


Multi-Hypergraph Neural Networks for Emotion Recognition in Multi-Party Conversations


Abstract
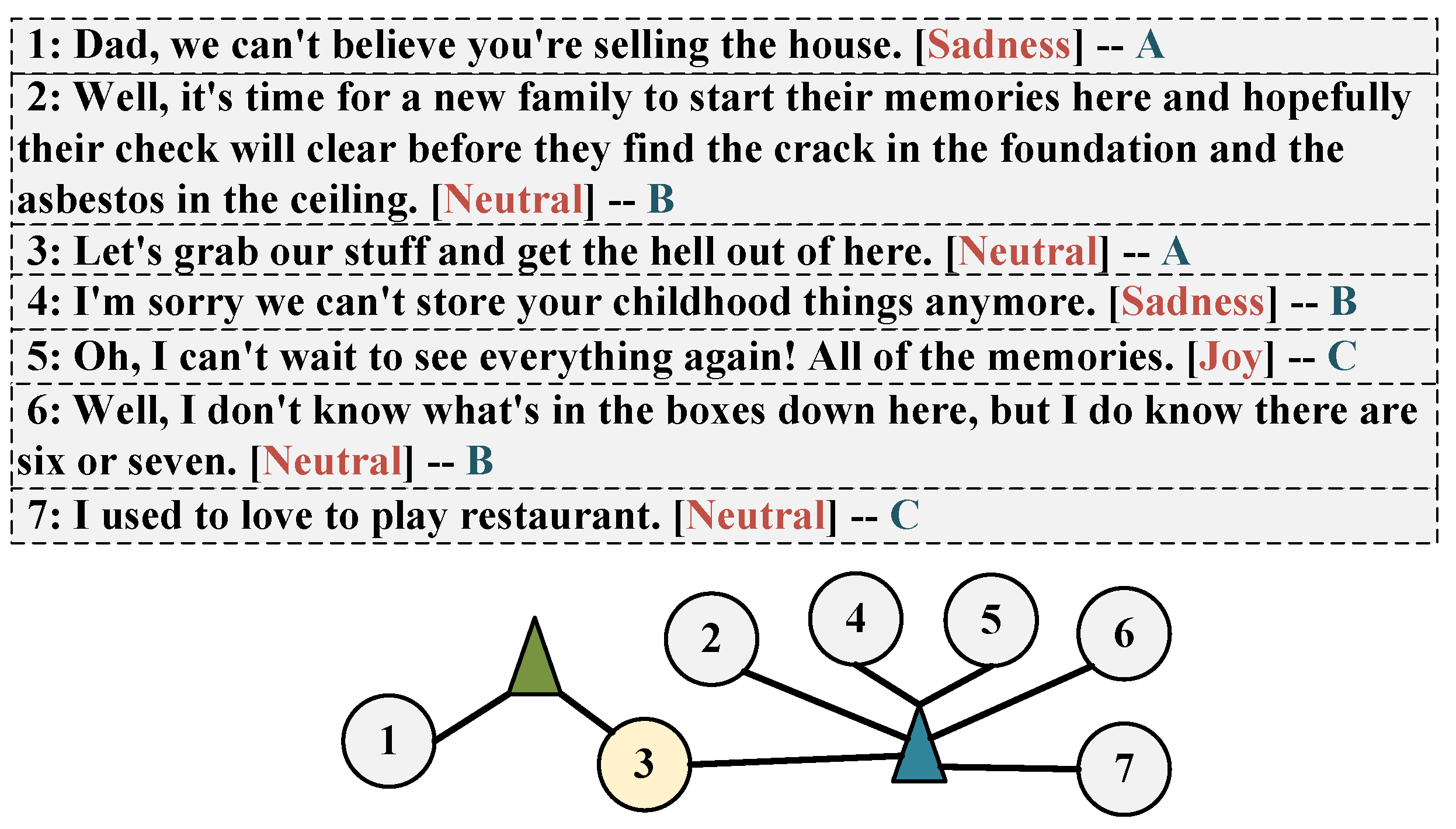
:1. Introduction
- We construct hypergraphs for two different dependencies among participants and design a multi-hypergraph neural network for emotion recognition in multi-party conversations. To the best of our knowledge, this is the first attempt to build graphs for inter-dependency alone.
- We combine average aggregation and attention aggregation to generate hyperedge features that can allow better utilization of the information of utterances.
- We conducted experiments on two public benchmark datasets. The results consistently demonstrate the effectiveness and superiority of the proposed model. In addition, we achieved good results on the emotional shift issue.
