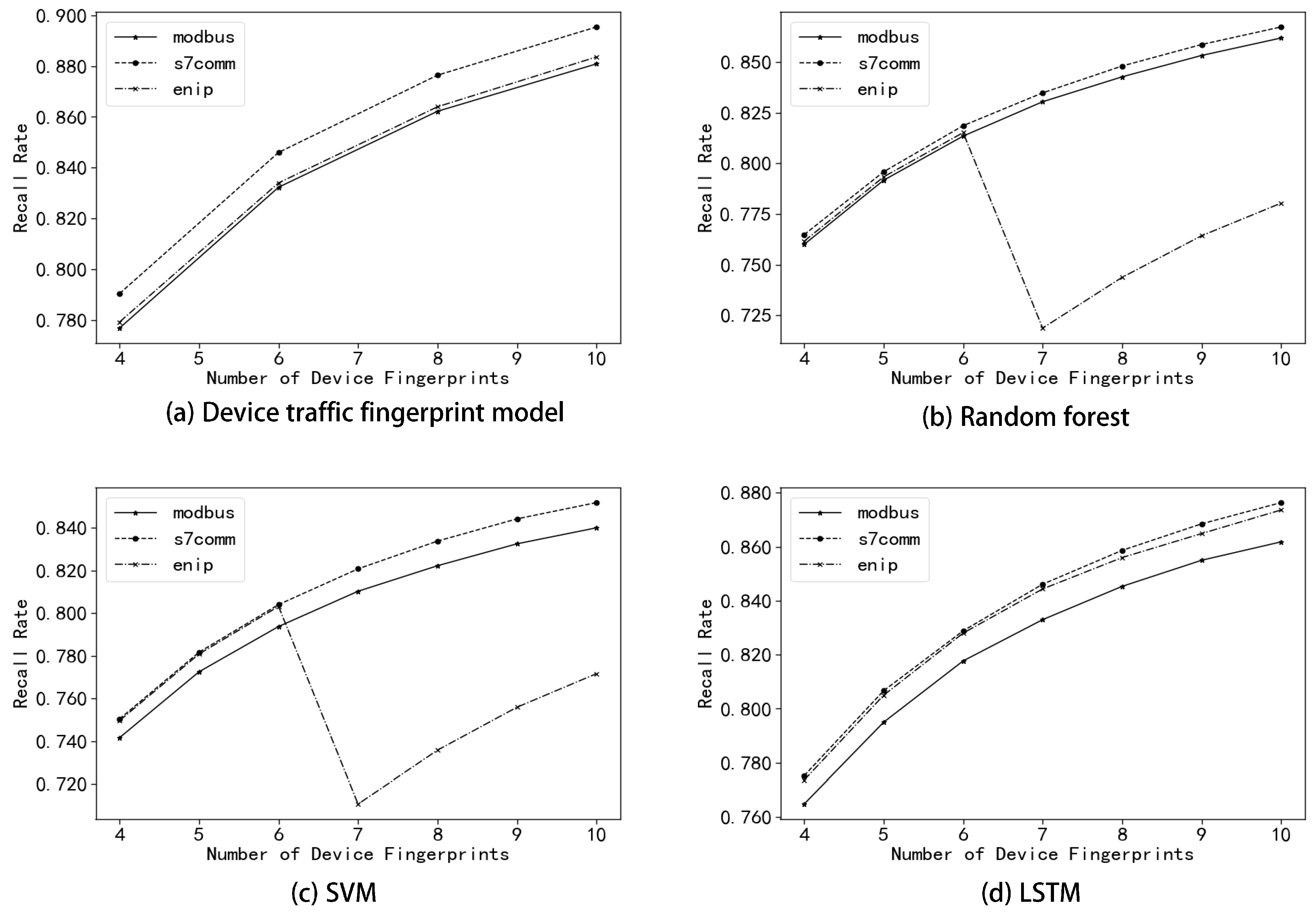
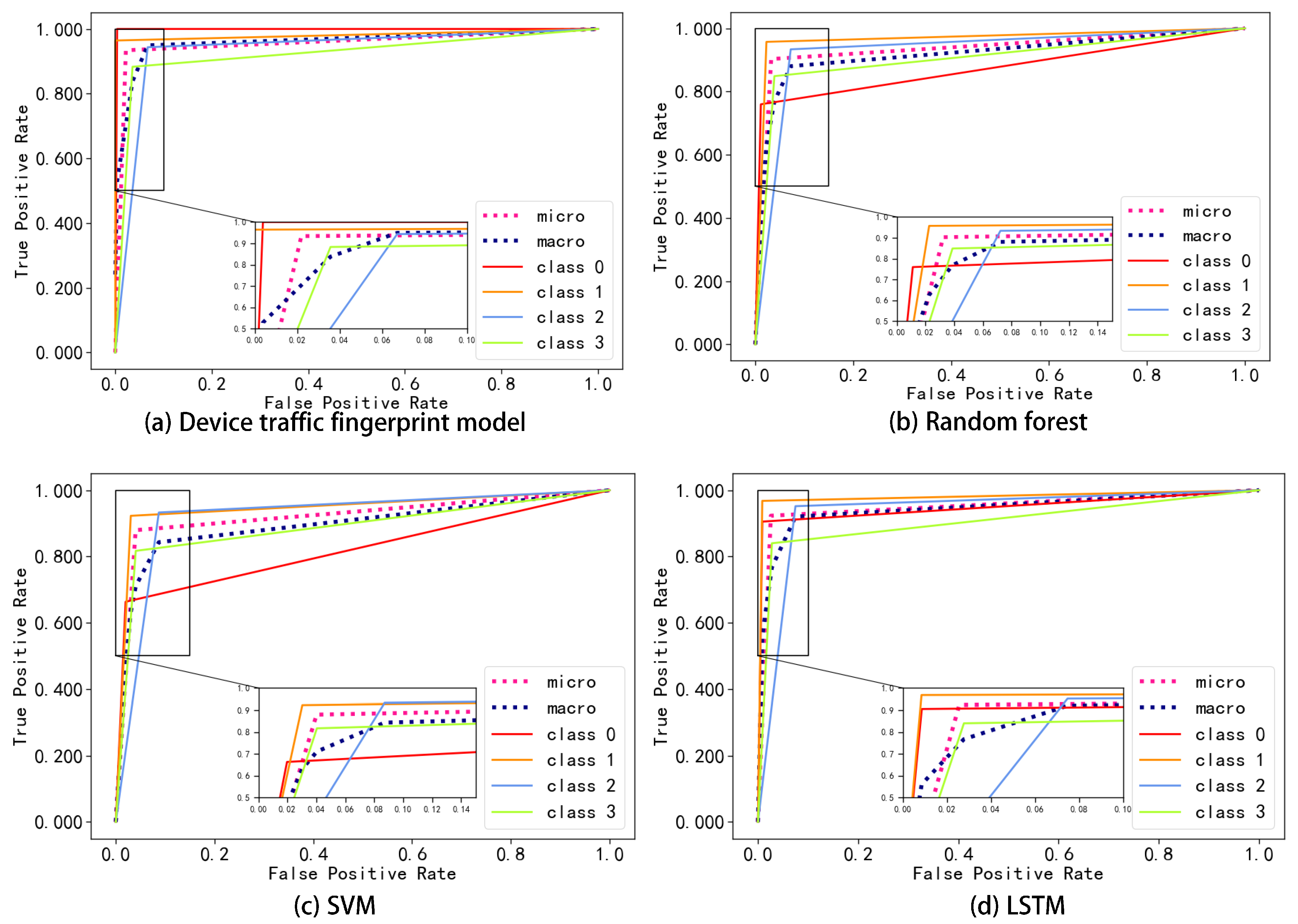
3.1. Device Fingerprint Extraction
The flow data of all devices can be collected from the SCADA system. For a single data packet in the flow data, it is abstracted into a mode
. The calculation process is as Equation (
1):
f is an abstract function, the specific implementation depends on the type of industrial control protocol.
u represents the specific industrial control protocol,
l represents the length of the data packet,
t represents the function of the protocol, and m represents the information carried by the protocol. The more information there is, the more patterns are abstracted, resulting in a large difference in the pattern sequence of the same device in different time periods, which cannot be recognized. On the contrary, if the selected information is less, the pattern sequence between different devices will be more similar, causing device confusion. Therefore, characteristic fields with high identification and few changes in the protocol are usually selected. For example, Modbus is a data communication protocol that is based on a request-response model, and is used for transmitting information between devices that are connected to buses or networks over serial lines or Ethernet. The format of Modbus protocol is illustrated in
Figure 1. This paper adopts MAC layer, IP layer, TCP layer, transaction, function code, unit, and address information instead of coil value information, because the coil value has a high rate of change and is not suitable for abstraction.
