1. Introduction
With the rapid development of mobile communication, the number of devices and the amount of application data at the network edge have significantly increased [
1,
2,
3]. However, traditional cloud computing architectures require centralized processing of all data, which cannot meet the requirements of low latency, high traffic volume, and high reliability in current wireless communications. To overcome these issues, edge computing has been proposed as one of the key technologies in 5G application scenarios. Unlike centralized processing, edge computing enables user devices to offload computation tasks directly to edge computing servers (ECSs), reducing the data traffic on the network bandwidth and improving system responsiveness, thus better meeting the low-latency and high-reliability service requirements of 5G data networks [
4,
5,
6,
7]. By deploying ECSs, which act as micro-clouds, in ground infrastructure, edge computing brings computing resources closer to service users, reducing latency and energy consumption in long-distance data transmission processes. User devices offload computation-intensive and latency-sensitive tasks generated by local applications to ECSs that are closer in proximity, thereby improving computational efficiency and ensuring a better user service experience. It is crucial to acknowledge that dependable and unwavering edge computing services necessitate exceedingly strict demands on the offloading scheme of computing tasks. Inappropriate pairing of users with edge computing servers will result in elevated energy consumption and prolonged waiting latency, consequently reducing edge computing network throughput. Within the confines of limited edge servers and deployment locations, enhancing the flexibility of the edge computing network while effectively offloading computing tasks poses a significant challenge for the current state of edge computing.
It should be noted that, in edge computing, deployable ECSs play a crucial role. However, due to the high cost of hardware, it can be challenging to meet the business experience needs of all users with a limited number of ECSs deployed in fixed locations. This is especially true when wireless links are obstructed by buildings, mountains, and other obstacles, severely affecting the wireless link between user terminals (UEs) and ECSs. In recent years, unmanned aerial vehicles (UAVs) have been deployed in wireless communication networks due to their advantages in mobility and cost. UAVs can be used as mobile relay nodes to facilitate information exchange between distant users and as mobile base stations to enhance the coverage range of wireless networks. By leveraging the wide coverage, low cost, and flexibility of UAVs, they can be used as relay nodes in edge computing applications to effectively address the issue of degraded link quality, thereby ensuring a satisfactory user experience at the UE. However, the performance of UAV-assisted edge computing is directly related to the deployment location. To ensure a good user experience in edge computing, the deployment location of UAVs needs to be precisely designed. Furthermore, the incorporation of UAVs will impact the selection of deployment tactics, which is a convoluted process. As opposed to conventional terrestrial mobile edge computing networks, the integration of unmanned aerial vehicles enhances network flexibility, yet simultaneously introduces fresh obstacles to network deployment and decision-making. Joint optimization of computation offloading and drone deployment in drone-assisted edge computing networks, considering heterogeneous user demands and resource constraints, will be critical for enhancing the performance of edge computing networks.
Currently, many resource allocation problems in mobile communication networks are primarily solved using convex optimization, game theory, and other methods. Typically, these methods require the objective function or problem model to conform to specific forms. Moreover, the spatial scale of traditional solution methods exponentially increases with the variables of the problem, requiring more time to converge or even making the solution infeasible. Recently, reinforcement learning methods based on Markov decision processes have been proposed to solve dynamic decision problems under unknown models. In the absence of statistical information about the environment, an agent can learn effective strategies by continuously interacting with the environment, exhibiting a certain level of decision-making ability. Furthermore, deep learning neural networks possess perception capabilities, meaning they can effectively approximate functions. By combining the decision-making ability of reinforcement learning with the perception capabilities of neural networks in deep learning, i.e., deep reinforcement learning (DRL), an agent can make decisions based on local observations without prior information, interact with the environment, and adjust its strategy based on environmental feedback. Through long-term dynamic exploration and training, the agent can effectively learn a strategy to achieve the best long-term goal. DRL combines the perception capabilities of deep learning with the decision-making ability of reinforcement learning, enabling the resolution of complex high-dimensional state space decision problems. Therefore, deep reinforcement learning holds promise for addressing complex decision-making problems in UAV-assisted edge computing applications.
