


A Knowledge Graph Framework for Dementia Research Data

 , , and
, , and
Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
3. Materials and Methods
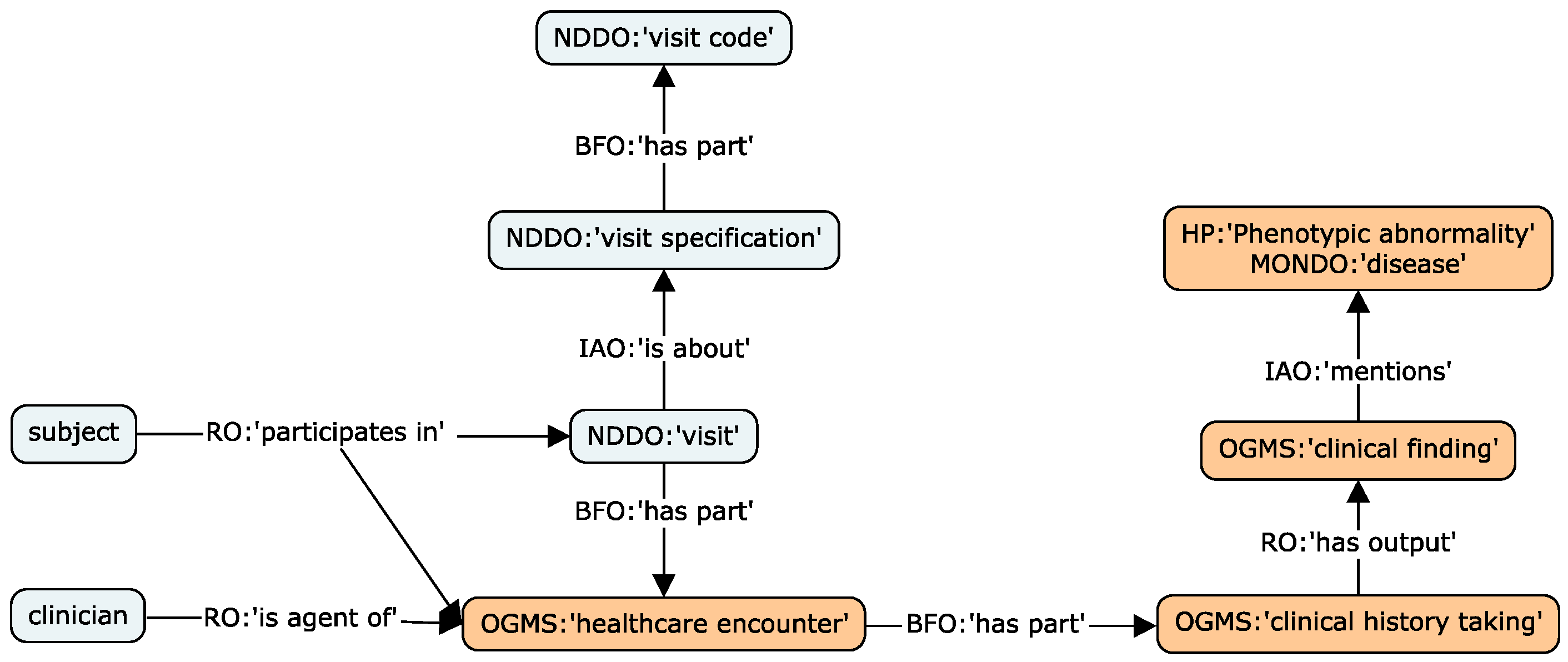
3.1. Terminological Foundation
- The concept definitions are concise, accurate, and relevant;
- There exists an active community keeping the ontology updated;
- They are widely recognized, cross-referenced, and follow consistent design patterns.
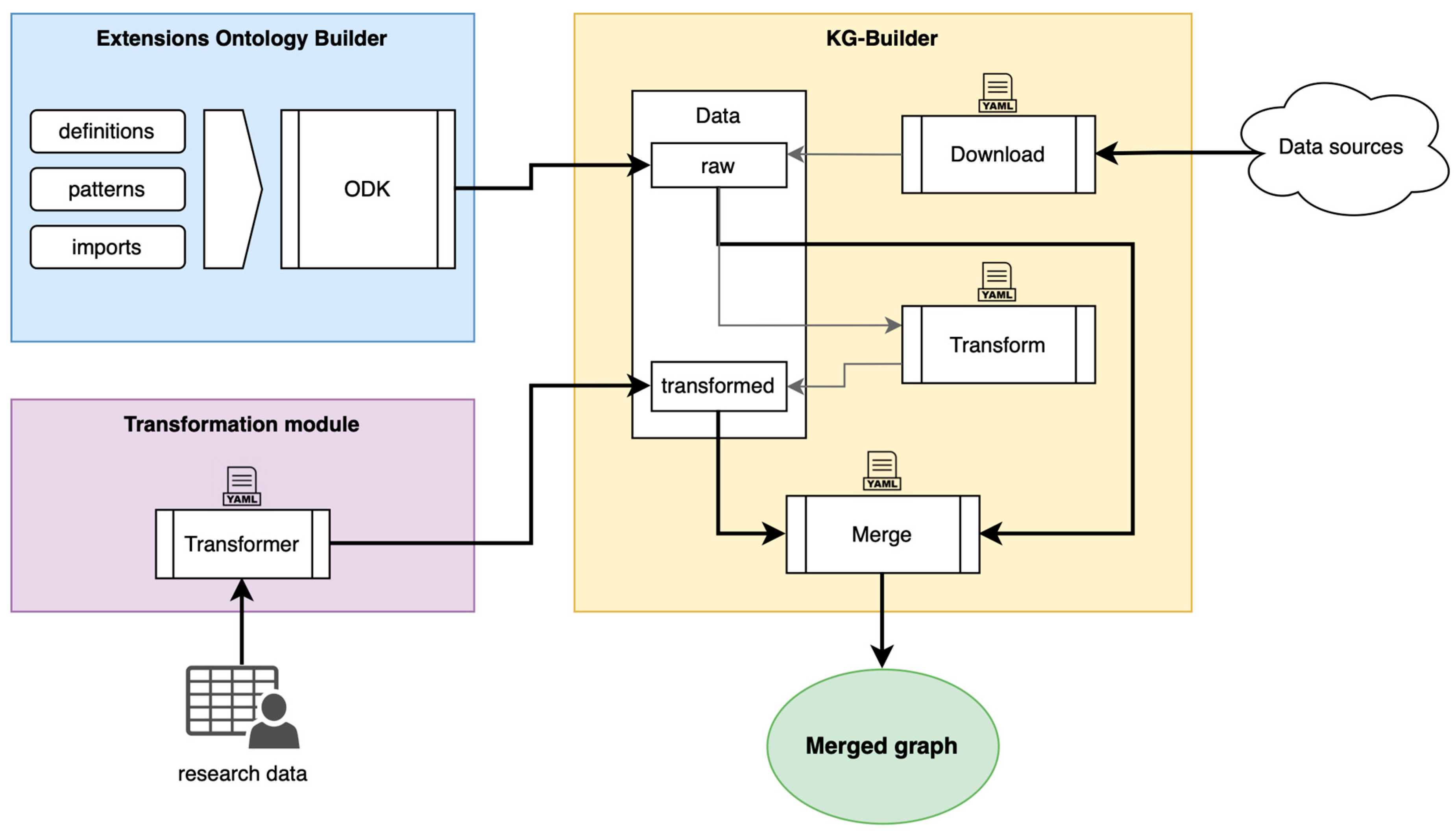
3.2. Terminological Extensions
3.3. Technical Implementation
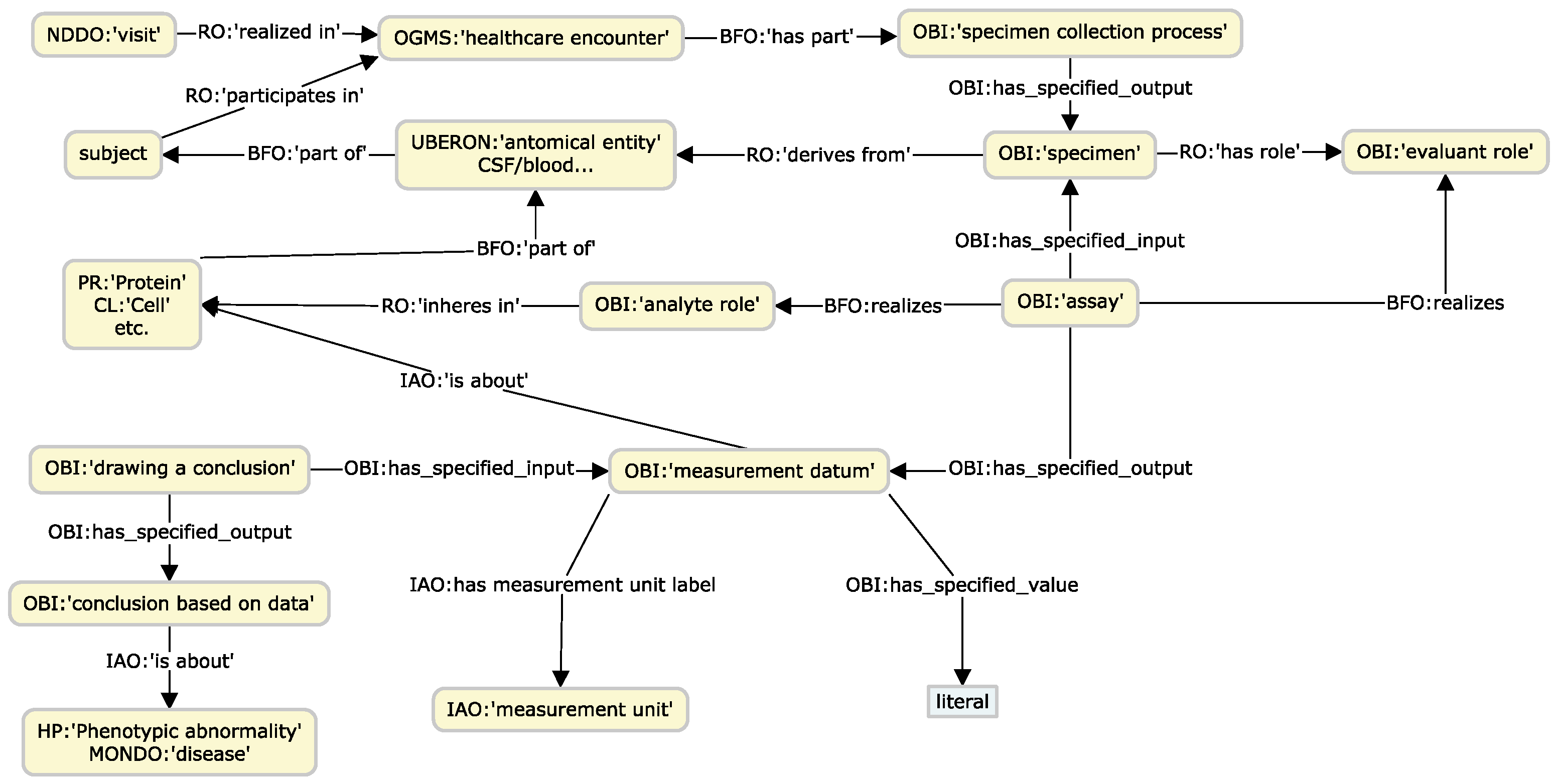
3.4. Data Transformation Design Patterns
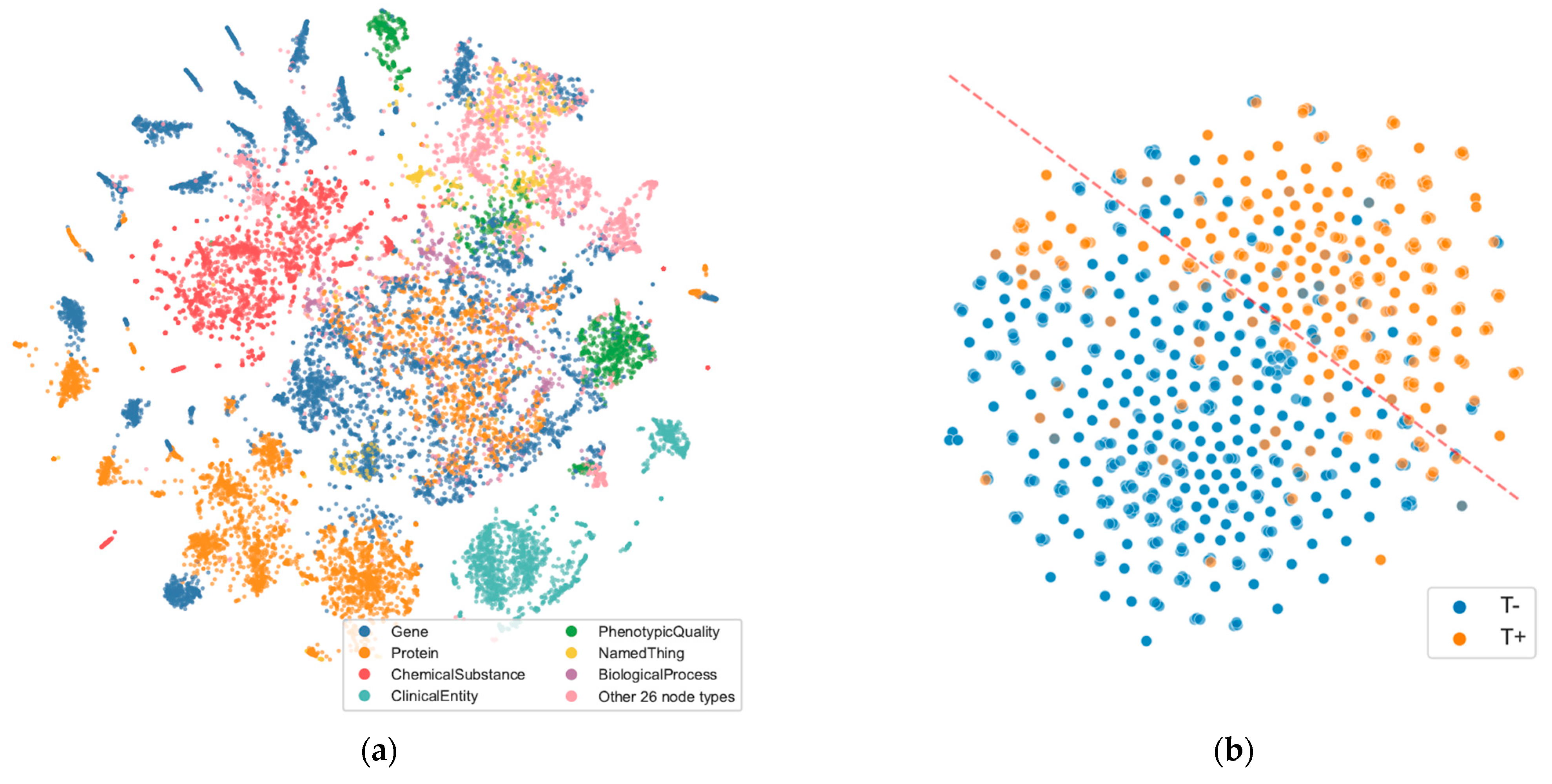
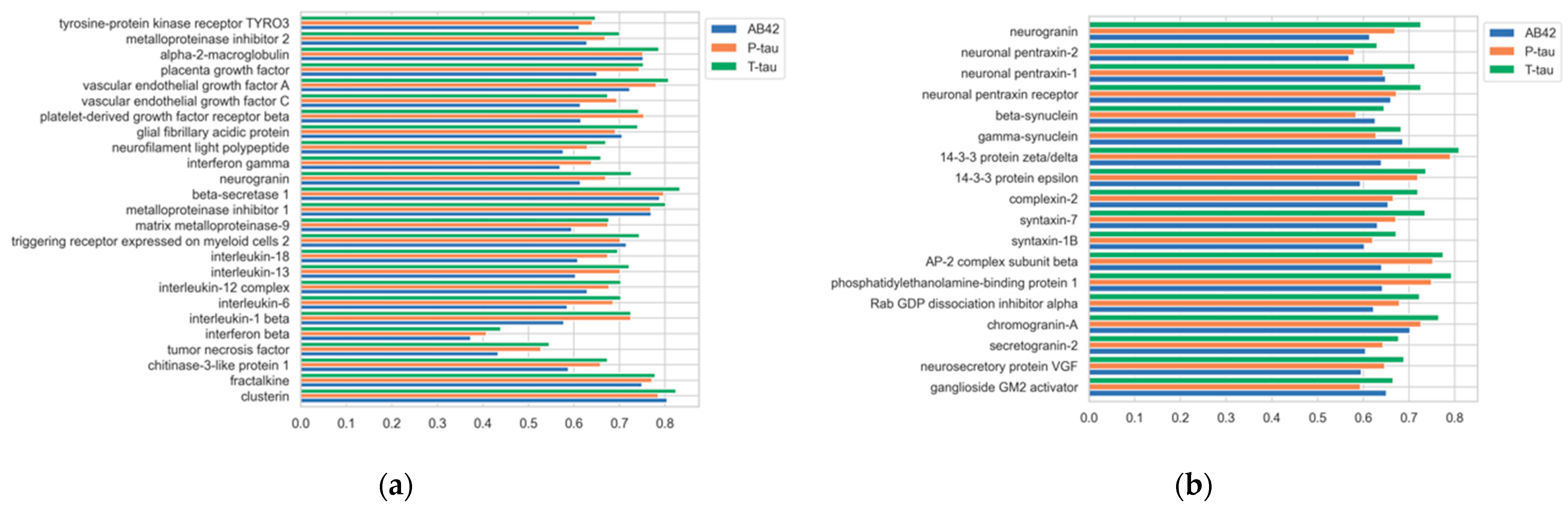
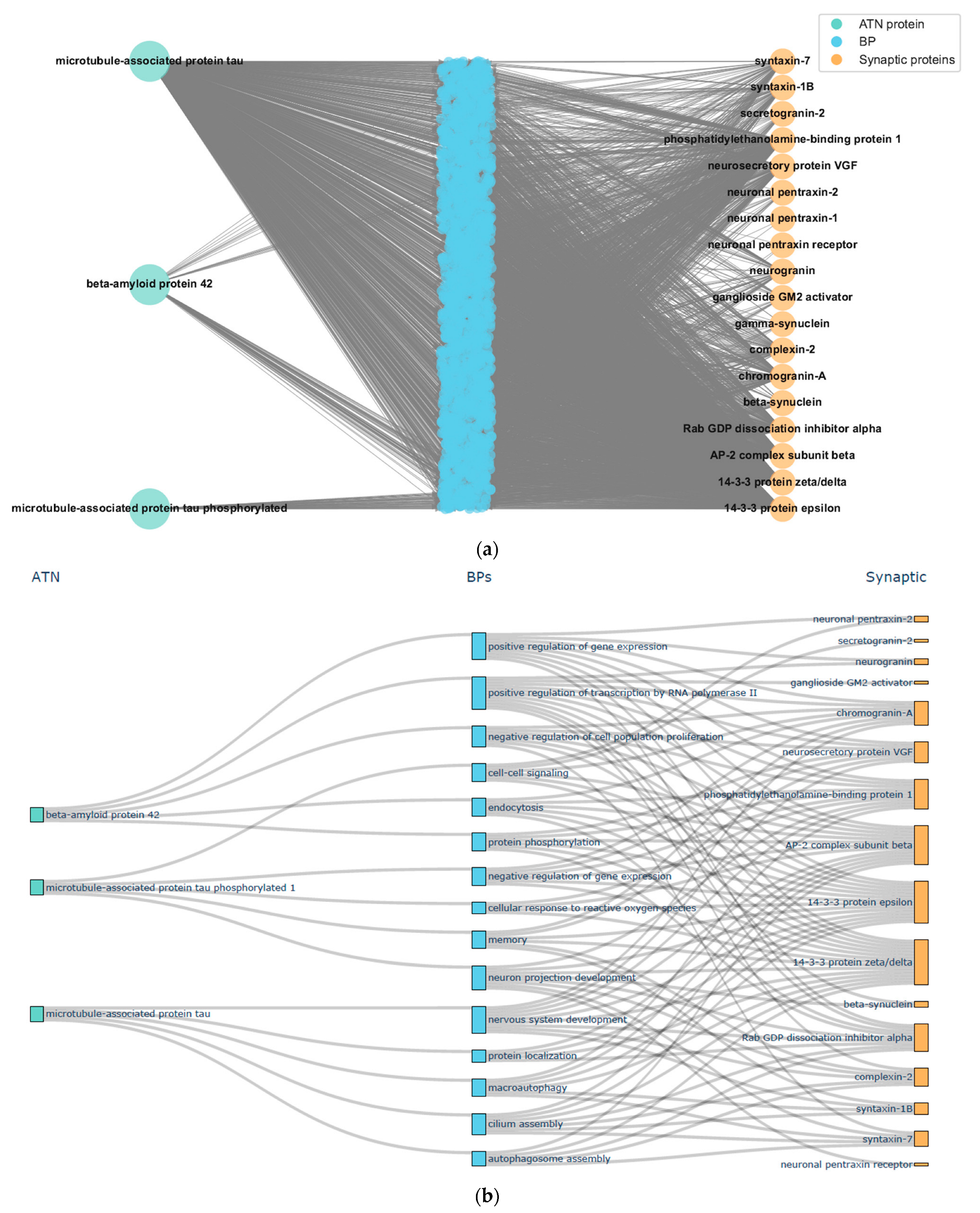
4. Results
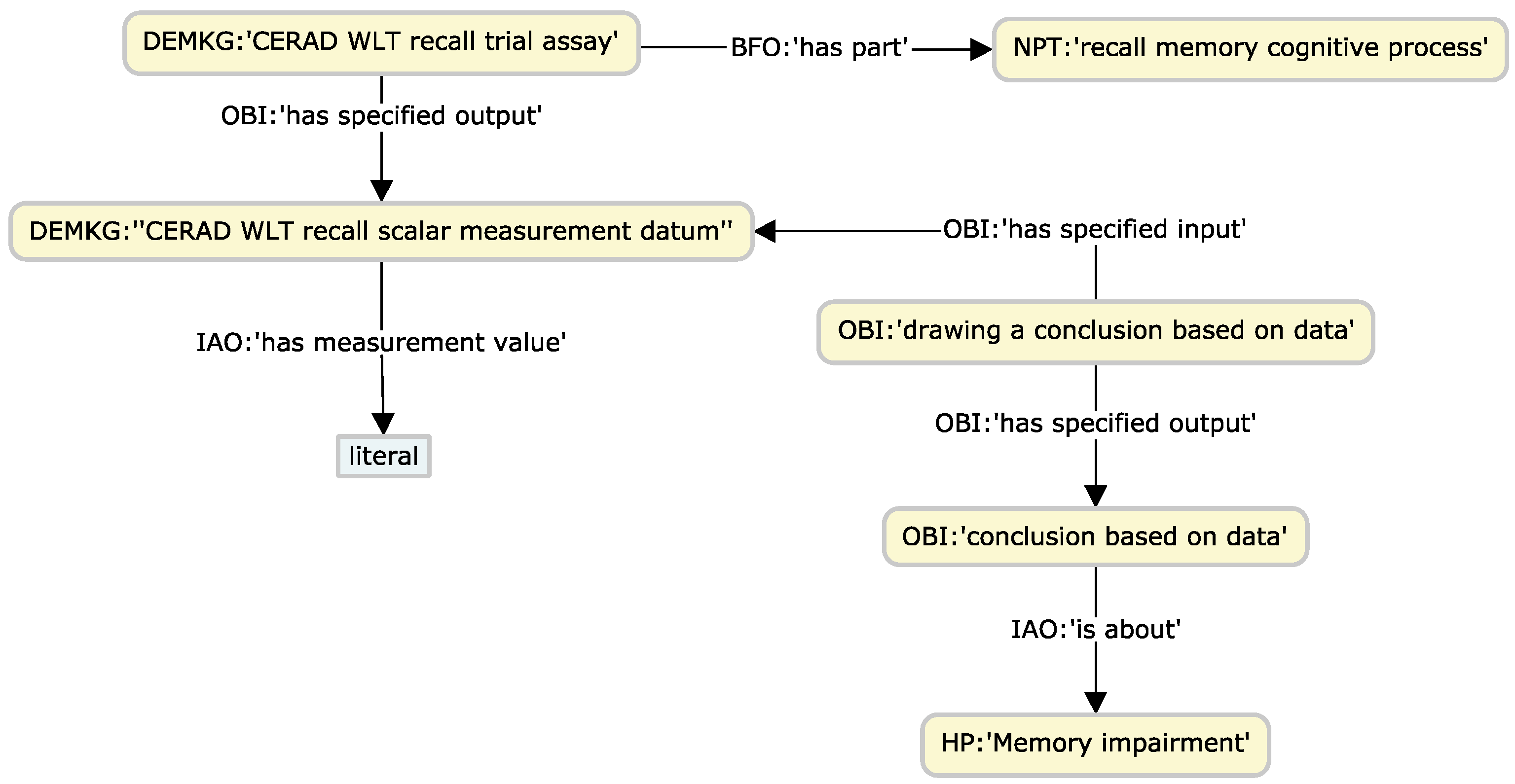
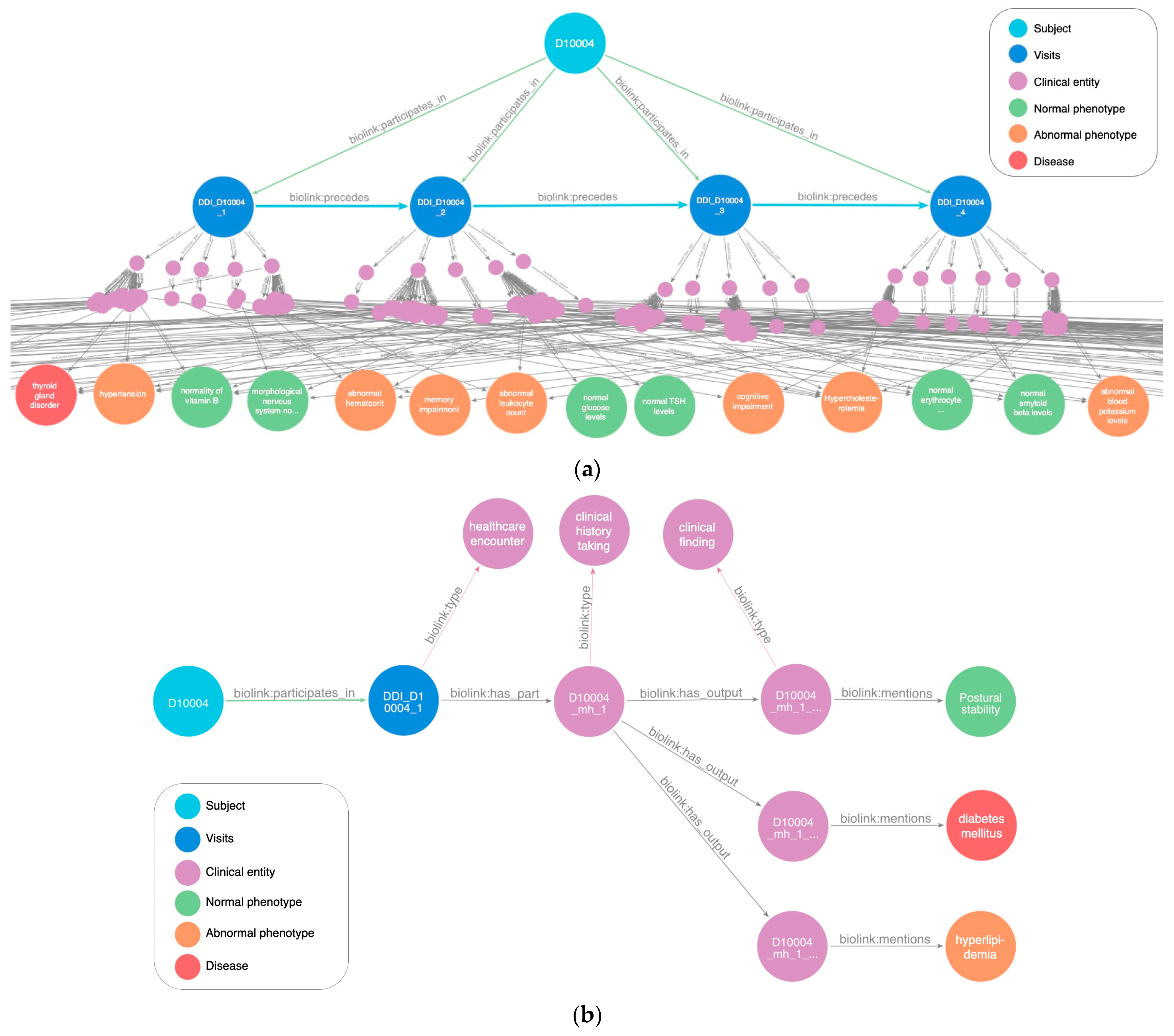
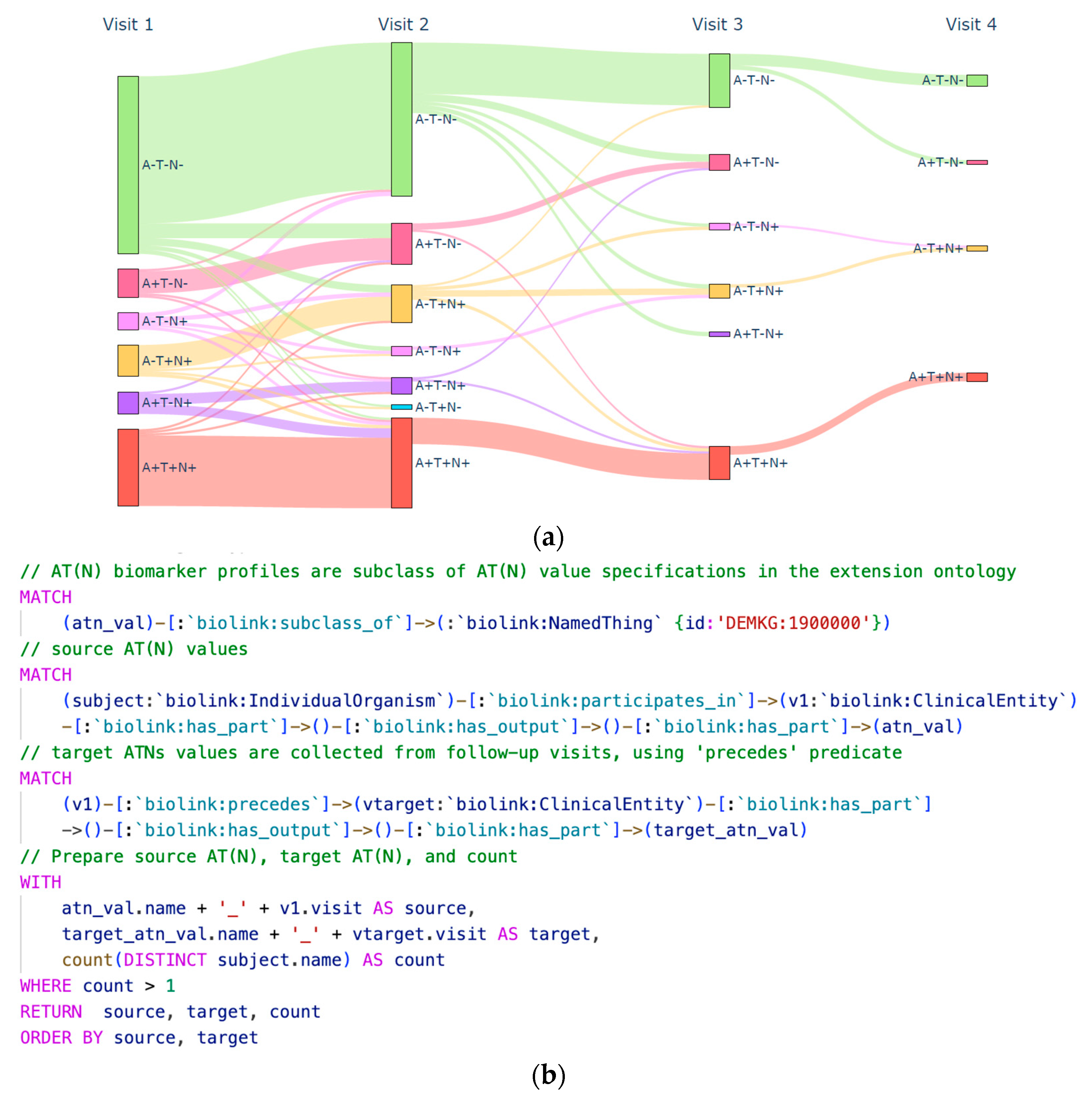
4.1. Use Case: Graph-Enabled Phenotype, Flow, and Protein Exploration from AT(N) Biomarker Profiles
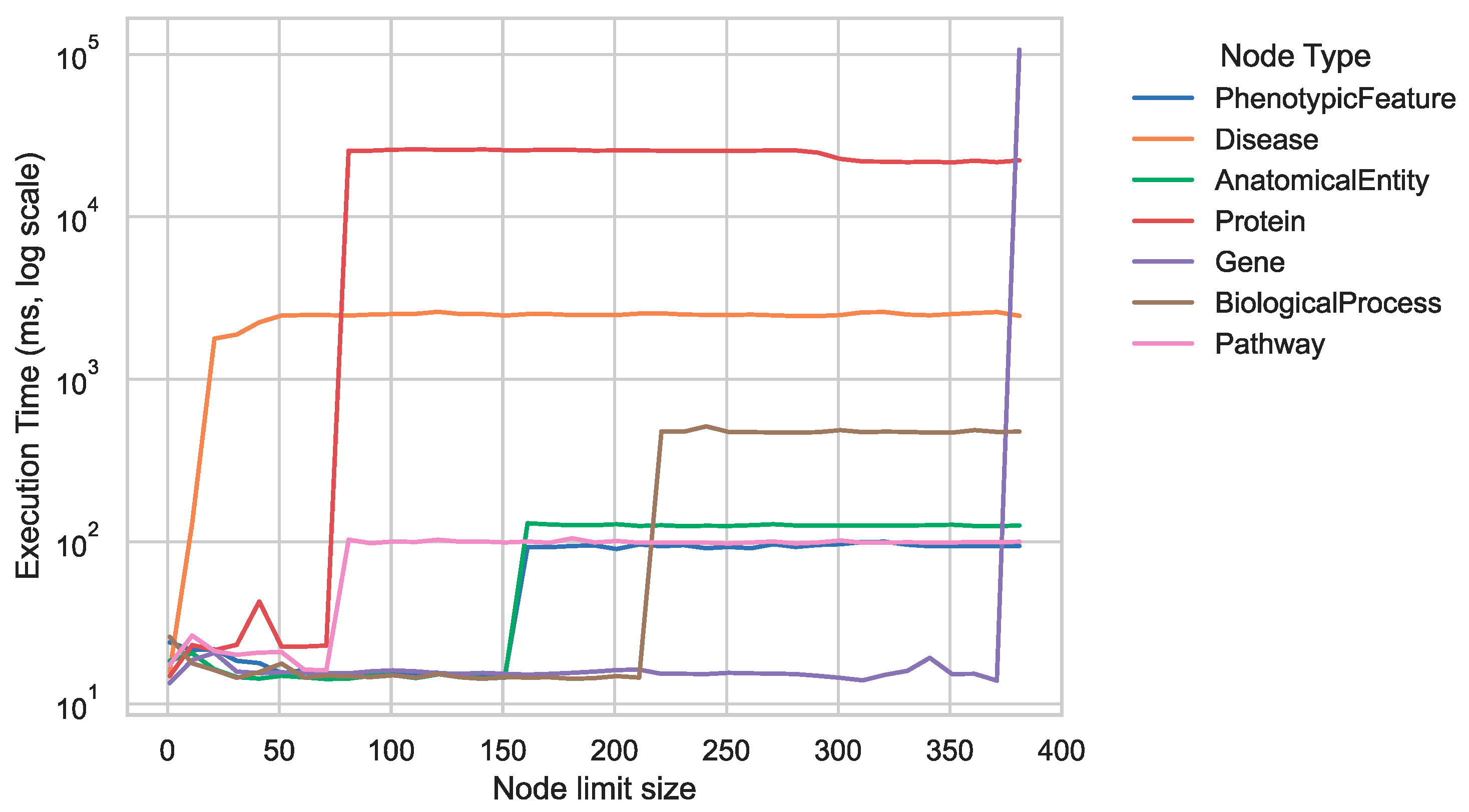
4.1.1. Experimental Setup
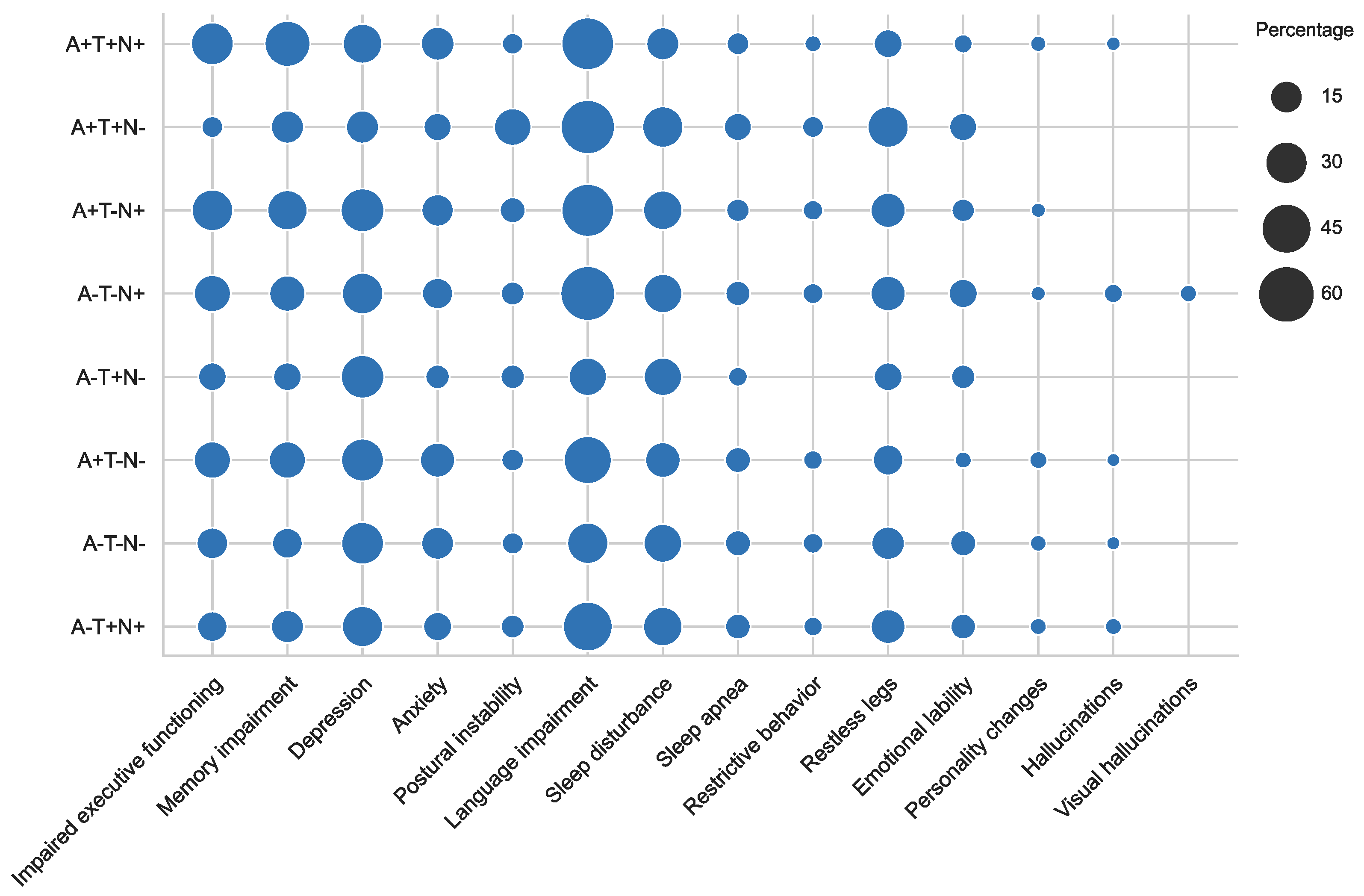
4.1.2. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manzoni, C.; Kia, D.A.; Vandrovcova, J.; Hardy, J.; Wood, N.W.; Lewis, P.A.; Ferrari, R. Genome, Transcriptome and Proteome: The Rise of Omics Data and Their Integration in Biomedical Sciences. Brief. Bioinform. 2018, 19, 286–302. [Google Scholar] [CrossRef] [PubMed]
- Misra, B.B.; Langefeld, C.; Olivier, M.; Cox, L.A. Integrated Omics: Tools, Advances and Future Approaches. J. Mol. Endocrinol. 2019, 62, R21–R45. [Google Scholar] [CrossRef]
- Glaab, E.; Rauschenberger, A.; Banzi, R.; Gerardi, C.; Garcia, P.; Demotes, J. Biomarker Discovery Studies for Patient Stratification Using Machine Learning Analysis of Omics Data: A Scoping Review. BMJ Open 2021, 11, e053674. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Ng, K.; Ramli, N. Biomedical Imaging Research: A Fast-Emerging Area for Interdisciplinary Collaboration. Biomed. Imaging Interv. J. 2011, 7, e21. [Google Scholar] [CrossRef]
- Lussier, Y.A.; Liu, Y. Computational Approaches to Phenotyping: High-Throughput Phenomics. Proc. Am. Thorac. Soc. 2007, 4, 18–25. [Google Scholar] [CrossRef] [PubMed]
- Che, Z.; Liu, Y. Deep Learning Solutions to Computational Phenotyping in Health Care. In Proceedings of the IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 1100–1109. [Google Scholar]
- Che, Z.; Kale, D.; Li, W.; Bahadori, M.T.; Liu, Y. Deep Computational Phenotyping. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 507–516. [Google Scholar]
- Barabasi, A.-L.; Oltvai, Z.N. Network Biology: Understanding the Cell’s Functional Organization. Nat. Rev. Genet. 2004, 5, 101–113. [Google Scholar] [CrossRef] [PubMed]
- Barabási, A.-L.; Gulbahce, N.; Loscalzo, J. Network Medicine: A Network-Based Approach to Human Disease. Nat. Rev. Genet. 2011, 12, 56–68. [Google Scholar] [CrossRef]
- Timón-Reina, S.; Rincón, M.; Martínez-Tomás, R. An Overview of Graph Databases and Their Applications in the Biomedical Domain. Database 2021, 2021, 26. [Google Scholar] [CrossRef]
