
Bearing Fault Diagnosis Based on Image Information Fusion and Vision Transformer Transfer Learning Model


Abstract
:1. Introduction
- (1)
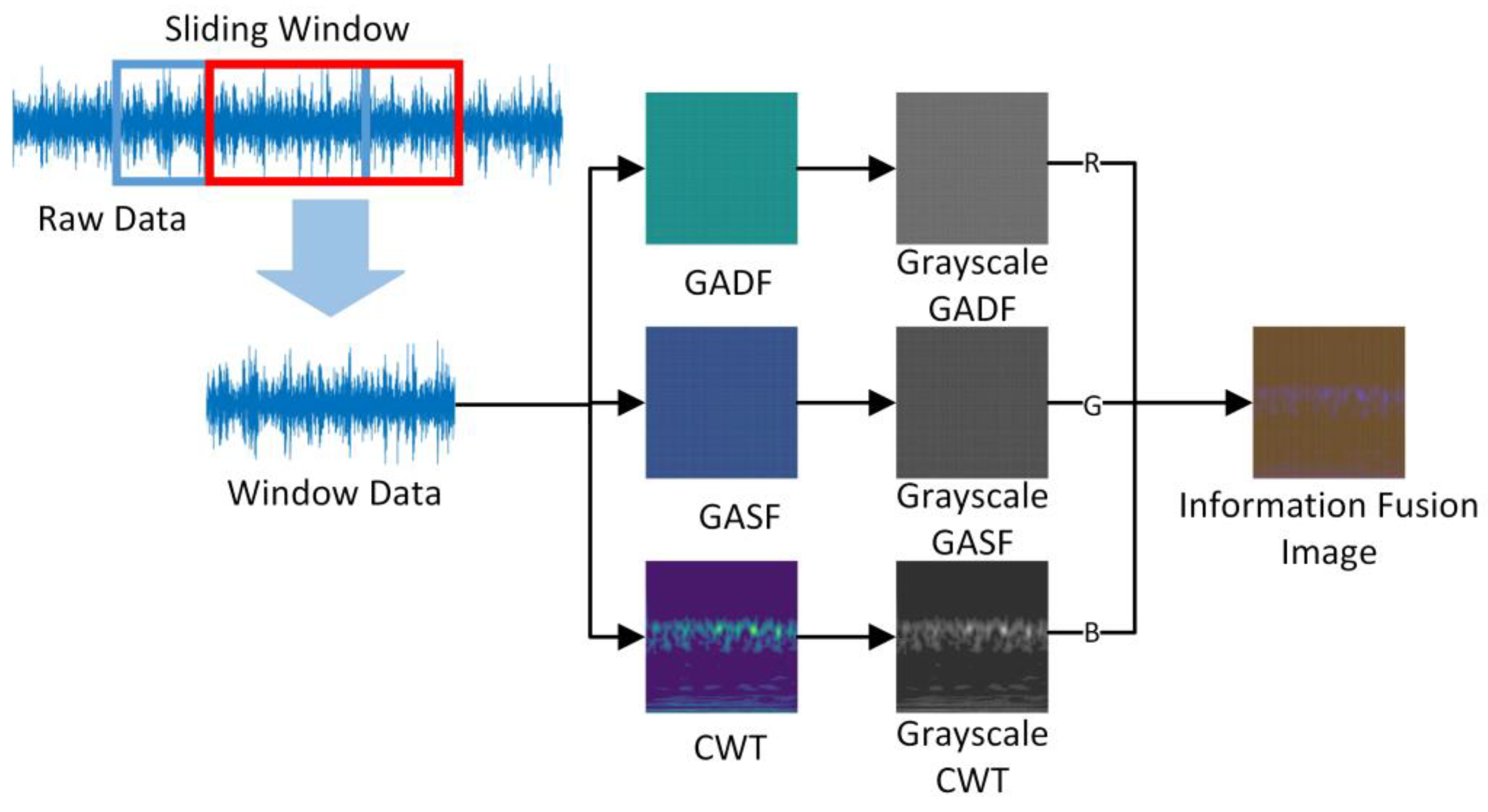
- In response to the problem that a single image generation method is unable to describe the features of time-domain vibration signals from multiple perspectives, resulting in poor generalization and noise resistance of the fault diagnosis method, this paper combined images generated using different methods into Information Fusion Images (IFI) based on image channel splicing. The IFI combined the information provided by the GAF method and the CWT method, which has both time sensitivity and frequency domain information, and can represent the effective information contained in the original time series data more comprehensively, which is conducive to the deep learning model to learn various fault characteristics and improve the accuracy and robustness of fault diagnosis.
- (2)
- In order to address challenges such as difficult data collection, limited sample size, and complex operating conditions in real production environments, this paper used a fine-tuned transfer learning Vision Transformer (TLViT) model. The model was pre-trained on a data-rich domain and then transferred to a domain with limited samples. This approach tackles the issue of ViT models requiring a large amount of training data to learn image features and reduces the demand for bearing fault data volume.