3. System Model and Problem Formulation
In this section, we design a UAV-assisted multi-node edge computing network as shown in
Figure 1. The considered system has
K UEs,
M ECSs, and a UAV, where each UE has a certain computational demand, each ECS has a certain processing capability, and the UAV has only a communication function without computational capability. In this network, the UE cannot establish a good direct wireless link with the edge calculator due to the obstruction of terrain and buildings. In order to satisfy the computational needs of the UE, a UAV is deployed as a relay node in the network. The computation task of the UE is first sent to the UAV and, after a reasonable selection, is forwarded to one of the ECSs. In particular, the matching of UEs and ECSs is crucial for the service experience of UEs. Through reasonable design, the transmission delay and waiting delay of the computation tasks can be ensured in an acceptable range. At the same time, UAVs are highly maneuverable, and by adjusting the hovering position of UAVs, the latency of the computation task can also be effectively reduced. Compared to the existing work [
13,
14,
15], this scenario focuses on possible problems with the wireless link and compensates for the degradation of the channel quality by means of UAVs. The proposed scheme can be adapted to application scenarios such as large cities with heavy building occlusion and mountains with geographic occlusion.
In this work, we adopt the probabilistic line-of-sight channel model. The wireless transmission channel between the UE and the UAV can be categorized by line-of-sight (LoS) and non-line-of-sight (NLoS). The probability of having a LoS wireless channel between UE and UAV is
where
a and
b are constants determined by the environment, and
z is the hovering height of the UAV. Denote the horizontal coordinates of the UAV by
, and that of UE
k by
. The distance from UE
k to the UAV in the horizontal plane is expressed as
Then, the probability of having an NLoS wireless channel between the UE and the UAV is
Let
denote the carrier frequency, and use
c to denote the electromagnetic velocity in free space. Let
and
denote the average additional path loss for LoS and NLoS channels, respectively. Then, the path loss of LoS channel and NLoS channel can be expressed respectively as
Then, the probabilistic average path loss from UE
k to UAV is
where
,
. Define the transmit power as
p, the bandwidth as
B, and the variance of add white Gaussian noise (AWGN) as
; then, the maximum transmit rate at UE
k can be expressed as
From
Figure 1, it can be seen that the computational task from generation to completion contains a total of sending delay, propagation delay, waiting delay, and processing delay, which can be expressed by the following equation:
Considering that the range of this edge computing network is usually small and the signal propagation speed is fast, the propagation delay
in it is negligible. The sending delay, on the other hand, is determined by the size of the computing task and the sending rate. Suppose that end user
k generates a computation task with task size
. In the case that the sending rate of the UE
k is
, and the sending rate is
when the UAV relays, the sending delay of this computational task can be expressed as
where the sending delay in the link from the ECS to the UE is ignored, considering that the computation results returned from the ECS are usually small. Define the ECS matched by UE
k as
m, and define its corresponding computing power as
; then, the processing delay of the computing task of UE
k can be obtained as
The waiting delay indicates the time that this computation task waits in the ECS to be processed. Consider a business cycle in which all UEs simultaneously send computation tasks to the UAV. The UAV is equipped with multiple antennas to forward all the computation tasks simultaneously. In the considered system, the first computational task to arrive at the ECS is the one with the smallest task size among the computational tasks matched by the ECS, and its waiting delay is 0. Subsequent computational tasks arriving at the ECS are categorized into two scenarios based on whether the previous computational task has been processed or not. When the previous task has been processed, the waiting delay of the task is also 0. Otherwise, the waiting delay of the task is accumulated from the time it arrives at the ECS until the previous task has been processed. Based on the above derivation, the waiting delay of a computation task of UE
k at ECS
m can be expressed as
where
represents the set of computational tasks at ECS
m,
j represents the computational task that is second only to
k in terms of task volume, and if
j does not exist, then
holds forever.
and
denote the moment when the processing of computational task
j is completed and the arrival moment of computational task
k, respectively.