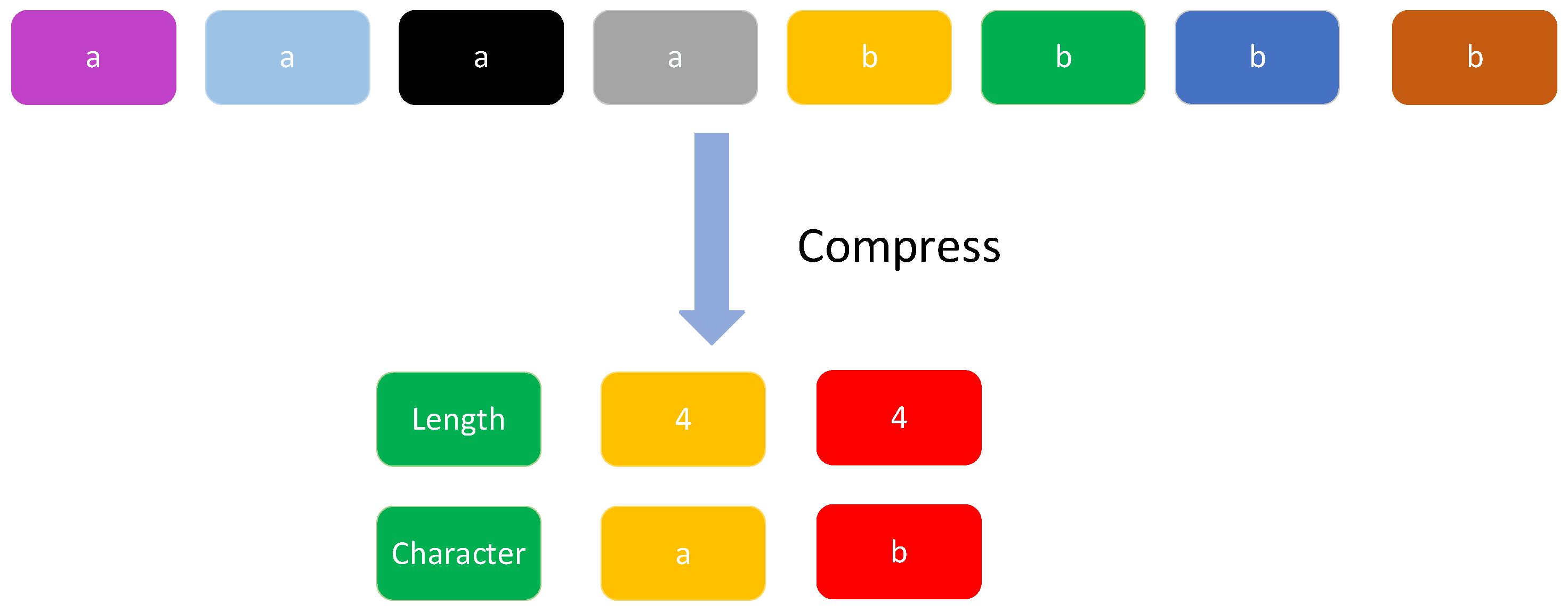
After abstracting the data packet into a pattern, a pattern sequence
can be obtained. The traffic collected from the industrial control network often has a large number of repeated data packets. If the repeated data packets are not preprocessed, it will not only waste storage space, affect the efficiency of device identification, but also affect the identification accuracy due to the irregular number of repetitions. Therefore, this paper stores the number of repeating patterns and patterns separately, as shown in
Figure 2.
The kernel of the industrial control system is a fixed cyclic operation process, and the work that all devices are responsible for will not change easily. Therefore, the collected traffic data has a certain regularity. The pattern sequence can be used as the fingerprint of the device, and then it is identified based on pattern matching. If only the pattern sequence of the device is kept, each match is time-intensive and inefficient. Therefore, this paper uses the suffix matching algorithm to process the pattern sequence. The matching process in the identification only needs time complexity, where n is the length of the query sequence, and k is the number of times the query sequence appears in the fingerprint sequence. Suffix matching can be stored in suffix array or suffix tree. Compared with suffix tree, the time overhead of suffix array in matching is almost the same, but it can save storage space. Therefore, this paper adopts the form of suffix array to store.
In order to explain the suffix array generation algorithm more clearly, the concepts used in the algorithm are listed first, as shown in
Table 1:
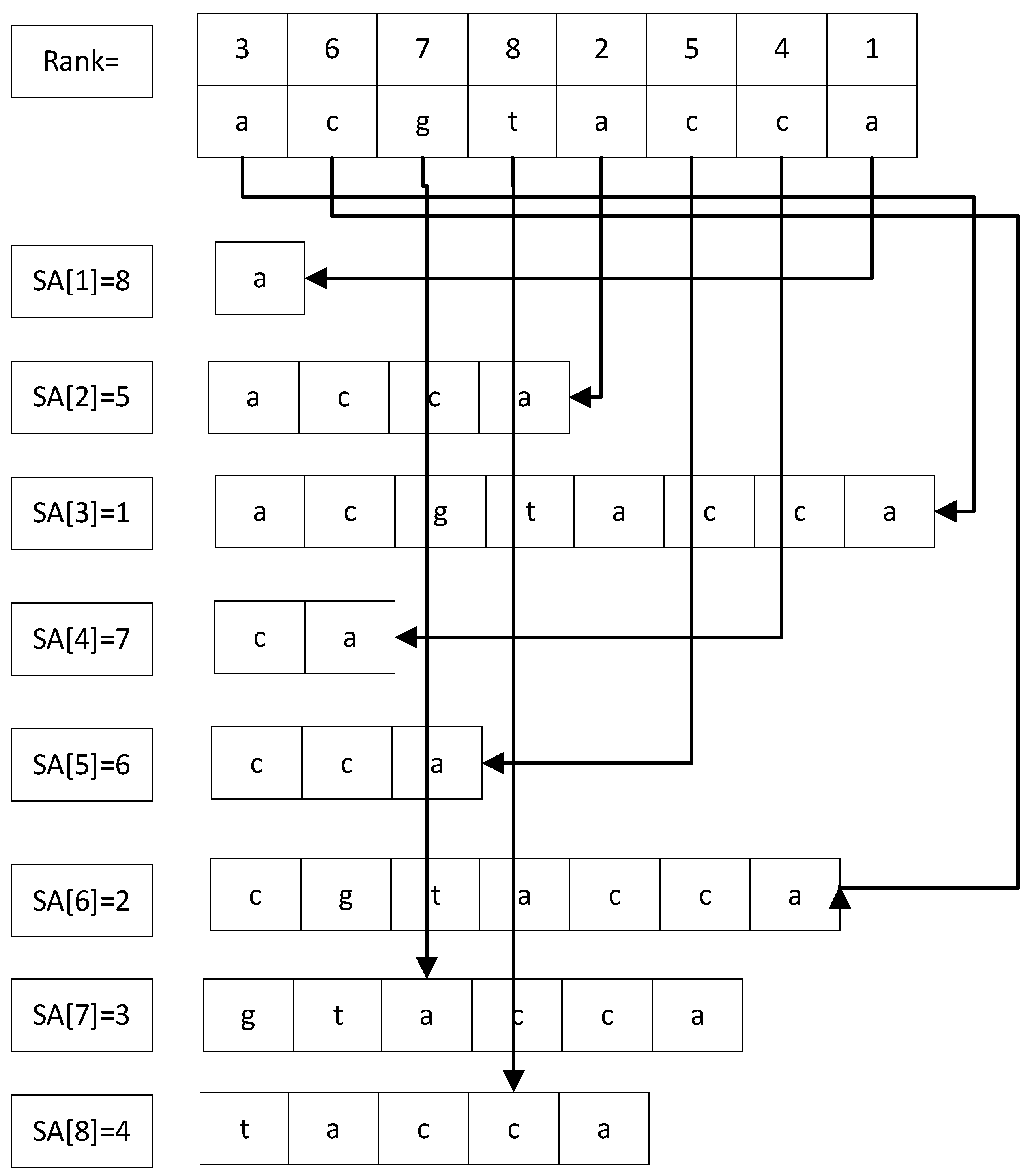
The
SA array and the
RK array have a reciprocal relationship, that is,
, as shown in
Figure 3. The time complexity of suffix array-based matching is relatively low, and can be roughly divided into three categories: multiplication algorithm, induced copy algorithm and divide and conquer recursive algorithm. The average time complexity of the multiplication algorithm is
, but the space overhead is large, and the order of prefixes needs to be stored. The induced copy algorithm first sorts the selected suffixes according to certain rules, and then induces sorting of all suffixes through the sorted suffixes. The disadvantage is that the time complexity of the algorithm is unstable, which is related to the selected suffixes. The divide-and-conquer recursive algorithm first selects a part of the subsequences, arranges them linearly, then renames the shortened pattern sequence to obtain a new pattern sequence, and then recursively arranges the new shortened pattern sequence until the selected subsequences are arranged. Finally, the unselected subsequences are sorted according to the selected subsequences to generate a suffix array. In this paper, the SA-IS algorithm is used to generate the suffix array.
