
A Linear Memory CTC-Based Algorithm for Text-to-Voice Alignment of Very Long Audio Recordings




Abstract
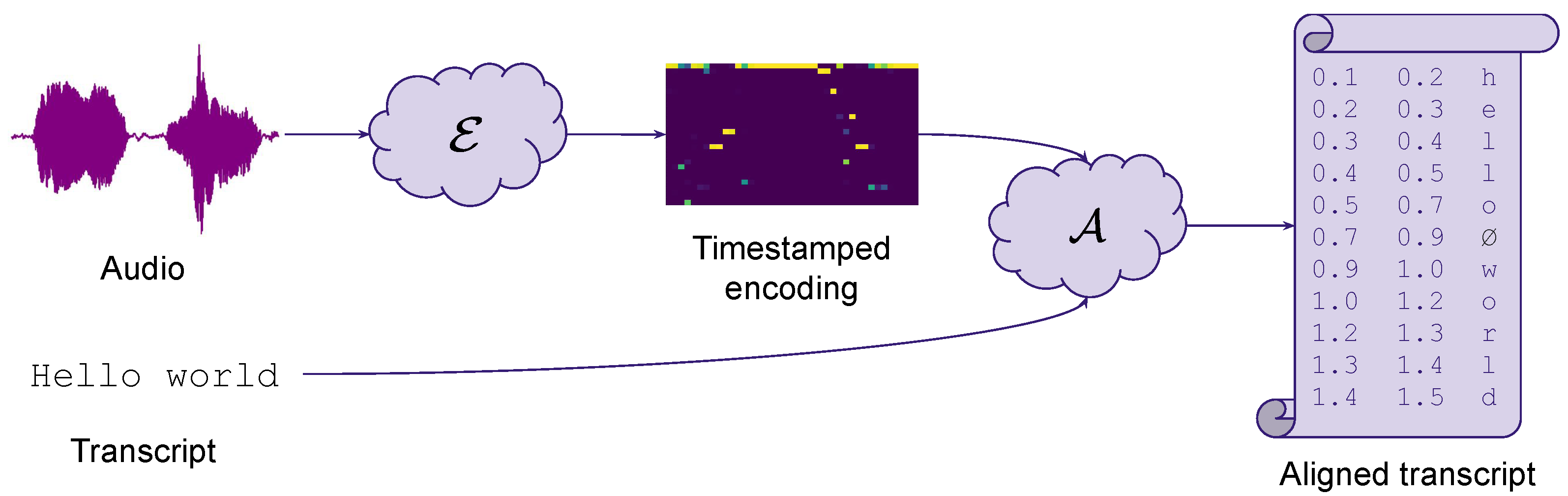
:1. Introduction
2. Related Works
2.1. CTC-Based Modeling for the Encoding Step
2.2. Optimized DTW for the Alignment Step
3. Method
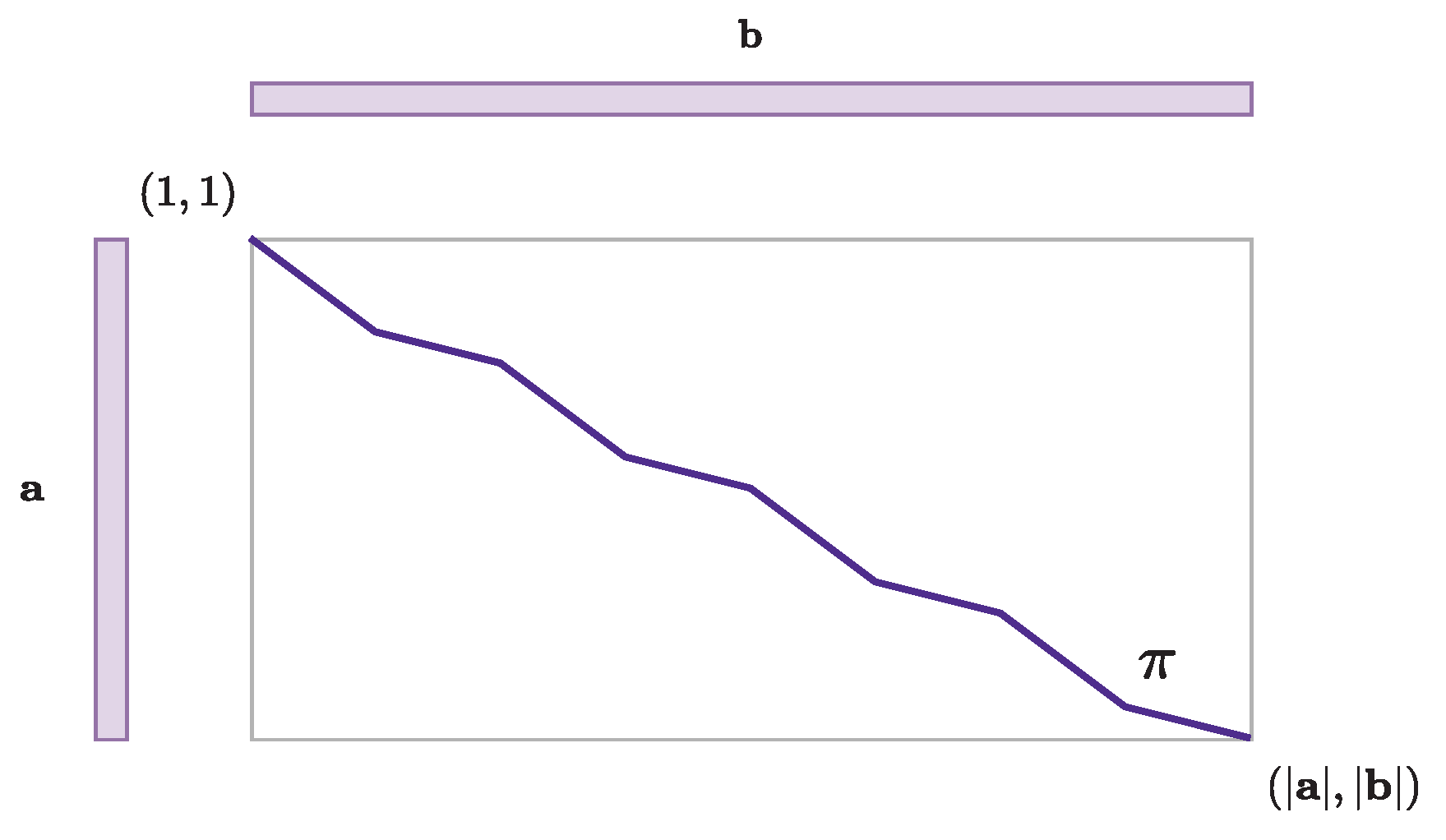
3.1. The Textbook DTW Alignment Algorithm
3.1.1. Definitions
- Boundaries: starts and ends at the beginning and end of each sequence, i.e.,:
- Monotonicity: does not go backward, i.e.,:The Figure 2 illustrates these constraints:
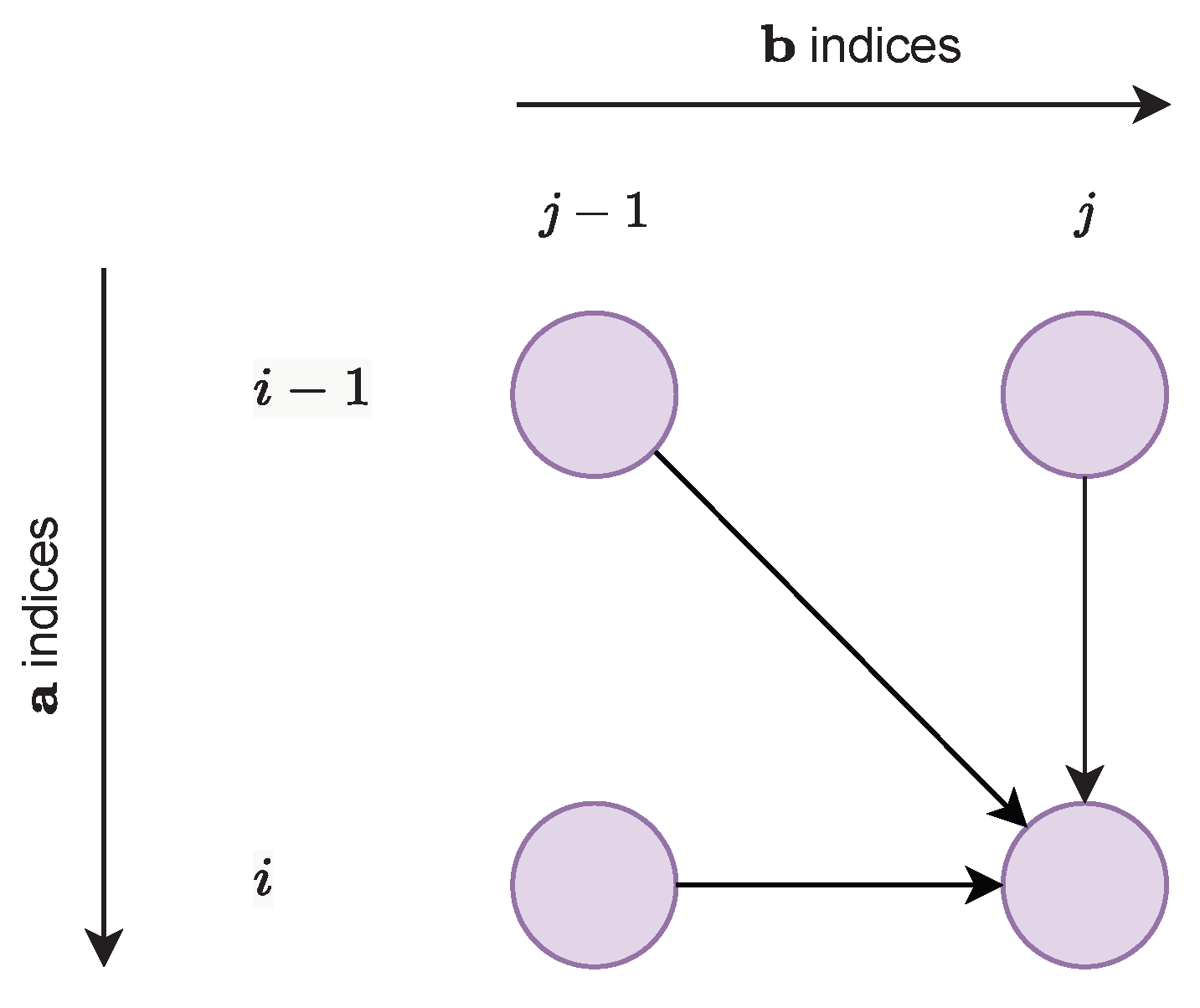
3.1.2. * Computation via Dynamic Programming
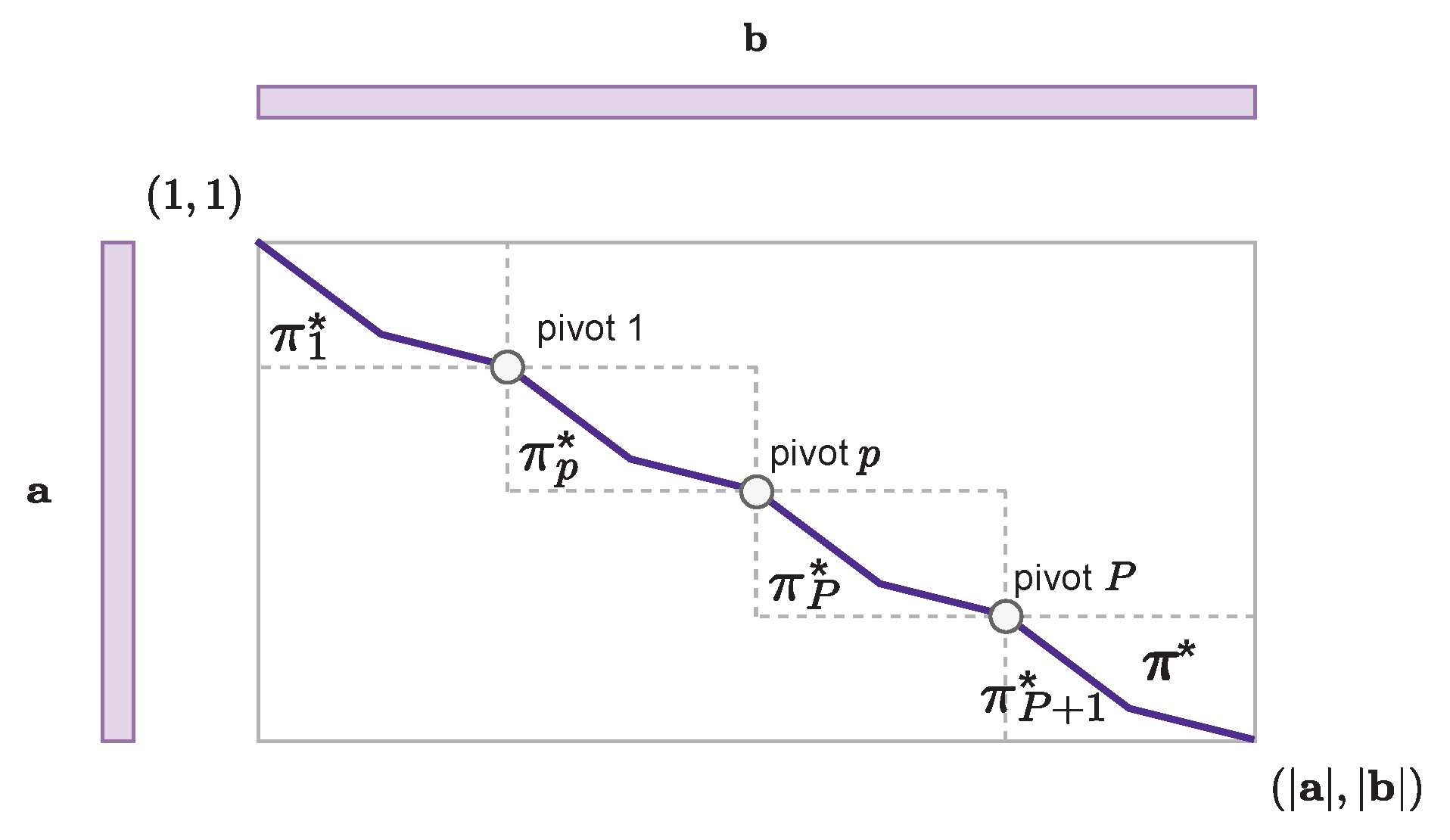
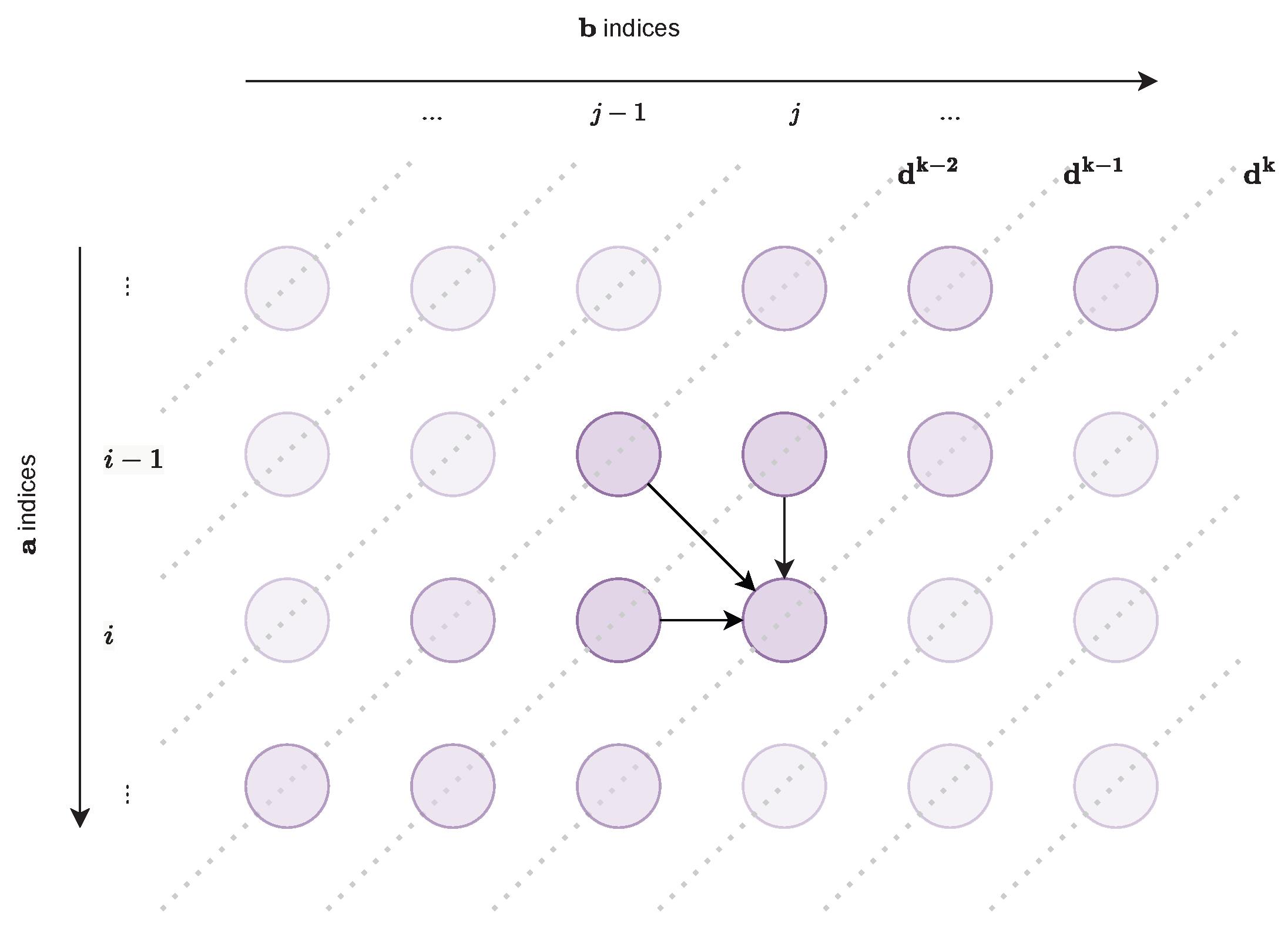
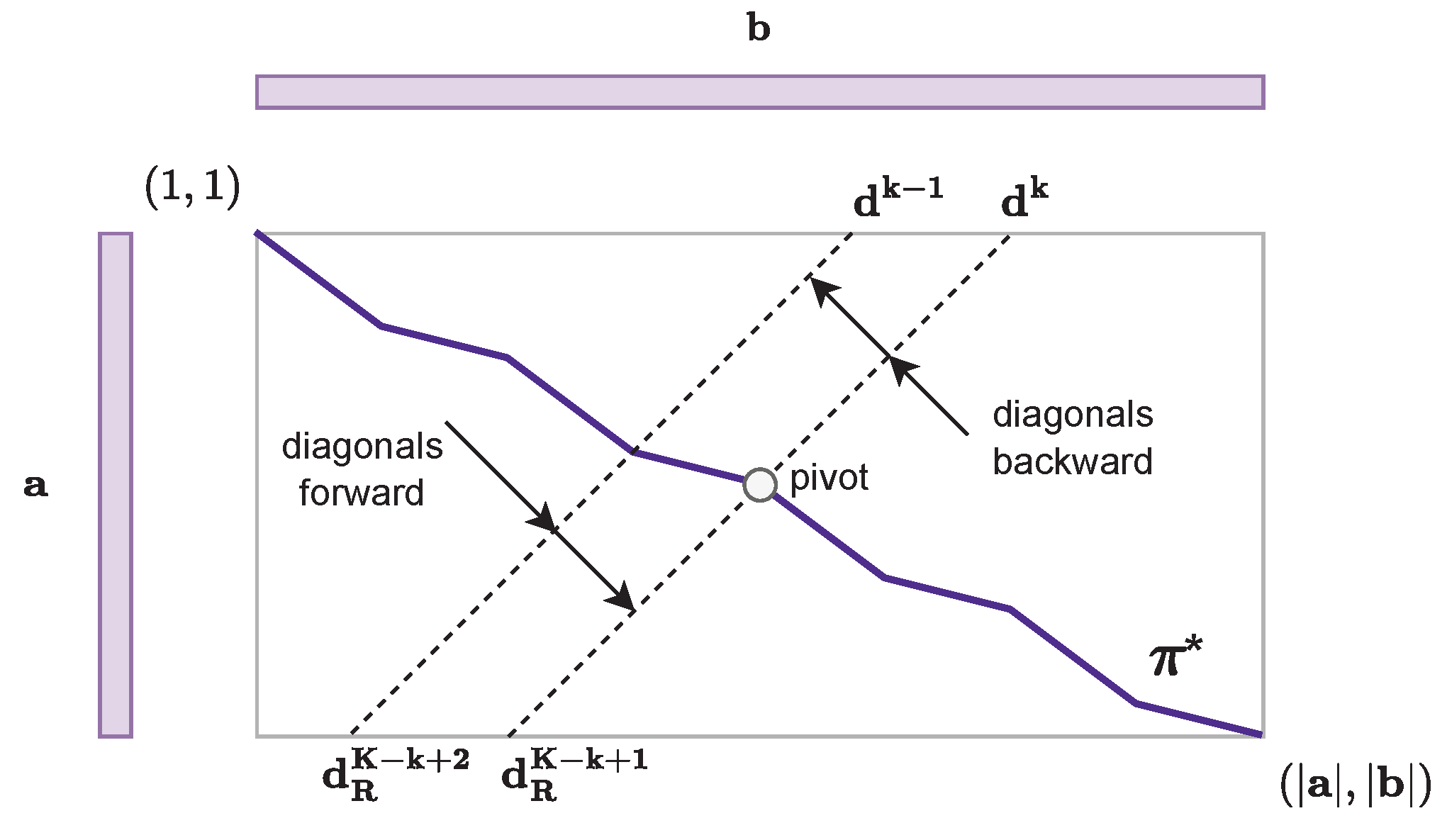
3.2. Linear Memory DTW Algorithm
3.2.1. Principle
3.2.2. Pivot Search
3.2.3. Pivot Search on and
3.2.4. Diagonal Computation with Linear Memory Complexity
3.3. The CTC Alignment Algorithm
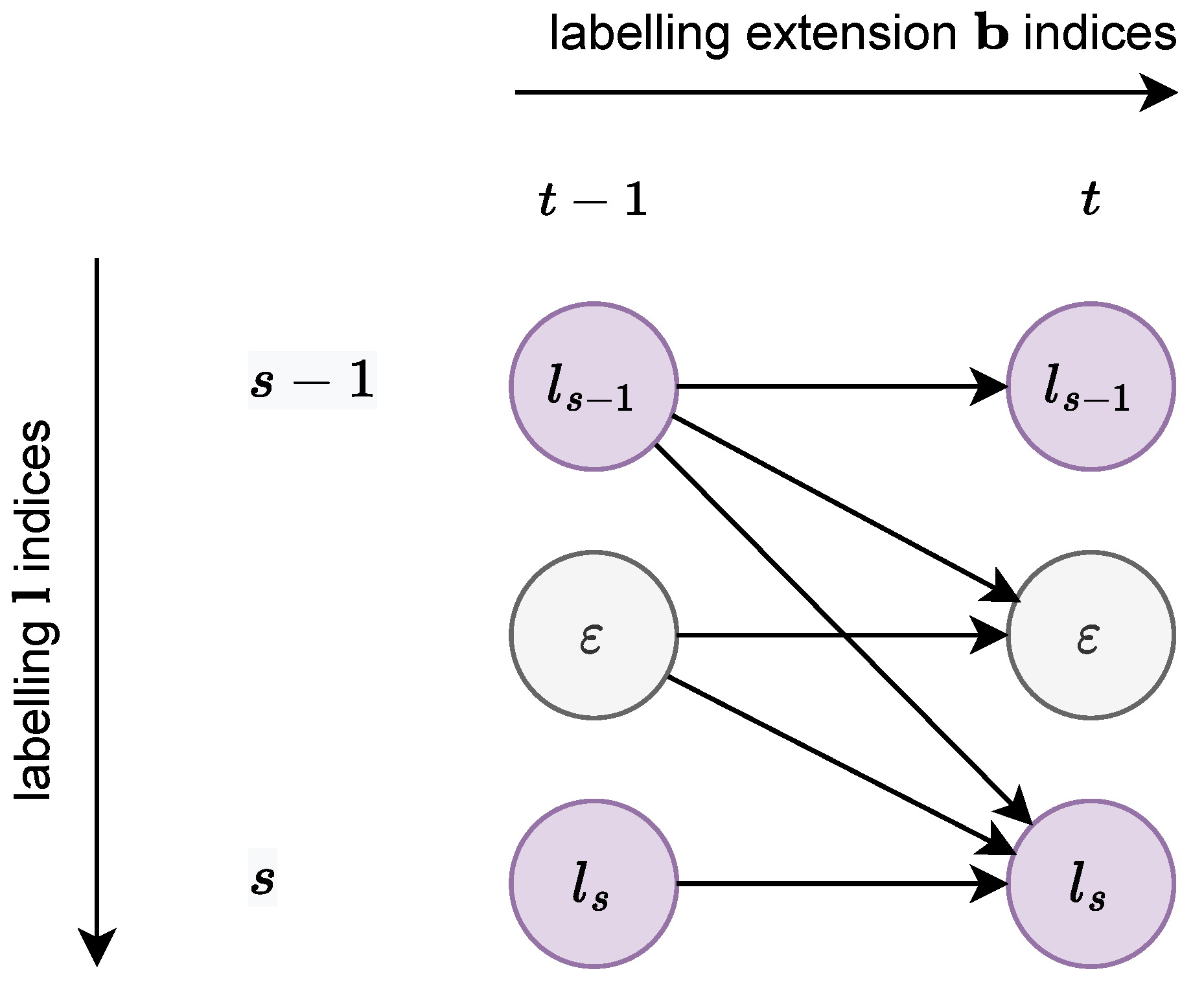
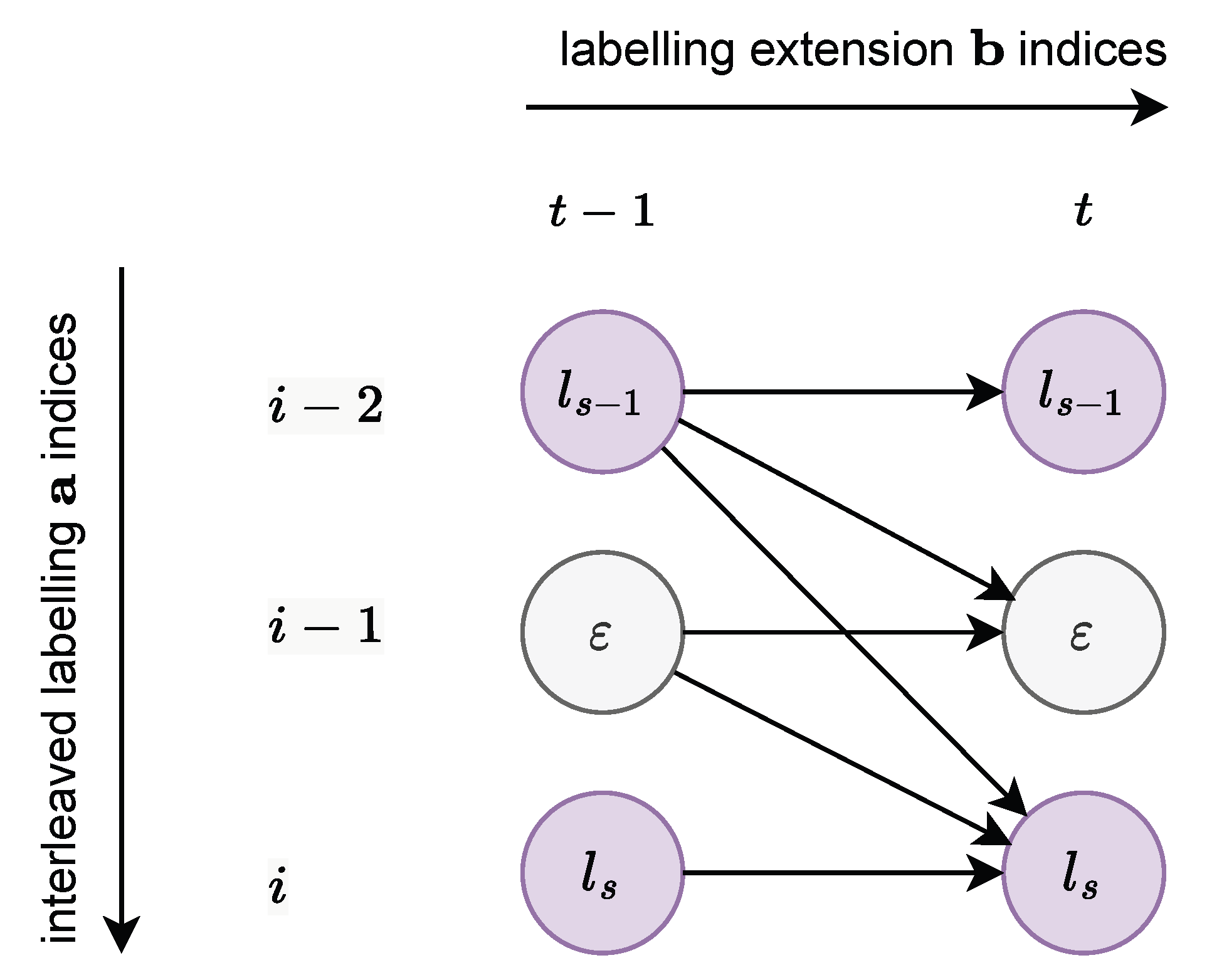
3.3.1. Definitions
