
Classification of Virtual Harassment on Social Networks Using Ensemble Learning Techniques


Abstract
:1. Introduction
1.1. Research Limitation
1.2. Organization
2. Background
3. Related Works
Methodology
4. Results
4.1. Data Collection
4.1.1. Dataset 1
4.1.2. Dataset 2
4.1.3. Dataset 3
4.1.4. Dataset 4
4.2. Machine Learning Algorithms
4.2.1. Decision Tree Algorithm
4.2.2. KNN
4.2.3. Logistics Regression
- We know the equation of the straight line can be written as:
- In Logistic Regression y can be between 0 and 1 only, so we divide the above equation by (1 − y):
- We need a range between −[infinity] to +[infinity], then, if we take the logarithm of the equation, it will become:
4.2.4. Naïve Bayes
4.2.5. Neural Network
- Z is the symbol for denotation of the above graphical representation of ANN;
- W is, are the weights or the beta coefficients;
- X is, are the independent variables or the inputs;
- Bias or intercept = W0
4.2.6. Quadratic Discriminant Analysis
4.2.7. Support Vector Machine
4.3. Ensemble Learning
4.4. Experiments
4.5. Performance Metrics
- True Positive (TP): This instance indicates virtual harassment that was classified as virtual harassment;
- True Negative (TN): This instance indicates non-virtual harassment samples that were classified as non-virtual harassment;
- False Positive (FP): This instance indicates virtual harassment samples that were classified as non-virtual harassment;
- False Negative: It indicates non-virtual harassment samples that were classified as virtual harassment.
5. Discussion
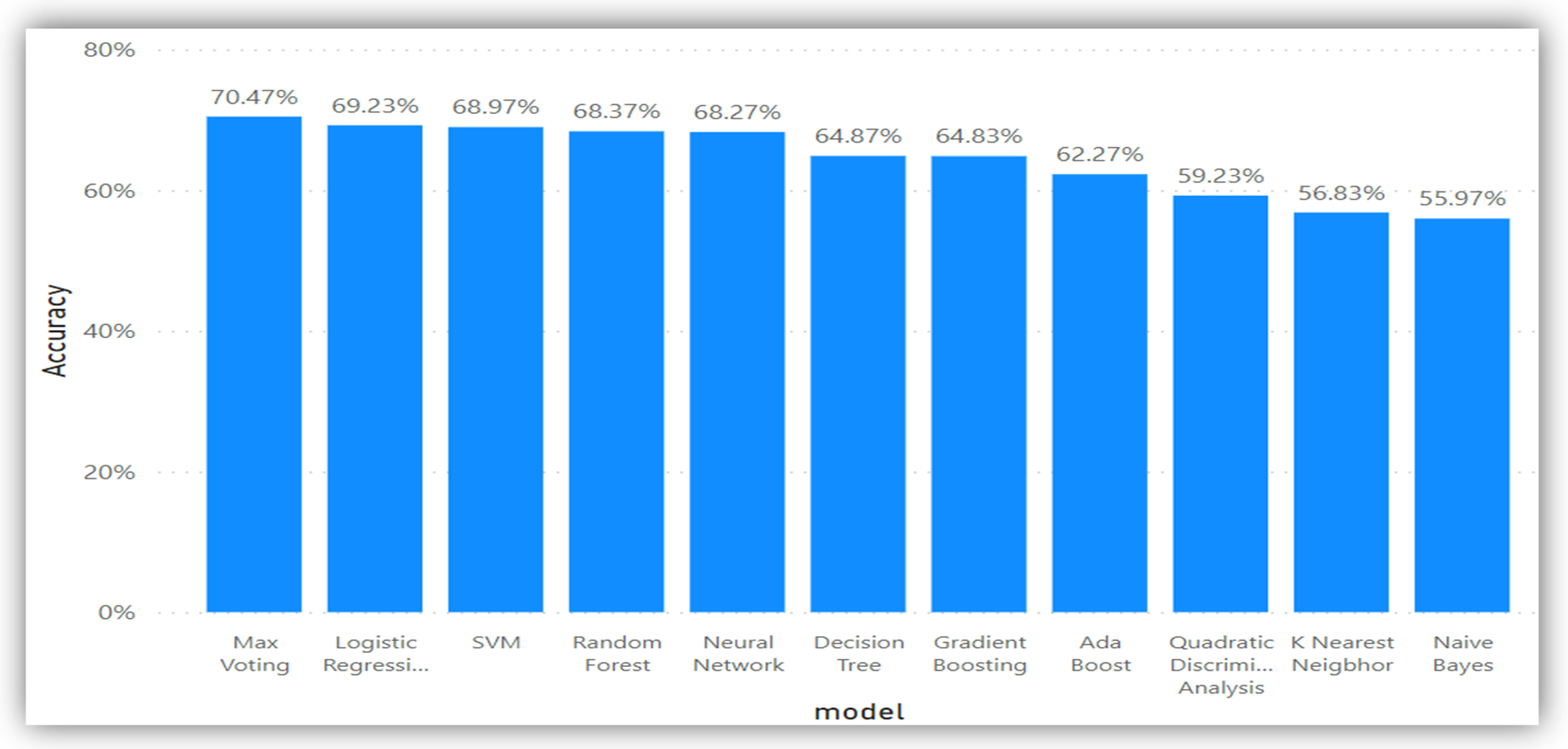
