
Data Rights Confirmation Scheme Based on Auditable Ciphertext CP-ABE in the Cloud Storage Environment


Abstract
:1. Introduction
- (1)
- User privacy protection. We propose a new data confirmation scheme based on CP-ABE in the cloud storage environment. Users only need to embed the information with their own identity into the ciphertext after Paillier encryption and upload it to the cloud. They do not need to worry about revealing their identity.
- (2)
- Prevent original plaintext data leakage. During the entire right confirmation process, the authority can only access the ciphertext and only needs to process the ciphertext. This greatly reduces the risk of plaintext data leakage during the right confirmation process.
- (3)
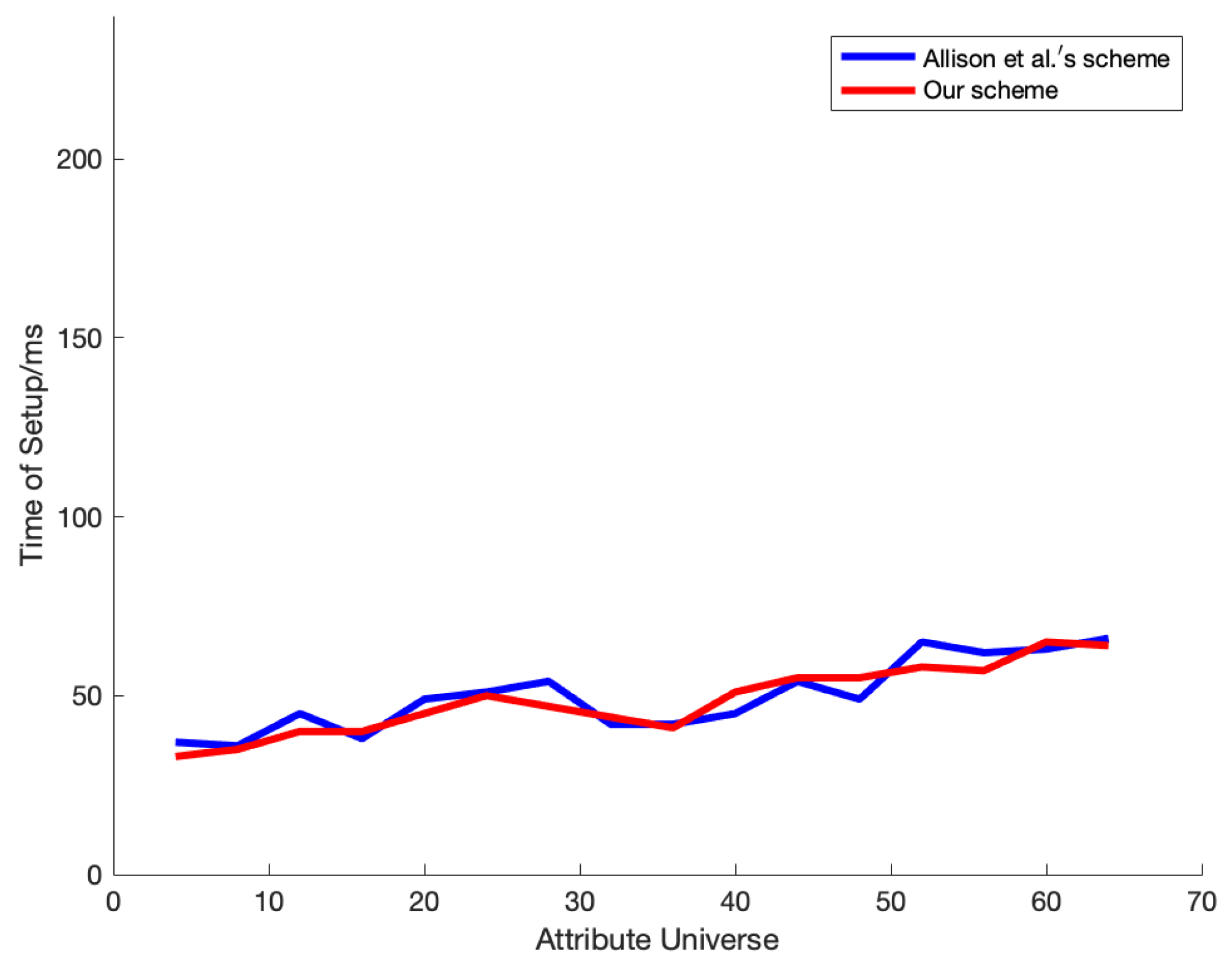
- The scheme is safe and efficient. We reduce the scheme to the three-prime subgroup decision problem and prove that the scheme is safe, and through experimental analysis, our scheme is almost as efficient as the scheme proposed by Allison et al. [21] in terms of system setup, key generation, encryption, and encryption algorithms. Table 1 shows the comparison between our scheme and other data confirmation schemes.
