
Matrix Chain Multiplication and Equivalent Reduced-Order Parallel Calculation Method for a Robotic Arm

Abstract
:Featured Application
Abstract
1. Introduction
2. Kinematic Calculation Matrix Chain Multiplication
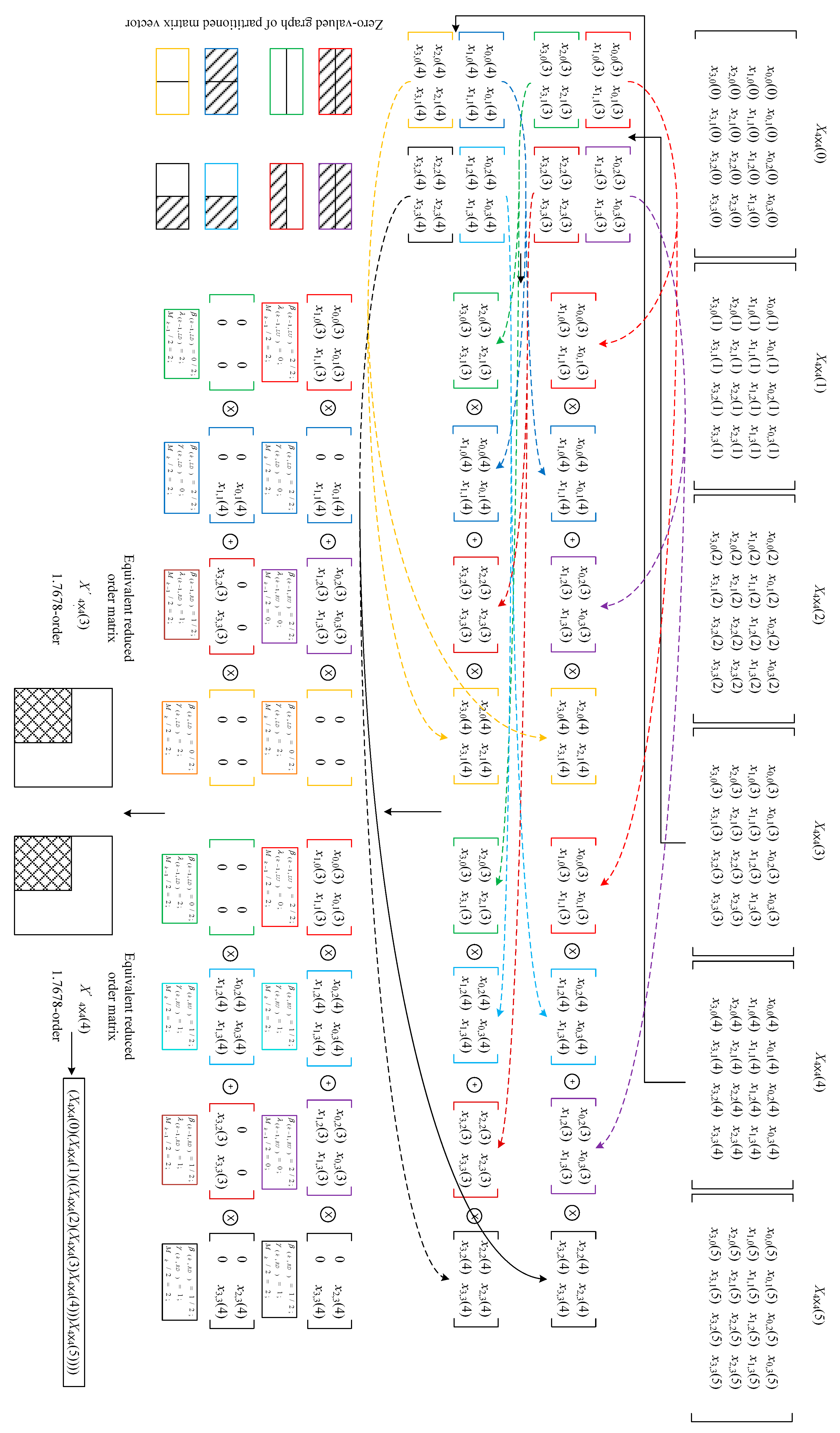
3. Equivalent Order Reduction Method
4. Parallel Dot Product Matrix Calculation
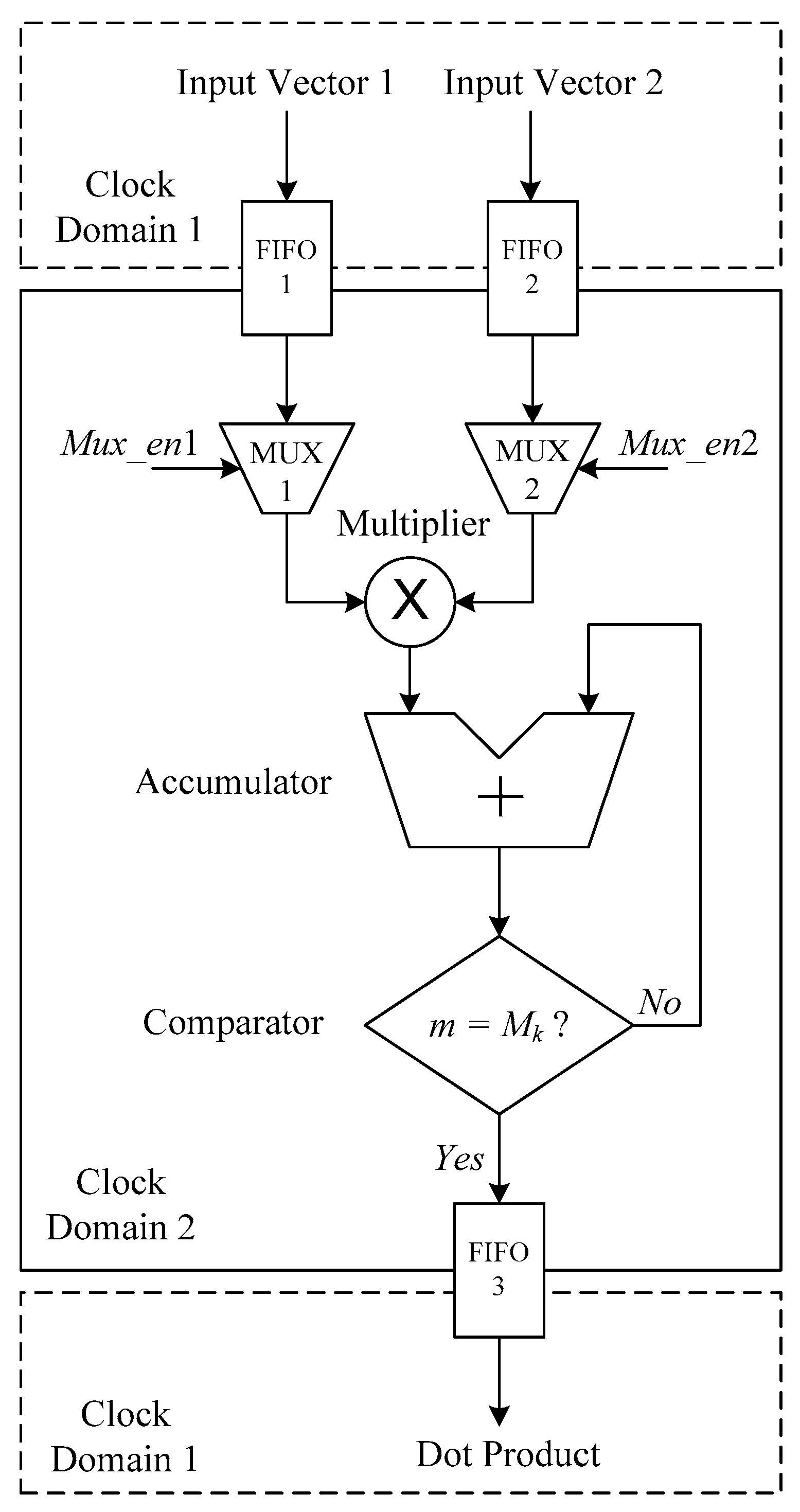
4.1. Parallel Dot Product Matrix Computing Architecture
4.2. Calculation Examples and Results
4.3. Performance Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, P.; Long, J.; Yang, W.; Leng, J. Inverse Kinematics Solution of Underwater Manipulator Based on Jacobi Matrix. In Proceedings of the OCEANS 2021: San Diego—Porto, San Diego, CA, USA, 20–23 September 2021; pp. 1–4. [Google Scholar]
- Li, T.; Calandra, R.; Pathak, D.; Tian, Y.; Meier, F.; Rai, A. Planning in Learned Latent Action Spaces for Generalizable Legged Locomotion. IEEE Robot. Autom. Lett. 2021, 6, 2682–2689. [Google Scholar] [CrossRef]
- Wiedmeyer, W.; Altoé, P.; Auberle, J.; Ledermann, C.; Kröger, T. A Real-Time-Capable Closed-Form Multi-Objective Redundancy Resolution Scheme for Seven-DoF Serial Manipulators. IEEE Robot. Autom. Lett. 2021, 6, 431–438. [Google Scholar] [CrossRef]
- Hu, C.; Lin, S.; Wang, Z.; Zhu, Y. Task Space Contouring Error Estimation and Precision Iterative Control of Robotic Manipulators. IEEE Robot. Autom. Lett. 2022, 7, 7826–7833. [Google Scholar] [CrossRef]
- Plancher, B.; Brumar, C.D.; Brumar, I.; Pentecost, L.; Rama, S.; Brooks, D. Application of Approximate Matrix Multiplication to Neural Networks and Distributed SLAM. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 24–26 September 2019; pp. 1–7. [Google Scholar]
