1. Introduction
Urban tree cadastres are established and maintained for various reasons, including: The location and species of trees on public land play an increasing role in maintenance planning, especially in light of the expected effects of climate change. In particular, the condition of the trees is important for the municipality to fulfill its road safety obligations. In addition, trees are essential for urban land-use planning, and, last but not least, they are highly relevant for nature conservation.
The digitalization of the urban tree cadastre has brought other benefits in recent decades: the process of data collection and processing can be made easier and more efficient. Better planning, coordination, and transfer of relevant data can be achieved more quickly due to easier accessibility. This also contributes to more transparent communication. Exporting data also enables analysis and automated applications.
However, keeping the tree cadastre up-to-date, complete, and accurate is a major challenge for municipalities, as it is a very large database that changes regularly.
Various (mostly proprietary) applications support municipal staff with intuitive input masks for editing the municipal tree cadastre. However, the challenge remains that the various characteristics of individual trees or groups of trees, such as species, genus, height, and age, have to be created or edited manually. The more attributes a tree cadastre contains, the more time-consuming this becomes, and the more likely it is that incorrect entries will be made due to a lack of time or technical knowledge. Although there are technical tools such as identification applications that can be used for non-trivial characteristics such as height, some characteristics, such as age, can often only be estimated.
For all these reasons, the data quality of urban tree cadastres is often weak, and the data cannot be used without doubt. In addition, in the context of climate change, attributes that have not yet been recorded become relevant. For example, additional information on the site (tree disc or park, soil composition) can be used to better predict potential drought stress. In addition, German municipal tree cadastres often only cover trees located in public or semi-public areas, for which the municipality is responsible. However, private trees are also relevant to air quality and should be included for applications in this area. This is of interest, among other things, for the potential assessment of areas with high allergy potential due to tree pollen as well as the ozone formation potential due to biogenic hydrocarbon emissions [
1].
The aim of this article is to show how AI-supported tree mapping can be employed in a transdisciplinary approach to identify and develop integrated urban climatological and urban planning issues, challenges, and potentials in order to answer the sometimes pressing questions of adaptation to climate change in the field of tension between urban density and green and open space planning.
The initially technical perspective on the part of the development of the corresponding AI creates an explanatory path that provides directional certainty for urban and green space planning and a future perspective. In addition, the spatial planning approach offers the opportunity to introduce further steps towards optimized urban climate adaptation into the scientific and practical planning discourse. This builds a bridge to applied, planning-oriented urban climatology, which is of immense relevance in the aforementioned field of tension.
Preliminary studies have already shown that bioclimatic and air-hygienic factors play an important role in spending time in open spaces and that these differ for different age groups. In addition to its many benefits, green infrastructure can also cause health problems due to so-called biological noxae. One aim must therefore be to use an AI-based tree register to provide a planning basis that is as optimized as possible in terms of local climate, air hygiene, and health [
2].
In order to minimize the time and human resources required for future maintenance of the urban tree cadastre and to integrate other planning and science-relevant features on a large scale, a transdisciplinary approach is being tested in Kaiserslautern (Rhineland-Palatinate, Germany). This approach operates on different databases and involves a wide range of stakeholders.
The starting point is the city’s existing tree cadastre, which is incomplete and contains few attributes but is a good starting point due to its precise GPS locations. A deep learning model can be trained to recognize not-yet-recorded trees in the tree cadastre using aerial imagery. It is planned to train another AI model, using panoramic imagery and LIDAR data from road surveys, to recognize tree genera. The results will be randomly evaluated by experts, creating a feedback loop that will gradually improve the models.
A web application is being developed that will provide a user-friendly interface for researchers and interested citizens to display the available data, edit it, and add more features—more models could be trained on this data. Other attributes, such as tree height, can be automatically extracted from the LIDAR data. As part of the process, different databases will be used as training data, considering legal frameworks, costs, and availability, and statements will be made about the quality of the results. Another objective is to design the AI models to be open and transferable, allowing direct application in regions with similar tree populations. In addition, these models could be used to update the tree cadastre and monitor data quality as new information becomes available.