2. Related Work
2.1. Emotion Recognition in Conversations
2.2. Hypergraph Neural Networks
3. Methodology
3.1. Hypergraph Definition
| Algorithm 1 Constructing a Hypergraph |
|
3.2. Problem Definition
3.3. Model
3.3.1. Utterance Feature Extraction
3.3.2. Hypergraph Convolution (HGC) Layer
3.4. Classifier
4. Experimental Setting
4.1. Datasets
4.2. Compared Methods
4.3. Implementation Details
5. Results and Discussions
5.1. Overall Performance
5.2. Ablation Study
5.3. Effects of the Depth of the GNN and Window Sizes
5.4. Error Analysis
5.5. Case Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chatterjee, A.; Narahari, K.N.; Joshi, M.; Agrawal, P. SemEval-2019 Task 3: EmoContext Contextual Emotion Detection in Text. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 39–48. [Google Scholar] [CrossRef]
- Rashkin, H.; Smith, E.M.; Li, M.; Boureau, Y.L. Towards Empathetic Open-domain Conversation Models: A New Benchmark and Dataset. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 5370–5381. [Google Scholar] [CrossRef]
- Majumder, N.; Poria, S.; Hazarika, D.; Mihalcea, R.; Gelbukh, A.; Cambria, E. DialogueRNN: An Attentive RNN for Emotion Detection in Conversations. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI’19/IAAI’19/EAAI’19), Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Palo Alto, CA, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Poria, S.; Majumder, N.; Mihalcea, R.; Hovy, E. Emotion Recognition in Conversation: Research Challenges, Datasets, and Recent Advances. IEEE Access 2019, 7, 100943–100953. [Google Scholar] [CrossRef]
- Ghosal, D.; Majumder, N.; Poria, S.; Chhaya, N.; Gelbukh, A. DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 154–164. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Yu, N.; Fu, G. A Discourse-Aware Graph Neural Network for Emotion Recognition in Multi-Party Conversation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 2949–2958. [Google Scholar] [CrossRef]
- Hazarika, D.; Poria, S.; Zadeh, A.; Cambria, E.; Morency, L.P.; Zimmermann, R. Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, Louisiana, 1–6 June 2018; Association for Computational Linguistics: Toronto, ON, Canada, 2018; pp. 2122–2132. [Google Scholar] [CrossRef]
- Hazarika, D.; Poria, S.; Mihalcea, R.; Cambria, E.; Zimmermann, R. ICON: Interactive Conversational Memory Network for Multimodal Emotion Detection. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Toronto, ON, Canada, 2018; pp. 2594–2604. [Google Scholar] [CrossRef] [Green Version]
- Jiao, W.; Lyu, M.R.; King, I. Real-Time Emotion Recognition via Attention Gated Hierarchical Memory Network. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, the Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 8002–8009. [Google Scholar]
- Li, W.; Shao, W.; Ji, S.; Cambria, E. BiERU: Bidirectional emotional recurrent unit for conversational sentiment analysis. Neurocomputing 2022, 467, 73–82. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.; Ma, J.; Wang, S.; Xiao, J. Contextualized Emotion Recognition in Conversation as Sequence Tagging. In Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Virtual, 1–3 July 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 186–195. [Google Scholar]
- Hu, D.; Wei, L.; Huai, X. DialogueCRN: Contextual Reasoning Networks for Emotion Recognition in Conversations. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 7042–7052. [Google Scholar] [CrossRef]
- Ghosal, D.; Majumder, N.; Gelbukh, A.; Mihalcea, R.; Poria, S. COSMIC: COmmonSense knowledge for eMotion Identification in Conversations. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 2470–2481. [Google Scholar] [CrossRef]
- Li, J.; Zhang, M.; Ji, D.; Liu, Y. Multi-Task Learning with Auxiliary Speaker Identification for Conversational Emotion Recognition. arXiv 2020, arXiv:2003.01478. [Google Scholar]
- Ishiwatari, T.; Yasuda, Y.; Miyazaki, T.; Goto, J. Relation-aware Graph Attention Networks with Relational Position Encodings for Emotion Recognition in Conversations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 7360–7370. [Google Scholar] [CrossRef]
- Liang, C.; Yang, C.; Xu, J.; Huang, J.; Wang, Y.; Dong, Y. S+PAGE: A Speaker and Position-Aware Graph Neural Network Model for Emotion Recognition in Conversation. arXiv 2021, arXiv:2112.12389. [Google Scholar]
