1. Introduction
An arc magnet [
1] generally refers to a curved, magnetic object made of ferrite, NdFeB, AlNiCo, etc. It is mounted on the stator or rotor of the motor and is essential to generate a constant magnetic field in a permanent magnet motor. Surface defects, such as cracks, blowholes, fray, break, unevenness, and blot, may appear on an arc magnet due to the complex manufacturing process. These defects tend to seriously affect the mechanical strength and magnetic properties of an arc magnet, leading to abnormal motor operation and even safety accidents [
2]. The current widely used surface defect detection method for arc magnets still relies on manual observation methods under visible light. However, such methods require extensive manual experience and are characterized by vague detection criteria, unstable recognition accuracy, low execution efficiency, and weak automation [
3]. In order to ensure the large-scale production of diverse high-quality arc magnets, it is particularly urgent and important to develop accurate, fast, and automated identification methods for arc magnet surface defects.
Due to the visibility of surface defects, machine vision [
4] is widely recognized as a promising technology for identifying surface defects on arc magnets. Over the last decade, several studies [
5,
6,
7] have sought to determine typical surface defects by analyzing the surface images of arc magnets. In general, the image-based surface-defect identification of arc magnets can be defined by two approaches: traditional mathematical methods [
8] and deep-learning methods [
9]. The former focuses on presenting information rules through the discrete transformation of images to discover and extract defect features. For example, Li et al. [
10] combined non-sampling outline transformation and texture characteristics to detect surface defects from arc magnet images; the defect extraction accuracy by this method reached 93.57%. Gharsallah et al. [
11] proposed an image recognition algorithm for arc magnet surface defects based on a new anisotropic diffusion filtering model that performed well in the edge extraction of surface defects, resulting in a significant improvement in defect recognition accuracy. Li et al. [
12] proposed a crack defect detection algorithm based on the Contourlet transform and singular value decomposition to build relationships between image grey features and arc magnet surface defects, effectively overcoming noise interference in identifying the crack and fray.
Although these methods are conducive to extracting the image features that represent surface defects, they are extremely sensitive to the matching and selecting of discrete laws and feature distributions, which is unsuitable for complex and weak surface defects with features of poor regularity. On the other hand, with the advancement of recent developments in artificial intelligence, deep learning [
13] has made increasingly noteworthy achievements in solving the identification problem of arc magnet surface defects. A growing number of novel learning models are being created to autonomously learn and identify surface defect information in arc magnet images. For instance, An et al. [
14] presented a segmentation method of the weighted You Only Look At CoefficienTs (YOLACT) model to solve the problems of slow speed and low segmentation accuracy of different defects on the magnetic tile surface, achieving good segmentation results at the segmentation speed of 24.40 fps and mean average precision of 53.44. Hu et al. [
15] used UPM-DenseNet to design an online two-stage model for arc magnet surface defects, improving the accuracy and speed of the recognition regarding weak defects. Liu et al. [
16] provided a semi-supervised learning method based on pseudo-labeling to address the time-consuming and error-prone problems of surface defect classification of magnetic tiles with limited labeled samples. Cao et al. [
17] constructed an unsupervised defect segmentation method using attention-enhanced flexible U-Net to automate surface defect inspection for magnetic tiles, in which the recall rate reached 97.5% better than the supervised method. Liang et al. [
18] applied a feature enhancement and loop-shaped fusion convolutional neural network to enhance shallow features and fuse features with a loop-shaped feature pyramid structure when identifying small objects of magnetic tile surface defects. Compared with traditional mathematical methods, deep-learning models are more suitable for autonomous discovery and identification of surface defect targets of arc magnets, which tend to have higher accuracy and faster speed. Nevertheless, existing models are usually developed for specific surface defects and lack general applicability to a wide range of defect types.