- (3)
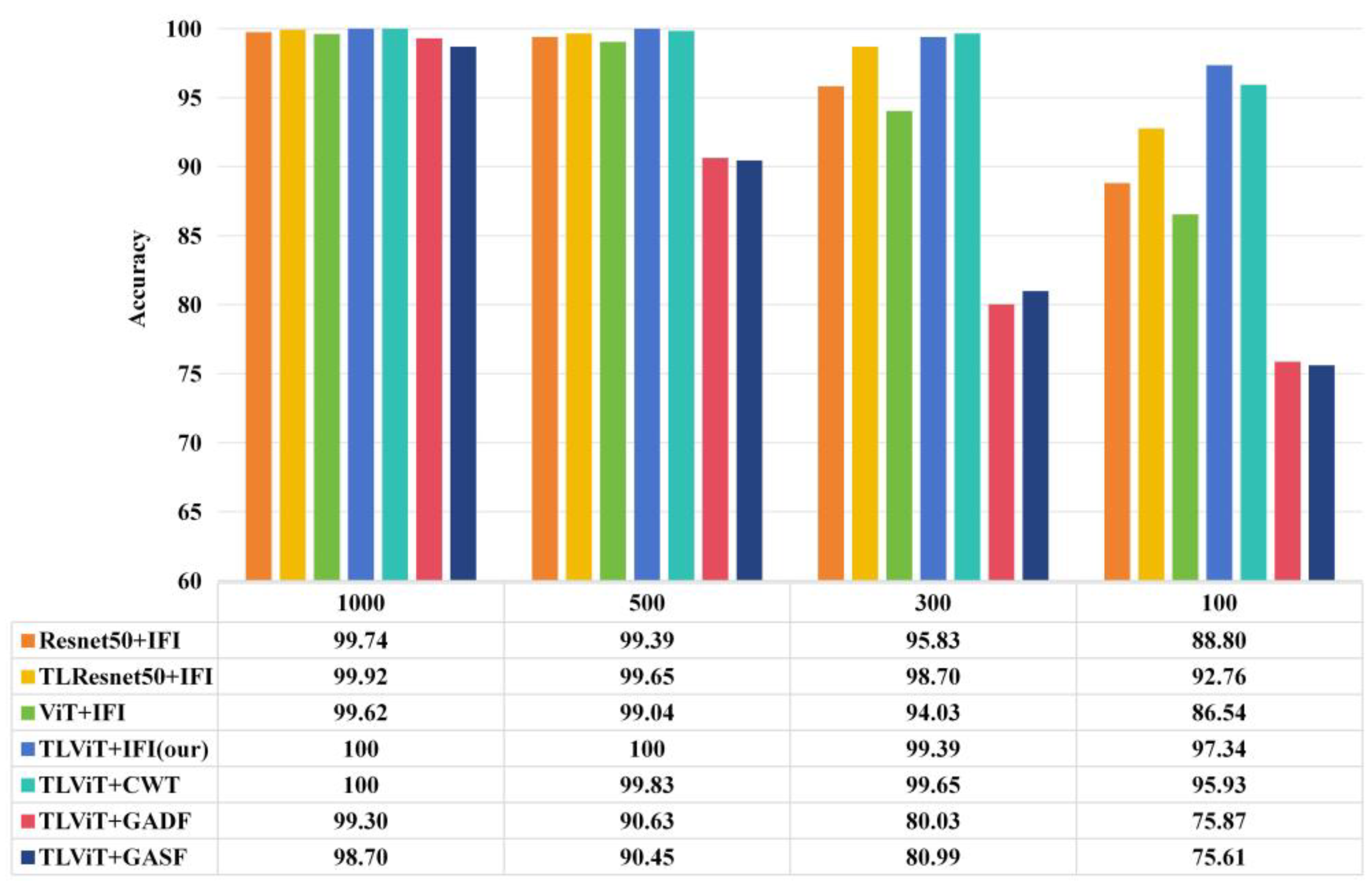
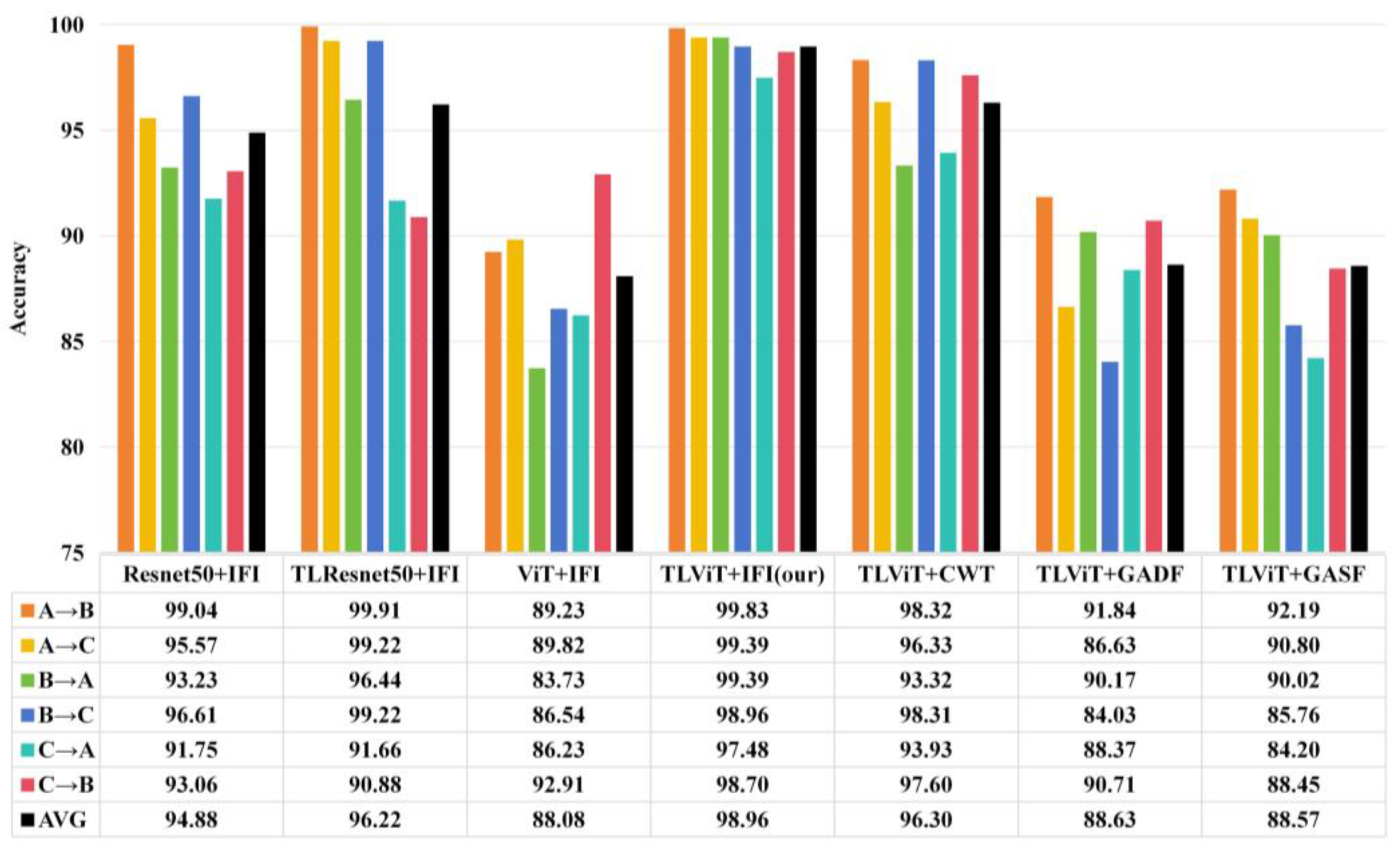
- In order to prove the effectiveness and generality of the proposed method, a dataset from Case Western Reserve University (CWRU) was selected to perform small-sample performance tests, variable load performance tests, and noise resistance tests on the proposed method [33]. The ViT model, Resnet50 model, and Resnet50 model based on transfer learning training (TLResnet50) were used as the baseline model, and the TLViT model was trained and tested on IFI dataset; then the TLViT model was trained and tested in the image dataset generated using CWT, GASF, and GADF, respectively, and, compared with the proposed TLViT + IFI, it was confirmed that the proposed method has higher fault-diagnosis accuracy.
2. Correlation Method
2.1. Continuous Wavelet Transform
2.2. Gramian Angular Field
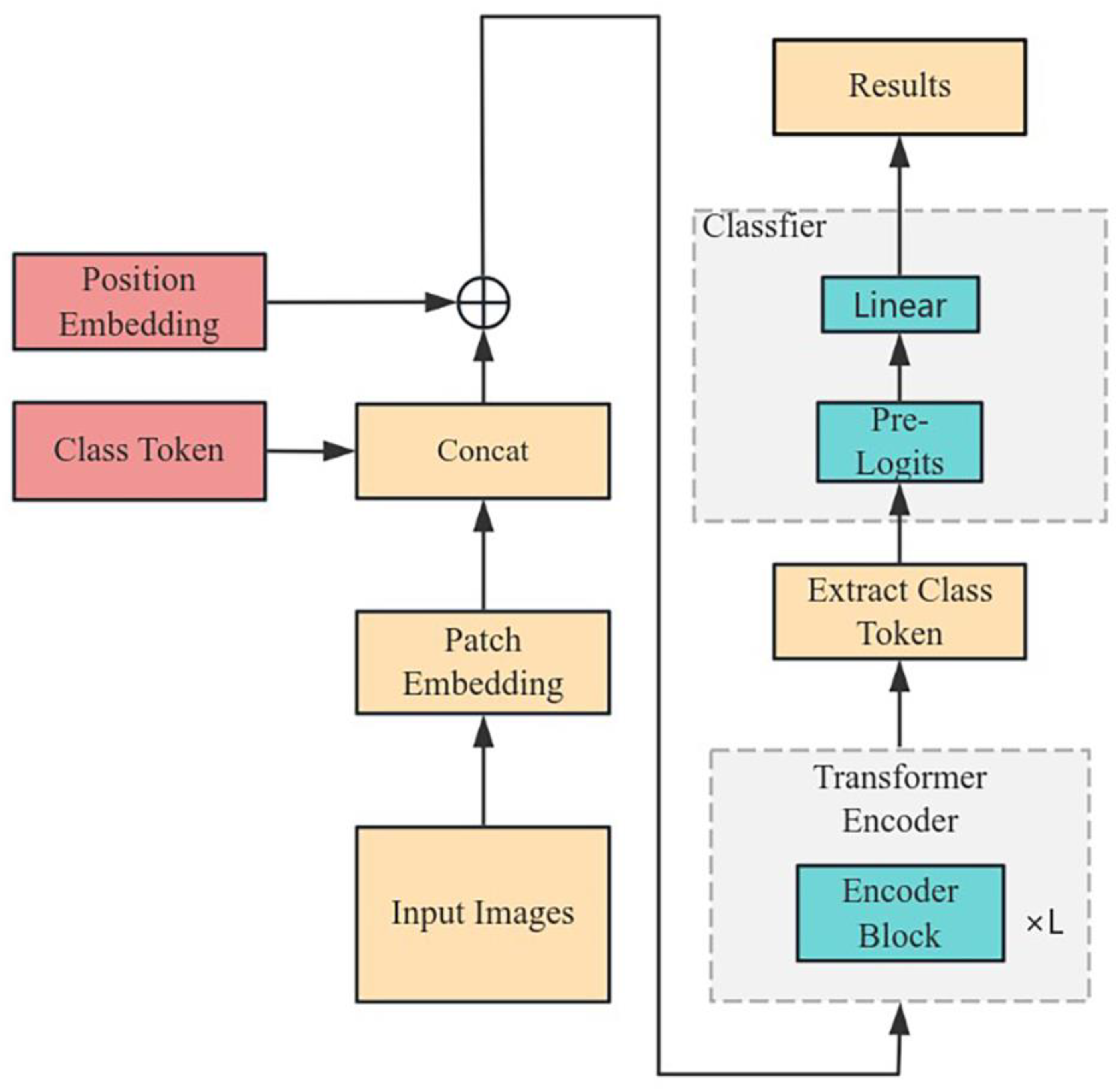
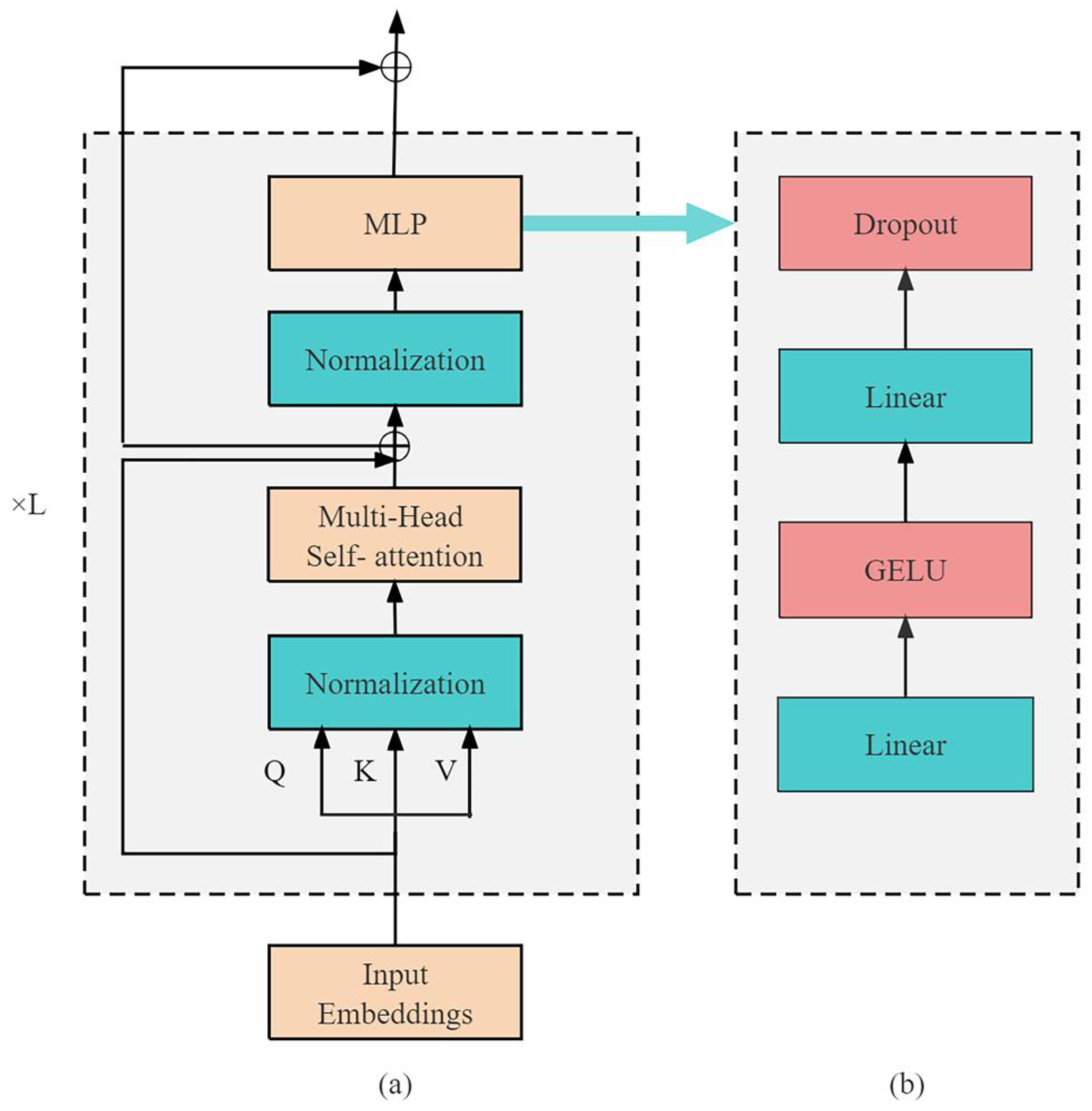
2.3. Vision Transformer
2.4. Transfer Learning
3. Fault Diagnosis Experiment and Analysis
3.1. Dataset
3.2. Experimental Data Preparation
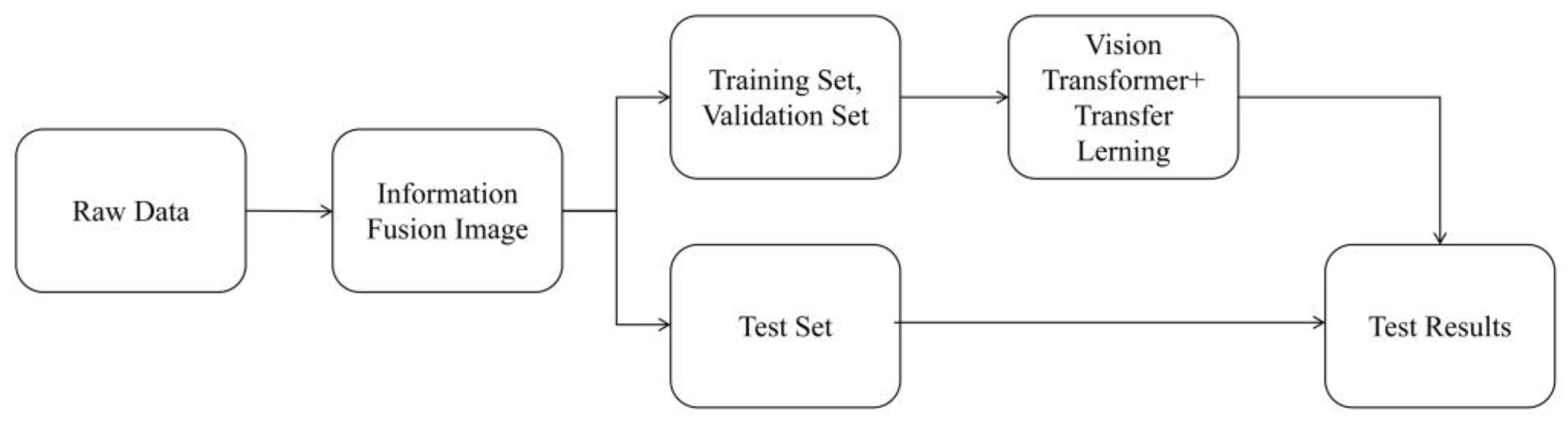
3.3. Fault Diagnosis Process
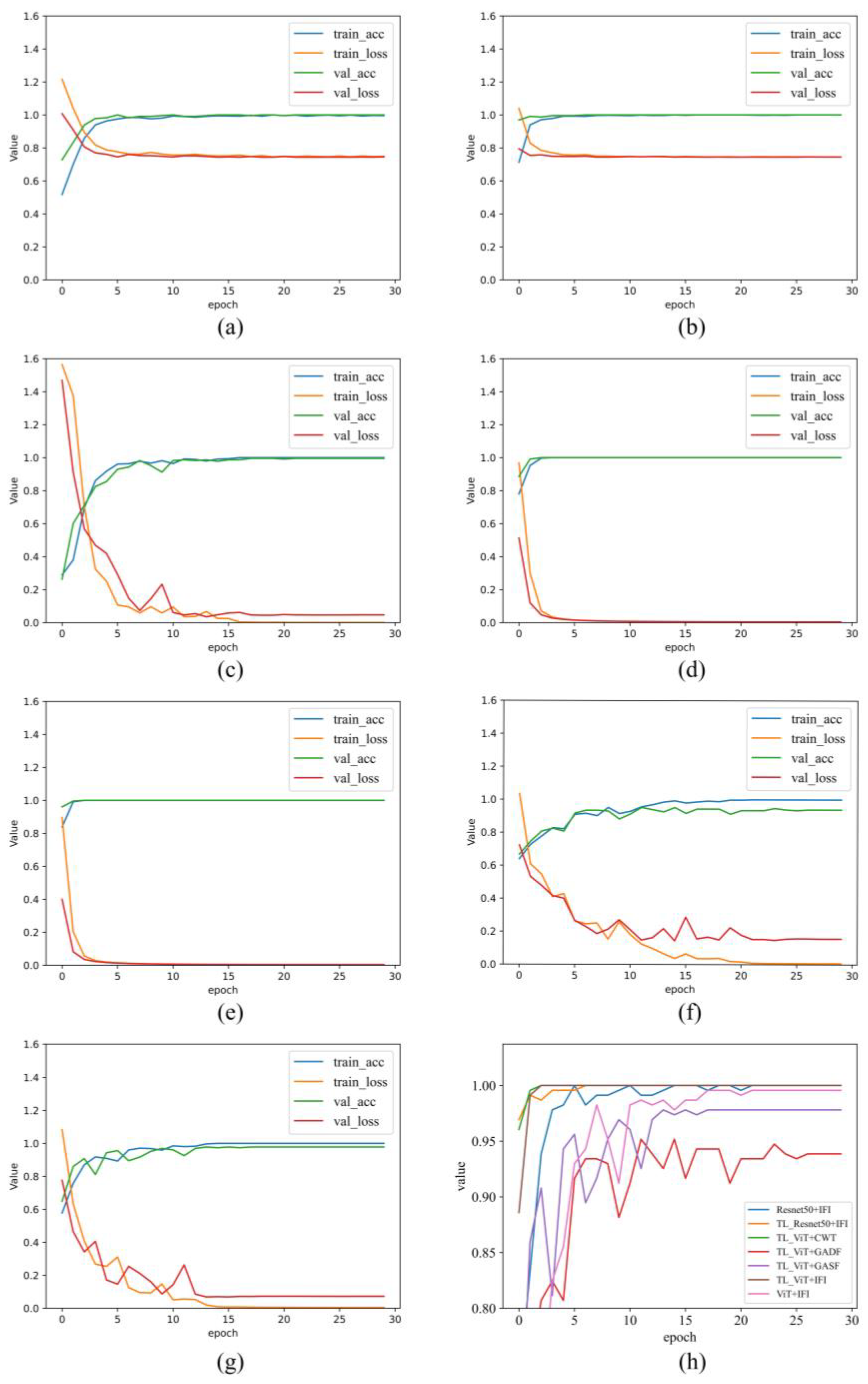
3.4. Model Training
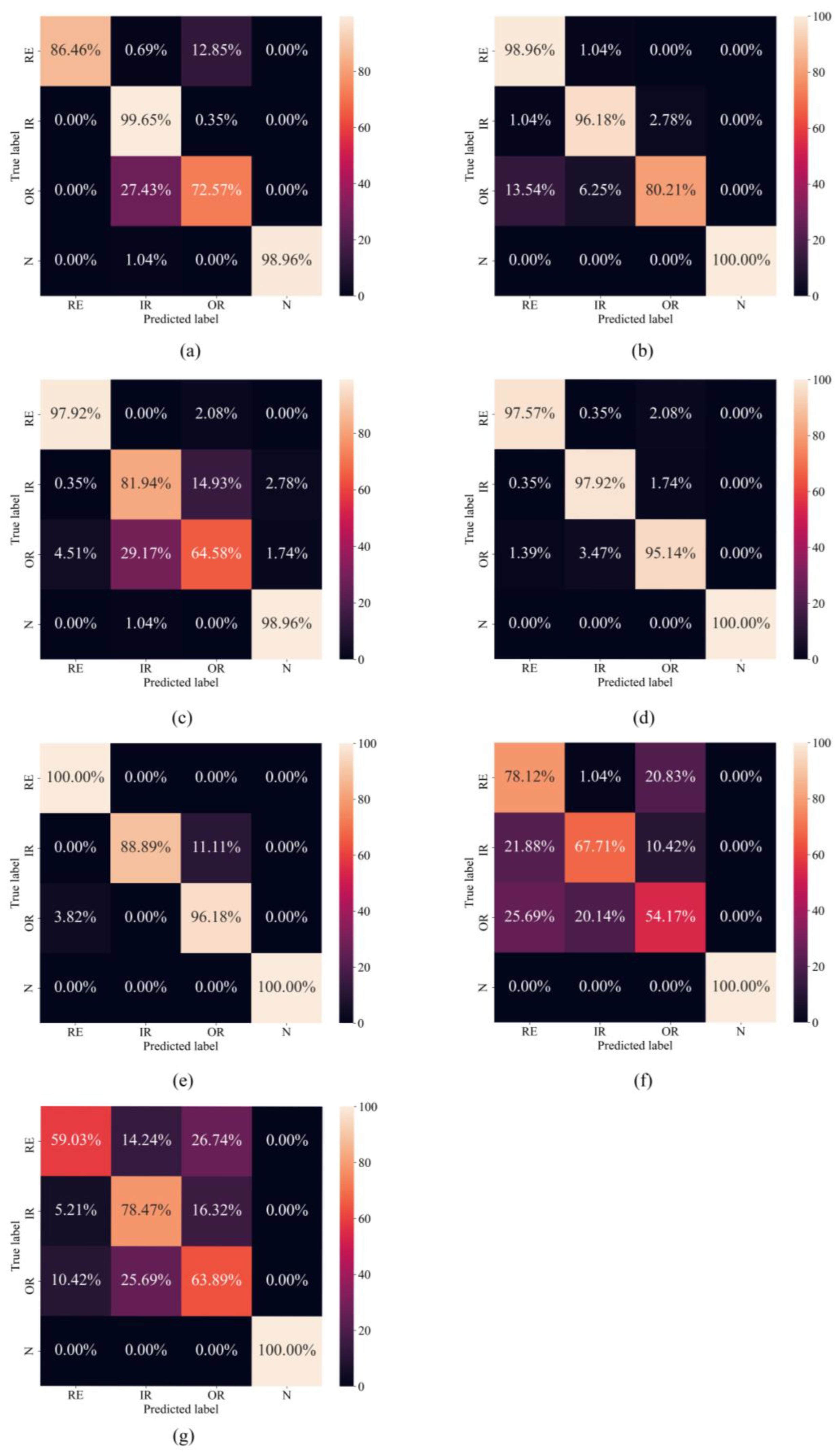
3.5. Experimental Analysis of Small Samples
3.6. Experimental Analysis of Variable Motor Load
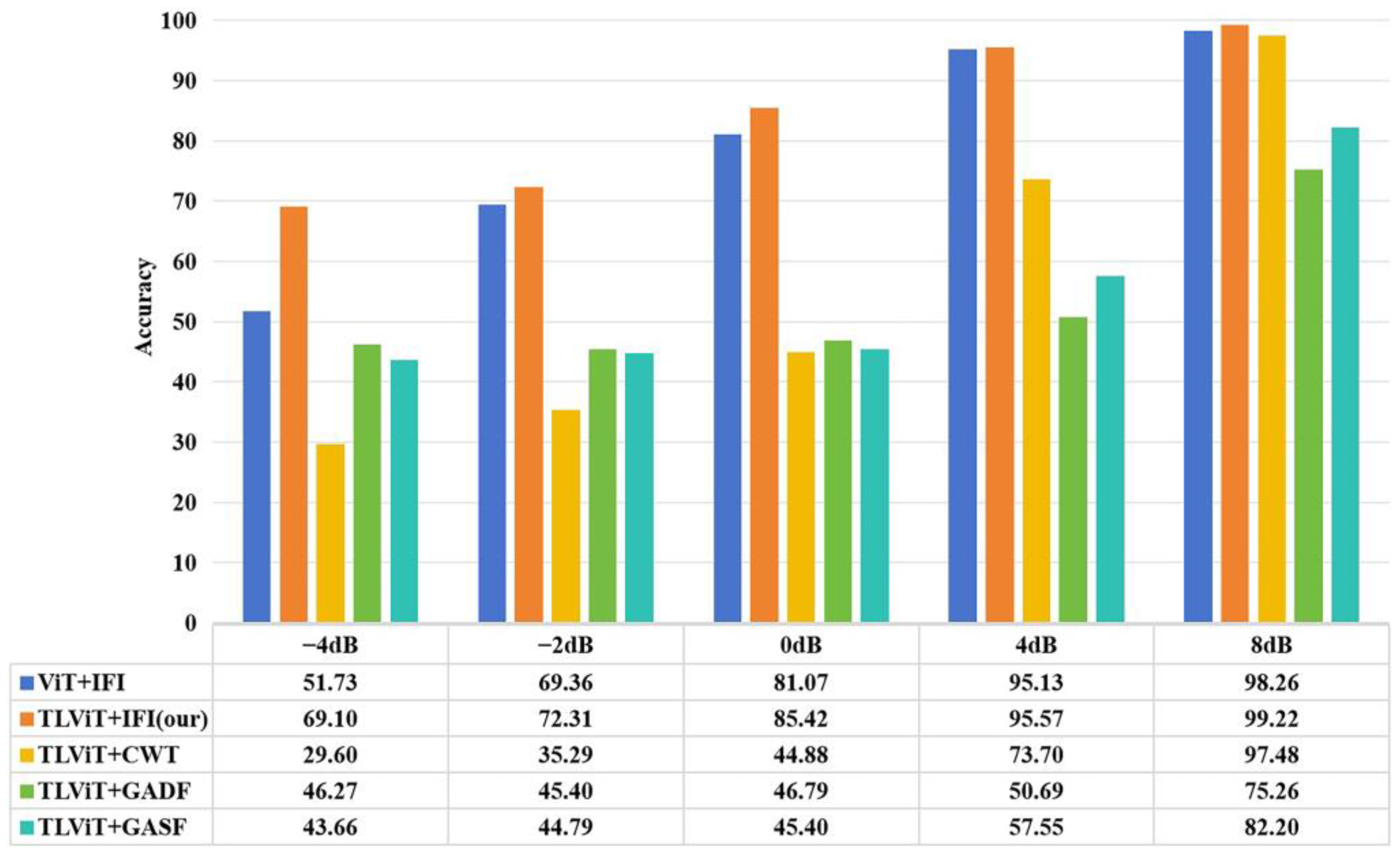
