
Real-Time Semantic Segmentation of Point Clouds Based on an Attention Mechanism and a Sparse Tensor



Abstract
:1. Introduction
- A lightweight full convolutional network based on an attention mechanism and a sparse tensor is proposed to solve the real-time point cloud semantic segmentation problem for unmanned vehicle systems;
- We propose a global feature-learning module and a multi-scale feature fusion module. The former is used to learn global contextual information, and the latter is used to achieve the effective fusion of feature information at different scales;
- As demonstrated by the experimental results for the SemanticKITTI and NuScenes datasets, our model improves the mIoU metric by 6.4% and 5%, respectively, over existing models that can be applied in real time. The comparative efficiency analysis shows that our model is able to meet the real-time requirements.
2. Related Works
2.1. Point Cloud Semantic Segmentation
2.2. Attention Mechanism
2.3. Sparse Convolution in Point Cloud Processing
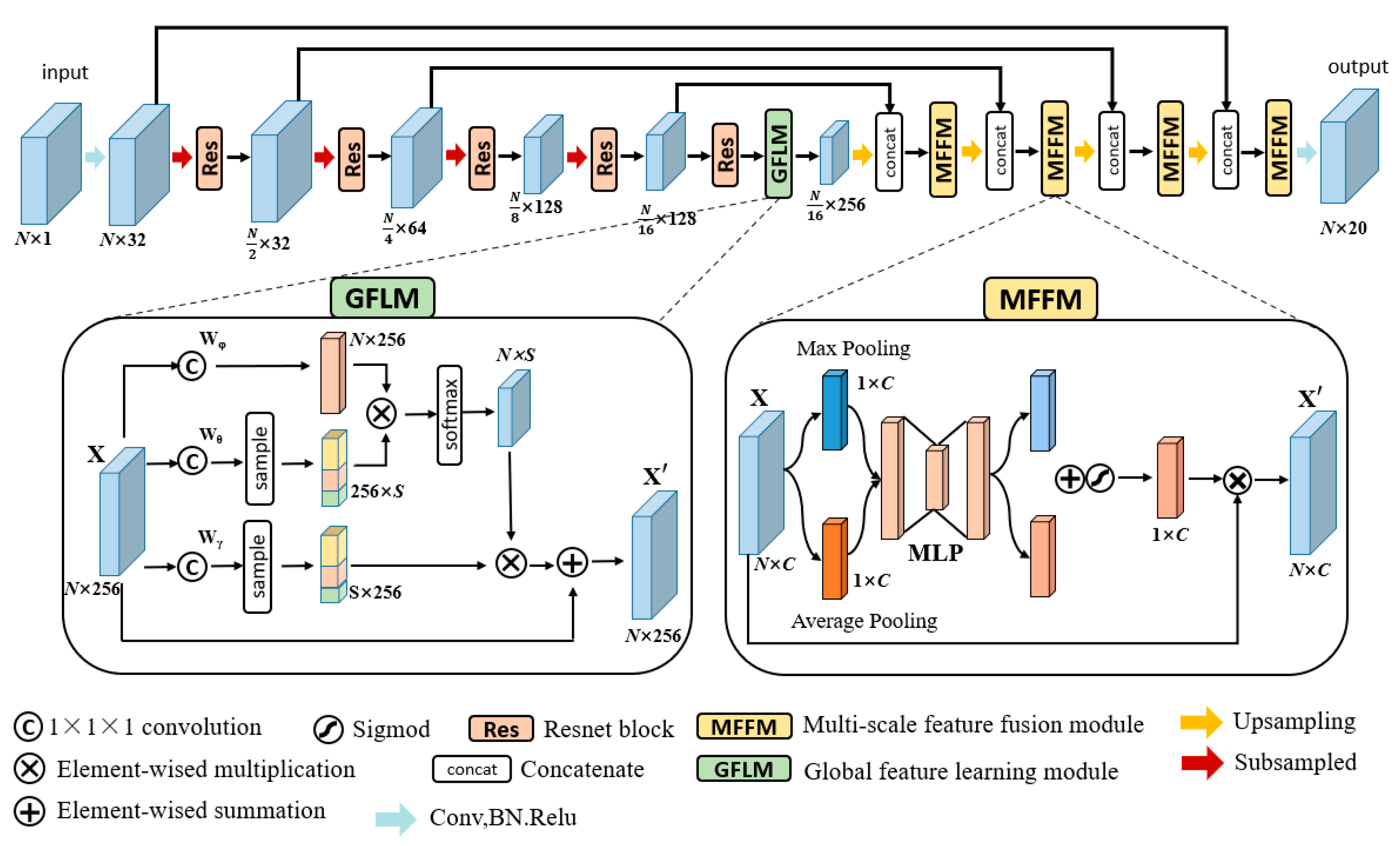
3. Methods
3.1. Overview
3.2. Global Feature-Learning Module
3.3. Multi-Scale Feature Fusion Module
3.4. Sparse Operation
3.4.1. Sparse Tensor
3.4.2. Submanifold Convolution Operation
3.4.3. Other Operations
4. Results
4.1. Datasets
4.2. Experimental Setup
4.3. Evaluation Criterion
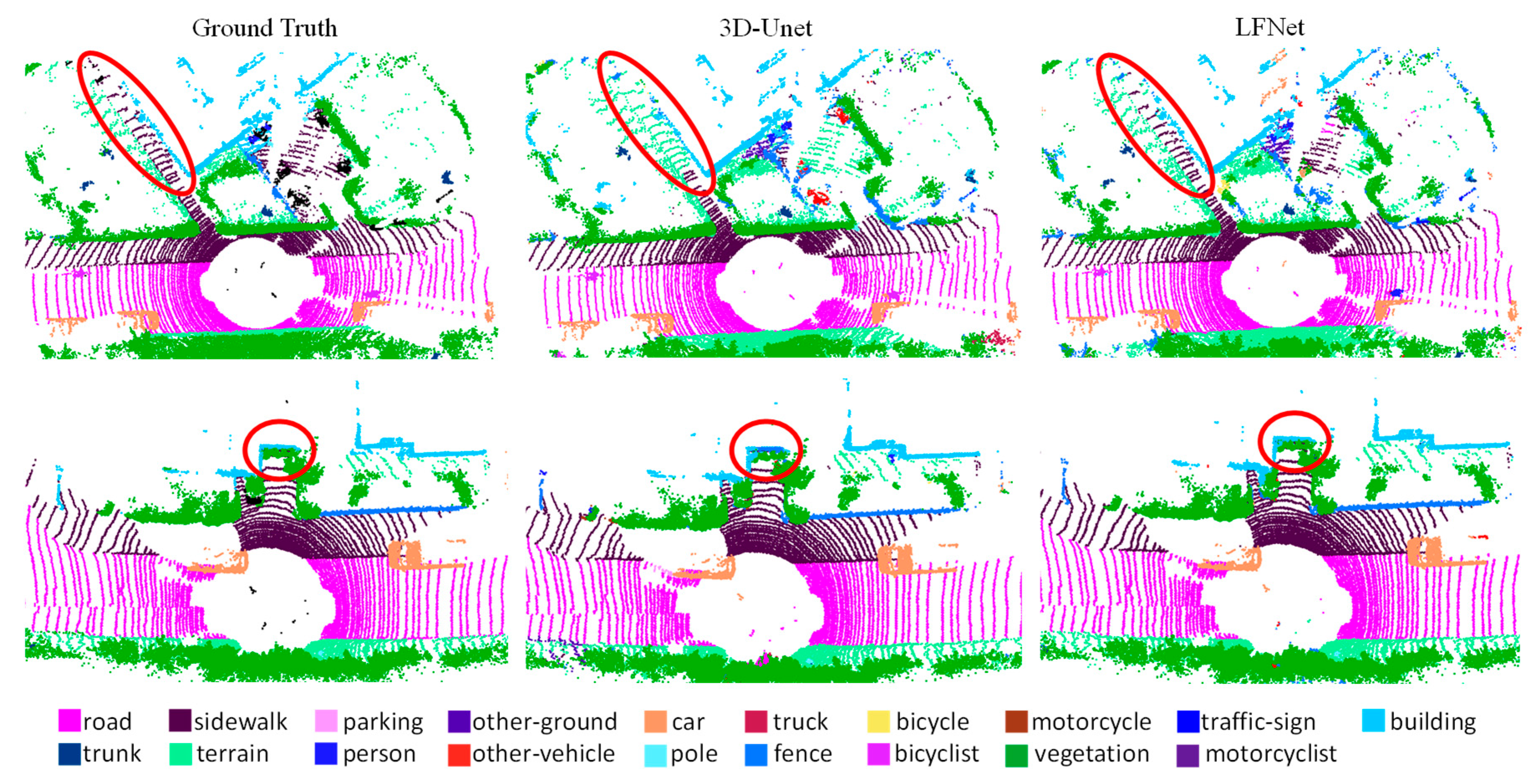
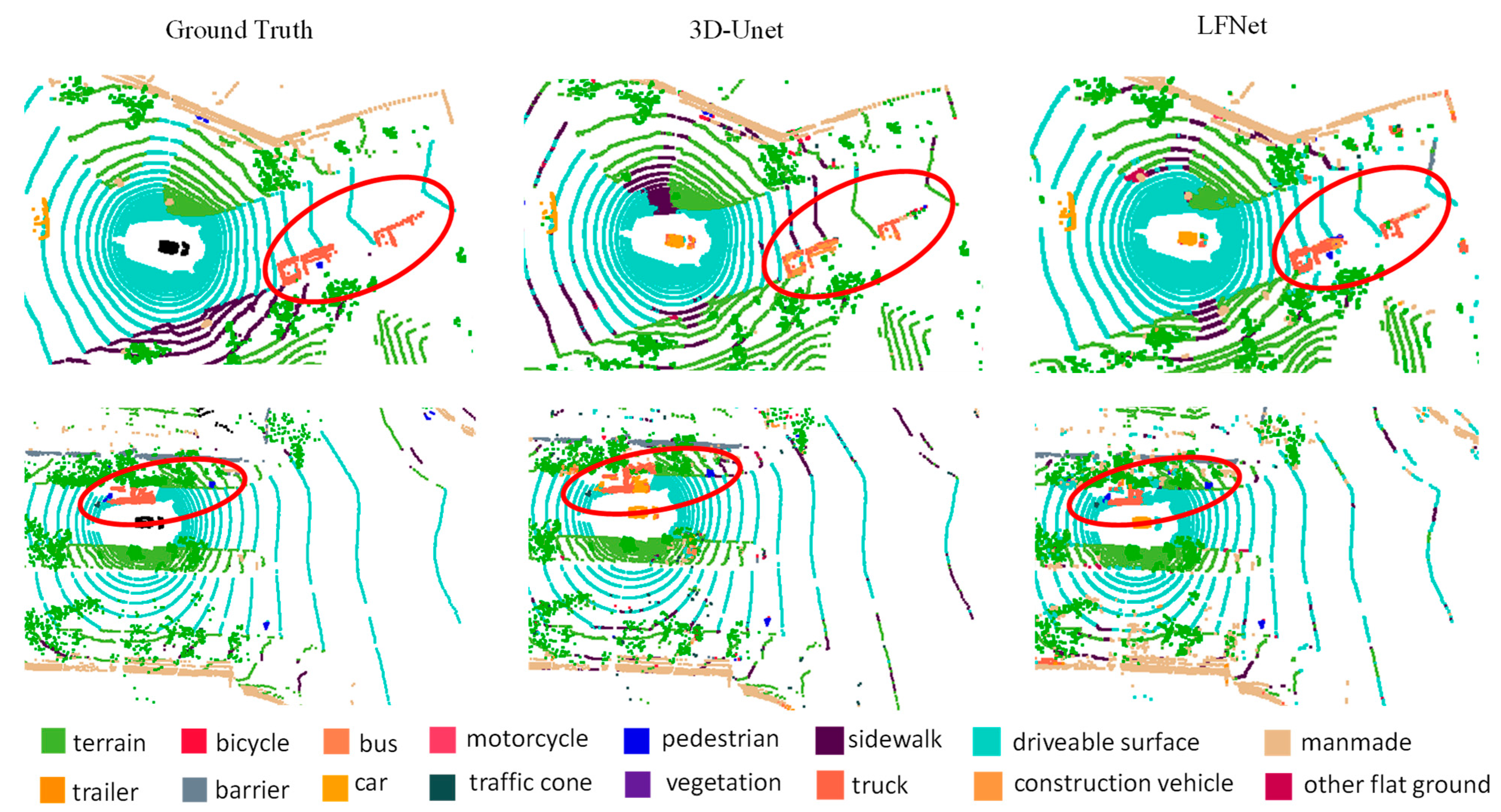
4.4. Qualitative Comparison
4.5. Quantitative Comparisons
4.6. Efficiency Comparisons
4.7. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Achirei, S.-D.; Heghea, M.-C.; Lupu, R.-G.; Manta, V.-I. Human Activity Recognition for Assisted Living Based on Scene Understanding. Appl. Sci. 2022, 12, 10743. [Google Scholar] [CrossRef]