Recently, deep-learning-based object detection algorithms [
19] for extensive categories have made significant breakthroughs, bringing a new potential solution to the problems involved in the surface defect detection of arc magnets. The applicable methods can be broadly defined by two categories: two-stage algorithms and one-stage algorithms. The former, which includes R-CNN [
20], Fast R-CNN [
21], Faster R-CNN [
22], etc., requires the algorithm to generate a series of target candidate frames and then classify and regress the frames to identify targets. The latter, including You Only Look Once (YOLO) [
23], Single Shot MultiBox Detector (SSD) [
24], etc., can directly predict the class and location of different targets using only one convolutional neural network (CNN), usually with a higher execution speed. Among them, YOLO algorithms have been widely used in real-time target detection due to their obvious advantages in accuracy and speed. The YOLO series has evolved from YOLOv1 to YOLOv7 and continues to develop. Compared with the old and new versions, YOLOv5 currently has superior comprehensive performance as well as many application cases. Moreover, YOLOv5s, which has a minimal network size in the YOLOv5 version, is more convenient for achieving high-efficiency object detection. For example, Wang et al. [
25] developed an accurate apple fruitlet detection method with a small model size based on a channel-pruned YOLO v5s deep-learning algorithm, achieving a recall, precision, F1 score, and false detection rate of 87.6%, 95.8%, 91.5%, and 4.2%, respectively. Xu et al. [
26] modified the backbone network of the YOLOv5s architecture for zanthoxylum target detection, which improved accuracy, recall rate, and mean average precision by 4.19%, 28.7%, and 14.8%, respectively. Zhao et al. [
27] presented a system for detecting damage in concrete dams that combined the proposed YOLOv5s-HSC algorithm and a three-dimensional photogrammetric reconstruction method to identify and locate objects accurately. Most current efforts have been devoted to further refining the performance of YOLOv5s to expand its applications, but there are few studies on identifying surface defects on arc magnets.
In addition, it is worth noting that improving the performance of the deep-learning model inevitably brings a significant increase in training samples, parameters, and model size. It necessarily imposes an additional burden on computing power and data volume, raising a series of issues related to cost and efficiency. Therefore, reusing the trained neural network and compressing the model play an important role in solving these problems. Transfer learning [
28] can convert a model that is already well-trained in some original task into a model for a new task by using relatively small training samples. Its essence is to use the knowledge learned from previous tasks, such as data features, model parameters, and so on, to assist the learning process for the new task. Transfer learning is receiving increasing attention and applications in many fields. Saber et al. [
29] designed a novel transfer learning model to detect and classify breast cancer using mammogram breast images automatically. Ali et al. [
30] proposed an enhanced technique of skin cancer classification using a deep convolutional neural network with transfer learning models. Network pruning [
31] and knowledge distillation [
32] are also model compression techniques that are currently popular and have generated many studies and applications. Network pruning methods involve the removal of irrelevant weight connections in a network to increase inference speed and decrease model size. Knowledge distillation approaches transfer knowledge from a heavy network to a compact network so that the lightweight model retains the performance of the massive one as much as possible. They have proven effective in compressing most deep-learning models. For instance, Jiang et al. [
33] provided a pruning approach for reducing model parameters to shorten the computation overhead and overall training time in federated learning on edge devices. Xu et al. [
34] used a knowledge-distillation framework to reduce the model weight and floating-point operations in compressing a deep neural network for the prediction of a machine’s remaining useful life.
According to the literature reviews mentioned above, YOLOv5s is expected to achieve highly accurate recognition, while network pruning and knowledge distillation may contribute greatly to its computing efficiency. However, it remains unclear how they could be correctly integrated and utilized in the automated identification of surface defects on arc magnets. To this end, we proposed a lightweight transfer learning model with pruned and distilled YOLOv5s and applied it to identify multiple surface defects on various arc magnets. The contributions of this paper can be mainly summarized in three aspects:
(1) We developed a transfer learning model based on the frozen and fine-tuned YOLOv5s to achieve high accuracy in identifying surface defects of arc magnets through small-sample training.
(2) We presented a YOLOv5s compression strategy of network pruning followed by knowledge distillation to minimize the loss of recognition accuracy when maximizing the reduction of model parameters and size.
(3) We introduced a newly defined λ weight factor in the confidence loss function of the student model during knowledge distillation to improve the sensitivity of identifying image information regarding the surface defects.
