
Valuable Knowledge Mining: Deep Analysis of Heart Disease and Psychological Causes Based on Large-Scale Medical Data



Abstract
:1. Introduction
2. Related Work
3. Motivation
4. Materials and Methods
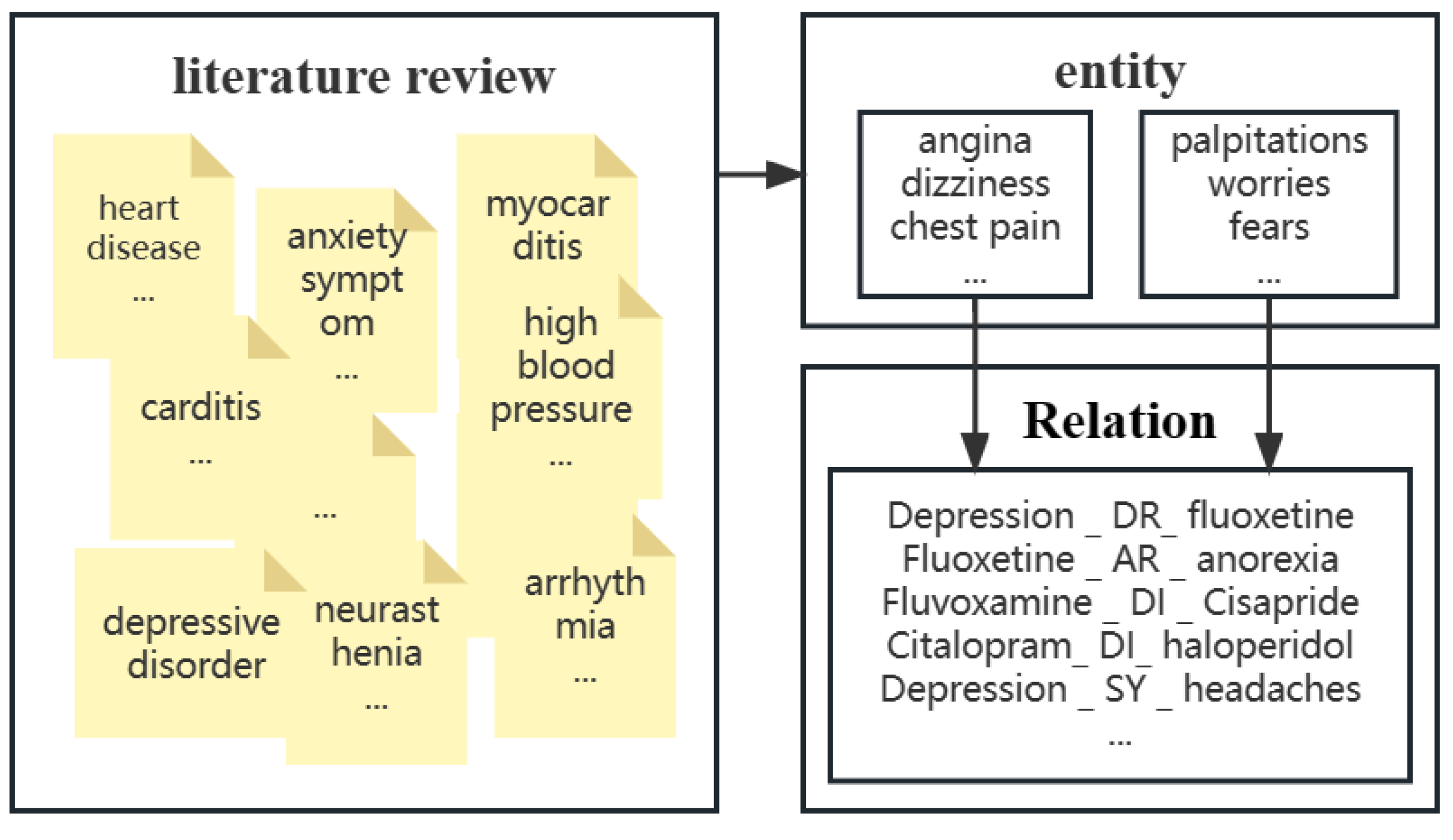
4.1. Dataset
4.2. WBC Model
4.2.1. Word-Embedding Layer
4.2.2. BiLSTM Layer
4.2.3. CRF Layer
4.3. CSR Model
5. Results
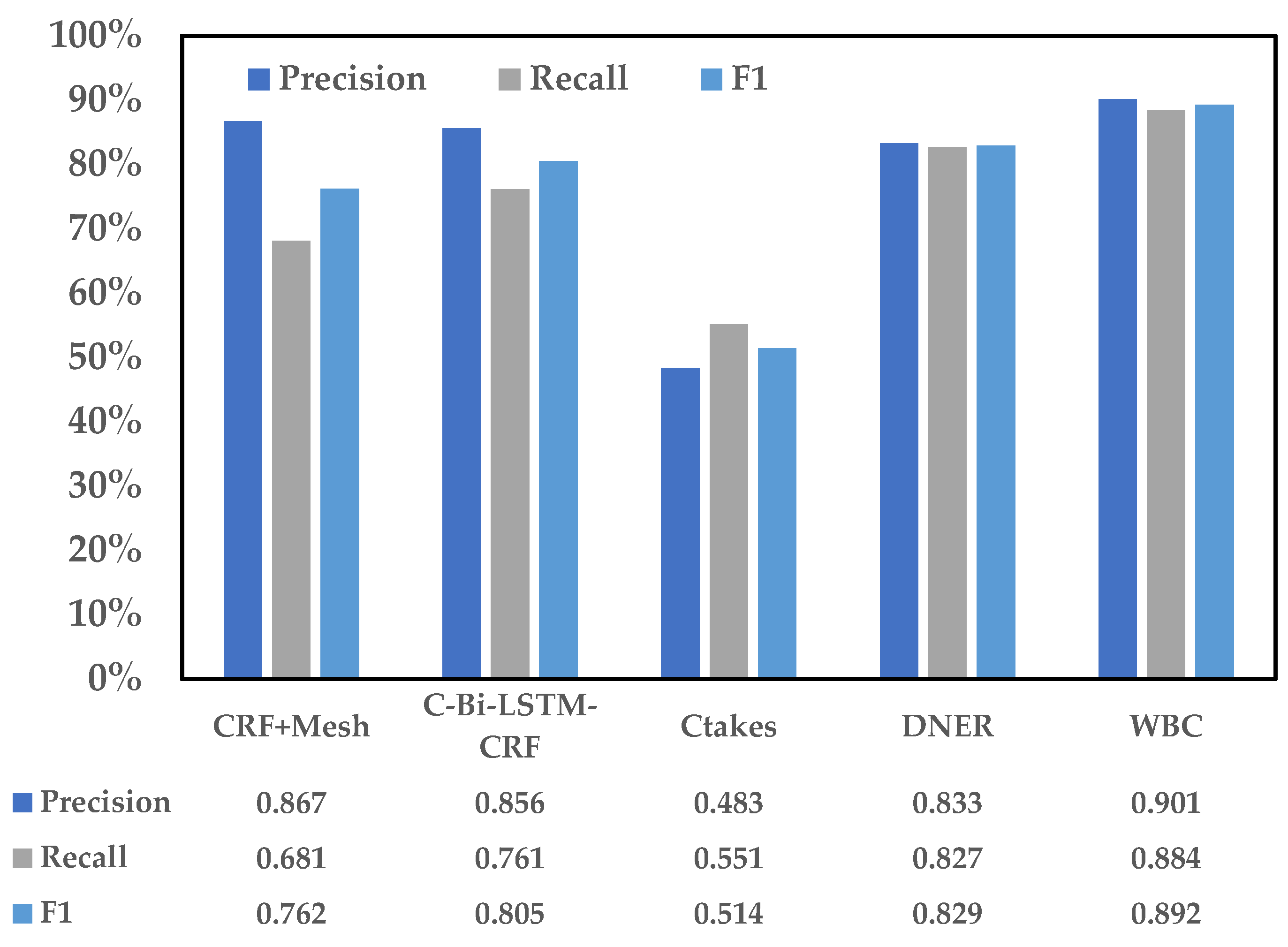
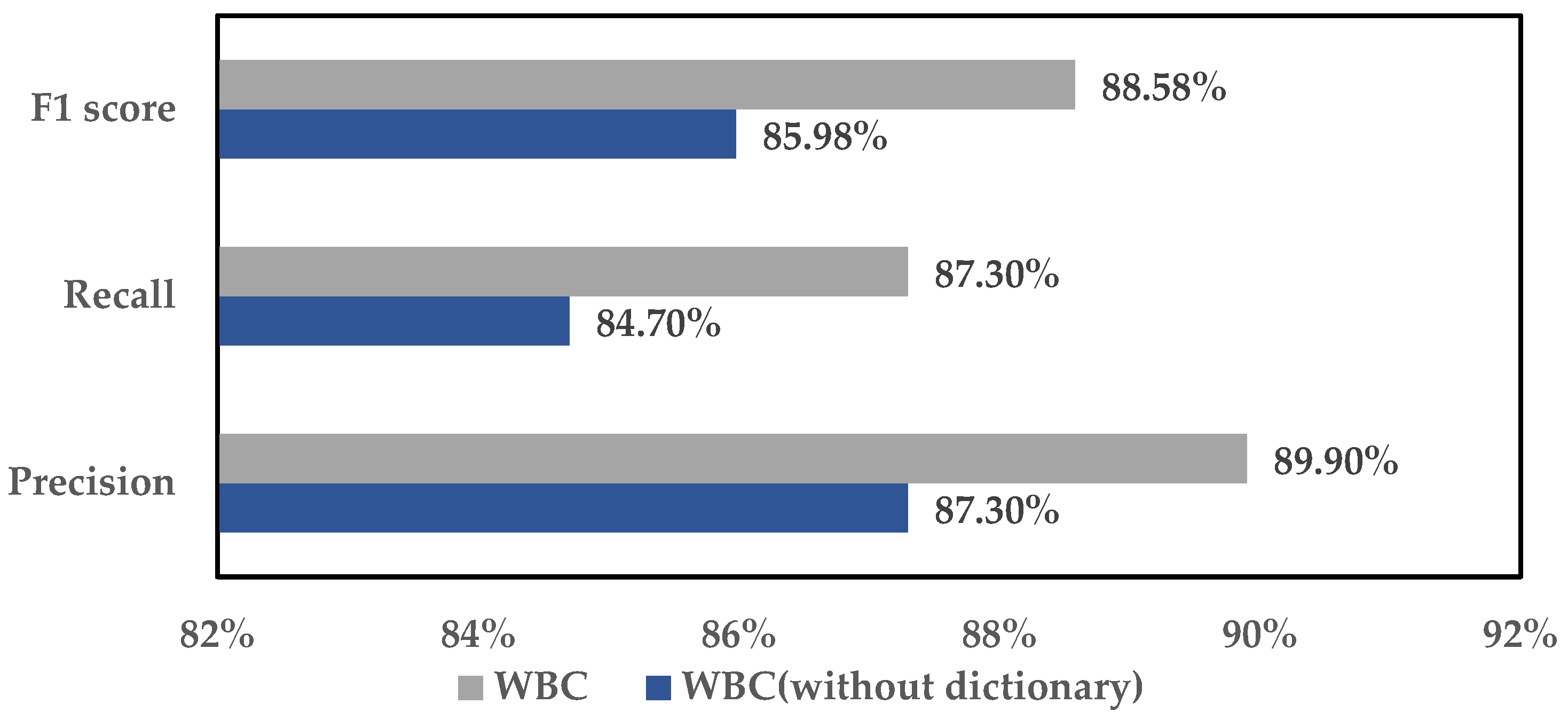
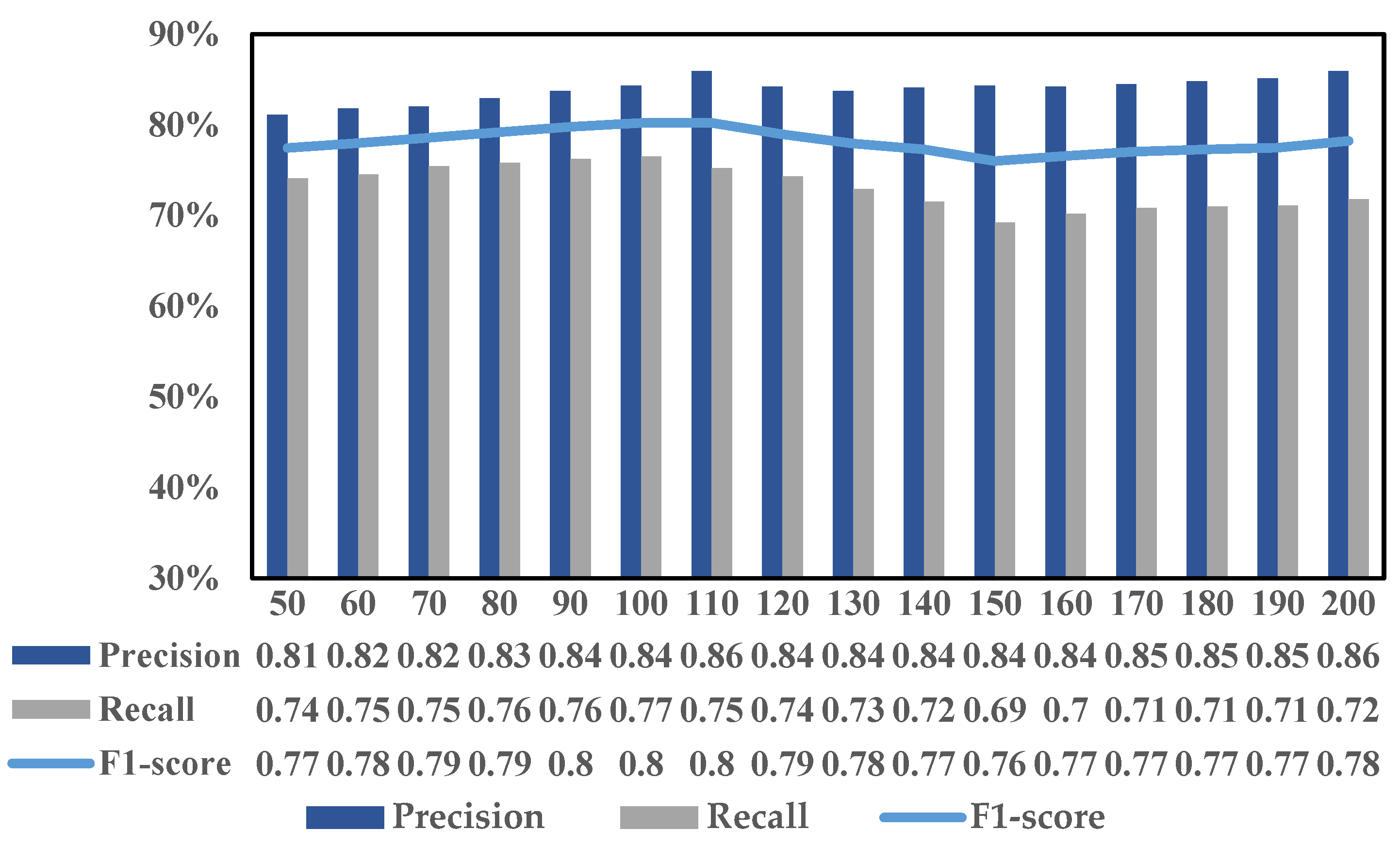
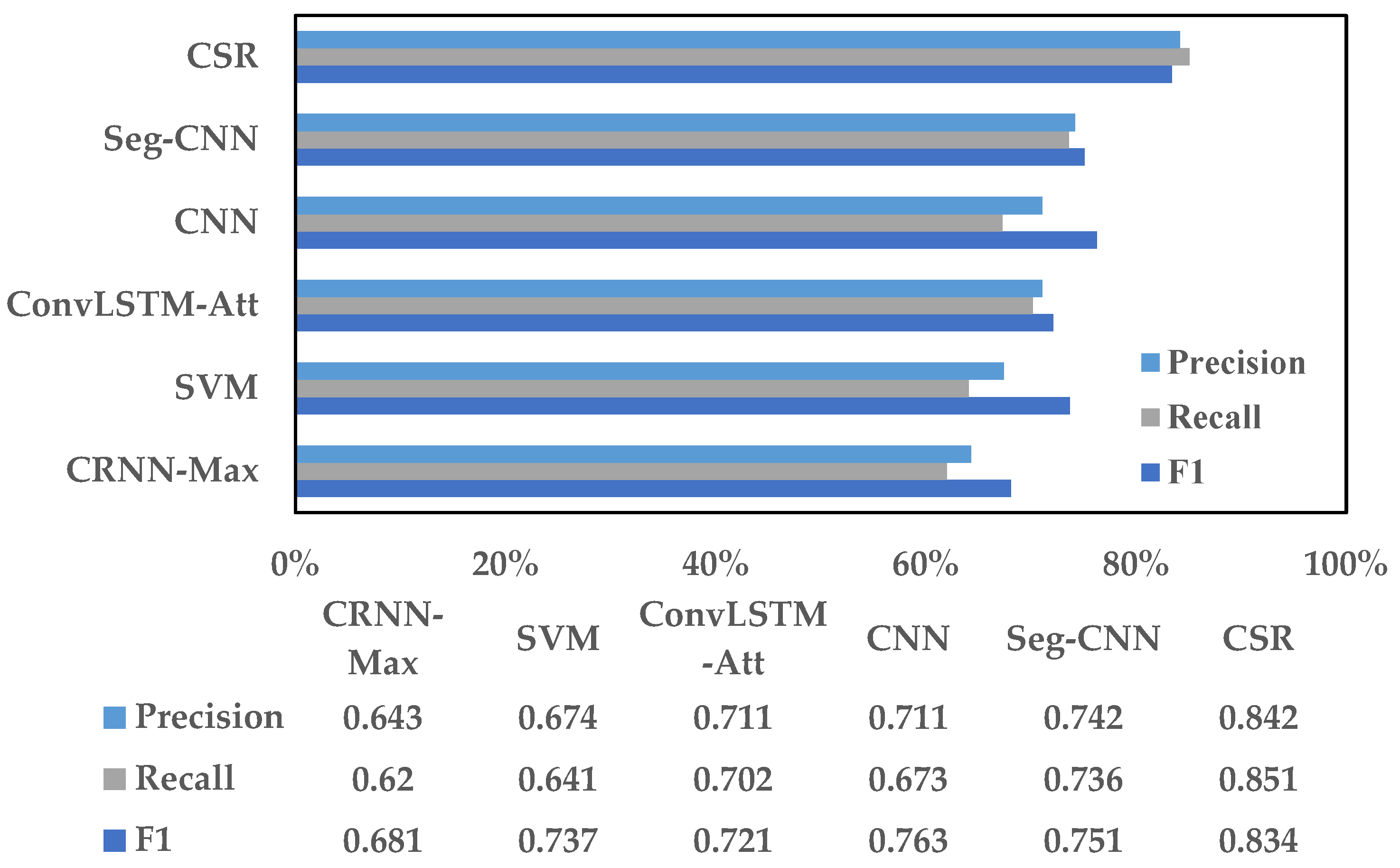
5.1. Experiment about WBC Model
5.2. Experiment with CSR Model