- If it is a blank label , the next label can be or the next non-blank label .
- If it is a non-blank label , the next label can either be the same label , the blank label , or the next label, , if .
3.3.2. Computation via Dynamic Programming
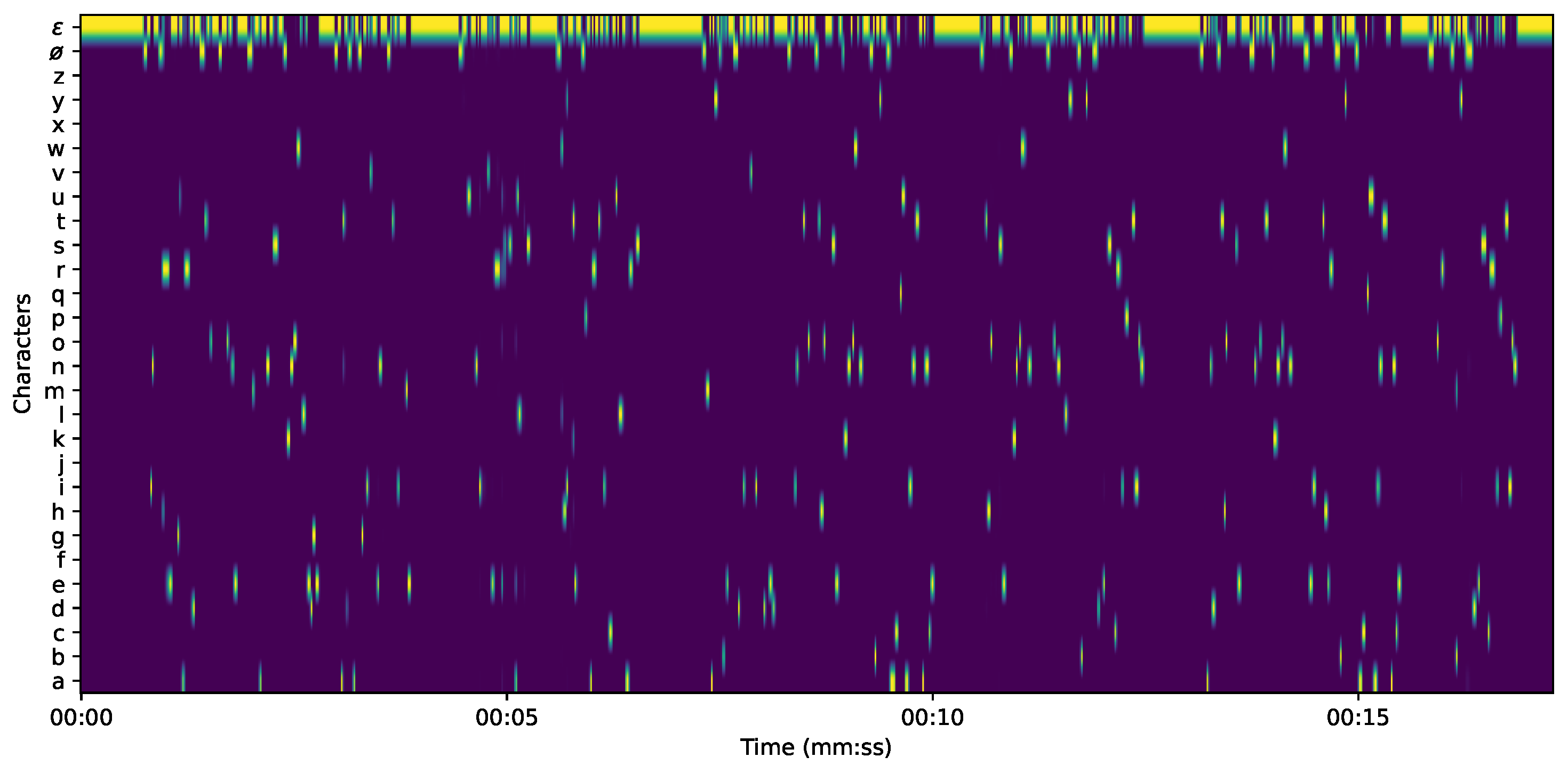
3.3.3. CTC-Forced Alignment
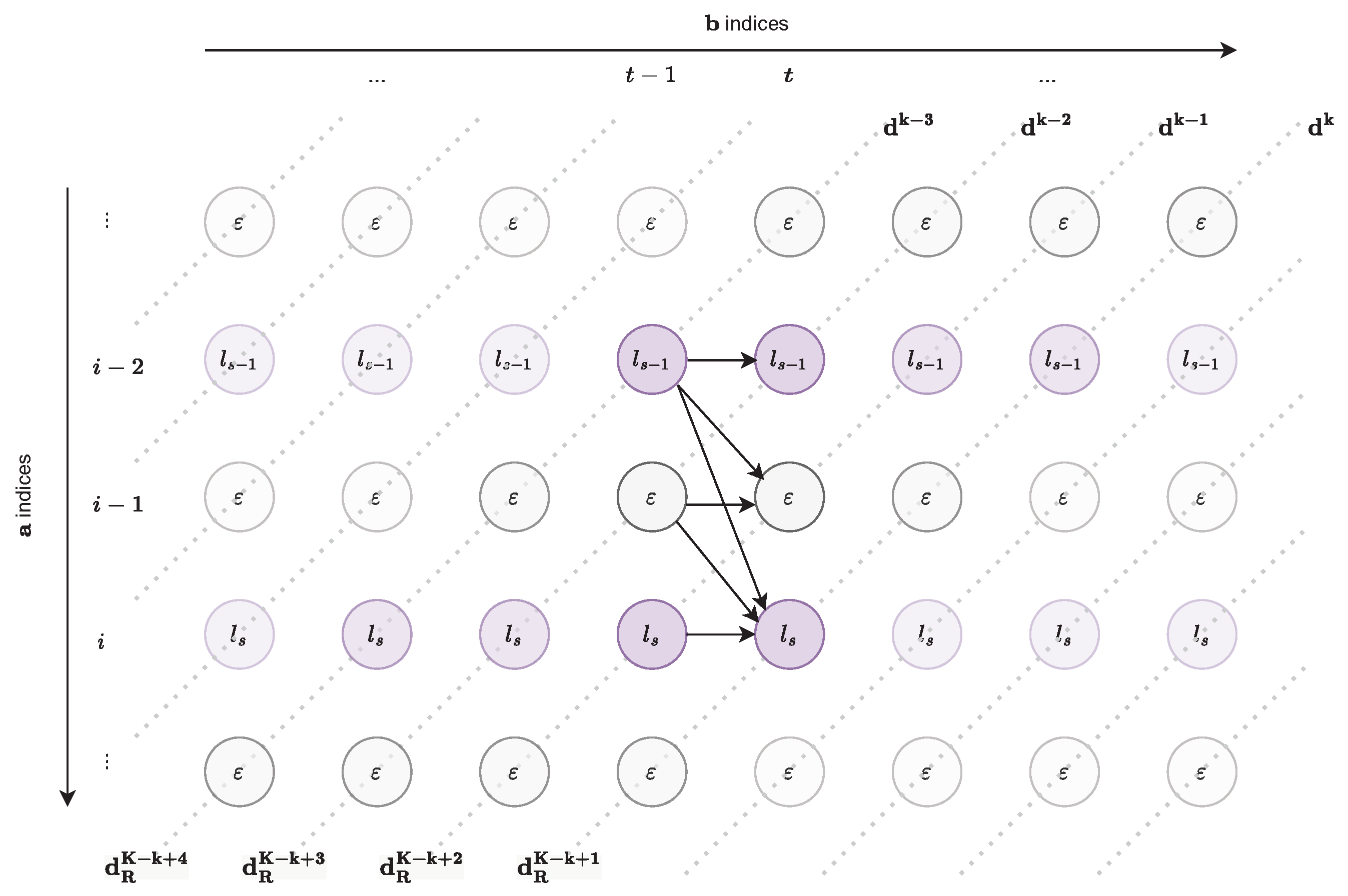
3.4. Linear Memory CTC Alignment
3.4.1. Pivot Search
3.4.2. Pivot Search on , , and
3.4.3. α and αR Computation Diagonal-Wise
3.5. Neural Architecture
3.5.1. Inputs
3.5.2. Architecture
3.5.3. Output
4. Experiments and Results
4.1. Model Training
4.1.1. Speech
4.1.2. Singing voice
4.2. Reference Corpora
4.2.1. Speech
4.2.2. Singing Voice
4.3. Evaluation Metrics
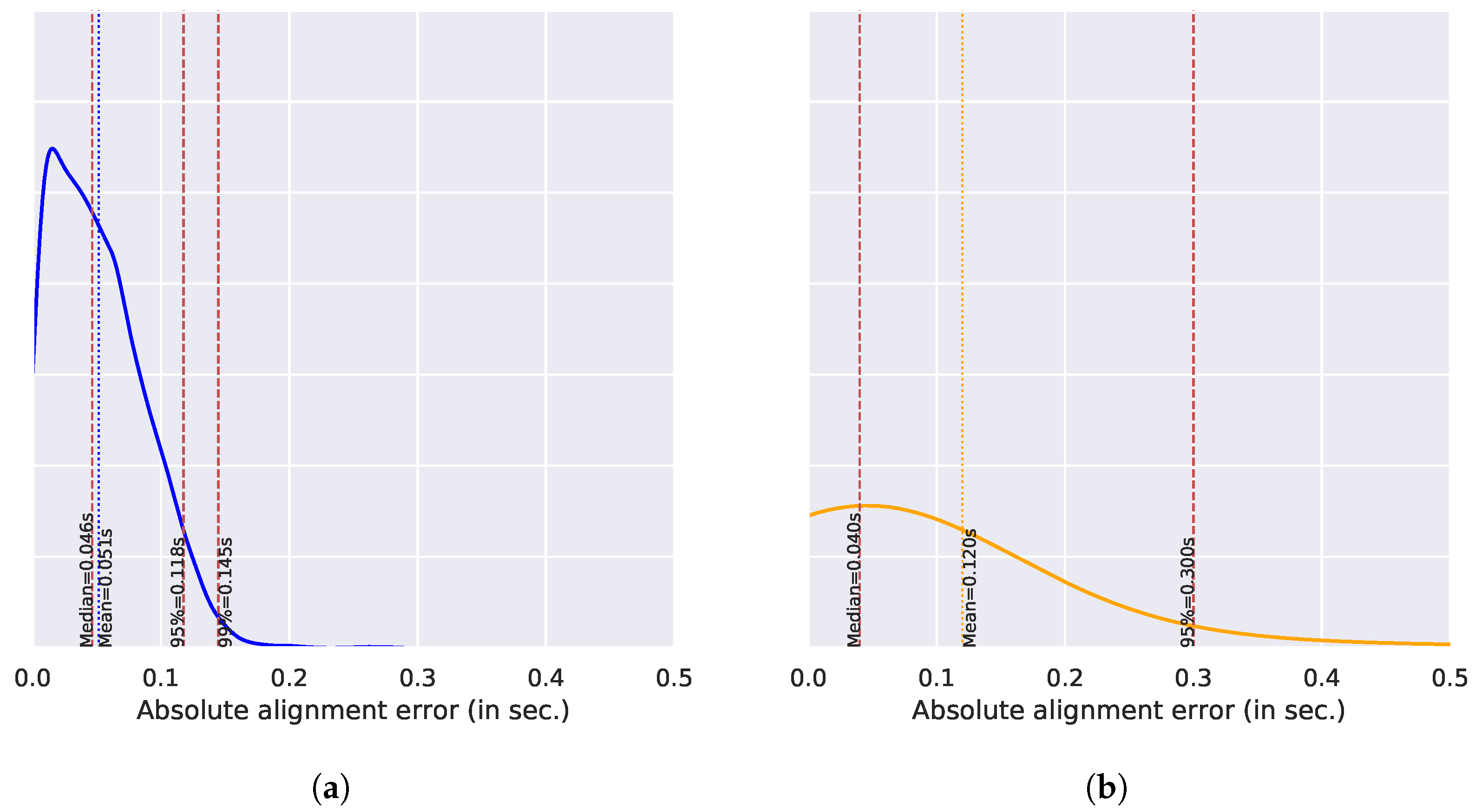
4.4. Baseline Results
4.5. Effect of Audio Duration and Number of Words on Performances
4.6. Effect of Text Transcription Errors on Performances
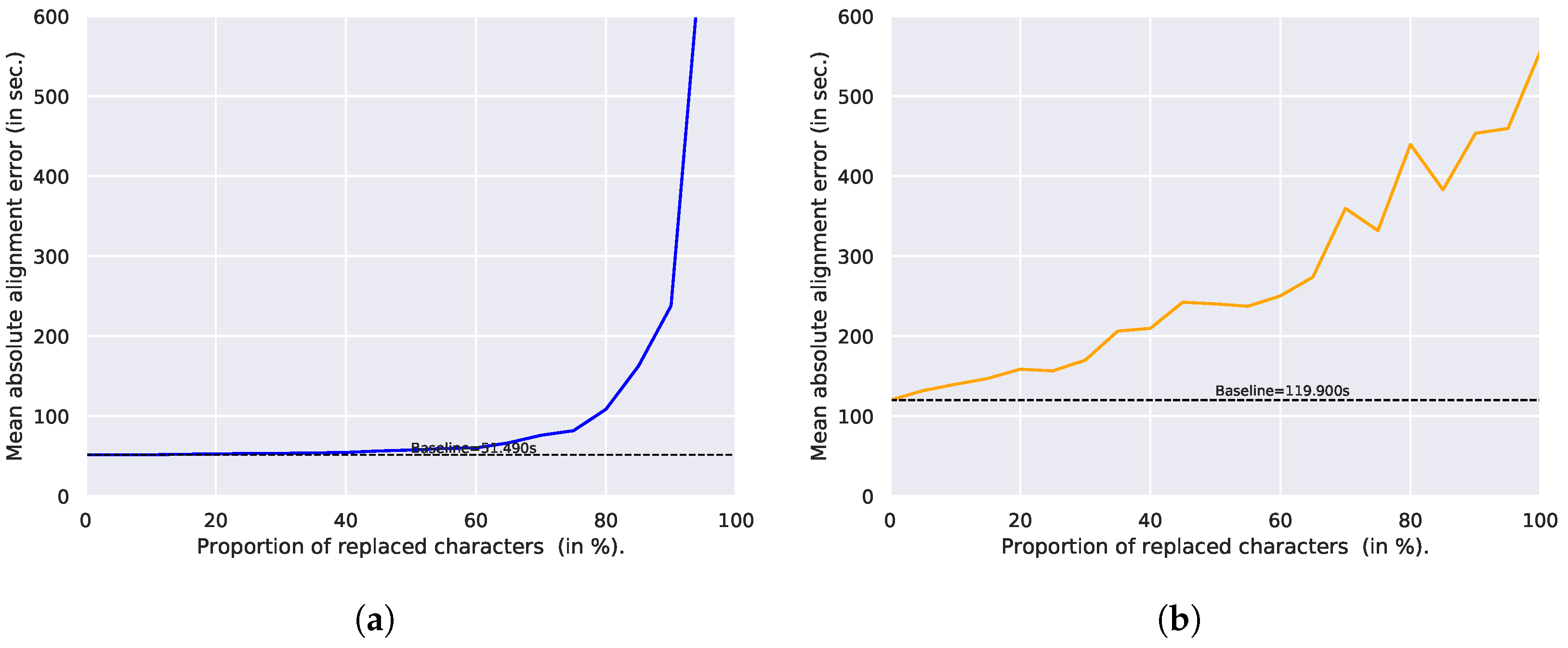
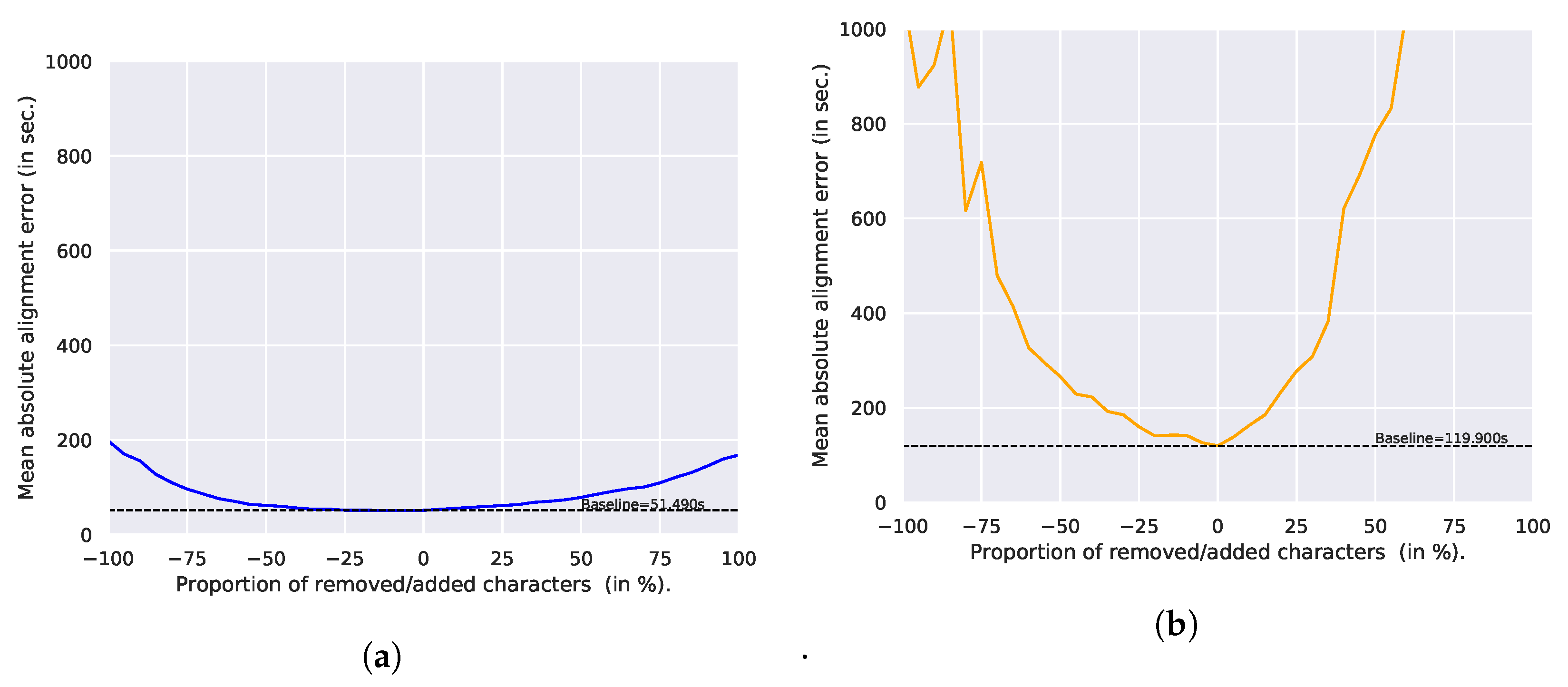
4.6.1. Effect of Replaced Characters
4.6.2. Effect of Added/Removed Characters