- He, P.; Ma, Z.; Fei, M.; Liu, W.; Guo, G.; Wang, M. A Multiscale Multi-Feature Deep Learning Model for Airborne Point-Cloud Semantic Segmentation. Appl. Sci. 2022, 12, 11801. [Google Scholar] [CrossRef]
- Kang, X.; Li, J.; Fan, X.; Jian, H.; Xu, C. Object-Level Semantic Map Construction for Dynamic Scenes. Appl. Sci. 2021, 11, 645. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 20–26 October 2019. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P. Polarnet: An improved grid representation for online lidar point clouds semantic segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020. [Google Scholar]
- Xu, C.; Wu, B.; Wang, Z. Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation. In Proceedings of the 2020 European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Choy, C.; Gwak, J.Y.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S. Searching efficient 3d architectures with sparse point-voxel convolution. In Proceedings of the 2020 European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Graham, B.; Engelcke, M.; Van, D.M.L. 3d semantic segmentation with submanifold sparse convolutional networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018. [Google Scholar]
- Rosu, R.A.; Schütt, P.; Quenzel, J. Latticenet: Fast point cloud segmentation using permutohedral lattices. arXiv 2019, arXiv:1912.05905. [Google Scholar]
- Wang, X.; Jia, R.H.; Fu, L.Y. Online Spatial Crowdsensing with Expertise-Aware Truth Inference and Task Allocation. IEEE J. Sel. Areas Commun. 2021, 40, 412–427. [Google Scholar] [CrossRef]
- Fan, G.Y.; Jin, H.M.; Fu, L.Y. Joint Scheduling and Incentive Mechanism for Spatio-Temporal Vehicular Crowd Sensing. IEEE Trans Mob Comput. 2019, 20, 1449–1464. [Google Scholar] [CrossRef]
