




Performance Comparison of Deep Learning Models for Damage Identification of Aging Bridges


Abstract
:1. Introduction
1.1. Research Background
1.2. Scope and Methods of Research
2. Related Works
2.1. Bridge-Damage Identification Using Deep Learning
2.2. Loss Values of Deep Learning Models
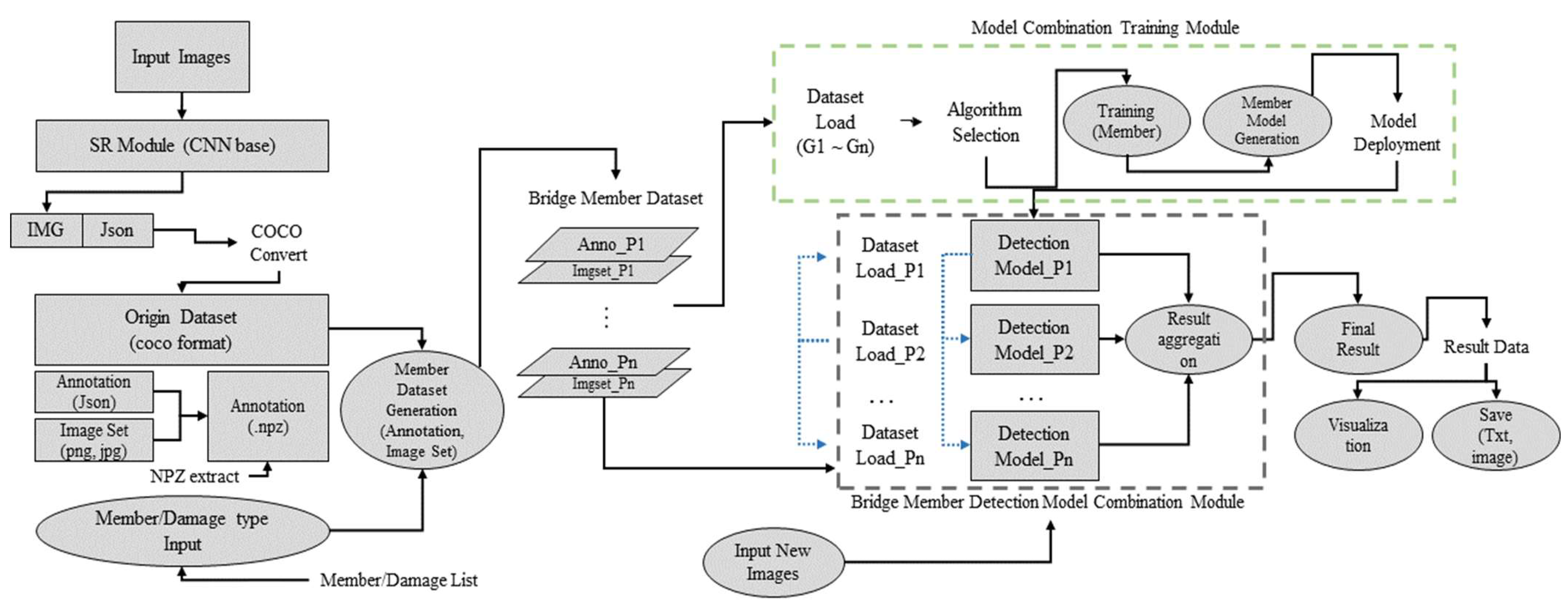
3. Proposed Framework
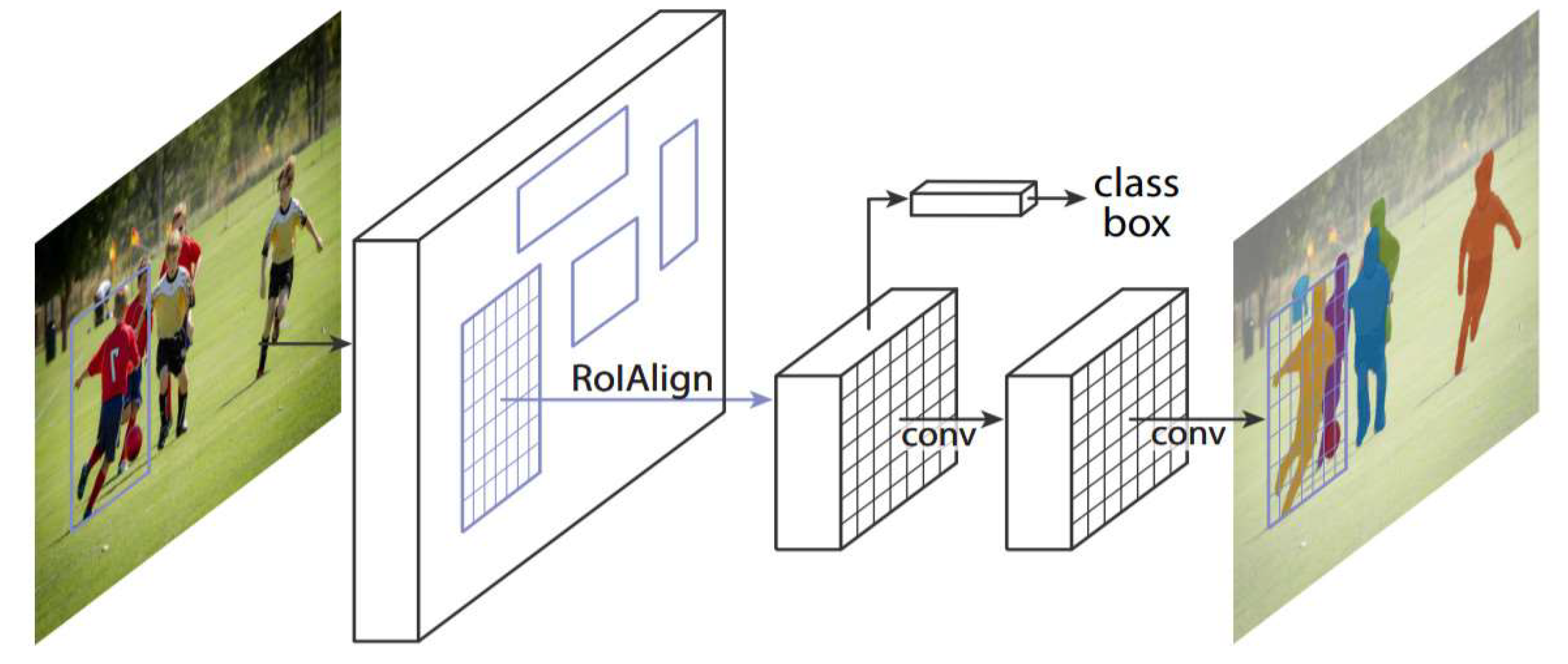
3.1. Mask R-CNN
- Region Proposal Network (RPN): Like Faster R-CNN, Mask R-CNN begins with an RPN to suggest object regions in the image, predicting locations where objects are likely to be present.
- RoIAlign: This accurately maps the RoI. It replaces RoIPool to improve pixel alignment accuracy, enabling accurate mask prediction during instance segmentation.
- Mask Head: This component predicts the segmentation mask at the pixel level for the object within each RoI, along with the object’s bounding box. It consists of a CNN-based fully convolutional network that generates the mask using the feature map within the given RoI.
3.2. BlendMask
- High Accuracy: BlendMask’s superior performance on the COCO dataset is because of its two-branch structure (IMB and SMB) and the integration of a RoI transformer and soft proposal generator, which together enhance the accuracy of segmentation boundaries.
- High Speed: The use of a RoI transformer, instead of traditional RoI pooling, contributes to BlendMask’s fast processing capabilities. Additionally, its ability to maintain accuracy with fewer parameters enables high performance in memory-constrained environments.