Based on the above derivation, we can obtain the total delay of the computation task for user
k as
Considering the entire edge computing network, we use the average delay of the network as a criterion for evaluating the experience of edge computing services, which can be expressed as
Our goal is to minimize the average delay of edge computing networks. In the considered UAV-assisted edge computing network, the matching of UEs and ECSs has a crucial impact on the waiting delay and processing delay. Also, the choice of UAV hovering position determines the maximum sending rate and affects the sending delay. Therefore, we consider establishing the optimization problem for joint UE–ECS matching and deployment of three hovering positions of UAVs. Specifically, the problem is modeled as follows:
where the optimization variables are the three UAV deployment locations,
, and the matching of the UEs,
. The first constraint is that the UAV needs to hover within a reasonable range,
; the second constraint is that the user needs to select the ECSs present in the network for matching, in which
represents the matching of the UEs,
k; and the last constraint is that each edge user can select only one ECS for matching.
4. PPO-Based Joint Optimization Algorithm
We provided the optimization problem for joint UE–ECS matching and deployment of UAVs with three hovering positions in the previous section. However, it can be observed by looking at the problem model that the problem is a complex mixed integer nonlinear programming problem, which is usually difficult to solve by traditional optimization methods. Fortunately, the advancement of artificial intelligence has introduced novel research techniques for mobile edge computing. PPO has gained widespread acceptance as a reinforcement learning algorithm due to its stability and reliability. In contrast to traditional policy gradient algorithms and other RL algorithms based on the actor-critic framework, PPO incorporates an older actor network to constrain the variance of the new policy. This approach effectively mitigates instability issues that could potentially arise in other algorithms. Secondly, the PPO algorithm can consistently perform well in various environments and can effectively suit the UAV-assisted edge computing environment that is being studied. Hence, in this work, we consider designing solution algorithms for joint optimization based on the PPO framework. Specific algorithmic details are given next.
Note that deep reinforcement learning frameworks, including PPO, can usually only handle discrete or continuous decision problems. However, the joint optimization problem in this work is mixed integer programming with both discrete and continuous variables, which is difficult to handle for PPO. Therefore, we first introduce matching factors to convert the original mixed integer programming into a continuous variable problem. We design
M matching factors for each UE, which represent the matching priority of each of the
M ECSs at that UE. The value range of the matching factors is
. Following this design principle, the matching factors of UE
k are
; then, the ECS matched by UE
k is the one with the largest matching factor, denoted by
So far, the original integer variable is transformed into a continuous variable, i.e., the matching factor, and the original problem is transformed into a continuous-variable decision process that can be solved by the PPO implementation. We first model the problem as a Markov decision process, where the state space, action space, state transfer function, and reward function are described as follows.
State space: the environment is described to the agent body by the state space, which needs to provide enough information to make the agent body take appropriate actions. For the considered UAV-assisted edge computing network, the hovering position of the UAV determines the sending delay, while the matching of the UE and the ECS determines the processing delay and the waiting delay. Therefore, the state space designed in this work contains the following points: the three-dimensional hovering position of the UAV and the matching factor at all UEs. The state space is defined as , and the state at time step t is defined as .
Action space: based on the decision variables and state space in the problem model, we design the action space for the problem. The action space also contains two parts: one is the displacement of the UAV in three-dimensional space, and the other is the amount of change of the matching factor. The action space is defined as , and the state at time step t is defined as .
State transfer probability function: according to the state and action of the agent body designed above, the next state of the agent body can be obtained from its current state plus the action, i.e., the current three-dimensional position of the UAV base station plus the displacement to the next three-dimensional position. Therefore, the state transfer probability function is defined as
Reward function: the designed PPO-based joint optimization algorithm aims to minimize the average delay of the UAV-assisted edge computing network. Therefore, the average delay is designed as the body of the reward function. Meanwhile, in order to make the agent body transfer minimize the average delay, the average delay exists in the form of the opposite number in the reward function. Specifically, the reward function is expressed as
where
p and
q are constant terms to adjust the reward value to within a suitable range.
Based on the modeling of the Markov decision process, the agent body can perform actions to obtain the reward value and complete the state transfer. The agent body in the PPO algorithm collects the state transfer trajectories for every T time steps, then performs a round of updating. Each round of updating uses the group of trajectory data to update D times, and the object of the updating is the parameter of the Actor network and the parameter of the Critic network.
