
Non-Axiomatic Logic Modeling of English Texts for Knowledge Discovery and Commonsense Reasoning



Abstract
:Featured Application
Abstract
1. Introduction
- 1.
- We reverse the traditional process of tackling the problem of natural language translation into formal language by selecting some linguistic analysis tools as a guide for constructing logic expressions with approximately the same semantics as the natural language sentences being translated.
- 2.
- We use a logic that has features that other classic logics lack: subject–predicate sentences, experience-grounded semantics and syllogistic inference rules [14].
- 1.
- We predefined some NAL terms (concepts), as well as some NAL term relations, for representing grammatical and semantic relations commonly found in English sentences.
- 2.
- We propose a set of NL-to-NAL translation rules general enough to cover the great majority of English universal dependencies use cases and provide a full set of examples.
- 3.
- We include not only grammatical properties of the translated sentences but semantic elements too.
- 4.
- Finally, we glimpse into the possible use of the proposed translation rules for supporting commonsense reasoning tasks [15].
2. Related Works
- You gave me the important manual
- You gave the important manual to me
- The important manual was given to me by you
3. Theoretical Foundations and Required Background Knowledge
3.1. Non-Axiomatic Logic
- Frequency (f) is a real number in the interval [0, 1] computing the ratio of positive evidence () for the formula over the total available evidence (W, the sum of positive and negative evidence) about it; therefore, .
- Confidence (c) is another real number in [0, 1) computing the ratio of currently available evidence (W) for the formula over the total amount of evidence expected to exist (), so , where the k variable is a constant expressing the system’s learning speed, and it is usually set at .
3.2. Linguistic Tools
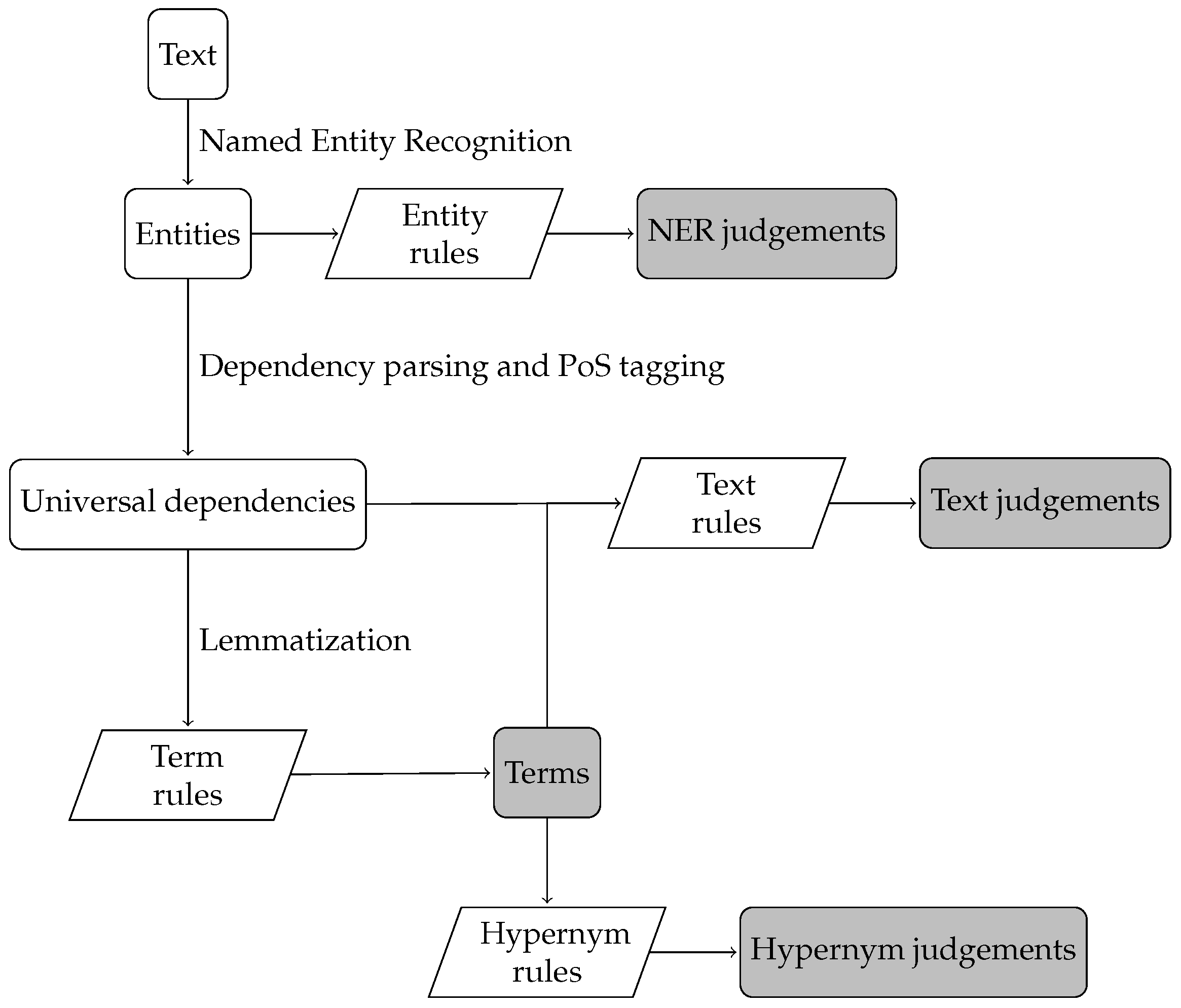
4. Proposal
Translation Rules
- Entity rules: Rules that only require as input the result of the named entity recognition analysis. These rules ground some of the logical terms and establish some of the context judgements. With these rules, the words “Bill Gates” will be translated to a single term and the judgment
- Term rules: These rules take as input the lemmatization of the text, dependency parsing and PoS tagging results of the text. This type of rule obtains some compound and non-compound terms that will be used in the translation—for example, the words “the manual”, “chasing” and “important” will be mapped to the terms , chase and
- Hypernym rules: As the name suggests, these rules take as input hypernyms of concepts in the text via WordNet. The output of these rules is judgments representing “is a” context, for example
- Text rules: Their input consist of the dependency parsing of the text, PoS tagging results and hypernyms of some of the concepts in the text. Establishing judgements that involve defined terms and express the content of the text is the main goal of this group of rules. Suppose the sentence “Ana writes poems” is in the text, then these rules will obtain the judgment .