6. Diseases Pathogenesis Study
6.1. Biological Factors
- (1)
- Inflammatory response (chest pain, headaches, etc.): inflammatory response is one of the important factors linking psychological disorders and emotional heart disease. Patients with psychological problems or under mental stress have elevated levels of inflammatory markers in their bodies. There is a correlation between elevated levels of inflammatory cytokines and the presence of emotional issues (depressive symptoms, anxiety symptoms, etc.) in patients, with significantly elevated levels of inflammatory markers such as C-reactive protein (CRP), pro-inflammatory cytokines (IL1β, IL2, IL6), and tumor necrosis factor-α (TNF-α) in patients with emotional problems. Compared to healthy individuals, the concentration of kyn trp−1 in patients’ blood increases from 36.3 ± 13.26 µmol L−1 to 28.1 ± 5.15 µmol L−1, while the concentration of tryptophan decreases from 8.51 ± 4.11 µmol L−1 to 5.84 ± 1.30 µmol L−1. Based on the changes in kyn trp−1 and tryptophan indices, it is evident that cellular immune response has been activated, resulting in an increased rate of tryptophan degradation. This demonstrates that negative psychological factors such as stress and negative emotions can activate the body’s stress pathways, leading to an inflammatory response, thereby causing heart problems in patients through symptoms such as arterial atherosclerosis.
- (2)
- Endothelial dysfunction, manifested as hypertension and tachycardia, is a fundamental factor in acute coronary syndrome, which is a heart issue. Flow-mediated dilation (FMD) is used to quantify endothelial function. FMD refers to the metabolic waste produced by muscle contraction entering the bloodstream through the arteries, which is sensed by endothelial cells that then release signaling molecules. The FMD value of emotional heart disease patients, as analyzed, was 4.36 ± 0.75% when the value below 5%, while that of non-emotional heart disease patients was 7.46 ± 0.89%. A healthy value should be greater than 10%. The FMD index indicates that emotional heart disease patients have endothelial dysfunction, indicating that psychological issues resulting in emotional disturbances (such as depressive and anxiety symptoms) play a role in the pathogenesis of emotional heart disease.
