ISBN 978-3-319-17289-7. [Google Scholar]
- Clauset, A.; Newman, M.E.; Moore, C. Finding Community Structure in Very Large Networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast Unfolding of Communities in Large Networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Traag, V.A.; Waltman, L.; Van Eck, N.J. From Louvain to Leiden: Guaranteeing Well-Connected Communities. Sci. Rep. 2019, 9, 5233. [Google Scholar] [CrossRef]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near Linear Time Algorithm to Detect Community Structures in Large-Scale Networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef] [PubMed]
- Bonald, T.; Charpentier, B.; Galland, A.; Hollocou, A. Hierarchical Graph Clustering Using Node Pair Sampling. arXiv 2018, arXiv:1806.01664. [Google Scholar]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The Bottlenose Dolphin Community of Doubtful Sound Features a Large Proportion of Long-Lasting Associations: Can Geographic Isolation Explain This Unique Trait? Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Newman, M.E. Modularity and Community Structure in Networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Knuth, D.E. The Stanford GraphBase: A Platform for Combinatorial Computing; AcM Press: New York, NY, USA, 1993; Volume 1. [Google Scholar]
- Gleiser, P.M.; Danon, L. Community Structure in Jazz. Adv. Complex Syst. 2003, 6, 565–573. [Google Scholar] [CrossRef]
- Guimera, R.; Danon, L.; Diaz-Guilera, A.; Giralt, F.; Arenas, A. Self-Similar Community Structure in a Network of Human Interactions. Phys. Rev. E 2003, 68, 065103. [Google Scholar] [CrossRef]
- Newman, M.E. Finding Community Structure in Networks Using the Eigenvectors of Matrices. Physical review E 2006, 74, 036104. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective Dynamics of ‘Small-World’Networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Leskovec, J.; Mcauley, J. Learning to Discover Social Circles in Ego Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 539–547. [Google Scholar]
- Boguná, M.; Pastor-Satorras, R.; Díaz-Guilera, A.; Arenas, A. Models of Social Networks Based on Social Distance Attachment. Phys. Rev. E 2004, 70, 056122. [Google Scholar] [CrossRef] [PubMed]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark Graphs for Testing Community Detection Algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef]
- Danon, L.; Diaz-Guilera, A.; Duch, J.; Arenas, A. Comparing Community Structure Identification. J. Stat. Mech. Theory Exp. 2005, 2005, P09008. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware/Software | Configuration |
|---|---|
| OS | Windows 11 Home |
| CPU | Intel(R) Core(TM) i5-11400H @ 2.70GHz |
| RAM | 16 GB |
| GPU | NVIDIA GeForce RTX 3050 Ti Laptop |
| Anaconda | 3.9.12 |
| Python | 3.7.12 |
| NetworkX | 2.6.3 |
| scikit-learn | 1.0.2 |
| Dataset | Nodes | Edges | Community |
|---|---|---|---|
| Karate | 34 | 78 | 2 |
| Dolphins | 62 | 159 | 2 |
| Polbooks | 105 | 441 | 3 |
| Football | 115 | 613 | 12 |
| Lesmis | 77 | 254 | - |
| Jazz | 198 | 5484 | - |
| 1133 | 5451 | - | |
| Netscience | 1589 | 2742 | - |
| Power Grid | 4941 | 6594 | - |
| 4039 | 88,234 | - | |
| PGP | 10,680 | 24,316 | - |
| Network | ||||||||