The idea of the SA-IS algorithm [
31] is as follows: firstly, mark the L/S suffixes, then sort the LMS subsequences according to the properties of the L/S suffixes, and then induce the sorting of the L suffixes by the LMS subsequences. The S suffix is then induced to sort, and finally the suffix array
SA is generated. The overall algorithm flow is shown in Algorithm 1.
| Algorithm 1 SA-IS algorithm |
Input: Trav: original pattern sequence
Output: : suffix array of pattern sequences
- 1:
Scan Trav from right to left to get the array u, which records the type of each suffix. - 2:
Scan the array u to get all the LMS subsequences. - 3:
Induce sorting SA on the LMS subsequence obtained in (2). - 4:
Rename each LMS subsequence to generate a new pattern sequence. - 5:
if has no repeating moels then - 6:
Calculation - 7:
else - 8:
- 9:
end if - 10:
Use to induce sorting, - 11:
return
|
First, you need to obtain the sorted LMS suffix. LMS suffixes can be sorted directly using traditional radix sorting, and the time complexity is also . However, it is difficult to implement radix sorting for pattern sequences, and the constant term in the time complexity is large. The radix sorting will become the performance bottleneck of the entire algorithm. Induced sorting can be used to achieve the sorting of LMS suffixes. The specific process is as follows.
(1) Request an empty pseudo-suffix array of length n.
(2) Determine the starting position of the S-barrel in each barrel. Put the first pattern of each LMS subsequence into the corresponding bucket according to the sequence in the sequence.
(3) Determine the starting position of the L-barrel in each barrel. Traverse from front to back. When traversing to , if is L model, then is put into the L bucket corresponding to the .
(4) Re-determine the starting position of the S-barrel in each barrel. Traverse from back to front. When traversing to , if is S model, then is put into the end of S bucket corresponding to the .
(5) It is assumed that the original LMS sequence can be written as in sequence, where m is the number of LMS subsequences. Assuming w is the number of different LMS subsequences, can be renamed for each LMS subsequence. The naming rules are sorted lexicographically from low to high, so that when , , when , , a new pattern sequence is generated. The lexicographical relationship of suffixes in is the lexicographical relationship of LMS suffixes in .
(6) If the same pattern exists in , the induction operation is performed recursively until there is no same pattern in the newly generated pattern sequence. Swap the name of the LMS subsequence with its current position in to generate .
After obtaining the suffix array of the LMS subsequence, L suffix and S suffix are induced successively through . The specific process is as follows:
(1) Request an empty suffix array of length n.
(2) Determine the starting position of the S-barrel in each barrel. The number of L suffixes and S suffixes and the number of each pattern can be obtained when the suffix types are counted in Algorithm 1. According to the characteristics of the suffix array, can directly obtain the sorting of the original LMS suffix. Put all the LMS suffix numbers in the S bucket of the corresponding mode, and the relative order remains unchanged.
(3) Determine the starting position of the L-barrel in each barrel. Traverse SA from front to back. When traversing to , if is L model, then is put into L bucket corresponding to the .
(4) Re-determine the starting position of the S-barrels in each barrel. SA is traversed from back to front to ensure that each LMS suffix is properly ordered. When traversing to , if is S model, then is put into the end of S bucket corresponding to the .
So far, the linear time sorting and the naming calculation
are completed first, and then the sorted
induces the production of a complete suffix array
, the process of the
algorithm ends. In the subsequent identification process, a matching operation is required, and the following intermediate variables as shown in
Table 2 can be recorded when running the
algorithm to improve the matching efficiency.
Theorem 1. When the length of the pattern sequence is n, the time complexity of the algorithm is , and the space complexity is bits.
Proof. Each step of the
algorithm is computed in linear time. In the worst case, it is necessary to recursively solve the same problem up to half the original size, so the time complexity formula is
. That is, the
layers are recursively calculated, and the problem of each layer is sorted from small to large as
. The final time complexity is calculated by Equation (
2) and the result is
.
The space complexity mainly depends on the space required to store the suffix array to simplify the problem at each recursion. In the first calculation, it consumes at most
bits of storage space, and each recursion will reduce at least half of the storage space. The space complexity is calculated by Equation (
3), and the final complexity is
. The proof is over.
The device fingerprint collection process is as follows: first, the device traffic is collected, then abstracted into a pattern sequence, and finally the algorithm is used to generate the suffix array and intermediate variables and store them in the device fingerprint database. Then, the location device can be identified using the fingerprint database. □
3.2. Exact Matching to Identify Unknown Devices
After building the device fingerprint database, the device identification can be completed. After collecting the traffic data of the unknown device, first it is abstracted into an unknown pattern sequence Trav according to the Formula (
1), and then it is slidably divided into multiple subsequences
. The subsequences are matched with all fingerprint sequences in the fingerprint database, and the device with the highest matching degree is the identification result. The first step of matching is exact matching, that is, the subsequence is required to be a successful match only if it completely matches the device fingerprint sequence. The exact matching base adopts the FM index sequence matching algorithm, and the overall algorithm flow is shown in Algorithm 2.
| Algorithm 2 FM index matching algorithm |
Input: Sorted suffix first pattern sequence.
Sorted fuffix preceding pattern series. The starting position of the pattern in the f sequence. pattern sequence to be queried. The number of occurrences of the pattern in the f sequence. The correspondence between the f sequence and the l sequence elements.
Output: Record the position where the query pattern sequence appears in the original pattern sequence.
- 1:
Calculate the position where the character c at the end of the pattern sequence appears in the sequence f using the count array and the position array. - 2:
Determine whether the element at the position of in the l sequence is equal to the previous element of c, If it is not equal, it will be discarded, and if it is equal, it will be recorded in . - 3:
Reverse mapping to the f sequence via l2f produces a new position array , and updates c to its previous character. - 4:
Execute step (2), if the number of elements of is 0, it means that there is no strict match, and the calculation is terminated. - 5:
When the pattern sequence traversal is completed, the final sequence is obtained. - 6:
Map to the position array match where the pattern sequence appears in the original pattern sequence through the suffix array .