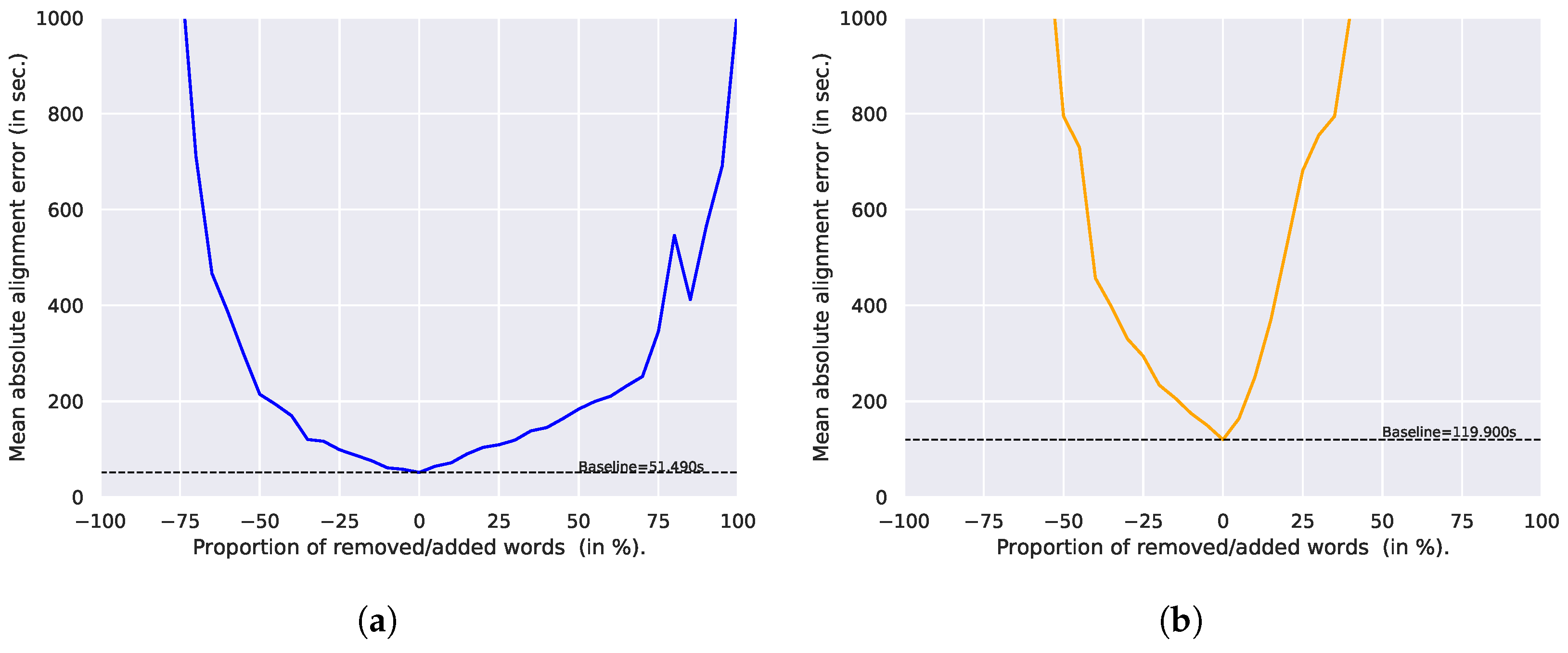
4.6.3. Effect of Added/Removed Words
4.7. Different Languages
4.7.1. Speech
4.7.2. Singing Voice
4.8. Performance Benchmark
4.8.1. Comparison with Other ASR Systems
4.8.2. Comparison with Other Alignment Systems
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Viterbi, A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans. Inf. Theory 1967, 13, 260–269. [Google Scholar] [CrossRef] [Green Version]
- Needleman, S.B.; Wunsch, C.D. A general method applicable to the search for similarities in the amino acid sequence of two proteins. J. Mol. Biol. 1970, 48, 443–453. [Google Scholar] [CrossRef] [PubMed]
- Vintsyuk, T.K. Speech discrimination by dynamic programming. Cybernetics 1968, 4, 52–57. [Google Scholar] [CrossRef]
- Velichko, V.; Zagoruyko, N. Automatic recognition of 200 words. Int. J. Man-Mach. Stud. 1970, 2, 223–234. [Google Scholar] [CrossRef]
- Itakura, F. Minimum prediction residual principle applied to speech recognition. IEEE Trans. Acoust. Speech Signal Process. 1975, 23, 67–72. [Google Scholar] [CrossRef]