The role of the Actor network is to fit the agent’s policy
, representing the policy in the form of a Gaussian distribution, which can be fully described by its mean
and standard deviation
. Then, the Actor network completes the state to
mapping. When the intelligence needs to take an action, it first recovers that Gaussian distribution through
and then randomly samples to pick an action. The PPO, in order to keep the old policy unchanged in each round of update, initializes a network with the same structure and parameters as the Actor network, called Actor-old. The Actor-old network does not participate in training and only copies parameters from the Actor network before each round of updates to keep the old strategy
for the current round; then, the Actor network can continue searching for the new strategy
. The Actor network is trained to maximize the agent objective function, whose parameters are given by the following equation update
where
k denotes the first round of update and
is the dominance function calculated based on the state value estimated by the Critic network and the temporal difference method, where
and
are the reward value of the time step and the state value of
, respectively.
The Critic network completes the estimation of the state value
, and its training objective is to minimize the loss function based on the mean square error. Then, its parameter
is updated by the following equation:
where
is the accumulated reward computed from the state transfer trajectory data. Based on the above neural network design, the basic framework of PPO is built.
According to the above description, both the main framework and Markov decision process of the PPO algorithm have been designed. Next, we reduce the average delay of the network by jointly optimizing the UE–ECS matching and the UAV three-dimensional hovering position. The designed optimization algorithm is called the PPO-based joint optimization algorithm, and the detailed algorithm flow is shown in Algorithm 1.
| Algorithm 1 PPO-based joint optimization algorithm |
- 1:
Initialize the parameters and of the Actor network and Critic estimation network; initialize the Actor-old network. - 2:
for each training round do - 3:
Initialize the three-dimensional position of the UAV and the matching factor. - 4:
for each time step t do - 5:
UAV base station observes its own three-dimensional position and reads matching factor as state . - 6:
Actor inputs and outputs a Gaussian distribution for the strategy; the agent body recovers the strategy and randomly selects an action . - 7:
Calculate the average delay of the system and obtain the reward value. - 8:
Agent body implements action and updates to the next state . - 9:
Collect the state transfer trajectory into the cache. - 10:
Based on the output of the Critic network and the reward value of each time step in the cache, backtrack to calculate the state value of the corresponding time step. - 11:
Copy the parameters of the Actor network to the Actor-old network to maintain the old policy. - 12:
for do - 13:
Update the parameters of Actor network and Critic network. - 14:
end for - 15:
end for - 16:
end for - 17:
Return: UAV hover position, match factor, and average delay.
|
5. Simulation Results
In this work, we simulate and validate the designed UAV-assisted edge computing network. We consider the presence of
UEs and
ECSs in a square cell of length 400 m. The UAV hovers over the cell and is at an altitude between 40 m and 200 m. The carrier frequency is set to
MHz, the bandwidth is 1 MHz, and the noise power spectral density is −174 dBm/Hz. The air-to-ground channel is set with reference to the commonly used environment, i.e.,
,
,
, and
. The UEs and ECSs are generated using a hybrid process of uniform randomization plus Gaussian randomization. This is because, if the users were completely uniformly distributed in the region, it would make the planar location deployment of the UAVs not optimized. The PPO-related parameter settings are shown in
Table 1.
We plot the change in reward values during training of the PPO-based joint optimization algorithm in
Figure 2. The vertical coordinate is the cumulative reward value per 200 time steps, and the horizontal coordinate is the time step. It can be seen that all three curves increase gradually with the increase in time steps and stabilize at three million time steps. The above changes can effectively illustrate that the proposed PPO-based joint optimization algorithm has good convergence properties. Meanwhile, the trend of the reward increasing with time steps also verifies the effectiveness of the proposed algorithm in UAV-assisted edge computing networks. The 3 curves in the figure correspond to varying transmission power levels, where training processes 1, 2, and 3 correspond to transmit power levels of 1.5 W, 1 W, and 0.5 W. As the figure illustrates, the reward value initially increases with the increase in power, implying that increasing power can achieve better system performance to some extent.