- Introducing the Knowledge Graph: Things, Not Strings. Available online: https://blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 13 September 2023).
- Noy, N.; Gao, Y.; Jain, A.; Narayanan, A.; Patterson, A.; Taylor, J. Industry-Scale Knowledge Graphs: Lessons and Challenges: Five Diverse Technology Companies Show How It’s Done. Queue 2019, 17, 48–75. [Google Scholar] [CrossRef]
- Sheth, A.; Padhee, S.; Gyrard, A. Knowledge Graphs and Knowledge Networks: The Story in Brief. IEEE Internet Comput. 2019, 23, 67–75. [Google Scholar] [CrossRef]
- Ehrlinger, L.; Wöß, W. Towards a definition of knowledge graphs. In CEUR Workshop Proceedings; CEUR-WS: Aachen, Germany, 2016; Volume 1695. [Google Scholar]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; de Melo, G.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S. Knowledge Graphs. ACM Comput. Surv. CSUR 2021, 54, 1–37. [Google Scholar]
- Besta, M.; Peter, E.; Gerstenberger, R.; Fischer, M.; Podstawski, M.; Barthels, C.; Alonso, G.; Hoefler, T. Demystifying Graph Databases: Analysis and Taxonomy of Data Organization, System Designs, and Graph Queries. ACM Comput. Surv. 2019, 56, 1–40. [Google Scholar] [CrossRef]
- Brandizi, M.; Singh, A.; Rawlings, C.; Hassani-Pak, K. Getting the Best of Linked Data and Property Graphs: Rdf2neo and the KnetMiner Use Case. In Proceedings of the CEUR Workshop Proceedings, Antwerp, Belgium, 3–6 December 2018; Volume 2275. [Google Scholar]
- Alocci, D.; Mariethoz, J.; Horlacher, O.; Bolleman, J.T.; Campbell, M.P.; Lisacek, F. Property Graph vs RDF Triple Store: A Comparison on Glycan Substructure Search. PLoS ONE 2015, 10, e0144578. [Google Scholar] [CrossRef] [PubMed]
- Hoehndorf, R.; Schofield, P.N.; Gkoutos, G.V. The Role of Ontologies in Biological and Biomedical Research: A Functional Perspective. Brief. Bioinform. 2015, 16, 1069–1080. [Google Scholar] [CrossRef]
- Dovrolis, N.; Stefanut, T.; Dietze, S.; Yu, H.Q.; Valentine, C.; Kaldoudi, E. Semantic Annotation and Linking of Medical Educational Resources. In 5th European Conference of the International Federation for Medical and Biological Engineering 14–18 September 2011, Budapest, Hungary; Jobbágy, Á., Ed.; IFMBE Proceedings; Springer: Berlin/Heidelberg, Germany, 2011; Volume 37, pp. 1400–1403. [Google Scholar]
- Song, D.; Chute, C.G.; Tao, C. Semantator: Annotating Clinical Narratives with Semantic Web Ontologies. AMIA Jt. Summits Transl. Sci. Proc. 2012, 2012, 20–209. [Google Scholar] [PubMed]
- Shah, N.H.; Bhatia, N.; Jonquet, C.; Rubin, D.; Chiang, A.P.; Musen, M.A. Comparison of concept recognizers for building the open biomedical annotator. In BMC Bioinformatics; BioMed Central: London, UK, 2009; Volume 10. [Google Scholar]
- El-Haj, M.; Rutherford, N.; Coole, M.; Ezeani, I.; Prentice, S.; Ide, N.; Knight, J.; Piao, S.; Mariani, J.; Rayson, P.; et al. Infrastructure for Semantic Annotation in the Genomics Domain. In Proceedings of the LREC, Marseille, France, 20–25 June 2020. [Google Scholar]