The remainder of this paper is structured as follows: the proposed method for identifying surface defects on arc magnets is described in
Section 2. The details of the experiments for our method are presented in
Section 3. The experimental results are analyzed and discussed in
Section 4. Finally, our conclusions with topics for future research are given in
Section 5.
4. Results and Discussion
4.1. Pre-Training of the YOLOv5s Model
In our study, we adopted the publicly available dataset called COCO2017 to train the learning networks of the YOLO family to build suitable pre-trained models. This dataset stems from Microsoft Common Objects in Context (MS COCO), which is a large-scale dataset for object detection, segmentation, keypoint detection, and captioning. COCO2017 belongs to the sub-dataset of MS COCO for object detection, containing 164,000 images of 80 object categories with bounding boxes and segmentation masks for each instance. The number of images for the training set, validating set, and testing set was 118,000, 5000, and 41,000, respectively.
The YOLO family is currently in its seventh generation; YOLOv3-v7 are the versions with relatively superior performance in object detection. Since lightweight models are beneficial for quickly identifying images, we trained the pre-trained model on the smallest network in terms of size over each generation. As shown in
Table 2, YOLOv5s, YOLOv6-nano, and YOLOv7-tiny had better comprehensive performance in terms of scale, accuracy, and speed compared to other models. Considering that the mAP indicator of YOLOv5s is extremely similar to that of YOLOv6-nano and YOLOv7-tiny, and more importantly, that its current applications and researches are more extensive, we finally decided on YOLOv5s for our pre-training model due to its high acceptance.
4.2. Transfer Learning Process from a Pre-Trained YOLOv5s to a Fine-Tuned YOLOv5s
The pre-training result empowered the YOLOv5s model to extract and distinguish image-based features, resulting in the ability to identify specific objects. The network weights obtained from pre-training were also general for the processing of data not involved in training, but did not necessarily achieve acceptable performance, especially in cases like arc magnet images that differ significantly from the object images used for pre-training. Although retraining the pre-trained model with a large number of arc magnet images was highly beneficial for improving the surface defect identification performance, our dataset was limited and relatively small. Therefore, in our study, transfer learning was exploited to retain those parts of the network in the pre-trained model that were suitable for processing arc magnet images and to adapt the others to be more conducive to perceiving and distinguishing the image-based features of the surface defects through the training of small samples. Our strategy for transfer learning was model-based and contained two aspects. The first was to freeze the partial layers from the backbone network in the already trained YOLOv5s; they were available for extracting the image-based features of arc magnets. The second was to fine-tune the remaining layers of YOLOv5s under small-sample training to improve the accuracy of the model in extracting and discriminating image-based features of the surface defects.
Since the three CSP1-Xs in the backbone network of YOLOv5s are the most crucial feature extraction modules, we used them as references to divide the backbone network into three frozen regions, each of which referred to the corresponding CSP1-X and all layers before it. In parallel, we treated the maximum
[email protected] and the minimum training loss as the basis for judging the optimal effect of fine-tuning all network layers outside the frozen region. As a result, comparing the effects of fine-tuning in different freezing cases enabled us to determine the most suitable transfer from a pre-trained model for the COCO2017 dataset to a highly accurate identification model for our dataset. The effects of the
[email protected] and training loss formed by different combinations of freezing and fine-tuning are depicted in
Figure 5a,b. As can be seen, freezing with fewer layers gave better results after fine-tuning. The maximum
[email protected] (0.999 at the 72nd epoch) and the minimum training loss (0.018 at the 268th epoch) always appeared in the fine-tuning result when freezing the network layers up to the first CSP1-X (namely, CSP1-1). In contrast, the worst
[email protected] and training loss occurred in the fine-tuning result without any frozen layer. Thus, freezing the first CSP1-X module and its preceding layers, which is the approach that we adopted in our proposed framework, proved to be the most reasonable way to freeze layers.