- Mongeau, M.; Sankoff, D. Comparison of musical sequences. Comput. Humanit. 1990, 24, 161–175. [Google Scholar] [CrossRef]
- Orio, N.; Schwarz, D. Alignment of monophonic and polyphonic music to a score. In Proceedings of the International Computer Music Conference (ICMC), Havana, Cuba, 17–22 September 2001. [Google Scholar]
- Müller, M.; Kurth, F.; Clausen, M. Audio Matching via Chroma-Based Statistical Features. In Proceedings of the ISMIR (International Society for Music Information Retrieval), London, UK, 11–15 September 2005. [Google Scholar]
- Ellis, D.P. Beat Tracking with Dynamic Programming. J. New Music. Res. 2007, 36, 51–60. [Google Scholar] [CrossRef] [Green Version]
- Serrà, J.; Gómez, E. A cover song identification system based on sequences of tonal descriptors. MIREX (Music Information Retrieval Evaluation eXchange); Citeseer: Princeton, NJ, USA, 2007; Volume 46. [Google Scholar]
- Wagner, M. Automatic labelling of continuous speech with a given phonetic transcription using dynamic programming algorithms. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’81), Atlanta, GA, USA, 30 March–1 April 1981; Volume 6, pp. 1156–1159. [Google Scholar]
- Leung, H.; Zue, V. A procedure for automatic alignment of phonetic transcriptions with continuous speech. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’84), San Diego, California, USA, 19–21 March 1984; Volume 9, pp. 73–76. [Google Scholar]
- Ljolje, A.; Riley, M. Automatic segmentation and labeling of speech. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Toronto, ON, Canada, 14–17 April 1991; pp. 473–476. [Google Scholar]
- Placeway, P.; Lafferty, J. Cheating with imperfect transcripts. In Proceeding of Fourth International Conference on Spoken Language Processing (ICSLP’96), Philadelphia, PA, USA, 3–6 October 1996; Volume 4, pp. 2115–2118. [Google Scholar]
- Moreno, P.J.; Joerg, C.; Thong, J.M.V.; Glickman, O. A recursive algorithm for the forced alignment of very long audio segments. In Proceedings of the Fifth International Conference on Spoken Language Processing, Sydney, Australia, 30 November–4 December 1998. [Google Scholar]
- Hazen, T.J. Automatic alignment and error correction of human generated transcripts for long speech recordings. In Proceedings of the Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17– 21 September 2006. [Google Scholar]
- Katsamanis, A.; Black, M.; Georgiou, P.G.; Goldstein, L.; Narayanan, S. SailAlign: Robust long speech-text alignment. In Proceedings of the Workshop on New Tools and Methods for Very-Large Scale Phonetics Research, Philadelphia, PA, USA, 29–31 January 2011. [Google Scholar]
- Anguera, X.; Perez, N.; Urruela, A.; Oliver, N. Automatic synchronization of electronic and audio books via TTS alignment and silence filtering. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar]
- Hoffmann, S.; Pfister, B.; Text-to-speech alignment of long recordings using universal phone models. INTERSPEECH. Citeseer. 2013, pp. 1520–1524. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=c2de617d6eeb82cba0fe7e1453d4ab9a354d3d78 (accessed on 31 January 2023).