- Tan, H.; Lambrix, P. Selecting an ontology for biomedical text mining. In Workshop on Current Trends in Biomedical Natural Language Processing; Association for Computational Linguistics: Boulder, CO, USA, 2009; pp. 55–62. [Google Scholar]
- Witte, R.; Kappler, T.; Baker, C.J.O. Ontology Design for Biomedical Text Mining. In Semantic Web: Revolutionizing Knowledge Discovery in the Life Sciences; Springer: Boston, MA, USA, 2007; Volume 9780387484, pp. 281–313. ISBN 978-0-387-48438-9. [Google Scholar]
- Jackson, R.; Matentzoglu, N.; Overton, J.A.; Vita, R.; Balhoff, J.P.; Buttigieg, P.L.; Carbon, S.; Courtot, M.; Diehl, A.D.; Dooley, D.M.; et al. OBO Foundry in 2021: Operationalizing Open Data Principles to Evaluate Ontologies. Database 2021, 2021, baab069. [Google Scholar] [CrossRef] [PubMed]
- Musen, M.A.; Noy, N.F.; Shah, N.H.; Whetzel, P.L.; Chute, C.G.; Story, M.A.; Smith, B. The National Center for Biomedical Ontology. J. Am. Med. Inform. Assoc. 2012, 19, 190–195. [Google Scholar] [CrossRef]
- Whetzel, P.L.; Noy, N.F.; Shah, N.H.; Alexander, P.R.; Nyulas, C.; Tudorache, T.; Musen, M.A. BioPortal: Enhanced Functionality via New Web Services from the National Center for Biomedical Ontology to Access and Use Ontologies in Software Applications. Nucleic Acids Res. 2011, 39, W541–W545. [Google Scholar] [CrossRef] [PubMed]
- Mungall, C.J.; McMurry, J.A.; Köhler, S.; Balhoff, J.P.; Borromeo, C.; Brush, M.; Carbon, S.; Conlin, T.; Dunn, N.; Engelstad, M.; et al. The Monarch Initiative: An Integrative Data and Analytic Platform Connecting Phenotypes to Genotypes across Species. Nucleic Acids Res. 2017, 45, D712–D722. [Google Scholar] [CrossRef] [PubMed]
- Santos, A.; Colaço, A.R.; Nielsen, A.B.; Niu, L.; Strauss, M.; Geyer, P.E.; Coscia, F.; Albrechtsen, N.J.W.; Mundt, F.; Jensen, L.J.; et al. A Knowledge Graph to Interpret Clinical Proteomics Data. Nat. Biotechnol. 2022, 40, 692–702. [Google Scholar] [CrossRef] [PubMed]
- Chandak, P.; Huang, K.; Zitnik, M. Building a Knowledge Graph to Enable Precision Medicine. Sci. Data 2023, 10, 67. [Google Scholar] [CrossRef] [PubMed]
- Morris, J.H.; Soman, K.; Akbas, R.E.; Zhou, X.; Smith, B.; Meng, E.C.; Huang, C.C.; Cerono, G.; Schenk, G.; Rizk-Jackson, A. The Scalable Precision Medicine Open Knowledge Engine (SPOKE): A Massive Knowledge Graph of Biomedical Information. Bioinformatics 2023, 39, btad080. [Google Scholar] [CrossRef] [PubMed]
- Reese, J.T.; Unni, D.; Callahan, T.J.; Cappelletti, L.; Ravanmehr, V.; Carbon, S.; Shefchek, K.A.; Good, B.M.; Balhoff, J.P.; Fontana, T.; et al. KG-COVID-19: A Framework to Produce Customized Knowledge Graphs for COVID-19 Response. Patterns 2021, 2, 100155. [Google Scholar] [CrossRef] [PubMed]
- Badal, V.D.; Wright, D.; Katsis, Y.; Kim, H.-C.; Swafford, A.D.; Knight, R.; Hsu, C.-N. Challenges in the Construction of Knowledge Bases for Human Microbiome-Disease Associations. Microbiome 2019, 7, 129. [Google Scholar] [CrossRef] [PubMed]