There are already several initiatives in Germany working to enhance the urban tree cadastre through the use of technological innovations. In the Metropole Ruhr, for example, the location of trees is determined based on similar data and using AI [
3]. As the models are intended to be released as open source, they could be integrated into the approach being pursued in this context. Furthermore, there are already deep learning models for urban tree detection, e.g., Ventura et al. [
4] and Weinstein et al. [
5]. The first one was adapted and will be discussed in more detail in
Section 3.
A successful application of a well-maintained tree register is to engage the public in watering initiatives. In Berlin [
6] and Leipzig [
7], for example, platforms are used to coordinate and track the watering of urban trees. In Magdeburg [
8], information on felled trees is also openly available online.
In the following, we will first introduce the project context and address the role of urban trees in mitigating climate impacts. We then present our approach to improving the urban tree cadastre by using a combination of an adapted deep learning model for accurate tree detection and a citizen science approach. The different data sources that were available and the challenges of using them within our approach are also discussed. The paper concludes with a summary and an outlook.
2. Background and Project Context
The successful implementation of the project requires collaboration among various stakeholder groups, each contributing their expertise. A comprehensive understanding of the environment and climate, urban planning, data processing, web design, and AI is required, and these aspects are addressed by the researchers involved. Public administrations possess knowledge of available data, facilitate its accessibility, and provide practical use cases. Moreover, established communication channels are already in place to connect with citizens and involve them in crowdsourcing activities. On designated action days, interested citizens, supported by researchers, will digitally record tree characteristics over as large an area as possible and validate the results of the AI models.
The research project is part of the joint project “Ageing Smart—Designing Spaces Intelligently” funded by the German Carl Zeiss Foundation. The overall project focuses on baby boomers, those born between 1955 and 1969, whose entry into retirement age poses a challenge for local authorities. They are often faced with the need to create not only age-appropriate residential areas but also appropriate care and leisure structures. The overall aim of the project is to develop a data-based “Decision Support System” (DSS) to assist public administrations in these planning processes. A total of ten subprojects from the departments of Spatial and Environmental Planning, Computer Science and Mathematics at the University of Kaiserslautern-Landau (RPTU), in Kaiserslautern, are working on this topic in an interdisciplinary way. The Fraunhofer Institute for Experimental Software Engineering (IESE) and the German Research Center for Artificial Intelligence (DFKI) GmbH are also involved (see
Figure 1).
The Physical Geography subproject will examine existing local public green spaces to determine whether they can be used equally by all groups of people. Particular attention will be paid to meteorological conditions and local climatic and air-hygienic issues. In the context of the further development of the tree cadastre, the subproject will provide possible use cases and technical expertise. In the further course of the subproject, the methodological approach already presented by Albert et al. in 2022 will be transferred to settlement areas. This requires an (almost) complete digital tree cadastre.
The existing urban vegetation has a large cooling potential. However, it is important to note that all tree species emit varying concentrations of biogenic volatile organic compounds (BVOCs) (e.g., isoprene and terpenes), which can act as precursors for the formation of ground-level ozone. Particularly in urban green spaces, which serve as recreational areas for many people, poorly composed tree populations are contraindicated as they can lead to significant exposure to harmful ozone. The use of such species along roadsides or in urban green spaces should therefore be avoided. Particularly in urban green spaces, it is important to reduce potential BVOC sources to minimize the formation of O3, which can have adverse effects on human health. Near-surface ozone has the ability to react with particulate matter such as soot, polycyclic aromatic hydrocarbons, or pollen proteins to form oxygen-free radicals.
The possible heterogeneous reactions of ozone with different aerosol particles are of particular interest for urban air quality. So-called reactive oxygen species (ROS) play a key role in chemical transformations and adverse health effects [
9,
10]. They are closely linked through radical reactions and cyclic transformation into toxic or allergenic airborne particles. Different types of ROS can pass through different types of tissues, for example, the human respiratory tract [
11]. Many heterogeneous reactions of O
3 with aerosol particles are also being studied. Polycyclic aromatic hydrocarbons (PAHs) are a prominent group of organic aerosol constituents that could readily react with ozone to the detriment of human health. PAHs are an integral part of soot and other carbonaceous combustion aerosol particles. They have the ability to penetrate deep into the human lungs. A chemical reaction with O
3 can alter their toxicity. Ozone can also promote the nitration of protein molecules contained in biological aerosol particles such as pollen or fungal spores [
12,
13]. This reaction can increase the allergenic potential of proteins. As a result, airborne soot or pollen can become toxic through oxidation or nitrification processes. This causes inflammation, and inhaled allergens can increase the risk of respiratory diseases [
14].