- Fang, Y.; Xu, C.; Cui, Z. Spatial transformer point convolution. arXiv 2020, arXiv:2009.01427. [Google Scholar]
- Zhou, J.C.; Pang, L.; Li, C.Y. Underwater image enhancement method by multi-interval histogram equalization. IEEE J. Oceanic. Eng. 2023. [Google Scholar] [CrossRef]
- Zhou, J.C.; Zhang, D.H.; Ren, W.Q. Auto Color Correction of Underwater Images Utilizing Depth Information. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, J.C.; Zhang, D.H.; Zhang, W.S. Underwater image enhancement method via multi-feature prior fusion. Appl. Intell. 2022, 52, 16435–16457. [Google Scholar] [CrossRef]
- Wu, H.Y.; Fu, L.Y.; Long, H. Unraveling the Detectability of Stochastic Block Model with Overlapping Communities. IEEE Trans. Netw. Sci. Eng. 2021, 8, 1443–1455. [Google Scholar] [CrossRef]
- Li, R.; Zhang, Y. PointVGG: Graph convolutional network with progressive aggregating features on point clouds. Neurocomputing. 2021, 429, 187–198. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.L.; Zhao, X.F. Self-Supervised Locality Preserving Low-Pass Graph Convolutional Embedding for Large-Scale Hyperspectral Image Clustering. IEEE Trans Geosci Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Zhu, X.; Zhou, H.; Wang, T. Cylindrical and asymmetrical 3d convolution networks for lidar segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TX, USA, 19–25 June 2021. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhou, R.; Li, X.; Jiang, W. SCANet: A Spatial and Channel Attention based Network for Partial-to-Partial Point Cloud Registration. Pattern Recognit. Lett. 2021, 151, 120–126. [Google Scholar] [CrossRef]
- Feng, M.; Zhang, L.; Lin, X. Point attention network for semantic segmentation of 3D point clouds. Pattern Recogn. 2020, 107, 107446. [Google Scholar] [CrossRef]