To further illustrate the fine-tuning effect, we used the visualization for the output of the second CSP1-X (namely, the CSP1-3 closest to the CSP1-1) in the backbone network as an example to observe the improvement in the feature extraction. As seen in
Figure 5c, for the same image, the outputs of extracted features from the layer in the frozen and fine-tuned model, which was also regarded as the transferred model, were superior to those of the un-frozen and un-tuned ones. The edge contours belonging to the surface defects of an arc magnet extracted by the transferred model were generally sharper, implying more accurate feature extraction results. Moreover, the image information extracted by the transferred model was more concentrated and had less redundant data, facilitating the filtering and reduction of the output. These results demonstrate that the design of both freezing and fine-tuning the YOLOv5s model that was adopted in our proposed framework was effective. Considering the significant difference between the dataset for pre-training and our dataset for transferring, these freezing and fine-tuning results also indicate a noteworthy phenomenon in transferring a model in the case of large differences in training data: layers frozen in the pre-trained model decrease, while those to be fine-tuned increase.
The performance of the transferred and un-transferred YOLOv5s model in identifying arc magnet surface defects was also evaluated on our dataset’s testing set. The un-transferred model refers to the pre-trained model that had only been retrained by the training set in our dataset, instead of the transferred one that had been frozen and then fine-tuned under our dataset. As shown in
Figure 5d, the transferred model performed better in each accuracy indicator that was related to identifying different surface defects in the testing set of our dataset. Compared to the pre-trained model dataset, our dataset’s training volume was only 12.20% (14,400:118,000). This suggests that our transfer learning strategy allowed the pre-trained model to be adapted and become competent for the arc magnet surface defect identification task with relatively low dependence on the training volume. This also implies that the performance of the pre-trained model that was suitable for surface defect identification was effectively inherited and improved.
4.3. Pruning of the Transferred YOLOv5s Model
The transferred YOLOv5s model only increased in accuracy but did not improve in complexity, size, or computing power dependency, which determine its running speed. To achieve the fast identification of the surface defects, as can be seen in
Figure 6a, we adopted a network pruning approach based on channel removal after calculating the
norm. Taking the output channels corresponding to all convolutional kernels with the 3 × 3 × 32 size in the second layer of the transferred YOLOv5s network as an example, a total of 64 output channels were available in these layers. For the convenience of observation, the 3 × 3 × 32 values of each output channel were accumulated in a 3 × 3 matrix to form a 3 × 3 visualization of this channel, as shown in
Figure 6b. According to Equation (6), each channel can obtain an
norm value corresponding to itself. As depicted in
Figure 6c, these norm values reorder all channels in descending order. Of them, 75%, corresponding to the smaller norm values, were considered redundant channels that need to be removed. By rounding, a total of 48 channels were deleted from this layer. We found that the deleted channels did not contain significant feature information, or even not at all. Except for the input and output layers in the YOLOv5s network, this sort of channel removal was performed for every layer, thereby creating a pruned model. By pruning 75% of the channels, the transferred YOLOv5s model was significantly reduced. The performance of the transferred YOLOv5s model before and after the network pruning is shown in
Figure 6d.
After the channel removal, TNNP, FLOPS, MS, and AITC were decreased by 93.505%, 88.337%, 92.943%, and 9.839%, respectively. Such results offered greater possibilities for rapid identification and easy deployment. However, there was an unacceptable degradation in accuracy; for instance, mAP and
dropped by 98.990% and 100% in the validating set of our dataset, respectively. It was strongly necessary to recover the accuracy after pruning. The most convenient way to improve the accuracy of a changed model is to retrain it. After retraining on the same training set in our dataset, as also shown in
Figure 6d, the mAP and
of the pruned model in the validating set were significantly regained by 98.950% and 99.521%, respectively, and were rather close to the accuracy level of the un-pruned model. This implies that retraining offers a tremendous contribution to accuracy recovery and that pruned channels do not have a serious impact on accuracy. Nevertheless, the retraining could not fully restore the accuracy. Especially in the case of
, which requires a strict performance of 100%, this constituted an unacceptable loss.