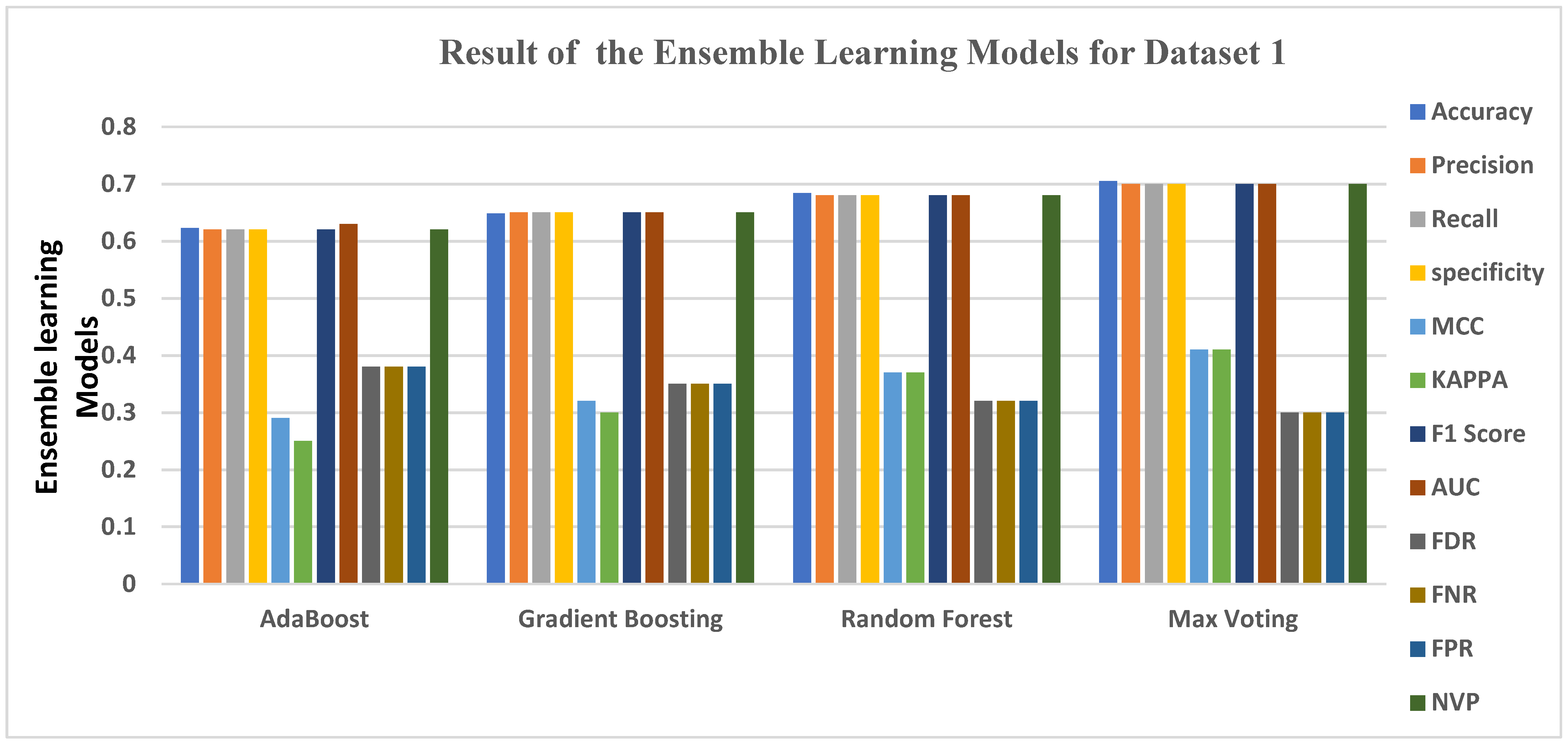
5.1. Data Analysis for Dataset 1
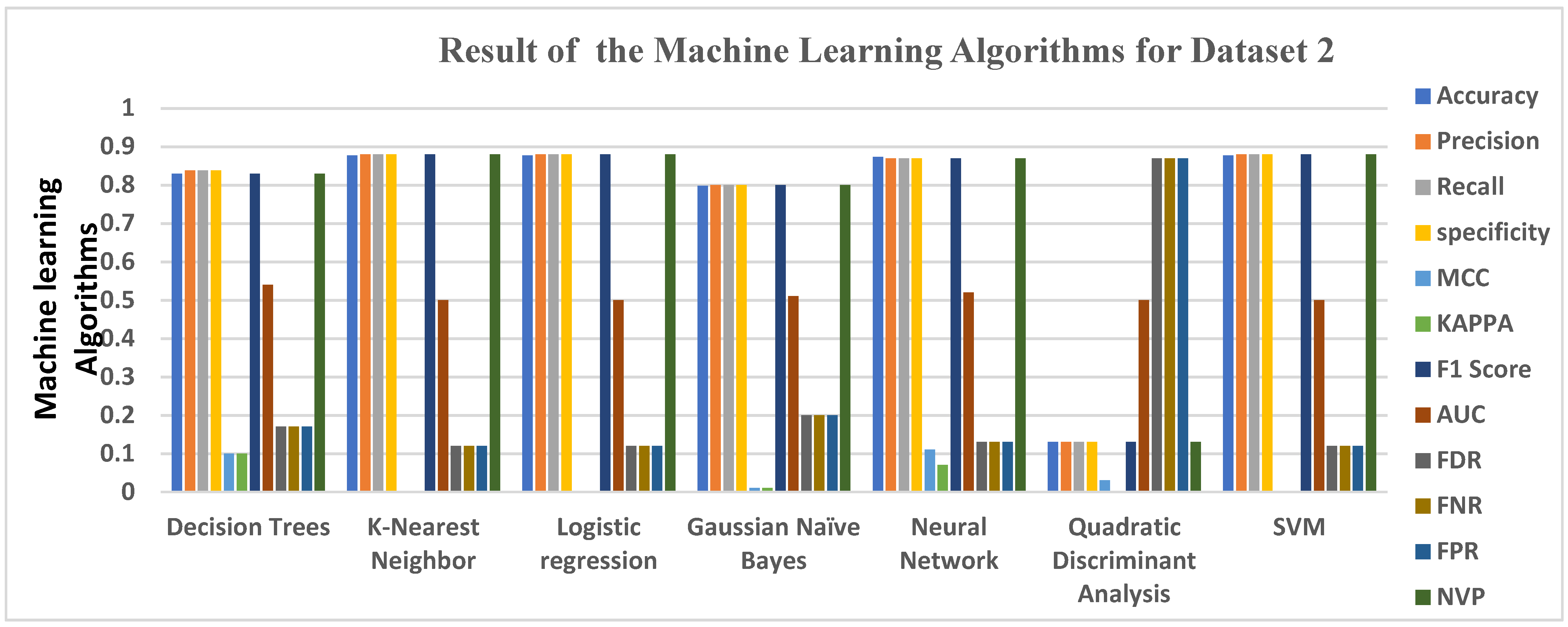
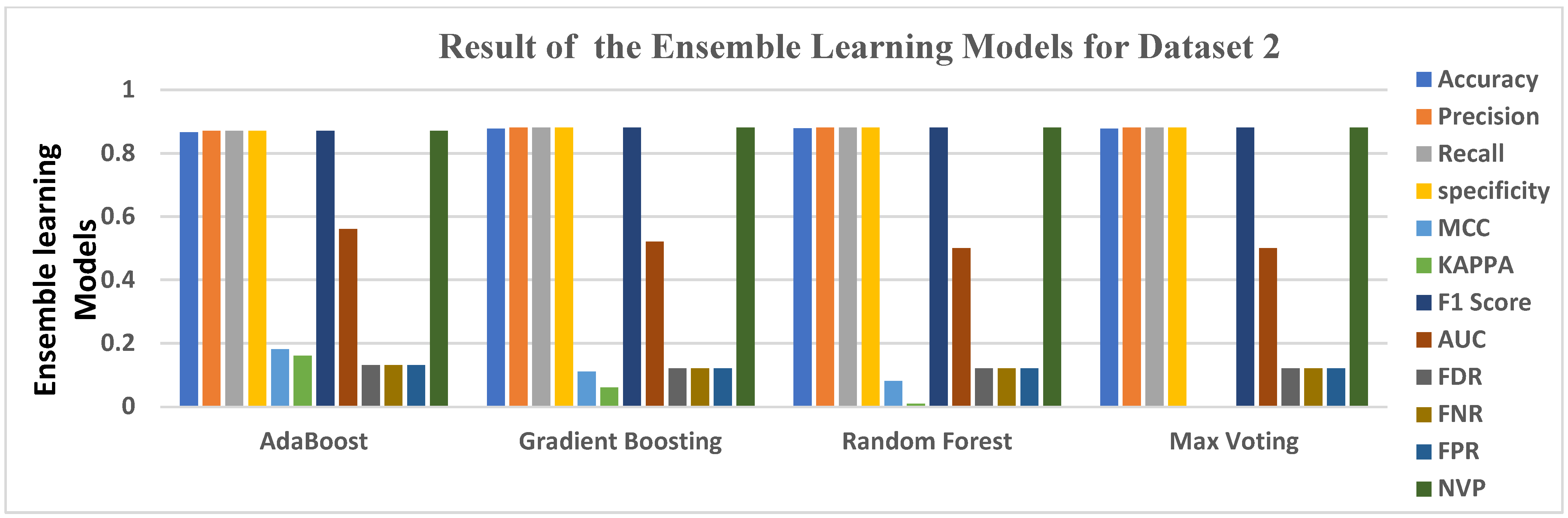
5.2. Data Analysis for Dataset 2
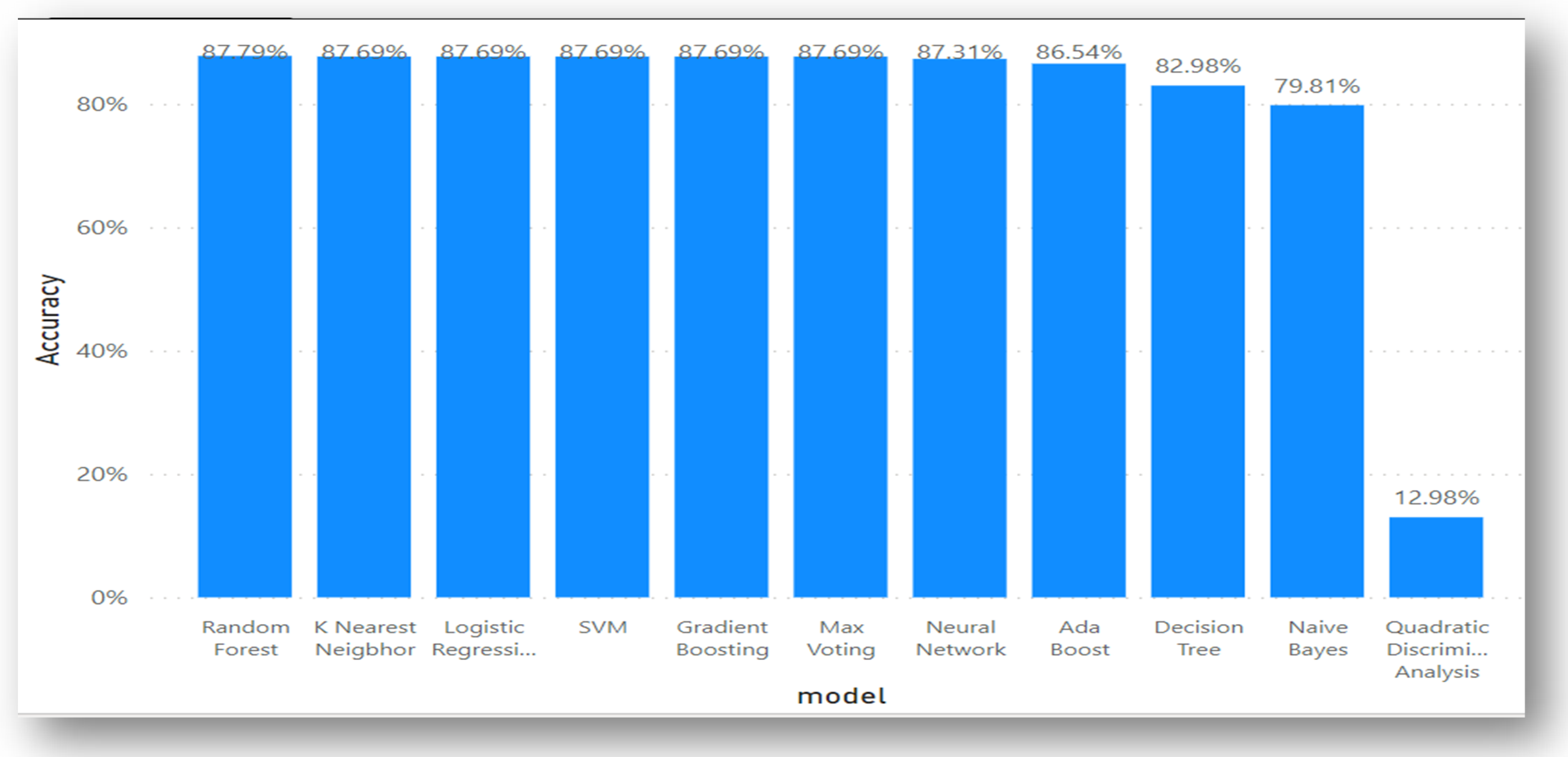
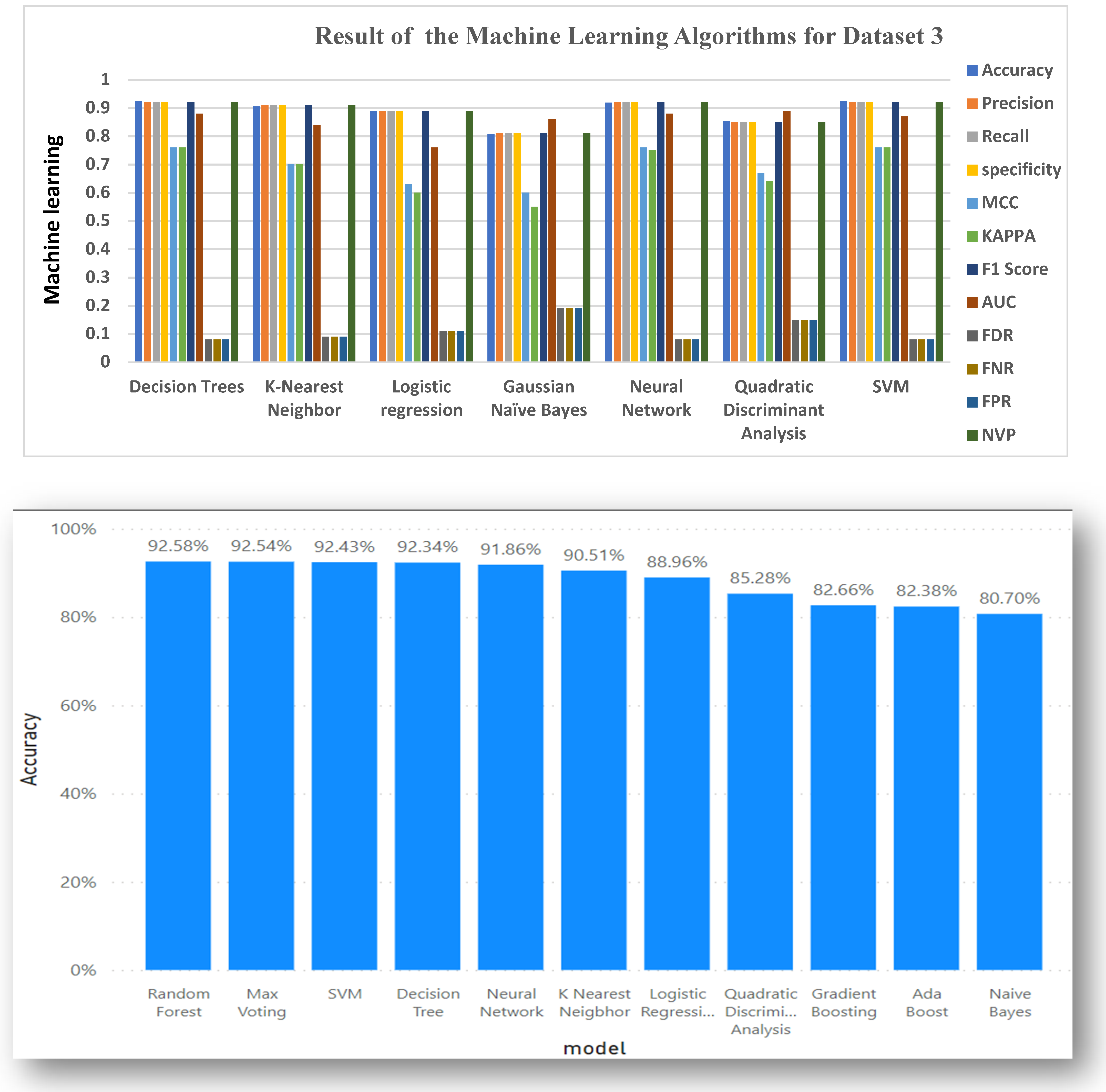
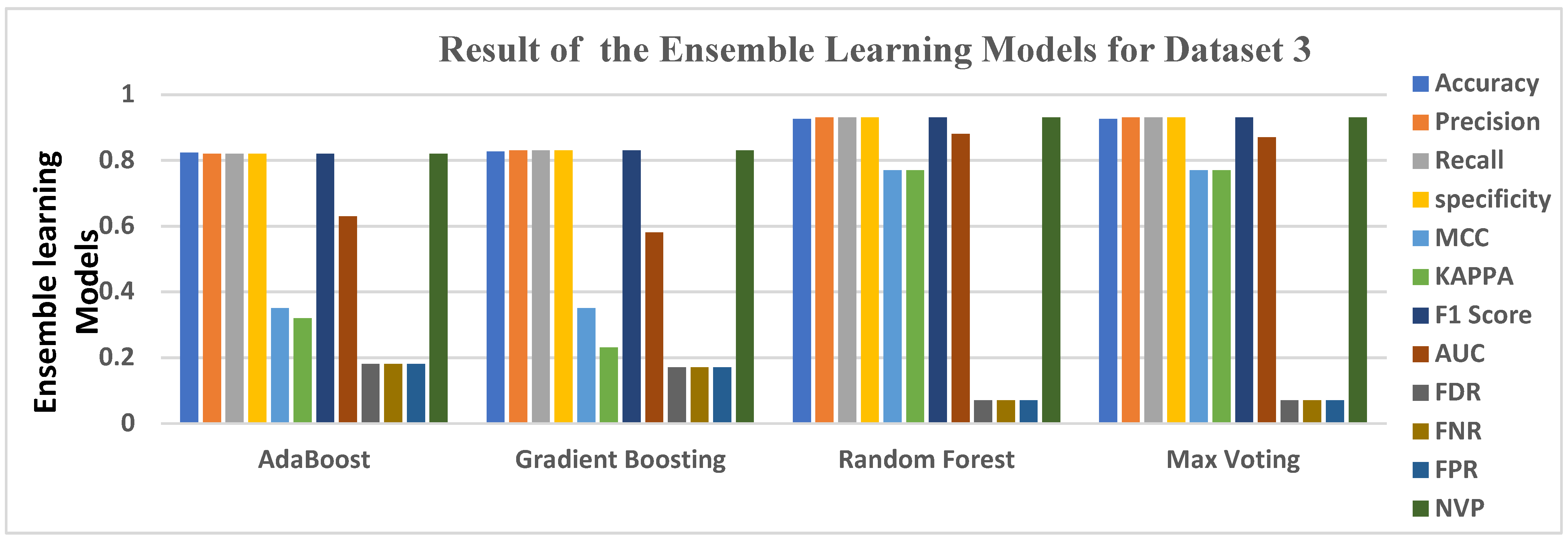
5.3. Data Analysis for Dataset 3
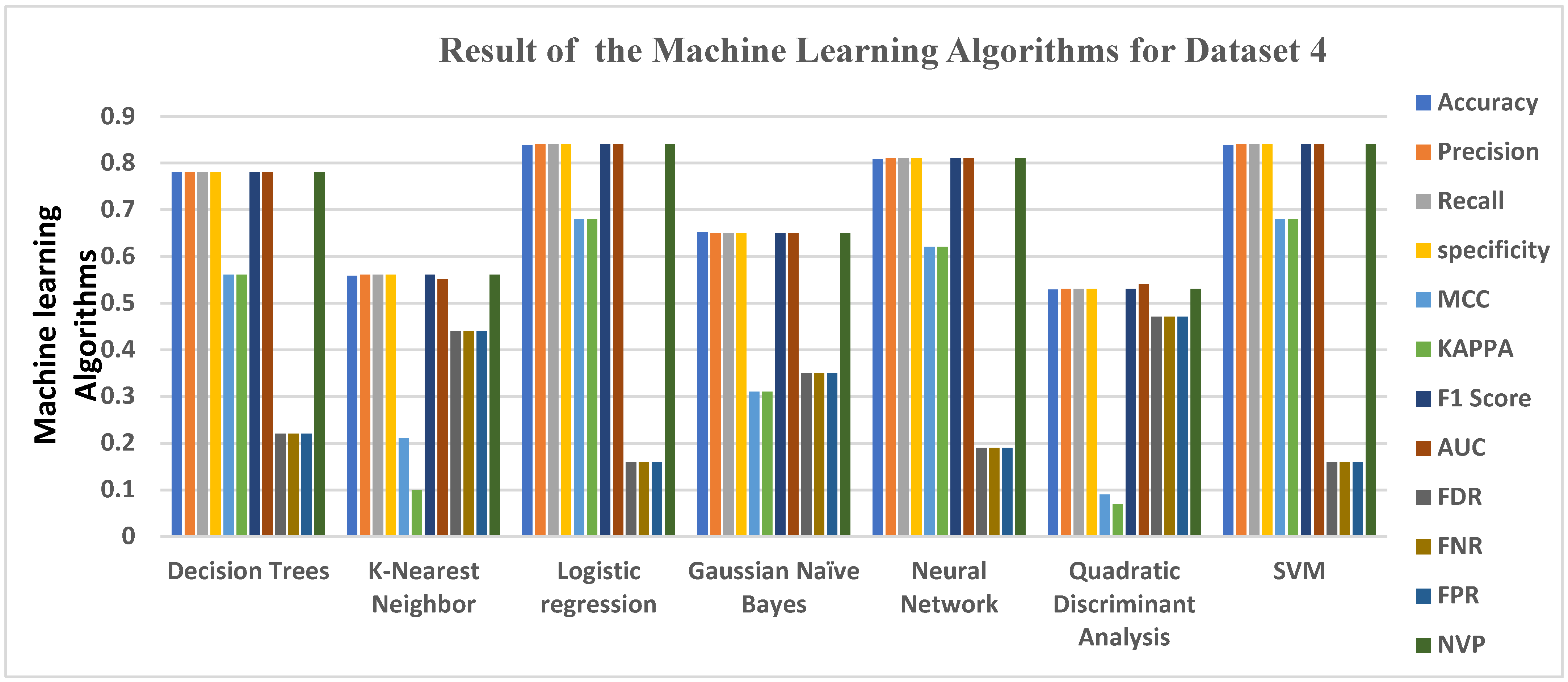
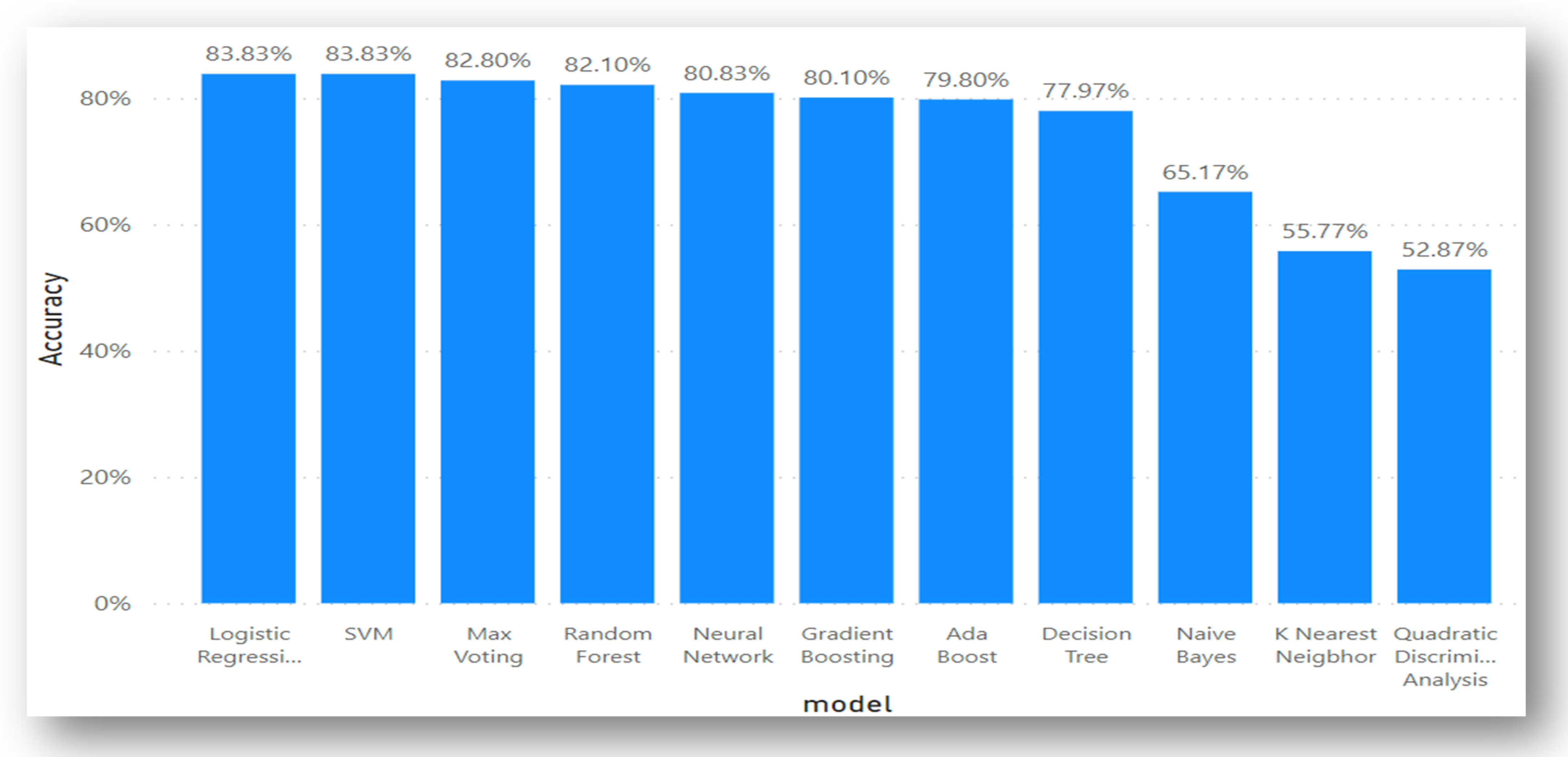
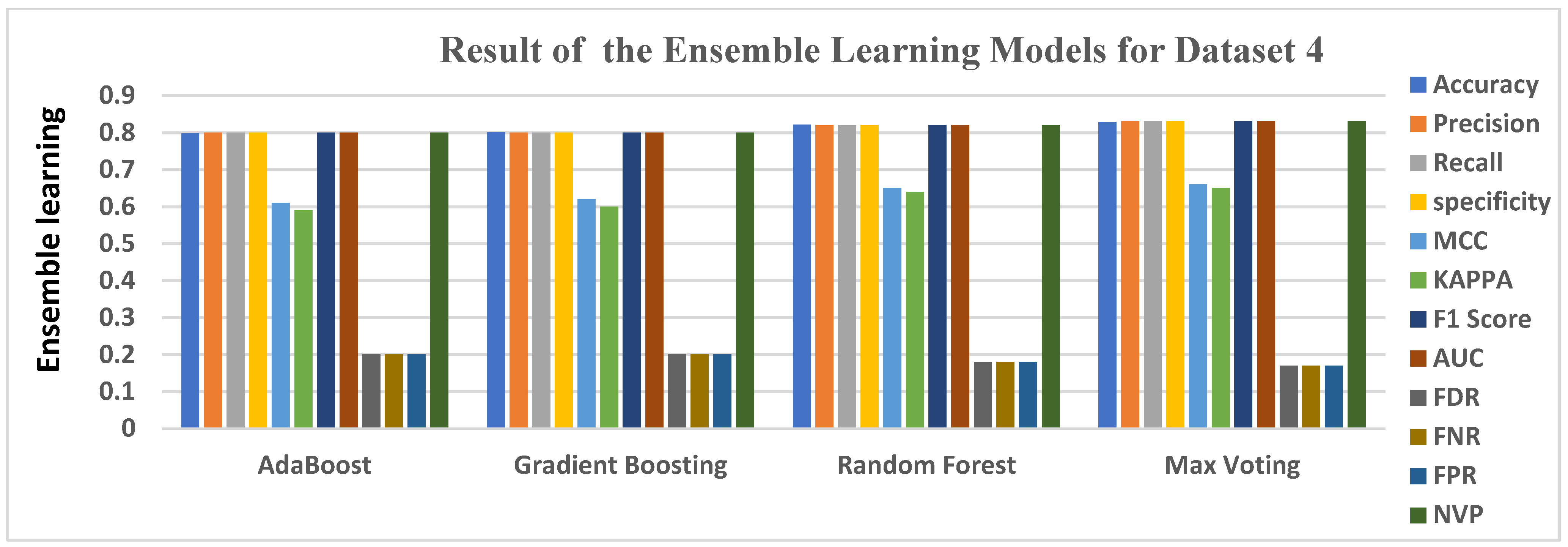
5.4. Data Analysis for Dataset 4
6. Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shaffer, D.; Kipp, K. Develpmental Psychology: Childhood and Adolescent, 8th ed.; Wadsworth, Cengage Learning: Belmont, CA, USA, 2010; Volume 33, p. 8. [Google Scholar]
- Kayes, I.; Kourtellis, N.; Quercia, D.; Iamnitchi, A.; Bonchi, F. The Social World of Content Abusers in Community Questions Answering. WWW CyberSafety Workshop 2015, 3, 22–24. [Google Scholar]
- Mahmud, J.; Zhou, M.; Megiddo, N.; Nichola, J.; Drews, C. Recommending targeted strangers from whom to solicit information on social media. In Proceedings of the 2013 International Conference on Intelligent User Interface, Santa Monica, CA, USA, 19–22 March 2013; pp. 37–48. [Google Scholar]
- Azeez, N.A.; Salaudeen, B.B.; Misra, S.; Damasevicius, R.; Maskeliunas, R. Identifying phishing attacks in communication networks using URL consistency features. Int. J. Electron. Secur. Digit. Forensics 2020, 12, 200–213. [Google Scholar] [CrossRef]
- Lexico. Available online: https://www.lexico.com/en/definition/cyberbullying (accessed on 26 December 2019).