- Chen, X.; Wu, Y.; Xu, W. PointSCNet: Point Cloud Structure and Correlation Learning Based on Space-Filling Curve-Guided Sampling. Symmetry. 2022, 14, 8. [Google Scholar] [CrossRef]
- Chen, X.T.; Li, Y.; Fan, J.H. RGAM: A novel network architecture for 3D point cloud semantic segmentation in indoor scenes. Inform. Sci. 2021, 571, 87–103. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Y.; Liu, Z. Pointgrow: Autoregressively learned point cloud generation with self-attention. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 2–5 May 2020. [Google Scholar]
- Wang, G.; Zhai, Q.; Liu, H. Cross self-attention network for 3D point cloud. Knowl. Based Syst. 2022, 247, 108769. [Google Scholar] [CrossRef]
- Wen, X.; Han, Z.; Youk, G. CF-SIS: Semantic-instance segmentation of 3D point clouds by context fusion with self-attention. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, DC, USA, 12–16 October 2020. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018. [Google Scholar]
- Gu, X.; Wang, Y.; Wu, C. Hplflownet: Hierarchical permutohedral lattice flownet for scene flow estimation on large-scale point clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the 2016 Medical Image Computing and Computer-Assisted Intervention, Istanbul, Turkey, 17–21 October 2016. [Google Scholar]
- Xu, J.; Zhang, R.; Dou, J. Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation. In Proceedings of the 2021 IEEE International Conference on Computer Vision, Montreal, QC, Canada, 11–18 October 2021. [Google Scholar]
- Zhang, F.; Fang, J.; Wah, B. Deep FusionNet for Point Cloud Semantic Segmentation. In Proceedings of the 2020 European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Ye, D.Q.Z.; Zhou, Z.X.; Chen, W.J. LidarMultiNet: Towards a Unified Multi-task Network for LiDAR Perception. arXiv 2022, arXiv:2209.09385. [Google Scholar]
