
Locally Activated Gated Neural Network for Automatic Music Genre Classification

Abstract
:1. Introduction
- We reveal the intra-class differences problem in music genre classification, which impedes the progress of recognition performance.
- We propose the locally activated gated network, which can adaptively dispatch the most appropriate network layer based on inputs.
- Our experimental results demonstrate that LGNet outperforms the existing methods on the filtered GTZAN dataset.
2. Related Works
2.1. Classic Machine Learning
2.2. Deep Learning
3. Materials and Methods
3.1. Acoustic Feature Extraction
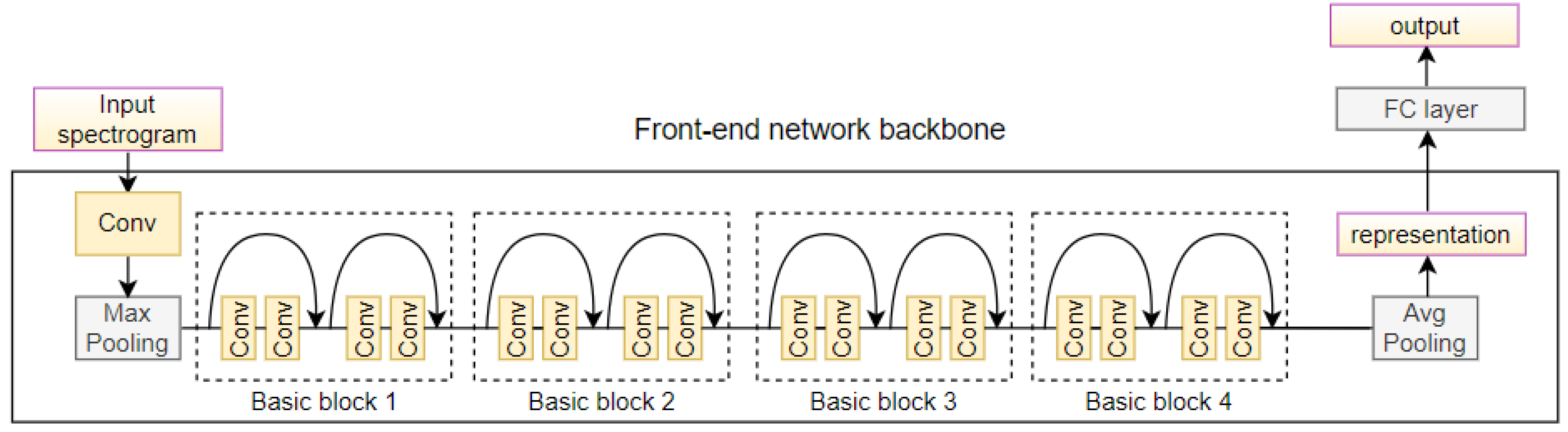
3.2. Neural Network Backbone
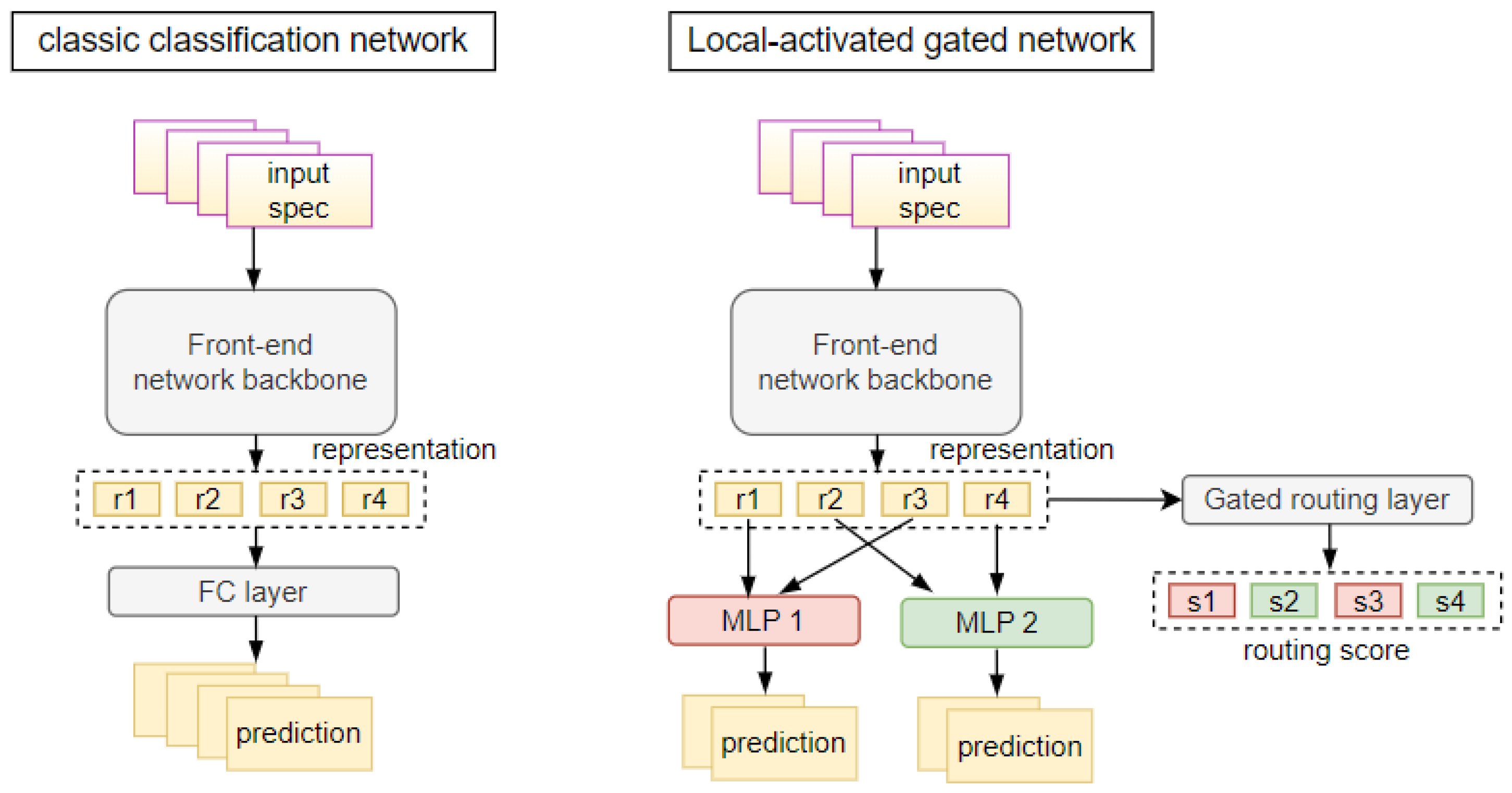
3.3. Framework of Locally Activated Gated Network
| Algorithm 1: The overall training flow for LGNet. |
 |
4. Experiment Setup
4.1. Dataset
4.2. Baseline Methods
4.3. Parameters Setup
5. Results and Discussion
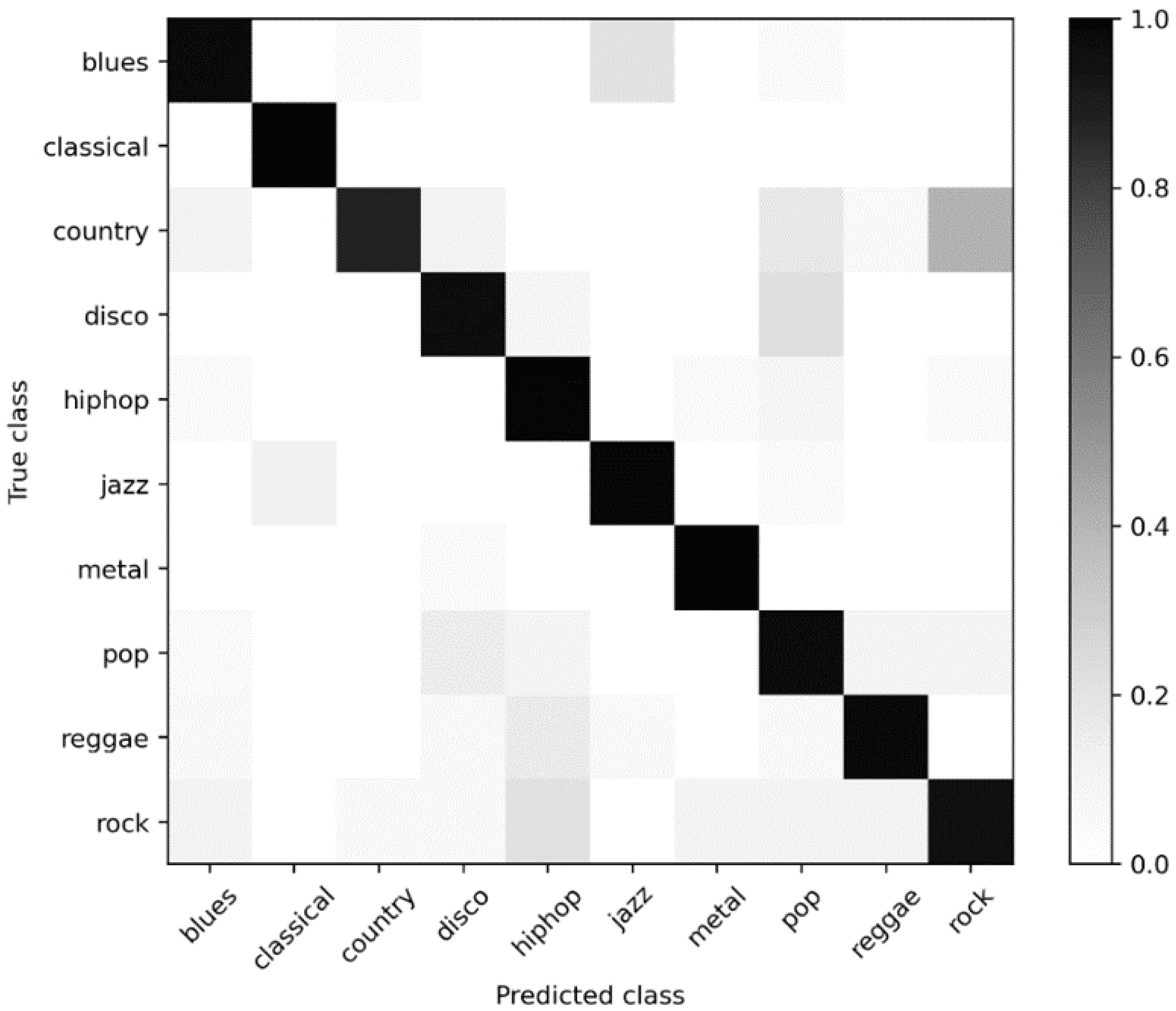
5.1. Main Results
5.2. Selection of Activation Function
5.3. Number of MLP Layers
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Tzanetakis, G.; Cook, P. Musical genre classification of audio signals. IEEE Trans. Speech Audio Process. 2002, 10, 293–302. [Google Scholar] [CrossRef]
- Liu, J.; Wang, C.; Zha, L. A middle-level learning feature interaction method with deep learning for multi-feature music genre classification. Electronics 2021, 10, 2206. [Google Scholar] [CrossRef]
- Chaudhury, M.; Karami, A.; Ghazanfar, M.A. Large-Scale Music Genre Analysis and Classification Using Machine Learning with Apache Spark. Electronics 2022, 11, 2567. [Google Scholar] [CrossRef]
- Elbir, A.; Aydin, N. Music genre classification and music recommendation by using deep learning. Electron. Lett. 2020, 56, 627–629. [Google Scholar] [CrossRef]