- Dictionary. Available online: https://www.dictionary.com/browse/cyberbullying (accessed on 25 December 2019).
- Azeez, N.A.; Vyver, C.V. Towards a Dependable Access Framework for E-Health. In Proceedings of the 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2017; pp. 1695–1701. [Google Scholar]
- Azeez, N.A.; Vyver, C.V. Dynamic Patient-Regulated Access Control Framework for Electronic Health Information. In Proceedings of the 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2017; pp. 1684–1690. [Google Scholar]
- Azeez, N.A.; Ade, J.; Misra, S.; Adewumi, A.; Vyver, C.V.; Ahuja, R. Identifying Phishing Through Web Content and Addressed Bar-Based Features. Data Manag. Anal. Innov. 2020, 1016, 19. [Google Scholar]
- Sophia, A. Cyberbullying in the world of Teenagers and social media: A Literature review. Int. J. Cyber Behav. Psychol. Learn. 2016, 2, 1–29. [Google Scholar]
- Camparitech. Cyberbullying Facts and Statistics for 2020. 2020. Available online: https://www.comparitech.com/internet-providers/cyberbullying-statistics/ (accessed on 30 November 2020).
- Nureni, A.A.; Sunday, I.; Chinazo, O.J.; Charles, V.V. Cyberbullying Detection in Social Networks: Artificial Intelligence Approach. J. Cyber Secur. Mobil. 2021, 10, 745–774. [Google Scholar] [CrossRef]
- Azeez, N.A.; Odufuwa, O.E.; Misra, S.; Oluranti, J.; Damaševičius, R. Windows PE Malware Detection Using Ensemble Learning. Informatics 2021, 8, 10. [Google Scholar] [CrossRef]
- Manuel, F.V.; Francisco, N.J.; Victor, C.; Fidel, C. Early Detection of Cyber bullying on Social Media Networls. Future Gener. Comput. Syst. 2021, 118, 219–229. [Google Scholar]
- Celestine, I.; Gautam, S.; Suleman, K.; Praveen, K.M. Cyber bullying detection based on deep learning architectures. Multimedia Syst. 2020, 1–14. [Google Scholar]
- Chen, Y.; Zhou, Y.; Zhu, S.; Xu, H. Detecting Offensive Language in Social Media to Protect Adolescent Online Safety. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Confernece on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 71–80. [Google Scholar]
- Hine, G.; Onaolapo, J.; De Cristofaro, E.; Kourtellis, N.; Leontiadis, I.; Samaras, G.; Samaras, R.; Blackburn, J.; God, T.E. A measurement Study of 4chain’s Polotically Incorrectly Forum and its effects on the Web. WWW CyberSafety Workshop 2017, 3, 11–15. [Google Scholar]
- Abdulbasit, A.; Darem, F.A.G.; Al-Hashmi, A.A.; Abawajy, J.H.; Alanazi, S.M.; Al-Rezami, A.Y. An adaptive behavioral-based increamental batch learning malware variants detection model using concept drift detection and sequential deep learning. IEEE Access 2021, 9, 97180–97196. [Google Scholar]
- Krishna, K.B.; Narendra, S.M. A frame work for Cyberbullying Detection in social media. Int. J. Curr. Eng. Technol. 2015, 5, 1–5. [Google Scholar]
- Potha, N.; Maragoudakis, M. Cyberbullying detection using time series modeling. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 373–382. [Google Scholar]
- Dinakar, K.; Reichart, R.; Lieberman, H. Modelling the detection of Textual Cyberbullying. Soc. Mob. Web 2011, 2, 11. [Google Scholar]
- Walisa, R.; Lodchakorn, N.N.; Pimpaka, P.; Piyaporn, N.; Pirom, K. Autmated Cyberbullying detections using clutering appearance patterns. In Proceedings of the 9th International Conference on knowledge and Smart Technology, Chonburi, Thailand, 1–4 February 2017; pp. 242–247. [Google Scholar]
- Liu, W.; Ruths, D. What’s a name? Using first name as features for gender information on twitter. In Proceedings of the International Conference of Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 23–45. [Google Scholar]
- Saravanaraj, A.; Sheeba, J.; Pradeep, D.S. Automatic Detection of Cyberbullying from Twitter. J. Comput. Sci. Inf. Technol. 2016, 3, 22. [Google Scholar]
- Nahar, V.; Unankard, S.; Li, X.; Pang, C. Sentiment Analysis for Effective Deection of CyberBullying. In Proceedings of the Asia-Pacific Web and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, Kunming, China, 11–13 April 2012; Volume III, p. 22. [Google Scholar]
- Hosseinmardi, H.; Han, R.; Lv, Q.; Mishra, S. Analyzing Labelled Cyberbullying incidents on the Instagram Social Networks. In Proceedings of the Social Informatics: 7th International Conference, SocInfo 2015, Beijing, China, 9–12 December 2015; pp. 49–66. [Google Scholar]
- Jason, B. Machine Learning Mastery. January 2020. Available online: https://machinelearningmastery.com/category/deep-learning/ (accessed on 10 September 2020).
- Dadvar, M.; Trieschnigg, D.; Jong, F. Experts and Machine against bullies: A hybrid approach to detect cyberbulies. In Advances in Artificial Intelligence: 27th Canadian Conference on Artificial Intelligence, Canadian AI 2014, Montréal, QC, Canada, 6–9 May 2014. Proceedings 27; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 275–281. [Google Scholar]
- Despoina, C.; Nicolas, K.; Jermy, B.; Emiliano, D.; Gianluca, S.; Athena, V. Telefonica Research; University College London: London, UK, 2017; pp. 1–10. [Google Scholar]
- Kowalski, R.M.; Limber, S.P.; Limber, S.; Agatston, P.W. Cyberbullying: Bullying in the Digital Age; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Ptaszynski, M.; Dybala, P.; Matsuba, T.; Masui, F.; Rzepka, R.; Araki, K. Machine learning and affect analysis against cyber-bullying. In Proceedings of the 36th AISB, Leicester, UK, 29 March–1 April 2010; pp. 7–16. [Google Scholar]
- Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Rasosavljevic, V.; Bhamidipati, N. Hate Speect Detection with Comment Embeddedings. In Proceedings of the 24th International Conference on World Wide Web, Taipei, Taiwan, 20–24 April 2017; pp. 29–30. [Google Scholar]
- Dvořáková, I.; Vochozka, M. Vykorystannjanejronnychmereždlja prognozuv annj arozytjujompaniji. Nac. Naakedemijamak Ukajainj Kijiv 2015, 3–5. [Google Scholar]
- GitHub. 2018. Available online: https://github.com/dhfbk/WhatsApp-Dataset (accessed on 25 January 2020).
