
UAV Cluster-Assisted Task Offloading for Emergent Disaster Scenarios


Abstract
:1. Introduction
- This paper proposes a UAV cluster-assisted task-offloading model in the disaster scenario. To ensure that the communications of ground users in the disaster area are repaired promptly, we adopt an aerial mobile edge server composed of UAV clusters to provide assisted communications and computational offloading services for ground users. The ground users first offload the computational tasks to the UAVs with free resources, and then the UAVs forward the task data within the cluster to collaboratively complete the tasks. The model significantly reduces the transmission energy consumption between ground users and traditional edge servers and overcomes the problem of the limited computing power of UAVs.
- This paper proposes a deep reinforcement learning-based UAV cluster-assisted task-offloading algorithm (DRL-UCTO) for jointly optimizing UAV flight trajectory and ground user task-offloading policy, taking full advantage of the high mobility and flexible communication of UAVs. This paper simplifies the deep reinforcement learning state transfer model through the Markov decision process to make the modeling process feasible, and optimizes the UAV flight trajectory through deep reinforcement learning, so that the DRL-UCTO algorithm quickly locates the location of ground users and makes optimal task offloading and forwarding decisions. The problem of limited resources in the disaster area is solved by maximizing the energy efficiency of the system while guaranteeing the quality of service for users.
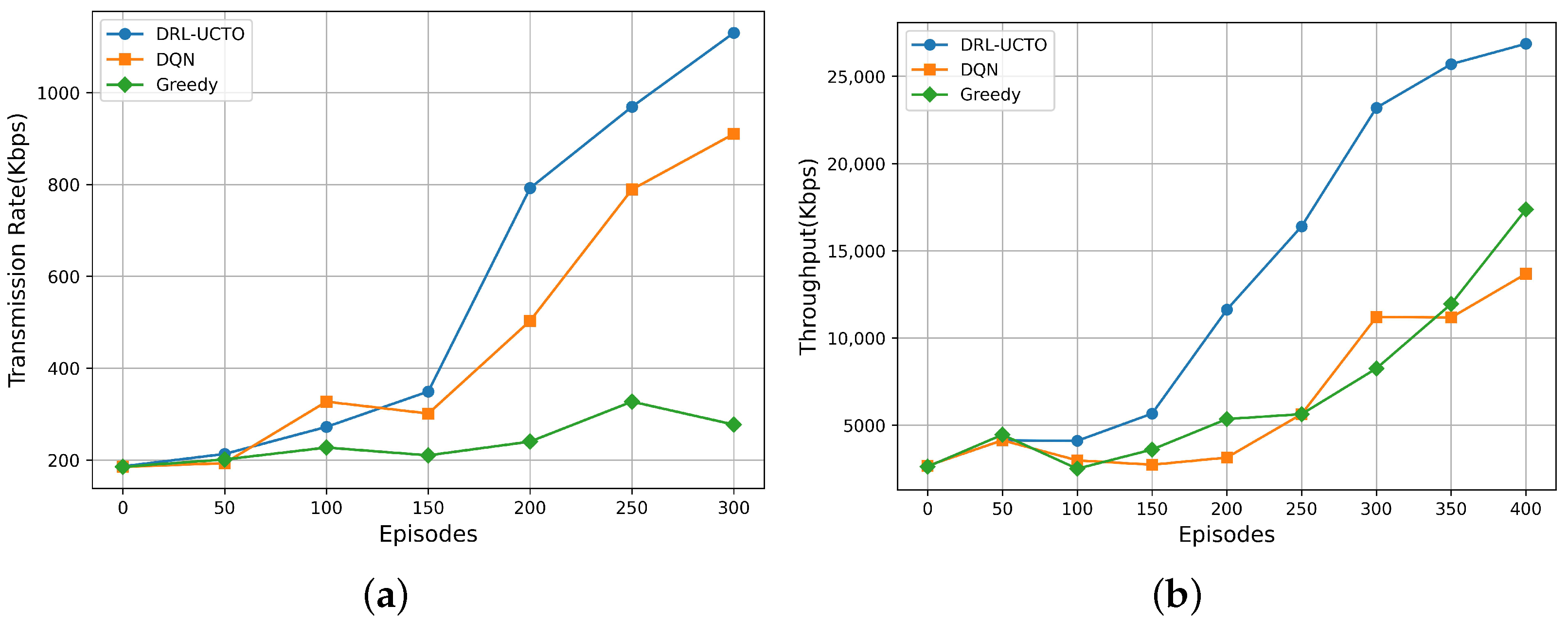
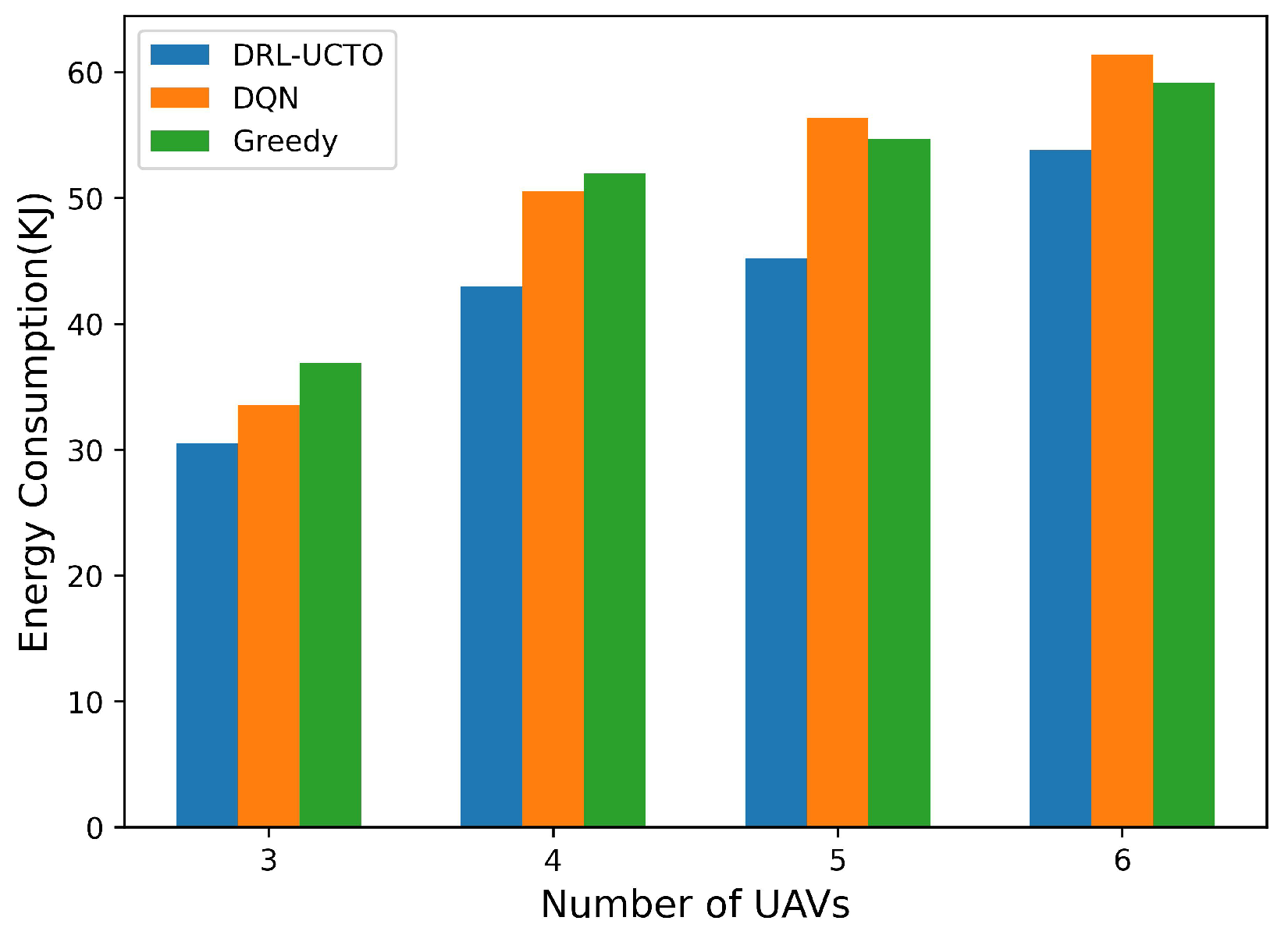
- In this paper, we verify the feasibility and effectiveness of the DRL-UCTO algorithm through extensive simulation experiments. Because of the stable action selection policy of the DRL-UCTO algorithm, the flight energy overhead of the UAV cluster during the search for ground users is reduced. The numerical results show that compared with other baseline algorithms, the DRL-UCTO algorithm significantly improves system transmission rate and throughput, and further increases system energy efficiency.