- Chaves-Fraga, D.; Endris, K.M.; Iglesias, E.; Corcho, O.; Vidal, M.-E. What Are the Parameters That Affect the Construction of a Knowledge Graph? In Proceedings of the On the Move to Meaningful Internet Systems: OTM 2019 Conferences: Confederated International Conferences: CoopIS, ODBASE, C&TC 2019, Rhodes, Greece, 21–25 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 695–713. [Google Scholar]
- Unni, D.R.; Moxon, S.A.T.; Bada, M.; Brush, M.; Bruskiewich, R.; Caufield, J.H.; Clemons, P.A.; Dancik, V.; Dumontier, M.; Fecho, K.; et al. Biolink Model: A Universal Schema for Knowledge Graphs in Clinical, Biomedical, and Translational Science. Clin. Transl. Sci. 2022, 15, 1848–1855. [Google Scholar] [CrossRef] [PubMed]
- Caufield, J.H.; Putman, T.; Schaper, K.; Unni, D.R.; Hegde, H.; Callahan, T.J.; Cappelletti, L.; Moxon, S.A.; Ravanmehr, V.; Carbon, S.; et al. KG-Hub—Building and Exchanging Biological Knowledge Graphs 2023. Bioinformatics 2023, 39, btad418. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation Learning on Graphs: Methods and Applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Chami, I.; Abu-El-Haija, S.; Perozzi, B.; Ré, C.; Murphy, K. Machine Learning on Graphs: A Model and Comprehensive Taxonomy. J. Mach. Learn. Res. 2022, 23, 3840–3903. [Google Scholar]
- Cappelletti, L.; Fontana, T.; Casiraghi, E.; Ravanmehr, V.; Callahan, T.J.; Joachimiak, M.P.; Mungall, C.J.; Robinson, P.N.; Reese, J.; Valentini, G. GRAPE: Fast and Scalable Graph Processing and Embedding 2021. Nat. Comput. Sci. 2023, 3, 552–568. [Google Scholar] [CrossRef]
- Ilievski, F.; Garijo, D.; Chalupsky, H.; Divvala, N.T.; Yao, Y.; Rogers, C.; Li, R.; Liu, J.; Singh, A.; Schwabe, D. KGTK: A Toolkit for Large Knowledge Graph Manipulation and Analysis. In Proceedings of the The Semantic Web–ISWC 2020: 19th International Semantic Web Conference, Athens, Greece, 2–6 November 2020; pp. 278–293. [Google Scholar]
- Nelson, C.A.; Bove, R.; Butte, A.J.; Baranzini, S.E. Embedding Electronic Health Records onto a Knowledge Network Recognizes Prodromal Features of Multiple Sclerosis and Predicts Diagnosis. J. Am. Med. Inform. Assoc. 2022, 29, 424–434. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Li, X.; Chen, W.; Chen, Y.; Zhang, X.; Gu, J.; Zhang, M.Q. Network Embedding-Based Representation Learning for Single Cell RNA-Seq Data. Nucleic Acids Res. 2017, 45, e166. [Google Scholar] [CrossRef]
- Liu, X.; Yang, Z.; Sang, S.; Lin, H.; Wang, J.; Xu, B. Detection of Protein Complexes from Multiple Protein Interaction Networks Using Graph Embedding. Artif. Intell. Med. 2019, 96, 107–115. [Google Scholar] [CrossRef]
- Wang, X.; Gong, Y.; Yi, J.; Zhang, W. Predicting Gene-Disease Associations from the Heterogeneous Network Using Graph Embedding. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine—BIBM 2019, San Diego, CA, USA, 1 November 2019; pp. 504–511. [Google Scholar]
- Xu, B.; Liu, Y.; Yu, S.; Wang, L.; Dong, J.; Lin, H.; Yang, Z.; Wang, J.; Xia, F. A Network Embedding Model for Pathogenic Genes Prediction by Multi-Path Random Walking on Heterogeneous Network. BMC Med. Genom. 2019, 12, 188. [Google Scholar] [CrossRef]