- (3)
- Platelet abnormalities (thrombosis, etc.): platelets, endothelial components, and coagulation factors interact with each other, playing an important role in the process of thrombus formation. In the arteries of patients with atherosclerosis, serotonin mediates platelet aggregation by binding to 5-hydroxytryptamine (5-HT). In a healthy state, the serotonin uptake rate of platelets is between 50% and 80%, with a serotonin content of about 0.09–0.27 ng/108 platelets. The platelet release rate is usually between 20% and 70%. Patients with emotional symptoms (depression, anxiety, etc.) have abnormal levels of platelet serotonin, with a decrease in platelet serotonin transporter levels of 17.6%, and an increase in platelet serotonin receptor concentration of about 20.6%. Serotonin is an endogenous substance that mainly participates in the onset of depression, and it binds to 5-hydroxytryptamine (5-HT) receptors on platelets, promoting platelet function and affecting the process of blood coagulation.
- (4)
- Abnormal neurotransmitters (palpitation, elevated blood glucose, etc.): there is an association between abnormal neurotransmitters and psychological as well as cardiac diseases. Higher concentrations of catecholamines (adrenaline and noradrenaline)—products of sympathetic adrenomedullary activation—have been observed in cardiac patients. Activation of the sympathetic adrenomedullary system leads to vasoconstriction, hypertension, increased heart rate, and platelet activation in cardiac patients. Analysis suggests that levels of adrenaline and cortisol in the blood of cardiac patients with emotional distress are elevated, possibly due to autonomic nervous system changes that increase their mortality rate. HPA (hypothalamic–pituitary–adrenal axis)-related abnormalities lead to higher than normal range indicators of adrenaline and dopamine (adrenaline: 107–412 pg/mL (M); 62–363 pg/mL (F), dopamine: 10–178 pg/mL (M); 10–150 pg/mL (F)), ultimately causing other clinical conditions such as metabolic disorders like obesity, hypertension, impaired glucose tolerance, hypertriglyceridemia, and hypercholesterolemia, which directly lead to adverse development of cardiovascular conditions.
- (5)
- Heart rate variability (HRV): the normal range of HRV values in individuals can vary depending on factors such as age, gender, physical health status, and activity level. Generally, higher HRV values indicate better cardiac stability and stronger autonomic nervous system function. HRV is significantly lower in emotional heart disease patients compared to non-emotional heart disease patients (90 ± 35 vs. 117 ± 26 ms), and reduced HRV is an important factor in the onset and exacerbation of emotional heart disease.
6.2. Lifestyle Behavioral Factors
6.3. Therapeutic Drugs Factors
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Névéol, A.; Li, J.; Lu, Z. Linking Multiple Disease-Related Resources through UMLS. In Proceedings of the ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; pp. 767–772. [Google Scholar]
- Doğan, R.I.; Leaman, R.; Lu, Z. NCBI disease corpus: A resource for disease name recognition and concept normalization. J. Biomed. Inform. 2014, 47, 1–10. [Google Scholar] [CrossRef]
- Leaman, R.; Islamaj Doğan, R.; Lu, Z. DNorm: Disease name normalization with pairwise learning to rank. Bioinformatics 2013, 29, 2909–2917. [Google Scholar] [CrossRef] [PubMed]
- Meystre, S.M.; Savova, G.K.; Kipper-Schuler, K.C. Extracting information from textual documents in the electronic health record: A review of recent research. Yearb. Med. Inform. 2008, 17, 128–144. [Google Scholar]
- Eltyeb, S.; Salim, N. Chemical named entities recognition: A review on approaches and applications. J. Cheminform. 2014, 6, 17. [Google Scholar] [CrossRef]
- Goulart, R.R.V.; Strube de Lima, V.L.; Xavier, C.C. A systematic review of named entity recognition in biomedical texts. J. Braz. Comput. Soc. 2011, 17, 103–116. [Google Scholar] [CrossRef]
- Meystre, S.M.; Friedlin, F.J.; South, B.R. Automatic de-identification of textual documents in the electronic health record: A review of recent research. BMC Med. Res. Methodol. 2010, 10, 70. [Google Scholar] [CrossRef] [PubMed]