- Shen, W.; Wu, S.; Yang, Y.; Quan, X. Directed Acyclic Graph Network for Conversational Emotion Recognition. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 1551–1560. [Google Scholar] [CrossRef]
- Li, J.; Lin, Z.; Fu, P.; Wang, W. Past, Present, and Future: Conversational Emotion Recognition through Structural Modeling of Psychological Knowledge. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 1204–1214. [Google Scholar] [CrossRef]
- Schlichtkrull, M.S.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In The Semantic Web, Proceedings of the 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018, Proceedings; Gangemi, A., Navigli, R., Vidal, M., Hitzler, P., Troncy, R., Hollink, L., Tordai, A., Alam, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10843, pp. 593–607. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Yin, H.; Liu, B.; Chen, H.; Cao, J.; Shao, Y.; Hung, N.Q.V. Heterogeneous Hypergraph Embedding for Graph Classification. In Proceedings of the Fourteenth ACM International Conference on Web Search and Data Mining, WSDM ’21, Virtual Event, Israel, 8–12 March 2021; Lewin-Eytan, L., Carmel, D., Yom-Tov, E., Agichtein, E., Gabrilovich, E., Eds.; ACM: Boston, MA, USA, 2021; pp. 725–733. [Google Scholar] [CrossRef]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph Neural Networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, the Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, the Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Palo Alto, CA, USA, 2019; pp. 3558–3565. [Google Scholar] [CrossRef] [Green Version]
- Yi, J.; Park, J. Hypergraph Convolutional Recurrent Neural Network. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD’20, Virtual Event, CA, USA, 23–27 August 2020; Gupta, R., Liu, Y., Tang, J., Prakash, B.A., Eds.; ACM: Boston, MA, USA, 2020; pp. 3366–3376. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; 2017; pp. 5998–6008. [Google Scholar]
- Shen, W.; Chen, J.; Quan, X.; Xie, Z. DialogXL: All-in-One XLNet for Multi-Party Conversation Emotion Recognition. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; AAAI Press: Palo Alto, CA, USA, 2021; pp. 13789–13797. [Google Scholar]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Toronto, ON, Canada, 2014; pp. 1746–1751. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Tang, F.; Zhao, M.; Zhu, Y. EmoCaps: Emotion Capsule based Model for Conversational Emotion Recognition. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2022; pp. 1610–1618. [Google Scholar] [CrossRef]
- Ong, D.; Su, J.; Chen, B.; Luu, A.T.; Narendranath, A.; Li, Y.; Sun, S.; Lin, Y.; Wang, H. Is Discourse Role Important for Emotion Recognition in Conversation? In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022, Virtual Event, 22 February–1 March 2022; AAAI Press: Palo Alto, CA, USA, 2022; pp. 11121–11129. [Google Scholar] [CrossRef]
- Zhu, L.; Pergola, G.; Gui, L.; Zhou, D.; He, Y. Topic-Driven and Knowledge-Aware Transformer for Dialogue Emotion Detection. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Online, 2021; pp. 1571–1582. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Li, S.; Yan, H.; Qiu, X. Contrast and Generation Make BART a Good Dialogue Emotion Recognizer. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022, Virtual Event, 22 February–1 March 2022; AAAI Press: Palo Alto, CA, USA, 2022; pp. 11002–11010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Zhang, D.; Wu, L.; Sun, C.; Li, S.; Zhu, Q.; Zhou, G. Modeling both Context- and Speaker-Sensitive Dependence for Emotion Detection in Multi-speaker Conversations. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019; Kraus, S., Ed.; ijcai.org, 2019. pp. 5415–5421. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Liu, Y.; Zhao, J.; Jin, Q. MMGCN: Multimodal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 5666–5675. [Google Scholar] [CrossRef]
- Lee, B.; Choi, Y.S. Graph Based Network with Contextualized Representations of Turns in Dialogue. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 443–455. [Google Scholar] [CrossRef]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with Hypergraphs: Clustering, Classification, and Embedding. In Proceedings of the Advances in Neural Information Processing Systems 19, Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; Schölkopf, B., Platt, J.C., Hofmann, T., Eds.; MIT Press: Cambridge, MA, USA, 2006; pp. 1601–1608. [Google Scholar]
