1. Introduction
With the continuous development of urbanization, the number of vehicles has increased gradually, and the traffic safety situation is still grim. Several studies showed that an abnormal driving behavior of drivers is the main factor that causes traffic accidents [
1,
2]. Therefore, the correct identification and timely pre-warning of abnormal driving behaviors can effectively remind drivers to correct their driving behavior, which is of great significance for reducing road traffic accidents. By analyzing traffic accident data in the CIDAS database, Hu et al. [
3] concluded that drivers with dangerous driving behaviors were closely related to accidents and constructed an evaluation system to describe this relationship. Guo et al. [
4] established a traffic collision risk prediction model for highways after analyzing the relationship of between dangerous driving behaviors and traffic accidents. Ucar et al. [
5] established an abnormal driving behavior management system and adopted mitigation strategies to improve the safety of all test vehicles by about 10 times based on the actual traffic data in Virginia.
As a measure of a driver’s various operational performances during driving, driving behavior is affected by many aspects. Singh et al. [
6] reviewed natural driving research and data collecting methods, discussed various factors that influence the driving behavior, and found that the driving behavior was the main cause of most road accidents. Song et al. [
7] used the SHRP2 large-scale questionnaire to study the relationship between demographic characteristics, sensation seeking, risk perception, and dangerous driving behavior, finding that lower levels of sensation seeking and higher levels of risk perception can serve to inhibit dangerous driving behaviors. Linkov et al. [
8] studied the relation of personality variables and driving behavior safety and concluded that the driver’s personality with a high sense of seeking and a low sense of responsibility is closely related to a higher mean speed and a higher risk behavior during driving.
Currently, there are three methods for studying the driving behavior: questionnaire surveys, driving simulations, and algorithmic models. Among them, questionnaire surveys require a large amount of manpower, and the cost of driving simulations is high. It is most suitable to use an algorithm model for the evaluation of the driving behavior. Chandra et al. [
9] used the centrality function C-Measurement to classify drivers’ behavior; they proposed a formula to quantify the driving behavior and divided it into four categories by combining the graph theory and social psychology. Wang et al. [
10] proposed a new pattern recognition algorithm for unsupervised driving behavior data to discover the common driving behavior patterns for each cluster. Van et al. [
11] collected data for different driving behaviors through a driving simulator, including maximum speed, lateral position, and distance from the preceding car, and compared the objective data retrieved by the driving simulator with the resulting scores of a questionnaire. The results showed that people may have a different understanding of the safety level of driving behaviors. The measurement of driving behavior risks is also a popular research field. However, the majority of data utilized in driving behavior risk measurement is derived from videos and simulation experiments. The length of road sections captured by video is limited, and simulation experiments struggle to provide accurate driving behavior trajectory data. In recent years, with the acquisition of a vast quantity of natural driving trajectory data, it has become possible to conduct in-depth research on vehicle driving behavior. Jiang et al. [
12] proposed a new improved traffic conflict indicator, based on trajectory data collected using unmanned aerial vehicles (UAVs), that builds upon the strengths of conventional indicators and addresses their limitations. These indicators require the definitions and calculations for three types of traffic conflicts (rear-end, lane change, and with fixed objects) that accurately reflect real traffic risks. Park et al. [
13] designed accurate algorithms to extract vehicle trajectory data from video data collected by UAVs and then proposed a lane-changing risk factor. This risk factor can provide a safety evaluation for the target vehicle and adjacent vehicles during lane change. Yang et al. [
14] proposed a real-time driving behavior safety level classification and evaluation framework based on driving behavior data and divided the driving behavior into normal driving, low-risk driving, and high-risk driving by using the k-means clustering method, the hierarchical clustering method, and the model-based clustering method, respectively. Based on the analysis of a large number of trajectory data, Matousek et al. [
15] proposed an abnormal driving pattern detection method based on outlier detection to detect the driving behavior of drivers. This method does not require specific data for normal driving behaviors and various abnormal driving behaviors and is very reliable in detecting abnormal vehicle-driving behaviors. In terms of risk measurement for driving behavior, the extant research primarily concentrates on evaluating traffic conflicts and predicting the likelihood of traffic collisions, while lacking a comprehensive risk assessment of various driving operations performed by drivers. Concurrently, the existing research on driver classification focuses on considering a driver’s overall driving style and lacks an evaluation of the driver’s driving behavior risk at each moment.