3.7. Experimental Analysis of Anti-Noise Ability
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rai, A.; Upadhyay, S.H. A Review on Signal Processing Techniques Utilized in the Fault Diagnosis of Rolling Element Bearings. Tribol. Int. 2016, 96, 289–306. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Wang, B.; Habetler, T.G. Deep Learning Algorithms for Bearing Fault Diagnostics—A Comprehensive Review. IEEE Access 2020, 8, 29857–29881. [Google Scholar] [CrossRef]
- Song, W.; Xiang, J. A Method Using Numerical Simulation and Support Vector Machine to Detect Faults in Bearings. In Proceedings of the 2017 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Shanghai, China, 16–18 August 2017; pp. 603–607. [Google Scholar]
- Zhu, H.; Li, X.; Liu, H. Fault Diagnosis of Rolling Bearing Based on WT-VMD and Random Forest. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 2130–2135. [Google Scholar]
- Amarnath, M.; Sugumaran, V.; Kumar, H. Exploiting Sound Signals for Fault Diagnosis of Bearings Using Decision Tree. Measurement 2013, 46, 1250–1256. [Google Scholar] [CrossRef]
- Fuan, W.; Hongkai, J.; Haidong, S.; Wenjing, D.; Shuaipeng, W. An Adaptive Deep Convolutional Neural Network for Rolling Bearing Fault Diagnosis. Meas. Sci. Technol. 2017, 28, 095005. [Google Scholar] [CrossRef]