2. Related Work
3. System Model
3.1. UAV Mobile Model
3.2. Computational Process Model
3.3. Optimization Problem Definition
4. Deep Reinforcement Learning-Based UAV Cluster-Assisted Task Offloading Solution
4.1. Markov Decision Process
- denotes the state space, and each state is a multi-dimensional vector containing multiple parameters that represent the current state of the ground user and the UAV, including their current location and resource information, as well as the amount of task data and the task deadline for the ground user. Overall, the state of each time slice is defined as:
- denotes the action space, which contains all feasible actions that the UAV can take. The main points are the flight direction and distance of the UAV, the task offloading of the ground user, the UAV task forwarding, and the proportion of data offloaded and forwarded. Therefore, the action for each time slice can be defined as follows:where denotes the UAV horizontal displacement vector, which is used to control the UAV flight direction or hovering. Thus, the UAV position for the next time slice can be expressed as .
- denotes the effect of the policy adopted by the current UAV on the reward returns at future moments, where .
- denotes the reward set, which consists of the reward returns for the actions performed by the UAV in the current environmental state. The reward function at a certain moment mainly indicates the energy efficiency of the system and gives a certain penalty when the UAV flies out of the service area. Thus, the reward function at moment t is defined as follows:
4.2. Deep Reinforcement Learning-Based UAV Cluster-Assisted Task-Offloading Algorithm (DRL-UCTO) Idea
4.3. DRL-UCTO Algorithm Implementation
| Algorithm 1 Deep Reinforcement Learning-Based UAV Cluster-Assisted Task-Offloading Algorithm (DRL-UCTO). |
| 1: Initialize the replay buffer D; |
| 2: Randomly initialize main network Q and target network with weights and , and set ; |
| 3: for episode do |
| 4: Initialize the environment to state s(1); |
| 5: for do |
| 6: Select action based on policy ; |
| 7: Execute obtain and ; |
| 8: for do |
| 9: if UAV u flies out of service scope then |
| 10: Apply the penalty to ; |
| 11: Cancel the movement of UAV u and update ; |
| 12; end if |
| 13: end for |
| 14: Store training sample in D; |
| 15: end for |
| 16: Select a random mini-batch of training samples of size n from D; |
| 17: ; |
| 18: ; |
| 19: Update weights of : ; |
| 20: end for |
5. Performance Evaluation and Analysis
5.1. Experimental Environment Settings
5.2. Result Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, Y.J.; Chen, Q.Z.; Ling, H.F.; Xue, J.Y. Rescue wings: Mobile computing and active services support for disaster rescue. IEEE Trans. Serv. Comput. 2015, 9, 594–607. [Google Scholar] [CrossRef]
- Erdelj, M.; Król, M.; Natalizio, E. Wireless sensor networks and multi-UAV systems for natural disaster management. Comput. Netw. 2017, 124, 72–86. [Google Scholar] [CrossRef]
- Alzenad, M.; El-Keyi, A.; Lagum, F.; Yanikomeroglu, H. 3-D placement of an unmanned aerial vehicle base station (UAV-BS) for energy-efficient maximal coverage. IEEE Wirel. Commun. Lett. 2017, 6, 434–437. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Zhang, H.; He, Q.; Bian, K.; Song, L. Joint trajectory and power optimization for UAV relay networks. IEEE Commun. Lett. 2017, 22, 161–164. [Google Scholar] [CrossRef]
