


SubvectorS_Geo: A Neural-Network-Based IPv6 Geolocation Algorithm

 , , and
, , and
Abstract
:1. Introduction
- We propose a new IPv6 geolocation algorithm, which solves the problem of the low accuracy of existing geolocation and the lack of reasonable and effective constraints on regional delay similarity.
- We apply residual paths (measured paths in trusted regions) to IPv6 geolocation models, and residual path features have a strong geographic correlation with the target IP. A region constraint strategy is added based on IPv6 prefix similarity to improve the fine-grained trusted region constraint scheme, and IPv6 prefix similarity has a high geographic correlation. To the best of our knowledge, we are the first to introduce residual paths and IPv6 prefix similarity in the IPv6 geolocation domain.
- The final experimental results of our method show that our method outperforms current IPv6 geolocation algorithms in IPv6 geolocation tasks under noncollaborative conditions.
2. Related Work
2.1. IP Geolocation Algorithm
2.2. Analysis of Existing Advanced IP Geolocation Algorithms
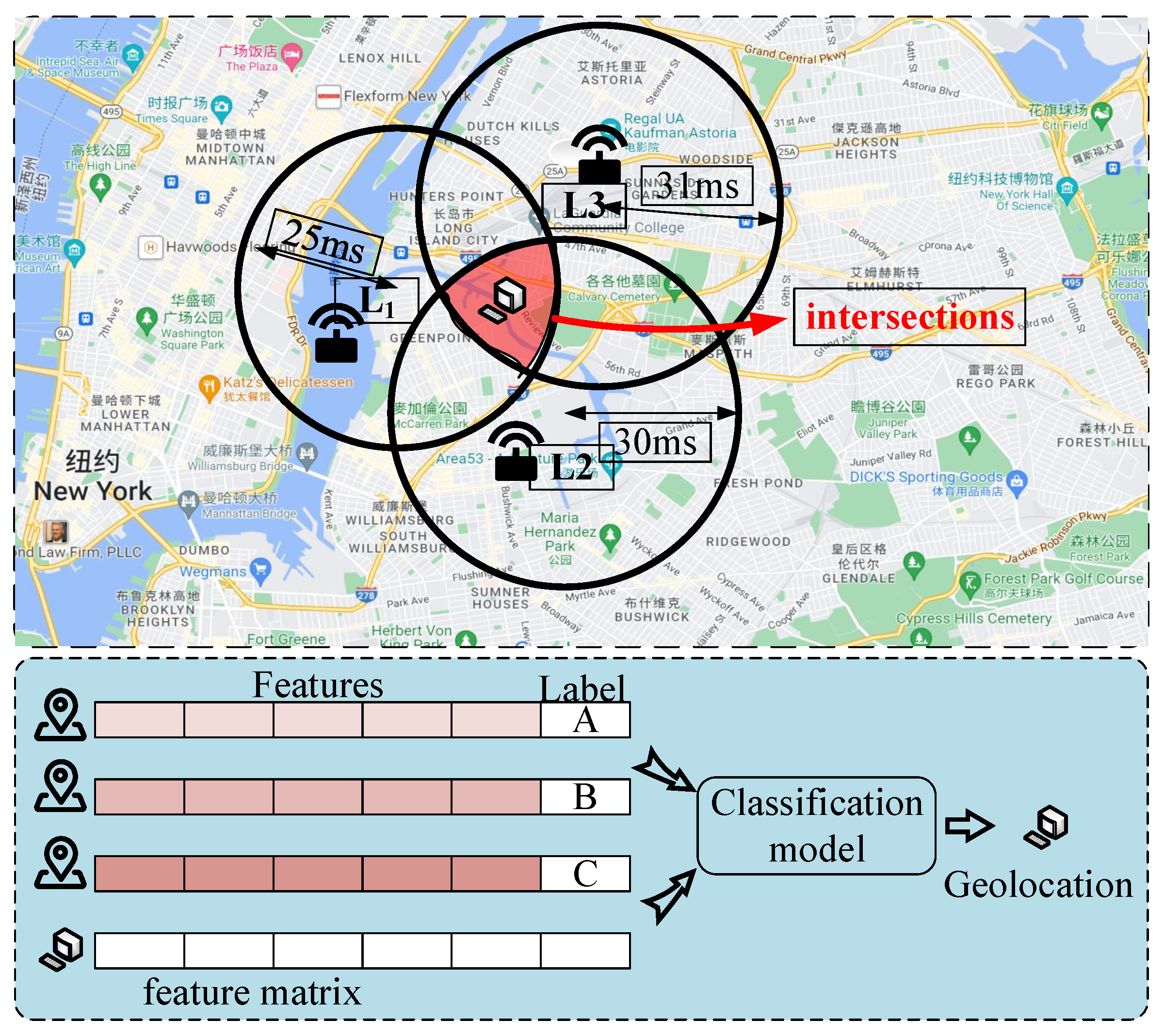
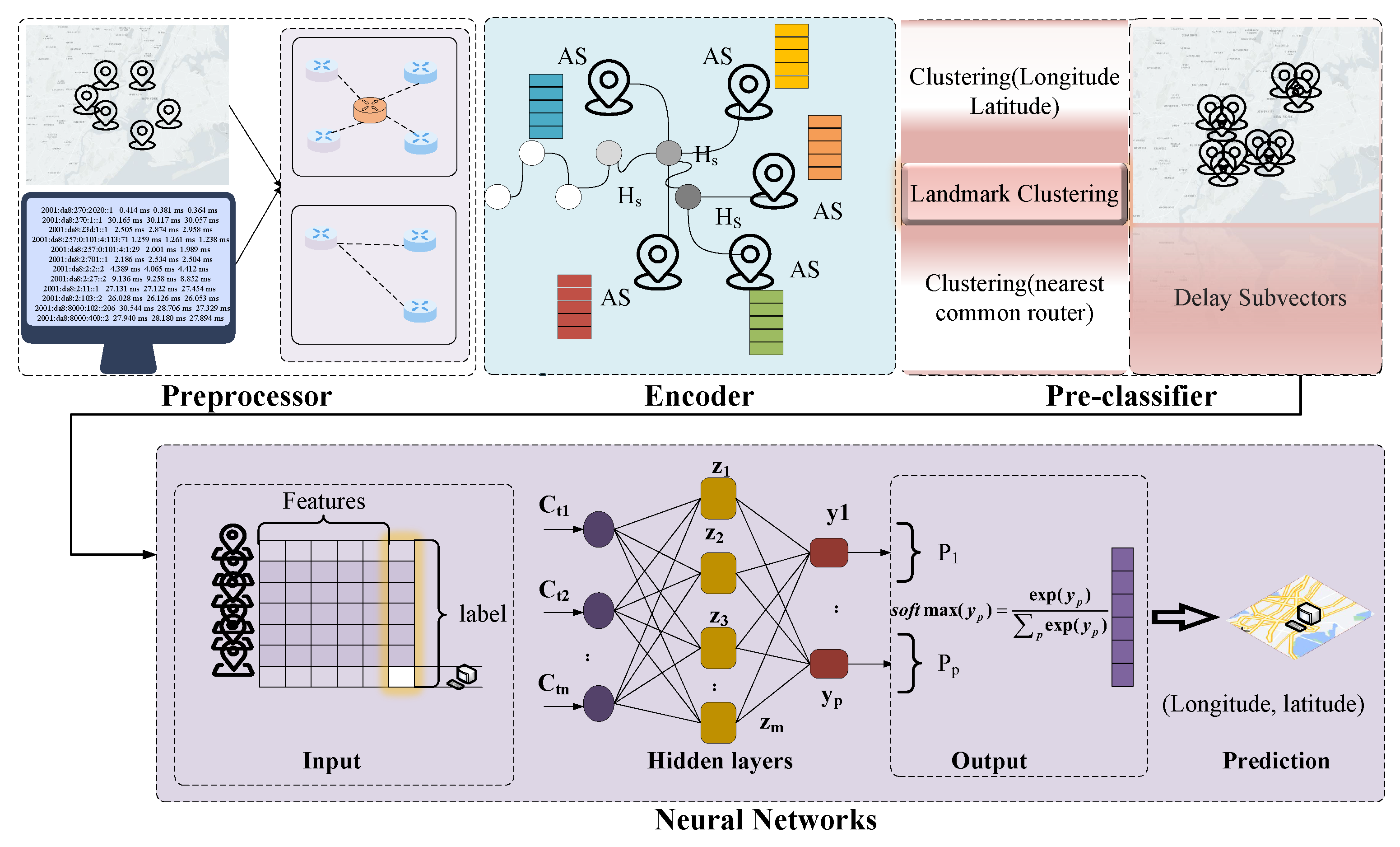
3. The SubvectorS_Geo Algorithm
3.1. Algorithm Overview
3.2. Preprocessor
3.3. Encoder
3.3.1. Dataset Construction
3.3.2. Closest Common Router Set
3.3.3. Path Encoding
3.4. Pre-Classifier
| Algorithm 1 SubvectorS |