|---|---|---|---|---|---|---|---|---|
| LFR1 | 1000 | 15 | 50 | 20 | 100 | 2 | 1.1 | 0.1–0.8 |
| LFR2 | 4000 | 15 | 50 | 20 | 100 | 2 | 1.1 | 0.1–0.8 |
| Algorithm | Karate | Dolphins | Polbooks | Football |
|---|---|---|---|---|
| Walktrap | 0.504 | 0.582 | 0.543 | 0.887 |
| Infomap | 0.699 | 0.417 | 0.529 | 0.911 |
| CNM | 0.692 | 0.557 | 0.531 | 0.698 |
| Louvain | 0.587 | 0.484 | 0.569 | 0.885 |
| Leiden | 0.687 | 0.581 | 0.574 | 0.890 |
| LPA | 0.445 | 0.595 | 0.534 | 0.870 |
| TS | 0.710 | 0.888 | 0.550 | 0.900 |
| GLLPA | 0.753 | 0.790 | 0.580 | 0.909 |
| SSCLPA | 0.826 | 0.616 | 0.493 | 0.919 |
| Paris | 0.835 | 0.780 | 0.565 | 0.831 |
| MSC | 0.836 | 0.777 | 0.539 | 0.921 |
| SCL | 0.821 | 0.816 | 0.552 | 0.861 |
| LNSSCL | 0.848 | 0.899 | 0.610 | 0.937 |
| Algorithm | Karate | Dolphins | Polbooks | Football |
|---|---|---|---|---|
| Walktrap | 0.353 | 0.489 | 0.507 | 0.603 |
| Infomap | 0.401 | 0.532 | 0.521 | 0.600 |
| CNM | 0.381 | 0.495 | 0.502 | 0.550 |
| Louvain | 0.415 | 0.516 | 0.526 | 0.602 |
| Leiden | 0.420 | 0.527 | 0.527 | 0.602 |
| LPA | 0.375 | 0.499 | 0.481 | 0.583 |
| TS | 0.420 | 0.381 | 0.520 | 0.600 |
| GLLPA | 0.438 | 0.496 | 0.507 | 0.608 |
| SSCLPA | 0.415 | 0.525 | 0.518 | 0.601 |
| Paris | 0.372 | 0.380 | 0.426 | 0.510 |
| MSC | 0.418 | 0.495 | 0.519 | 0.600 |
| SCL | 0.371 | 0.463 | 0.508 | 0.581 |
| LNSSCL | 0.424 | 0.532 | 0.524 | 0.613 |
| Algorithm | Lesmis | Jazz | Netscience | Power Grid | PGP | ||
|---|---|---|---|---|---|---|---|
| Walktrap | 0.521 | 0.438 | 0.531 | 0.956 | 0.831 | 0.812 | 0.832 |
| Infomap | 0.546 | 0.442 | 0.538 | 0.930 | 0.759 | 0.706 | 0.821 |
| CNM | 0.501 | 0.439 | 0.503 | 0.955 | 0.935 | 0.777 | 0.853 |
| Louvain | 0.527 | 0.282 | 0.463 | 0.907 | 0.627 | 0.835 | 0.885 |
| Leiden | 0.558 | 0.443 | 0.563 | 0.959 | 0.935 | 0.836 | 0.887 |
| LPA | 0.560 | 0.445 | 0.574 | 0.960 | 0.939 | 0.737 | 0.745 |
| TS | 0.535 | 0.440 | 0.550 | 0.924 | 0.930 | 0.796 | 0.767 |
| GLLPA | 0.556 | 0.440 | 0.292 | 0.920 | 0.784 | 0.785 | 0.786 |
| SSCLPA | 0.557 | 0.406 | 0.513 | 0.906 | 0.838 | 0.779 | 0.801 |
| Paris | 0.504 | 0.276 | 0.451 | 0.876 | 0.405 | 0.586 | 0.679 |
| MSC | 0.544 | 0.447 | 0.565 | 0.948 | 0.890 | 0.812 | 0.872 |
| SCL | 0.539 | 0.411 | 0.550 | 0.932 | 0.863 | 0.804 | 0.815 |
| LNSSCL | 0.575 | 0.463 | 0.585 | 0.971 | 0.952 | 0.847 | 0.896 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Gu, Y. Unsupervised Community Detection Algorithm with Stochastic Competitive Learning Incorporating Local Node Similarity. Appl. Sci. 2023, 13, 10496. https://doi.org/10.3390/app131810496
Huang J, Gu Y. Unsupervised Community Detection Algorithm with Stochastic Competitive Learning Incorporating Local Node Similarity. Applied Sciences. 2023; 13(18):10496. https://doi.org/10.3390/app131810496
Chicago/Turabian StyleHuang, Jian, and Yijun Gu. 2023. "Unsupervised Community Detection Algorithm with Stochastic Competitive Learning Incorporating Local Node Similarity" Applied Sciences 13, no. 18: 10496. https://doi.org/10.3390/app131810496
APA StyleHuang, J., & Gu, Y. (2023). Unsupervised Community Detection Algorithm with Stochastic Competitive Learning Incorporating Local Node Similarity. Applied Sciences, 13(18), 10496. https://doi.org/10.3390/app131810496