2. Preliminaries
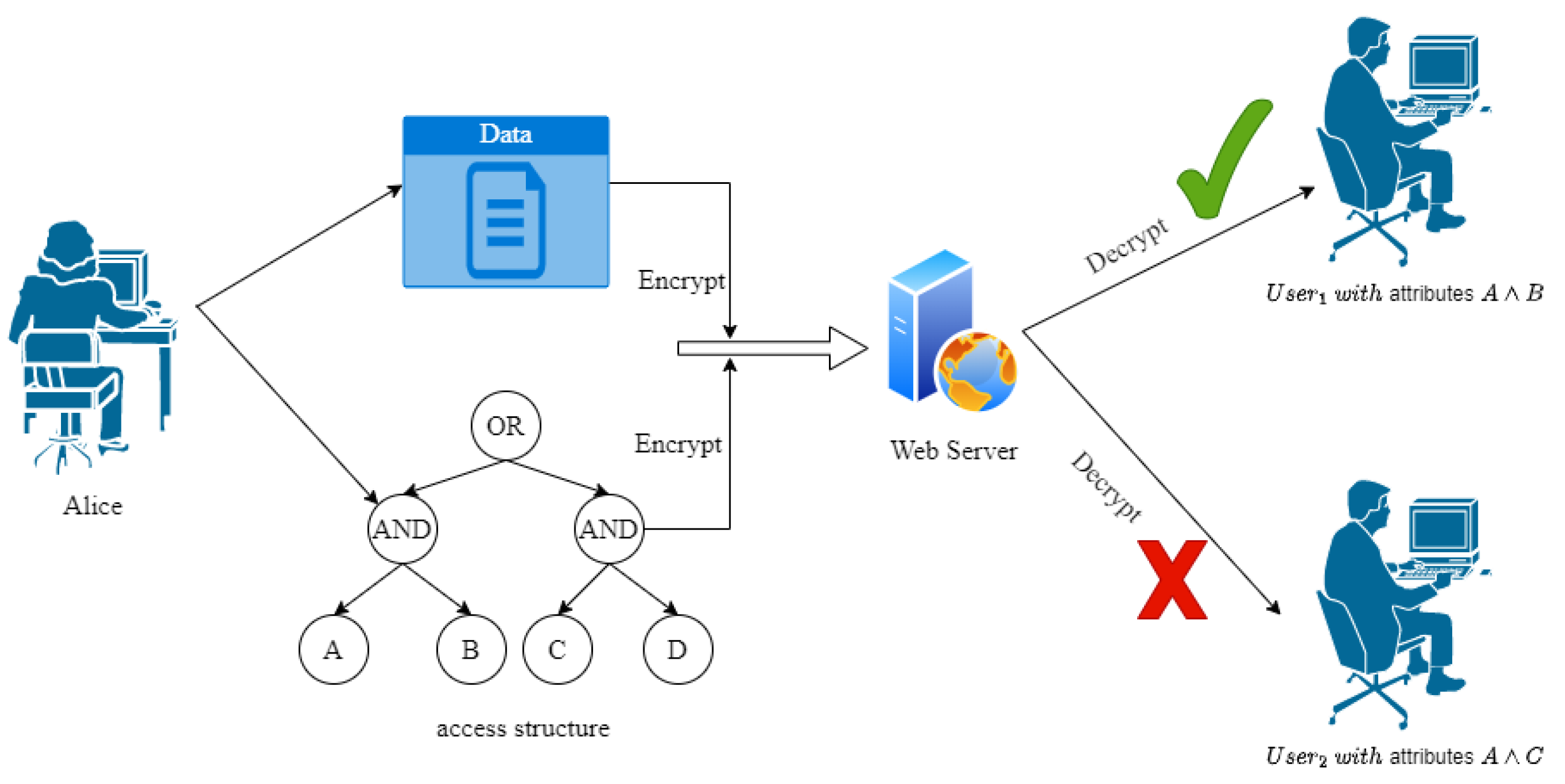
2.1. Access Structure
2.2. Linear Secret-Sharing Schemes
- The secret shared by each participant forms a column vector on .
- A secret sharing scheme Π has a shared generator matrix M, which is an l-by-n matrix for every access structure defined on S. For , the ith line of M is marked as an attribute (ρ is a map that maps each row of matrix M to Π). Given a vector , where s is the shared secret, are randomly selected; identifies the l shares of Π to the secret number s. Line i belongs to attribute .
- –
- If , there exists a vector of integers in such that .
- –
- If , there exists a vector of integers in such that and .
2.3. Composite Order Bilinear Groups
2.4. CDH Assumption
2.5. Paillier Encryption
- Key generation:
- (1)
- Obtain two large prime numbers and that satisfy . This ensures that the prime numbers and have equal lengths.
- (2)
- The following values are computed: , .
- (3)
- Define .
- (4)
- Randomly select a positive integer g less than , and there exists .
- (5)
- System public key , and system secret key .
- Encryption:Given the plaintext , randomly select and calculate .
- Decryption:.
2.6. Fully Secure CP-ABE
- –
- : The setup procedure receives two input parameters: the security parameter , which determines the level of security required, and the attribute universe , which defines the set of attributes. It then generates two output values: the public parameter , which can be shared publicly and used for encryption and decryption, and the master key , which is kept secret and used for key generation.
- –
- : Given the master key , the user’s attribute , and the public parameter as input, the key generation algorithm computes the decryption key as its output. The decryption key can be used to decrypt data encrypted using the corresponding attribute and the public parameter .
- –
- : To encrypt a plaintext , the encryption algorithm takes as input a matrix A, where each row of the matrix is mapped to an attribute , along with the public parameter . The encryption algorithm computes the ciphertext as its output.
- –
- : Given the ciphertext , the public parameter , and the decryption key , the decryption algorithm computes the corresponding plaintext as its output. The decryption key must be associated with an authorization set mapped to rows of the matrix used during encryption, otherwise the decryption will fail.
3. Construction
3.1. Membership
3.2. Security
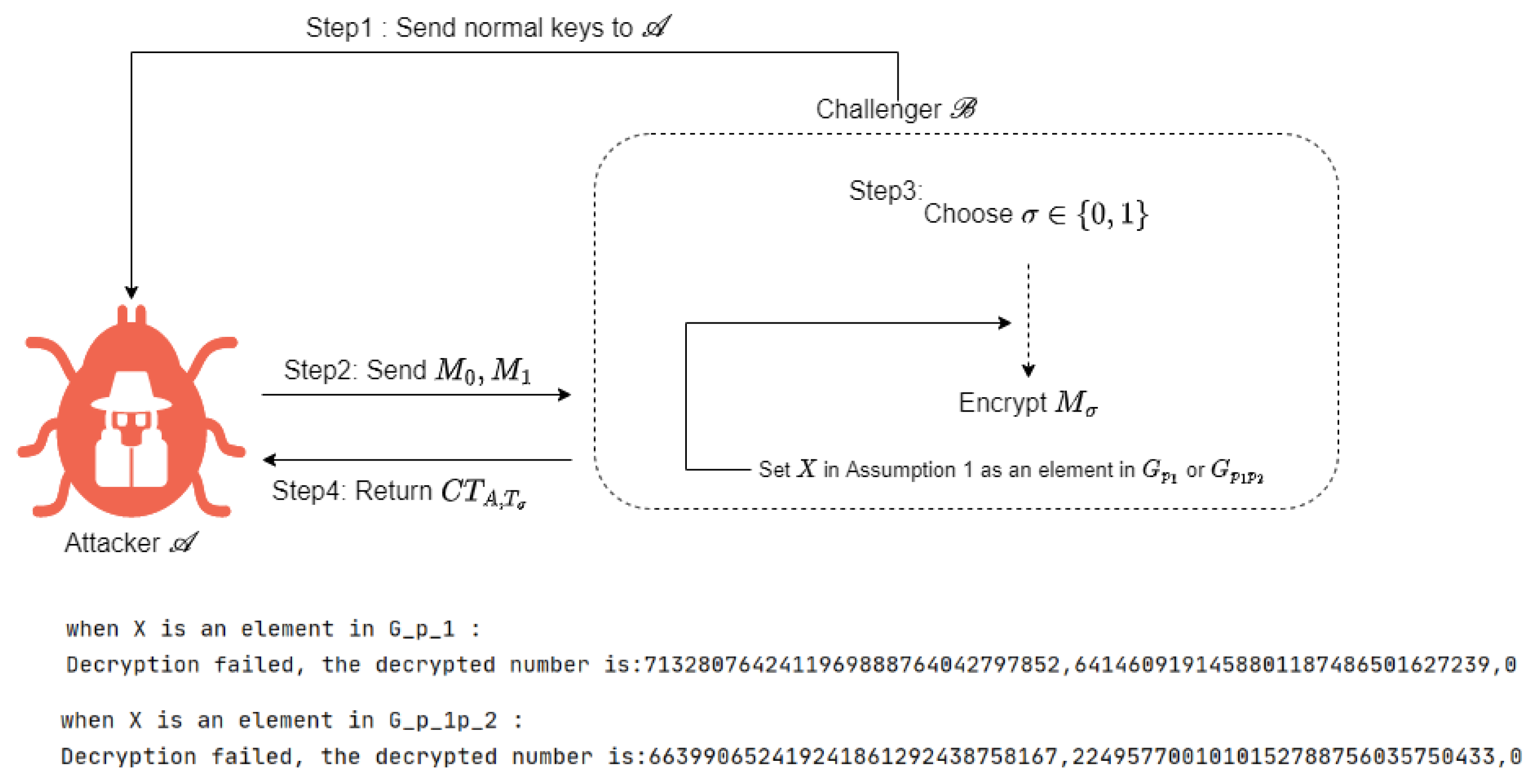
3.2.1. IND-CPA Security
- –
- : The adversary is given the public parameter after the challenger calls the algorithm.