In addition, to justify the amount of pruning, we selected different pruning rates in 5% steps between 60% and 85% to form six models: 60%, 65%, 70%, 75%, 80%, and 85%. The changes in
and MS, corresponding to the validating set, reflect the effect of the pruning rate on the model performance. The optimal pruning rate needed to make
AD as large as possible and MS as small as possible. However, a decrease in MS is bound to cause an inevitable reduction in
. Thus, the most appropriate pruning rate can be considered as a balance between maximizing
and minimizing MS. To describe such a balance, we designed the following objective function
related to the pruning rate,
, and MS:
where
indicates a variable of the pruning rate;
and
denote the
and MS corresponding to
, respectively;
is the MS when unpruned. According to the MS of the transferred YOLOv5s in
Figure 6d,
. The maximum value of
is the most appropriate balance between ad and
and MS. As illustrated in
Figure 6e, it is clear that the maximum extreme value of
is obtained when the pruning rate is equal to 75%. This also means that setting the pruning rate to 75% can establish a relatively reasonable balance between maximizing
and minimizing MS, whereas the others suffer from either too much loss in
or too little reduction in MS.
Figure 6f further shows the change in the number of channels before and after pruning. Except for one input and three output layers, all layers have a proportional decrease in the number of channels, and these reductions are significant.
4.4. Knowledge Distillation from the Transferred YOLOv5s Model to the Pruned Model
Since the transferred YOLOv5s model was unable to fully recover the accuracy by retraining after the network pruning, we resorted to a knowledge-distillation technique to further improve the accuracy. In the knowledge-distillation process we designed, the transferred YOLOv5s model was regarded as the teacher network, while the student network referred to its pruned model. The customized total loss function formulated in Equation (7) served as the core to guide the operation of knowledge distillation; that is, a model that could stabilize and minimize such a total loss was established through repeated training. The minor total loss indicated that the student network inherited more adequate knowledge from the teacher network, implying that its accuracy performance was closer to that of the teacher network. Unlike conventional knowledge distillation, we introduced a new weight factor in the confidence part of the total loss function to adjust the sensitivity to defective objects. Since represents the sensitivity weight for distinguishing defective arc magnets, if the value is too large, the ability to identify defect-free magnets would be seriously compromised. In our design, when this weight factor is less than 1, the model can be insensitive to defective arc magnets; in contrast, when greater than 2, it can be exponentially more sensitive to identifying defective arc magnets than defect-free ones, which is not conducive to balancing the identification performance. As a result, we limited to the range of 1 to 2.
Figure 7a illustrates the variation in the accuracy performance of the student network when such a weighting factor was assigned to different values. Obviously, the increase in
tended to improve both mAP and
, but the optimal value was reached at 1.85 when
was already 100% and mAP was also maximum. Following this value, we obtained the training process results shown in
Figure 7b. It can be clearly viewed that both mAP and distillation loss converged rapidly during the iterative training process. The rapid convergence was completed around the 50th epoch, and it tended to stabilize after the 250th epoch. There were no large fluctuations or variances in mAP or distillation loss throughout the training process. This means that the student network did not have a significant training burden or risk and was able to form an identification performance similar to that of the teacher network with a small training cost. To further demonstrate the improved performance of the student network, the output visualization of the first CSP1-3 of the YOLOv5s backbone in this network before and after knowledge distillation is shown as an example in
Figure 7c. It can be seen that the output of the corresponding layer in the teacher network had 128 channels, while there were only 32 channels in that of the student network due to pruning.
Before knowledge distillation, through our pruning strategy, the retrained student network retained most of the teacher network’s channel information that characterized the original image. Still, the feature information belonging to the 2nd, 3rd, 4th, 5th, 17th, and 25th channels was always less or almost absent. This is likely to be the cause of the inability of the student network to fully recover the accuracy of the teacher network by repetitive training before knowledge distillation. On the contrary, after implementing the knowledge distillation we designed, channels that initially lacked the feature information were supplemented with considerable new information related to the arc magnet surface defects in the image. The defect-related feature output capability of this layer was enhanced explicitly, which also reflected the crucial role of our designed loss function with the new weight factor, . In this way, the student network could be used as a model for identifying surface defects on arc magnets after completing the knowledge-distillation training process.