- Wang, Y.; Tang, Z.; Li, D.; Zeng, L.; Zhang, X.; Wang, N. Research and Software Implementation of Accuracy Analysis of Space Manipulator. Manned Spacefl. 2021, 27, 59–65. [Google Scholar]
- Bhardwaj, G.; Sukavanam, N.; Panwar, R.; Balasubramanian, R. An Unsupervised Neural Network Approach for Inverse Kinematics Solution of Manipulator following Kalman Filter based Trajectory. In Proceedings of the 2019 IEEE Conference on Information and Communication Technology, Allahabad, India, 6–8 December 2019; pp. 1–6. [Google Scholar]
- Liu, Q.; Liu, C. Calculation Optimization for Convolutional Neural Networks and FPGA-based Accelerator Design Using the Parameters Sparsity. J. Electron. Inf. Technol. 2018, 40, 1368–1374. [Google Scholar] [CrossRef]
- Li, Y.; Xue, W.; Chen, D.; Wang, X.; Xu, P.; Zhang, W.; Yang, G. Performance Optimization for Sparse Matrix-Vector Multiplication on Sunway Architecture. Chin. J. Comput. 2020, 43, 1010–1024. [Google Scholar]
- Pligouroudis, M.; Nuno, R.A.G.; Kazmierski, T. Modified Compressed Sparse Row Format for Accelerated FPGA-Based Sparse Matrix Multiplication. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- Tang, Y.; Zhao, D.; Huang, Z.; Dai, Z. High Performance Row-based Hashing GPU SpGEMM. J. Beijing Univ. Posts Telecommun. 2019, 42, 106–113. [Google Scholar] [CrossRef]
- Finean, M.N.; Merkt, W.; Havoutis, I. Simultaneous Scene Reconstruction and Whole-Body Motion Planning for Safe Operation in Dynamic Environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3710–3717. [Google Scholar]