- Eren, L.; Ince, T.; Kiranyaz, S. A Generic Intelligent Bearing Fault Diagnosis System Using Compact Adaptive 1D CNN Classifier. J. Signal Process. Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Song, X.; Cong, Y.; Song, Y.; Chen, Y.; Liang, P. A Bearing Fault Diagnosis Model Based on CNN with Wide Convolution Kernels. J. Ambient Intell. Humaniz. Comput. 2022, 13, 4041–4056. [Google Scholar] [CrossRef]
- Guo, Y.; Zhou, Y.; Zhang, Z. Fault Diagnosis of Multi-Channel Data by the CNN with the Multilinear Principal Component Analysis. Measurement 2021, 171, 108513. [Google Scholar] [CrossRef]
- Liu, X.; Centeno, J.; Alvarado, J.; Tan, L. One Dimensional Convolutional Neural Networks Using Sparse Wavelet Decomposition for Bearing Fault Diagnosis. IEEE Access 2022, 10, 86998–87007. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y. Fault Diagnosis of Rolling Bearings with Recurrent Neural Network-Based Autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef]
- Zou, P.; Hou, B.; Lei, J.; Zhang, Z. Bearing Fault Diagnosis Method Based on EEMD and LSTM. Int. J. Comput. Commun. Control 2020, 15. [Google Scholar] [CrossRef]
- Pan, H.; He, X.; Tang, S.; Meng, F. An Improved Bearing Fault Diagnosis Method using One-Dimensional CNN and LSTM. J. Mech. Eng. 2018, 64, 443. [Google Scholar]
- Hoang, D.-T.; Kang, H.-J. Convolutional Neural Network Based Bearing Fault Diagnosis. In Proceedings of the Intelligent Computing Theories and Application, Liverpool, UK, 7–10 August 2017; Huang, D.-S., Jo, K.-H., Figueroa-García, J.C., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 105–111. [Google Scholar]