- Scale Invariance: BlendMask’s scale invariance ensures consistent performance across multiple image sizes, a feature influenced by the pre-trained models; this allows BlendMask to maintain high accuracy at various image sizes.
- Multi-Object Segmentation: BlendMask’s capability to segment multiple objects within a single image is a huge advantage in both commercial processes and computer vision.
- Small Training-Data Requirement: Typically, instance-segmentation models necessitate extensive labeling of training data, particularly in specific domains. BlendMask can achieve high performance with a limited dataset by using techniques that reduce the demand for a large amount of labeled data.
3.3. SWIN
- Window-Based Self-Attention: SWIN segments the input image into grids and performs self-attention within each, facilitating the integration of local context and global image structure.
- Shifted Window: It employs a hierarchical strategy to enlarge each window incrementally through shifting operations, capturing a variety of resolutions and contextual information.
- Tokenization and Patch Embedding: The model converts the image into a series of patches, which undergo tokenization and embedding processes.
- Hierarchical Feature Fusion: SWIN utilizes a technique for merging features across different scales hierarchically, attaining various resolutions and spatial diversities.
- Mask R-CNN focuses on object detection and pixel-level segmentation for accurate and reliable results.
- BlendMask builds on Cascade Mask R-CNN, utilizing an ensemble technique to combine multi-stage network outputs and mask predictions.