- –
- : Adversary can dynamically request the decryption keys associated with attribute sets from the challenger . In response, executes the key generation algorithm to generate and sends it to .
- –
- : Adversary provides two equal-length messages and and a generator matrix that corresponds to an access structure that does not satisfy to the challenger . Then randomly chooses a bit and generates the ciphertext by calling the encryption algorithm with , , , and . Finally, sends to adversary .
- –
- : Adversary keeps asking for decryption keys corresponding to attribute sets , where each set cannot satisfy the access structure . Upon each request, calls the key generation algorithm and sends to adversary .
- –
- : outputs a guess .
3.2.2. Dishonest User Game (Non-Replicability of Ciphertext)
3.3. Implementation
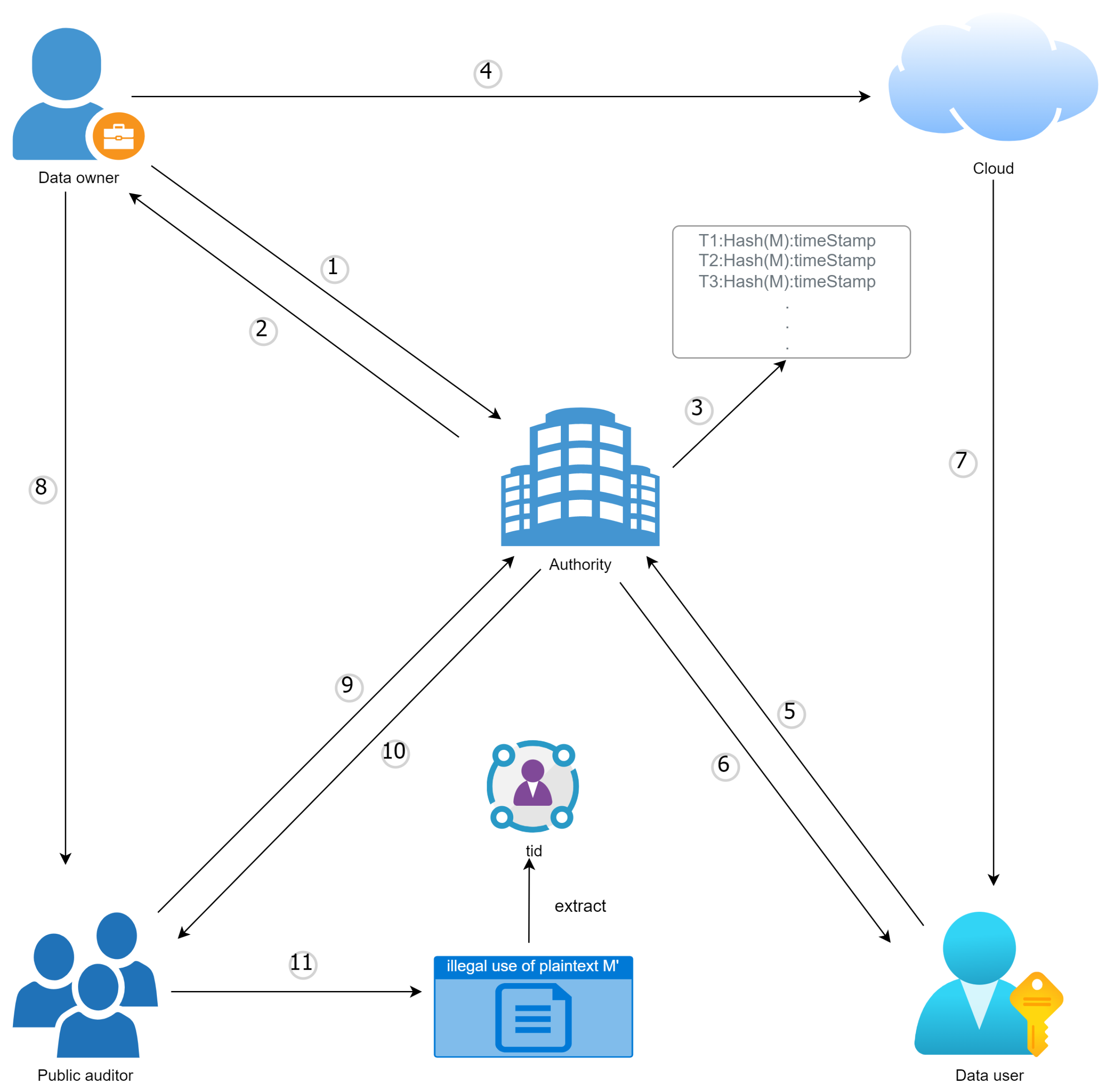
- : In the setup phase of our system, we provide the security parameter and the user attribute universe U as inputs to the setup algorithm. This algorithm then generates a group G of order , a mapping e, an integer group , and a hash function . This setup process establishes the necessary parameters and functions to enable secure and efficient cryptographic operations in our system. The resulting setup allows us to implement our system in a manner that satisfies our security and performance requirements. Then the system proceeds to select random parameters , and the generator . For each attribute , the system randomly selects a corresponding value . The system global parameter is set as( and is a generator) and is sent to the authority ; performs the following steps locally: randomly selecting two safe large primes p and q, which satisfy , calculating , and then randomly selecting a positive integer that is less than . Next, AT computes and randomly selects a value . The public parameter is generated, whereas the private key is stored locally.