Input: Landmark paths and delay vectors Output: Training set 1: 2: for (int i = 0; i < n; i++) do 3: for (int k = 0; k < j; k++) do 4: 5: 6: 7: end for 8: end for 9: return |
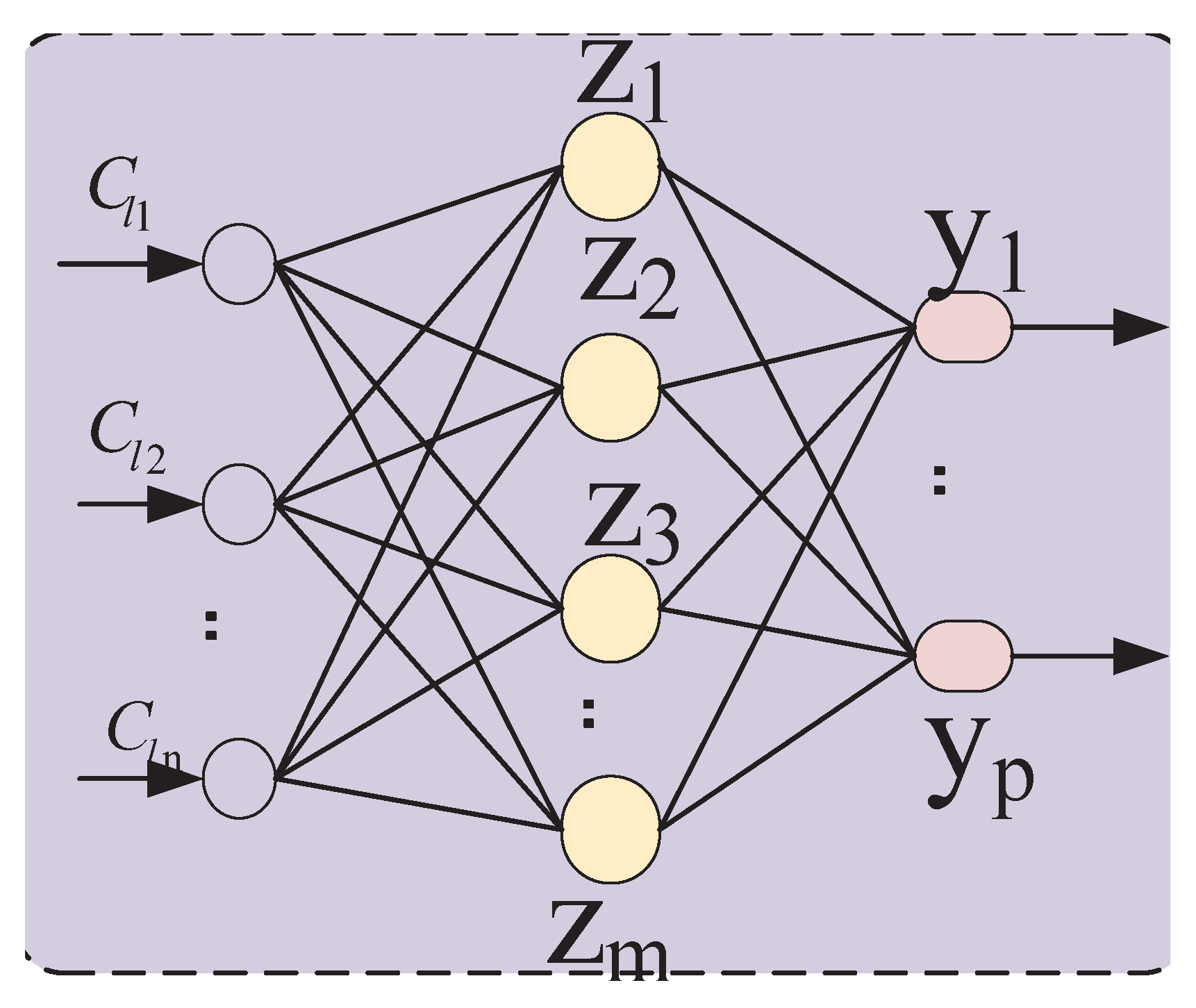
3.5. Neural Network
3.5.1. Model Training
3.5.2. Network Entity Geolocation
| Algorithm 2 SubvectorS_Geo |
Input: Target IP path and delay vector Output: Target IP (longitude, latitude) 1: 2: 3: if 4: return geolocation success, The target IP geographic location is (longitude, latitude) 5: else 6: return geolocation failure |
4. Experimental Results and Discussion
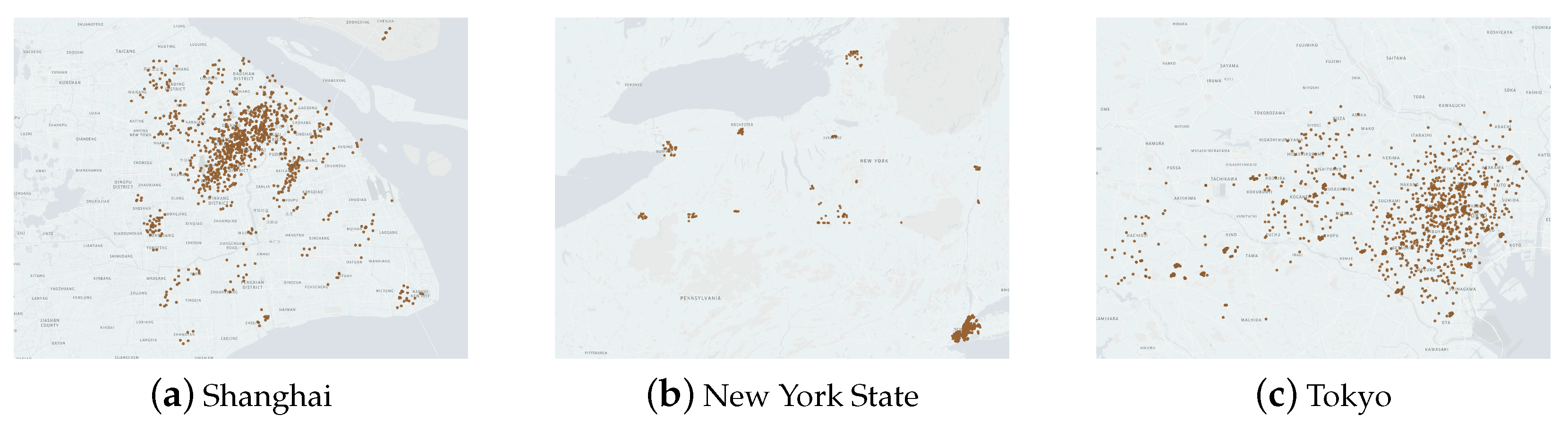
4.1. Dataset
4.2. Model Parameter Settings
4.3. Geolocation Experiment Result
4.4. Comparison and Verification
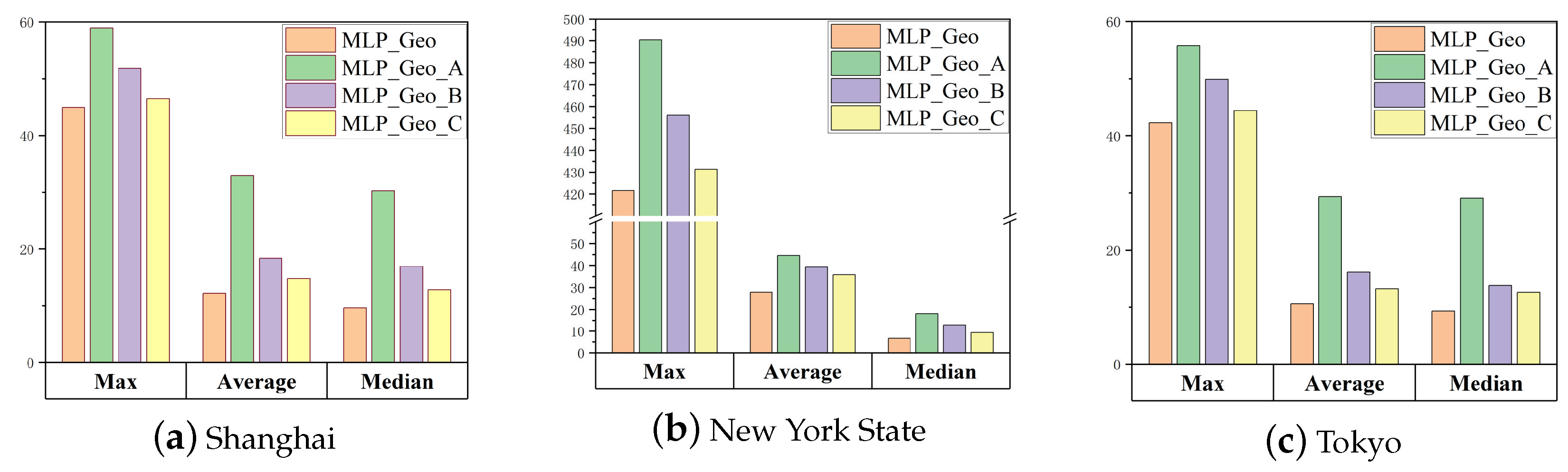
4.5. Ablation Study
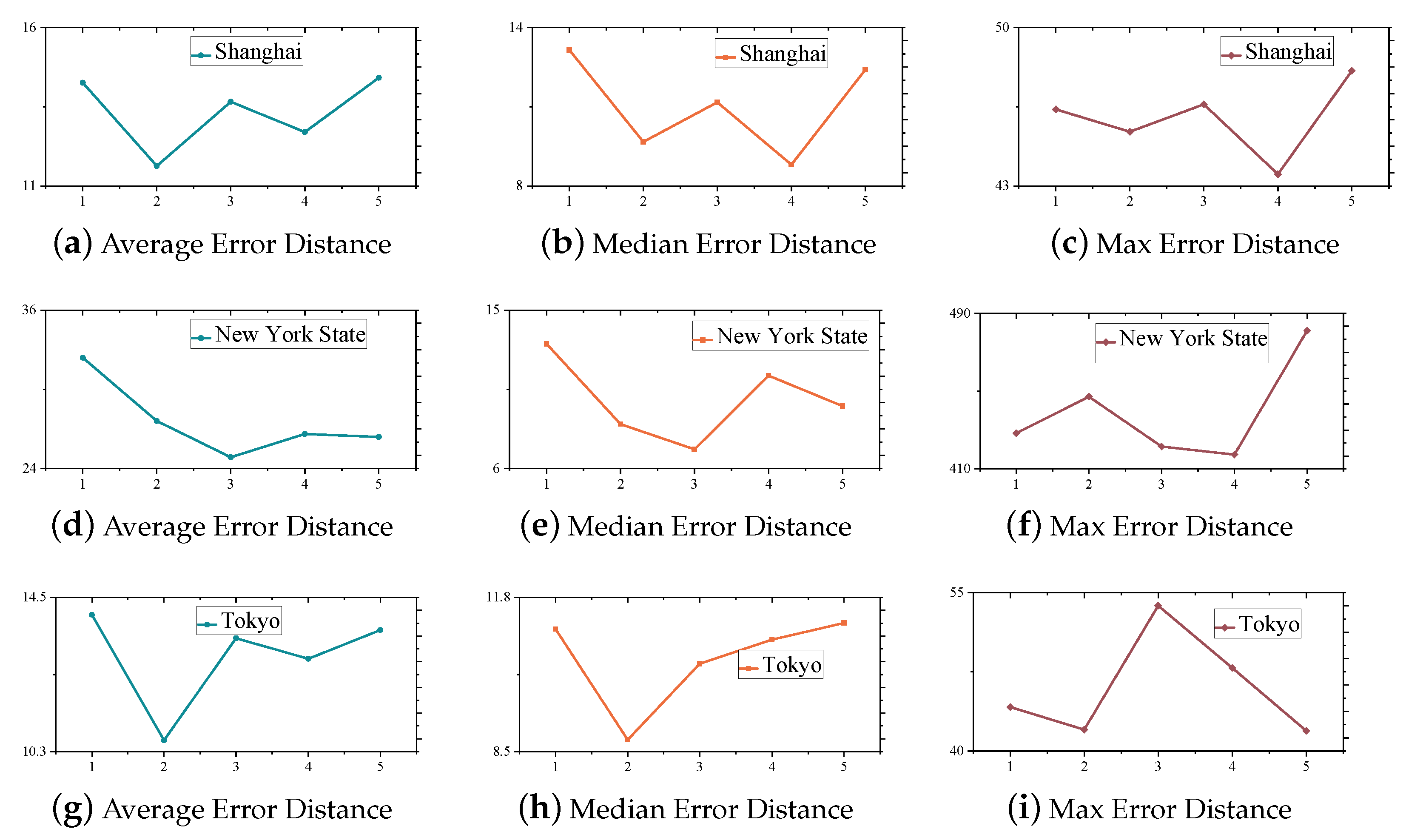
4.6. Effect of the Number of Hidden Layers on the Model
4.7. Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kawamura, S.; Kawashima, M. A Recommendation for IPv6 Address Text Representation; Technical Report; NEC BIGLOBE, Ltd.: Tokyo, Japan, 2010. [Google Scholar]
- Katz-Bassett, E.; John, J.P.; Krishnamurthy, A.; Wetherall, D.; Anderson, T.; Chawathe, Y. Towards IP geolocation using delay and topology measurements. In Proceedings of the 6th ACM SIGCOMM Conference on Internet Measurement, Janeriro, Brazil, 25–27 October 2006; pp. 71–84. [Google Scholar]