- Ruiz, P.; Álvarez, A.; Arzelus, H. Phoneme similarity matrices to improve long audio alignment for automatic subtitling. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC), Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Álvarez, A.; Arzelus, H.; Ruiz, P. Long audio alignment for automatic subtitling using different phone-relatedness measures. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6280–6284. [Google Scholar]
- Bordel, G.; Penagarikano, M.; Rodríguez-Fuentes, L.J.; Álvarez, A.; Varona, A. Probabilistic kernels for improved text-to-speech alignment in long audio tracks. IEEE Signal Process. Lett. 2015, 23, 126–129. [Google Scholar] [CrossRef]
- Gupta, C.; Yılmaz, E.; Li, H. Automatic Lyrics Alignment and Transcription in Polyphonic Music: Does Background Music Help? In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 496–500. [Google Scholar]
- Mohamed, A.r.; Dahl, G.E.; Hinton, G. Acoustic modeling using deep belief networks. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 14–22. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Kelley, M.C.; Tucker, B.V.; A comparison of input types to a deep neural network-based forced aligner. Interspeech 2018. Available online: https://era.library.ualberta.ca/items/0fbd7532-1105-4641-9e12-ebb0e349e460/download/169d5d27-d3a6-411e-ad6d-320032130103 (accessed on 31 January 2023).
- Backstrom, D.; Kelley, M.C.; Tucker, V.B. Forced-alignment of the sung acoustic signal using deep neural nets. Can. Acoust. 2019, 47, 98–99. [Google Scholar]
- Schulze-Forster, K. Informed Audio Source Separation with Deep Learning in Limited Data Settings. Ph.D. Thesis, Institut Polytechnique de Paris, Palaiseau, France, 2021. [Google Scholar]
- Schulze-Forster, K.; Doire, C.S.; Richard, G.; Badeau, R. Phoneme level lyrics alignment and text-informed singing voice separation. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2021, 29, 2382–2395. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1764–1772. [Google Scholar]
- Collobert, R.; Puhrsch, C.; Synnaeve, G. Wav2letter: An end-to-end convnet-based speech recognition system. arXiv 2016, arXiv:1609.03193. [Google Scholar]
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Bengio, C.L.Y.; Courville, A. Towards end-to-end speech recognition with deep convolutional neural networks. arXiv 2017, arXiv:1701.02720. [Google Scholar]
- Hori, T.; Watanabe, S.; Zhang, Y.; Chan, W. Advances in joint CTC-attention based end-to-end speech recognition with a deep CNN encoder and RNN-LM. arXiv 2017, arXiv:1706.02737. [Google Scholar]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/attention architecture for end-to-end speech recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Kim, S.; Hori, T.; Watanabe, S. Joint CTC-attention based end-to-end speech recognition using multi-task learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, Lousiana, USA, 5–9 March 2017; pp. 4835–4839. [Google Scholar]
- Stoller, D.; Durand, S.; Ewert, S. End-to-end Lyrics Alignment for Polyphonic Music Using an Audio-to-Character Recognition Model. arXiv 2019, arXiv:1902.06797. [Google Scholar]
- Kürzinger, L.; Winkelbauer, D.; Li, L.; Watzel, T.; Rigoll, G. CTC-segmentation of large corpora for german end-to-end speech recognition. In Proceedings of the International Conference on Speech and Computer, Online, 7–9 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 267–278. [Google Scholar]
- Tralie, C.; Dempsey, E. Exact, parallelizable dynamic time warping alignment with linear memory. arXiv 2020, arXiv:2008.02734. [Google Scholar]
- Stoller, D.; Ewert, S.; Dixon, S. Wave-u-net: A multi-scale neural network for end-to-end audio source separation. arXiv 2018, arXiv:1806.03185. [Google Scholar]
- Vaglio, A.; Hennequin, R.; Moussallam, M.; Richard, G.; d’Alché Buc, F. Audio-Based Detection of Explicit Content in Music. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 526–530. [Google Scholar]
- Vaglio, A.; Hennequin, R.; Moussallam, M.; Richard, G. The words remain the same—Cover detection with lyrics transcription. In Proceedings of the ISMIR (International Society for Music Information Retrieval), Online, 7–12 November 2021. [Google Scholar]
- Vaglio, A.; Hennequin, R.; Moussallam, M.; Richard, G.; d’Alché Buc, F. Multilingual lyrics-to-audio alignment. In Proceedings of the ISMIR (International Society for Music Information Retrieval), Montréal, Canada, 11–15 October 2020. [Google Scholar]
- Meseguer-Brocal, G.; Cohen-Hadria, A.; Peeters, G. DALI: A large Dataset of synchronized Audio, LyrIcs and notes, automatically created using teacher-student machine learning paradigm. In Proceedings of the 19th International Society for Music Information Retrieval Conference, Paris, France, 23–27 September 2018. [Google Scholar]
- Teytaut, Y.; Roebel, A. Phoneme-to-audio alignment with recurrent neural networks for speaking and singing voice. In Proceedings of the Interspeech 2021; International Speech Communication Association ISCA, Brno, Czechia, 30 August–3 September 2021; pp. 61–65. [Google Scholar]
- Salais, L.; Arias, P.; Le Moine, C.; Rosi, V.; Teytaut, Y.; Obin, N.; Roebel, A. Production Strategies of Vocal Attitudes. In Proceedings of the Interspeech 2022, Incheon, Korea, 18–22 September 2022; pp. 4985–4989. [Google Scholar]
- Le Moine, C.; Obin, N. Att-HACK: An Expressive Speech Database with Social Attitudes. Speech Prosody. arXiv 2020, arXiv:2004.04410. [Google Scholar]
- Teytaut, Y.; Bouvier, B.; Roebel, A. A study on constraining Connectionist Temporal Classification for temporal audio alignment. In Proceedings of the Interspeech 2022, Incheon, Korea, 18–22 September 2022; pp. 5015–5019. [Google Scholar]
- Yi, B.K.; Jagadish, H.V.; Faloutsos, C. Efficient retrieval of similar time sequences under time warping. In Proceedings of the 14th International Conference on Data Engineering, Orlando, FL, USA, 23–27 February 1998; pp. 201–208. [Google Scholar]
- Kim, S.W.; Park, S.; Chu, W.W. An index-based approach for similarity search supporting time warping in large sequence databases. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; pp. 607–614. [Google Scholar]
- Keogh, E.; Ratanamahatana, C.A. Exact indexing of dynamic time warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Rakthanmanon, T.; Campana, B.; Mueen, A.; Batista, G.; Westover, B.; Zhu, Q.; Zakaria, J.; Keogh, E. Searching and mining trillions of time series subsequences under dynamic time warping. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 262–270. [Google Scholar]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process.. 1978, 26, 43–49. [Google Scholar] [CrossRef] [Green Version]
- Chu, S.; Keogh, E.; Hart, D.; Pazzani, M. Iterative deepening dynamic time warping for time series. In Proceedings of the 2002 SIAM International Conference on Data Mining, Arlington, VA, USA, 11–13 April 2002; pp. 195–212. [Google Scholar]
- Salvador, S.; Chan, P. Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef]
- Müller, M.; Mattes, H.; Kurth, F. An efficient multiscale approach to audio synchronization. ISMIR Citeseer. 2006, Volume 546, pp. 192–197. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=323315c47f1fb9c39473d00f9e417f378787d7d3 (accessed on 31 January 2023).