4.5. Identification Results for Multiple Surface Defects on Various Arc Magnets
The models trained by knowledge distillation were applied to test all data of the testing set in our dataset to verify our models’ ability to identify different defect types. Depending on our previously prepared and expanded dataset, a total of 1871 data points, covering eight categories of images for defective arc magnets and one category of that for defect-free magnets, were tested by our model. The amount of data per category ranged from 200 to 217 in order to allow for a relative data balance between different categories, avoiding considerable specificity in the testing results. The confusion matrix in
Figure 8a illustrates the identification results of our model for each data item in all categories. As can be seen, each category of data representing defective arc magnets was identified with 100% accuracy, confirming that
is also at 100%. This ability to identify different surface defects is entirely consistent with the teacher network corresponding to the transferred YOLOv5s before network pruning and knowledge distillation. Moreover, it overcomes the problem that the
of the previously retrained and pruned transferred YOLOv5s could not reach 100%.
For defect-free arc magnets, there were two misidentifications, including one with a blowhole and one with a crack, such that the accuracy was only 99%. The existing misidentification rate was most likely caused by the enhanced sensitivity to defective arc magnet recognition and the weakened recognition ability of defect-free magnets in knowledge distillation, but the misidentification rate of 1%, as well as the arbitrary defect recognition rate of 100%, fully met the conventional accuracy requirements and could be widely accepted by the actual production.
Figure 8b further shows realistic scenarios of identifying different surface defects on arc magnets from their images. It follows that our model is extremely capable of accurately identifying the surface defects, regardless of the number and type of defects in the same image. These results demonstrate that the student network, after knowledge distillation, fully inherited the accurate recognition performance of the teacher network for all defects, compensating for the accuracy loss given by pruning the teacher network as the student network. It is noteworthy that the student network model generated by the knowledge distillation process we designed is more oriented towards accurately identifying surface defects. Its 100% accuracy is reflected in the ability to confirm both the presence of surface defects on an arc magnet and the type of the corresponding defects.
4.6. Performance Comparison of Different Models for Identifying the Surface Defects
To further investigate the effectiveness of the proposed method for the surface defect detection in this work, we selected current lightweight models that are widely available in a large number of object detection studies, including SSD-VGG16, YOLOv3-tiny, YOLOv4-tiny, original YOLOv5s, and YOLOx-nano, for comparison with our model. The performances of these selected models were all obtained from the same testing set used for our model. The corresponding performance comparison results are exhibited in
Figure 9. The results show that our model was consistently minimal in terms of TNNP, FLOPS, and MS. In the case of TNNP, our model was 98.136%, 94.704%, 92.190%, 93.505%, and 48.775% smaller than the other five models, respectively. Similar reductions were observed in the other two indicators (FLOPS and MS): for example, 98.685%, 93.751%, 88.146%, 88.337%, and 22.562% in FLOPS; 97.957%, 94.208%, 91.463%, 92.932%, and 48.457% in MS. For the identification speed, compared to the original YOLOv5s and YOLOx-nano, our model reduced AITC by 12.867% and 44.017%, separately. Due to the simpler model architectures of SSD-VGG16, YOLOv3-tiny and YOLOv4-tiny, they produced shorter AITCs than our model. However, all three of them were significantly worse than our model as well as the original YOLOv5s and YOLOx-nano in the
Precision and
Recall indicators. This indicates that their accuracy was measurably weaker than our model, such that the faster speeds of these three models do not have potential for practical application. The significant results mentioned above demonstrate that our model had a lower complexity, a smaller scale, a weaker computing power dependence, and a faster running speed. Our model also offers notable improvements in mAP,
,
Precision, and
Recall in identifying the eight types of surface defects. Our model outperformed the others in the indicators related to the accuracy. In particular, it exclusively achieved 100% for
and all Recalls for defective arc magnets where other models did not. Unlike the other models, the false identification rate of our model on the Recall indicator occurred only in the defect-free arc magnets and was merely 1%, which is widely acceptable for actual production. Such results suggest that our model is more conducive to accurately identifying defective arc magnets. The above performance comparison shows that our model had obvious advantages in the deployment (1.921 MB in MS), speed (9.46 ms in AITC), and accuracy (100% in Recall for different defective arc magnets) for identifying surface defects on arc magnets, signifying more reliable application.