- : The unique identifier (e.g., ID number, address, mailbox, etc.) is hashed by data owner and mapped to an integer in , denoted asAfter mapping the data owner’s unique identifier to an integer in , chooses a value and employs Paillier encryption to generate the encrypted output . The Algorithm 1 is as follows (here we assume the unique identifier string is ):
| Algorithm 1 Encrypt |
| Input: |
|
| Output: |
| = 79847630022358710946125273965671104052858 065717629025639108307113838327353 |
- : To encode the access structure for the data, the owner of the data, , creates a shared generator matrix A with dimensions l by n using the LSSS. First, a secret number is randomly selected. Then, random numbers are selected to generate a vector . Finally, random numbers are chosen for each row of matrix A( that represents the entire set of ), is obtained by taking a hash of the plaintext M and mapping it to to generate ciphertext:: Both and T are sent to the authority for decryption. The decryption process begins with decrypting using the following method:After successfully decrypting , the authority checks if it already has a record of in its database. If a record already exists, the application is rejected; otherwise, utilizes their private key to sign the message and generatesand stores the data credentials of in the local database in the form of . By following this process, it is guaranteed that there is only one legitimate owner associated with the original data source. This measure also serves as a safeguard against any attempts by malicious actors to produce ciphertext and assert false ownership over the data. Furthermore, this also serves to prevent from directly accessing the plaintext, which enhances the security of the system. Finally, is sent back to the data owner for further processing. The user credentials setting Algorithm 2 is as follows:
| Algorithm 2 Store user credentials |
| Input: , , T |
|
- : first calculatesafter receiving , afterwards, the ciphertext is assigned the valueand uploads to the cloud.Note: A notable characteristic of this scheme is the possibility of having multiple owners for a given , which is made feasible by the additive homomorphism property of Paillier encryption. For example, in a scenario where the data are jointly owned by two parties, denoted as and , they can both hash their unique identifiers and use them to generate separate ciphertexts and using different random numbers, then calculate , let .During the entire encryption stage, we have realized data confirmation. Hash the plaintext and map it to for encryption() and send it to ; only needs to perform division and signature operations on , and store user ID T locally as a certificate. Therefore, cannot touch the plaintext.
- 3.
- The generation of the decryption key in this scheme is a collaborative process between and ; first chooses a random number as a parameter. Next, forwards their personal set of attributes S and the value to “ as part of its request to generate a key. Then, selects random numbers and to generate part of the decryption keyFinally, transmits the decryption key and a collection of values labeled as to , and generates the decryption key locally using these values:
- 4.
- The decryption key allows to decrypt the ciphertext and obtain access to the data. The decryption algorithm searches for a vector such that , if the attributes of do not satisfy the access policy, then there is only one vector , such that and , the plaintext M is obtained by the following formula:
- 5.
- : If the data owner suspects that his data have been infringed upon or abused, he can prove his ownership by interacting with the public auditor and the authority . This interaction serves two purposes:
- (a)
- To demonstrate that was the first to upload the data;
- (b)
- To prove that the ciphertext corresponding to the data is indeed generated by .: To prove that is the first to upload the data, the source data M and are sent by to the public auditor . obtains the hash value of the source data M by applying the hash function and sends it to the authority to identify the owner of the plaintext.: First, PA carries out a comparison:If they are equal, enter the extraction process using n, , defines , calculates , then by to extract the .: is needed to verify whether the given equation is valid or false.
| Algorithm 3 Decrypt |
|
| Output: |
| = 79847630022358710946125273965671104052858 065717629025639108307113838327353 |
- (1)
- Compare whether the leaked plaintext is the same as that owned by and calculate whether the ciphertext is generated by through the formula ;
- (2)
- Obtain the user credential T corresponding to the plaintext in the ’s database and obtain the owner of the plaintext through Paillier decryption.
3.4. Correctness
3.5. IND-CPA Security
3.6. Ciphertext Non-Replicability
- Case 1: After the adversary (dishonest user) decrypts the ciphertext and obtains the plaintext M, it regenerates the ciphertext by itself. This method is obviously not advisable, because even if the original decryption key of the ciphertext is generated, it is unable to decrypt and has been stored locally in the authority.
- Case 2: The adversary obtains the signature and generates the ciphertext by eavesdropping on the channel between the data owner and , and sending information that is beneficial to to ; randomly selects , hashes the plaintext M and maps it to , and are sent to .