- SWIN leverages a vision transformer architecture, combining window-based self-attention with hierarchical feature mapping.
4. Experiment and Results
4.1. Experimental Environment
- CPU: Intel(R) Core(TM) i7-10900k CPU 2.90 GHz
- RAM: 96 GB
- GPU: NVIDIA GeForce RTX3090
4.2. Hyperparameters
4.3. Measurement Method
- Mean Squared Error: Employed in regression problems, it is calculated by squaring the differences between predicted and actual values; these squares are then averaged.
- Cross-Entropy Loss: This function is mainly used in classification problems to measure the differences between the predicted-probability distribution and the actual class labels. Binary cross-entropy is typically used for binary classification, while categorical cross-entropy is suited for multi-class scenarios.
- Log-Likelihood Loss: Often used in generative models, this function seeks to maximize the logarithm of the likelihood of the predicted probabilities matching the actual data.
- Custom loss–function for specific tasks: Such functions are tailored to specific problems. The composite loss–function in Mask R-CNN is an example; it is designed for concurrent object classification, bounding box regression, and mask segmentation.
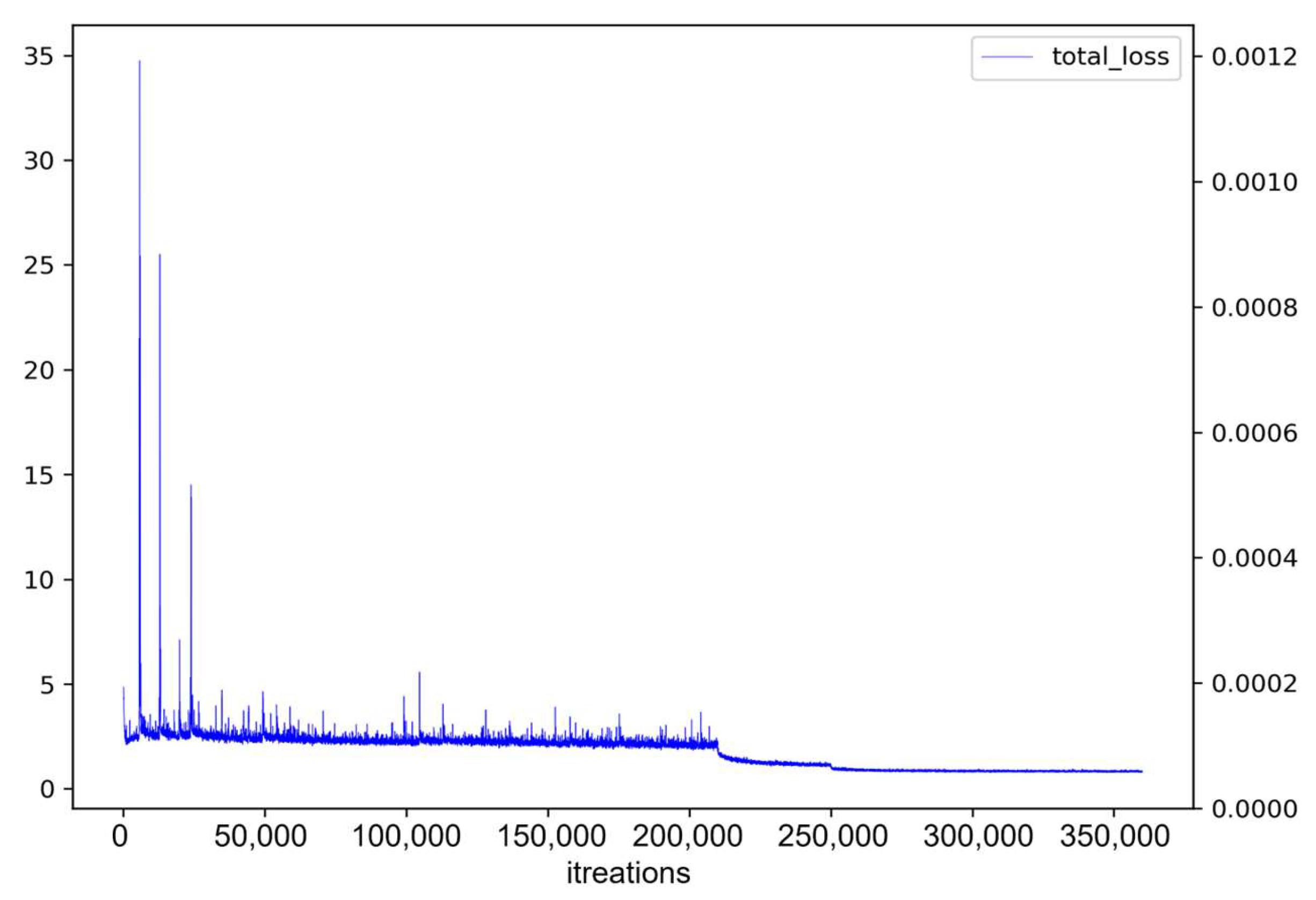