|
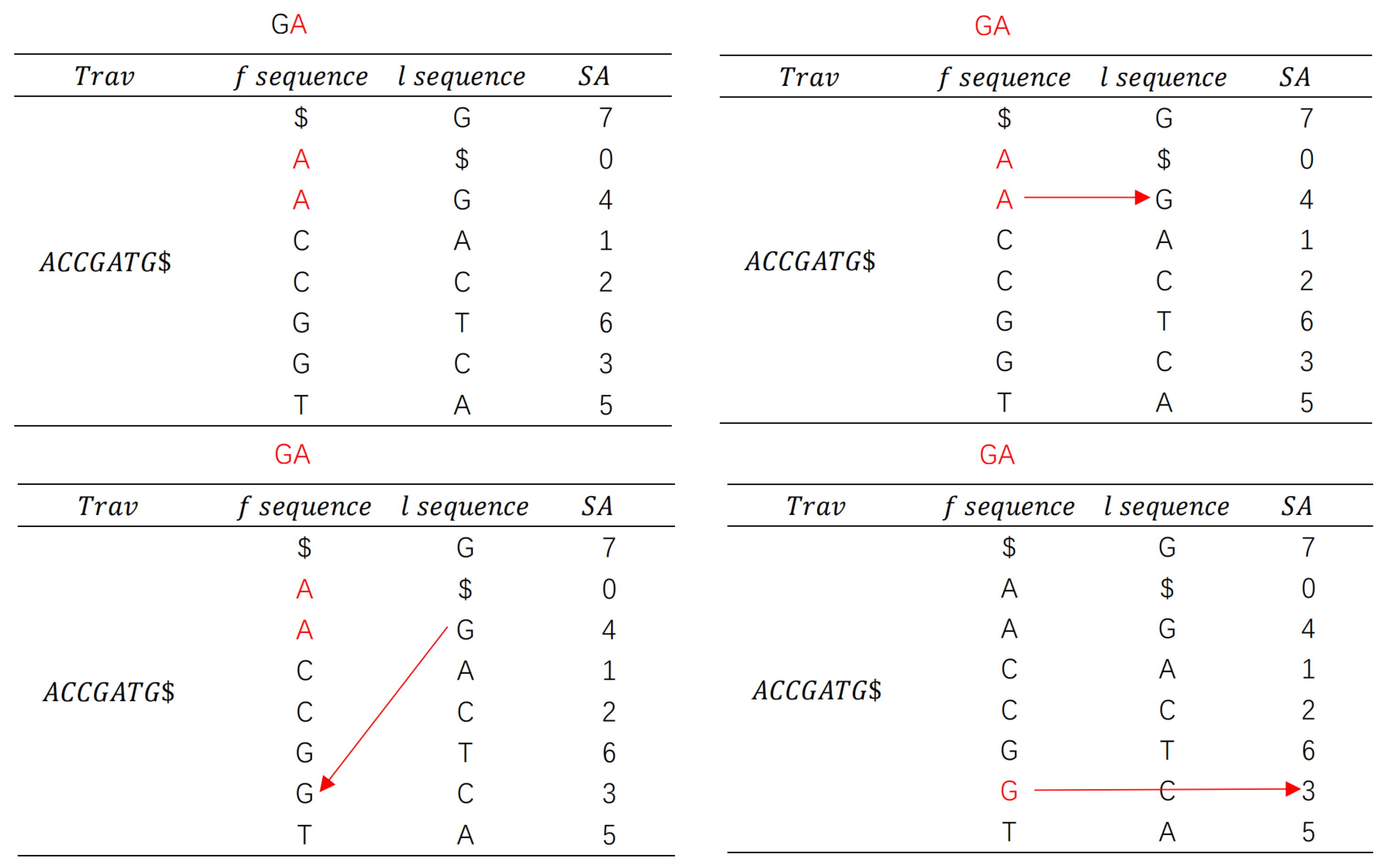
For the original pattern sequence
, the query sequence pattern = GA. The matching process is shown in
Figure 4.
After obtaining the position match of the query sequence pattern in the original pattern sequence
, the matching score with the fingerprint sequence will be calculated by Equation (
4), and the fingerprint sequence with the highest matching score will be determined as the final recognition result.
represents the total length of the fingerprint sequence. indicated the number of consecutive repetitions of each matching pattern in the query subsequence. indicates the number of repetitions of the matching pattern in the fingerprint sequence. indicates the length of each subsequence of the query sequence. Finally, the evaluation scores of all subsequences are accumulated to caluculate the evaluation score of the query sequence.
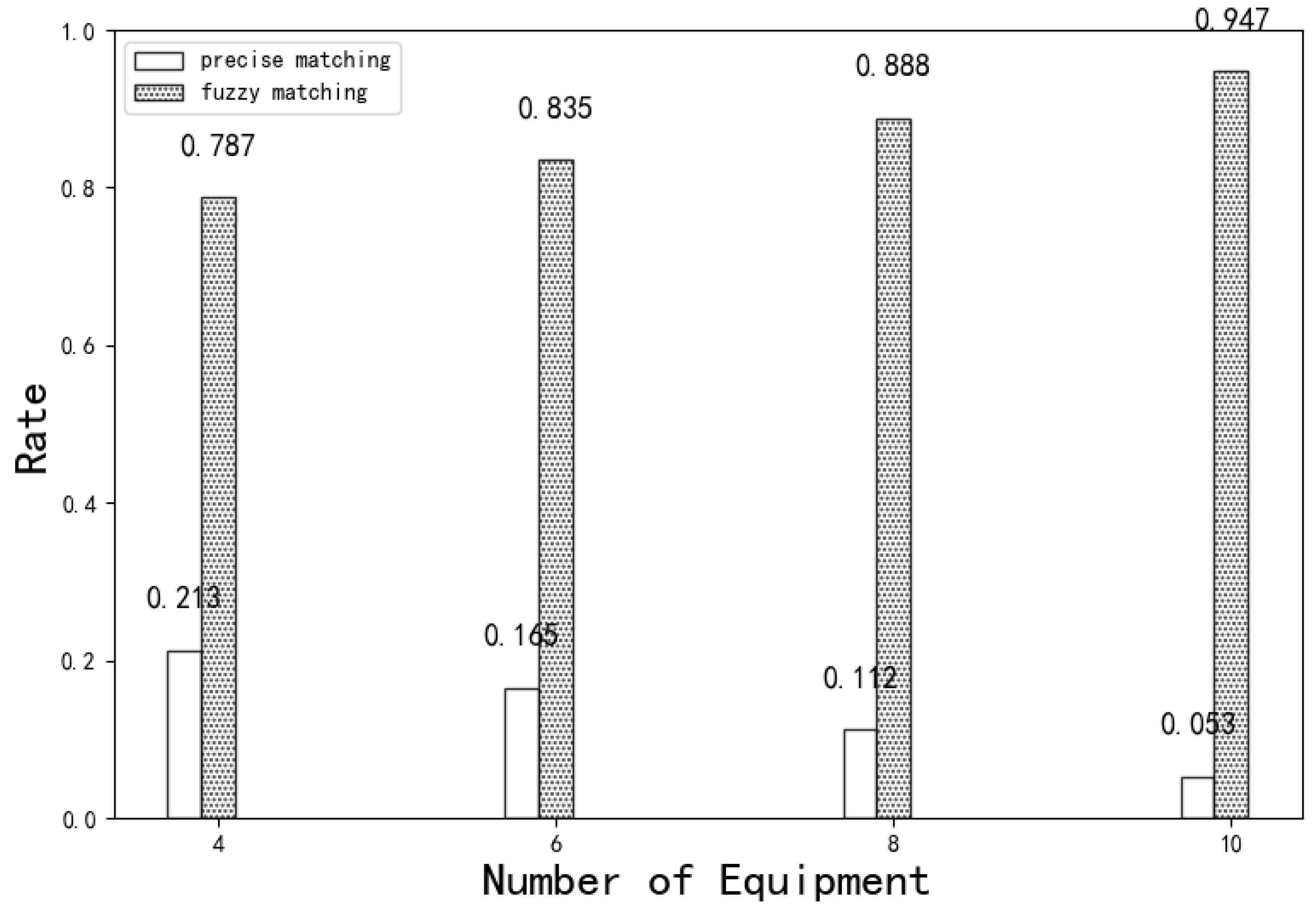
Match the query sequence with the fingerprints in the fingerprint database one by one, and the device with the highest matching score is the final identification result. However, relying only on exact matching is not ideal in many cases, because there is a lot of noise in the industrial control system, filled with a large number of redundant data packets with an indeterminate number, and the content or type of data packets in different periods are not the same. Periods are not stable. The conditions for exact matching are strict, and all fingerprint matching scores may be 0, resulting in the device not being recognized. In order to solve the problem, this chapter adopts fuzzy matching to identify the device in the case that exact matching cannot be identified.
3.3. Fuzzy Matching to Identify Unknown Devices
Because the exact matching conditions are strict, the query sequence may not match any device fingerprint, so fuzzy pattern matching will be used for the final device identification. For device fingerprint Finger, query pattern sequence q, and allowable error threshold
, fuzzy pattern matching is to find all subsequences
satisfying
≤
, where
sim is Similarity function, where 1 ≤
i,
j ≤
n,
is the original sequence corresponding to the device fingerprint. The process of fuzzy matching is shown in the
Figure 5. The sequence is first preprocessed to shard it into multi-segment subsequences, and then the multi-segment subsequences are accurately matched, and the error values between the matching sequence and the original sequence are counted. If the error value is higher than a certain threshold, it is directly judged that the matching failed, otherwise its matching score is calculated for the judgment of the final device. This section, we will first outline the overall process of fuzzy matching, then optimize the two processes of fragmentation and computing errors, and finally describe how to calculate the matching score of fuzzy matching.