- Zhou, F.; Zhou, W.; Chen, D.; Wen, C. Rolling Bearing Real Time Fault Diagnosis Using Convolutional Neural Network. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 377–382. [Google Scholar]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Luo, H.; Bo, L.; Peng, C.; Hou, D. An Improved Convolutional-Neural-Network-Based Fault Diagnosis Method for the Rotor–Journal Bearings System. Machines 2022, 10, 503. [Google Scholar] [CrossRef]
- Guo, Y.; Mao, J.; Zhao, M. Rolling Bearing Fault Diagnosis Method Based on Attention CNN and BiLSTM Network. Neural Process. Lett. 2023, 55, 3377–3410. [Google Scholar] [CrossRef]
- Yang, S.; Liu, Y.; Tian, X.; Ma, L. Bearing Fault Diagnosis Based on Attentional Multi-Scale CNN. In Proceedings of the Intelligent Robotics and Applications, Yantai, China, 22–25 October 2021; Liu, X.-J., Nie, Z., Yu, J., Xie, F., Song, R., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 25–36. [Google Scholar]
- Yuan, X.; Zhang, H.; Liu, H. A Novel Fault Diagnosis Approach for Rolling Bearing Based on CWT and Adaptive Sparse Representation. Shock Vib. 2022, 2022, e9079790. [Google Scholar] [CrossRef]
- Zhang, Q.; Deng, L. An Intelligent Fault Diagnosis Method of Rolling Bearings Based on Short-Time Fourier Transform and Convolutional Neural Network. J Fail. Anal. Preven. 2023, 23, 795–811. [Google Scholar] [CrossRef]