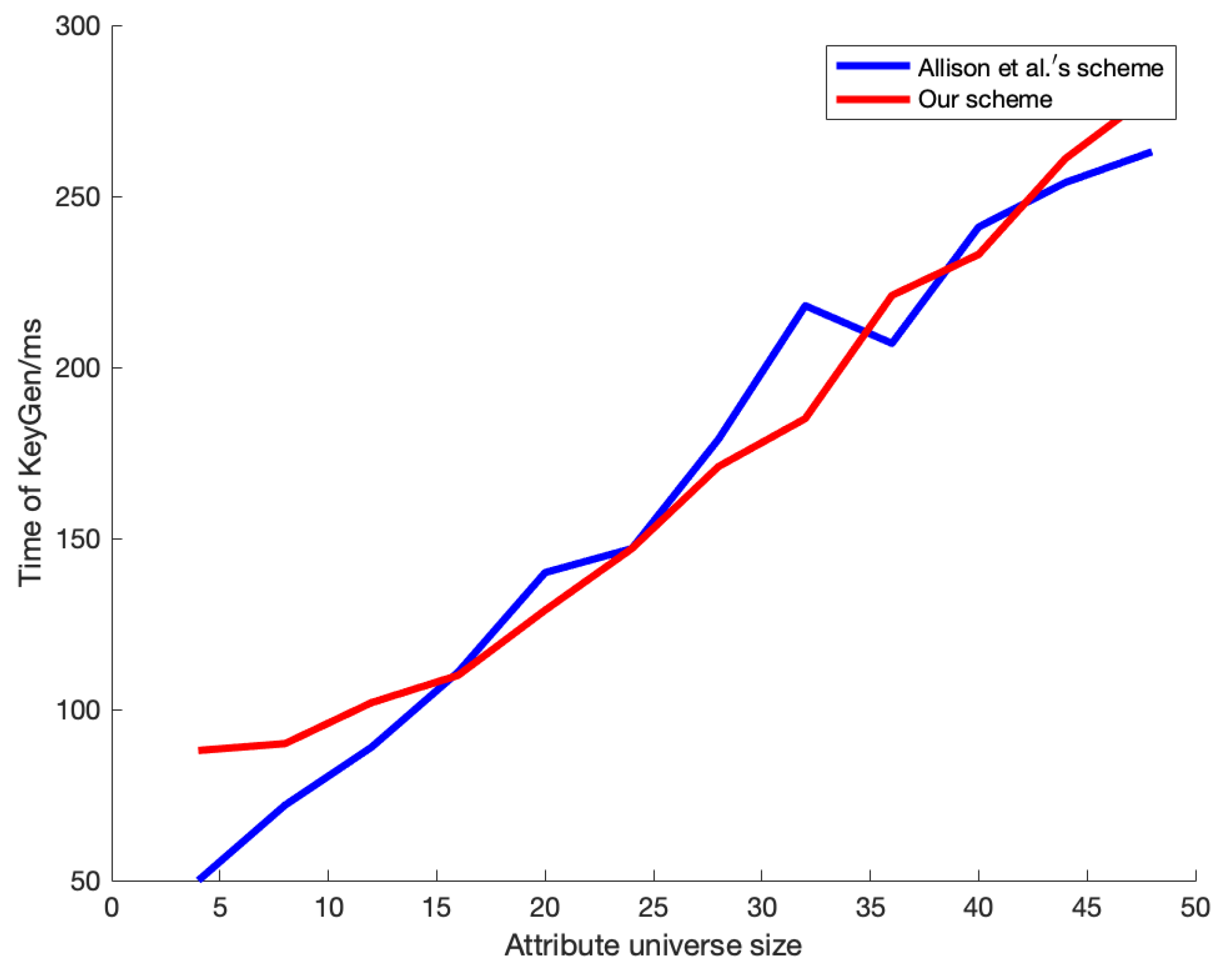
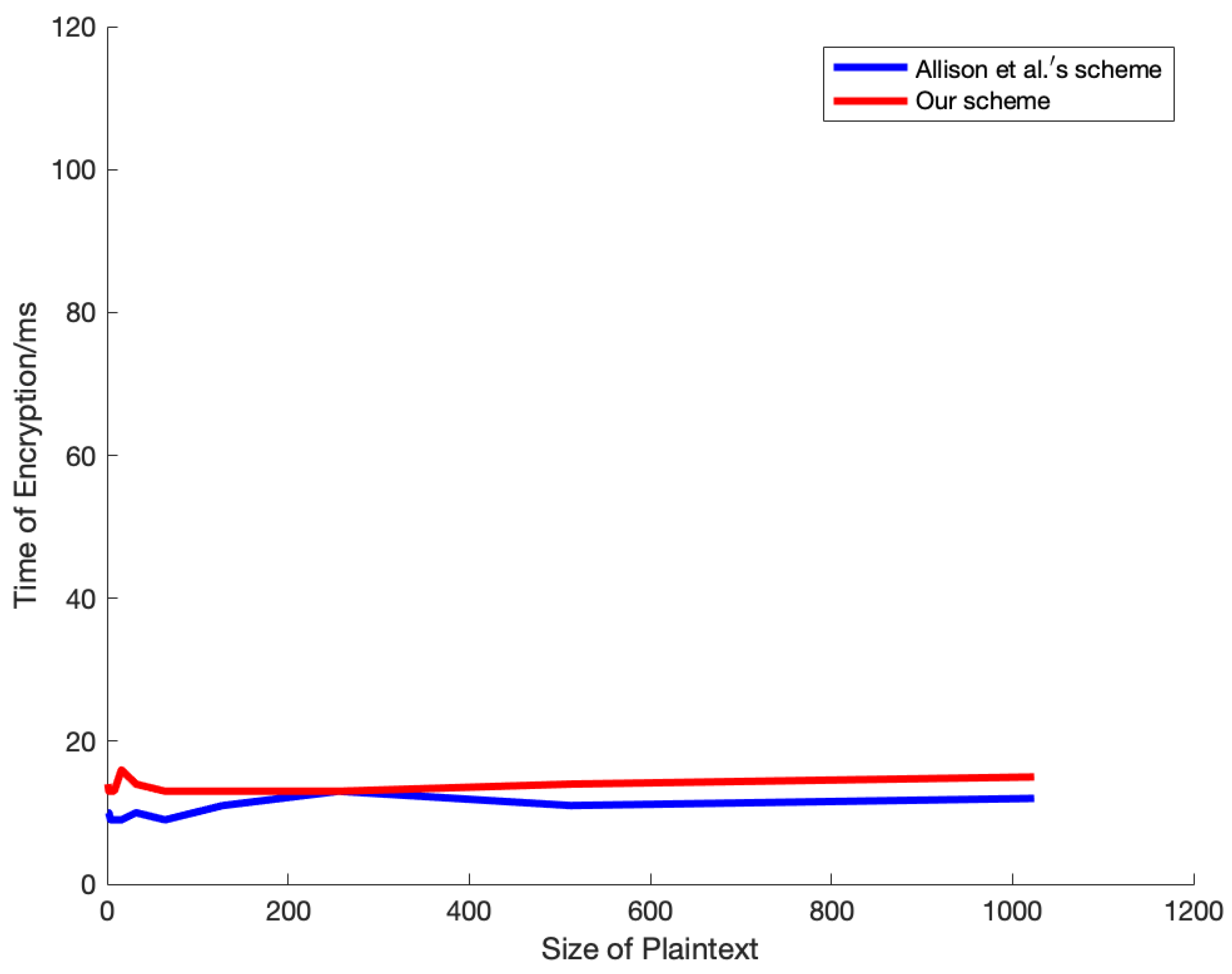
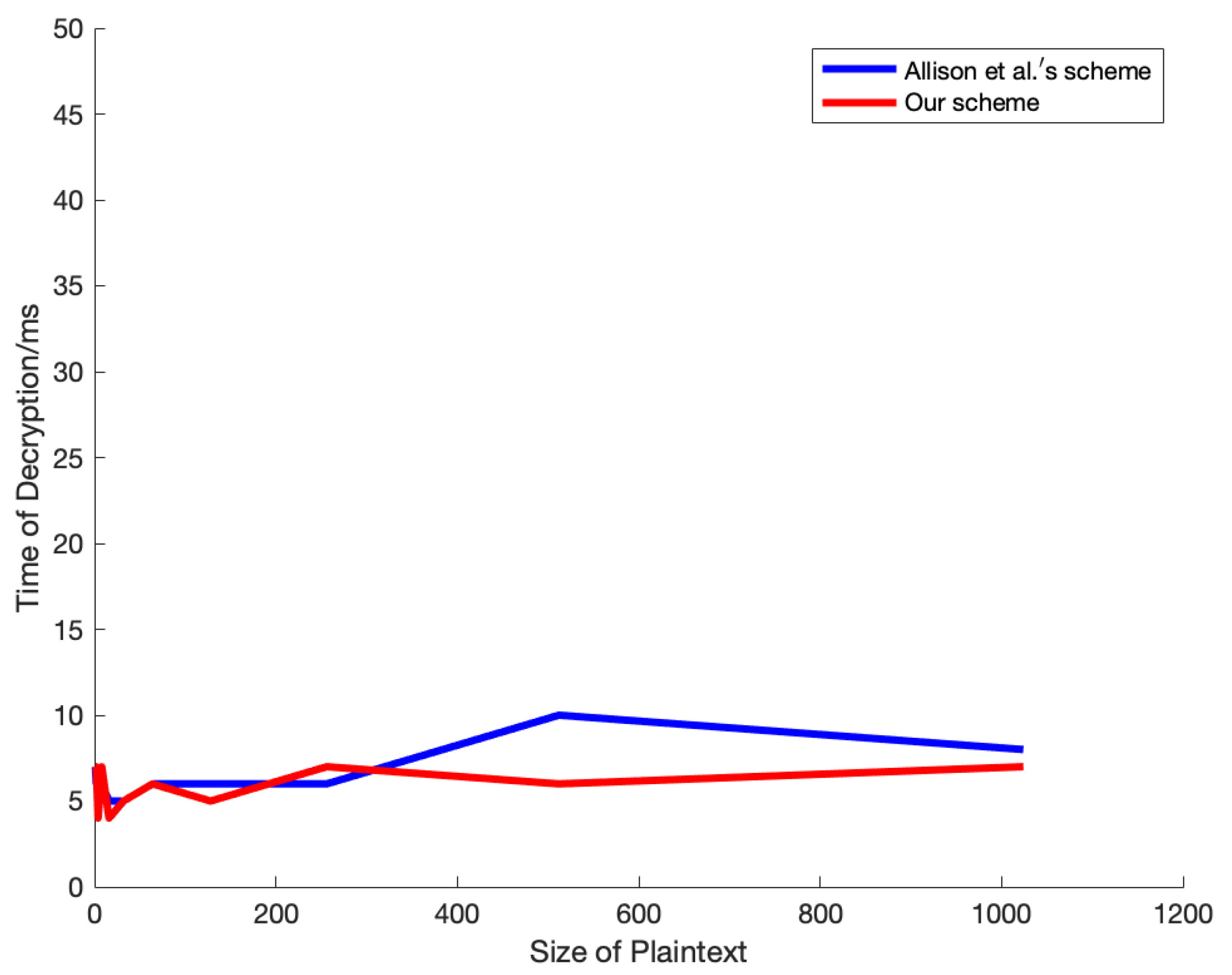
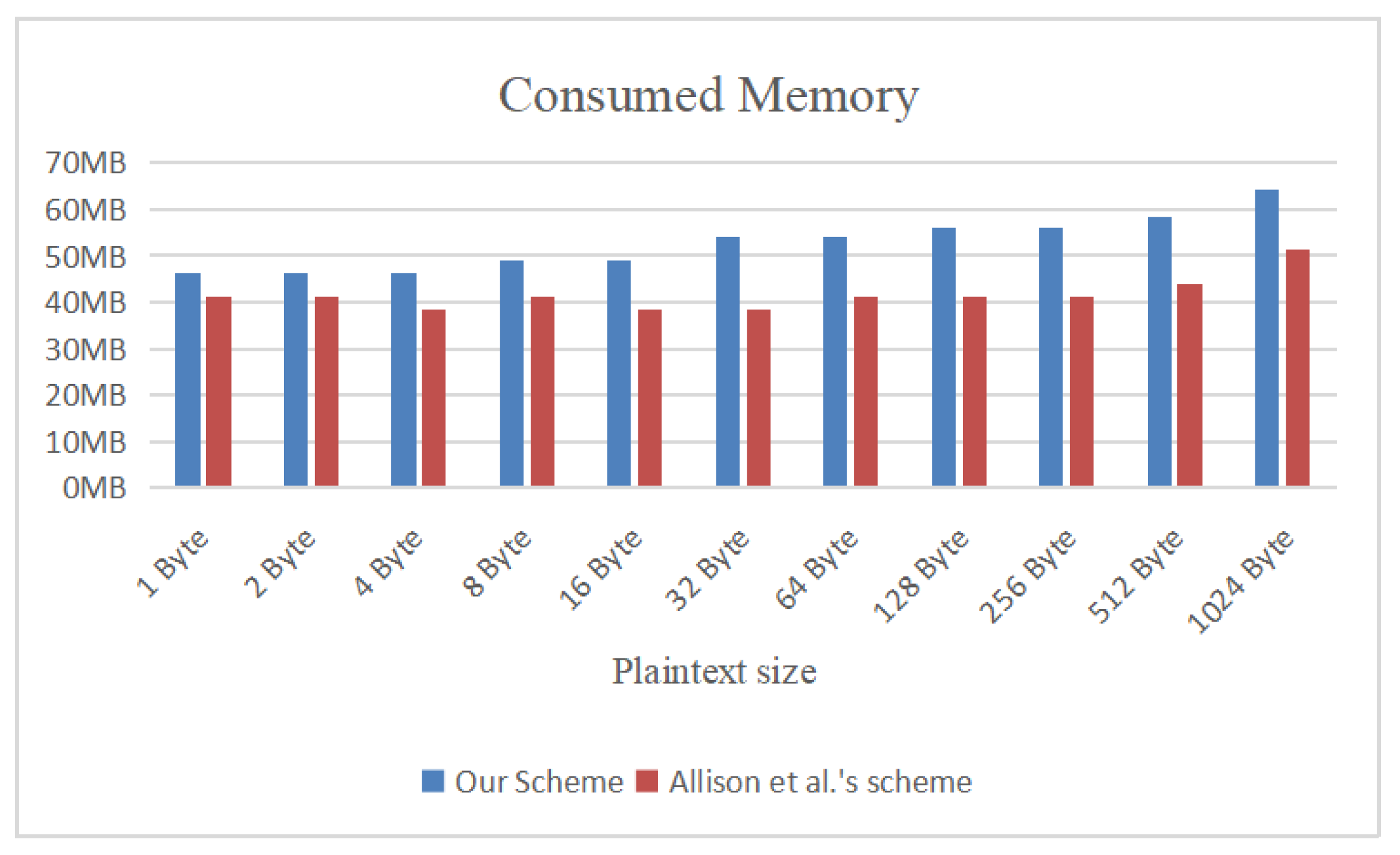
4. Experiments and Analysis
| MSK: alpha:210810353108659863024409106247517618452769941479846636980134442864523125 |
| 95818033429445987282464226795828802774079330 |
| g3:507123706182628610741111547764849270218939290666858116887669480037266931236 |
| 6558956079248951460266712797586740186721012,3848333923503209101783513197106326 |
| 835379604308979589246948604032780415086659341351001892795149863403912326337017 |
| 537761,0 |
| beta:3971351897302668818568847385425920497495147741445579066512932780617650627 |
| 246730432329467425793820791111050407589402 |
| CT_AT: |
| C0_0:{x=18512619911661450195327750867443546794232624419671207238173221146535506 |
| 95552872207298169171836981828215064641158984234,y=70592147653957222146120442588 |
| 2624722810944092606551932879619145643069907176528665887436471753185725971617607 |
| 9123508797} |
| C0_1:{x=10305743198129175737055428555819461127421625147813759967731163938926816 |
| 650740214215836427503578249751830703585598710737,y=9864469019751328170985532932 |
| 3260154136345304295214862269824474212174107344885351182673330718902818130451275 |
| 75927761095} |
| C0_2:{x=85627632985010802758634299337508008509965737271381026168608890332725357 |
| 51769387446114503063186080075196481905182611275,y=69157043429120428487195645886 |
| 4787393452354723338419697486692137357841812076088296305720924512144895097136125 |
| 4706491542} |
| C0_3:{x=85627632985010802758634299337508008509965737271381026168608890332725357 |
| 51769387446114503063186080075196481905182611275,y=69157043429120428487195645886 |
| 4787393452354723338419697486692137357841812076088296305720924512144895097136125 |
| 4706491542} |
| C0_4:{x=10828209153804955834077646467569440299821102129146337294704720899926979 |
| 6582045437576244731444812151580842960742884772,y=411045008855643689234607591514 |
| 8105748998457729928230076680665408791706458037634503664240890763024397642409757 |
| 902239244} |
| ourScheme.Decrypt(“file/Key”,“file/CT_AT”); |
| The plaintext after decryption is:hello |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sheng, H.; Cong, R.; Yang, D.; Chen, R.; Wang, S.; Cui, Z. UrbanLF: A Comprehensive Light Field Dataset for Semantic Segmentation of Urban Scenes. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7880–7893. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, J.; Yang, Y.; Li, T.; Niu, X.; Zhou, H. PSSPR: A Source Location Privacy Protection Scheme Based on Sector Phantom Routing in WSNs. Int. J. Intell. Syst. 2022, 37, 1204–1221. [Google Scholar]
- Lv, Z.; Song, H. Mobile internet of things under data physical fusion technology. IEEE Internet Things J. 2019, 7, 4616–4624. [Google Scholar]