| “The important manual was reluctantly given to Bill Gates by Ford”. |

- 1.
- Every concept appearing in the text will be implicitly represented and its meaning extended with the help of auxiliary background judgements from the WordNet ontology.
- 2.
- NAL is a non-monotonic logic, an agent wielding that logic can always learn new concepts and receive new information, consequently adding new formulas to its knowledge base, even when such new formulas seem like contradictory information.
5. Experiments and Results
Experiments per Case
| 1. Nominal subject |
| (a) Active voice with a verb as root and nominal core arguments |
| Clinton defeated Dole |
| (b) Passive voice with a verb as root and nominal core arguments |
| Dole was defeated by Clinton |
| (c) Adjective as root |
| This toy is red |
| (d) Nominal as root and no case dependency |
| Roses are flowers |
| (e) Nominal as root and case dependency |
| We are in the barn |
| (f) Copular sentence with clausal complement (outer) |
| The important thing is to keep calm |
| 2. Object |
| (a) Active or passive voice with a verb as root |
| Ana teaches Logic |
| 3. Indirect object |
| (a) Active or passive voice with a verb as root |
| Ana teaches the students Logic |
| 4. Clausal subject |
| (a) Active voice with a verb as root |
| Taking a nap will relax you |
| (b) Passive voice with a verb as root |
| That she lied was suspected by everyone |
| (c) Adjective as root |
| Taking a nap is relaxing |
| (d) Nominal as root and no case dependency |
| What she said is a proverb |
| (e) Copular sentence with clausal complement (outer) |
| To hike in the mountains is to experience nature |
| 5. Clausal complement |
| (a) Active or passive voice with a verb as root and the explicit subject of the complement |
| He says you like flowers |
| (b) Active or passive voice with an adjective as root and the explicit subject of the complement |
| Ana is delighted that you could help |
| (c) Active or passive voice with a verb as root and not specified subject of the complement |
| The boss said to start digging |
| 6. Open clausal complement |
| (a) Active or passive voice with a verb as root and the implicit subject of the complement |
| I consider her honest |
| (b) Adjective as root and implicit subject of the complement |
| Susan is liable to be arrested |
| 7. Oblique nominal |
| (a) Locational modifier dependent on a verb |
| The will arrive in Boston |
| (b) Temporal modifier dependent on a verb |
| They will arrive on Friday |
| (c) Element of the dative alternation dependent on a verb |
| Ana teaches Logic to the students |
| (d) Agent dependent on a passive verb |
| The cat was chased by a dog |
| (e) Dependent on an adjective |
| He is afraid of sharks |
| (f) Adverbial modifiers |
| The director is 65 years old |
| [65-years] |
| 8. Expletive |
| (a) Existential there with an oblique modifier |
| There is a ghost in the room |
| (b) “It” in extraposition constructions |
| It is clear that we should decline |
| (c) Existential there without oblique modifiers |
| There are children |
| 9. Adverbial clause modifier |
| (a) Temporal modifier |
| The accident happened as night was falling |
| (b) Locational modifier |
| They drove beyond where the city ends |
| (c) Concession modifier |