- Zhao, F.; Luo, X.; Liu, F. Research on cyberspace surveying and mapping technology. Chin. J. Netw. Inf. Secur. 2016, 2, 1–11. [Google Scholar]
- Callejo, P.; Gramaglia, M.; Cuevas, R.; Cuevas, A. A deep dive into the accuracy of IP Geolocation Databases and its impact on online advertising. IEEE Trans. Mob. Comput. 2022, 1. [Google Scholar] [CrossRef]
- Maziku, H.; Shetty, S.; Han, K.; Rogers, T. Enhancing the classification accuracy of IP geolocation. In Proceedings of the MILCOM 2012-2012 IEEE Military Communications Conference, Orlando, FL, USA, 29 October 2012; pp. 1–6. [Google Scholar]
- Dan, O.; Parikh, V.; Davison, B.D. IP Geolocation Using Traceroute Location Propagation and IP Range Location Interpolation. In Proceedings of the Companion Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 332–338. [Google Scholar]
- Dhamdhere, A.; Luckie, M.; Huffaker, B.; Claffy, K.; Elmokashfi, A.; Aben, E. Measuring the deployment of IPv6: Topology, routing and performance. In Proceedings of the 2012 Internet Measurement Conference, Boston, MA, USA, 14–16 November 2012; pp. 537–550. [Google Scholar]
- Tran, T.V. IPv6 Geolocation Using Latency Constraints; Technical Report; Naval Postgraduate School: Monterey, CA, USA, 2014. [Google Scholar]
- Liu, C.; Luo, X.; Yuan, F.; Liu, F. Rnbg: A ranking nodes based ip geolocation method. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 80–84. [Google Scholar]