Figure 3 plots the average delay versus transmit power for the UAV-assisted edge computing network, where PBJO stands for the proposed PPO-based joint optimization algorithm. Baseline 1 is the greedy scheme, in which the UEs always choose the ECS closest to the UAV, and the UAV hovers in the center of the cell. Baseline 2 is the stochastic scheme, in which the UEs are randomly matched with the ECSs, and the UAV randomly chooses the hovering location. The figure shows that, as transmit power increases, the average delay typically decreases. This is because higher transmit power facilitates increased communication rates, which ultimately reduces transmission delays. Notably, the effect of transmit power on the average delay in Baseline 1 is minimal. In this scheme, all UEs select the ECS closest to the UAV for matching. This results in an average delay that is dominated by waiting time. However, it has been observed that the proposed scheme consistently achieves a lower average delay, which implies a superior edge computing service experience. For instance, at a transmission power of 1 Watt, the PBJO scheme achieves an average delay of approximately 0.88 s, which is 0.12 and 0.3 s lower than Baseline 1 and Baseline 2, respectively. Although the waiting delay in Baseline 1 is on the high side, its average delay is still lower than that of Baseline 2, which shows the necessity of optimizing the three hovering positions of the UAV.
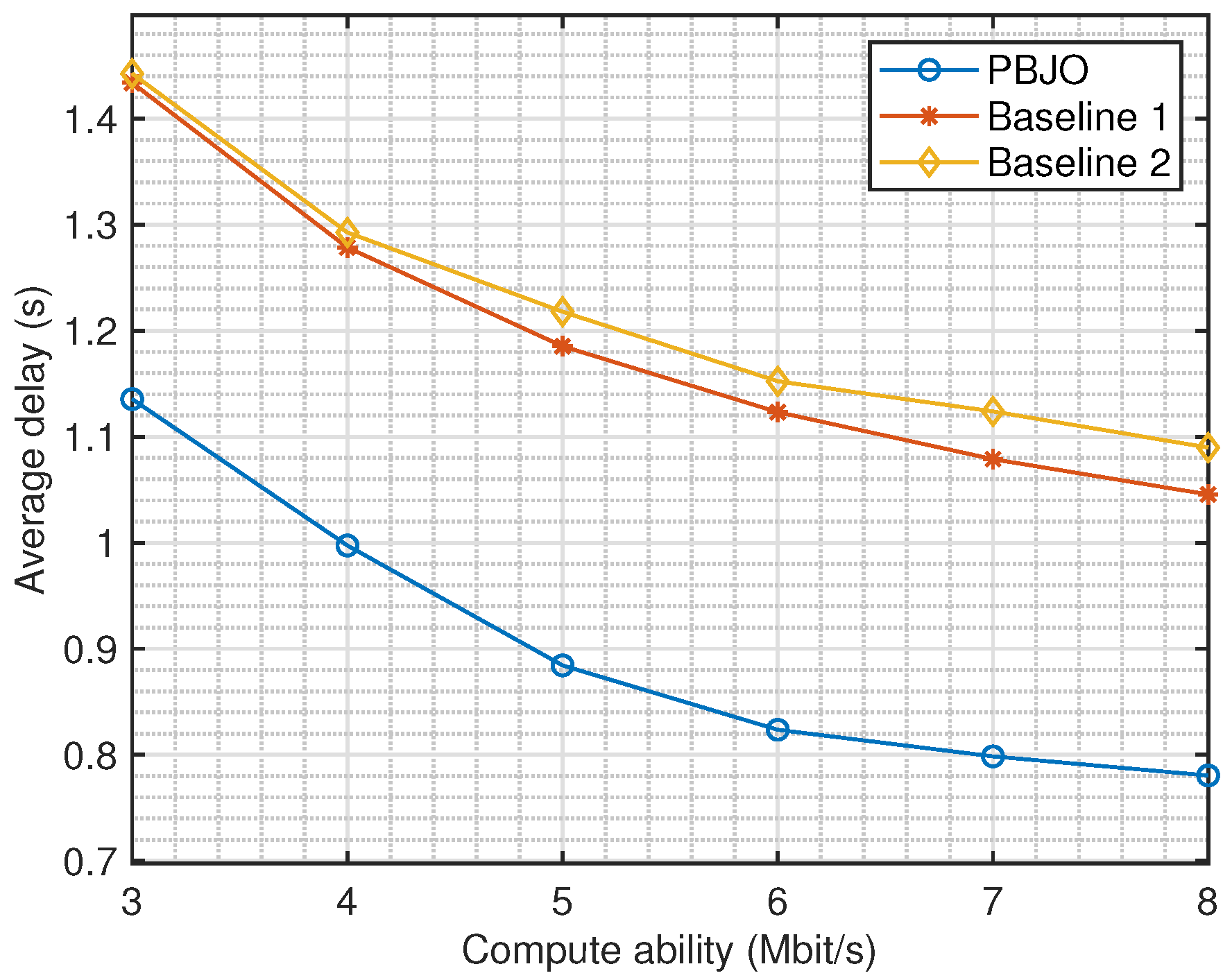
Figure 4 plots the variation in the average delay of the UAV-assisted edge computing network versus the computational ability of the ECS. The average latency consistently decreases with increased computational power, aligning with our expectations. This is due to the ECS’s ability to process tasks more quickly with greater computational power, effectively reducing the waiting latency of the edge computing network. Similarly, the proposed PPO-based joint optimization algorithm achieves a lower average delay compared to Baseline 1 and Baseline 2, which verifies the superiority of the proposed algorithm. At 1 Mbps, PBJO decreases latency by 0.3 s compared to the baseline scenarios, and the performance gap widens with increasing computing power. In addition, as the computational ability increases, we can observe that the trend of the average delay gradually flattens out. This is because the computational ability affects the waiting delay. Therefore, the significance of the delay change due to increasing computing ability gradually decreases relative to the total delay.
To further examine how deployment of ECSs affects the UAV-aided edge computing network under consideration, we plotted the changes in the average latency in
