
LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models

Abstract
:1. Introduction
- LWMD platform. In this paper, we propose the LWMD platform to design light-weight E2E ASR models, which consists of one LWAS framework to search light-weight architectures and one DSP algorithm to prune further searched architectures.
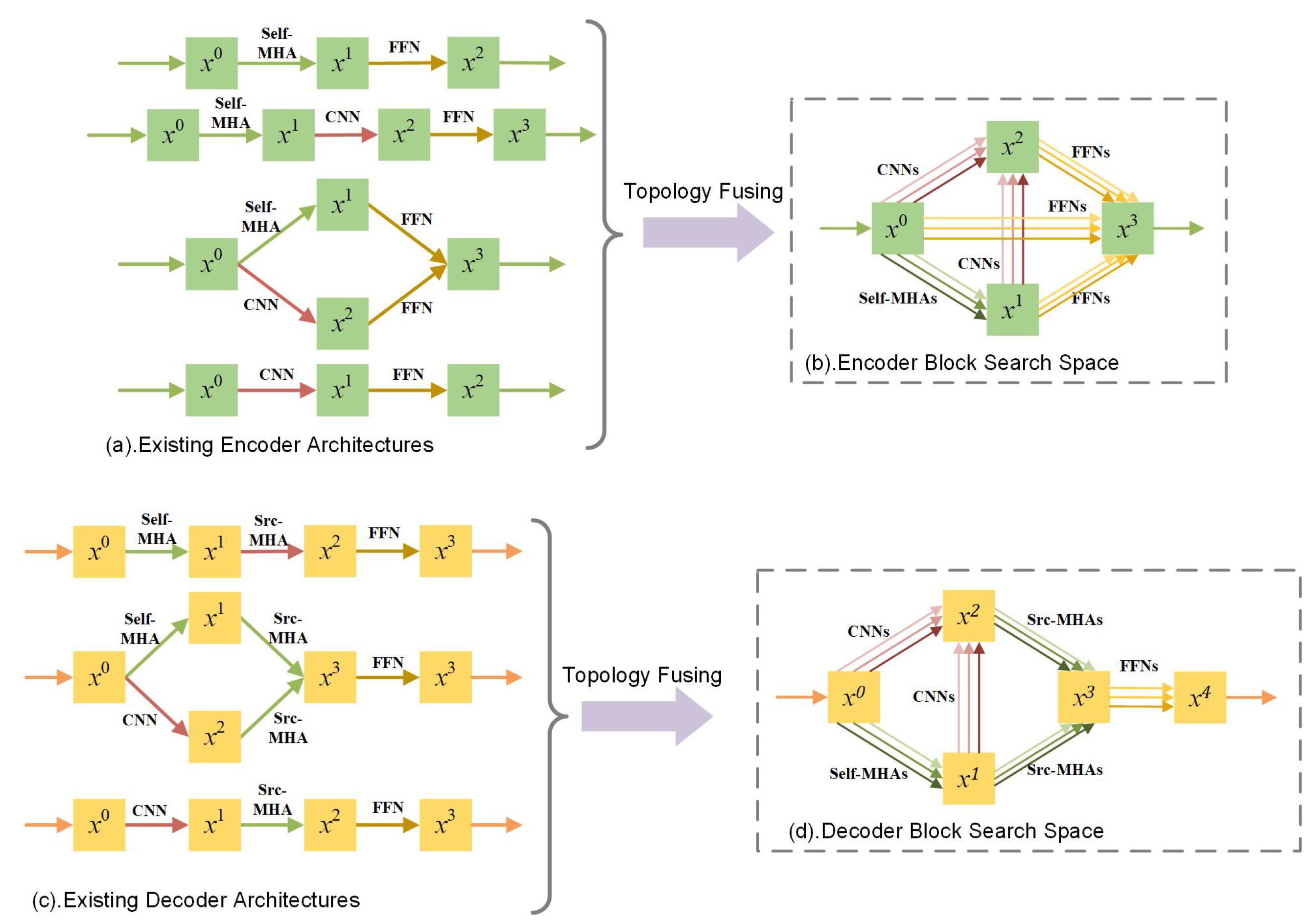
- The LWAS framework. By incorporating different topologies together, LWAS designs one topology-fused search space that can cover many human-designed architectures and develops a resource-aware differentiable search algorithm to select light-weight architectures from the search space.