One such BVOC is the biogenic hydrocarbon isoprene. Due to its high reactivity, it can form ozone. Compared to anthropogenic hydrocarbons, the precursor isoprene could lead to such O
3 formation at extremely low concentrations. The emission rate depends on the meteorological conditions and their effect on the vegetation (leaf temperature) [
15]. According to this, clear and calm weather conditions with high solar radiation and a high air temperature are most likely to lead to a high emission rate of isoprene from plant leaves.
The team of the SmartCity Living Lab of the DFKI takes care of data governance and data management to ensure sufficient data quality as the research project’s results and implementations are based on heterogeneous data. Adequate and high-quality databases are crucial for the quality of automated applications and artificial intelligence methods. Conversely, as in this case, AI can also be used to create or improve a desired database.
The city of Kaiserslautern was selected as one of seven model communities in the project and has been working closely with researchers from DFKI and RPTU for several years as part of the Model Project Smart Cities (MPSC) funded by the German Federal Ministry of Housing, Urban Development, and Construction (Bundesministerium für Wohnen, Stadtentwicklung und Bauwesen, BMWSB). It provides data, establishes connections between different stakeholders, and uses its channels of communication with citizens to actively involve them.
3. Approach
In order to supplement the tree cadastre with additional information, an initial investigation is required to assess the available databases and existing AI models. An evaluation was conducted to determine the suitability of the available data and the transferability of the models in this use case. The quality of the data plays a crucial role in the quality of the results, with particular emphasis on the attributes of completeness and accuracy.
The existing municipal tree cadastre, which contains the attributes’ location and species/genus, is first used to train a model that identifies additional tree locations. Since some trees are missing in the present dataset, especially those on private property, a significant amount of re-labeling is required here. It is planned that in further steps, other models will be trained to complete the genus of the newly detected trees using street view imagery and to identify the main tree species within urban tree clusters. An expert review is required to assess the quality of the results. In this way, the models can be successively improved.
In addition, the tree cadastre will be extended to include other attributes such as height, trunk diameter, or location. Two approaches will be followed:
Existing deep learning models can be applied to the available data and, in turn, optimized through a feedback loop by experts.
Automated applications (even without the use of AI) can augment certain features on a large scale.
The first methodology requires training data that can be labeled using a crowdsourcing approach. Interested members of the public, supported by experts and using user-friendly and intuitive software, record new features from a set of trees. In this way, the overall dataset is enriched with the relevant attributes.
3.1. Examination of the Available Databases
There are several data sources that provide information on urban trees in Kaiserslautern. These need to be assessed for availability and data quality first. Depending on the application, various criteria are assigned different weights and evaluated accordingly. In this case, the accuracy, accessibility, and availability of the data are particularly important. Incomplete but reliable data can be used to complete the dataset with the help of automated applications.
In order to use data sources as training data for AI methods, they should be as error-free as possible; otherwise, the model may reproduce these errors. In addition, it makes sense to use datasets that are already available to public administrations or that can be easily obtained or generated so that a model can be applied to other public administrations in the future.
The timeliness of the data is initially less important in this use case, as only a small proportion of the total number of trees are cut down or replanted. Other characteristics, such as height, are constantly changing. Inaccuracies must generally be expected and quantified using appropriate methods. This aspect needs particular consideration in applications where these characteristics are utilized.
3.1.1. The Tree Cadastre Managed by the Public Administration of Kaiserslautern
The tree cadastre of the city of Kaiserslautern contains very precise GPS coordinates of approximately 16,600 trees, along with their corresponding genus or species designation. However, a spot check of the data conducted through on-site inspections and image assessment revealed that a significant number of trees, not only on private properties, have not yet been documented (see
Figure 2). Furthermore, either genus or species is given, although the former may be derived from the latter but not vice versa. For many applications, however, the genus is sufficient information.