| He is a teacher, although he no longer teaches |
| (d) Condition modifier |
| If you know who did it, you should tell the teacher |
| (e) Purpose modifier |
| He talked to you in order to secure the account |
| (f) Reason modifier |
| I am in my house since I caught a cold |
| (g) Comparison modifier |
| John can speak English as fluently as his teacher can |
| (h) Manner modifier |
| He spent a lot of money as if he was rich |
| 10. Adverbial modifier |
| (a) Adverbial modifying verb |
| Ana rarely drinks coffee |
| (b) Adverbial modifying adjective |
| About 200 people came |
| (c) Adverbial modifying adverb |
| Tom is almost always busy |
| (d) Negation |
| Tom does not like Italian food |
| 11. Nominal modifier |
| (a) Determiner modifying a noun or noun phrase |
| Some of the toys are red |
| (b) Noun modifying a noun or noun phrase |
| Toys for children are cute |
| 12. Appositional modifier |
| (a) Appositional modifier |
| Sam, my brother, arrived |
| 13. Numeric modifier |
| (a) Numeric modifier |
| Sam spend forty dollars |
| 14. Clausal modifier of a noun |
| (a) Modified noun as subject |
| My sister has a parakeet named Cookie |
| (b) Modified noun as object |
| He is a teacher whom the students really love |
| 15. Adjectival modifier |
| (a) Adjectival modifier |
| Canaries are yellow |
| (b) Comparative adjective |
| Ana is taller than Tom |
| (c) Comparison “as … as” |
| Ana is as tall as Tom |
| (d) Superlative adjective |
| Ana is the tallest in the group |
6. Commonsense Reasoning
- 1.
- Inference formulas in NAL have both a syntactic component and an arithmetic component. The syntactic component shows how to combine the terms included in the initial premises to form a conclusion, while the arithmetic component shows how to compute the truth value of the conclusion from the truth value of the premises.
- 2.
- The conclusion expression, along with its truth value, must be translated back into natural language in order to complete the reasoning task. That translation involves the use of certain words to represent the numerical interval in which the values of both frequency and confidence in the truth value of the conclusion are found. This second translation process is also beyond the scope of this paper.
- Someone picked up some food for a snack at the supermarket.
- These ingredients were bought at the grocery store.
- Milk can be purchased at food markets.
7. Discussion
- A nominal subject sentence (Examples, Nominal subject, cases (a) and (b)) gets translated to the exact same NAL formula, regardless of it being in an active or passive voice.
- A double object construction (Example, Indirect object, case (a)) and a prepositional construction (Example, Oblique nominal, case (c)) also got translated to the same NAL pre-defined relation formula.
- A careful use of NAL product terms allows the pre-defined relations to endow their related terms with a more semantic role than their syntactic analysis would suggest. For example, the two sentences Ana teaches Logic and Ana teaches the students have exactly the same dependency parsing but are translated to slightly different NAL formulas. The first one is translated into , while the second one is translated into .