- Rajanna, A.R.; Aryafar, K.; Shokoufandeh, A.; Ptucha, R. Deep neural networks: A case study for music genre classification. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 655–660. [Google Scholar]
- Xu, C.; Maddage, N.C.; Shao, X.; Cao, F.; Tian, Q. Musical genre classification using support vector machines. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; Volume 5, pp. 429–432. [Google Scholar]
- Kour, G.; Mehan, N. Music genre classification using MFCC, SVM and BPNN. Int. J. Comput. Appl. 2015, 112, 12–14. [Google Scholar]
- Patil, N.M.; Nemade, M.U. Music genre classification using MFCC, K-NN and SVM classifier. Int. J. Comput. Eng. Res. Trends 2017, 4, 43–47. [Google Scholar]
- Khasgiwala, Y.; Tailor, J. Vision transformer for music genre classification using mel-frequency cepstrum coefficient. In Proceedings of the 2021 IEEE 4th International Conference on Computing, Power and Communication Technologies (GUCON), Kuala Lumpur, Malaysia, 23–25 September 2021; pp. 1–5. [Google Scholar]
- Pelchat, N.; Gelowitz, C.M. Neural network music genre classification. Can. J. Electr. Comput. Eng. 2020, 43, 170–173. [Google Scholar] [CrossRef]
- Cheng, Y.H.; Kuo, C.N. Machine Learning for Music Genre Classification Using Visual Mel Spectrum. Mathematics 2022, 10, 4427. [Google Scholar] [CrossRef]
- Jena, K.K.; Bhoi, S.K.; Mohapatra, S.; Bakshi, S. A hybrid deep learning approach for classification of music genres using wavelet and spectrogram analysis. Neural Comput. Appl. 2023, 1–26. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, C.; Zhu, B.; Ma, Z.; Zhang, K. S3t: Self-supervised pre-training with swin transformer for music classification. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 606–610. [Google Scholar]