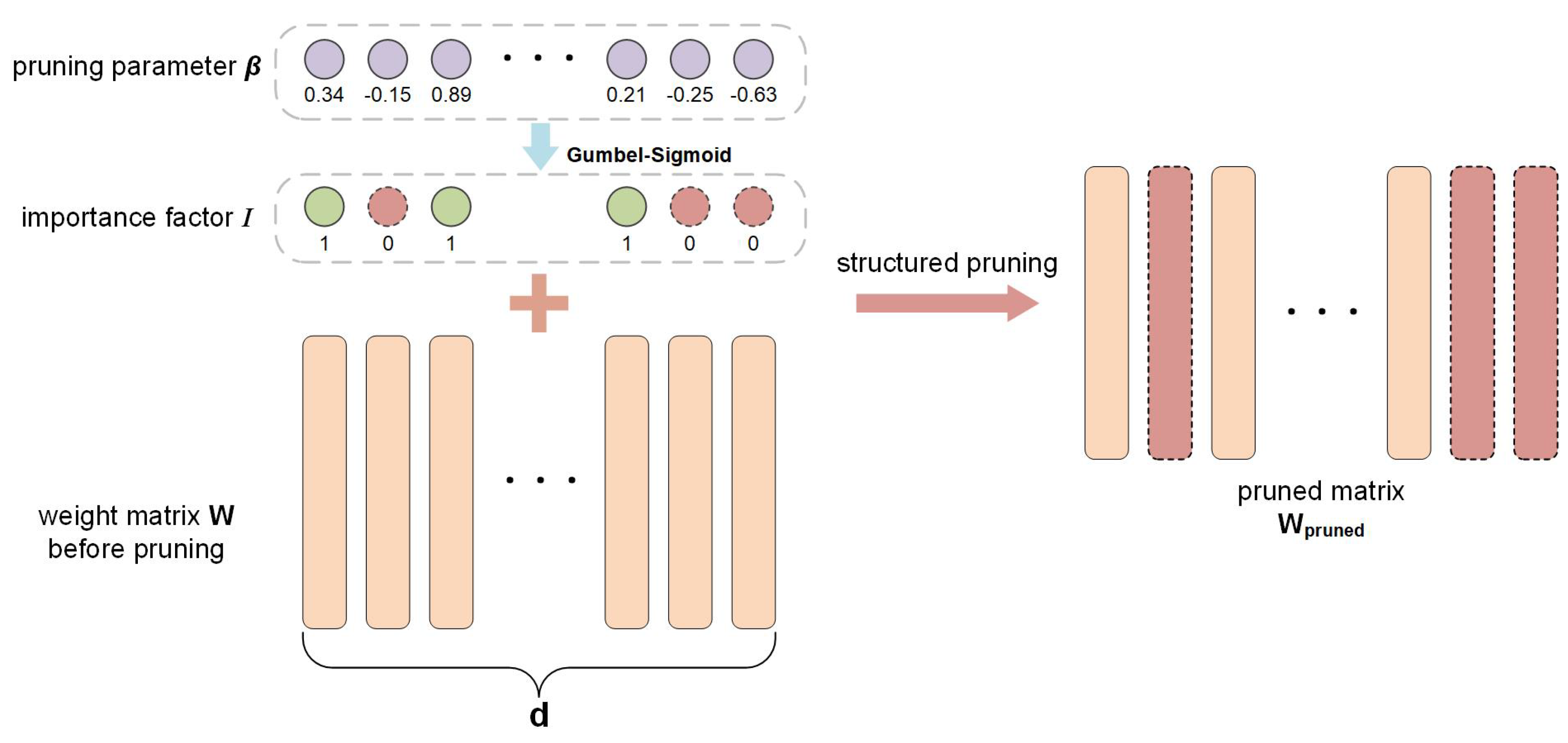
- The DSP algorithm. With the proposed differentiable pruning criterion, DSP can build a stronger correlation between the pruning criterion and the model performance. An additional attention-similarity loss function is specially developed for MHA modules to get better pruning performance.