7.1. Limitations and Future Work
- The rules are not capable of deciding if an adjective should be represented as a property or as a relation. This difference between adjectives can be clearly seen in possessive or predicative adjectives, as in [49]. Even more, their translation may depend on a specific context that could not be part of the current sentence.
- Some translations will not be useful to carry axiomatic reasoning. This can be clearly seen in the translation of numbers or unities, for example; consider the translation of the sentence One apple plus two apples equals three apples [50].
- Other linguistic analyses can be performed before the application of rules, such as word-sense disambiguation or anaphora resolution
- While all the variables considered in this work are dependent variables in NAL, this can be expanded so the rules also include independent variables.
- The implemented rules greatly depend in the linguistic software used. If an inadequate analysis is carried out before, the translation will also be erroneous.
- In addition to the previous point, the implementation is not connected to a semantic dependency parser to automatically obtain semantic roles in a sentence. Instead, Prolog predicates are used to denote locations, instruments, time, etc.
8. Conclusions
- From the perspective of the symbolic paradigm, this work explores the possibility of extracting fundamental term relationships expressed in natural language to construct with them a representation in a formal language (NAL) previously known to be well adapted for reasoning tasks, and particularly commonsense reasoning.
- From the point of view of natural language processing and computational linguistics, this work proposes a way to use non-axiomatic logic as a minimum-loss formal representation of natural language sentences.
- Finally, from the point of view of artificial general intelligence, this work advances the first step required on the way to designing an agent with language understanding and commonsense reasoning capabilities.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| NAL | Non-axiomatic logic |
| NL | Natural language |
| PL | Predicate logic |
| AIKR | Assumption of Insufficient Knowledge and Resources |
References
- Davis, E.; Marcus, G. Commonsense reasoning and commonsense knowledge in artificial intelligence. Commun. ACM 2015, 58, 92–103. [Google Scholar] [CrossRef]
- Sap, M.; Shwartz, V.; Bosselut, A.; Choi, Y.; Roth, D. Commonsense reasoning for natural language processing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, Online, 5–10 July 2020; pp. 27–33. [Google Scholar]
- McCarthy, J. Programs with Common Sense; Taylor & Francis: Abingdon, UK, 1959. [Google Scholar]
- Richardson, C.; Heck, L. Commonsense reasoning for conversational AI: A survey of the state of the art. arXiv 2023, arXiv:2302.07926. [Google Scholar]
- Davis, E. Logical formalizations of commonsense reasoning: A survey. J. Artif. Intell. Res. 2017, 59, 651–723. [Google Scholar] [CrossRef]
- McCarthy, J. Formalizing Common Sense; Intellect Books: Bristol, UK, 1990; Volume 5. [Google Scholar]
- McCarthy, J.; Buvac, S. Formalizing context. In Proceedings of the AAAI Fall Symposium on Context in Knowledge Representation, Seattle, WA, USA, 31 July–4 August 1994; pp. 99–135. [Google Scholar]
- Waismann, F. Ludwig Wittgenstein and the Vienna Circle; Basil Blackwell: Oxford, UK, 1979. [Google Scholar]
- Wang, P. Toward a logic of everyday reasoning. In Blended Cognition: The Robotic Challenge; Springer: Berlin/Heidelberg, Germany, 2019; pp. 275–302. [Google Scholar]
- Wang, P. From inheritance relation to non-axiomatic logic. Int. J. Approx. Reason. 1994, 11, 281–319. [Google Scholar] [CrossRef]
- Slam, N.; Wang, W.; Wang, P. An improvisational decision-making agent based on non-axiomatic reasoning system. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Warsaw, Poland, 11–14 August 2014; Volume 3, pp. 360–364. [Google Scholar]