- Analytics Vidhya. 2020. Available online: https://www.analyticsvidhya.com/blog/2015/09/questions-ensemble-modeling/ (accessed on 29 January 2021).
- Aggression. (n.d.). Kaggle_Aggressiondataset. Available online: www.kaggle.com (accessed on 27 January 2023).
- Lenhart, A. Teens, Cell Phones, and Texting. Pew Internet & American Life Project. Available online: http://pewresearch.org/pubs/1572/teens-cell-phones-text-messages (accessed on 23 December 2019).
- Nicole, A.M. Cyberbullying; The Graduate School, University of Wisconsin-Stout: Menomonie, WI, USA, 2009; pp. 1–33. [Google Scholar]
- Smith, P.K. Cyberbullying and cyber aggression. In Handbook of School Violence and School Safety; Routledge: London, UK, 2012; pp. 111–121. [Google Scholar]
- Kopecky, K.; Szotkowski, R. Cyberbullying, cyber aggression and their impact on the victim—The teacher. Telematics Inform. 2017, 34, 506–517. [Google Scholar] [CrossRef]
- Azeez, N.A.; Ayemobola, T.J.; Misra, S.; Maskeliūnas, R.; Damaševičius, R. Network Intrusion Detection with a Hashing Based Apriori Algorithm Using Hadoop MapReduce. Computers 2019, 8, 86. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Chen, L.; Thirnarayan, K.; Sheth, A. Cursing in English on Twitter. In Proceedings of the 17th ACM conference on Computer Supported Cooperative Work & SOCIAL Computing, Baltimore, MD, USA, 15–19 February 2014; pp. 415–425. [Google Scholar]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.; Carvalho, J.; Oliveira, S.; Coheur, L.; Paulino, P.; Simão, A.V.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Moreno, M.; Kota, R. Children, Adolescent and the Media; Strasburger, B., Wilson, B., Jordan, A., Eds.; Sage Publishers: Newbury Park, CA, USA, 2014. [Google Scholar]
- Shane, M.; William, B.J.; Adrian, S.; Gordon, R. Machine learning and semantics analysis of in-game chat for Cyberbullying. J. Comput. Secur. 2018, 76, 197–213. [Google Scholar]
- Shiels, M. A Chat with the Man Behind Mobiles. BBC News. Available online: http://news.bbc (accessed on 23 December 2003).
- Watkins, L.E.; Maldonado, R.C.; DiLillo, D. The Cyber Aggression in Relationships Scale: A new multidimensional measure of technology-based intimate partner aggression. Assessment 2018, 25, 608–626. [Google Scholar] [CrossRef]
- Turan, N.; Polat, O.; Karapirli, M.; Uysal, C.; Turan, S.G. The new violence type of the era: Cyber bullying among university students: Violence among university students. Neurol. Psychiatry Brain Res. 2011, 17, 21–26. [Google Scholar] [CrossRef]
- OrboGraph. 2020. Available online: https://orbograph.com/deep-learning-how-will-it-change-healthcare/ (accessed on 10 September 2020).
- Karthik, D.; Birago, J.; Catherine, H.; Henry, L.; Roslind, P. Common sense reasoning for detecting, prevention and mitigation of cyberbullying. ACM Trans. Interact. Intell. Syst. (TiiS) 2012, 2, 18. [Google Scholar]
- Michele, D.; Emmanuel, D.; Alfredo, P. Unsupervised Cyberbullying detection in social Network. In Proceedings of the 23rd Intenational Conference on pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 432–437. [Google Scholar]
- Batoul, H.; Maroun, C.; Ahmed, S. A Multilingual System for Cyberbullying detection: Arabic Content detection using maching learning. Adv. Sci. Technol. Eng. Syst. J. 2017, 2, 275–284. [Google Scholar]
- Banerjee, V.; Telavane, J.; Gaikwad, P.; Vartak, P. Detection of Cyberbullying Using Deep Neural Network. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019. [Google Scholar]
- Van Royen, K.; Poels, K.; Daelemans, W.; Vandebosch, H. Automatic monitoring of cyberbullying on social networking sites: From technological feasibility to desirability. Telemat. Inform. 2015, 32, 89–97. [Google Scholar] [CrossRef]
- Chikashi, N.; Joel, T.; Achint, T.; Yashar, M.; Yi, C. Abusive Language detection in online user content. In Proceedings of the 25th International Conference on World Wide Web, International World Wide Web Conferences Steeting Committee, Geneva, Switzerland, 11–15 April 2016; Volume 10, pp. 145–153. [Google Scholar]
- Seeland, M.; Mäder, P. Multi-view classification with convolutional neural networks. PLoS ONE 2021, 16, e0245230. [Google Scholar] [CrossRef] [PubMed]
- Pieschl, S.; Porsh, T.; Kahl, T.; Klockenbusch, R. Relevant dimensions of Cyberbullying-Resuls from two experimental studies. J. Appl. Dev. Psychol. 2013, 5, 241–252. [Google Scholar] [CrossRef]
- Richard, D. Bulling and Cyberbullying: History, Statistics, Law, Prevention and Analysis. Elon J. Undergrad. Res. Commun. 2012, 3, 1–10. [Google Scholar]
- Rui, Z.; Anna, Z.; Kezhi, M. Automatice detection of Cyberbullying on social networks based on bullying features. In Proceedings of the 17th International Conference on Distributed Computing and Networking, Singapore, 4–7 January 2016; Volume 43. [Google Scholar]
- Sani, M.; Livia, A. Cyberbullying Classificaton using text mining. In Proceedings of the 1st International Conference on Information and computational Science, Jakarta, Indonesia, 5–7 December 2017; pp. 241–246. [Google Scholar]
- Zaccagnino, R.; Capo, C.; Guarino, A.; Lettieri, N.; Malandrino, D. Techno-regulation and intelligent safeguards. Multimed. Tools Appl. 2021, 80, 15803–15824. [Google Scholar] [CrossRef]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How many trees in a random forest? In International Workshop on Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar]
- Sourabh, P.; Vaibhav, S. Cyberbullying detection and prevention: Data mining and psychological perspective. In Proceedings of the International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 20–21 March 2014; Volume 10, pp. 1541–1547. [Google Scholar]
- Van Hee, C.; Lefever, E.; Verhoeven, B.; Mennes, J.; Desmet, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Automatic detection and prevention of Cyberbullying. Hum. Soc. Anal. 2015, 2, 12–24. [Google Scholar]
- Zhang, X.; Tong, J.; Vishwamitra, N.; Whittaker, E.; Mazer, J.P.; Kowalski, R.; Hu, H.; Luo, F.; Macbeth, J.; Dillon, E. Cyberbullying detection with a pronunciation based convulutional neural Network. In Proceedings of the 15th IEEE International Conference on Machine Learning and Applicarions (ICMLA), Anaheim, CA, USA, 18–20 December 2016; Volume 10, pp. 740–745. [Google Scholar]
- Sun, S. A survey of multi-view machine learning. Neural Comput. Appl. 2013, 23, 2031–2038. [Google Scholar] [CrossRef]
- Guarino, A.; Malandrino, D.; Zaccagnino, R. An automatic mechanism to provide privacy awareness and control over unwittingly dissemination of online private information. Comput. Netw. 2022, 202, 108614. [Google Scholar] [CrossRef]
- Wang, Q.; Hao Xue, H.; Li, F.; Lee, D.; Luo, B. #DontTweetThis: Scoring Private Information in Social Networks. Proc. Priv. Enhancing Technol. 2019, 2019, 72–92. [Google Scholar]
- Prabhu, T.N. Method to Stop Cyber-Bullying Before It Occurs. Appl. No.: 14/738,874, Pub. No.: US 2015/0365366 A1Pub, 17 December 2022. [Google Scholar]
- Salmivalia, C. Bullying and the Peer group: A review. J. Aggress. Violent Behav. 2012, 15, 112–120. [Google Scholar] [CrossRef]
- Corcoran, L.; Guckin, C.; Prentice, G. Cyberbullying or cyber aggression? A review of existing definitions of cyber-based peer-to-peer aggression. Societies 2015, 5, 245–255. [Google Scholar] [CrossRef]
- Zhou, Z.-H. Ensemble Learning. In Machine Learning; Springer: Singapore, 2021; Available online: https://link.springer.com/chapter/10.1007/978-981-15-1967-3_8 (accessed on 23 November 2022).