- Extensive experiments demonstrate the effectiveness of LWMD in compressing E2E ASR models. More ablation and exploration explain the contributions of the LWAS framework and the DSP algorithm.
2. Related Works
2.1. E2E ASR Models
2.2. Model Compression
3. The Proposed Method
3.1. The LWAS Framework
3.1.1. Differentiable Architecture Search
3.1.2. The Topology-Fused Search Space
3.1.3. The Resource-Aware Search Algorithm
3.2. The DSP Algorithm
3.2.1. The Differentiable Pruning Criterion
3.2.2. The Attention-Similarity Loss Function
4. Experiments
4.1. Dataset and Model Implementation
4.2. Performance Comparisons
4.3. Ablation Study
4.3.1. The Proposed Search Space
4.3.2. The DSP Algorithm
4.4. Low-Bit Quantization
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Korkmaz, Y.; Boyacı, A. Unsupervised and supervised VAD systems using combination of time and frequency domain features. Biomed. Signal Process. Control 2020, 61, 102044. [Google Scholar] [CrossRef]
- Korkmaz, Y.; Boyacı, A. milVAD: A bag-level MNIST modelling of voice activity detection using deep multiple instance learning. Biomed. Signal Process. Control 2022, 74, 103520. [Google Scholar] [CrossRef]
- Korkmaz, Y.; Boyacı, A. Hybrid voice activity detection system based on LSTM and auditory speech features. Biomed. Signal Process. Control 2023, 80, 104408. [Google Scholar] [CrossRef]
- Hori, T.; Watanabe, S.; Hershey, J.R. Joint CTC/attention decoding for end-to-end speech recognition. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 518–529. [Google Scholar]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-art speech recognition with sequence-to-sequence models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; PMLR: New York, NY, USA, 2016; pp. 173–182. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Miao, H.; Cheng, G.; Zhang, P.; Yan, Y. Online hybrid CTC/attention end-to-end automatic speech recognition architecture. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1452–1465. [Google Scholar] [CrossRef]
- Cheng, G.; Miao, H.; Yang, R.; Deng, K.; Yan, Y. ETEH: Unified Attention-Based End-to-End ASR and KWS Architecture. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1360–1373. [Google Scholar] [CrossRef]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Wu, F.; Fan, A.; Baevski, A.; Dauphin, Y.N.; Auli, M. Pay less attention with lightweight and dynamic convolutions. arXiv 2019, arXiv:1901.10430. [Google Scholar]
- Wu, Z.; Liu, Z.; Lin, J.; Lin, Y.; Han, S. Lite transformer with long-short range attention. arXiv 2020, arXiv:2004.11886. [Google Scholar]
- Liu, Y.; Li, T.; Zhang, P.; Yan, Y. NAS-SCAE: Searching Compact Attention-based Encoders For End-to-end Automatic Speech Recognition. Proc. Interspeech 2022, 2022, 1011–1015. [Google Scholar]
- Gordon, M.A.; Duh, K.; Andrews, N. Compressing bert: Studying the effects of weight pruning on transfer learning. arXiv 2020, arXiv:2002.08307. [Google Scholar]
- Mao, Y.; Wang, Y.; Wu, C.; Zhang, C.; Wang, Y.; Yang, Y.; Zhang, Q.; Tong, Y.; Bai, J. Ladabert: Lightweight adaptation of bert through hybrid model compression. arXiv 2020, arXiv:2004.04124. [Google Scholar]
- Michel, P.; Levy, O.; Neubig, G. Are sixteen heads really better than one? Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://proceedings.neurips.cc/paper/2019/hash/2c601ad9d2ff9bc8b282670cdd54f69f-Abstract.html (accessed on 11 December 2022).