- Tsai, T.; Tjoa, S.K.; Müller, M.; Make Your Own Accompaniment: Adapting Full-Mix Recordings to Match Solo-Only User Recordings. ISMIR. 2017, pp. 79–86. Available online: https://www.audiolabs-erlangen.de/content/05-fau/professor/00-mueller/03-publications/2017_TsaiTM_Accompaniment_ISMIR.pdf (accessed on 31 January 2023).
- Dixon, S.; Widmer, G.; MATCH: A Music Alignment Tool Chest. ISMIR. 2005, pp. 492–497. Available online: http://www.cp.jku.at/research/papers/dixon_ismir_2005.pdf (accessed on 31 January 2023).
- Dixon, S. Live tracking of musical performances using on-line time warping. In Proceedings of the 8th International Conference on Digital Audio Effects, Madrid, Spain, 20–22 September 2005; Volume 92, pp. 22–97. [Google Scholar]
- Macrae, R.; Dixon, S.; Accurate Real-time Windowed Time Warping. ISMIR. Citeseer. 2010, pp. 423–428. Available online: http://www.eecs.qmul.ac.uk/~simond/pub/2010/Macrae-Dixon-ISMIR-2010-WindowedTimeWarping.pdf (accessed on 31 January 2023).
- Li, J.; Wang, Y. EA DTW: Early Abandon to Accelerate Exactly Warping Matching of Time Series. In Proceedings of the International Conference on Intelligent Systems and Knowledge Engineering 2007; 2007; pp. 1200–1207. Available online: https://www.atlantis-press.com/proceedings/iske2007/1421 (accessed on 31 January 2023).
- Silva, D.F.; Batista, G.E. Speeding up all-pairwise dynamic time warping matrix calculation. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, Florida, USA, 5–7 May 2016; pp. 837–845. [Google Scholar]
- Cont, A.; Schwarz, D.; Schnell, N.; Raphael, C. Evaluation of real-time audio-to-score alignment. In Proceedings of the International Symposium on Music Information Retrieval (ISMIR), Vienna, Austria, 23–27 September 2007. [Google Scholar]
- Kuchaiev, O.; Ginsburg, B.; Gitman, I.; Lavrukhin, V.; Li, J.; Nguyen, H.; Case, C.; Micikevicius, P. Mixed-precision training for nlp and speech recognition with openseq2seq. arXiv 2018, arXiv:1805.10387. [Google Scholar]
- Gao, X.; Gupta, C.; Li, H.; Lyrics Transcription and Lyrics-to-Audio Alignment with Music-Informed Acoustic Models. MIREX. 2021. Available online: https://www.researchgate.net/profile/Gao-Xiaoxue/publication/345628181_LYRICS_TRANSCRIPTION_AND_LYRICS-TO-AUDIO_ALIGNMENT_WITH_MUSIC-INFORMED_ACOUSTIC_MODELS/links/5fa953cb92851cc286a08264/LYRICS-TRANSCRIPTION-AND-LYRICS-TO-AUDIO-ALIGNMENT-WITH-MUSIC-INFORMED-ACOUSTIC-MODELS.pdf (accessed on 31 January 2023).
- Zhang, B.; Wang, W.; Zhao, E.; Lui, S.; Lyrics-to-Audio Alignment for Dynamic Lyric Generation. Music Inf. Retrieval Eval. eXchange Audio-Lyrics Alignment Challenge. 2022. Available online: https://www.music-ir.org/mirex/abstracts/2020/ZWZL1.pdf (accessed on 31 January 2023).
- Demirel, E.; Ahlback, S.; Dixon, S.; A recursive Search Method for Lyrics Alignment. MIREX 2020 Audio-to-Lyrics Alignment and Lyrics Transcription Challenge. 2020. Available online: https://www.music-ir.org/mirex/abstracts/2020/DDA3.pdf (accessed on 31 January 2023).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chapter 10 AAE | ||||||||
|---|---|---|---|---|---|---|---|---|
| Chapters | Duration (hh:mm:ss) | # Words | # Pivots | MAAE [ms] | Q50% [ms] | Q95% [ms] | Q99% [ms] | PCO [%] |
| 10 (baseline) | 00:20:26 | 2672 | 0 | 51 | 46 | 118 | 145 | 100 |
| 7–10 | 01:23:25 | 11,322 | 4 | 52 | 46 | 117 | 147 | 100 |
| 10–13 | 01:17:36 | 10,762 | 4 | 51 | 46 | 117 | 147 | 100 |
| 7–13 | 02:20:35 | 19,411 | 6 | 52 | 46 | 118 | 147 | 100 |
| Playlist 50 AAE | ||||||||
|---|---|---|---|---|---|---|---|---|
| Tracks | Duration (hh:mm:ss) | # Words | # Pivots | MAAE [ms] | Q50% [ms] | Q95% [ms] | Q99% [ms] | PCO [%] |
| P50 (baseline) | 02:51:43 | 18,904 | 8 | 120 | 40 | 300 | 1221 | 94.9 |
| 50 + P50 | 05:34:32 | 34,990 | 12 | 121 | 40 | 302 | 1223 | 94.9 |
| P50 + 50 | 05:29:53 | 34,261 | 12 | 121 | 40 | 302 | 1222 | 94.8 |
| 50 + P50 + 50 | 08:12:42 | 51,157 | 16 | 122 | 42 | 302 | 1223 | 94.7 |
| Language | MAAE [ms] | Q50% [ms] | Q95% [ms] | Q99% [ms] | PCO [%] |
|---|---|---|---|---|---|
| Arabic * | 42 | 29 | 116 | 236 | 100 |
| Chinese * | 30 | 27 | 75 | 112 | 100 |
| Czech | 27 | 7 | 78 | 109 | 100 |
| Dutch | 79 | 82 | 124 | 158 | 100 |
| French | 49 | 45 | 97 | 115 | 100 |
| German | 25 | 24 | 54 | 95 | 100 |
| Greek * | 37 | 36 | 85 | 92 | 100 |
| Italian | 80 | 79 | 129 | 165 | 100 |
| Spanish | 77 | 80 | 137 | 206 | 100 |
| Language | MAAE [ms] | Q50% [ms] | Q95% [ms] | Q99% [ms] | PCO [%] |
|---|---|---|---|---|---|
| English | 116 | 37 | 260 | 1501 | 95.7 |
| French | 2013 | 68 | 7759 | 44,767 | 78.6 |
| German | 1502 | 49 | 5807 | 35,435 | 84.1 |
| Italian | 1596 | 60 | 6628 | 35,557 | 79.9 |
| Spanish | 1571 | 47 | 6281 | 39,648 | 84.1 |
| Librispeech Dev-Clean | Chapter 10 | ||||
|---|---|---|---|---|---|
| Model | # Params | CER [%] | WER [%] | MAAE [ms] | Q50% [ms] |
| Wav2Letter | 106.5M | 3.6 | 10.6 | 66 | 61 |
| Ours | 37.8M | 8.5 | 26.9 | 51 | 46 |
| Hansen (a Cappella) | Jamendo | |||
|---|---|---|---|---|
| System | MAAE [ms] | Q50% [ms] | MAAE [ms] | Q50% [ms] |
| Gao et al. [66] | 87 | 32 | 217 | 46 |
| Zhang et al. [67] | 110 | 32 | 610 | 60 |
| Demirel et al. [68] | 930 | 946 | 500 | 85 |
| Ours | 117 | 44 | 310 | 46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doras, G.; Teytaut, Y.; Roebel, A. A Linear Memory CTC-Based Algorithm for Text-to-Voice Alignment of Very Long Audio Recordings. Appl. Sci. 2023, 13, 1854. https://doi.org/10.3390/app13031854
Doras G, Teytaut Y, Roebel A. A Linear Memory CTC-Based Algorithm for Text-to-Voice Alignment of Very Long Audio Recordings. Applied Sciences. 2023; 13(3):1854. https://doi.org/10.3390/app13031854
Chicago/Turabian StyleDoras, Guillaume, Yann Teytaut, and Axel Roebel. 2023. "A Linear Memory CTC-Based Algorithm for Text-to-Voice Alignment of Very Long Audio Recordings" Applied Sciences 13, no. 3: 1854. https://doi.org/10.3390/app13031854
APA StyleDoras, G., Teytaut, Y., & Roebel, A. (2023). A Linear Memory CTC-Based Algorithm for Text-to-Voice Alignment of Very Long Audio Recordings. Applied Sciences, 13(3), 1854. https://doi.org/10.3390/app13031854