- Yan, X.; Gao, J.T.; Li, J. Sparse Single Sweep LiDAR Point Cloud Segmentation via Learning Contextual Shape Priors from Scene Completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Cheng, R.; Razani, R.; Taghavi, E. (AF)2-S3Net: Attentive Feature Fusion with Adaptive Feature Selection for Sparse Semantic Segmentation Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-aware Semantic Segmentation of LiDAR Point Clouds for Autonomous Driving. In Proceedings of the 2020 International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Method | Params/M | FLOPs/G |
|---|---|---|
| Sampling model | 0.2 | 0.94 |
| No sampling model | 0.2 | 1.14 |
| Method | Real Time | Acc/% | mIoU/% | Car | Bicycle | Motorcycle | Truck | Other-Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalk | Other-Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic-Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPVNet [33] | no | - | 70.3 | 97.6 | 68.4 | 68.7 | 44.2 | 61.1 | 75.9 | 74.4 | 73.4 | 93.4 | 70.3 | 80.7 | 33.3 | 93.5 | 72.1 | 86.5 | 75.1 | 71.8 | 64.8 | 61.4 |
| Cylinder3D [21] | no | - | 67.8 | 97.1 | 67.6 | 64.0 | 50.8 | 58.6 | 73.9 | 67.9 | 36.0 | 91.4 | 65.1 | 75.5 | 32.3 | 91.0 | 66.5 | 85.4 | 71.8 | 68.5 | 62.6 | 65.6 |
| FusionNet [34] | no | 91.8 | 61.3 | 95.3 | 47.5 | 37.7 | 41.8 | 34.5 | 59.5 | 56.8 | 11.9 | 91.8 | 68.8 | 77.1 | 30.8 | 92.5 | 69.4 | 84.5 | 69.8 | 68.5 | 60.4 | 66.5 |
| STPC [14] | no | - | 54.6 | 94.7 | 31.1 | 39.7 | 34.4 | 24.5 | 51.1 | 48.9 | 15.3 | 90.8 | 63.6 | 74.1 | 5.3 | 90.7 | 61.5 | 82.7 | 62.1 | 67.5 | 51.4 | 47.9 |