- Xue, J.; Li, J.; Yu, D.; Seltzer, M.; Gong, Y. Singular value decomposition based low-footprint speaker adaptation and personalization for deep neural network. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6359–6363. [Google Scholar]
- Dudziak, L.; Abdelfattah, M.S.; Vipperla, R.; Laskaridis, S.; Lane, N.D. Shrinkml: End-to-end asr model compression using reinforcement learning. arXiv 2019, arXiv:1907.03540. [Google Scholar]
- Zafrir, O.; Boudoukh, G.; Izsak, P.; Wasserblat, M. Q8bert: Quantized 8bit bert. In Proceedings of the 2019 Fifth IEEE Workshop on Energy Efficient Machine Learning and Cognitive Computing-NeurIPS Edition (EMC2-NIPS), Vancouver, BC, Canada, 13 December 2019; pp. 36–39. [Google Scholar]
- Zadeh, A.H.; Edo, I.; Awad, O.M.; Moshovos, A. Gobo: Quantizing attention-based nlp models for low latency and energy efficient inference. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 811–824. [Google Scholar]
- Bondarenko, Y.; Nagel, M.; Blankevoort, T. Understanding and overcoming the challenges of efficient transformer quantization. arXiv 2021, arXiv:2109.12948. [Google Scholar]
- Bhandare, A.; Sripathi, V.; Karkada, D.; Menon, V.; Choi, S.; Datta, K.; Saletore, V. Efficient 8-bit quantization of transformer neural machine language translation model. arXiv 2019, arXiv:1906.00532. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Xie, S.; Zheng, H.; Liu, C.; Lin, L. SNAS: Stochastic neural architecture search. arXiv 2018, arXiv:1812.09926. [Google Scholar]
- Lin, Y.; Li, Q.; Yang, B.; Yan, Z.; Tan, H.; Chen, Z. Improving speech recognition models with small samples for air traffic control systems. Neurocomputing 2021, 445, 287–297. [Google Scholar] [CrossRef]
- Xue, J.; Zheng, T.; Han, J. Convolutional Grid Long Short-Term Memory Recurrent Neural Network for Automatic Speech Recognition. In Proceedings of the International Conference on Neural Information Processing, Sydney, Australia, 12–15 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 718–726. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. arXiv 2015, arXiv:1506.07503. [Google Scholar]
- Xue, J.; Zheng, T.; Han, J. Exploring attention mechanisms based on summary information for end-to-end automatic speech recognition. Neurocomputing 2021, 465, 514–524. [Google Scholar] [CrossRef]
- Billa, J. Improving LSTM-CTC based ASR performance in domains with limited training data. arXiv 2017, arXiv:1707.00722. [Google Scholar]
- Hou, L.; Huang, Z.; Shang, L.; Jiang, X.; Chen, X.; Liu, Q. Dynabert: Dynamic bert with adaptive width and depth. Adv. Neural Inf. Process. Syst. 2020, 33, 9782–9793. [Google Scholar]
- Tian, S.; Deng, K.; Li, Z.; Ye, L.; Cheng, G.; Li, T.; Yan, Y. Knowledge Distillation For CTC-based Speech Recognition Via Consistent Acoustic Representation Learning. Proc. Interspeech 2022, 2022, 2633–2637. [Google Scholar]
- Winata, G.I.; Cahyawijaya, S.; Lin, Z.; Liu, Z.; Fung, P. Lightweight and efficient end-to-end speech recognition using low-rank transformer. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6144–6148. [Google Scholar]
- Sun, X.; Gao, Z.F.; Lu, Z.Y.; Li, J.; Yan, Y. A model compression method with matrix product operators for speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2837–2847. [Google Scholar] [CrossRef]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Ochiai, T. ESPnet: End-to-End Speech Processing Toolkit. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aishell-1 | HKUST | |||||||