- Fu, H.; Hu, P.; Zheng, Z.; Das, A.K.; Pathak, P.H.; Gu, T.; Zhu, S.; Mohapatra, P. Towards automatic detection of nonfunctional sensitive transmissions in mobile applications. IEEE. Trans. Mob. Comput. 2020, 20, 3066–3080. [Google Scholar] [CrossRef]
- Zhu, J.; Zhao, H.; Wei, Y.; Ma, C.; Lv, Q. Unmanned aerial vehicle computation task scheduling based on parking resources in post-disaster rescue. Appl. Sci. 2023, 13, 289. [Google Scholar] [CrossRef]
- Bai, T.; Wang, J.; Ren, Y.; Hanzo, L. Energy-efficient computation offloading for secure UAV-edge-computing systems. IEEE Trans. Veh. Technol. 2019, 68, 6074–6087. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Jin, R.; Dai, H. Multi-hop task offloading with on-the-fly computation for multi-UAV remote edge computing. IEEE Trans. Commun. 2021, 70, 1332–1344. [Google Scholar] [CrossRef]
- Qin, Y.; Kishk, M.A.; Alouini, M.S. Performance evaluation of UAV-enabled cellular networks with battery-limited drones. IEEE Commun. Lett. 2020, 24, 2664–2668. [Google Scholar] [CrossRef]
- Zhang, X.; Duan, L. Optimal patrolling trajectory design for multi-uav wireless servicing and battery swapping. In 2019 IEEE Globecom Workshops, Proceedings of the IEEE Communications Society’s Flagship Global Communications Conference, Waikoloa, HI, USA, 9–13 December 2019; IEEE: Piscataway, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Abeywickrama, H.V.; Jayawickrama, B.A.; He, Y.; Dutkiewicz, E. Comprehensive energy consumption model for unmanned aerial vehicles, based on empirical studies of battery performance. IEEE Access 2018, 6, 58383–58394. [Google Scholar] [CrossRef]
- Mir, T.; Waqas, M.; Tu, S.; Fang, C.; Ni, W.; MacKenzie, R.; Xue, X.; Han, Z. Relay hybrid precoding in uav-assisted wideband millimeter-wave massive mimo system. IEEE Trans. Wirel. Commun. 2022, 21, 7040–7054. [Google Scholar] [CrossRef]
- Zou, Y.; Yu, D.; Hu, P.; Yu, J.; Cheng, X.; Mohapatra, P. Jamming-Resilient Message Dissemination in Wireless Networks. IEEE. Trans. Mob. Comput. 2021, 22, 1536–1550. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, Y.; Loo, J.; Yang, D.; Xiao, L. Joint computation and communication design for UAV-assisted mobile edge computing in IoT. IEEE Trans. Ind. Inform. 2019, 16, 5505–5516. [Google Scholar] [CrossRef] [Green Version]
- Sacco, A.; Esposito, F.; Marchetto, G.; Montuschi, P. Sustainable task offloading in UAV networks via multi-agent reinforcement learning. IEEE Trans. Veh. Technol. 2021, 70, 5003–5015. [Google Scholar] [CrossRef]
- Chen, W.; Liu, B.; Huang, H.; Guo, S.; Zheng, Z. When UAV swarm meets edge-cloud computing: The QoS perspective. IEEE Netw. 2019, 33, 36–43. [Google Scholar] [CrossRef]
- Yin, R.; Li, W.; Wang, Z.Q.; Xu, X.X. The application of artificial intelligence technology in UAV. In Proceedings of the 2020 5th International Conference on Information Science, Computer Technology and Transportation (ISCTT), Shenyang, China, 13–15 November 2020; pp. 238–241. [Google Scholar]
- Li, P.J.; Mao, P.J.; Geng, Q.; Huang, C.P.; Fang, Q.; Zhang, J.R. Research status and trend of UAV swarm technology. Aero Weaponry 2020, 27, 25–32. [Google Scholar]
- Ahmed, S.; Chowdhury, M.Z.; Sabuj, S.R.; Alam, M.I.; Jang, Y.M. Energy-efficient UAV relaying robust resource allocation in uncertain adversarial networks. IEEE Access 2021, 9, 59920–59934. [Google Scholar] [CrossRef]
- Jiang, X.; Wu, Z.; Yin, Z.; Yang, Z. Power and trajectory optimization for UAV-enabled amplify-and-forward relay networks. IEEE Access 2018, 6, 48688–48696. [Google Scholar] [CrossRef]