If the query sequence q is divided into
+ 1 slices, because the error threshold is an integer, it is impossible for all
+ 1 slice sequences to have errors, and at least one slice sequence is an exact match. First, the query pattern sequence q is evenly divided into
+ 1 slices, and then all subsequences of the slice sequence that exactly match in the fingerprint sequence are found. For this work, please refer to
Section 3.2. Considering a sharding sequence
of the query sequence q, the sharding divides the query sequence q into three parts
,
, and
. The sequence can also be divided into three parts,
,
, and
, which can be verified by checking the left and right subsequences, respectively.
and
represent the longest left and right extensions, respectively. First, Equation (
5) is used to calculate the similarity between all suffixes of the longest extension on the left
and
.
Then, Equation (
6) is used to calculate the similarity between all suffixes of the longest extension on the right
and
.
If there is an approximate sequence of the sequence q, then there must be . The time complexity of verification on the left and right is .
3.3.1. Sequence Sharding
The sequence fragmentation is involved in fuzzy pattern matching, and different fragmentation methods will also affect the performance of the algorithm. The most common sharding method is uniform sharding, the specific process is: first determine the length of each subsequence according to the total length of the sequence and the number of shards, and then cut evenly according to the length from the beginning of the sequence, so that the length of each subsequence is as consistent as possible. The advantage of this method is that it is fast, but there are certain shortcomings in slicing accuracy. For the query pattern sequence , if the uniform sharding strategy is adopted, it will be divided into three shard sequences of . For , shard iss has two exact matching subsequences on Trav, shard pp has one exact matching subsequence on Trav, and shard aa has no exact matching subsequence on Trav, all of which need to be verified. However, if it is divided into , there is only one fragment sequence pp that exactly matches, and only needs to be verified once.
Definition 1. Optimal k division: Given a fingerprint sequence , a query sequence q and division number k, the optimal division of q is , which satisfies Equation (7). represents all sharding strategies that divide q into k shards. represents the set of all k shards of the sharding strategy P. represents the number of shard p appearing in , that is, the weight of shard p. Enumerating all sharding schemes can find the optimal solution, but there are
strategies for dividing the query sequence
q into
slices, which is extremely inefficient. It will be better to directly divide
q evenly. By observing the division strategy, it can be found that if
is the optimal
division of
q, then
must be the optimal
partition of
, where
. Therefore, a dynamic programming algorithm can be used to solve the optimal partition of q. In this paper,
is used to represent the minimum weight for dividing
into i shards.
represents the optimal solution for dividing the sequence
q into
slices, that is, the result.
is initialized and updated with Equations (
8) and (
9).
can be calculated using the exact matching algorithm in
Section 3.2. The time complexity of calculating
is
, the time complexity of computing all subsequence weights of
q is
. This process has high time complexity and can be further optimized. After calculating the weight of
, only
time complexity is needed to calculate
. Therefore, the suffix weight of
can be calculated from right to left, and the time complexity of this process is
. At this time, the overall time complexity will be reduced to
, and the time complexity of solving
is
. In addition, an acceleration strategy can be adopted. If
and
have the same weight, then
does not need
to be updated. Because
, there is
,
cannot be used to obtain smaller weights. Therefore, judgment conditions can be added in the dynamic programming process. If there is a group of consecutive units of equal value, they can be stored in a skip chain, and the calculation of these units can be skipped at one time, thereby improving the efficiency of the algorithm.
Two sharding algorithms, the uniform sharding strategy and the optimal sharding strategy, have been discussed above. Fragmentation using both algorithms is divided into three processes. The first step is sharding, the second step is query, and the last step is verification. The time complexity is shown in the
Table 3.
From the above table, it can be calculated that the cost difference between the two sharding algorithms is . a and b are the unit costs of the sharding phase and the verification phase, respectively, and and represent the weights of the uniform sharding strategy and the optimal sharding strategy, . When the cost difference is less than 0, that is, , the optimal sharding strategy is better than the uniform distribution strategy. However, can only be calculated after determining the optimal sharding strategy. It is very inaccurate to determine which sharding strategy to choose by setting a threshold, and setting a fixed threshold in advance cannot adapt to the identification of different query sequences, which has poor flexibility.
This paper introduces a machine learning method to predict and select a segmentation strategy. After the device fingerprint is constructed in
Section 3.1, a large number of query sequences with different lengths will be randomly generated, and then the cost of the two sharding strategies will be compared and labeled. The uniform sharding strategy has a small cost and is marked as 0, otherwise it is marked as 1. The problem is transformed into a binary classification problem. Four features are collected in this chapter, namely the length of the query sequence
, the number of shards
, the weight of the uniform division method
, and the weight difference of adjacent shards
. The first two features are the basic information of the query sequence.
is the baseline value of overhead. measures the probability of changing sharding to reduce overhead. When the value is small, it will favor the uniform sharding strategy. The training model adopts the support vector machine model (SVM). The main idea is to find a hyperplane that accurately distinguishes different sample data, and to make the Euclidean distance from the point closest to the hyperplane to the hyperplane as large as possible. The radial basis function kernel function (RBF) is used in the model training process, and the penalty factor C and the RBF kernel function coefficient g are obtained by grid optimization method to obtain the optimal value. After the model training is completed, the sharding strategy can be predicted and selected to improve the overall efficiency of the recognition algorithm.
3.3.2. Similarity Function
The most widespread way to measure the similarity of two sequences is based on the Levenstein distance, also known as the edit distance. It can achieve fault-tolerant matching of two sequences at the character level, and is also the similarity measure used in this chapter. It represents changing from one sequence to another with a minimum number of operations, including insertion, replacement, and deletion of characters. Given two sequences
p and
q, the similarity function based on edit distance is
,
. When
in the two sequences, where
is the allowable error value above. The edit distance can be calculated by dynamic programming, as shown in Equations (
10)–(
13).
Initially, the cell values in the first row and first column of the edit distance matrix are directly obtained by Equations (
10) and (
11), while other cell values can be obtained iteratively by Equations (
12) and (
13). For any unit on the edit distance matrix composed of sequence p and sequence
q,
, so their edit distances satisfy
, the time complexity of calculating the edit distance between two sequences is
. In general, successful matches between sequences are rare. The above equation calculates the value of each column from top to bottom when updating the edit distance matrix. A cell value will soon be greater than
, where the surface is already mismatched. If the value of a cell is greater than
, the search results will not depend on this cell.
Based on the above conclusions, the algorithm can be further optimized. If the value of a cell in the edit distance matrix is less than or equal to , the cell is called the active cell. When updating the edit distance matrix, it only needs to calculate the last active cell of each column and stop, and the value of its cells below will not be updated. In the process of device recognition, most of the recognition sequences and pattern sequences have a low degree of matching, and the number of updated active units is small, which can improve the recognition efficiency. The reason why this optimization algorithm is established is that the cost of insertion, deletion and replacement operations are all 1, so the difference between adjacent elements in the edit distance matrix is at most 1. This also limits the scalability of the recognition algorithm. In fact, various noises such as redundancy, disorder, and presence of noise in data traffic have different effects on device identification. Simply setting all operation overheads to 1 will reduce the accuracy of identification. In this paper, the generalized edit distance is used to improve the scalability and accuracy of the algorithm, that is, the cost of each operation is not the same, and the specific value is determined by the protocol and function.