4.7. Potential for Other Applications
To explore the application potential of our method on objects other than arc magnets, we attempted to use our model for the detection of image-based insulator defects in a high-voltage tower. The data used in this attempt were sourced from the Chinese Power Line Insulator Dataset (CPLID) [
42], which provided 600 defect-free insulator images captured by unmanned aerial vehicles (UAVs) and 248 synthetic defective insulator images. All images in this dataset were derived from a synthesis of the ground truth and defective insulators due to the limited number of real defective insulator images. The purpose of this identification was to determine whether the insulator in each image has defects. The same data augmentation was still followed due to the small and unbalanced sample data. The number of images of both defect-free and defective insulators was expanded to 1200, which were also respectively divided into the training set, the validating set, and the testing set according to a ratio of 8:1:1. The model employed wass still derived from a fine-tuned network based on the same pre-trained YOLOv5s and compressed with the help of pruning and distillation. An example of the detection of defective insulators is shown in
Figure 10. We found that the defective insulators in the figure could be detected accurately. We chose the original YOLOv5s trained directly with the augmented CPLID data to compare with our model to investigate their performance in detecting defective insulators. As exhibited in
Table 3, compared to the original YOLOv5s, our model reduced TNNP, FLOPS, MS, and AITC by 93.559%, 88.380%, 92.985%, and 5.634%, respectively. This indicates that the complexity and computing power dependence of the model were significantly smaller, implying a faster detection speed and a more convenient deployment. More importantly, mAP increased by 0.03% and
was boosted by 1.667% and improved to 100%, enabling the most accurate detection of defective insulators. It follows that there is considerable potential for broader applications given the advantages of our method in compressing models and improving accuracy.
5. Conclusions
This paper proposed a machine-vision method for identifying surface defects on arc magnets. The proposed method combines transfer learning, network pruning, and knowledge distillation for the YOLOv5s model to obtain high recognition accuracy of surface defects while greatly compressing the model size at a slight loss of accuracy, thereby improving the recognition speed. In our work, the type and quantity of the original public image-based dataset of surface defects on arc magnets were appended by us to make the dataset more extensive and representative. To overcome the dependence of model training on massive image-based data of arc magnets, our model was derived from YOLOv5s that had been robustly pre-trained by another publicly available dataset with a large number of different targets other than arc magnets. The transfer-learning mechanism under the frozen and fine-tuned YOLOv5s enabled the target recognition ability obtained by pre-training on the other dataset to be converted into highly accurate surface-defect identification after training based on relatively few image-based arc magnets. The proposed pruning rate, validated by the objective function we designed, achieved an optimal balance between maximizing model compression and minimizing accuracy loss during the network pruning for the transferred YOLOv5s. The unpruned and pruned transferred YOLOv5s were respectively employed as the teacher and student networks for knowledge distillation. A proposed λ weighting factor was introduced into the confidence loss function of knowledge distillation to increase the sensitivity of the student network for extracting and identifying image-based features of surface defects, but such a sensitivity improvement was bound to sacrifice a small amount of recognition accuracy for defect-free arc magnets. The experimental results show that our model is only 1.921 MB in size and can identify any defective arc magnet with 100% accuracy within an average inference time of 9.46 ms. Moreover, the misidentification rate for defect-free arc magnets did not exceed 1%. Considering accuracy, speed, and size together, our model outperforms other conventional lightweight models and is more conducive to high-precision and rapid identification of surface defects on arc magnets under a lightweight model deployment with low computing power. Similar superior performance was also obtained for the detection of insulator defects in a high-voltage tower, for which our model was used to identify image-based insulator data. Given the advantages of our model in compressing models and improving accuracy, more applications based on our method have the potential to be developed.
Even though the identification accuracy of defective arc magnets reached 100%, 1% of defect-free arc magnets still could not be accurately identified. The significant compression of the model size did not result in a substantial reduction of inference time. These phenomena make it necessary to continue improving our method in terms of accuracy and speed, but the corresponding improvements are also limited by the performance of YOLOv5s. Along with developing the YOLO series, we will attempt newer and better YOLO models to update YOLOv5s for the surface-defect identification of arc magnets in future work. Meanwhile, we will continue to explore different model compression methods to achieve faster identification speed.