- Han, S.; Schoelkopf, H.; Zhao, Y.; Qi, Z.; Riddell, M.; Benson, L.; Sun, L.; Zubova, E.; Qiao, Y.; Burtell, M.; et al. FOLIO: Natural language reasoning with first-order logic. arXiv 2022, arXiv:2209.00840. [Google Scholar]
- Purdy, W.C. A logic for natural language. Notre Dame J. Form. Log. 1991, 32, 409–425. [Google Scholar] [CrossRef]
- Wang, P. Non-Axiomatic Logic: A Model of Intelligent Reasoning; World Scientific: Singapore, 2013. [Google Scholar]
- Jackson, P.C., Jr. Toward human-level qualitative reasoning with a natural language of thought. In Proceedings of the Biologically Inspired Cognitive Architectures Meeting; Springer: Berlin/Heidelberg, Germany, 2021; pp. 195–207. [Google Scholar]
- Kryvyi, S.; Hoherchak, H. Analyzing Natural Language Knowledge Uncertainty. In Proceedings of the 2022 IEEE 4th International Conference on Advanced Trends in Information Theory (ATIT), Kyiv, Ukraine, 15–17 December 2022; pp. 268–272. [Google Scholar] [CrossRef]
- Dzifcak, J.; Scheutz, M.; Baral, C.; Schermerhorn, P. What to do and how to do it: Translating natural language directives into temporal and dynamic logic representation for goal management and action execution. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 4163–4168. [Google Scholar] [CrossRef]
- Wang, P. Rigid Flexibility; Springer: Berlin/Heidelberg, Germany, 2006; Volume 55. [Google Scholar]
- Hammer, P.; Lofthouse, T.; Fenoglio, E.; Latapie, H.; Wang, P. A Reasoning Based Model for Anomaly Detection in the Smart City Domain. In Intelligent Systems and Applications; Arai, K., Kapoor, S., Bhatia, R., Eds.; Springer: Cham, Switzerland, 2021; pp. 144–159. [Google Scholar]
- Hammer, P.; Isaev, P.; Lofthouse, T.; Johansson, R. ONA for Autonomous ROS-Based Robots. In International Conference on Artificial General Intelligence; Goertzel, B., Iklé, M., Potapov, A., Ponomaryov, D., Eds.; Springer: Cham, Switzerland, 2023; pp. 231–242. [Google Scholar]
- Wang, P. Natural language processing by reasoning and learning. In Proceedings of the International Conference on Artificial General Intelligence, Beijing, China, 31 July–3 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 160–169. [Google Scholar]
- Hammer, P. English to Narsese. 2020. Available online: https://github.com/opennars/OpenNARS-for-Applications (accessed on 13 May 2022).
- Adi, Y.; Kermany, E.; Belinkov, Y.; Lavi, O.; Goldberg, Y. Fine-grained analysis of sentence embeddings using auxiliary prediction tasks. arXiv 2016, arXiv:1608.04207. [Google Scholar]
- Kádár, A.; Chrupała, G.; Alishahi, A. Representation of linguistic form and function in recurrent neural networks. Comput. Linguist. 2017, 43, 761–780. [Google Scholar] [CrossRef]
- Ranaldi, L.; Pucci, G. Knowing knowledge: Epistemological study of knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]
- McCoy, R.T.; Pavlick, E.; Linzen, T. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference. arXiv 2019, arXiv:1902.01007. [Google Scholar]
- Talmor, A.; Elazar, Y.; Goldberg, Y.; Berant, J. oLMpics-On what language model pre-training captures. Trans. Assoc. Comput. Linguist. 2020, 8, 743–758. [Google Scholar] [CrossRef]
- Hitzler, P.; Eberhart, A.; Ebrahimi, M.; Sarker, M.K.; Zhou, L. Neuro-symbolic approaches in artificial intelligence. Natl. Sci. Rev. 2022, 9, nwac035. [Google Scholar] [CrossRef] [PubMed]
- Zanzotto, F.M.; Santilli, A.; Ranaldi, L.; Onorati, D.; Tommasino, P.; Fallucchi, F. KERMIT: Complementing Transformer architectures with Encoders of explicit syntactic interpretations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 256–267. [Google Scholar] [CrossRef]
- Sinha, K.; Sodhani, S.; Dong, J.; Pineau, J.; Hamilton, W.L. CLUTRR: A diagnostic benchmark for inductive reasoning from text. arXiv 2019, arXiv:1908.06177. [Google Scholar]
- Hammer, P. NARS-GPT. 2022. Available online: https://github.com/opennars/NARS-GPT (accessed on 31 August 2023).