- Nandhini, B.; Sheeba, J. Cyberbullying detection and classifiation using informton retrieval algorithm. In Proceedings of the 2015 International Conference on Advanced Research in Computer Science, Engineering & Technology, Unnao, India, 6–7 March 2015. Article No. 20. [Google Scholar]
- Ma, J.; Li, M.; Li, H.J. Traffic dynamics on multilayer networks with different speeds. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 1697–1701. [Google Scholar] [CrossRef]
- Ma, J.; Ma, J.; Li, H.J. An improved optimal routing strategy on scale-free networks. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 4578–4582. [Google Scholar] [CrossRef]
- Peter, S.K.; Jess, M.; Manuel, C.; Sonja, F.; Shanette, R.; Neil, T. Cyberbullying; Its nature and impact in Secondary Schools pupils. J. Child Psyvhol. Psychiatry 2008, 49, 376–385. [Google Scholar]
- Bayzick. (n.d.). Bayzick_Repository. Available online: www.bayzick.com (accessed on 27 January 2023).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Approach | Strength | Weakness |
|---|---|---|---|---|
| (Nureni, Sunday, Chinazo, & Charles) [12] | 2021 | Naive Bayes, K-Nearest Neighbors, Logistic Regression, Decision Tree, Random Forest, Linear Support Vector Classifier, Adaptive Boosting, Stochastic Gradient Descent, and Bagging classifiers are some of the techniques used for evaluation. | The medians for the Random Forest classifier across the datasets are 0.77, 0.73, and 0.94, making it the top-performing classifier. With medians of 0.77, 0.66, and 0.94 compared to the linear support vector classifier’s 0.59, 0.42, and 0.86. | The ensemble model has demonstrated an improvement in the performance of its constituent classifiers |
| (Manuel, Francisco, Victor, & Fidel) [14] | 2021 | Followed two supervised learning methods namely:
| Results show how to improve baseline detection models by up to 42% | Experiment with a dataset from some other social media platforms. Use random forest for negative models. Extra tree for the positive models. |
| (Celestine, Gautam, Suleman, & Praveen) [15] | 2020 | Empirical analysis to determine the effectiveness and performance of deep learning algorithms in detecting insults in social media commentary. | Results show that the BLSTM model achieved high accuracy and F1-measure scores in comparison to RNN, LSTM, and GRU. | Deep learning models can be most effective against cyberbullying when directly compared with others and paves the way for future hybrid technologies that may be employed to combat this serious online issue. |
| (Abaido) | 2019 | Enhance Timing Approach (ETA) and Ensemble learning. | SPSS was used for the reliability test and it showed satisfactory results for the research study (Alpha = 0.718) further results showed that virtual harassment exists on social media platforms at 91% positive. | Further quantitative research is required to assess the socio-psychological impacts of virtual harassment on victims in conservative societies |
| (Shane, William, Adrian, & Gordon) [45] | 2018 | Datasets were gotten from the war of Tanks game and classifications were done manually. | It has a similarity with the Simple Naïve classification that uses emotional analysis. | The results produces were very poor |
| (Walisa, Lodchakorn, Pimpaka, Piyaporn, & Pirom) [22] | 2017 | Improved Naïve Bayes classifier was used to eliminate words and examine the loaded pattern | 95.79% correctness was achieved after the experiment | The cluster pattern does not work in parallel |
| (Sani & Livia) [60] | 2017 | Two classifiers were used Naïve Bayes and SVM and the data set was collected from Kaggle | 92,81% accuracy for Naïve Bayes and 97.11% for SVM | The dataset used for testing and training was not mentioned, hence their result isn’t credible |
| (Batoul et al.) [52] | 2017 | They made use of the Arabic language and the classifiers used were Naïve Bayes and SVM | 90.85% precision with Naïve Bayes and 94.1% precision on SVM | The result had a high rate of false Positive |
| (Michele, Emmanuel, & Alfredo ) [51] | 2016 | An unsupervised learning approach was used | Accuracy of 67%, 60%,69%, 94% and 67% were achieved | The average levels of accuracy were low than when compared with supervised learning algorithms |
| (Celestine, et al.) [15] | 2016 | Deep learning and Neural Networks approaches were used for the experiment | 56% exactness, 70% recall, and accuracy 96% | The data set was unbalanced while achieving high accuracy, so it gave incorrect output |
| (Rui, Anna, & Kezhi) [59] | 2016 | Word embedding makes a list of pre-defined words | 79.4% accuracy using Support Vector Machine | Only one classifier was used |
| (Chikashi, Joel, Achint, Yashar, & YI) [55] | 2016 | Vowpalwabbit framework was used for classification and NLP features | It performs better when compared with the deep learning approach with about 81% accuracy | the other classifiers such as Naive Bayes gave better accuracy |
| (Nandhini & Sheeba) [73] | 2015 | Naïve Bayes machine learning Effort | 91% Accuracy was achieved | Efficiency is reduced when tried with another classifier |
| Dataset | URL | Source | Remark |
|---|---|---|---|
| Dataset 1 | https://github.com/jo5hxxvii/cyberbullying-text-classification | Kaggle | GitHub, 2022 |
| Dataset 2 | https://github.com/jo5hxxvii/youtube_parsed_dataset-text-classification | You-tube | GitHub, 2022 |
| Dataset 3 | https://www.bayzick.com/bullying_dataset | Bayzick | Bayzick.com |
| Dataset 4 | https://github.com/jo5hxxvii/aggression_parsed_dataset-text-classification | Kaggle | GitHub, 2022 |
| PREDICTED POSITIVE | PREDICTED NEGATIVE | |
|---|---|---|
| ACTUAL POSITIVE | TRUE POSITIVE (TP) | FALSE NEGATIVE (FN) |
| ACTUAL NEGATIVE | TRUE NEGATIVE (TN) | FALSE POSITIVE (FP) |
| Model | Accuracy | Precision | Recall | Specificity | MCC | KAPPA | F1 Score | AUC | FDR | FNR | FPR | NVP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Decision Trees | 0.6487 | 0.6500 | 0.6500 | 0.6500 | 0.3000 | 0.3000 | 0.6500 | 0.6500 | 0.3500 | 0.3500 | 0.3500 | 0.6500 |
| The K-Nearest Neighbor | 0.5683 | 0.5700 | 0.5700 | 0.5700 | 0.1900 | 0.1200 | 0.5700 | 0.5600 | 0.4300 | 0.4300 | 0.4300 | 0.5700 |
| Logistic regression | 0.6923 | 0.6900 | 0.6900 | 0.6900 | 0.3900 | 0.3900 | 0.6900 | 0.6900 | 0.3100 | 0.3100 | 0.3100 | 0.6900 |
| Gaussian Naïve Bayes | 0.5597 | 0.5600 | 0.5600 | 0.5600 | 0.0800 | 0.0600 | 0.5600 | 0.5400 | 0.4400 | 0.4400 | 0.4400 | 0.5600 |