- Malec, S.A.; Taneja, S.B.; Albert, S.M.; Elizabeth Shaaban, C.; Karim, H.T.; Levine, A.S.; Munro, P.; Callahan, T.J.; Boyce, R.D. Causal Feature Selection Using a Knowledge Graph Combining Structured Knowledge from the Biomedical Literature and Ontologies: A Use Case Studying Depression as a Risk Factor for Alzheimer’s Disease. J. Biomed. Inform. 2023, 142, 104368. [Google Scholar] [CrossRef]
- Nicholson, D.N.; Greene, C.S. Constructing Knowledge Graphs and Their Biomedical Applications. Comput. Struct. Biotechnol. J. 2020, 18, 1414–1428. [Google Scholar] [CrossRef] [PubMed]
- Arp, R.; Smith, B. Function, role and disposition in basic formal ontology. Nat. Preced. 2008. [Google Scholar] [CrossRef]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene Ontology: Tool for The Unification of Biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef]
- The Gene Ontology Consortium; Aleksander, S.A.; Balhoff, J.; Carbon, S.; Cherry, J.M.; Drabkin, H.J.; Ebert, D.; Feuermann, M.; Gaudet, P.; Harris, N.L.; et al. The Gene Ontology Knowledgebase in 2023. Genetics 2023, 224, iyad031. [Google Scholar] [CrossRef]
- Hastings, J.; Owen, G.; Dekker, A.; Ennis, M.; Kale, N.; Muthukrishnan, V.; Turner, S.; Swainston, N.; Mendes, P.; Steinbeck, C. ChEBI in 2016: Improved Services and an Expanding Collection of Metabolites. Nucleic Acids Res. 2016, 44, D1214–D1219. [Google Scholar] [CrossRef] [PubMed]
- Natale, D.A.; Arighi, C.N.; Barker, W.C.; Blake, J.A.; Bult, C.J.; Caudy, M.; Drabkin, H.J.; D’Eustachio, P.; Evsikov, A.V.; Huang, H. The Protein Ontology: A Structured Representation of Protein Forms and Complexes. Nucleic Acids Res. 2010, 39, D539–D545. [Google Scholar] [CrossRef]
- Vasilevsky, N.A.; Matentzoglu, N.A.; Toro, S.; Flack, J.E.; Hegde, H.; Unni, D.R.; Alyea, G.F.; Amberger, J.S.; Babb, L.; Balhoff, J.P.; et al. Mondo: Unifying Diseases for the World, by the World. medRxiv 2022. [Google Scholar] [CrossRef]
- Köhler, S.; Doelken, S.C.; Mungall, C.J.; Bauer, S.; Firth, H.V.; Bailleul-Forestier, I.; Black, G.C.M.; Brown, D.L.; Brudno, M.; Campbell, J.; et al. The Human Phenotype Ontology Project: Linking Molecular Biology and Disease through Phenotype Data. Nucleic Acids Res. 2014, 42, D966–D974. [Google Scholar] [CrossRef] [PubMed]
- Köhler, S.; Gargano, M.; Matentzoglu, N.; Carmody, L.C.; Lewis-Smith, D.; Vasilevsky, N.A.; Danis, D.; Balagura, G.; Baynam, G.; Brower, A.M.; et al. The Human Phenotype Ontology in 2021. Nucleic Acids Res. 2021, 49, D1207–D1217. [Google Scholar] [CrossRef]
- Gkoutos, G.V.; Schofield, P.N.; Hoehndorf, R. The Anatomy of Phenotype Ontologies: Principles, Properties and Applications. Brief. Bioinform. 2018, 19, 1008–1021. [Google Scholar] [CrossRef] [PubMed]
- Mungall, C.J.; Torniai, C.; Gkoutos, G.V.; Lewis, S.E.; Haendel, M.A. Uberon, an Integrative Multi-Species Anatomy Ontology. Genome Biol. 2012, 13, R5–R20. [Google Scholar] [CrossRef] [PubMed]