Furthermore, research on driving behavior could be applied in many frontier research fields, such as autonomous driving and ecological driving, in the future. Collin [
16] used the autonomous driving rule manual to analyze the safety of driving behavior, formulated the driving behavior of driverless vehicles through the precise definition of rules, and made good use of trajectory violation indicators to help identify specific unsafe scenes. Xiang et al. [
17] proposed a hybrid model composed of the cloud model and the Elman neural network to predict dangerous driving behaviors based on vehicle motion state estimation and passenger subjective evaluation, which could provide a practical solution for safe driving. Based on research into the rules governing the association between driving behavior and accident risk, the individual driving behavior can be quantitatively evaluated and utilized as an index for assessing the accident risk. The research findings related to the driving behavior can be applied to driver training, enhancing driving safety, developing driver behavior recommendation systems, or formulating personalized insurance for vehicles, and hold significant value.
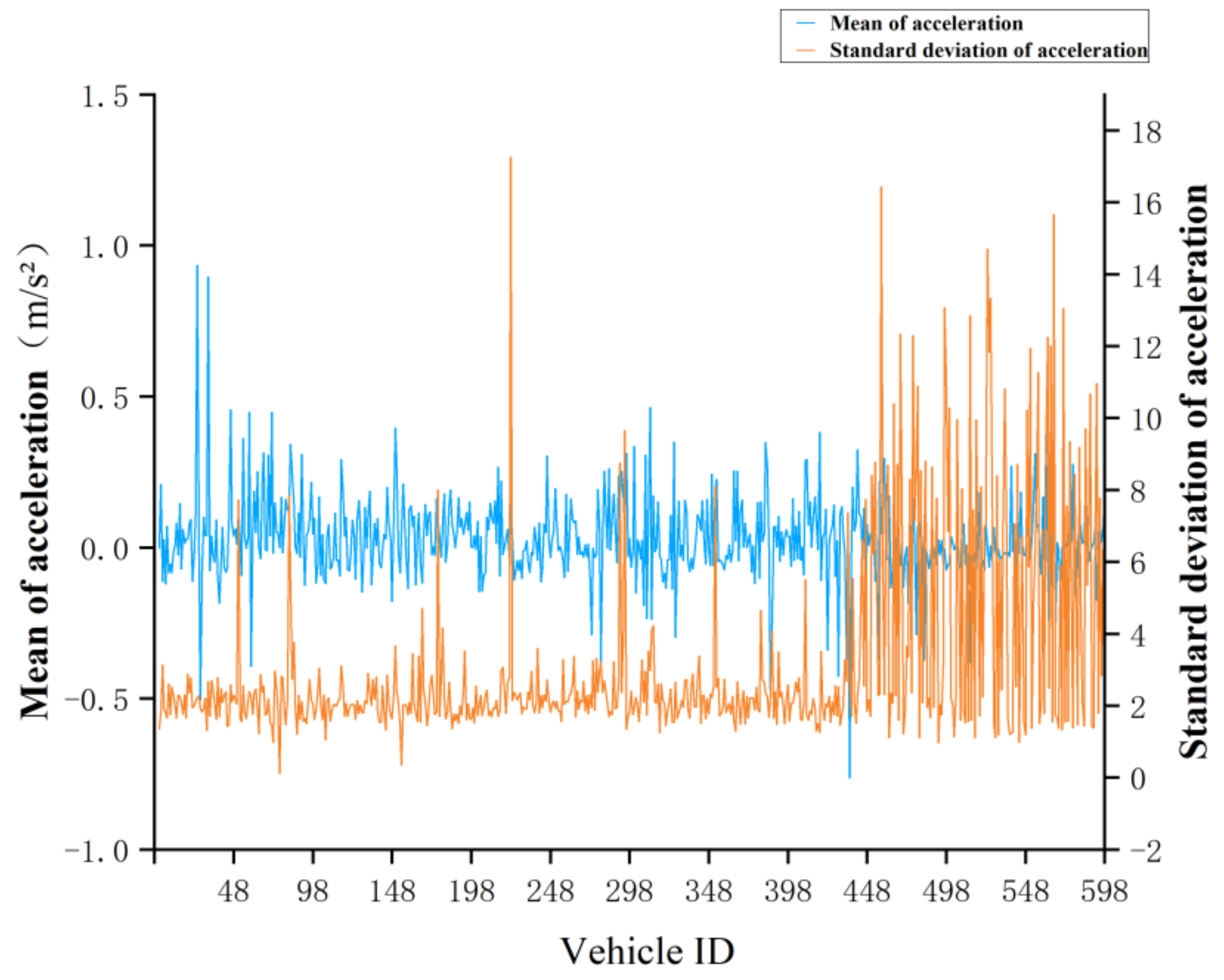
In summary, the extant research on driving behavior risk measurement is not comprehensive and lacks a well-suited model for the real-time evaluation of driving behavior risks. The primary contributions of this study are as follows: (a) we utilized the NGSIM vehicle trajectory dataset as the data source for our research and employed a more accurate method to extract the required trajectory data; (b) we comprehensively measured the driving behavior risk from three perspectives: driving, car-following, and lane-changing. The parameters used in the established index model are easily collectible; (c) we constructed a risk measurement model for driving behavior and clustered the driving behavior risk into four categories. This model can assess the risk status at each moment during the driving process of a vehicle in real-time. The research results can be used for monitoring and warning against hazardous driving behaviors, driver training, and the creation of driver behavior recommendation systems.
This paper is organized as follows:
Section 2 introduces the driving behavior risk indicators established in this study and the methods used;
Section 3 conducts a case analysis through the NGSIM data set, establishes a driving behavior risk measurement model, divides the driving behavior risk categories through cluster analysis, and at the same time, tests the driving behavior risk measurement model;
Section 4 provides a summary of this work.
4. Conclusions
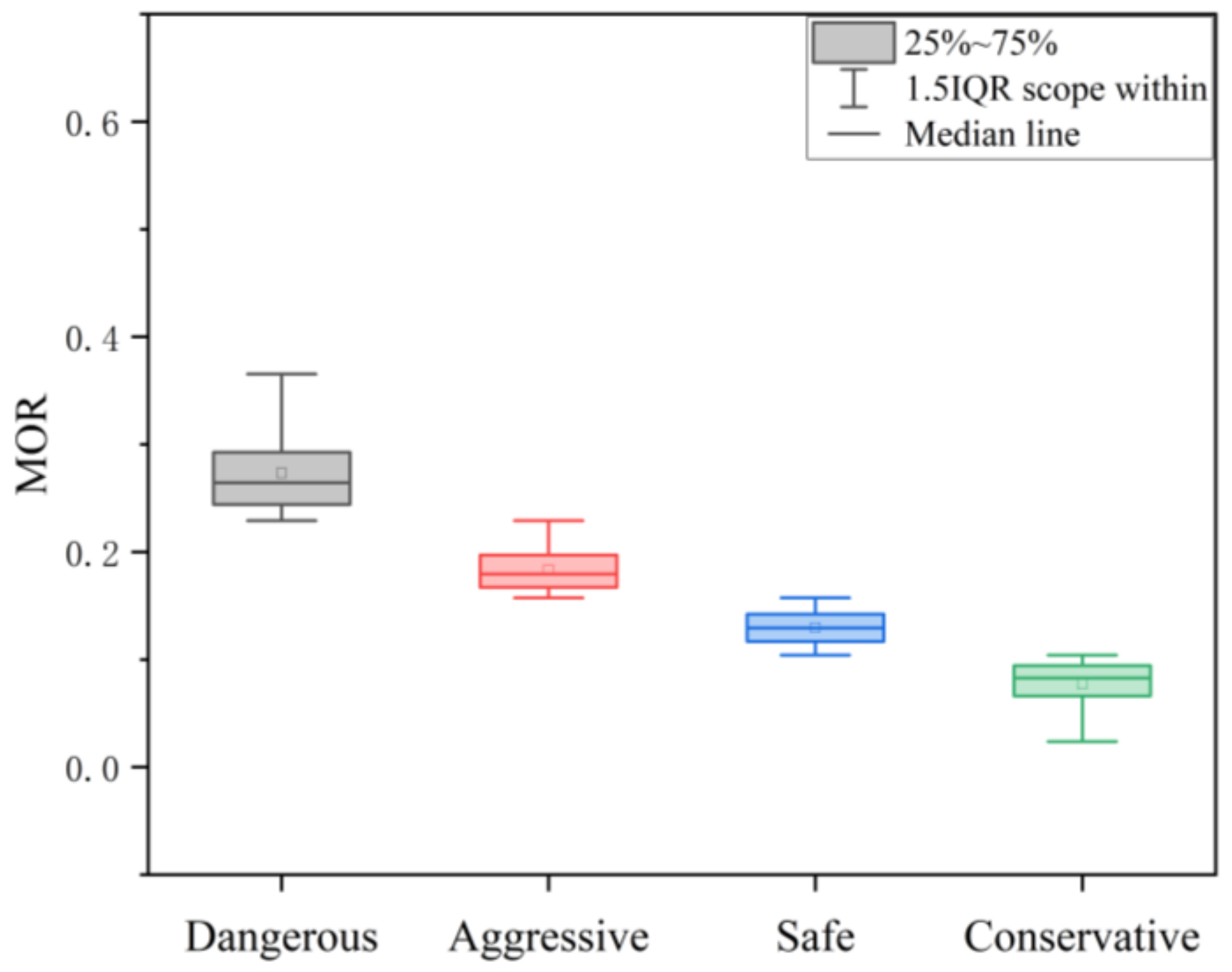
After analyzing the driving characteristics of vehicles, this research defined four indicators for driving behavior risk measurement and established a driving behavior risk measurement method based on the analysis of the driving trajectory data of a large number of vehicles. Then, the driving behaviors were clustered into four types, namely, dangerous, aggressive, safe, and conservative, based on the results of the driving behavior risk measurement.