| SPVNAS [9] | yes | - | 66.4 | 97.3 | 51.5 | 50.8 | 59.8 | 58.8 | 65.7 | 65.2 | 43.7 | 90.2 | 67.6 | 75.2 | 16.9 | 91.3 | 65.9 | 86.1 | 73.4 | 70.0 | 64.2 | 66.9 |
| SqueezeSegV3 [7] | yes | 88.6 | 55.9 | 92.5 | 38.7 | 36.5 | 29.6 | 33.0 | 45.6 | 46.2 | 20.1 | 91.7 | 63.4 | 74.8 | 26.4 | 89.0 | 59.4 | 82.0 | 58.7 | 65.4 | 49.6 | 58.9 |
| PolarNet [6] | yes | 90.0 | 54.3 | 83.8 | 40.3 | 30.1 | 22.9 | 28.5 | 43.2 | 40.2 | 5.6 | 90.8 | 61.7 | 74.4 | 21.7 | 90.0 | 61.3 | 84.0 | 65.5 | 67.8 | 51.8 | 57.5 |
| LFNet (ours) | yes | 93.3 | 72.8 | 92.5 | 43.8 | 63.6 | 84.1 | 75.8 | 41.9 | 69.2 | 52.6 | 95.8 | 77.7 | 85.9 | 77.6 | 91.6 | 79.2 | 90.4 | 59.7 | 84.5 | 61.1 | 56.6 |
| Method | Real Time | mIoU/% | Barrier | Bicycle | Bus | Car | Construction Vehicle | Motorcycle | Pedestrain | Traffic cone | Trailer | Truck | Driveable Surface | Other Flat Ground | Sidewalk | Terrain | Manmade | Vegetation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LidarMultiNet [35] | no | 81.4 | 80.4 | 48.4 | 94.3 | 90 | 71.5 | 87.2 | 85.2 | 80.4 | 86.9 | 74.8 | 97.8 | 67.3 | 80.7 | 76.5 | 92.1 | 89.6 |
| Cylinder3D [21] | no | 76.1 | 76.4 | 40.3 | 91.2 | 93.8 | 51.3 | 78.0 | 78.9 | 64.9 | 62.1 | 84.4 | 96.8 | 71.6 | 76.4 | 75.4 | 90.5 | 87.4 |
| SPVNAS [9] | yes | 74.8 | 78.1 | 31.2 | 89.2 | 88.0 | 65.4 | 69.1 | 81.2 | 53.4 | 72.7 | 70.4 | 94.9 | 61.6 | 76.8 | 79.7 | 93.8 | 90.7 |
| JS3C-Net [36] | yes | 73.6 | 80.1 | 59.4 | 88.0 | 85.1 | 63.7 | 84.4 | 82.0 | 76.0 | 84.8 | 71.9 | 96.9 | 67.4 | 79.8 | 76.0 | 92.1 | 89.2 |
| AF2S3Net [37] | yes | 62.2 | 60.3 | 12.6 | 82.3 | 80.0 | 20.1 | 62.0 | 59.0 | 49.0 | 42.2 | 67.4 | 94.2 | 68.0 | 64.1 | 68.6 | 82.9 | 82.4 |
| PolarNet [6] | yes | 71.0 | 74.7 | 28.2 | 85.3 | 90.9 | 35.1 | 77.5 | 71.3 | 58.8 | 57.4 | 76.1 | 96.5 | 71.7 | 74.7 | 74.0 | 87.3 | 85.7 |