- Zhang, Z.; Wang, J.; Zhang, L.; Xiao, J. FPGA based Floating Point Separable Convolutional Neural Network Acceleration Method. Chin. High Technol. Lett. 2022, 32, 441–453. [Google Scholar]
- Ran, D.; Wu, D.; Qian, L. Design of Matrix Multiplication Accelerator for Deep Learning Inference. Comput. Eng. 2019, 45, 40–45. [Google Scholar]
- Zhang, R.; Zhang, J.; Dai, Y.; Shang, H.; Li, Y. Forward and Inverse Kinematics of the Robot Based on FPGA. Acta Sci. Nat. Univ. Nankaiensis (Nat. Sci. Ed.) 2018, 51, 18–23. [Google Scholar]
- Weiss, E.; Schwartz, O. Computation of Matrix Chain Products on Parallel Machines. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 491–500. [Google Scholar]
- Song, Y.; Zheng, Q.; Wang, Z.; Zhang, D. A large dimensional matrix chain matrix multiplier for extremely low IO bandwidth requirements. Appl. Electron. Tech. 2019, 45, 32–38. [Google Scholar]
- Han, L.-L.; Ye, P.; Sun, H.; Ji, X. A Jacobian Matrix Inversion Method for Redundant Robotic Manipulator Base on QR Decomposition. Comput. Eng. Softw. 2013, 11, 64–66. [Google Scholar]
- Shyamala, K.; Kiran, K.R.; Rajeshwari, D. Design and implementation of GPU-based matrix chain multiplication using C++AMP. In Proceedings of the International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 22–24 February 2017; pp. 1–6. [Google Scholar]
- Ma, R.; Chen, Q.; Zhang, H.; Mei, Z.; Wang, R.; Wei, W. Low Power Visual Odometry Technology Based on Monocular Depth Estimation. J. Syst. Simul. 2021, 33, 3001–3011. [Google Scholar] [CrossRef]