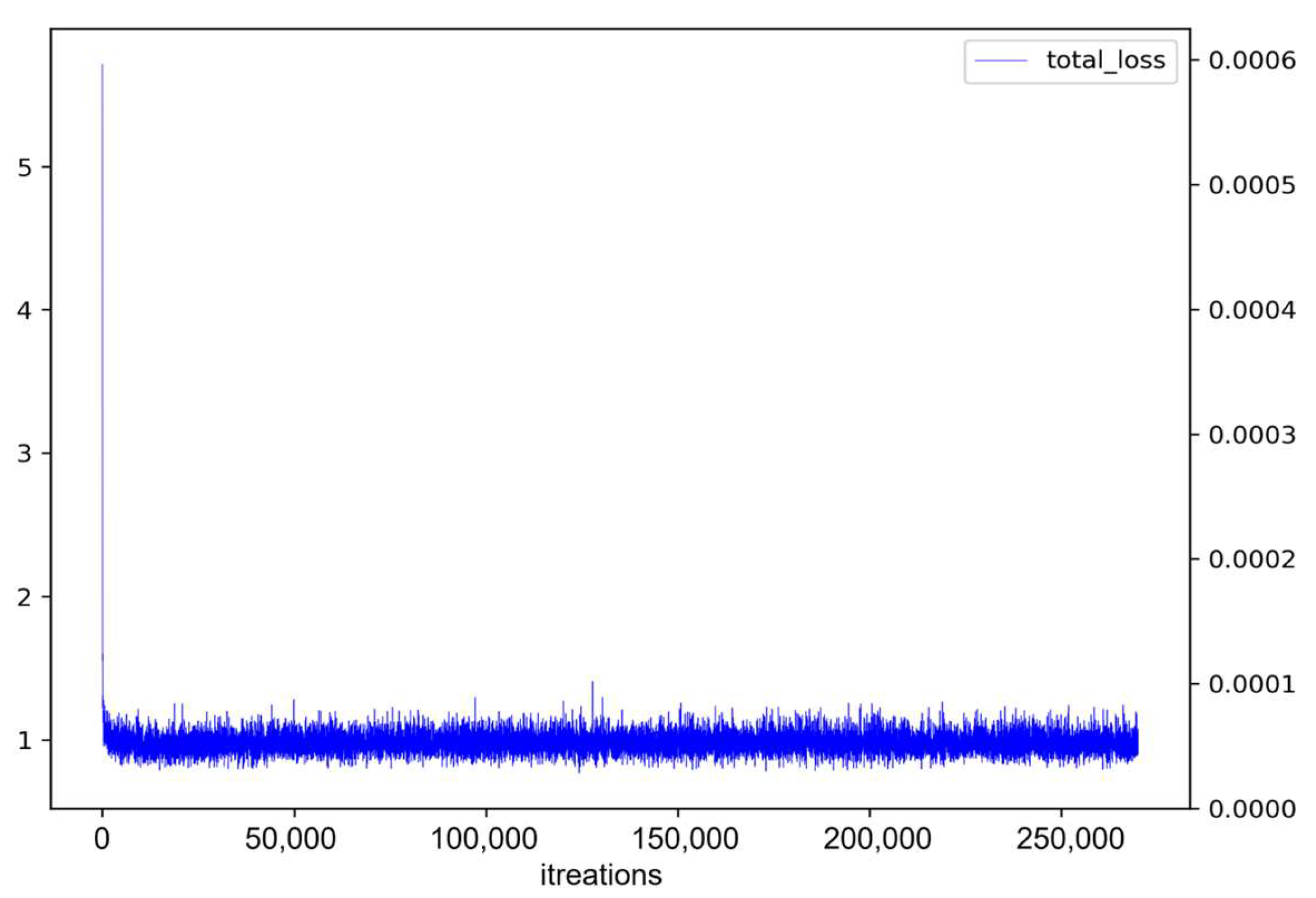
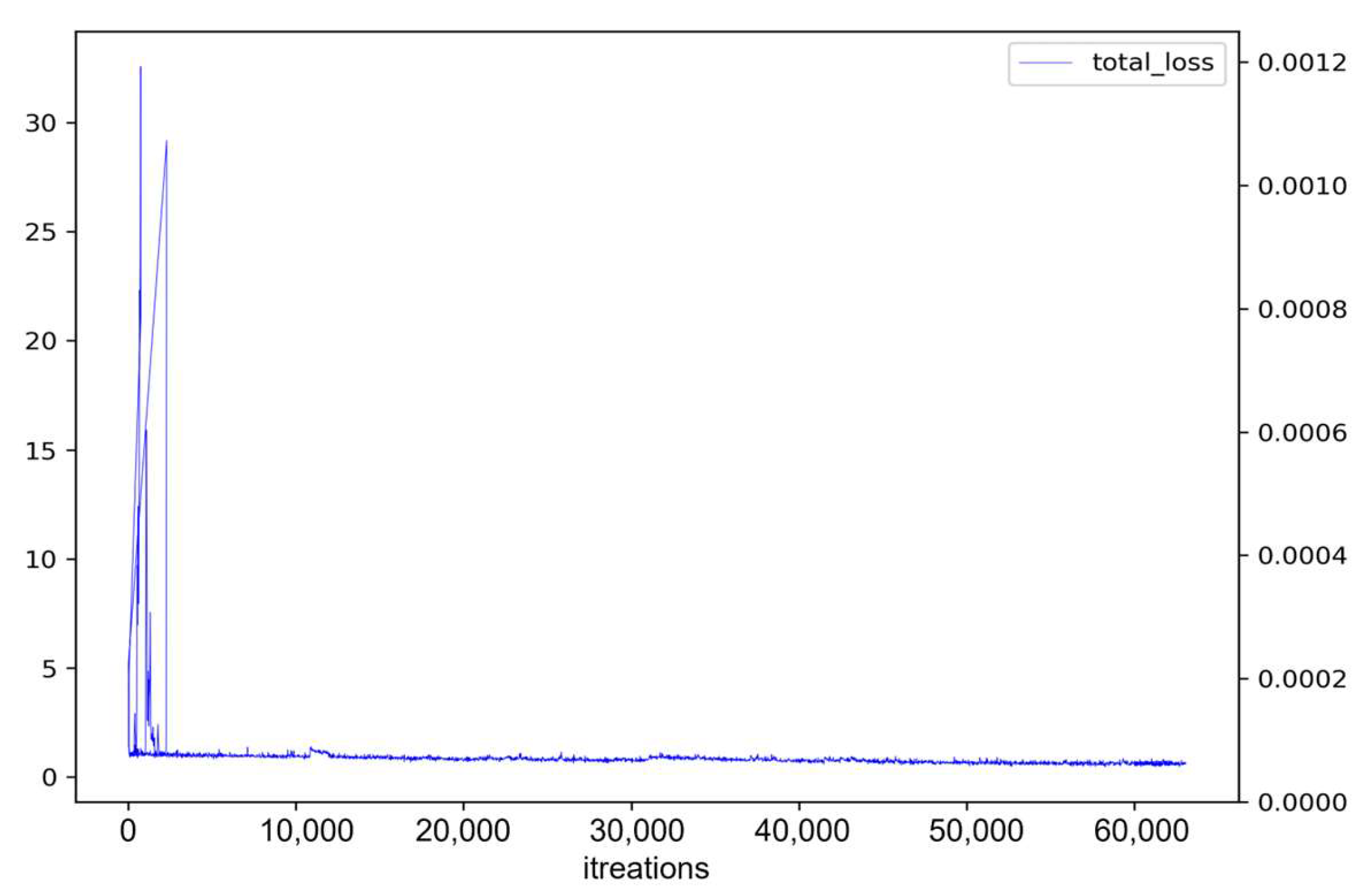
4.4. Comparison of Mask R-CNN and BlendMask
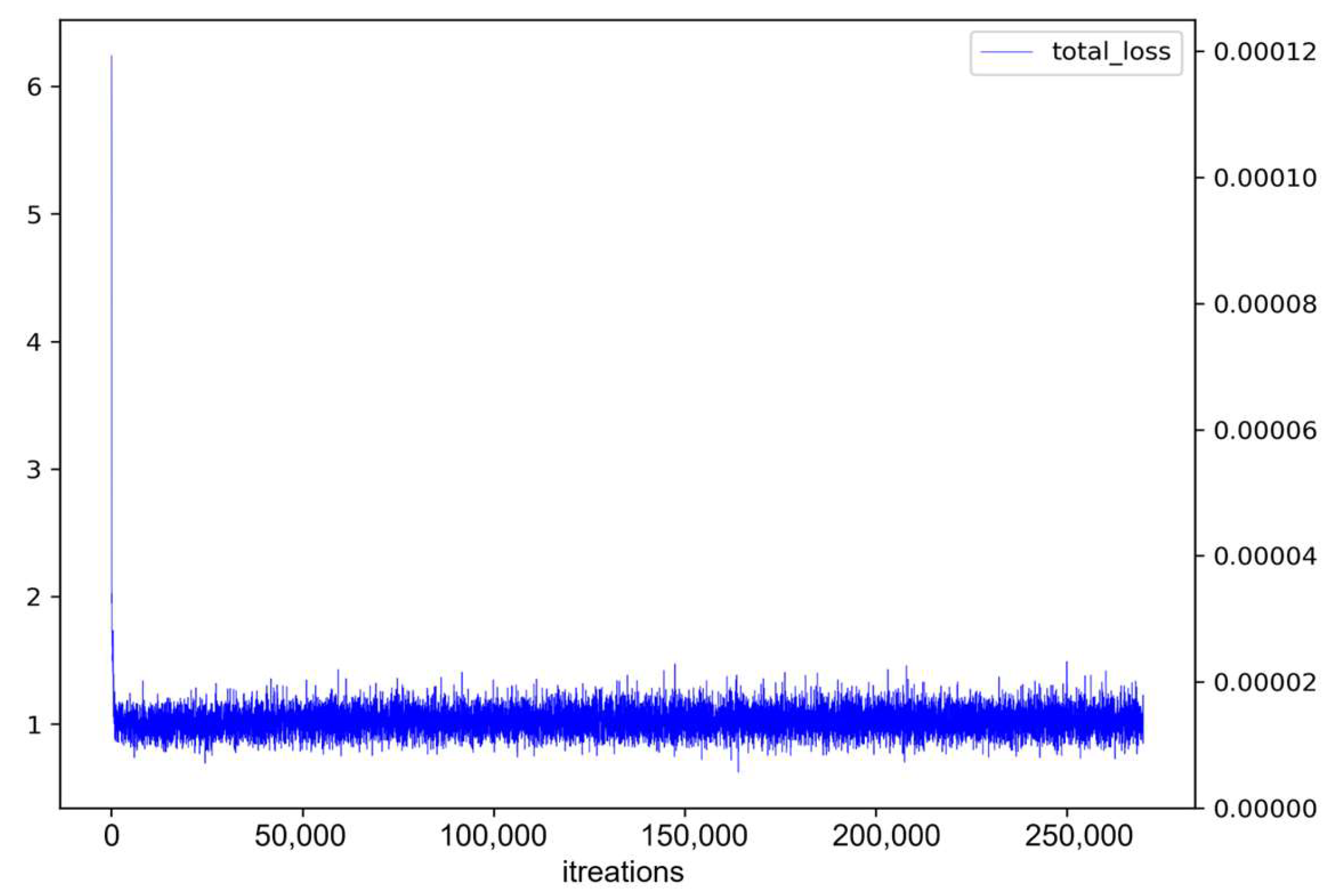
4.5. Comparison of Mask R-CNN and SWIN
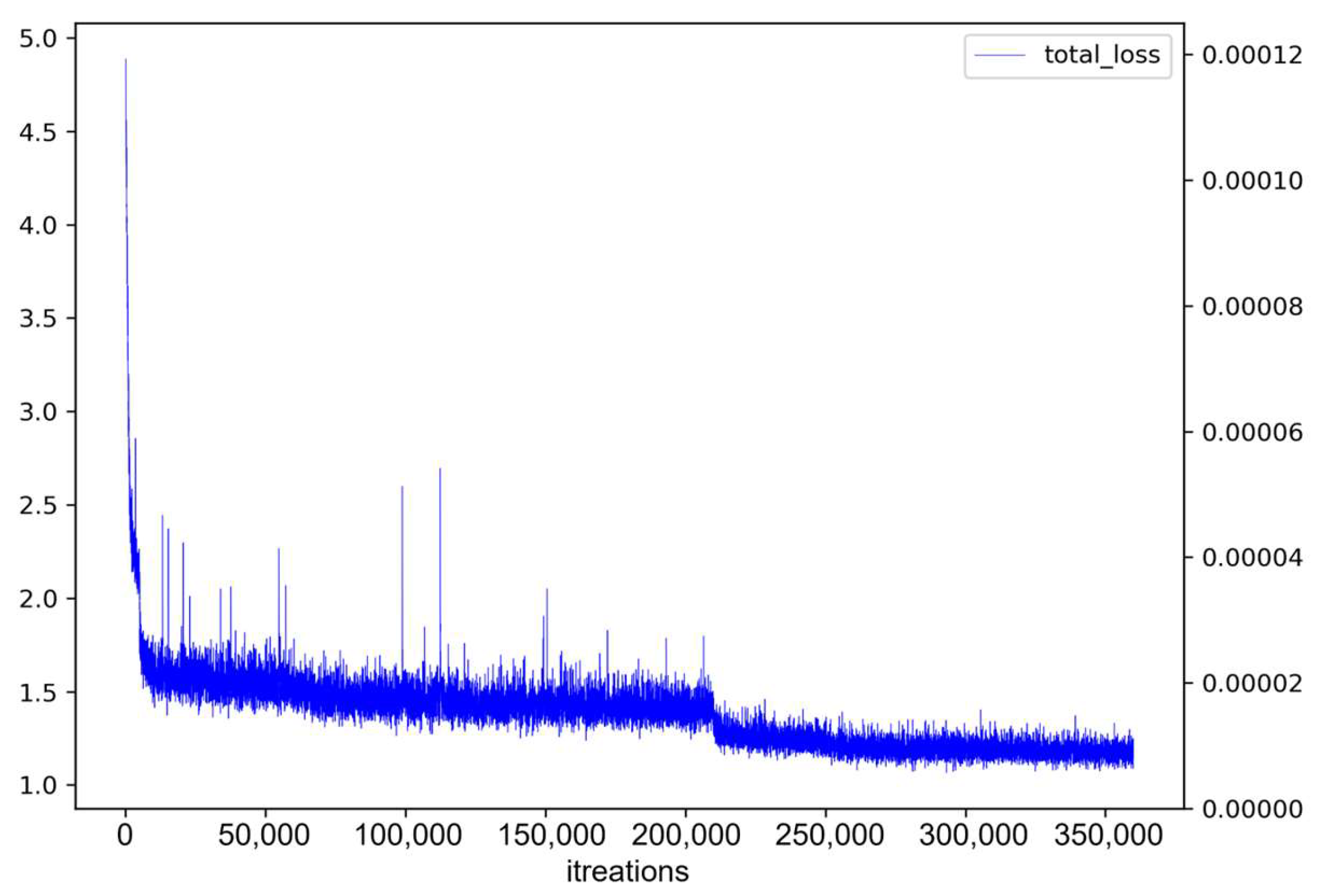
4.6. Comparison of Mask R-CNN, BlendMask, and SWIN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mishra, M.; Lourenço, P.B.; Ramana, G.V. Structural health monitoring of civil engineering structures using the Internet of things: A review. J. Build. Eng. 2022, 48, 103954. [Google Scholar] [CrossRef]
- Morishige, H.; Tanaka, S. Nondestructive inspection of concrete structures using ultrasonic sensor. In Proceedings of the of the SICE 2004 Annual Conference, 4–6 August 2004; IEEE: New York, NY, USA, 2004; Volume 2, pp. 1890–1895. [Google Scholar]
- Tao, Y.; Shi, J.; Guo, W.; Zheng, J. Convolutional Neural Network Based Defect Recognition Model for Phased Array Ultrasonic Testing Images of Electrofusion Joints. J. Press. Vessel. Technol. 2023, 145, 024502. [Google Scholar] [CrossRef]
- Yang, J.; Xiang, F.; Li, R.; Zhang, L.; Yang, X.; Jiang, S.; Zhang, H.; Wang, D.; Liu, X. Intelligent bridge management via big data knowledge engineering. Autom. Constr. 2022, 135, 104118. [Google Scholar] [CrossRef]