- Ding, S.; Zhao, F.; Luo, X. A Street-Level IP Geolocation Method Based on Delay-Distance Correlation and Multilayered Common Routers. Secur. Commun. Netw. 2021, 2021, 6658642. [Google Scholar] [CrossRef]
- Yang, T.; Hou, B.; Cai, Z.; Wu, K.; Zhou, T.; Wang, C. 6Graph: A graph-theoretic approach to address pattern mining for Internet-wide IPv6 scanning. Comput. Netw. 2022, 203, 108666. [Google Scholar] [CrossRef]
- Gouel, M.; Vermeulen, K.; Fourmaux, O.; Friedman, T.; Beverly, R. IP geolocation database stability and implications for network research. In Proceedings of the Network Traffic Measurement and Analysis Conference, Virtual, 14–15 September 2021. [Google Scholar]
- Zhao, F.; Luo, X.; Gan, Y.; Zu, S.; Cheng, Q.; Liu, F. IP geolocation based on identification routers and local delay distribution similarity. Concurr. Comput. Pract. Exp. 2019, 31, e4722. [Google Scholar] [CrossRef]
- Shavitt, Y.; Zilberman, N. A geolocation databases study. IEEE J. Sel. Areas Commun. 2011, 29, 2044–2056. [Google Scholar] [CrossRef]
- Zhao, Q.; Wang, F.; Huang, C.; Yu, C. Improving IP geolocation databases based on multi-method classification. In Proceedings of the 2020 IEEE 14th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 30 October–1 November 2020; pp. 44–48. [Google Scholar]