- Meng, F.; Xiao, X.; Wang, J. Rating the crisis of online public opinion using a multi-level index system. arXiv 2022, arXiv:2207.14740. [Google Scholar]
- Cao, B.; Zhao, J.; Lv, Z.; Yang, P. Diversified Personalized Recommendation Optimization Based on Mobile Data. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2133–2139. [Google Scholar] [CrossRef]
- Chen, T.; Yu, Y.; Duan, Z.T. BlockChain/ABE-based Fusion Solution for E-government Data Sharing and Privacy protection. In Proceedings of the EITCE 2020: 2020 4th International Conference on Electronic Information Technology and Computer Engineering, Xiamen, China, 6–8 November 2020. [Google Scholar]
- Li, T.; Wang, Z.; Chen, Y.; Li, C.; Jia, Y.; Yang, Y. Is semi-selfish mining available without being detected? Int. J. Intell. Syst. 2021, 37, 10576–10597. [Google Scholar]
- Heidari, A.; Navimipour, N.J.; Unal, M. A Secure Intrusion Detection Platform Using Blockchain and Radial Basis Function Neural Networks for Internet of Drones. IEEE Internet Things J. 2023; early access. [Google Scholar] [CrossRef]
- Waters, B.R.; Sahai, A. Fuzzy identity based encryption. In Proceedings of the Advances in Cryptology—EUROCRYPT 2005: 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, 22–26 May 2005. [Google Scholar] [CrossRef] [Green Version]
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-based encryption for finegrained access control of encrypted data. In Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006. [Google Scholar] [CrossRef]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-policy attribute-based encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 20–23 May 2007. [Google Scholar] [CrossRef] [Green Version]
- Waters, B. Ciphertext-policy attribute-based encryption: An expressive, efficient, and provably secure realization. In Proceedings of the International Workshop on Public Key Cryptography, Taormina, Italy, 6–9 March 2011. [Google Scholar] [CrossRef] [Green Version]
- Lewko, A.; Waters, B. New proof methods for attribute-based encryption: Achieving full security through selective techniques. In Annual Cryptology Conference; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef] [Green Version]
- Ning, J.; Dong, X.; Cao, Z.; Wei, L. Accountable Authority Ciphertext-Policy Attribute-Based Encryption With White-Box Traceability and Public Auditing in the Cloud; Springer: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- Cao, B.; Sun, Z.; Zhang, J.; Gu, Y. Resource allocation in 5G IoV architecture based on SDN and fog-cloud computing. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3832–3840. [Google Scholar]
- Yu, G.; Wang, Y.; Cao, Z.; Lin, J.; Wang, X. Traceable and undeniable ciphertext-policy attribute-based encryption for cloud storage service. Int. J. Distrib. Sens. Netw. 2019, 15. [Google Scholar] [CrossRef]