- Haendel, M.A.; Balhoff, J.P.; Bastian, F.B.; Blackburn, D.C.; Blake, J.A.; Bradford, Y.; Comte, A.; Dahdul, W.M.; Dececchi, T.A.; Druzinsky, R.E. Unification of Multi-Species Vertebrate Anatomy Ontologies for Comparative Biology in Uberon. J. Biomed. Semant. 2014, 5, 21. [Google Scholar] [CrossRef]
- Rosse, C.; Mejino, J.L.V. A Reference Ontology for Biomedical Informatics: The Foundational Model of Anatomy. J. Biomed. Inform. 2003, 36, 478–500. [Google Scholar] [CrossRef]
- Cox, A.P.; Jensen, M.; Ruttenberg, A.; Szigeti, K.; Diehl, A.D. Measuring Cognitive Functions: Hurdles in the Development of the NeuroPsychological Testing Ontology. In Proceedings of the ICBO, Montreal, QC, Canada, 7–12 July 2013; pp. 78–83. [Google Scholar]
- Gomez-Valades, A.; Martinez-Tomas, R.; Rincon, M. Integrative Base Ontology for the Research Analysis of Alzheimer’s Disease-Related Mild Cognitive Impairment. Front. Neuroinformatics 2021, 15, 561691. [Google Scholar] [CrossRef]
- Peters, B.; OBI Consortium, T. Ontology for Biomedical Investigations. Nat. Preced. 2009, 1. [Google Scholar] [CrossRef]
- Bandrowski, A.; Brinkman, R.; Brochhausen, M.; Brush, M.H.; Bug, B.; Chibucos, M.C.; Clancy, K.; Courtot, M.; Derom, D.; Dumontier, M. The Ontology for Biomedical Investigations. PLoS ONE 2016, 11, e0154556. [Google Scholar] [CrossRef]
- Szklarczyk, D.; Kirsch, R.; Koutrouli, M.; Nastou, K.; Mehryary, F.; Hachilif, R.; Gable, A.L.; Fang, T.; Doncheva, N.T.; Pyysalo, S.; et al. The STRING Database in 2023: Protein–Protein Association Networks and Functional Enrichment Analyses for Any Sequenced Genome of Interest. Nucleic Acids Res. 2023, 51, D638–D646. [Google Scholar] [CrossRef]
- Gillespie, M.; Jassal, B.; Stephan, R.; Milacic, M.; Rothfels, K.; Senff-Ribeiro, A.; Griss, J.; Sevilla, C.; Matthews, L.; Gong, C.; et al. The Reactome Pathway Knowledgebase 2022. Nucleic Acids Res. 2022, 50, D687–D692. [Google Scholar] [CrossRef] [PubMed]
- Diehl, A.D.; Meehan, T.F.; Bradford, Y.M.; Brush, M.H.; Dahdul, W.M.; Dougall, D.S.; He, Y.; Osumi-Sutherland, D.; Ruttenberg, A.; Sarntivijai, S. The Cell Ontology 2016: Enhanced Content, Modularization, and Ontology Interoperability. J. Biomed. Semant. 2016, 7, 44. [Google Scholar] [CrossRef] [PubMed]
- Nadendla, S.; Jackson, R.; Munro, J.; Quaglia, F.; Mészáros, B.; Olley, D.; Hobbs, E.T.; Goralski, S.M.; Chibucos, M.; Mungall, C.J.; et al. ECO: The Evidence and Conclusion Ontology, an Update for 2022. Nucleic Acids Res. 2022, 50, D1515–D1521. [Google Scholar] [CrossRef]
- Malone, J.; Holloway, E.; Adamusiak, T.; Kapushesky, M.; Zheng, J.; Kolesnikov, N.; Zhukova, A.; Brazma, A.; Parkinson, H. Modeling Sample Variables with an Experimental Factor Ontology. Bioinformatics 2010, 26, 1112–1118. [Google Scholar] [CrossRef] [PubMed]
- Mayer, G.; Montecchi-Palazzi, L.; Ovelleiro, D.; Jones, A.R.; Binz, P.-A.; Deutsch, E.W.; Chambers, M.; Kallhardt, M.; Levander, F.; Shofstahl, J.; et al. The HUPO Proteomics Standards Initiative- Mass Spectrometry Controlled Vocabulary. Database 2013, 2013, bat009. [Google Scholar] [CrossRef]