- Inam, H.; Islam, N.U.; Akram, M.U.; Ullah, F. Smart and automated infrastructure management: A deep learning approach for crack detection in bridge images. Sustainability 2023, 15, 1866. [Google Scholar] [CrossRef]
- Lingxin, Z.; Junkai, S.; Baijie, Z. A review of the research and application of deep learning-based computer vision in structural damage detection. Earthq. Eng. Eng. Vib. 2022, 21, 1–21. [Google Scholar] [CrossRef]
- Su, Y.; Wang, J.; Li, D.; Wang, X.; Hu, L.; Yao, Y.; Kang, Y. End-to-end deep learning model for underground utilities localization using GPR. Autom. Constr. 2023, 149, 104776. [Google Scholar] [CrossRef]
- Kerle, N.; Nex, F.; Gerke, M.; Duarte, D.; Vetrivel, A. UAV-based structural damage mapping: A review. ISPRS Int. J. Geo Inf. 2019, 9, 14. [Google Scholar] [CrossRef]
- Hong, S.S.; Hwang, C.H.; Chung, S.W.; Kim, B.K. A deep-learning-based bridge damaged object automatic detection model using a bridge member model combination framework. Appl. Sci. 2022, 12, 12868. [Google Scholar] [CrossRef]
- Kim, B.; Yuvaraj, N.; Sri Preethaa, K.R.; Arun Pandian, R. Surface crack detection using deep learning with shallow CNN architecture for enhanced computation. Neural Comput. Appl. 2023, 33, 9289–9305. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Jassmi, H.A.; Gocho, M.; Khan, W.; Serhani, M.A. Performance evaluation of deep CNN-based crack detection and localization techniques for concrete structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef] [PubMed]