| Neural Network | 0.6827 | 0.6800 | 0.6800 | 0.6800 | 0.3600 | 0.3600 | 0.6800 | 0.6800 | 0.3200 | 0.3200 | 0.3200 | 0.6800 |
| Quadratic Discriminant Analysis | 0.5923 | 0.5900 | 0.5900 | 0.5900 | 0.2100 | 0.1900 | 0.5900 | 0.6000 | 0.4100 | 0.4100 | 0.4100 | 0.5900 |
| SVM | 0.6897 | 0.6900 | 0.6900 | 0.6900 | 0.3800 | 0.3800 | 0.6900 | 0.6900 | 0.3100 | 0.3100 | 0.3100 | 0.6900 |
| AdaBoost | 0.6227 | 0.6200 | 0.6200 | 0.6200 | 0.2900 | 0.2500 | 0.6200 | 0.6300 | 0.3800 | 0.3800 | 0.3800 | 0.6200 |
| Gradient Boosting | 0.6483 | 0.6500 | 0.6500 | 0.6500 | 0.3200 | 0.3000 | 0.6500 | 0.6500 | 0.3500 | 0.3500 | 0.3500 | 0.6500 |
| Random Forest | 0.6837 | 0.6800 | 0.6800 | 0.6800 | 0.3700 | 0.3700 | 0.6800 | 0.6800 | 0.3200 | 0.3200 | 0.3200 | 0.6800 |
| Max Voting | 0.7047 | 0.7000 | 0.7000 | 0.7000 | 0.4100 | 0.4100 | 0.7000 | 0.7000 | 0.3000 | 0.3000 | 0.3000 | 0.7000 |
| Models | Accuracy | Precision | Recall | Specificity | MCC | KAPPA | F1 Score | AUC | FDR | FNR | FPR | NVP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Decision Trees | 0.8298 | 0.8383 | 0.8383 | 0.8383 | 0.1000 | 0.1000 | 0.8300 | 0.5400 | 0.1700 | 0.1700 | 0.1700 | 0.8300 |
| K-Nearest Neighbor | 0.8769 | 0.8800 | 0.8800 | 0.8800 | 0.0000 | 0.0000 | 0.8800 | 0.5000 | 0.1200 | 0.1200 | 0.1200 | 0.8800 |
| Logistic regression | 0.8769 | 0.8800 | 0.8800 | 0.8800 | 0.0000 | 0.0000 | 0.8800 | 0.5000 | 0.1200 | 0.1200 | 0.1200 | 0.8800 |
| Gaussian Naïve Bayes | 0.7981 | 0.8000 | 0.8000 | 0.8000 | 0.0100 | 0.0100 | 0.8000 | 0.5100 | 0.2000 | 0.2000 | 0.2000 | 0.8000 |
| Neural Network | 0.8731 | 0.8700 | 0.8700 | 0.8700 | 0.1100 | 0.0700 | 0.8700 | 0.5200 | 0.1300 | 0.1300 | 0.1300 | 0.8700 |
| Quadratic Discriminant Analysis | 0.1298 | 0.1300 | 0.1300 | 0.1300 | 0.0300 | 0.0000 | 0.1300 | 0.5000 | 0.8700 | 0.8700 | 0.8700 | 0.1300 |
| SVM | 0.8769 | 0.8800 | 0.8800 | 0.8800 | 0.0000 | 0.0000 | 0.8800 | 0.5000 | 0.1200 | 0.1200 | 0.1200 | 0.8800 |
| AdaBoost | 0.8654 | 0.8700 | 0.8700 | 0.8700 | 0.1800 | 0.1600 | 0.8700 | 0.5600 | 0.1300 | 0.1300 | 0.1300 | 0.8700 |
| Gradient Boosting | 0.8769 | 0.8800 | 0.8800 | 0.8800 | 0.1100 | 0.0600 | 0.8800 | 0.5200 | 0.1200 | 0.1200 | 0.1200 | 0.8800 |
| Random Forest | 0.8779 | 0.8800 | 0.8800 | 0.8800 | 0.0800 | 0.0100 | 0.8800 | 0.5000 | 0.1200 | 0.1200 | 0.1200 | 0.8800 |
| Max Voting | 0.8769 | 0.8800 | 0.8800 | 0.8800 | 0.0000 | 0.0000 | 0.8800 | 0.5000 | 0.1200 | 0.1200 | 0.1200 | 0.8800 |
| Model | Accuracy | Precision | Recall | Specificity | MCC | KAPPA | F1 Score | AUC | FDR | FNR | FPR | NVP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Decision Trees | 0.9234 | 0.9200 | 0.9200 | 0.9200 | 0.7600 | 0.7600 | 0.9200 | 0.8800 | 0.0800 | 0.0800 | 0.0800 | 0.9200 |
| K-Nearest Neighbor | 0.9051 | 0.9100 | 0.9100 | 0.9100 | 0.7000 | 0.7000 | 0.9100 | 0.8400 | 0.0900 | 0.0900 | 0.0900 | 0.9100 |
| Logistic regression | 0.8896 | 0.8900 | 0.8900 | 0.8900 | 0.6300 | 0.6000 | 0.8900 | 0.7600 | 0.1100 | 0.1100 | 0.1100 | 0.8900 |
| Gaussian Naïve Bayes | 0.8070 | 0.8100 | 0.8100 | 0.8100 | 0.6000 | 0.5500 | 0.8100 | 0.8600 | 0.1900 | 0.1900 | 0.1900 | 0.8100 |
| Neural Network | 0.9186 | 0.9200 | 0.9200 | 0.9200 | 0.7600 | 0.7500 | 0.9200 | 0.8800 | 0.0800 | 0.0800 | 0.0800 | 0.9200 |
| Quadratic Discriminant Analysis | 0.8528 | 0.8500 | 0.8500 | 0.8500 | 0.6700 | 0.6400 | 0.8500 | 0.8900 | 0.1500 | 0.1500 | 0.1500 | 0.8500 |
| SVM | 0.9243 | 0.9200 | 0.9200 | 0.9200 | 0.7600 | 0.7600 | 0.9200 | 0.8700 | 0.0800 | 0.0800 | 0.0800 | 0.9200 |
| AdaBoost | 0.8238 | 0.8200 | 0.8200 | 0.8200 | 0.3500 | 0.3200 | 0.8200 | 0.6300 | 0.1800 | 0.1800 | 0.1800 | 0.8200 |
| Gradient Boosting | 0.8266 | 0.8300 | 0.8300 | 0.8300 | 0.3500 | 0.2300 | 0.8300 | 0.5800 | 0.1700 | 0.1700 | 0.1700 | 0.8300 |
| Random Forest | 0.9258 | 0.9300 | 0.9300 | 0.9300 | 0.7700 | 0.7700 | 0.9300 | 0.8800 | 0.0700 | 0.0700 | 0.0700 | 0.9300 |
| Max Voting | 0.9254 | 0.9300 | 0.9300 | 0.9300 | 0.7700 | 0.7700 | 0.9300 | 0.8700 | 0.0700 | 0.0700 | 0.0700 | 0.9300 |
| Model | Accuracy | Precision | Recall | Specificity | MCC | KAPPA | F1 Score | AUC | FDR | FNR | FPR | NVP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Decision Trees | 0.7797 | 0.7800 | 0.7800 | 0.7800 | 0.5600 | 0.5600 | 0.7800 | 0.7800 | 0.2200 | 0.2200 | 0.2200 | 0.7800 |
| K-Nearest Neighbor | 0.5577 | 0.5600 | 0.5600 | 0.5600 | 0.2100 | 0.1000 | 0.5600 | 0.5500 | 0.4400 | 0.4400 | 0.4400 | 0.5600 |
| Logistic regression | 0.8383 | 0.8400 | 0.8400 | 0.8400 | 0.6800 | 0.6800 | 0.8400 | 0.8400 | 0.1600 | 0.1600 | 0.1600 | 0.8400 |
| Gaussian Naïve Bayes | 0.6517 | 0.6500 | 0.6500 | 0.6500 | 0.3100 | 0.3100 | 0.6500 | 0.6500 | 0.3500 | 0.3500 | 0.3500 | 0.6500 |
| Neural Network | 0.8083 | 0.8100 | 0.8100 | 0.8100 | 0.6200 | 0.6200 | 0.8100 | 0.8100 | 0.1900 | 0.1900 | 0.1900 | 0.8100 |
| Quadratic Discriminant Analysis | 0.5287 | 0.5300 | 0.5300 | 0.5300 | 0.0900 | 0.0700 | 0.5300 | 0.5400 | 0.4700 | 0.4700 | 0.4700 | 0.5300 |
| SVM | 0.8383 | 0.8400 | 0.8400 | 0.8400 | 0.6800 | 0.6800 | 0.8400 | 0.8400 | 0.1600 | 0.1600 | 0.1600 | 0.8400 |
| AdaBoost | 0.7980 | 0.8000 | 0.8000 | 0.8000 | 0.6100 | 0.5900 | 0.8000 | 0.8000 | 0.2000 | 0.2000 | 0.2000 | 0.8000 |
| Gradient Boosting | 0.8010 | 0.8000 | 0.8000 | 0.8000 | 0.6200 | 0.6000 | 0.8000 | 0.8000 | 0.2000 | 0.2000 | 0.2000 | 0.8000 |
| Random Forest | 0.8210 | 0.8200 | 0.8200 | 0.8200 | 0.6500 | 0.6400 | 0.8200 | 0.8200 | 0.1800 | 0.1800 | 0.1800 | 0.8200 |
| Max Voting | 0.8280 | 0.8300 | 0.8300 | 0.8300 | 0.6600 | 0.6500 | 0.8300 | 0.8300 | 0.1700 | 0.1700 | 0.1700 | 0.8300 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azeez, N.A.; Fadhal, E. Classification of Virtual Harassment on Social Networks Using Ensemble Learning Techniques. Appl. Sci. 2023, 13, 4570. https://doi.org/10.3390/app13074570
Azeez NA, Fadhal E. Classification of Virtual Harassment on Social Networks Using Ensemble Learning Techniques. Applied Sciences. 2023; 13(7):4570. https://doi.org/10.3390/app13074570
Chicago/Turabian StyleAzeez, Nureni Ayofe, and Emad Fadhal. 2023. "Classification of Virtual Harassment on Social Networks Using Ensemble Learning Techniques" Applied Sciences 13, no. 7: 4570. https://doi.org/10.3390/app13074570
APA StyleAzeez, N. A., & Fadhal, E. (2023). Classification of Virtual Harassment on Social Networks Using Ensemble Learning Techniques. Applied Sciences, 13(7), 4570. https://doi.org/10.3390/app13074570