3.1.2. OpenStreetMap
There are initiatives within the OpenStreetMap (OSM) community to map trees and tree areas with distinct tree characteristics. However, at least in the city of Kaiserslautern, there are currently only a limited number of entries so far, totaling approximately 1000. In addition, GPS locations recorded with a smartphone may be too inaccurate for certain applications. Additionally, the quality of the data collected thus far remains uncertain. OpenStreetMap provides some attributes that can serve as a guide for the integration of newly generated data into the platform in the future. It is important to note, however, that some attributes have implications for others. For instance, the deciduous or coniferous nature of a tree can be inferred from its genus, but the reverse is not possible. On the other hand, this attribute is easily understood by individuals lacking knowledge of tree species or the technical tools to identify them. Additionally, a distinction exists between the ‘height’ and ‘estimated height’ attributes, preventing the misinterpretation of incorrect or roughly estimated information as accurate [
16].
3.1.3. Aerial Imagery
The city of Kaiserslautern possesses aerial imagery captured at various times of the year and at different resolutions. Initially, we utilized images from the spring aerial survey of 2018, which are openly accessible at a resolution of 40 cm through the geoportal of the federal state of Rhineland-Palatinate [
17]. Higher-resolution aerial images with a ground resolution of 6 cm are not freely available for data protection reasons but are provided by the municipality for research purposes.
One objective was to assess whether and under what circumstances higher resolution leads to improved detection. If the benefits of a higher resolution are not significant, the use of freely available, non-protected data becomes feasible. This facilitates the transferability of results to other municipalities and the application of models to more recent aerial images.
Furthermore, a comparison will also be made with flights from other seasons, each with different foliage conditions. It is expected that the preference for different seasons will vary depending on the application. For example, when determining the location (tree disc, tree row, or green area), it is likely that aerial imagery from seasons without foliage will give better results.
3.1.4. Street View Images
In the autumn of 2021 and in the summer of 2023, the city of Kaiserslautern conducted a comprehensive survey of the entire city area, capturing panoramic images and LIDAR data. This enables precise measurements (height, crown diameter, and trunk diameter) to be made without the necessity of physically inspecting the locations using suitable software. A direct comparison of the trees in OSM with the street survey images of the corresponding section of the park readily reveals that only a fraction of the trees have been documented in OSM (see
Figure 3).
3.2. Selection, Application, and Adaptation of AI Methods for Position and Species Determination
There are already existing approaches for detecting urban trees. The transferability to Kaiserslautern depends, among other factors, on the data used to train the existing models. If training data from regions with very significantly different vegetation were used, it is questionable whether the corresponding model would deliver meaningful results with the local images. In addition, the season must be considered. Furthermore, most models perform well for individual trees. For tree clusters, an alternative approach needs to be developed.
3.2.1. Proposed Model Based on Ventura et al. [3] Applied to the Aerial Imagery of Kaiserslautern
Ventura et al. trained a convolutional neural network (CNN) using aerial imagery from California, providing a confidence map from which the tree location can be obtained [
3]. Based on this architecture (see
Figure 4), we conducted experiments with different datasets and backbones, as depicted in
Table 1. We observed the best results while using a combination of the Urban Tree Detection Dataset (UTD) from Ventura et al. [
3] and our dataset as described in
Section 3.2.2 together with a ResNet50 backbone. We chose to stick to the basic U-Net [
18] architecture with two heads from Ventura et al. [
3] as they conducted extensive experiments and found this set-up to perform best. As the VGG16 backbone is based on an old architecture, we chose to replace it with a ResNet50. With this model, we obtained a maximum accuracy of 0.778 and a corresponding recall of 0.783 (see
Table 1 and
Figure 5).
That means that less than 80% of the trees are detected. In addition, about 21% of the detected trees are not trees but something else. Using imagery with higher resolution did not improve the results. However, there are several possible explanations for this outcome and thus promising approaches to improving it. In the data preprocessing, some forest-like areas of Kaiserslautern had to be masked as it was impossible to label trees there (see
Figure 6). The handling of those masked areas will be discussed in
Section 3.2.2. In addition, the model had four channels (RGBN), whereas the aerial imagery in Kaiserslautern had only three (RGB). Another promising model was trained on trees outside cities and then fine-tuned on urban trees in Munich [
4].