| SalsaNext [38] | yes | 58.8 | 56.6 | 4.7 | 77.1 | 81.0 | 18.4 | 47.5 | 52.8 | 43.5 | 38.3 | 65.7 | 94.2 | 60.0 | 68.9 | 70.3 | 81.2 | 80.5 |
| LFNet (ours) | yes | 79.8 | 86.2 | 50.3 | 92.4 | 58.7 | 79.0 | 79.0 | 78.9 | 63.8 | 87.0 | 83.4 | 96.6 | 76.8 | 81.5 | 82.4 | 90.9 | 90.0 |
| Methods | Params/M | Flops/G | Device | Time/ms |
|---|---|---|---|---|
| RPVNet [33] | 24.8 | 239 | Tesla V100 | 168 |
| SPVNAS [9] | 12.5 | 147.6 | GTX 1080Ti | 259 |
| FusionNet [34] | - | - | GTX 1080 | 900 |
| SqueezeSegV3 [7] | 26.2 | 1030.4 | - | 142 |
| LFNet (ours) | 17.7 | ≈64 | GTX 3090 | 94 |
| Method | Acc | mIoU | Time/ms |
|---|---|---|---|
| 3D Unet | 91.5% | 64.9% | 67.8 |
| 3D Unet + GFLM | 92.9% | 68.2% | 80.4 |
| 3D Unet + MFFM | 92.6% | 67.3% | 74.7 |
| 3D Unet + GFLM + MFFM (LFNet) | 93.3% | 72.8% | 94.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Yang, Y.; Wu, Z.; Zhou, J.; Zhang, W. Real-Time Semantic Segmentation of Point Clouds Based on an Attention Mechanism and a Sparse Tensor. Appl. Sci. 2023, 13, 3256. https://doi.org/10.3390/app13053256
Wang F, Yang Y, Wu Z, Zhou J, Zhang W. Real-Time Semantic Segmentation of Point Clouds Based on an Attention Mechanism and a Sparse Tensor. Applied Sciences. 2023; 13(5):3256. https://doi.org/10.3390/app13053256
Chicago/Turabian StyleWang, Fei, Yujie Yang, Zhao Wu, Jingchun Zhou, and Weishi Zhang. 2023. "Real-Time Semantic Segmentation of Point Clouds Based on an Attention Mechanism and a Sparse Tensor" Applied Sciences 13, no. 5: 3256. https://doi.org/10.3390/app13053256
APA StyleWang, F., Yang, Y., Wu, Z., Zhou, J., & Zhang, W. (2023). Real-Time Semantic Segmentation of Point Clouds Based on an Attention Mechanism and a Sparse Tensor. Applied Sciences, 13(5), 3256. https://doi.org/10.3390/app13053256