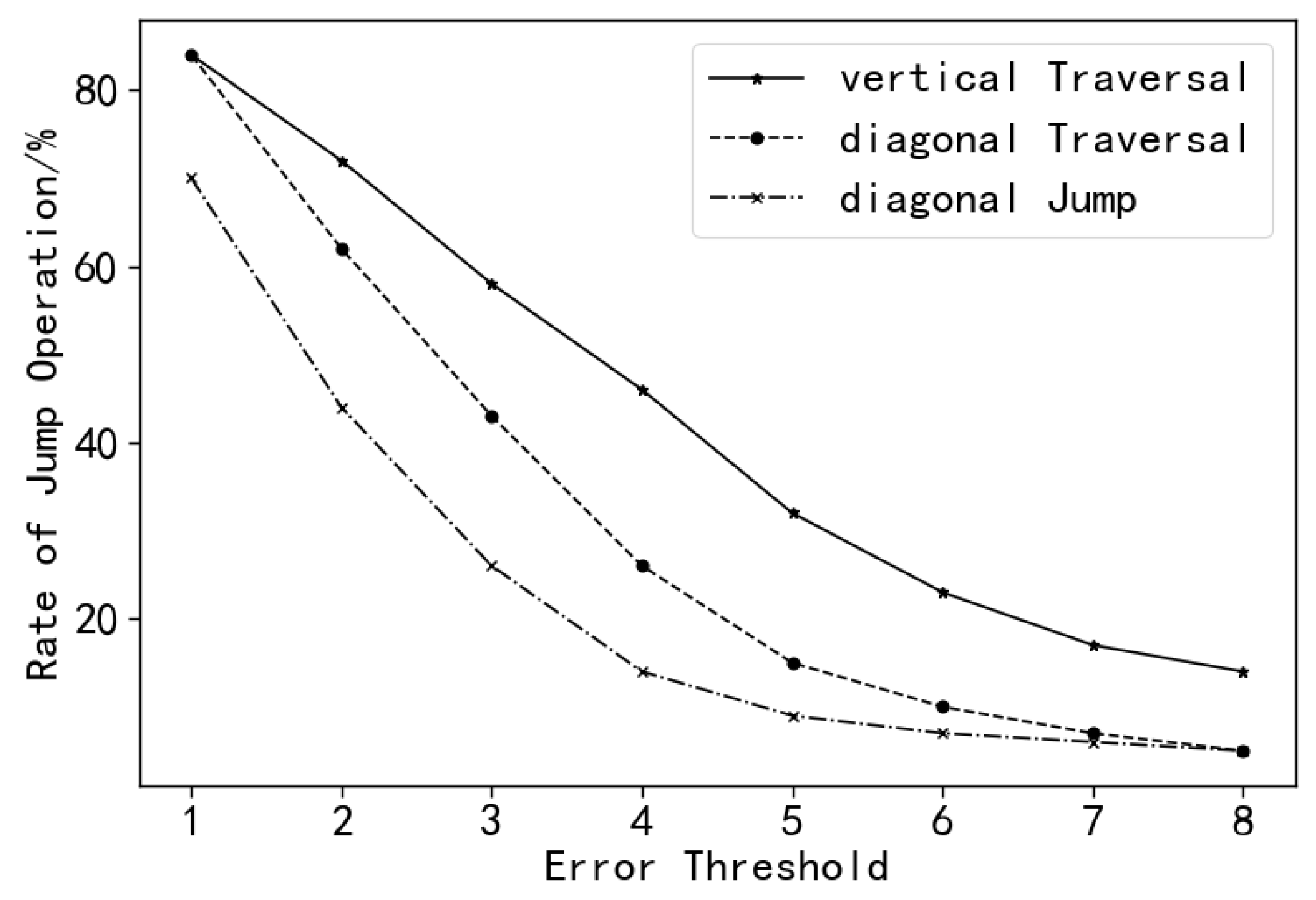
Although the generalized edit distance can improve the correctness and scalability of the algorithm, it cannot be optimized in time, because the cost of each operation is not a fixed value, and the difference between adjacent unit values cannot be determined. The edit distance matrix needs to be completely updated each time to match with the device, which will waste a lot of time on meaningless calculations. In order to solve this problem, this paper proposes a diagonal jump algorithm for optimization.
3.3.3. Diagonal Jump Algorithm
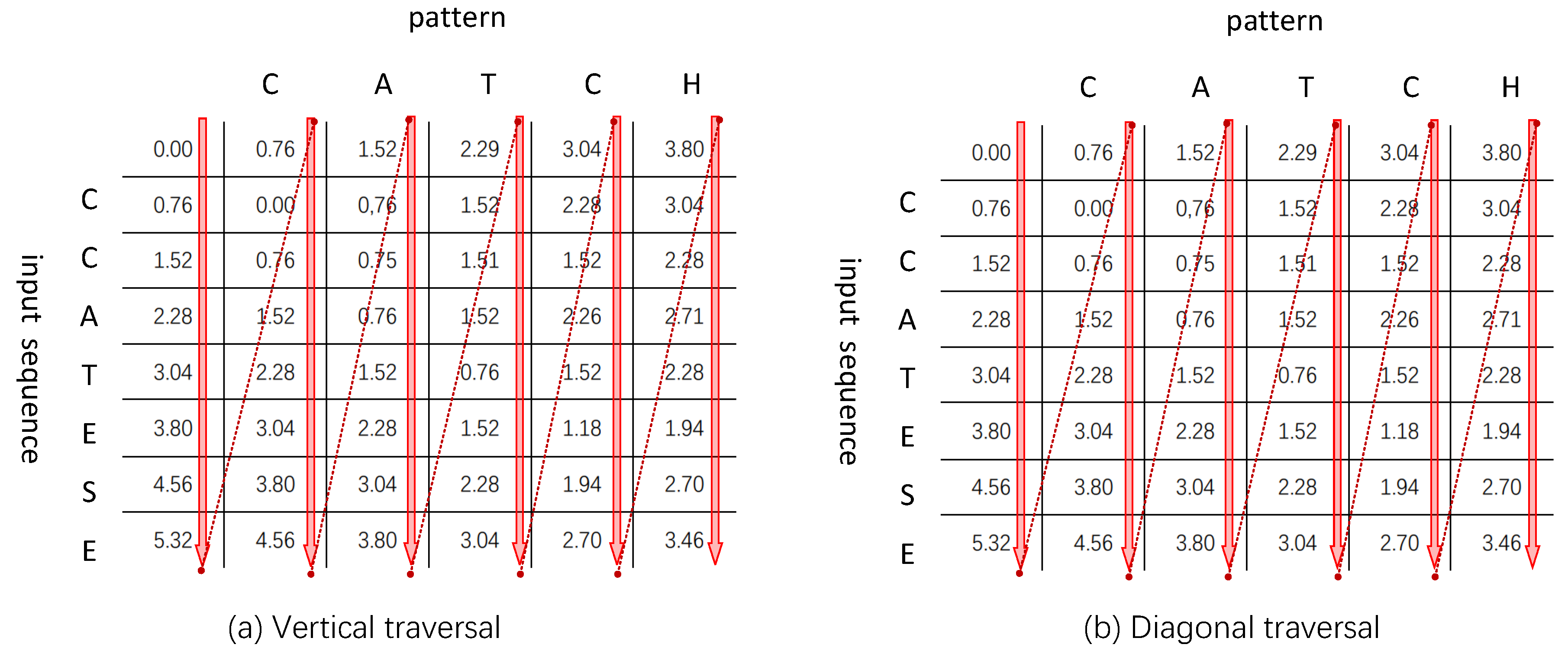
In this paper, the diagonal jump algorithm is adopted to avoid unnecessary cell value calculation. Different from the vertical traversal shown in
Figure 6a, the edit distance matrix is updated using the diagonal traversal shown in
Figure 6b.
Figure 6 shows the process of a diagonal traversal, where the arrows illustrate the order of steps computed in each traversal. In a diagonal traversal, the upper right cell value is computed before the lower left cell value. If
is used to represent the value of a diagonal line, then
needs to be updated by
and
, and there is no dependency on the unit value inside
. When
and
are updated, the calculation of unnecessary unit values can be skipped when calculating
. Jump bitmaps are employed, avoiding multiple iterations during the loop without accessing all elements in the edit distance matrix. Each bit in the skip bitmap is assigned to a column of the edit distance matrix. When the trim bit of the column is set to “1”, the cell value of the column does not need to be updated in subsequent calculations. The specific steps are shown in Algorithm 3.
| Algorithm 3 Diagonal jump algorithm |
Input: Sequence to be queried.
Original pattern sequence. Edit distance unit value. Jump bitmap. Maximum allowed error threshold.
Output: Edit distance matrix.