- Yuan, F.; Chen, S.; Xu, K.L.L. Research on the Coordination Mechanism of Traditional Chinese Medicine Medical Record Data Standardization and Characteristic Protection under Big Data Environment; Shandong People’s Publishing House: Jinan, China, 2021. [Google Scholar]
- Chen, B.; Hu, J.; Zhao, Y.; Ghosh, B.K. Finite-Time Velocity-Free Rendezvous Control of Multiple AUV Systems With Intermittent Communication. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 6618–6629. [Google Scholar] [CrossRef]
- Lu, S.; Ban, Y.; Zhang, X.; Yang, B.; Yin, L.; Liu, S.; Zheng, W. Adaptive control of time delay teleoperation system with uncertain dynamics. Front. Neurorobot. 2022, 152, 928863. [Google Scholar]
- Peng, Y. Research on authenticating data rights in Big Data environment. Mod. Sci. Technol. Telecommun. 2016, 46, 17–20. [Google Scholar] [CrossRef]
- Guo, B.; Li, Q.; Duan, X.L.; Shen, Y.C.; Dong, X.Q.; Zhang, H.; Shen, Y.; Zhang, Z.L.; Luo, J. Personal Data Bank: A New Mode of Personal Big Data Asset Management and Value-Added Services Based on Bank Architecture. Chin. Comput. 2017, 40, 126–143. [Google Scholar]
- Wang, S.; Li, C. A Big Data Right Confirmation Method and System Based on Blockchain Technology. Patent CN106815728A, 9 June 2017. [Google Scholar]
- Wang, H.; Tian, Y.; Yi, X. Blockchain-based Big Data Right Confirmation Scheme. Comput. Sci. 2018, 45, 6. [Google Scholar]
- Zhao, H.; Zhao, B.; Cheng, S. The Mechanism of Confirming Big Data Property Rights Based on Smart Contract. In Proceedings of the 2019 4th International Conference, Jinan, China, 18–21 October 2019. [Google Scholar] [CrossRef]
- Zhou, G.; Yan, B.; Wang, G.; Yu, J. Blockchain-Based Data Ownership Confirmation Scheme in Industrial Internet of Things. In Proceedings of the Wireless Algorithms, Systems and Applications: 16th International Conference, WASA 2021, Nanjing, China, 25–27 June 2021; Part I. Springer International Publishing: Cham, Switzerland, 2021; pp. 121–132. [Google Scholar]
- Dai, X.; Xiao, Z.; Jiang, H.; Alazab, M.; Lui, J.C.; Min, G.; Dustdar, S.; Liu, J. Task Offloading for Cloud-Assisted Fog Computing With Dynamic Service Caching in Enterprise Management Systems. IEEE Trans. Ind. Inform. 2023, 19, 662–672. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Yang, Y.; Ma, Y. DOCS: A Data Ownership Confirmation Scheme for Distributed Data Trading. Systems 2022, 10, 226. [Google Scholar]
- Damgrd, I.; Thorbek, R. Linear integer secret sharing and distributed exponentiation. In Proceedings of the Public Key Cryptography—PKC 2006, 9th International Conference on Theory and Practice of Public-Key Cryptography, New York, NY, USA, 24–26 April 2006. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Cao, Z.; Wong, D.S. Blackbox traceable CP-ABE: How to catch people leaking their keys by selling decryption devices on ebay. In Proceedings of the 2013 ACM Conference on Computer and Communications Security, Berlin, Germany, 4–8 November 2013. [Google Scholar] [CrossRef]