- Rzhetsky, A.; Seringhaus, M.; Gerstein, M. Seeking a new biology through text mining. Cell 2008, 134, 9–13. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K. Distributed representations of words and phrases and their compositionality. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Arnaud, É.; Elbattah, M.; Gignon, M.; Dequen, G. Learning Embeddings from Free-text Triage Notes using Pretrained Transformer Models. HEALTHINF 2022, 5, 835–841. [Google Scholar]
- Wang, X.; Zhang, Y.; Li, Q. Distantly supervised biomedical named entity recognition with dictionary expansion. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 496–503. [Google Scholar]
- Xu, K.; Yang, Z.; Kang, P. Document-level attention-based BiLSTM-CRF incorporating disease dictionary for disease named entity recognition. Comput. Biol. Med. 2019, 108, 122–132. [Google Scholar] [CrossRef]
- Mu, X.; Wang, W.; Xu, A. Incorporating token-level dictionary feature into neural model for named entity recognition. Neurocomputing 2020, 375, 43–50. [Google Scholar]
- Shang, J.; Liu, L.; Ren, X. Learning named entity tagger using domain-specific dictionary. arXiv 2018, arXiv:1809.03599. [Google Scholar]
- Fan, R.; Wang, L.; Yan, J. Deep learning-based named entity recognition and knowledge graph construction for geological hazards. ISPRS Int. J. Geo-Inf. 2019, 9, 15. [Google Scholar] [CrossRef]
- Li, Y.; Shetty, P.; Liu, L. BERTifying the Hidden Markov Model for Multi-Source Weakly Supervised Named Entity Recognition. arXiv 2021, arXiv:2105.12848. [Google Scholar]
- Greenberg, N.; Bansal, T.; Verga, P. Marginal likelihood training of BiLSTM-CRF for biomedical named entity recognition from disjoint label sets. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2824–2829. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- van de Kerkhof, J. Convolutional Neural Networks for Named Entity Recognition in Images of Documents; Aalto University: Espoo, Finland, 2016. [Google Scholar]
- Chiu, J.P.C.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Xin, J.; Lin, Y.; Liu, Z. Improving neural fine-grained entity typing with knowledge attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 1. [Google Scholar]
- De Magistris, G.; Russo, S.; Roma, P. An explainable fake news detector based on named entity recognition and stance classification applied to COVID-19. Information 2022, 13, 137. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Gutmann, M.; Hyvärinen, A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Proceedings of the JMLR Workshop and Conference Proceedings. pp. 297–304. [Google Scholar]
- Liu, C.; Sun, W.; Chao, W. Convolution neural network for relation extraction. In International Conference on Advanced Data Mining and Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 231–242. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph convolution over pruned dependency trees improves relation extraction. arXiv 2018, arXiv:1809.10185. [Google Scholar]
- Dai, H.; Zhu, M.; Yuan, G.; Niu, Y.; Shi, H.; Chen, B. Entity recognition for Chinese hazardous chemical accident data based on rules and a pre-trained model. Appl. Sci. 2022, 13, 375. [Google Scholar] [CrossRef]
- Panoutsopoulos, H.; Brewster, C.; Espejo-Garcia, B. Developing a Model for the Automated Identification and Extraction of Agricultural Terms from Unstructured Text. Chem. Proc. 2022, 10, 94. [Google Scholar]
- Sun, M.; Yang, Q.; Wang, H.; Pasquine, M.; Hameed, I.A. Learning the Morphological and Syntactic Grammars for Named Entity Recognition. Information 2022, 13, 49. [Google Scholar] [CrossRef]
- Cunha, L.F.C.; Ramalho, J.C. NER in Archival Finding Aids: Extended. Mach. Learn. Knowl. Extr. 2022, 4, 42–65. [Google Scholar] [CrossRef]
- Sboev, A.; Sboeva, S.; Moloshnikov, I.; Gryaznov, A.; Rybka, R.; Naumov, A.; Selivanov, A.; Rylkov, G.; Ilyin, V. Analysis of the Full-Size Russian Corpus of Internet Drug Reviews with Complex NER Labeling Using Deep Learning Neural Networks and Language Models. Appl. Sci. 2022, 12, 491. [Google Scholar] [CrossRef]
- Wei, Z.; Su, J.; Wang, Y. A novel cascade binary tagging framework for relational triple extration. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1105–1106. [Google Scholar]
- NCBI. Available online: https://www.ncbi.nlm.nih.gov/CBBresearch/Dogan/DISEASE/ (accessed on 18 September 2023).