3.2.2. Positioning Challenges
Two quality measures of AI applications are accuracy and coverage. In this context, accuracy refers to capturing as many trees as possible while minimizing errors. For example, no trees should be detected where none exist (false positives, FP), which may result from misclassification of another object or noise in the data. Conversely, no trees should be overlooked. False negatives (FN) may occur when image quality is poor or environmental conditions are unfavorable.
As many trees are already missing from the municipal tree cadastre, prioritizing high coverage is desirable. Erroneously detected trees can be promptly removed from the dataset by volunteers in the field using a web application for editing the tree attributes. In contrast, adding unrecognized trees is more complex, requiring accurate GPS coordinates.
For pragmatic reasons, urban tree cadastres normally only include trees on public land for which the city is responsible for maintenance and safety compliance. AI, on the other hand, detects all trees in the given images, including those on private land. This is particularly relevant for use cases dealing with shading and air quality [
1], to show the ratio of ‘high emitter’ to ‘low emitter’ plants.
A misalignment in ratios could indicate that it might be contraindicated to have numerous tree species with high isoprene emission potential. Likewise, when comparing new planting with climate-adapted construction throughout the urban area, the predominant species need to be considered at the planning stage to prevent such an imbalance. Consequently, a complete tree cadastre could help identify the locations of potential biogenic isoprene sources at an early stage and develop strategies to optimize the air quality situation.
The employed deep learning model encounters challenges in detecting individual trees when they are densely populated, as is often the case in forests. Generating sufficiently high-quality training data by manually annotating these densely packed tree patches also proves to be challenging. For this reason, these areas, primarily located on the outskirts of the city, were initially masked. This prevented the model from being trained on incorrect information and enhanced the usability of the results. It is anticipated that accuracy and recall will improve if smaller groups of trees in the urban area are also initially masked and the model is applied exclusively to individual trees. Those masked tree groups are being examined using other, more appropriate methods.
There are some approaches that can provide added value and additional information on tree clusters without having to manually record every single tree and its species:
Aerial imagery from different seasons can be used to estimate the proportion of deciduous and coniferous trees within a group of trees [
20].
There are approaches to calculating the total number of trees in a forested area, employing techniques known as crown segmentation. Although these methods do not provide precise locations, they infer that the location falls within the crown, indicating a specific area. However, the accuracy of the results is greatly influenced by the condition of the forest, with dense areas being particularly prone to distortion [
20].
The German forestry offices record the main tree species for each forested area. Existing approaches calculate these species classifications from satellite images [
20]. The applicability of those models to groups of trees on the urban fringe and in the city needs further investigation.
Deur et al. [
21] studied forest areas in Croatia with the three main tree species: oak, hornbeam, and black alder. Welle et al. [
20], on the other hand, differentiated between multiple main tree species: beech, oak, larch, and other broadleaves among deciduous trees, and spruce, pine, and Douglas fir among evergreen trees.