- Wang, P.; Hofstadter, D. A logic of categorization. J. Exp. Theor. Artif. Intell. 2006, 18, 193–213. [Google Scholar] [CrossRef]
- Gärdenfors, P.; Makinson, D. Nonmonotonic inference based on expectations. Artif. Intell. 1994, 65, 197–245. [Google Scholar] [CrossRef]
- Lindes, P. Constructing Meaning, Piece by Piece: A Computational Cognitive Model of Human Sentence Comprehension. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 2022. [Google Scholar]
- Frege, G. Begriffsschrift, a formula language, modeled upon that of arithmetic, for pure thought. In From Frege to Gödel: A Source Book in Mathematical Logic, 1879–1931; Harvard University Press: Cambridge, MA, USA, 1879; pp. 1–82. [Google Scholar]
- Mitkov, R. The Oxford Handbook of Computational Linguistics; Oxford University Press: Oxford, UK, 2022. [Google Scholar]
- de Marneffe, M.C.; Manning, C.D.; Nivre, J.; Zeman, D. Universal Dependencies. Comput. Linguist. 2021, 47, 255–308. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics and Speech Recognition; Prentice Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Dan, K.; Manning, C. Accurate unlexicalized parsing. In Proceedings of the 41st Meeting of the Association for Computational Linguistics, Sapporo, Japan, 7–12 July 2003; pp. 423–430. [Google Scholar]
- Kapetanios, E.; Tatar, D.; Sacarea, C. Natural Language Processing: Semantic Aspects; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C. Incorporating non-local information into information extraction systems by Gibbs sampling. In Proceedings of the 43nd Annual Meeting of the Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 363–370. [Google Scholar]
- Miller, G. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Schuler, K.K. VerbNet: A Broad-Coverage, Comprehensive Verb Lexicon; University of Pennsylvania: Philadelphia, PA, USA, 2005. [Google Scholar]
- Documentation of Universal Dependency Relations. 2014. Available online: https://universaldependencies.org/u/dep/index.html (accessed on 28 August 2023).
- Gärdenfors, P. The emergence of meaning. Linguist. Philos. 1993, 16, 285–309. [Google Scholar] [CrossRef]
- Chabierski, P.; Russo, A.; Law, M. Logic-Based Approach to Machine Comprehension of Text. 2017. Available online: https://www.imperial.ac.uk/media/imperial-college/faculty-of-engineering/computing/public/1617-ug-projects/Piotr-Chabierski—Logic-based-Approach-to-Machine-Comprehension-of-Text.pdf (accessed on 28 August 2023).
- Barker-Plummer, D.; Cox, R.; Dale, R.; Etchemendy, J. An empirical study of errors in translating natural language into logic. Proc. Annu. Meet. Cogn. Sci. Soc. 2008, 30, 30. [Google Scholar]
- Wang, P. The interpretation of fuzziness. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 1996, 26, 321–326. [Google Scholar] [CrossRef] [PubMed]
- Kamp, H. Two theories about adjectives. In Meaning and the Dynamics of Interpretation; Brill: Leiden, The Netherlands, 2013; pp. 225–261. [Google Scholar]
- Wang, P. Axiomatic Reasoning in NARS; Technical Report; Technical Report 15, AGI Team; Temple University: Philadelphia, PA, USA, 2022. [Google Scholar]


{kind=link}
| Copula | Formula Structure | English Meaning | Example |
|---|---|---|---|
| Inheritance | S is a type of P | (Canaries are a type of bird) | |
| Similarity | S is similar to P | (Tweety is similar to Birdy) | |
| Instance | S is an instance of P | (Tweety is a canary) | |
| Property | S has property P | (Canaries are yellow) | |
| Instance–property | Instance S has property P | (Tweety is yellow) |
| Term Connector | Term Structure | English Concept | Example |
|---|---|---|---|
| ∪ Set Union | Any element of concept T1 or concept T2 | () | |
| ∩ Set Intersection | An element of concept T1 and of concept T2 | () | |
| − Asymmetric Set Difference | An element of concept T1 but not of concept T2 | () | |