- 1:
Initialize (D[i][0],D[0][j], ). - 2:
for each do - 3:
for each step(,)2 do - 4:
if () == 1 then - 5:
Break - 6:
end if - 7:
if () == 0 then - 8:
D[,]=costmin(D[][],D[][],D[][]) - 9:
else - 10:
D[][]=costmin(D[][],D[][]) - 11:
end if - 12:
if D[][]>k and () == 1 then - 13:
() = 1 - 14:
end if - 15:
end for - 16:
end for - 17:
return D
|
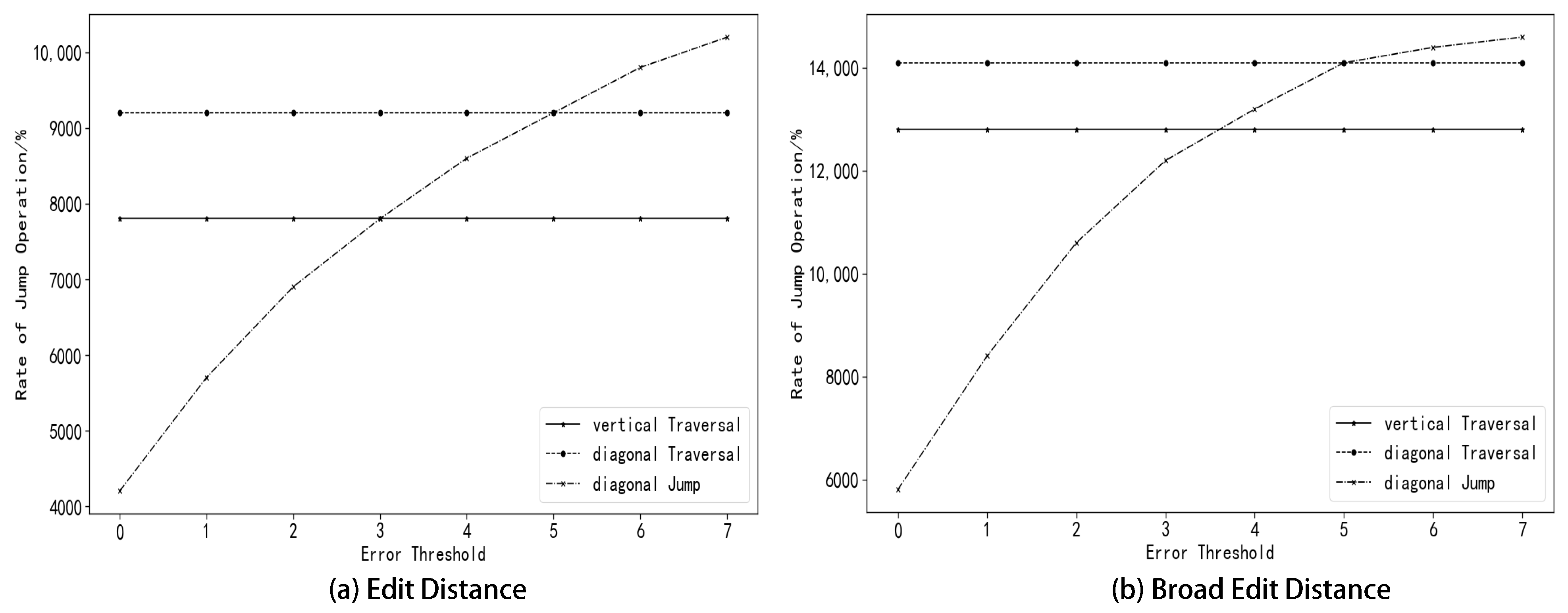
The number of diagonal traversals is proportional to the pattern sequence length
j, so the time complexity is
.
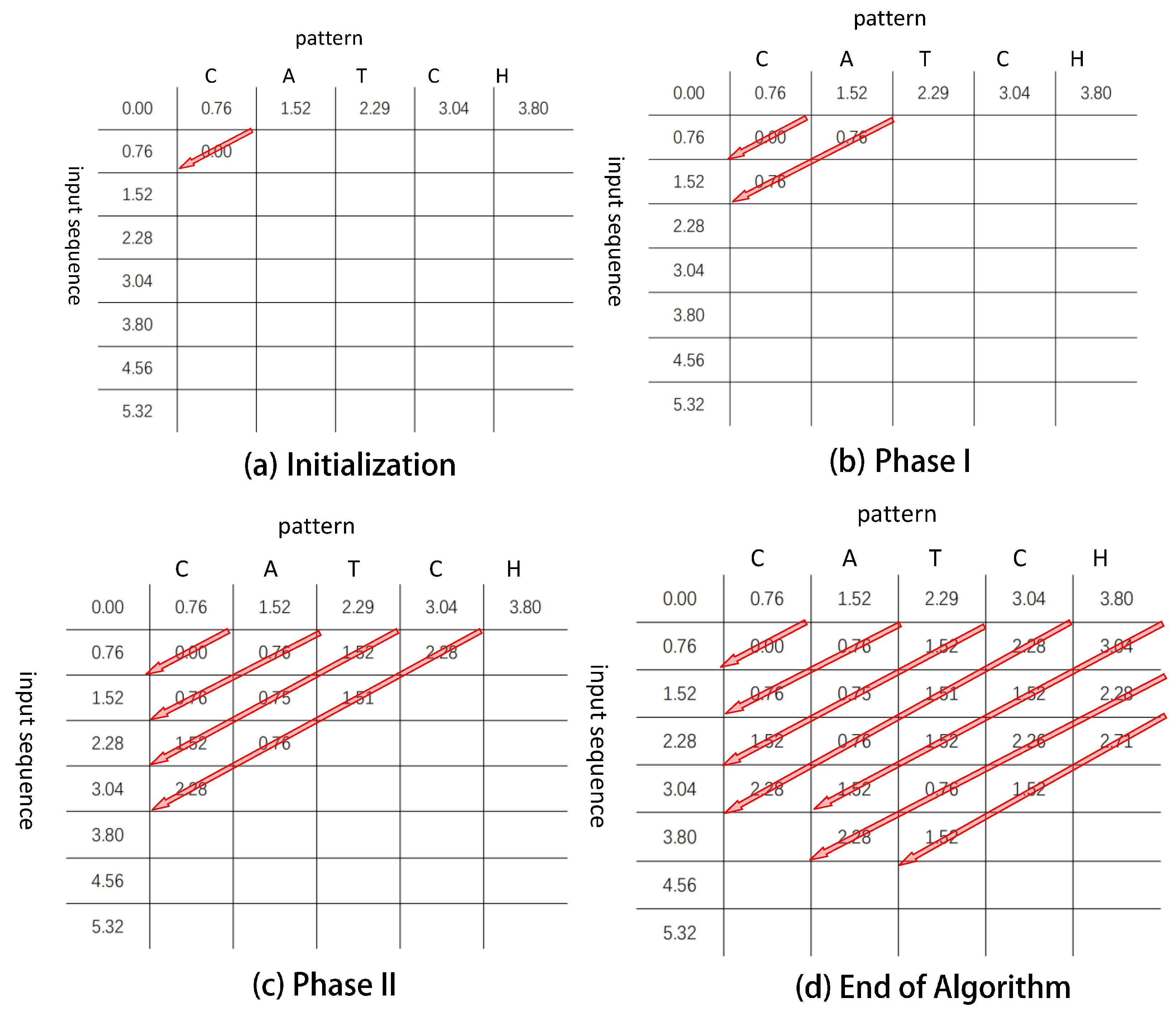
Figure 7 depicts the matrix update operation of the original sequence “ccatese” and the query sequence “catch”, with a threshold
of 2. First, initialize the bit of the leftmost column in the skip bitmap to “1” and initialize
and
, as shown in
Figure 7a. When the fourth diagonal is updated, the cell value of the second column exceeds 2, as shown in
Figure 7c. When traversing the fifth diagonal, since
= 1,
and
will be used to update
, where the insert operation is skipped.
Figure 7d shows the updated result of the final edit distance matrix. The diagonal skipping method proposed in this paper only needs to access the skip bitmap to determine which steps to skip without relying on previously updated data. In addition, the algorithm can skip the computation of multiple cell values and operations, thereby reducing the time of updating the edit distance matrix.
Through the above algorithm, the approximate matching position of the query sequence in the fingerprint sequence can be found, and then the matching score with the fingerprint sequence can be calculated according to Equation (
14). The device with the highest matching score in the device fingerprint database is the identification result.