- Hong, S.S.; Hwang, C.; Chung, S.W.; Kim, B.K. A deep learning-based bridge damaged objects automatic detection model using bridge members model combination framework. JNCIST 2023, 12, 105–118. [Google Scholar] [CrossRef]
- Liu, K.; Han, X.; Chen, B.M. Deep learning based automatic crack detection and segmentation for unmanned aerial vehicle inspections. In Proceedings of the 2019 IEEE International Conference Robot. Biomim (ROBIO), Dali, China, 6–8 December 2019; pp. 381–387. [Google Scholar] [CrossRef]
- Da Silva, W.R.L.; de Lucena, D.S. Concrete cracks detection based on deep learning image classification. Proceedings 2018, 2, 489. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, H.; Wang, S.; Li, Y.; Wang, H.; Yan, F. Structural damage detection using deep convolutional neural network and transfer learning. KSCE J. Civ. Eng. 2019, 23, 4493–4502. [Google Scholar] [CrossRef]
- Aslam, S.; Ayub, N.; Farooq, U.; Alvi, M.J.; Albogamy, F.R.; Rukh, G.; Haider, S.I.; Azar, A.T.; Bukhsh, R. Towards electric price and load forecasting using cnn-based ensembler in smart grid. Sustainability 2021, 13, 12653. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.A.; Waller, S.T.; Islam, M.R. Modern crack detection for bridge infrastructure maintenance using machine learning. Hum.-Cent. Intell. Syst. 2022, 2, 95–112. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Gabbouj, M.; Inman, D.J. A review of vibration-based damage detection in civil structures: From traditional methods to machine learning and deep learning applications. Mech. Syst. Signal Process. 2021, 147, 107077. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Bjorck, N.; Gomes, C.P.; Selman, B.; Weinberger, K.Q. Understanding batch normalization. Adv. Neural Inf. Process. Syst. 2018, 31, 1–12. [Google Scholar]
- Kukačka, J.; Golkov, V.; Cremers, D. Regularization for Deep Learning: A Taxonomy. arXiv 2017, arXiv:1710.10686. Available online: https://arxiv.org/abs/1710.10686 (accessed on 19 June 2021).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. Blendmask: Top-down meets bottom-up for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8570–8578. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Common Parameters |
|---|
| MODEL: BACKBONE: NAME: “build_resnet_fpn_backbone” RESNETS: DEPTH: 50 OUT_FEATURES: [“res2”, “res3”, “res4”, “res5”] FPN: IN_FEATURES: [“res2”, “res3”, “res4”, “res5”] ANCHOR_GENERATOR: SIZES: [[32], [64], [128], [256], [512]] # One size for each in feature map ASPECT_RATIOS: [[0.5, 1.0, 2.0]] # Three aspect ratios (same for all in feature maps) ROI_HEADS: NAME: “StandardROIHeads” IN_FEATURES: [“p2”, “p3”, “p4”, “p5”] SOLVER: IMS_PER_BATCH: 2 STEPS: (210000, 250000) MAX_ITER: 270000 WEIGHT_DECAY: 0.05 BASE_LR: 0.001 INPUT: MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chung, S.-W.; Hong, S.-S.; Kim, B.-K. Performance Comparison of Deep Learning Models for Damage Identification of Aging Bridges. Appl. Sci. 2023, 13, 13204. https://doi.org/10.3390/app132413204
Chung S-W, Hong S-S, Kim B-K. Performance Comparison of Deep Learning Models for Damage Identification of Aging Bridges. Applied Sciences. 2023; 13(24):13204. https://doi.org/10.3390/app132413204
Chicago/Turabian StyleChung, Su-Wan, Sung-Sam Hong, and Byung-Kon Kim. 2023. "Performance Comparison of Deep Learning Models for Damage Identification of Aging Bridges" Applied Sciences 13, no. 24: 13204. https://doi.org/10.3390/app132413204
APA StyleChung, S. -W., Hong, S. -S., & Kim, B. -K. (2023). Performance Comparison of Deep Learning Models for Damage Identification of Aging Bridges. Applied Sciences, 13(24), 13204. https://doi.org/10.3390/app132413204