- Pathak, P.H.; Feng, X.; Hu, P.; Mohapatra, P. Visible light communication, networking, and sensing: A survey, potential and challenges. IEEE Commun. Surv. Tutor. 2015, 17, 2047–2077. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, R.; Liu, Q.; Thompson, J.S.; Kadoch, M. Energy-efficient data collection and device positioning in UAV-assisted IoT. IEEE Internet Things J. 2019, 7, 1122–1139. [Google Scholar] [CrossRef]
- Huang, X.; Yang, X.; Chen, Q.; Zhang, J. Task offloading optimization for UAV-assisted fog-enabled Internet of Things networks. IEEE Internet Things J. 2021, 9, 1082–1094. [Google Scholar] [CrossRef]
- Zhu, S.; Gui, L.; Cheng, N.; Sun, F.; Zhang, Q. Joint design of access point selection and path planning for UAV-assisted cellular networks. IEEE Internet Things J. 2019, 7, 220–233. [Google Scholar] [CrossRef]
- Yuan, Z.; Jin, J.; Sun, L.; Chin, K.W.; Muntean, G.M. Ultra-reliable IoT communications with UAVs: A swarm use case. IEEE Commun. Mag. 2018, 56, 90–96. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, T.; Wang, S. UAV-assisted emergency communications: An extended multi-armed bandit perspective. IEEE Commun. Lett. 2019, 23, 938–941. [Google Scholar] [CrossRef]
- Lyu, J.; Zeng, Y.; Zhang, R. UAV-aided offloading for cellular hotspot. IEEE Trans. Wirel. Commun. 2018, 17, 3988–4001. [Google Scholar] [CrossRef] [Green Version]
- Özdamar, L.; Demir, O. A hierarchical clustering and routing procedure for large scale disaster relief logistics planning. Transp. Res. Pt. e-Logist. Transp. Rev. 2012, 48, 591–602. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Localization and clustering based on swarm intelligence in UAV networks for emergency communications. IEEE Internet Things J. 2019, 6, 8958–8976. [Google Scholar] [CrossRef]
- Masood, A.; Scazzoli, D.; Sharma, N.; Le Moullec, Y.; Ahmad, R.; Reggiani, L.; Magarini, M.; Alam, M.M. Surveying pervasive public safety communication technologies in the context of terrorist attacks. Phys. Commun. 2020, 41, 101109. [Google Scholar] [CrossRef]
- Yang, J.; Huang, X. A distributed algorithm for UAV cluster task assignment based on sensor network and mobile information. Appl. Sci. 2023, 13, 3705. [Google Scholar] [CrossRef]
- Minhas, H.I.; Ahmad, R.; Ahmed, W.; Alam, M.M.; Magarani, M. On the impact of clustering for Energy critical Public Safety Networks. In Proceedings of the 2019 International Symposium on Recent Advances in Electrical Engineering (RAEE), Islamabad, Pakistan, 28–29 August 2019; pp. 1–5. [Google Scholar]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef] [Green Version]
- Abuqaddom, I.; Mahafzah, B.; Faris, H. Oriented stochastic loss descent algorithm to train very deep multi-layer neural networks without vanishing gradients. Knowl.-Based Syst. 2021, 230, 107391. [Google Scholar] [CrossRef]
- Jeong, S.; Simeone, O.; Kang, J. Mobile edge computing via a UAV-mounted cloudlet: Optimization of bit allocation and path planning. IEEE Trans. Veh. Technol. 2017, 67, 2049–2063. [Google Scholar] [CrossRef] [Green Version]
- Du, Y.; Yang, K.; Wang, K.; Zhang, G.; Zhao, Y.; Chen, D. Joint resources and workflow scheduling in UAV-enabled wirelessly-powered MEC for IoT systems. IEEE Trans. Veh. Technol. 2019, 68, 10187–10200. [Google Scholar] [CrossRef]
- Yu, Z.; Gong, Y.; Gong, S.; Guo, Y. Joint task offloading and resource allocation in UAV-enabled mobile edge computing. IEEE Internet Things J. 2020, 7, 3147–3159. [Google Scholar] [CrossRef]