- Gauch, M.; Kratzert, F.; Klotz, D.; Nearing, G.; Lin, J.; Hochreiter, S. Rainfall–runoff prediction at multiple timescales with a single Long Short-Term Memory network. Hydrol. Earth Syst. Sci. 2021, 25, 2045–2062. [Google Scholar] [CrossRef]
- Chen, K.; Wang, R.; Utiyama, M.; Sumita, E. Context-aware positional representation for self-attention networks. Neurocomputing 2021, 451, 46–56. [Google Scholar] [CrossRef]
- Xu, K.; Zhou, Z.; Hao, T.; Liu, W. A bidirectional LSTM and conditional random fields approach to medical named entity recognition. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 9–11 September 2017; Springer: Cham, Switzerland, 2018; pp. 355–365. [Google Scholar]
- Savova, G.K.; Masanz, J.J.; Ogren, P.V.; Zheng, J.; Sohn, S.; Kipper-Schuler, K.C.; Chute, C.G. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): Architecture, component evaluation and applications. J. Am. Med. Inform. Assoc. 2010, 17, 507–513. [Google Scholar] [CrossRef]
- Wei, Q.; Chen, T.; Xu, R.; He, Y.; Gui, L. Disease named entity recognition by combining conditional random fields and bidirectional recurrent neural networks. Database 2016, 2016, baw140. [Google Scholar] [CrossRef]
- Goldberg, Y.; Levy, O. Word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Sohn, S.; Comeau, D.C.; Kim, W. Abbreviation definition identification based on automatic precision estimates. BMC Bioinform. 2008, 9, 402. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Setting | Description |
|---|---|---|
| Word_ dimension | 200 | Token embedding dimension |
| Word_LSTM_dim | 110 | Token size in hidden layer |
| Word_bidirectional | TRUE | Using Bi-LSTM |
| Word Embedding | TRUE | Using word embedding |
| CRF | TRUE | Using CRF |
| Ab3P | TRUE | Using Ab3P |
| Pluralistic Relation | Support Degree |
|---|---|
| Stress cardiomyopathy–depression–palpitation–sleep disorders–TCAs | 0.3165 |
| Takotsubo cardiomyopathy–anxiety–hormonal changes–chest pain–lorazepam | 0.3038 |
| Takotsubo cardiomyopathy–depression–anxiety–tachycardia–aspirin | 0.2970 |
| Takotsubo cardiomyopathy–psychological stress–Dyspnea–Biological differences–diazine pyridine | 0.2775 |
| Stress cardiomyopathy–anxiety–insomnia–palpitation–metoprolol | 0.2511 |
| Stress cardiomyopathy–anxiety–elevated blood pressure–loss of appetite–SSRIs | 0.2396 |
| Takotsubo cardiomyopathy–heart failure–arrhythmia– vasoconstriction–ACE inhibitors | 0.2006 |
| Stress cardiomyopathy–anxiety–elevated blood sugar–tachycardia–clopidogrel | 0.1869 |
| Broken heart syndrome–hypertension–headache–atherosclerosis–nifedipine | 0.1788 |
| Broken heart syndrome–hyperlipidemia–arrhythmia– thrombosis–warfarin | 0.1628 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Shan, M.; Zhou, T.H.; Ryu, K.H. Valuable Knowledge Mining: Deep Analysis of Heart Disease and Psychological Causes Based on Large-Scale Medical Data. Appl. Sci. 2023, 13, 11151. https://doi.org/10.3390/app132011151
Wang L, Shan M, Zhou TH, Ryu KH. Valuable Knowledge Mining: Deep Analysis of Heart Disease and Psychological Causes Based on Large-Scale Medical Data. Applied Sciences. 2023; 13(20):11151. https://doi.org/10.3390/app132011151
Chicago/Turabian StyleWang, Ling, Minglei Shan, Tie Hua Zhou, and Keun Ho Ryu. 2023. "Valuable Knowledge Mining: Deep Analysis of Heart Disease and Psychological Causes Based on Large-Scale Medical Data" Applied Sciences 13, no. 20: 11151. https://doi.org/10.3390/app132011151
APA StyleWang, L., Shan, M., Zhou, T. H., & Ryu, K. H. (2023). Valuable Knowledge Mining: Deep Analysis of Heart Disease and Psychological Causes Based on Large-Scale Medical Data. Applied Sciences, 13(20), 11151. https://doi.org/10.3390/app132011151