| ⊖ Symmetric Set Difference | An element with properties of T1 but no properties of T2 | () | |
| × Relation | Terms T1 to Tm are related by a Tn relation |
| Nominals | Clauses | Modifiers | Function Words | |
|---|---|---|---|---|
| Core Arguments | nominal subject object indirect object | clausal subject clausal complement open complement | ||
| Non-core Dependents | oblique nominal expletive | adverbial cl modifier | adverbial modifier | copula marker |
| Nominal Dependents | nominal modifier appositional mod numeric modifier | clausal modifier | adjectival modifier | determiner case marking |
| Coordination | Multi Word Expression | Special |
|---|---|---|
| conjunct coordinating conjunct | fixed flat compound | goes with |
| Linguistic Analysis | Software | Output |
|---|---|---|
| Named entity recognition | Stanford Named Entity Recognizer, v. 4.2.0 | Tagged entities in text |
| Dependency parsing | Stanford Parser, v. 4.2.0 | Universal dependencies |
| PoS tagging | Stanford Parser | Penn Treebank PoS Tags |
| - | WordNet, v. 3.0 | Hypernyms of nouns and verbs in text |
| Semantic dependency parsing | - | VerbNet roles |
| Pre-Defined Term | Semantics |
|---|---|
| Term for expressing the location of something or of an event. See example 1. Nominal subject, case (e) | |
| Term for expressing when something occurred or to indicate that two events happened at the same time. See example 7. Oblique nominal, case (b) | |
| Term for expressing concession between two events. See example 9. Adverbial clause modifier, case (c) | |
| Term for expressing that an event is the purpose of another. See example 9. Adverbial clause modifier, case (e) | |
| Term for expressing that an event is the reason for another. See example 9. Adverbial clause modifier, case (f) | |
| Term for expressing that an event modifies the manner in which another occurred. See example 9. Adverbial clause modifier, case (h) |
| Pre-Defined Relation | Semantics |
|---|---|
| subject (actor, agent or experiencer as in [43]) makes verb (an action), the direct object (not a recipient) of verb is object, and recipient is the recipient. See example 1. Nominal subject, case (a) or 3. Indirect object, case (a) | |
| argument1 and argument2 are related under the semantics of the pre-defined term. See example 1. Nominal subject, case (e) or 7. Oblique nominal, case (b) | |
| argument1 and argument2 are related following the semantics of adjective. See example 6. Open clausal complement, case (b) or 7. Oblique nominal, case (e) | |
| argument1 and argument2 are related following the semantics of comparative, which represents a comparative or superlative adjective. See example 6. Open clausal complement, case (b) or 7. Oblique nominal, case (e) | |
| argument1 and argument2 are related following the semantics of equality, which represents an equality comparison. See example 9. Adverbial clause modifier, case (g) or 15. Adjectival modifier, case (c) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juárez, O.; Godoy-Calderon, S.; Calvo, H. Non-Axiomatic Logic Modeling of English Texts for Knowledge Discovery and Commonsense Reasoning. Appl. Sci. 2023, 13, 11535. https://doi.org/10.3390/app132011535
Juárez O, Godoy-Calderon S, Calvo H. Non-Axiomatic Logic Modeling of English Texts for Knowledge Discovery and Commonsense Reasoning. Applied Sciences. 2023; 13(20):11535. https://doi.org/10.3390/app132011535
Chicago/Turabian StyleJuárez, Osiris, Salvador Godoy-Calderon, and Hiram Calvo. 2023. "Non-Axiomatic Logic Modeling of English Texts for Knowledge Discovery and Commonsense Reasoning" Applied Sciences 13, no. 20: 11535. https://doi.org/10.3390/app132011535
APA StyleJuárez, O., Godoy-Calderon, S., & Calvo, H. (2023). Non-Axiomatic Logic Modeling of English Texts for Knowledge Discovery and Commonsense Reasoning. Applied Sciences, 13(20), 11535. https://doi.org/10.3390/app132011535