- Zhou, Y.; Long, X.; Sun, M.; Chen, Z. Bearing Fault Diagnosis Based on Gramian Angular Field and DenseNet. MBE 2022, 19, 14086–14101. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, W. Role of Image Feature Enhancement in Intelligent Fault Diagnosis for Mechanical Equipment: A Review. Eng. Fail. Anal. 2024, 156, 107815. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: San Francisco, CA, USA, 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A Theory of Learning from Different Domains. Mach Learn 2010, 79, 151–175. [Google Scholar] [CrossRef]
- Shao, S.; McAleer, S.; Yan, R.; Baldi, P. Highly Accurate Machine Fault Diagnosis Using Deep Transfer Learning. IEEE Trans. Ind. Inform. 2019, 15, 2446–2455. [Google Scholar] [CrossRef]
- Wang, Z.; He, X.; Yang, B.; Li, N. Subdomain Adaptation Transfer Learning Network for Fault Diagnosis of Roller Bearings. IEEE Trans. Ind. Electron. 2022, 69, 8430–8439. [Google Scholar] [CrossRef]
- Wang, R.; Huang, W.; Wang, J.; Shen, C.; Zhu, Z. Multisource Domain Feature Adaptation Network for Bearing Fault Diagnosis Under Time-Varying Working Conditions. IEEE Trans. Instrum. Meas. 2022, 71, 3511010. [Google Scholar] [CrossRef]
- He, J.; Ouyang, M.; Chen, Z.; Chen, D.; Liu, S. A Deep Transfer Learning Fault Diagnosis Method Based on WGAN and Minimum Singular Value for Non-Homologous Bearing. IEEE Trans. Instrum. Meas. 2022, 71, 3509109. [Google Scholar] [CrossRef]