- Stefancsik, R.; Balhoff, J.P.; Balk, M.A.; Ball, R.L.; Bello, S.M.; Caron, A.R.; Chesler, E.J.; de Souza, V.; Gehrke, S.; Haendel, M.; et al. The Ontology of Biological Attributes (OBA)—Computational Traits for the Life Sciences. Mamm. Genome 2023, 34, 364–378. [Google Scholar] [CrossRef]
- Scheuermann, R.H.; Ceusters, W.; Smith, B. Toward an Ontological Treatment of Disease and Diagnosis. Summit Transl. Bioinforma. 2009, 2009, 116. [Google Scholar]
- Hicks, A.; Hanna, J.; Welch, D.; Brochhausen, M.; Hogan, W.R. The Ontology of Medically Related Social Entities: Recent Developments. J. Biomed. Semant. 2016, 7, 47. [Google Scholar] [CrossRef] [PubMed]
- Kurlowicz, L.; Wallace, M. The Mini-Mental State Examination (MMSE). J. Gerontol. Nurs. 1999, 25, 8–9. [Google Scholar] [CrossRef]
- Fillenbaum, G.G.; Mohs, R. CERAD (Consortium to Establish a Registry for Alzheimer’s Disease) Neuropsychology Assessment Battery: 35 Years and Counting. J. Alzheimers Dis. 2023, 93, 1–27. [Google Scholar] [CrossRef] [PubMed]
- Quental, N.B.M.; Brucki, S.M.D.; Bueno, O.F.A. Visuospatial Function in Early Alzheimer’s Disease—The Use of the Visual Object and Space Perception (VOSP) Battery. PLoS ONE 2013, 8, e68398. [Google Scholar] [CrossRef]
- Bowie, C.R.; Harvey, P.D. Administration and Interpretation of the Trail Making Test. Nat. Protoc. 2006, 1, 2277–2281. [Google Scholar] [CrossRef]
- Mainland, B.J.; Shulman, K.I. Clock Drawing Test. In Cognitive Screening Instruments: A Practical Approach; Springer: London, UK, 2017; pp. 67–108. [Google Scholar] [CrossRef]
- Benton, A.L.; de Hamsher, S.; Sivan, A.B. Controlled Oral Word Association Test. Arch. Clin. Neuropsychol. 1994. [Google Scholar] [CrossRef]
- Jack, C.R., Jr.; Bennett, D.A.; Blennow, K.; Carrillo, M.C.; Dunn, B.; Haeberlein, S.B.; Holtzman, D.M.; Jagust, W.; Jessen, F.; Karlawish, J.; et al. NIA-AA Research Framework: Toward a Biological Definition of Alzheimer’s Disease. Alzheimers Dement. 2018, 14, 535–562. [Google Scholar] [CrossRef] [PubMed]
- Fecho, K.; Thessen, A.E.; Baranzini, S.E.; Bizon, C.; Hadlock, J.J.; Huang, S.; Roper, R.T.; Southall, N.; Ta, C.; Watkins, P.B.; et al. Progress toward a Universal Biomedical Data Translator. Clin. Transl. Sci. 2022, 15, 1838–1847. [Google Scholar] [CrossRef]
- Matentzoglu, N.; Goutte-Gattat, D.; Tan, S.Z.K.; Balhoff, J.P.; Carbon, S.; Caron, A.R.; Duncan, W.D.; Flack, J.E.; Haendel, M.; Harris, N.L.; et al. Ontology Development Kit: A Toolkit for Building, Maintaining, and Standardising Biomedical Ontologies. Database 2022, 2022, baac087. [Google Scholar] [CrossRef]
- Osumi-Sutherland, D.; Courtot, M.; Balhoff, J.P.; Mungall, C. Dead Simple OWL Design Patterns. J. Biomed. Semant. 2017, 8, 18. [Google Scholar] [CrossRef] [PubMed]
- Hitzler, P.; Krötzsch, M.; Parsia, B.; Patel-Schneider, P.F.; Rudolph, S. OWL 2 Web Ontology Language. Available online: https://www.w3.org/TR/owl2-primer/ (accessed on 30 August 2023).