- Ding, K.; Wang, J.; Li, J.; Li, D.; Liu, H. Be More with Less: Hypergraph Attention Networks for Inductive Text Classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–18 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 4927–4936. [Google Scholar] [CrossRef]
- Wang, J.; Ding, K.; Zhu, Z.; Caverlee, J. Session-based Recommendation with Hypergraph Attention Networks. In Proceedings of the 2021 SIAM International Conference on Data Mining, SDM 2021, Virtual Event, 29 April–1 May 2021; Demeniconi, C., Davidson, I., Eds.; SIAM: Philadelphia, PA, USA, 2021; pp. 82–90. [Google Scholar] [CrossRef]
- Zhu, J.; Zhao, X.; Hu, H.; Gao, Y. Emotion Recognition from Physiological Signals using Multi-Hypergraph Neural Networks. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 610–615. [Google Scholar] [CrossRef]
- Ye, Y.; Pan, T.; Meng, Q.; Li, J.; Lu, L. Online ECG Emotion Recognition for Unknown Subjects via Hypergraph-Based Transfer Learning. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, Vienna, Austria, 23–29 July 2022; Raedt, L.D., Ed.; 2022; pp. 3666–3672, Main Track. [Google Scholar] [CrossRef]
- Shao, J.; Zhu, J.; Wei, Y.; Feng, Y.; Zhao, X. Emotion Recognition by Edge-Weighted Hypergraph Neural Network. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2144–2148. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 527–536. [Google Scholar] [CrossRef] [Green Version]
- Zahiri, S.M.; Choi, J.D. Emotion Detection on TV Show Transcripts with Sequence-Based Convolutional Neural Networks. In Proceedings of the Workshops of the The Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Palo Alto, CA, USA, 2018; Volume WS-18, pp. 44–52. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MELD | EmoryNLP | |
|---|---|---|
| #Dial. | 1432 | 897 |
| Train | 1038 | 713 |
| Dev. | 114 | 99 |
| Test | 280 | 85 |
| #Utt. | 13,708 | 12,606 |
| Train | 9989 | 9934 |
| Dev. | 1109 | 1344 |
| Test | 2610 | 1328 |
| avg_utt | 9.57 | 14.05 |
| Classes | 7 | 7 |
| Metrics | Weighted-average F1 | Weighted-average F1 |
| # | Batch size | Dropout | Lr | Window | SSHG | NSHG |
|---|---|---|---|---|---|---|
| MELD | 32 | 0.1 | 0.001 | 1 | 1 | 1 |
| EmoryNLP | 16 | 0.4 | 0.0009 | 4 | 4 | 6 |
| Model | CSK | MELD | EmoryNLP |
|---|---|---|---|
| RoBERTa | × | 62.88 | 37.78 |
| DialogueRNN | × | 57.03 | - |
| +RoBERTa | × | 63.61 | 37.44 |
| DialogueCRN | × | 58.39 | - |
| VAE-ERC | × | 65.34 | - |
| DialogXL | × | 62.4 | 34.73 |
| BERT+MTL | × | 61.90 | 35.92 |
| CoG-BART | × | 64.81 | 39.04 |
| COSMIC | √ | 65.21 | 38.11 |
| TODKAT | √ | 65.47 | 38.69 |
| * | × | 63.51 | - |
| DialogueGCN | × | 58.10 | - |
| +RoBERTa | × | 63.02 | 38.10 |
| RGAT | × | 60.91 | 34.42 |
| +RoBERTa | × | 62.80 | 37.89 |
| TUCORE-GCN | × | 62.47 | 36.01 |
| +RoBERTa | × | 65.36 | 39.24 |
| DAG-ERC | × | 63.65 | 39.02 |
| ERMC-DisGCN | × | 64.22 | 36.38 |
| SKAIG | √ | 65.18 | 38.88 |
| * | × | 57.72 | - |
| ERMC-MHGNN | × | 66.4 | 40.1 |
| Method | MELD | EmoryNLP |
|---|---|---|
| Full model | 66.4 | 40.1 |
| w/o | 65.61 (↓0.79) | 39.15 (↓0.95) |
| w/o | 65.64 (↓0.76) | 39.05 (↓1.05) |
| w/o | 65.3 (↓1.1) | 38.93 (↓1.17) |
| w/o | 65.19 (↓1.21) | 38.9 (↓1.2) |
| # | MELD | EmoryNLP | ||
|---|---|---|---|---|
| Shift | w/o Shift | Shift | w/o Shift | |
| (1003) | (861) | (673) | (361) | |
| DialogXL | 57.33 | 71.43 | 33.88 | 43.77 |
| DAG-ERC | 59.02 | 69.45 | 37.29 | 42.10 |
| ERMC-MHGNN | 62.01 | 72.36 | 38.93 | 41.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Zheng, C.; Zhao, Z.; Sun, X. Multi-Hypergraph Neural Networks for Emotion Recognition in Multi-Party Conversations. Appl. Sci. 2023, 13, 1660. https://doi.org/10.3390/app13031660
Xu H, Zheng C, Zhao Z, Sun X. Multi-Hypergraph Neural Networks for Emotion Recognition in Multi-Party Conversations. Applied Sciences. 2023; 13(3):1660. https://doi.org/10.3390/app13031660
Chicago/Turabian StyleXu, Haojie, Cheng Zheng, Zhuoer Zhao, and Xiao Sun. 2023. "Multi-Hypergraph Neural Networks for Emotion Recognition in Multi-Party Conversations" Applied Sciences 13, no. 3: 1660. https://doi.org/10.3390/app13031660
APA StyleXu, H., Zheng, C., Zhao, Z., & Sun, X. (2023). Multi-Hypergraph Neural Networks for Emotion Recognition in Multi-Party Conversations. Applied Sciences, 13(3), 1660. https://doi.org/10.3390/app13031660