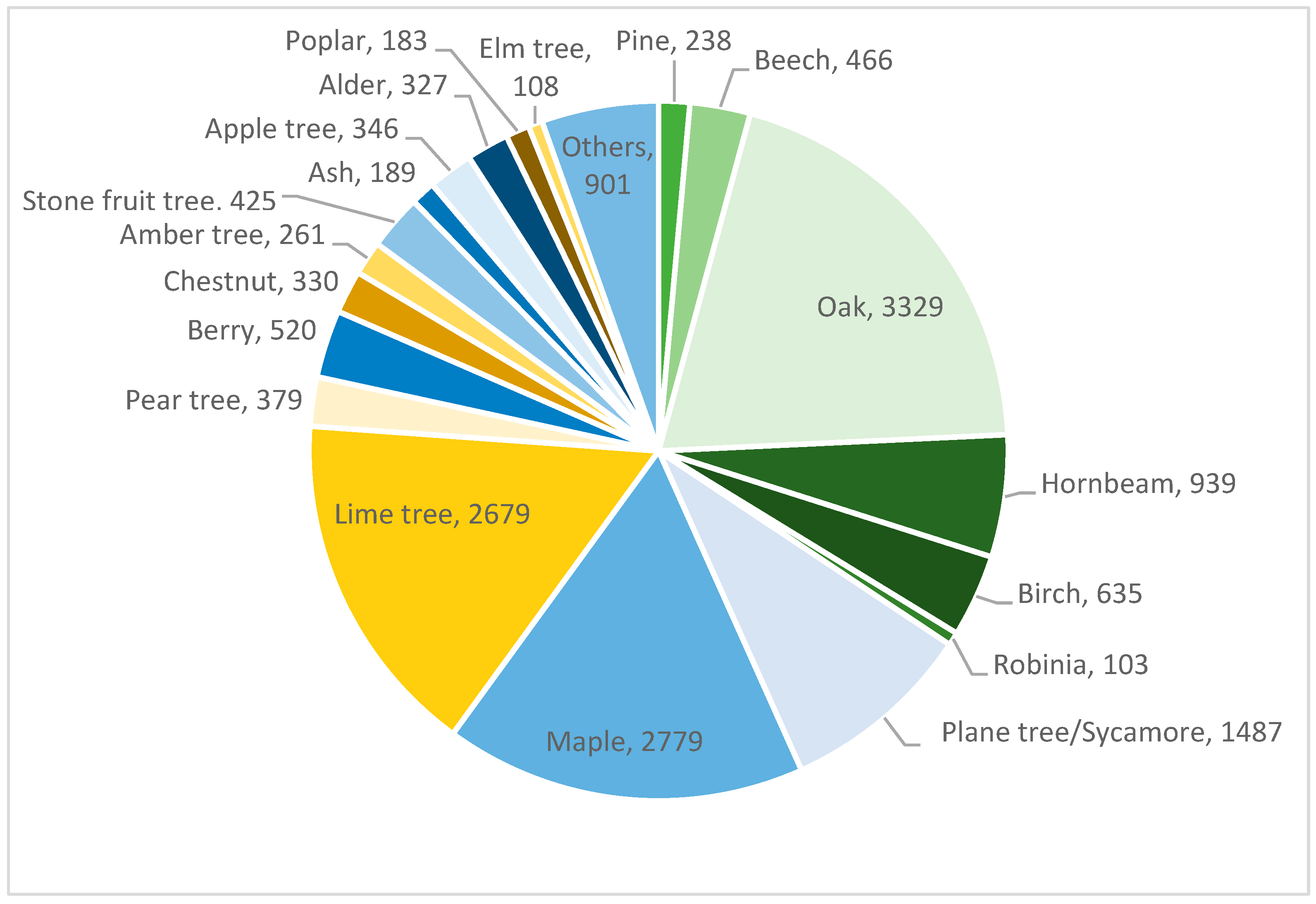
The diversity across the city as a whole is much higher than in the individual forest areas. An evaluation of the tree cadastre of Kaiserslautern reveals the occurrence of more than 200 different species from more than 50 different genera occurring there (see
Figure 7). This suggests that an application of models [
22] may not yield meaningful results. However, when examining the diversity of an urban tree plot, a different scenario emerges. Analyses of tree groups, where individual trees cannot be distinguished due to density in aerial images, indicate that the same main tree species dominate as in forests.
The example depicts an urban forest-like tree area covering just under 4000 square meters with a total of 101 recorded trees. There are only six different species: pine, beech, oak, hornbeam, robinia, and birch. The predominant tree species is clearly evident (see
Figure 8).
3.2.3. Species Identification of Urban Trees with AI
Identifying the species of individual trees newly added to the cadastre is much more complex. Two approaches based on the original cadastre will be followed. The first is to test how well a model based on high-resolution aerial imagery can categorize species. As training data are expected to be too sparse for this, a second approach will be pursued using panoramic images. These and existing tree classification models will be used to fill in the missing species information.
3.3. Adding Other Features
In addition to species and location, other features are relevant and should be added as far as possible. Prioritization will depend on the specific use case. In the context of the project, location and elevation have a high priority. The features used in OSM provide guidance (see
Table 2).