- Tu, S.; Waqas, M.; Rehman, S.U.; Mir, T.; Abbas, G.; Abbas, Z.H.; Halim, Z.; Ahmad, I. Reinforcement learning assisted impersonation attack detection in device-to-device communications. IEEE Trans. Veh. Technol. 2021, 70, 1474–1479. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| G | Number of ground users |
| U | Number of UAVs |
| T | Number of time slices |
| The length of time slice | |
| The coordinates of ground user g | |
| h | The UAV flight height |
| The projected coordinates of UAV u | |
| The horizontal flight speed of UAV u | |
| The propulsion energy consumption of UAV u | |
| The mass and load of UAV | |
| The computational task of ground user g | |
| The amount of task data for user g | |
| The task deadline of user g | |
| Number of CPU cycles per bit of data to be executed for the task of user g | |
| The proportion of task offloads for ground users g | |
| The proportion of ground user g tasks forwarded via UAVs | |
| The local computation delay of ground user g | |
| Number of CPU cycles per second that can be processed by ground user g | |
| The local computing energy consumption of ground user g | |
| The effective switching capacitance | |
| The channel gain between UAV u and ground user g | |
| The average path gain at a reference distance of 1 meter | |
| P | The transmit power |
| The communication rate between UAV u and ground user g | |
| B | The available bandwidth |
| The thermal noise power | |
| The channel gain between UAV and UAV u | |
| The communication rate between UAV and UAV u | |
| The task offload state of ground user g | |
| The state of ground user g forwarding tasks via UAV | |
| The transmission delay of UAV-assisted task offloading | |
| The computational delay of UAV-assisted task offloading | |
| The computational resources obtained by ground user g from UAV u | |
| The computational resources obtained by UAV u from UAV | |
| The total delay of UAV-assisted task offloading | |
| The total energy consumption of UAV-assisted task offloading | |
| The total task processing delay of ground user g | |
| The total task processing energy consumption of ground user g | |
| The minimum safe distance between UAVs | |
| The maximum flight speed of UAVs |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 9.65 kg | B | 2 MHz | |
| 1 GHz | P | 0.1 W | |
| 8 GHz | −110 dBm | ||
| 1000∼2000 | D | 10,000 | |
| n | 128 | ||
| 1∼3 Mbit | |||
| −30 dB | 10∼20 s |
| Algorithm | Complexity | Average Energy Consumption (KJ) |
|---|---|---|
| DRL-UCTO | 76.68 | |
| DQN | 85.51 | |
| Q-learning | 89.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, M.; Zhang, X.; Chen, J.; Cheng, H. UAV Cluster-Assisted Task Offloading for Emergent Disaster Scenarios. Appl. Sci. 2023, 13, 4724. https://doi.org/10.3390/app13084724
Shi M, Zhang X, Chen J, Cheng H. UAV Cluster-Assisted Task Offloading for Emergent Disaster Scenarios. Applied Sciences. 2023; 13(8):4724. https://doi.org/10.3390/app13084724
Chicago/Turabian StyleShi, Minglin, Xiaoqi Zhang, Jia Chen, and Hongju Cheng. 2023. "UAV Cluster-Assisted Task Offloading for Emergent Disaster Scenarios" Applied Sciences 13, no. 8: 4724. https://doi.org/10.3390/app13084724
APA StyleShi, M., Zhang, X., Chen, J., & Cheng, H. (2023). UAV Cluster-Assisted Task Offloading for Emergent Disaster Scenarios. Applied Sciences, 13(8), 4724. https://doi.org/10.3390/app13084724