- Boneh, D.; Goh, E.; Nissim, K. Evaluating 2-DNF Formulas on Ciphertexts; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar] [CrossRef] [Green Version]
- Lewko, A.B.; Waters, B. Decentralizing Attribute Based Encryption. In Proceedings of the 30th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tallinn, Estonia, 15–19 May 2011. [Google Scholar] [CrossRef] [Green Version]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the EUROCRYPT’99, Prague, Czech Republic, 2–6 May 1999. [Google Scholar] [CrossRef] [Green Version]
- Allison Lewko, B.; Okamoto, T.; Sahai, A.; Takashima, K.; Waters, B. Fully Secure Functional Encryption: Attribute-Based Encryption and (Hierarchical) Inner Product Encryption. In Proceedings of the International Conference on Theory and Applications of Cryptographic Techniques, French Riviera, France, 30 May–3 June 2010; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zhou et al. [25] | Liu et al. [27] | |
|---|---|---|
| Ways of identifying | Key verification | Fingerprint tracking protocol |
| Confirmation method | Consortium blockchain and smart contracts | Smart contract |
| Security assumption | Collision-resistant properties of hash function | null |
| Source data security | ✔ | ✔ |
| Can be applied to the cloud storage environment | × | × |
| Wang et al. [23] | ours | |
| Ways of identifying | Digital watermark | Pailler decryption |
| Confirmation method | Digital watermarking + blockchain | CP-ABE and Paillier encryption |
| Security assumption | CDH assumption | Subgroup decision problem for 3 primes |
| Source data security | × | ✔ |
| Can be applied to the cloud storage environment | ✔ | ✔ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Chen, Y.; Luo, Y.; He, Z.; Li, T. Data Rights Confirmation Scheme Based on Auditable Ciphertext CP-ABE in the Cloud Storage Environment. Appl. Sci. 2023, 13, 4355. https://doi.org/10.3390/app13074355
Zhang L, Chen Y, Luo Y, He Z, Li T. Data Rights Confirmation Scheme Based on Auditable Ciphertext CP-ABE in the Cloud Storage Environment. Applied Sciences. 2023; 13(7):4355. https://doi.org/10.3390/app13074355
Chicago/Turabian StyleZhang, Lingyun, Yuling Chen, Yun Luo, Zhongxiang He, and Tao Li. 2023. "Data Rights Confirmation Scheme Based on Auditable Ciphertext CP-ABE in the Cloud Storage Environment" Applied Sciences 13, no. 7: 4355. https://doi.org/10.3390/app13074355
APA StyleZhang, L., Chen, Y., Luo, Y., He, Z., & Li, T. (2023). Data Rights Confirmation Scheme Based on Auditable Ciphertext CP-ABE in the Cloud Storage Environment. Applied Sciences, 13(7), 4355. https://doi.org/10.3390/app13074355