- Jiang, L.; Zheng, C.; Li, Y. Rotating Machinery Fault Diagnosis Based on Transfer Learning and an Improved Convolutional Neural Network. Meas. Sci. Technol. 2022, 33, 105012. [Google Scholar] [CrossRef]
- Bearing Data Center|Case School of Engineering|Case Western Reserve University. Available online: https://engineering.case.edu/bearingdatacenter (accessed on 20 March 2024).
- Lin, J.; Qu, L. Feature extraction based on Morlet wavelet and its application for mechanical fault diagnosis. J. Sound Vib. 2000, 234, 135–148. [Google Scholar] [CrossRef]
- Tang, B.; Liu, W.; Song, T. Wind Turbine Fault Diagnosis Based on Morlet Wavelet Transformation and Wigner-Ville Distribution. Renew. Energy 2010, 35, 2862–2866. [Google Scholar] [CrossRef]
- Xu, Z.; Tang, X.; Wang, Z. A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples. Machines 2023, 11, 277. [Google Scholar] [CrossRef]
- Cai, C.; Li, R.; Ma, Q.; Gao, H. Bearing Fault Diagnosis Method Based on the Gramian Angular Field and an SE-ResNeXt50 Transfer Learning Model. Insight—Non-Destr. Test. Cond. Monit. 2023, 65, 695–704. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Kai, L.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Introduction to TensorFlow. Available online: https://tensorflow.google.cn/learn (accessed on 20 March 2024).