- Silla, C.N.; Koerich, A.L.; Kaestner, C.A. A machine learning approach to automatic music genre classification. J. Braz. Comput. Soc. 2008, 14, 7–18. [Google Scholar] [CrossRef]
- Bahuleyan, H. Music genre classification using machine learning techniques. arXiv 2018, arXiv:1804.01149. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Liang, S.; Xue, W.; Ni, C.; Liu, W. Long short-term memory recurrent neural network based segment features for music genre classification. In Proceedings of the 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP), Tianjin, China, 17–20 October 2016; pp. 1–5. [Google Scholar]
- Ashraf, M.; Abid, F.; Din, I.U.; Rasheed, J.; Yesiltepe, M.; Yeo, S.F.; Ersoy, M.T. A Hybrid CNN and RNN Variant Model for Music Classification. Appl. Sci. 2023, 13, 1476. [Google Scholar] [CrossRef]
- Kamala, A.; Hassani, H. Kurdish Music Genre Recognition Using a CNN and DNN. Eng. Proc. 2022, 31, 64. [Google Scholar]
- Rimmer, M. Beyond omnivores and univores: The promise of a concept of musical habitus. Cult. Sociol. 2012, 6, 299–318. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Xu, L.; Jordan, M.; Hinton, G.E. An alternative model for mixtures of experts. Adv. Neural Inf. Process. Syst. 1994, 7, 633–640. [Google Scholar]
- Abeßer, J.; Müller, M. Jazz bass transcription using a U-net architecture. Electronics 2021, 10, 670. [Google Scholar] [CrossRef]
- Zhuang, Y.; Chen, Y.; Zheng, J. Music genre classification with transformer classifier. In Proceedings of the 2020 4th International Conference on Digital Signal Processing, Chengdu, China, 19–21 June 2020; pp. 155–159. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lee, J.; Nam, J. Multi-level and multi-scale feature aggregation using pretrained convolutional neural networks for music auto-tagging. IEEE Signal Process. Lett. 2017, 24, 1208–1212. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Accuracy (STFT) | Accuracy (Mel) | Accuracy (CQT) |