|---|---|---|---|---|---|---|---|---|
| #Params (M) | FLOPs (G) | Dev CER | Test CER | #Params (M) | FLOPs (G) | Dev CER | Test CER | |
| Transformer | 18.3 | 0.83 | 5.6 | 6.2 | 18.3 | 0.83 | 22.1 | 22.8 |
| Conformer | 20.9 | 0.96 | 5.4 | 5.9 | 20.9 | 0.96 | 21.6 | 22.2 |
| LiteTransformer | 14.1 | 0.60 | 5.9 | 6.5 | 14.1 | 0.60 | 22.8 | 23.3 |
| LightConv | 11.0 | 0.52 | 6.1 | 6.8 | 11.0 | 0.52 | 23.0 | 23.9 |
| Random Search | 12.4 | 0.56 | 5.7 | 6.4 | 11.9 | 0.54 | 22.5 | 23.2 |
| LWAS | 11.4 | 0.51 | 5.4 | 5.9 | 11.8 | 0.54 | 21.4 | 22.2 |
| LWMD (LWAS + DSP) | 8.5 | 0.39 | 5.4 | 5.9 | 9.4 | 0.44 | 21.5 | 22.4 |
| Aishell-1 | HKUST | |||||||
|---|---|---|---|---|---|---|---|---|
| #Params (M) | FLOPs (G) | Dev CER | Test CER | #Params (M) | FLOPs (G) | Dev CER | Test CER | |
| Transformer | 29.9 | 6.96 | 5.0 | 5.4 | 29.9 | 7.14 | 20.3 | 20.8 |
| Conformer | 32.5 | 7.09 | 4.7 | 5.2 | 32.5 | 7.27 | 19.8 | 20.4 |
| LiteTransformer | 25.0 | 5.72 | 5.2 | 5.7 | 25.0 | 5.87 | 20.7 | 21.3 |
| LightConv | 20.8 | 5.61 | 5.4 | 6.0 | 20.8 | 5.76 | 21.0 | 21.9 |
| Random Search | 19.6 | 3.75 | 5.1 | 5.6 | 19.5 | 4.50 | 21.2 | 22.3 |
| LWAS | 17.7 | 2.81 | 4.7 | 5.2 | 18.1 | 2.90 | 20.0 | 20.4 |
| LWMD (LWAS + DSP) | 13.2 | 2.13 | 4.7 | 5.2 | 14.5 | 2.41 | 20.0 | 20.5 |
| Search Space | #Params (M) | FLOPs (G) | Dev CER | Test CER |
|---|---|---|---|---|
| Conformer Baseline | 32.5 | 7.09 | 4.7 | 5.2 |
| Fix MHA as MHA4 | 18.2 | 2.94 | 5.1 | 5.6 |
| Fix CNN as CNN15 | 17.9 | 2.84 | 5.2 | 5.6 |
| Fix FFN as FFN2048 | 23.4 | 4.22 | 4.7 | 5.2 |
| Fix Block Number | 22.3 | 3.95 | 4.7 | 5.2 |
| Complete Search Space | 17.7 | 2.81 | 4.7 | 5.2 |
| Pruning Methods | #Params (M) | FLOPs (G) | Dev CER | Test CER |
|---|---|---|---|---|
| w/o pruning | 17.7 | 2.81 | 4.7 | 5.2 |
| random pruning | 13.2 | 2.13 | 5.2 | 5.8 |
| structured -pruning | 13.2 | 2.13 | 5.0 | 5.6 |
| structured -pruning | 13.2 | 2.15 | 5.0 | 5.5 |
| DSP w/o Attention-similarity Loss | 13.2 | 2.13 | 4.8 | 5.4 |
| DSP with Attention-similarity Loss (Default) | 13.2 | 2.13 | 4.7 | 5.2 |
| Pruning Methods | #Params (M) | Dev CER | Test CER |
|---|---|---|---|
| Conformer Baseline | 32.5 | 4.7 | 5.2 |
| LWMD (float32) | 13.2 | 4.7 | 5.2 |
| LWMD + float16 | 7.6 | 4.9 | 5.3 |
| LWMD + int8 | 3.8 | 5.2 | 5.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Li, T.; Zhang, P.; Yan, Y. LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models. Appl. Sci. 2023, 13, 1587. https://doi.org/10.3390/app13031587
Liu Y, Li T, Zhang P, Yan Y. LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models. Applied Sciences. 2023; 13(3):1587. https://doi.org/10.3390/app13031587
Chicago/Turabian StyleLiu, Yukun, Ta Li, Pengyuan Zhang, and Yonghong Yan. 2023. "LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models" Applied Sciences 13, no. 3: 1587. https://doi.org/10.3390/app13031587
APA StyleLiu, Y., Li, T., Zhang, P., & Yan, Y. (2023). LWMD: A Comprehensive Compression Platform for End-to-End Automatic Speech Recognition Models. Applied Sciences, 13(3), 1587. https://doi.org/10.3390/app13031587