- Poese, I.; Uhlig, S.; Kaafar, M.A.; Donnet, B.; Gueye, B. IP geolocation databases: Unreliable? ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 53–56. [Google Scholar] [CrossRef]
- Scheitle, Q.; Gasser, O.; Sattler, P.; Carle, G. HLOC: Hints-based geolocation leveraging multiple measurement frameworks. In Proceedings of the 2017 Network Traffic Measurement and Analysis Conference (TMA), Dublin, Ireland, 21–23 June 2017; pp. 1–9. [Google Scholar]
- Bo, X.; Han, L.; Yong, W. An IP geolocation database evaluation and fusion model based on data correlation and delay similarity. In Proceedings of the 2nd International Conference on Telecommunications and Communication Engineering, New York, NY, USA, 28 November 2018; pp. 231–236. [Google Scholar]
- Rye, E.C.; Beverly, R. Discovering the ipv6 network periphery. In Proceedings of the International Conference on Passive and Active Network Measurement, Eugene, OR, USA, 30–31 March 2020; pp. 3–18. [Google Scholar]
- Wang, Y.; Burgener, D.; Flores, M.; Kuzmanovic, A.; Huang, C. Towards {Street-Level}{Client-Independent}{IP} Geolocation. In Proceedings of the 8th USENIX Symposium on Networked Systems Design and Implementation (NSDI 11), Boston, MA, USA, 30 March–1 April 2011. [Google Scholar]
- Zu, S.; Luo, X.; Liu, S.; Liu, Y.; Liu, F. City-level IP geolocation algorithm based on PoP network topology. IEEE Access 2018, 6, 64867–64875. [Google Scholar] [CrossRef]