|---|---|---|---|
| Naive Bayes | 50.48 | 54.45 | 51.90 |
| SVM | 62.25 | 64.36 | 64.99 |
| LSTM | 60.14 | 61.44 | 60.79 |
| Bi-LSTM | 61.48 | 62.01 | 61.41 |
| FCN | 73.55 | 74.39 | 68.86 |
| FCN-LSTM | 72.59 | 73.70 | 71.28 |
| ResNet | 74.60 | 74.55 | 72.51 |
| LGNet-2MLP | 82.43 | 82.36 | 79.17 |
| LGNet-4MLP | 82.24 | 82.71 | 79.55 |
| Methods | Accuracy (STFT) | Accuracy (Mel) | Accuracy (CQT) |
|---|---|---|---|
| Linear | 76.32 | 77.93 | 75.47 |
| Softmax | 82.24 | 82.71 | 79.55 |
| Sigmoid | 81.13 | 81.49 | 79.44 |
| Methods | Accuracy (STFT) | Accuracy (Mel) | Accuracy (CQT) |
|---|---|---|---|
| LGNet-2MLP | 82.43 | 82.36 | 79.17 |
| LGNet-4MLP | 82.24 | 82.71 | 79.55 |
| LGNet-8MLP | 82.20 | 82.59 | 79.67 |
| LGNet-16MLP | 81.71 | 81.46 | 78.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Bian, T.; Yang, M. Locally Activated Gated Neural Network for Automatic Music Genre Classification. Appl. Sci. 2023, 13, 5010. https://doi.org/10.3390/app13085010
Liu Z, Bian T, Yang M. Locally Activated Gated Neural Network for Automatic Music Genre Classification. Applied Sciences. 2023; 13(8):5010. https://doi.org/10.3390/app13085010
Chicago/Turabian StyleLiu, Zhiwei, Ting Bian, and Minglai Yang. 2023. "Locally Activated Gated Neural Network for Automatic Music Genre Classification" Applied Sciences 13, no. 8: 5010. https://doi.org/10.3390/app13085010
APA StyleLiu, Z., Bian, T., & Yang, M. (2023). Locally Activated Gated Neural Network for Automatic Music Genre Classification. Applied Sciences, 13(8), 5010. https://doi.org/10.3390/app13085010