It is important to note that all attributes are subject to variability. Height undergoes changes over time, and there are instances where a tree is felled and a different species is planted in the same location. Therefore, the tree cadastre needs to be regularly updated or referenced.
OSM also records the significance of a tree. This includes additional information, such as whether a tree is a natural monument, a special landmark, or has historical significance. Such attributes are not considered here as they are not relevant in the local climatic context; others have to be added instead (see
Table 3).
3.4. Automated Feature Extraction
Measurable attributes such as height, stem diameter, and crown diameter can be automatically calculated for trees with known positions derived from the LIDAR data (see
Figure 9) collected during the road surveys in autumn 2021.
3.5. Applying Deep Learning Models to Extract Further Attributes
We need to adapt other deep learning models capable of determining the tree’s location. Is it within a tree disc, a green strip, or a green area? This significantly influences the tree’s water requirements. In tree discs, species-typical root development into the wetter soil layers is sparsely possible, compounded by debris in the subsoil and the presence of infrastructure such as pipes, cables, and lines.
Recording these attributes can therefore be used to predict potential drought stress and help prioritize urban tree irrigation.
Certain characteristics present in well-maintained tree cadastres are not easily added automatically based on existing data sources. These include the age of the tree and the date of planting. The former can be roughly estimated from height and species, or an interval could be provided. Regarding the planting date, additional data sources (e.g., development plans) could provide further information, but it is only possible to estimate the earliest planting date. Therefore, this feature is not considered.
3.6. Civil Society Involvement
Concurrently with the initial testing and refinement of AI methods, a user-friendly and intuitive web application is being developed to enable the involvement of interested citizens. This application should enable users to easily add new features or edit existing ones. Additionally, the use of other tools, such as tree species identification apps or measurement tools, is recommended. Experts should be available regularly for introductions and advice.
In the web application, existing trees are displayed in a map view, similar to the portal from the Technologiestiftung Berlin [
5]. Clicking on one of these points opens a window with additional information. There should also be an option to register, so that, after logging in, users can edit or add features and provide information about missing or felled trees.
Initiated and managed by the researchers, with support from students and city staff, there will be regular action days, for example, as part of the nationwide Digital Day. During these events, participants can either check existing attributes or add new features. This data could serve as a training base for further AI models.
3.7. Portability, Evaluation and Maintenance
The code of the deep learning models as well as the trained weights of the models will be openly shared. This will enable other municipalities to create or improve their own digital tree cadastres with the required data sources with considerably less effort.
Furthermore, by using the models with data collected in the future, it will be possible to monitor and compare which trees have been felled, planted, or replaced without being recorded in the tree cadastre.
In the long term, the employed methods should undergo evaluation. For example, in cases where tree heights have been updated on the basis of species, original height, and time elapsed since the height was recorded, a comparison with the actual new height should be made to refine the process.
4. Summary and Outlook
Creating and maintaining a high-quality tree cadastre is a time-consuming task, yet it is increasingly urgent and crucial, especially in the context of climate change. A digital tree cadastre can assist municipal staff to better integrate environmental and climate considerations, enabling more sustainable decisions in urban planning. This includes the selection of appropriate tree species for specific locations and the prediction of potential drought stress, shading, and possible impacts on air quality under certain weather conditions. By including private trees and encompassing additional features, the tree cadastre can become more comprehensive and applicable for a broader range of scientific applications.
The further development of deep learning models allows not only the transfer to other municipalities but also a regular update with newly captured aerial and panoramic images. This ensures ongoing data maintenance and monitoring. Using appropriate interfaces, portals, and web applications, the data should be publicly accessible and editable.
The collaboration of various stakeholders from research, administration, and the public is both challenging and crucial for the success of the project. Transparent communication with simple explanations and understandable reasons for participation is essential.
It is also advisable, after testing different AI models on different databases, to conduct an evaluation to define criteria for the selection of data and models. Additionally, uniform and simplified procedures should be established for the collection and periodic updating of the tree cadastre and, especially, for handling potential errors from AI applications, which cannot be completely avoided.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}