{kind=link}
{kind=link}
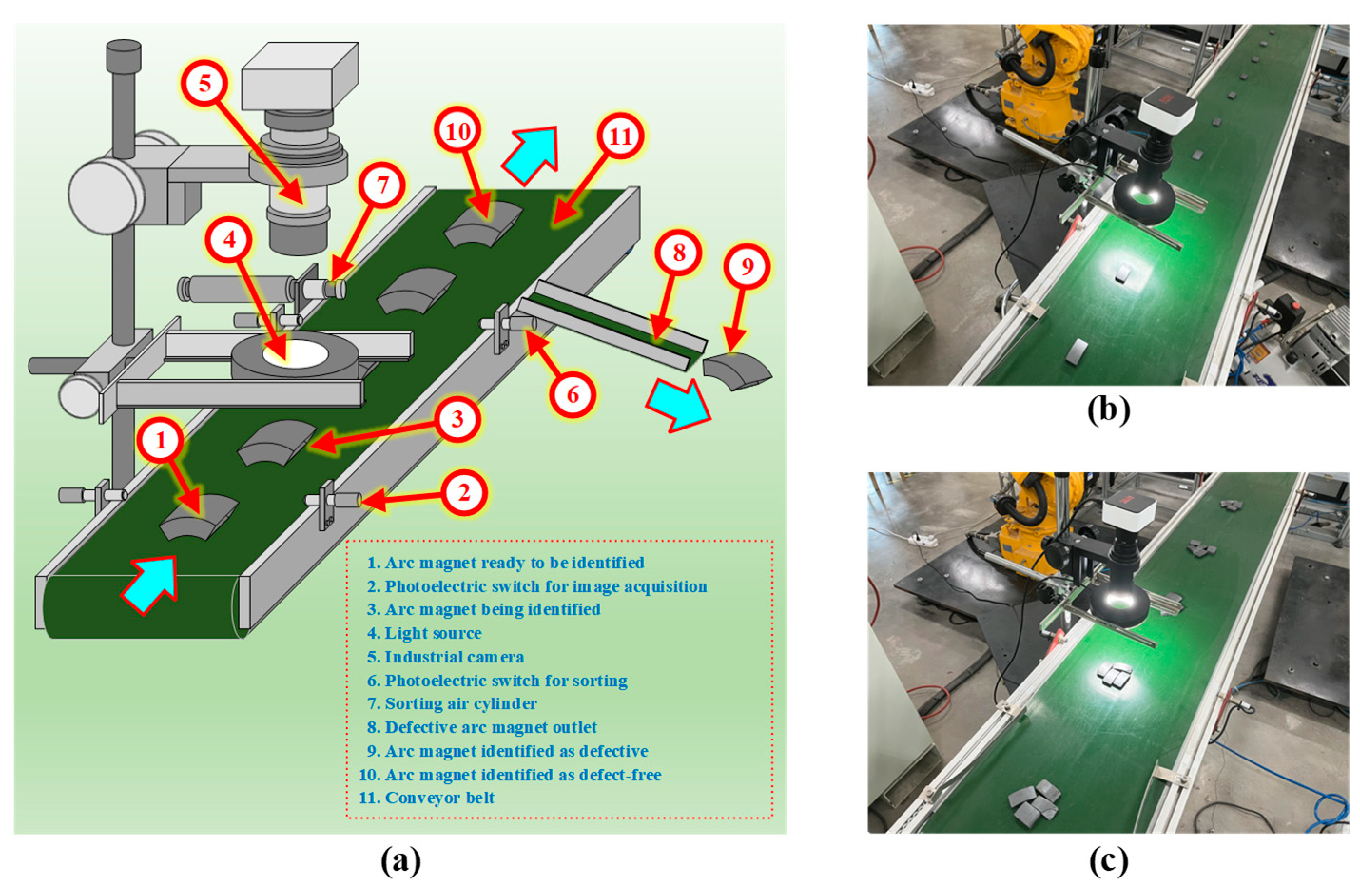{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}