Four evaluation indicators can accurately measure the risk of driving behavior on the basis of the lateral and longitudinal directions. The driving stability indicator includes the lateral stability indicator and the longitudinal stability indicator. It is used to measure if a vehicle performs serpentine driving and has an unstable speed. The car-following risk indicator that is expressed by the reciprocal of the collision time (TTC), is used to describe the car-following behavior risk. The lane-changing risk indicator considers the relationship between the target vehicle and adjacent vehicles (the front vehicles in the same lane, the front and rear vehicles in the target lane during lane changing),and is used to evaluate the safety degree of lane changing through the missing reaction time of the driver. Based on the NGSIM dataset, the vehicle trajectory data were extracted in this study, and the driving behavior risk measurement model was applied and verified by examples. The results showed that the measurement indicators defined in this study are reasonable and can accurately measure the driving behavior risk.
With the development of smart cities and big data, the availability of behavioral data will become widespread. The data source of this study was the NGSIM dataset, and more real-time vehicle trajectory data could be collected in the future. The results of this research can provide a theoretical basis for drivers’ driving behavior recognition based on artificial intelligence algorithms and further improve the accuracy of image recognition. In the follow-up research, we will further improve the sample size, consider the risk measurement for driving behaviors with multiple models, and consider more trajectory variables, such as vehicle performance, road environment, and other influencing factors, to recognize driver driving behavior risks better.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}