- Lawrence Berkeley National Laboratory. (BBOP), Lawrence Berkeley National Knowledge Graph Hub. Available online: https://kghub.org/ (accessed on 30 August 2023).
- KGX Format—Kgx 1.5.1 Documentation. Available online: https://kgx.readthedocs.io/en/latest/kgx_format.html (accessed on 30 August 2023).
- KG-OBO. Available online: https://github.com/Knowledge-Graph-Hub/kg-obo (accessed on 30 August 2023).
- Relation-Graph. Available online: https://github.com/INCATools/relation-graph (accessed on 30 August 2023).
- Balhoff, J.P.; Bayindir, U.; Caron, A.R.; Matentzoglu, N.; Osumi-Sutherland, D.; Mungall, C.J. Ubergraph: Integrating OBO Ontologies into a Unified Semantic Graph. In CEUR Workshop Proceedings; CEUR-WS: Aachen, Germany, 2022; Volume 1613, p. 73. [Google Scholar]
- Kostovska, A.; Tolovski, I.; Maikore, F.; Initiative, A.D.N.; Soldatova, L.; Panov, P. Neurodegenerative Disease Data Ontology. In Proceedings of the Discovery Science: 22nd International Conference, DS 2019, Split, Croatia, 28–30 October 2019; pp. 235–245. [Google Scholar]
- Vita, R.; Zheng, J.; Jackson, R.; Dooley, D.; Overton, J.A.; Miller, M.A.; Berrios, D.C.; Scheuermann, R.H.; He, Y.; McGinty, H.K.; et al. Standardization of Assay Representation in the Ontology for Biomedical Investigations. Database 2021, 2021, baab040. [Google Scholar] [CrossRef]
- Fischl, B. FreeSurfer. Neuroimage 2012, 62, 774–781. [Google Scholar] [CrossRef] [PubMed]
- Yushkevich, P.A.; Pluta, J.B.; Wang, H.; Xie, L.; Ding, S.-L.; Gertje, E.C.; Mancuso, L.; Kliot, D.; Das, S.R.; Wolk, D.A. Automated Volumetry and Regional Thickness Analysis of Hippocampal Subfields and Medial Temporal Cortical Structures in Mild Cognitive Impairment. Hum. Brain Mapp. 2015, 36, 258–287. [Google Scholar] [CrossRef] [PubMed]
- Basser, P.J.; Mattiello, J.; LeBihan, D. MR Diffusion Tensor Spectroscopy and Imaging. Biophys. J. 1994, 66, 259–267. [Google Scholar] [CrossRef] [PubMed]
- Low, A.; Mak, E.; Stefaniak, J.D.; Malpetti, M.; Nicastro, N.; Savulich, G.; Chouliaras, L.; Markus, H.S.; Rowe, J.B.; O’Brien, J.T. Peak Width of Skeletonized Mean Diffusivity as a Marker of Diffuse Cerebrovascular Damage. Front. Neurosci. 2020, 14, 238. [Google Scholar] [CrossRef] [PubMed]
- Fladby, T.; Pålhaugen, L.; Selnes, P.; Waterloo, K.; Bråthen, G.; Hessen, E.; Almdahl, I.S.; Arntzen, K.-A.; Auning, E.; Eliassen, C.F.; et al. Detecting At-Risk Alzheimer’s Disease Cases. J. Alzheimers Dis. 2017, 60, 97–105. [Google Scholar] [CrossRef]
- Marcus, D.S.; Olsen, T.R.; Ramaratnam, M.; Buckner, R.L. The Extensible Neuroimaging Archive Toolkit: An Informatics Platform for Managing, Exploring, and Sharing Neuroimaging Data. Neuroinformatics 2007, 5, 11–34. [Google Scholar] [CrossRef]
- Fillenbaum, G.G.; van Belle, G.; Morris, J.C.; Mohs, R.C.; Mirra, S.S.; Davis, P.C.; Tariot, P.N.; Silverman, J.M.; Clark, C.M.; Welsh-Bohmer, K.A.; et al. Consortium to Establish a Registry for Alzheimer’s Disease (CERAD): The First Twenty Years. Alzheimers Dement. 2008, 4, 96–109. [Google Scholar] [CrossRef] [PubMed]
- Kirsebom, B.E.; Espenes, R.; Hessen, E.; Waterloo, K.; Johnsen, S.H.; Gundersen, E.; Botne Sando, S.; Rolfseng Grøntvedt, G.; Timón, S.; Fladby, T. Demographically Adjusted CERAD Wordlist Test Norms in a Norwegian Sample from 40 to 80 Years. Clin. Neuropsychol. 2019, 33, 27–39. [Google Scholar] [CrossRef]
- Espenes, J.; Hessen, E.; Eliassen, I.V.; Waterloo, K.; Eckerström, M.; Sando, S.B.; Timón, S.; Wallin, A.; Fladby, T.; Kirsebom, B.-E. Demographically Adjusted Trail Making Test Norms in a Scandinavian Sample from 41 to 84 Years. Clin. Neuropsychol. 2020, 34, 110–126. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. Node2vec: Scalable Feature Learning for Networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Source Identifier | Reference |
|---|---|---|
| Basic Formal Ontology | BFO | [50] |
| Biolink model | biolink | [36] |
| Chemical Entities of Biological Interest | CHEBI | [53] |
| Cell Ontology | CL | [68] |
| Evidence and Conclusion Ontology | ECO | [69] |
| Environmental Factor Ontology | EFO | [70] |
| Gene Ontology | GO | [52] |
| Gene Ontology Annotations | GOA | - |
| Human Phenotype Ontology | HP | [57] |
| Human Phenotype Ontology Annotations | HPOA | - |
| Information Artifact Ontology | IAO | - |
| Mass Spectrometry Ontology | MS | [71] |
| Mondo Disease Ontology | MONDO | [55] |
| Monarch KG | Monarch | [29] |
| Neurocognitive Integrated Ontology | NIO | [63] |
| Neuropsychological Testing Ontology | NPT | [62] |
| Ontology of Biological Attributes | OBA | [72] |
| Ontology for Biomedical Investigations | OBI | [65] |
| Ontology for General Medical Science | OGMS | [73] |
| Ontology of Medically Related Social Entities | OMRSE | [74] |
| Phenotype And Trait Ontology | PATO | [58] |
| Phenomics Integrated Ontology | PHENIO | - |
| Protein Ontology | PR | [54] |
| Relations Ontology | RO | - |
| Reactome | Reactome | [67] |
| Scientific Evidence and Provenance Information Ontology | SEPIO | - |
| STRING database ingestion | STRING | [66] |
| Uber Anatomy Ontology | UBERON | [59] |
| AT(N) Profiles | Biomarker Category | |
|---|---|---|
| A-T-(N)- | Normal AD biomarkers | |
| A-+T-(N)- | Alzheimer’s pathologic change | Alzheimer’s continuum |
| A+T+(N)- | Alzheimer’s disease | |
| A+T+(N)+ | Alzheimer’s disease | |
| A+T-(N)+ | Alzheimer’s and concomitant suspected non-Alzheimer’s pathologic change | |
| A-T+(N)- | Non-AD pathologic change | |
| A-T-(N)+ | Non-AD pathologic change | |
| A-T+(N)+ | Non-AD pathologic change |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Timón-Reina, S.; Rincón, M.; Martínez-Tomás, R.; Kirsebom, B.-E.; Fladby, T. A Knowledge Graph Framework for Dementia Research Data. Appl. Sci. 2023, 13, 10497. https://doi.org/10.3390/app131810497
Timón-Reina S, Rincón M, Martínez-Tomás R, Kirsebom B-E, Fladby T. A Knowledge Graph Framework for Dementia Research Data. Applied Sciences. 2023; 13(18):10497. https://doi.org/10.3390/app131810497
Chicago/Turabian StyleTimón-Reina, Santiago, Mariano Rincón, Rafael Martínez-Tomás, Bjørn-Eivind Kirsebom, and Tormod Fladby. 2023. "A Knowledge Graph Framework for Dementia Research Data" Applied Sciences 13, no. 18: 10497. https://doi.org/10.3390/app131810497
APA StyleTimón-Reina, S., Rincón, M., Martínez-Tomás, R., Kirsebom, B. -E., & Fladby, T. (2023). A Knowledge Graph Framework for Dementia Research Data. Applied Sciences, 13(18), 10497. https://doi.org/10.3390/app131810497