- Yu, J.-Y.; Huang, D.; Liang, C.-C.; Wang, B.; Zhang, X.-D.; Lu, L. On-board Real-time Path Planning Design for Large-scale 7-DOF Space Manipulator. In Proceedings of the IEEE International Conference on Mechatronics and Automation, Harbin, China, 7–10 August 2016; pp. 1501–1506. [Google Scholar]
- Fan, X.; Saldivia, A.; Soto, P.; Li, J. Coded Matrix Chain Multiplication. In Proceedings of the IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), Tokyo, Japan, 25–28 June 2021; pp. 1–6. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Slices | DSP48E | Block RAM (18 kb) | Computation Time | Maximum Operating Frequency |
|---|---|---|---|---|---|
| [21] | 6739 | 76 | 388 | 2.3 ms | 167 MHz |
| Proposed | 7124 | 91 | 446 | 0.37 ms | 172 MHz |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Huang, D.; Li, W.; Wang, X.; Shi, X. Matrix Chain Multiplication and Equivalent Reduced-Order Parallel Calculation Method for a Robotic Arm. Appl. Sci. 2023, 13, 1931. https://doi.org/10.3390/app13031931
Yu J, Huang D, Li W, Wang X, Shi X. Matrix Chain Multiplication and Equivalent Reduced-Order Parallel Calculation Method for a Robotic Arm. Applied Sciences. 2023; 13(3):1931. https://doi.org/10.3390/app13031931
Chicago/Turabian StyleYu, Jiyang, Dan Huang, Wenjie Li, Xianjie Wang, and Xiaolong Shi. 2023. "Matrix Chain Multiplication and Equivalent Reduced-Order Parallel Calculation Method for a Robotic Arm" Applied Sciences 13, no. 3: 1931. https://doi.org/10.3390/app13031931
APA StyleYu, J., Huang, D., Li, W., Wang, X., & Shi, X. (2023). Matrix Chain Multiplication and Equivalent Reduced-Order Parallel Calculation Method for a Robotic Arm. Applied Sciences, 13(3), 1931. https://doi.org/10.3390/app13031931