- Eriksson, B.; Barford, P.; Sommers, J.; Nowak, R. A learning-based approach for IP geolocation. In Proceedings of the International Conference on Passive and Active Network Measurement, Zurich, Switzerland, 7–9 April 2010; pp. 171–180. [Google Scholar]
- Jiang, H.; Liu, Y.; Matthews, J.N. IP geolocation estimation using neural networks with stable landmarks. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 170–175. [Google Scholar]
- Zhang, F.; Liu, F.; Luo, X. Geolocation of covert communication entity on the Internet for post-steganalysis. EURASIP J. Image Video Process. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Du, F.; Bao, X.; Zhang, Y.; Yang, H. GeoCET: Accurate IP Geolocation via Constraint-Based Elliptical Trajectories. In Proceedings of the International Conference on Collaborative Computing: Networking, Applications and Worksharing, London, UK, 19–22 August 2019; pp. 603–622. [Google Scholar]
- Zhang, J.; Li, Y.; Xiao, W.; Zhang, Z. Online Spatiotemporal Modeling for Robust and Lightweight Device-Free Localization in Nonstationary Environments. IEEE Trans. Ind. Inf. 2022. Early Access. [Google Scholar] [CrossRef]
- Hussain, A.; Nazir, S.; Khan, F.; Nkenyereye, L.; Ullah, A.; Khan, S.; Verma, S.; Kavita. A resource efficient hybrid proxy mobile IPv6 extension for next generation IoT networks. IEEE Internet Things J. 2021. Early Access. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Z.; Tan, D.; Song, J.; Wang, H.; Sun, L.; Liu, J. GeoCAM: An IP-Based Geolocation Service Through Fine-Grained and Stable Webcam Landmarks. IEEE/ACM Trans. Netw. 2021, 29, 1798–1812. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Y.; Xiong, H.; Dou, D.; Miao, C.; Zhang, D. HandGest: Hierarchical Sensing for Robust in-the-air Handwriting Recognition with Commodity WiFi Devices. IEEE Internet Things J. 2022. Early Access. [Google Scholar] [CrossRef]
- Rye, E.; Beverly, R. IPvSeeYou: Exploiting Leaked Identifiers in IPv6 for Street-Level Geolocation. arXiv 2022, arXiv:2208.06767. [Google Scholar]
- WiFi.BSSID. Available online: https://www.arduino.cc/reference/en/libraries/wifi/wifi.bssid/ (accessed on 4 November 2022).
- Spring, N.; Mahajan, R.; Wetherall, D. Measuring ISP topologies with Rocketfuel. ACM SIGCOMM Comput. Commun. Rev. 2002, 32, 133–145. [Google Scholar] [CrossRef]
- Gunes, M.H.; Sarac, K. Resolving anonymous routers in internet topology measurement studies. In Proceedings of the IEEE INFOCOM 2008-The 27th Conference on Computer Communications, Phoenix, AZ, USA, 13–18 April 2008; pp. 1076–1084. [Google Scholar]
- Rapid7 Open Data. Available online: https://opendata.rapid7.com/ (accessed on 4 November 2022).
- APNIC. Available online: https://www.apnic.net/ (accessed on 4 November 2022).
- ARIN. Available online: https://www.arin.net/ (accessed on 4 November 2022).