Figure 5 with the number of ECSs. As anticipated, the average latency consistently decreases with an increase in the number of ECSs. An increase in ECSs will significantly enhance network computation, resulting in a reduction in the average latency. However, it is worth noting that there is a limit to the benefits of increasing ECSs. Specifically, deploying 6 ECSs only results in a reduction of around 0.2 s. When there are five or more ECSs, increasing the number of ECSs does not significantly reduce the average latency. This is because queuing is eliminated in the network when there are sufficient ECSs, and the latency of the network is mainly determined by the sending latency. The above event highlights the significance of logically strategizing the number of ECSs deployed, which is also a notable aspect of edge computing research. Furthermore, it is observed that the PBJO algorithm achieves a lower average delay than the two extreme algorithms, reaffirming its superiority. We have observed a fascinating phenomenon in which the disparity between PBJO and the other baseline algorithms initially rises and then falls in correlation with the number of ECSs. Specifically, with only one ECS, PBJO lags behind the other algorithms by a mere 0.1 s. However, PBJO boasts the most significant improvement when the number of ECSs is 2, achieving a decrease of 0.5 s. As the number of ECSs hits 6, the gap between the algorithms goes back to 0.1 s. When there are only a few ECSs, matching UEs and ECSs has minimal impact on system performance, and joint optimization brings only marginal improvement. However, as the number of ECSs increases, the computational offloading strategy plays a bigger role, and the benefits of employing PBJO become fully apparent. Further, when a large number of ECSs are present, the effect of computation offloading becomes minimal, and the gap between algorithms decreases accordingly.
Additionally, we plotted the trend of average delay based on the number of UEs in
Figure 6. Clearly, the average delay constantly rises with an increase in UEs. It is undeniable that a greater quantity of UEs equals a heavier load on the network, causing a higher average delay. Furthermore, we observe an interesting phenomenon where the average delay produced by the PBJO algorithm experiences a significant increase whenever the number of UEs surpasses a multiple of three. For instance, the average delay increases from 1.15 s to 1.55 s when the number of UEs rises from 9 to 10, which is 5 times greater than when the number of UEs increases from 10 to 11. This is because there are three ECSs in the simulation environment. As a result, an additional UE means that one ECS will have to manage four UEs, thus leading to a rise in the average network delay. Furthermore, the figure illustrates that PBJO exhibits a decrease of at least 0.15 s in comparison to the two baseline algorithms, thereby confirming the algorithm’s efficacy.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}