Among them, match represents the position where the query sequence approximately matches the fingerprint sequence. represents the similarity between the longest extension on the left and the left side of the shard at the ith matching position. represents the similarity between the longest extension on the right and the right side of the shard at the ith matching position.
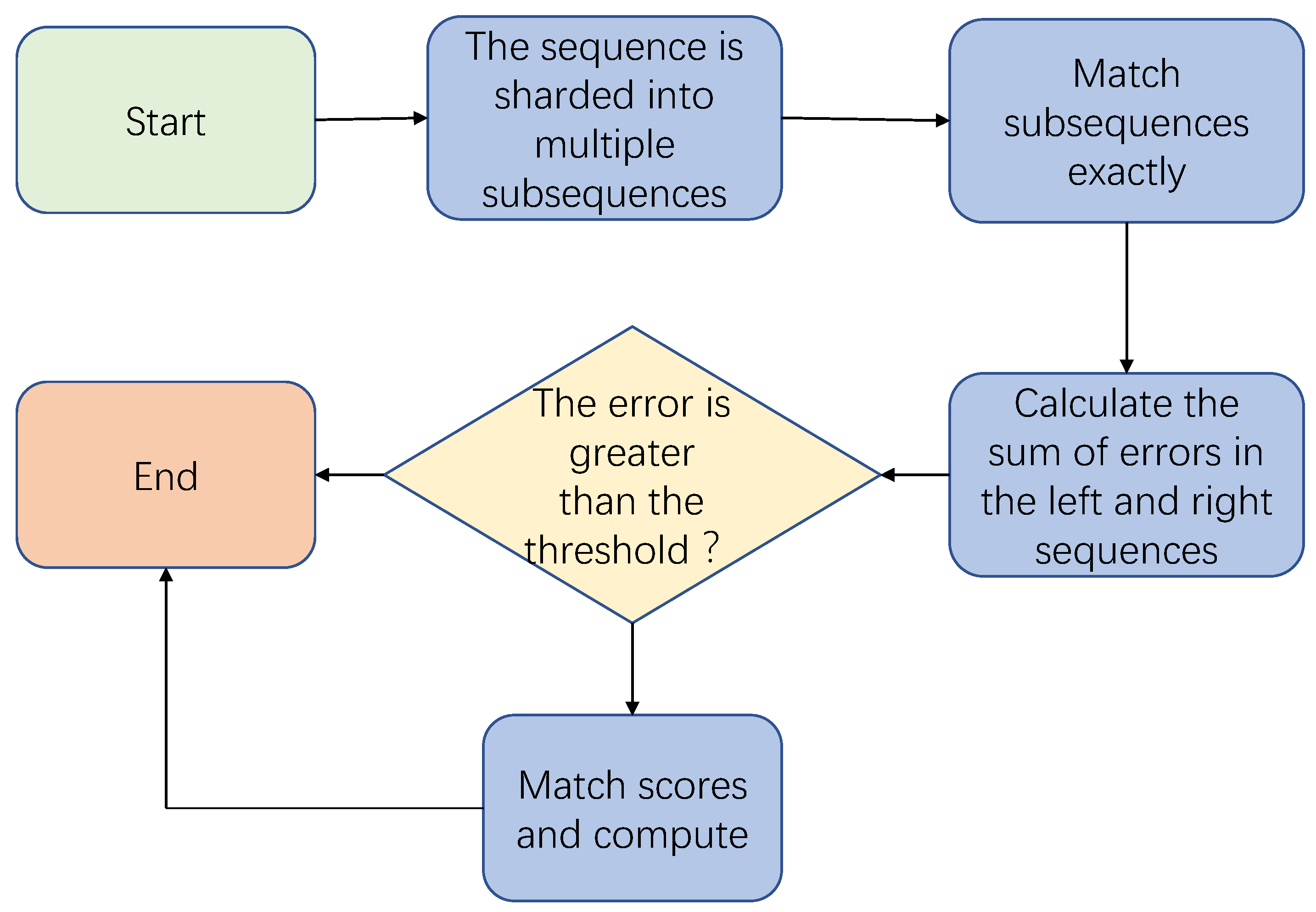
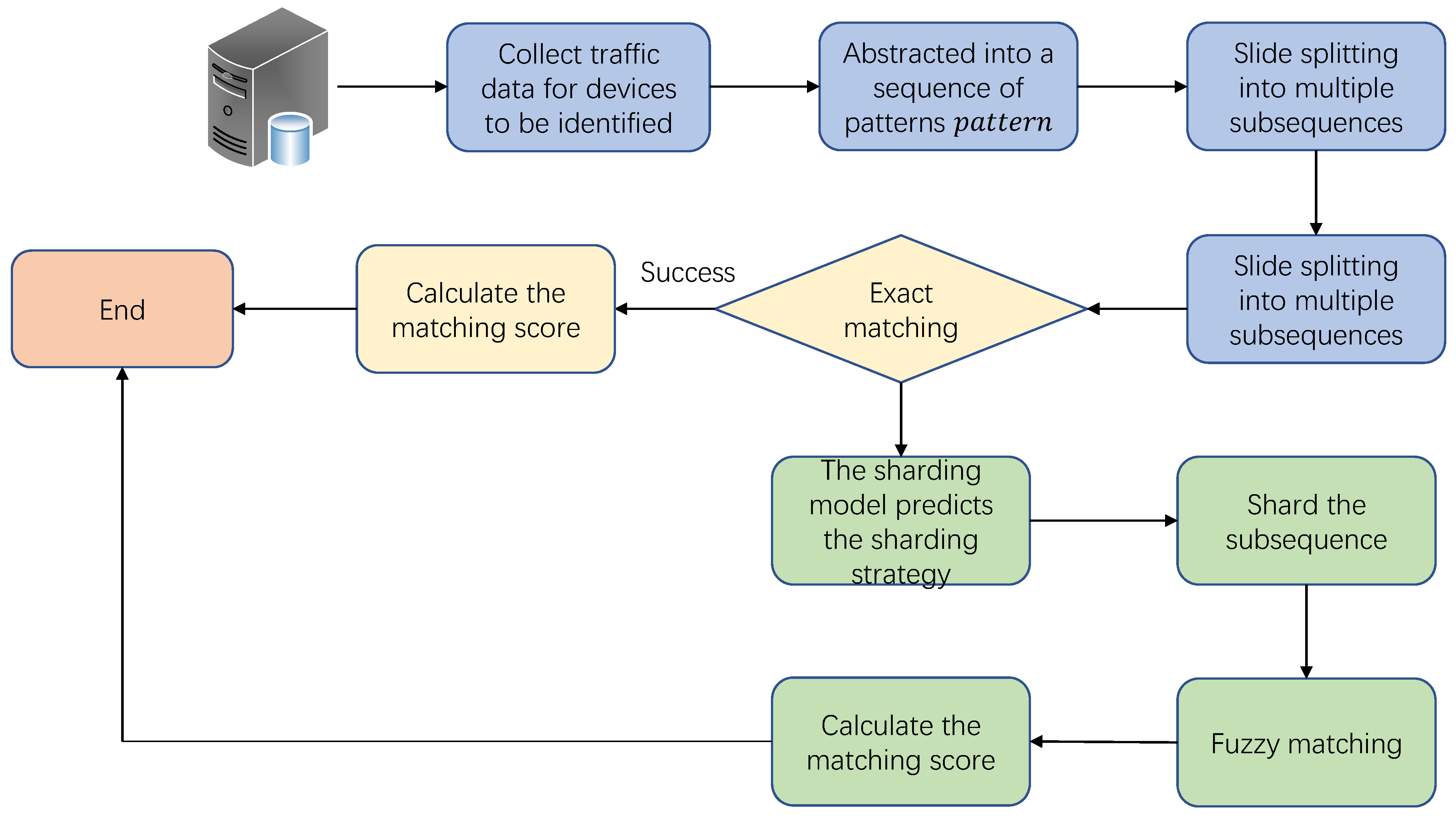
The device identification in this paper is based on a pattern matching algorithm, and the flow chart is shown in
Figure 8. First try to use exact matching for the fingerprints in the device fingerprint database, but there is noise in the industrial control system, so the exact match often fails. In response to this situation, this paper uses the fuzzy pattern matching algorithm to further evaluate the matching degree, and the device with the highest matching degree is the recognition result.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}