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In Proceedings of the COMPSTAT’2010: 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186, ISBN 978-3-7908-2604-3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Motor Load (HP) | Motor Speed (RPM) |
|---|---|
| 1 | 1772 |
| 2 | 1750 |
| 3 | 1730 |
| Fault Diagnosis Method | Average Accuracy on the Test Set |
|---|---|
| Resnet50 + IFI | 99.72% |
| TLResnet50 + IFI | 100% |
| ViT + IFI | 99.12% |
| TLViT + IFI | 100% |
| TLViT + CWT | 100% |
| TLViT + GADF | 99.30% |
| TLViT + GASF | 98.70% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Li, J.; Cai, C.; Ren, J.; Xue, Y. Bearing Fault Diagnosis Based on Image Information Fusion and Vision Transformer Transfer Learning Model. Appl. Sci. 2024, 14, 2706. https://doi.org/10.3390/app14072706
Zhang Z, Li J, Cai C, Ren J, Xue Y. Bearing Fault Diagnosis Based on Image Information Fusion and Vision Transformer Transfer Learning Model. Applied Sciences. 2024; 14(7):2706. https://doi.org/10.3390/app14072706
Chicago/Turabian StyleZhang, Zichen, Jing Li, Chaozhi Cai, Jianhua Ren, and Yingfang Xue. 2024. "Bearing Fault Diagnosis Based on Image Information Fusion and Vision Transformer Transfer Learning Model" Applied Sciences 14, no. 7: 2706. https://doi.org/10.3390/app14072706
APA StyleZhang, Z., Li, J., Cai, C., Ren, J., & Xue, Y. (2024). Bearing Fault Diagnosis Based on Image Information Fusion and Vision Transformer Transfer Learning Model. Applied Sciences, 14(7), 2706. https://doi.org/10.3390/app14072706