- Zhao, M.; Jha, A.; Liu, Q.; Millis, B.A.; Mahadevan-Jansen, A.; Lu, L.; Landman, B.A.; Tyska, M.J.; Huo, Y. Faster Mean-shift: GPU-accelerated clustering for cosine embedding-based cell segmentation and tracking. Med. Image Anal. 2021, 71, 102048. [Google Scholar] [CrossRef] [PubMed]
- Kale, Ö.; Akkar, S. A new procedure for selecting and ranking ground-motion prediction equations (GMPEs): The Euclidean distance-based ranking (EDR) method. Bull. Seismol. Soc. Am. 2013, 103, 1069–1084. [Google Scholar] [CrossRef]
- Bergroth, L.; Hakonen, H.; Raita, T. A survey of longest common subsequence algorithms. In Proceedings of the Proceedings Seventh International Symposium on String Processing and Information Retrieval, A Curuna, Spain, 27–29 September 2000; pp. 39–48. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Padmanabhan, R.; Rula, J.P.; Richter, P.; Strowes, S.D.; Dainotti, A. DynamIPs: Analyzing address assignment practices in IPv4 and IPv6. In Proceedings of the 16th International Conference on emerging Networking EXperiments and Technologies, Barcelona, Spain, 1–4 December 2020; pp. 55–70. [Google Scholar]
- Zheng, K.; Liu, B. V6Gene: A scalable IPv6 prefix generator for route lookup algorithm benchmark. In Proceedings of the 20th International Conference on Advanced Information Networking and Applications-Volume 1 (AINA’06), Vienna, Austria, 18–20 April 2006; Volume 1, p. 6. [Google Scholar]
- Mestres, A.; Alarcón, E.; Ji, Y.; Cabellos-Aparicio, A. Understanding the modeling of computer network delays using neural networks. In Proceedings of the 2018 Workshop on Big Data Analytics and Machine Learning for Data Communication Networks, Budapest, Hungary, 20 August 2018; pp. 46–52. [Google Scholar]
- Li, R.; Xu, R.; Ma, Y.; Luo, X. LandmarkMiner: Street-level network landmarks mining method for IP geolocation. ACM Trans. Internet Things 2021, 2, 1–22. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Region |
|---|---|
| Probe deployment | China: Zhengzhou and Hong Kong USA: Virginia |
| Landmark deployment Detection protocol | Shanghai, Tokyo, and New York State ICMPv6 |
| Region | Landmark Deployment | Quantity |
|---|---|---|
| China | Shanghai | 2195 |
| America | New York State | 1826 |
| Japan | Tokyo | 1589 |
| total | 5610 |
| Method | Shanghai, China | New York State, USA | Tokyo, Japan | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Max | Ave | Med | Max | Ave | Med | Max | Ave | Med | |
| IPv6-CBG | 59.892 | 31.802 | 29.254 | 486.729 | 43.603 | 16.105 | 53.766 | 27.587 | 28.088 |
| Corr-SLG | 55.427 | 15.337 | 13.916 | 481.127 | 37.303 | 7.501 | 46.881 | 12.019 | 9.856 |
| TNN | 48.881 | 15.139 | 13.617 | 447.095 | 34.39 | 10.381 | 47.874 | 14.475 | 12.249 |
| MLP-Geo | 46.273 | 13.809 | 11.614 | 428.376 | 27.361 | 8.047 | 43.972 | 12.118 | 10.618 |
| Our Proposed | 44.895 | 11.194 | 9.709 | 421.527 | 24.854 | 7.025 | 42.018 | 10.564 | 8.751 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Hu, X.; Zhang, S.; Li, N.; Liu, F.; Zhou, Q.; Wang, H.; Hu, G.; Dong, Q. SubvectorS_Geo: A Neural-Network-Based IPv6 Geolocation Algorithm. Appl. Sci. 2023, 13, 754. https://doi.org/10.3390/app13020754
Ma Z, Hu X, Zhang S, Li N, Liu F, Zhou Q, Wang H, Hu G, Dong Q. SubvectorS_Geo: A Neural-Network-Based IPv6 Geolocation Algorithm. Applied Sciences. 2023; 13(2):754. https://doi.org/10.3390/app13020754
Chicago/Turabian StyleMa, Zhaorui, Xinhao Hu, Shicheng Zhang, Na Li, Fenlin Liu, Qinglei Zhou, Hongjian Wang, Guangwu Hu, and Qilin Dong. 2023. "SubvectorS_Geo: A Neural-Network-Based IPv6 Geolocation Algorithm" Applied Sciences 13, no. 2: 754. https://doi.org/10.3390/app13020754
APA StyleMa, Z., Hu, X., Zhang, S., Li, N., Liu, F., Zhou, Q., Wang, H., Hu, G., & Dong, Q. (2023). SubvectorS_Geo: A Neural-Network-Based IPv6 Geolocation Algorithm. Applied Sciences, 13(2), 754. https://doi.org/10.3390/app13020754